一,操作步驟
1.通過瀏覽器打開嗶哩嗶哩
2.選擇一個播放量較合適的視頻(不要太大也不要太小 大概就50萬的樣子)比如我用的是:https://www.bilibili.com/video/BV1th411C7wA?spm_id_from=333.851.b_7265636f6d6d656e64.1
3.按F12打開源代碼,然后點擊network(網路)下面的XHR,然后再點擊播放視頻(不播放彈幕就顯示不了),這時XHR下面就有heartbeat的內容,上個圖給你們看看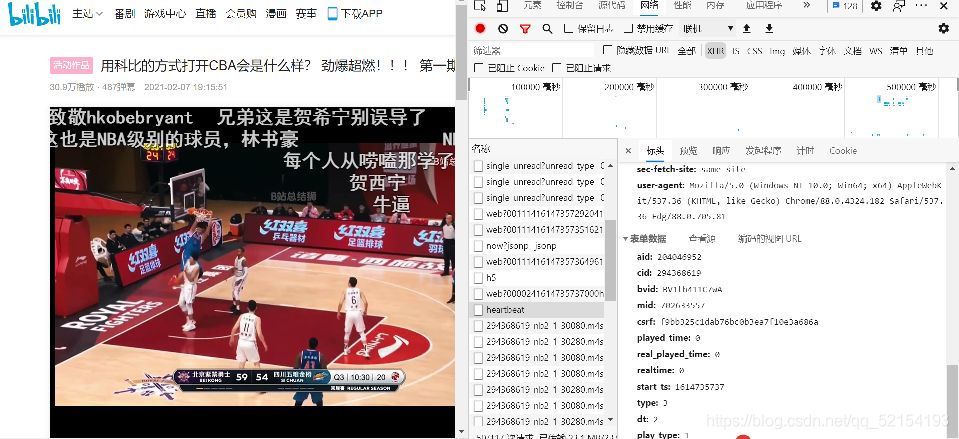
點擊這個heartbeat然后里面有一個cid 把cid的后面八位數字給復制了
4.每一個嗶哩嗶哩都有不同的cid,但是獲取評論的網址格式是一樣的:https://comment.bilibili.com/cid的八個數字.xml
5.打開獲取評論的網址頁面如下圖所示: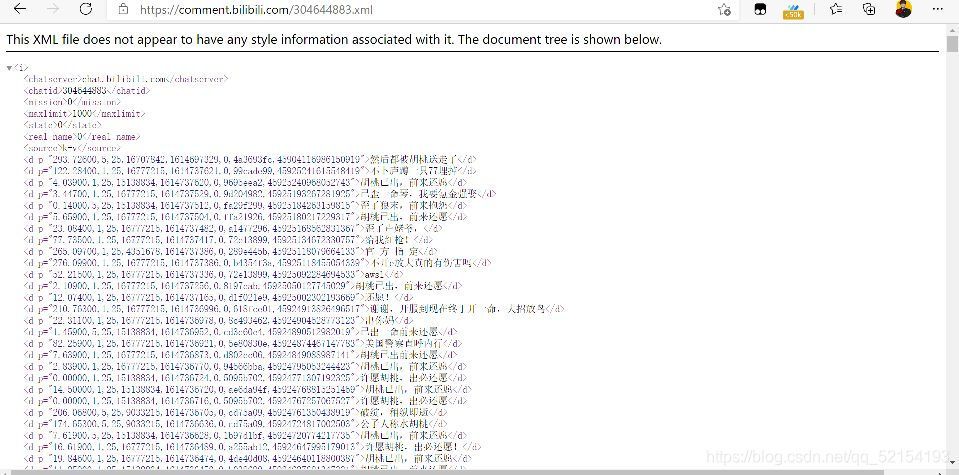
6.大家應該可以看到里面評論的所有內容都是包含再’d’內
那么就從d內提取所需內容
二、使用步驟
1.引入庫
代碼如下(示例):
import requests
from bs4 import BeautifulSoup
import lxml
import time
import pandas as pd
import jieba
from matplotlib import pyplot as plt
import wordcloud
from PIL import Image
import numpy as np
2.讀入實列代碼
代碼如下(示例):
def main(): #定義主函式
getdata()
def getdata(): #定義抓取網頁內容的函式
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81'
}
url = 'https://comment.bilibili.com/294368619.xml' #獲取評論的網頁鏈接,這個是我隨便挑的一個cid
html = requests.get(url,headers=headers)
bs = BeautifulSoup(html.content,'lxml') #用beautifulsoup來決議網頁
data = []
item = bs.find_all('d')
for item in bs.find_all('d'):
data.append(item.string.replace(' ','')) #把評論的里的空格符去掉
danmustr = ''.join(i for i in data)#把所有的評論連成字串
words = list(jieba.cut(danmustr)) #把字串拆分 并且以串列回傳
word = [i for i in words if len(i)>1] #把字串小于等于1個的排除并以串列型別回傳
#下面創造詞云庫
wc = wordcloud.WordCloud(height = 1000,width = 1000,font_path='simsun.ttc')
wc.generate(' '.join(word))
plt.imshow(wc)
wc.to_file(r'C:\Users\13772\Desktop\PS\nanren.png')#保存圖片
總結
代碼運行后得到圖:
爬取嗶哩嗶哩彈幕就到這里了 如果哪里有不懂的歡迎到評論區說一下,謝謝觀賞!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/266322.html
標籤:AI