hashMap 面試常問
1、HashMap的默認容量?

2、hash如何put,如何解決hash沖突
2.1、如何計算hash值
hashmap 如何put,可以回答先計算得到hash值,然后確定hash桶的坐標
1、通過hashcode()方法,使其無符號右移 16 位,并且與自身 位異域運算

2、再用該hash與map(總容量-1)做 位與運算, 得到一個 小于haspMap總容量的一個整數,

文字敘述:
如果 put一個 (“xxx”,123),首先根據 key 呼叫 hashcode()方法生成 hash值,然后無符號右移 16 位(jdk7 沒有這一部,jdk8為了是hash 低16位分布更加均勻,因為一般的長度不會超過 2的16次方),
然后進行 位異域運算 ,之后再與 容器長度(length -1)進行 位與運算
2.2、如何解決hash沖突
hash沖突定義:
基于上面,基于一系列二進制運算最后會得到一個 int型別 hash值,
不同的key,通過一系列計算會得到,相同的 hash值,
這里有一個概念,就是,hashcode 相同,equal 可能不相同,equal相同 hashcode 一定相同,
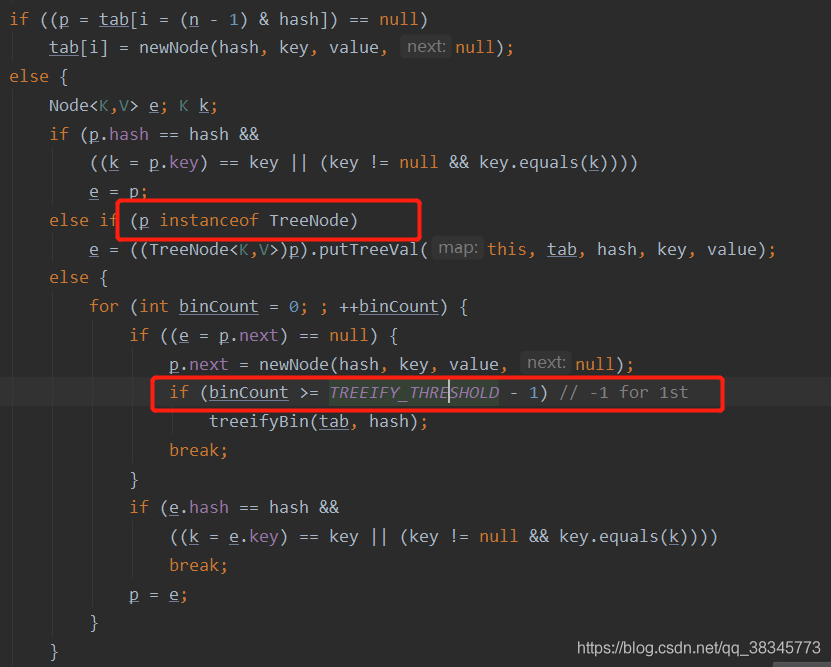
1、如果初次插入,判斷 tab陣列節點 是否為空,如果為空 會 new一個node節點

2、如果通過一系列二進制運算得到 的hash值,在原本的陣列節點已經存在,
這里分為倆種情況,
一種是 map.put(“a”,“舊值”) ,再次 map.put(“a”,"新值 ") ,相同key 覆寫的情況,
會比較倆者hash 值,并且比較二者的key 是不是相同,
如果二者經過一系列二進制運算得到的hash值相同,并且key(這里的key指的是這里的 “a”)也相同,
就會重寫寫入該值,

3、發生hash沖突,寫入鏈表,
基于步驟2,滿足hash值相同,并且 key值不相同,
會使用指標 p.next 存放當前發生沖突的key值,
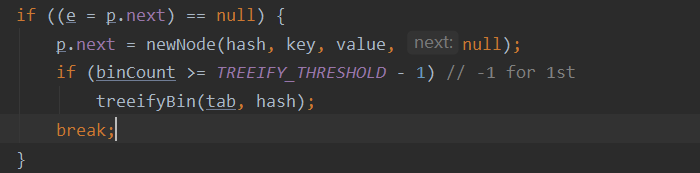
4、如果發生沖突的時候,會檢測我們桶節點,鏈表的長度,如果鏈表的長度大于8,會轉成紅黑樹,
3、為什么hashMap 的陣列大小為什么一定是 2 的冪?
1、HashMap為了存取高效,要盡量較少碰撞,就是要盡量把資料分配均勻,每個鏈表長度大致相同,這個實作就在把資料存到哪個鏈表中的演算法;
2、只有它的長度是2的N次方,對它進行減一操作,才能拿到所有是 1 的值
,這樣對它進行 按位與運算時,才能快速的用位運算的方式,拿到陣列的下標,并且 保證下標在容量之下,并且分配均勻
例如 2的5次方 = 32
32 = 100000
31 = 11111
#這樣的話,如果經過 map.put("key","value") 的操作,
#會首先得到一個hash值,跟 (32-1 ) 進行位異或運算
11100001 .... 11011
& 11111
= 11011 (二進制)
= 27 (十進制)
4、為什么hashmap負載因子是0.75
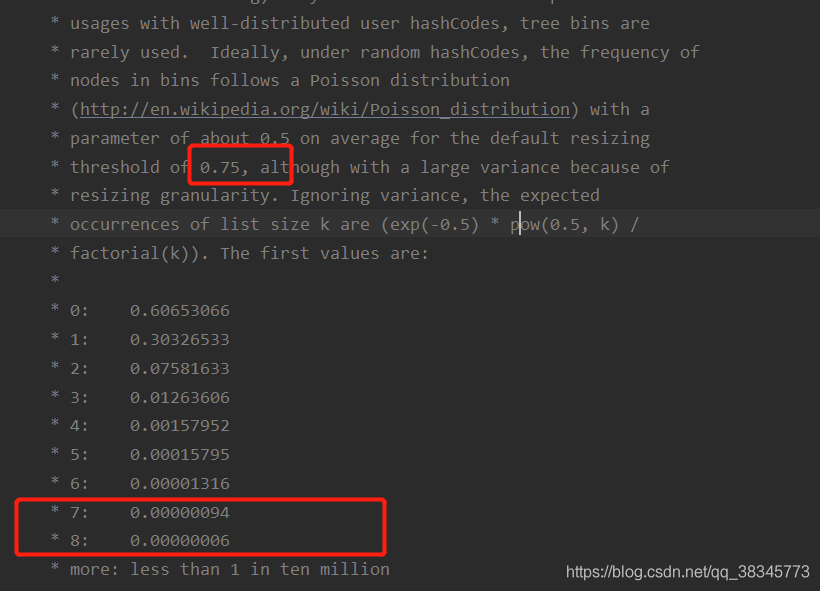
原始碼上面注釋大致意思就是說負載因子是0.75的時候,空間利用率比較高,
而且避免了相當多的Hash沖突,使得底層的鏈表或者是紅黑樹的高度比較低,提升了空間效率,
如果太高會導致查詢復雜度增加,如果太低會增加存盤空間
根據統計學來說,使用隨機哈希碼,節點出現的頻率在hash桶遵循泊松分布,
在負載因子0.75下,每個碰撞位置的鏈表長度超過8個概率很低,而出現 6或者 7個還挺大的,這里直接降低了,每個hash桶底層的查詢復雜度
5、JAVA7 HashMap的問題
1、并發環境容易死鎖
2、可以通過精心構造的惡意請求引發Dos
6、java7到java8 做了哪些改進?為什么?
1.7和1.8主要在處理哈希沖突和擴容問題上區別比較大,
1、底層設計改變
JDK1.8 (陣列+ 單鏈表 + 紅黑樹 )解決了1.7的大資料 查詢效率問題
JDK1.7的時候使用的是(陣列+ 單鏈表的資料結構),但是在JDK1.8及之后時,使用的是陣列+鏈表+紅黑樹的資料結構(當鏈表的深度達到8的時候,也就是默認閾值,就會自動擴容把鏈表轉成紅黑樹的資料結構來把時間復雜度從O(n)變成O(logN)提高了效率)出現哈希沖突時,1.7把資料存放在鏈表,1.8是先放在鏈表,鏈表長度超過8就轉成紅黑樹
2、擴容設計改變
擴容時插入順序的改變,解決了1.7的擴容時發生死鎖的問題
區別:
JDK1.7用的是頭插法,有可能在擴容時,出現回環,造成死鎖
而JDK1.8及之后使用的都是尾插法,但是仍有執行緒安全問題
總結:
HashMap之所以在并發下的擴容造成死回圈,是因為,多個執行緒并發進行時,因為一個執行緒先期完成了擴容,將原的鏈表重新散列到自己的表中,并且鏈表變成了倒序,后一個執行緒再擴容時,又進行自己的散列,再次將倒序鏈表變為正序鏈表,于是形成了一個環形鏈表,當表中不存在的元素時,造成死回圈,
雖然在JDK1.8中,Java的開發小組修正了這個問題,但是HashMap始終存在著其他的執行緒安全問題,所以在并發情況下,我們應該使用HastTable或者ConcurrentHashMap來代替HashMap,
7、為什么說,hashmap 不是執行緒安全的
1、HashMap 在插入的時候
現在假如 A 執行緒和 B 執行緒同時進行插入操作,然后計算出了相同的哈希值對應了相同的陣列位置,因為此時該位置還沒資料,然后對同一個陣列位置,兩個執行緒會同時得到現在的頭結點,然后 A 寫入新的頭結點之后,B 也寫入新的頭結點,那B的寫入操作就會覆寫 A 的寫入操作造成 A 的寫入操作丟失,
2、HashMap 在擴容的時候
HashMap 有個擴容的操作,這個操作會新生成一個新的容量的陣列,然后對原陣列的所有鍵值對重新進行計算和寫入新的陣列,之后指向新生成的陣列,
那么問題來了,當多個執行緒同時進來,檢測到總數量超過門限值的時候就會同時呼叫 resize 操作,各自生成新的陣列并 rehash 后賦給該 map 底層的陣列,結果最終只有最后一個執行緒生成的新陣列被賦給該 map 底層,其他執行緒的均會丟失,
3、HashMap 在洗掉資料的時候
洗掉這一塊可能會出現兩種執行緒安全問題,第一種是一個執行緒判斷得到了指定的陣列位置i并進入了回圈,此時,另一個執行緒也在同樣的位置已經刪掉了i位置的那個資料了,然后第一個執行緒那邊就沒了,但是洗掉的話,沒了倒問題不大,
再看另一種情況,當多個執行緒同時操作同一個陣列位置的時候,也都會先取得現在狀態下該位置存盤的頭結點,然后各自去進行計算操作,之后再把結果寫會到該陣列位置去,其實寫回的時候可能其他的執行緒已經就把這個位置給修改過了,就會覆寫其他執行緒的修改,
其他地方還有很多可能會出現執行緒安全問題,我就不一一列舉了,總之 HashMap 是非執行緒安全的,有并發問題時,建議使用 ConcrrentHashMap,
8、haspMap 為什么使用紅黑樹
hashMap 的場景要求,查詢快,插入快
1、紅黑樹(不完美平衡紅黑樹)
特點: 不追求完全平衡
插入比較快,因為不需要過多的自旋操作來維持,節點的絕對平衡,
查詢比較慢相對于完全平衡樹,
2、avl樹 (完美平衡樹)
特點:
查詢比較快,底層資料
插入比較慢,為了維持高度的平衡,就要付出更多代價,
區別
查詢復雜度:
紅黑樹和avl樹 查找的話都是logn,
插入、洗掉,復雜度:
平衡樹一般是 logn,可能需要通過一次或多次樹旋轉來重新平衡這個樹紅黑樹一般是 也是logn,但不需要額外的自旋,
此外由于它的設計,任何不平衡都會在三次旋轉之內解決,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/266337.html
標籤:其他