文章目錄
- ConcurrentHashMap
- 一、ConcurrentHashMap初始化的剖析
- 1.1 ConcurrentHashMap初始化
- 1.2 理解sizeCtl
- 二、JDK8的添加安全
- 2.1 putVal原始碼分析
- 2.2 putVal原始碼程式流程圖
- 2.3 putVal閱讀原始碼總結
- 2.4 initTable原始碼分析
- 2.5 initTable原始碼程式流程圖
- 2.6 JDK8中ConcurrentHashMap添加安全總結
- 三、JDK8擴容安全
- 3.1 transfer原始碼分析
- 3.2 擴容安全圖解
- 3.3 JDK8中ConcurrentHashMap擴容安全總結
- 四、JDK8多執行緒擴容效率改進
- 4.1 方案1:putVal原始碼分析
- 4.2 方案2:helpTransfer原始碼分析
- 4.3 JDK中ConcurrentHashMap擴容效率提高圖解
- 五、集合長度的累計方式
- 5.1 addCount原始碼分析
- 5.2 fullAddCount原始碼分析
- 六、jdk1.8集合長度獲取
- 6.1 size原始碼
- 6.2 sumCount原始碼
- 七、JDK7中ConcurrentHashMap
- 八、相關面試題
ConcurrentHashMap
有別于HashMap的執行緒不安全和HashTable的低效率(稍微看了一下原始碼,發現使用了大量的synchronized關鍵字修飾的同步方法),ConcurrentHashMap使用的是cas來保證整個元素插入、洗掉、擴容時候的同步安全,充分解決了HashMap和HashTable存在的問題,
下面需要對ConcurrentHashMap的原始碼做一些解讀,讓讀者更好的理解ConcurrentHashMap的底層運行邏輯,
一、ConcurrentHashMap初始化的剖析
1.1 ConcurrentHashMap初始化
如果我們在new一個ConcurrentHashMap的時候給定引數,那么put之后,該ConcurrentHashMap的初始容量為大于給定引數的2的冪次方,比如
// 給定引數32,那么在put之后chm的初始容量為64(JDK7是還是32)
ConcurrentHashMap chm = new ConcurrentHashMap(32);
原因 是ConcurrentHashMap原始碼
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
//給定引數大于最大容量的1/2容量?若大于,初始容量為最大值2^30
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
//引數是32的話,傳入tableSizeFor的引數是32+16+1=49
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
如果并不大于最大容量的1/2,呼叫以下函式,
這段代碼是指,右移多少位,就把最高位右邊的第x位設定為1;第一次,就把最右邊為1;第二次,就把右邊第2位再設定為1;第3次,就把右邊第3位再設定為1;這樣執行完,原來是110000(48),變成了111111,最后加1,就變成2的整數次方數了(64),
private static final int tableSizeFor(int c) {
// 傳入49
int n = c - 1;
// n=48
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
// 此時n=63,最后經過兩次判斷后回傳值為64
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
1.2 理解sizeCtl
sizeCtl = 0,代表陣列未初始化,且陣列初始容量為16
sizeCtl > 0,如果陣列未初始化,那么其記錄的是陣列的初始容量,如果陣列已經初始化,那么其記錄的是陣列的擴容閾值
sizeCtl = -1,表示陣列正在進行初始化
sizeCtl < 0 && sizeCtl != -1,表示陣列正在擴容,-(1+n),表示此時有n個執行緒正在共同完成陣列的擴容操作,
二、JDK8的添加安全
首先我們來看ConcurrentHashMap的添加元素程序的原始碼
2.1 putVal原始碼分析
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 如果有空值或空鍵,會直接拋出例外
if (key == null || value == null) throw new NullPointerException();
// 基于key計算hash值,并進行一定的擾動(目的是使結果分步平均)
// 這個值一定是一個整數,方便后面添加元素,判斷該節點的型別
int hash = spread(key.hashCode());
//記錄某個桶上元素的個數,如果超過8個,會轉成紅黑樹
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果陣列還未初始化,先對陣列進行初始化
if (tab == null || (n = tab.length) == 0)
// 解讀原始碼1,陣列初始化
tab = initTable();
// if判斷是指,hash函式計算得到的陣列下標對應的桶中若為空,就利用cas直接把元素放入陣列
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 在這里也使用了cas自旋鎖操作,因為有可能有兩個執行緒進入當前位置,確保只能有一個執行緒訪問臨界資源
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果hash計算得到的桶位置元素的hash值為MOVED,證明正在擴容,那么協助擴容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 保證這個位置的桶元素插入時執行緒安全的,即對桶加鎖
// 不影響其他元素的桶位置插入;既保證安全,又不影響效率
// hashtable則是鎖了整個陣列
synchronized (f) {
// 保證還在該位置,比如變成樹或者擴容之后,位置改變了
if (tabAt(tab, i) == f) {
// 判斷hash值大于0 ,就表示當前情況下該位置桶還是鏈式結構
if (fh >= 0) {
binCount = 1;
// 遍歷鏈表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果在鏈表中找到了put中key值,那么就替換
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
// 完成替換之后就跳出回圈
break;
}
// 如果沒有找到該值,就在使用尾插法將Entry插入鏈表的尾部
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,value, null);
break;
}
}
}
// 當前位置為樹結構,將元素添加到紅黑樹中
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 以上就是ConcurrentHashMap添加元素的安全操作
// 從上面代碼可以得到,ConcurrentHashMap是通過對桶加鎖而不是對整個陣列加鎖,對效率有提高
if (binCount != 0) {
// 如果元素個數大于等于8且陣列長度大于64,就變成了樹
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
2.2 putVal原始碼程式流程圖
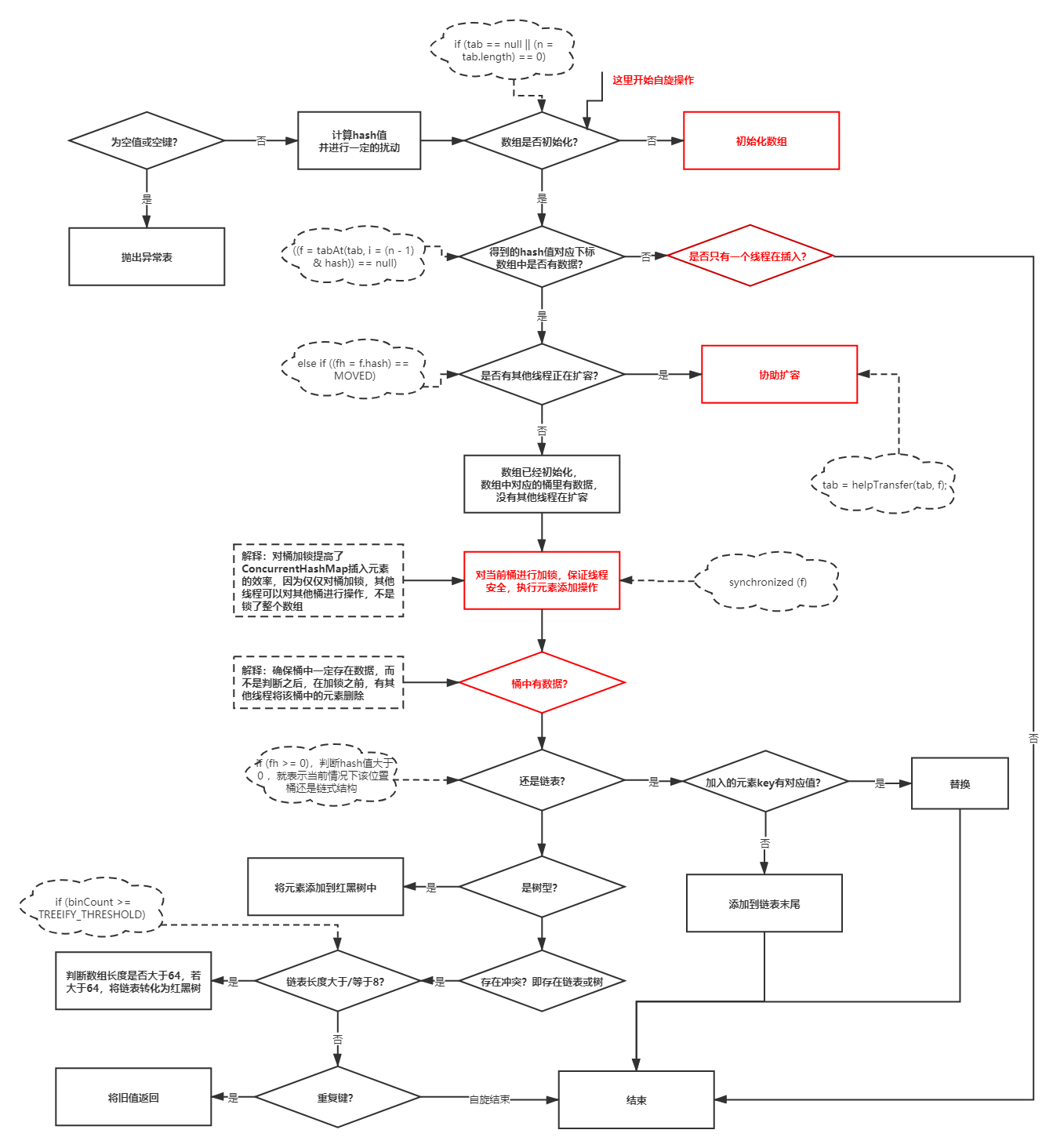
2.3 putVal閱讀原始碼總結
通過原始碼分析可以得到,ConcurrentHashMap插入元素大體來說和HashMap差不多,不同的是,ConcurrentHashMap添加了不少同步操作,如圖紅色標記,這樣就實作了同步安全,
不同于HashTable的是,ConcurrentHashMap主要采用的是CAS自旋鎖,提高了效率,
此外,ConcurrentHashMap鎖的物件是陣列中的每一個桶而不是整個陣列,這就意味著,在多執行緒操作的時候,同一個陣列不同的桶之間操作不影響,也就是說,同一個時間,可以有多個執行緒對陣列有插入元素的操作,提高了效率,
2.4 initTable原始碼分析
// 陣列初始化
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
// table 表示初始陣列
// 進行cas+自旋鎖,保證執行緒安全,對數進行初始化
while ((tab = table) == null || tab.length == 0) {
// 如果sizeCtl小于0,說明此時正在初始化,讓出cpu
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// cas修改sizeCtl的值為-1,如果修改成功,進行陣列初始化,如果修改失敗,繼續自選
// 就是sc和SIZECTL對比
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// 完成yield后,sc不是小于0
if ((tab = table) == null || tab.length == 0) {
// 如果sizeCtl值為0,取默認長度16;否則取sizeCtl中的值
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 基于初始長度,構造陣列物件
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// 計算擴容閾值,并賦值給sc,就是0.75*n
sc = n - (n >>> 2);
}
} finally {
// 最后將擴容閾值賦值給sizeCtl
sizeCtl = sc;
}
break;
}
}
return tab;
}
2.5 initTable原始碼程式流程圖
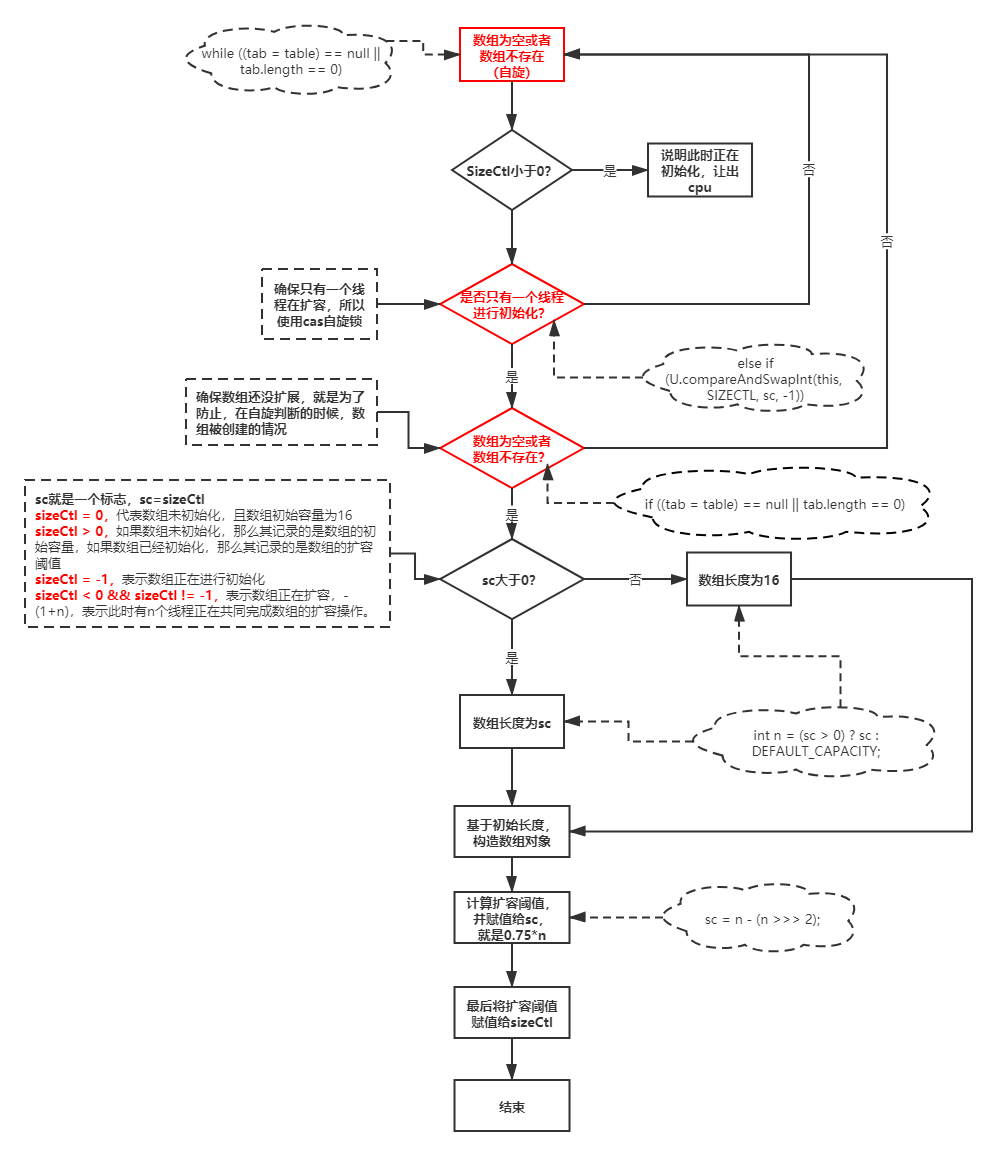
2.6 JDK8中ConcurrentHashMap添加安全總結
通過對initTable原始碼和putVal原始碼的閱讀比較,發現二者在實作同步的程序中都采用cas自旋鎖來實作同步的,極大提高了資源,
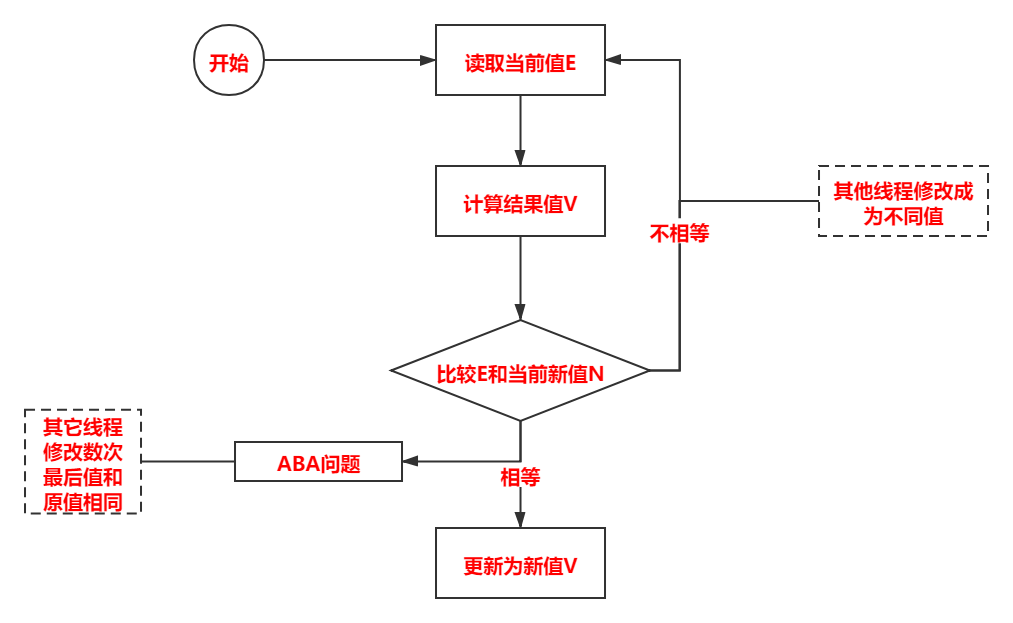
在原始碼中大量使用了 Unsafe.compareAndSwapInt(Object 0, long offset, int expected, int x),此方法是Java的native方法,并不由Java語言實作,
方法的作用是,讀取傳入物件o在記憶體中偏移量為offset位置的值與期望值expected作比較,相等就把x值賦值給offset位置的值,方法回傳true,不相等,就取消賦值,方法回傳false,這也是CAS的思想,及比較并交換,用于保證并發時的無鎖并發的安全性,
CAS程式流程圖
三、JDK8擴容安全
3.1 transfer原始碼分析
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// 如果是多cpu,那么每個執行緒劃分任務,最小任務量是16個桶位的遷移
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // MIN_TRANSFER_STRIDE = 16
// 如果是擴容執行緒,此時新陣列為null
// 計算最少任務量
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
// 創建新的陣列,陣列長度為原來陣列的兩倍
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; //左移0.5倍,右移2倍
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
// 記錄執行緒開始遷移的桶位,從后往前遷移
transferIndex = n;
}
// 記錄新陣列的末尾
int nextn = nextTab.length;
// 如果桶位已經被遷移,會用ForwardingNode占位(這個節點的hash值為-1--MOVED)
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
// 自旋,i記錄當前正在遷移桶位的索引值
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// 計算每一個執行緒到底負責多少元素的遷移
while (advance) {
int nextIndex, nextBound;
// bound記錄下一次任務遷移的開始桶位
// --i >= bound 成立表示當前執行緒分配的遷移任務還沒有完成
if (--i >= bound || finishing)
advance = false;
// 沒有元素需要遷移 -- 后續會去將擴容執行緒數減1,并判斷擴容是否完成
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// 主要計算是在這里,這里的遷移是從后往前遷移
// 計算下一次任務遷移的開始桶位,并將這個值賦值給transferIndex
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
// 分配任務,這一段標識任務是否做完
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
// 是否所有執行緒都做完了
// 擴容結束后,保存新陣列,并重新計算擴容閾值,賦值給sizeCtl
if (finishing) {
nextTable = null;
table = nextTab;
// 這一行代碼是說2 * n - 0.5 * n = 1.5 * n = 0.75 * 2n,位運算效率高
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 判斷擴容操作是否完成
// 擴容任務執行緒數減1
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// 判斷擴容動作還沒有完成,即還有其他執行緒在操作
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
//所有擴容執行緒都執行完,標識結束
finishing = advance = true;
i = n; // recheck before commit
}
}
//當前遷移的桶位沒有元素,直接在該位置添加一個fwd節點
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
//當前節點已經被遷移
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
// 非空且為被遷移
else {
// 如果正在做遷移,其他執行緒不能在當前位置上添加元素
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
3.2 擴容安全圖解
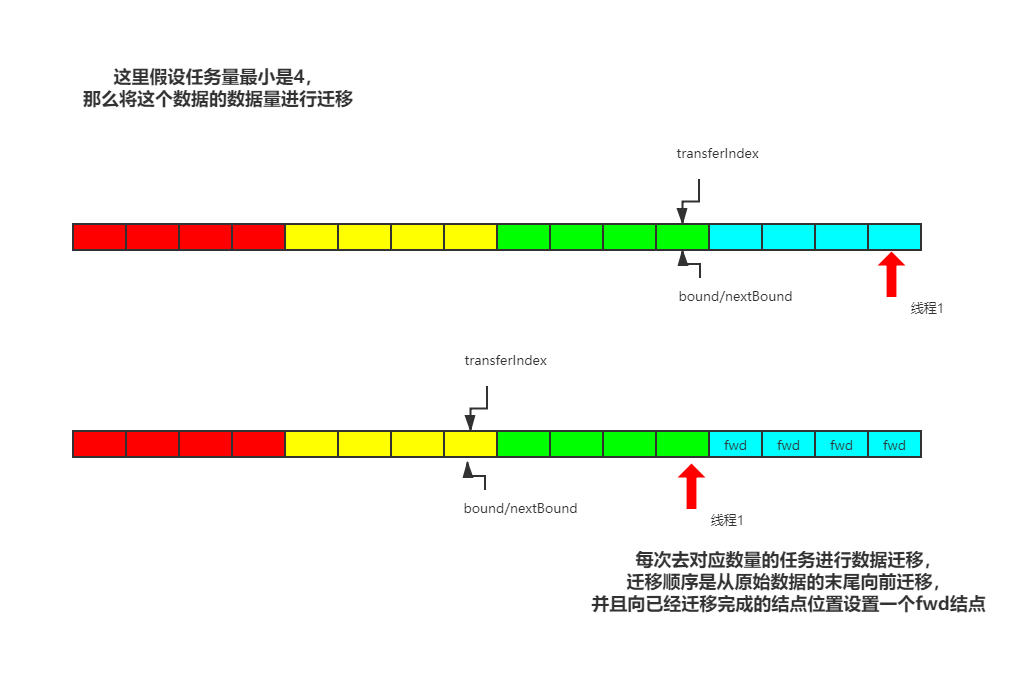
3.3 JDK8中ConcurrentHashMap擴容安全總結
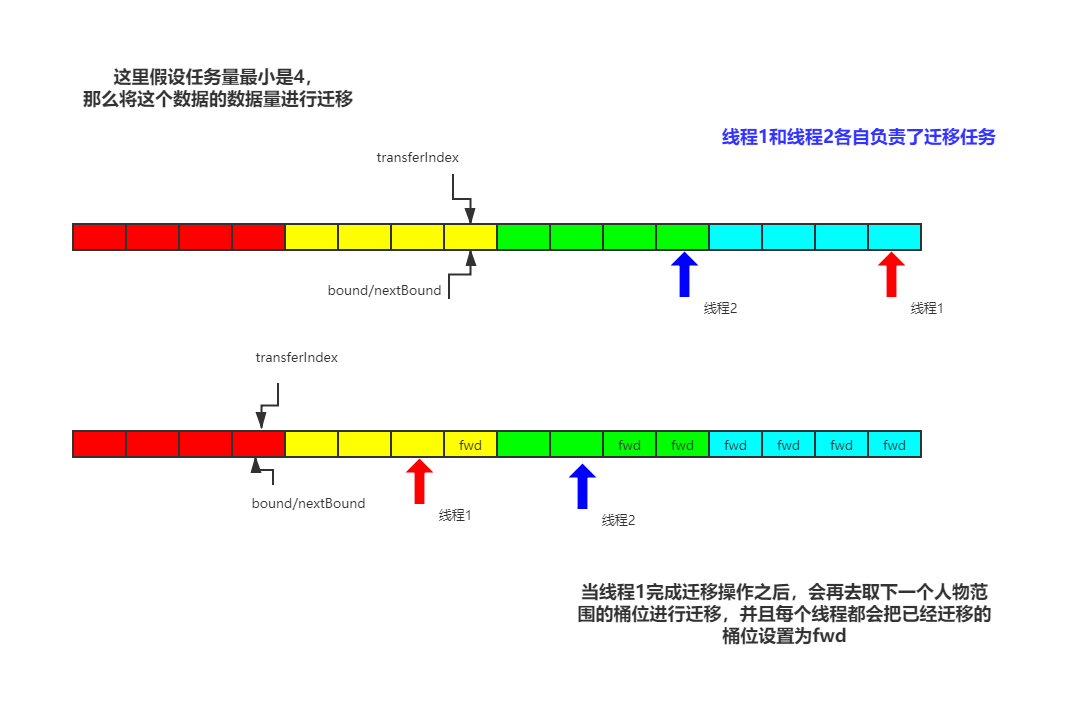
如果是多核CPU的前提下,那么每個執行緒劃分任務,最小任務量是16個桶位的遷移,
在遷移程序中,通過自旋來控制整個程序的持續性,直到所有執行緒完成擴容任務,
對于桶位來說,如果桶位已經被遷移,會用ForwardingNode占位(這個節點的hash值為-1–MOVED),使用advance標記執行緒是否完成擴容,那么,如果說當前遷移的桶位沒有元素,那該怎么辦呢?在原始碼中是直接在該位置添加一個fwd節點
在擴容的時候,需要計算下一次任務遷移的開始桶位,并將這個值賦值給transferIndex,這個程序是用cas完成的,
如果當前桶位需要被遷移,就好比在當前桶位插入資料一樣,需要使用synchronized關鍵字來為該桶位加鎖,保證多執行緒安全,
四、JDK8多執行緒擴容效率改進
多執行緒協助擴容的操作會在兩個地方被觸發:
① 當添加元素時,發現添加的元素對應的桶位為fwd節點,就會先去協助擴容,然后再添加元素
② 當添加完元素后,判斷當前元素個數達到了擴容閾值,此時發現sizeCtl的值小于0,并且新陣列不為空,這個時候,會去協助擴容
4.1 方案1:putVal原始碼分析
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//發現此處為fwd節點,協助擴容,擴容結束后,再回圈回來添加元素
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
//省略代碼
4.2 方案2:helpTransfer原始碼分析
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
//擴容,傳遞一個不是null的nextTab
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
4.3 JDK中ConcurrentHashMap擴容效率提高圖解
五、集合長度的累計方式
5.1 addCount原始碼分析
① CounterCell陣列不為空,優先利用陣列中的CounterCell記錄數量
② 如果陣列為空,嘗試對baseCount進行累加,失敗后,會執行fullAddCount邏輯
③ 如果是添加元素操作,會繼續判斷是否需要擴容
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
// 一開始counterCells不為空,所以前面一個判斷不成立
if ((as = counterCells) != null ||
// 在單執行緒的條件下,將s=b+1,加成功之后compareAndSwapLong回傳true,取反為false,所以不進入代碼,直接加入成功
// 當有兩個以上的執行緒進入這個位置,那么必然有一個執行緒加成功,其他執行緒加失敗,所以回傳false,取反回傳true,進入代碼塊
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
// 陣列為空,或陣列不存在(長度小于0)
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
// sumCount是獲取當前陣列長度
s = sumCount();
}
// 移除或替換元素
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
// 第一次sc不會小于0
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 協助擴容,nt指的是新的陣列
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 移完之后,最高位是1,所以變為sc為負數,所以sizeCtl也小于0
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
// 擴容
transfer(tab, null);
s = sumCount();
}
}
}
5.2 fullAddCount原始碼分析
① 當CounterCell陣列不為空,優先對CounterCell陣列中的CounterCell的value累加
② 當CounterCell陣列為空,會去創建CounterCell陣列,默認長度為2,并對陣列中的CounterCell的value累加
③ 當陣列為空,并且此時有別的執行緒正在創建陣列,那么嘗試對baseCount做累加,成功即回傳,否則自旋
// See LongAdder version for explanation
private final void fullAddCount(long x, boolean wasUncontended) {
int h;
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit(); // force initialization
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
// 整個程序沒有加鎖動作,只是使用cas+自旋的動作
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
// 陣列不為空
if ((as = counterCells) != null && (n = as.length) > 0) {
// 創建CounterCell物件,并對CounterCell中的value累加值,若成功,則結束回圈
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // Try to attach new Cell
CounterCell r = new CounterCell(x); // Optimistic create
if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean created = false;
try { // Recheck under lock
CounterCell[] rs; int m, j;
if ((rs = counterCells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
// 如果wasUncontended==false,那么rehash,然后asUncontended設定為true
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
// 桶位value累加成功結束回圈
else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
break;
// 有別的執行緒對陣列擴容/陣列容量達到最大值就是cpu的核數,并rehash
else if (counterCells != as || n >= NCPU)
collide = false; // At max size or stale
// collide=true,并rehash
else if (!collide)
collide = true;
// 陣列進行擴容,成功后繼續回圈
else if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
try {
if (counterCells == as) {// Expand table unless stale
CounterCell[] rs = new CounterCell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
counterCells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = ThreadLocalRandom.advanceProbe(h);
}
// 陣列為空,先創建陣列
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean init = false;
try { // Initialize table
if (counterCells == as) {
CounterCell[] rs = new CounterCell[2];
rs[h & 1] = new CounterCell(x);
counterCells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
// 陣列正在被創建,且陣列為空,baseCount++
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break; // Fall back on using base
}
}
六、jdk1.8集合長度獲取
6.1 size原始碼
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
6.2 sumCount原始碼
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
//獲取baseCount的值
long sum = baseCount;
if (as != null) {
//遍歷CounterCell陣列,累加每一個CounterCell的value值
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
注意:這個方法并不是執行緒安全的
七、JDK7中ConcurrentHashMap
ConcurrentHashMap與HashMap思路差不多,但是ConcurrentHashMap支持并發操作,
整個ConcurrentHashMap由一個個Segment組成,其作用就是用于分段鎖,
Segment繼承自ReentrantLock加鎖,
所以每一個加鎖鎖住的是一個個segment,確保每個segment是安全的,那么全域也是安全的,
與HashMap類似的,Java 7 中的ConcurrentHashMap的底層也是陣列+鏈表,
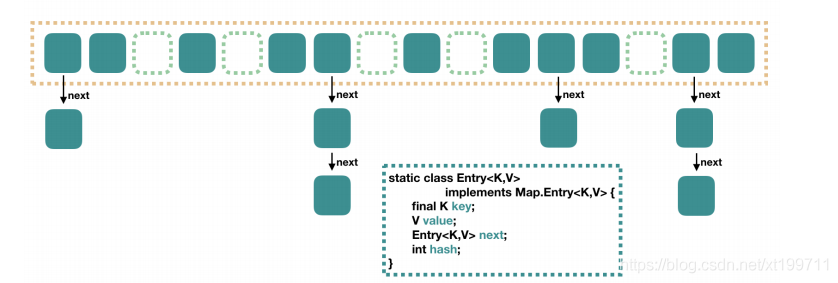
Java 8 中的ConcurrentHashMap則是陣列+鏈表+紅黑樹的結構實作
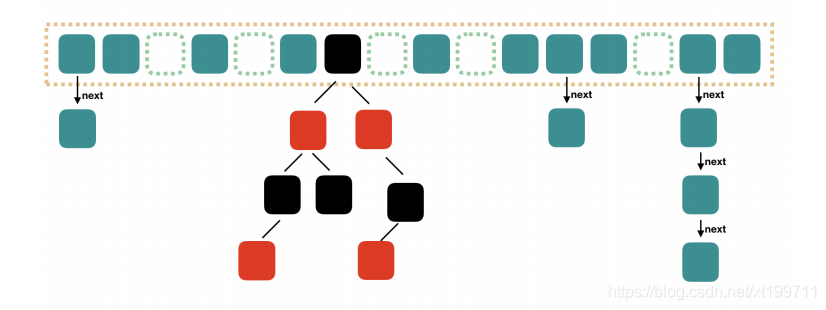
ConcurrentHashMap的ConcurrentLevel(并發級別)默認有16個Segments,理論上最多可以同時支持16個執行緒并發,只要它們的操作分布在不同的Segment上,
這個值(ConcurrentLevel)最初可以設定為其他值,但一旦初始化后,就不可以再擴容,
細化到Segment內部,其實每一個Segment相當于一個HashMap,不過要保證執行緒安全,所以要更麻煩些,
八、相關面試題
【Java自頂向下】ConcurrentHashMap面試題(2021最新版)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/266336.html
標籤:其他
上一篇:阿里云短信使用簡介demo
下一篇:HashMap面試靈魂幾問