全文目錄
原文
用戶畫像的概念和作用
- 字面上, 用戶畫像核心作用是對系統的用戶進行多維度的資訊刻畫;
- 深層次, 通過對用戶多維度的刻畫, 將不同的用戶映射到產品所提供的不同服務上, 或映射到同一服務的不同具體形態上;
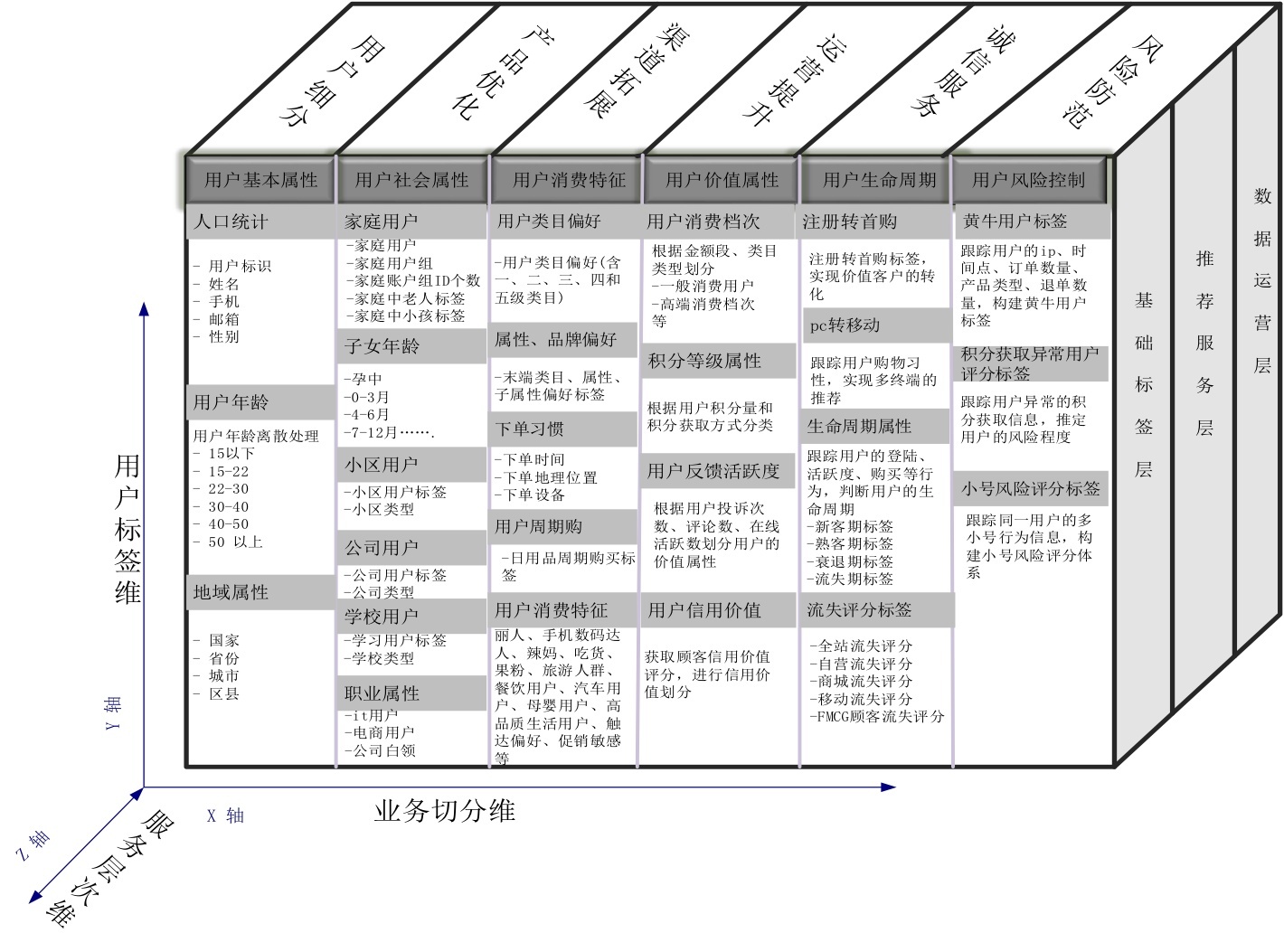
推薦系統的用戶畫像取上圖中可以將用戶和系統中物品連接起來的格子;
基于演算法二次加工后的畫像資料:
- 可讀性較差;
- 更強, 更綜合的表達能力和連接能力;
- 自主發現, 自主更新以及可用演算法持續優化;
- 可捕捉抽象層次更高, 維度更綜合的資訊;
推薦系統中的用戶畫像分:
- 顯式畫像資料, 基于規則生成的, 可讀性好的畫像;
- 隱式畫像資料, 基于演算法生成的, 可讀性較差的畫像;
常用方法: 召回(粗排), 排序;
用戶畫像的價值準則
- 準則一, 能夠建立起用戶和物品之間的
有效連接; - 準則二,
細致刻畫; 根據畫像資料中每個取值平均能夠覆寫的用戶或物品的多少來判斷; - 準則三,
覆寫率; 指一份畫像資料能夠覆寫到多大比例的用戶或物品; - 準則四,
差異化能力; 能否標識出不同用戶, 能夠映射到不同的物品上;
用戶畫像的構成要素
物品側畫像
計算用戶側畫像的基礎
- 對物品基礎屬性的客觀描述
- 基于基礎屬性進一步計算得到的深層次特征
-
文本資料的結構化資訊抽取
在分詞和詞性標注后, 構造一套針對自己領域和業務的知識圖譜以及配套的抽取決議演算法, 再根據效果反饋不斷調優;
結構化資訊抽取流程:
- 知識圖譜構建, 要抽取的結構化資訊對應的元資訊及其結構關系;
- 文本預處理, 分詞, 去噪, 歸一化等處理;
- 結構資料決議, 映射+合并;
-
非結構化物品標簽, 文本類標簽資料+行為類標簽資料
-
復合型別的物品畫像, 對物品的深層次描述, 是基于客觀屬性以及行為資料, 通過演算法深層次加工計算得到的;
- 物品聚類, LDA, 文本主題聚類;
- 向量化表示, word2vec
用戶側畫像
大部分是通過用戶與物品之間的行為計算得到; (局限性: 局限于歷史興趣范圍內, 不能給出用戶未曾有過行為的興趣維度)
輸入 = 用戶行為序列 + 物品的多維度畫像;
輸出 = 建立在物品畫像基礎上, 用戶對每個維度畫像的興趣 map;
見文末的用戶畫像系統架構圖
常用用戶畫像的計算方式:
-
時間衰減法
用戶對某個維度的興趣在行為剛產生時最大, 隨著時間不斷衰減, 直到可忽略不計;
興趣的初始最大值, 衰減方式;
\[w_t = w_0 \times e^{-\alpha \times \delta_t} \]\(w_t\) 時間 t 對應的興趣權重; \(w_0\) 初始興趣權重, \(\delta_t\) 時刻 t 相比初始時刻過去的時間;
選擇指數函式原因:
- 初始衰減快, 后期衰減慢;
- 兩個時間點 \(t_1\) 和 \(t_2\) 下興趣值的關系: \(w_{t_2} = w_{t_1} \times e^{-\alpha \times \delta_{t_2-t_1}}\) , 即只需要存盤用戶對一個興趣維度在任意時刻的興趣值和時間戳, 就可以完成后面任意時刻興趣值的計算;
\(w_0\) 初期根據業務經驗調整;
\(\alpha\), 興趣的衰減速度, 以"半衰期"計算值, \(0.5x=x \times e^{-\alpha \times \delta_0}\)
時間衰減法的流程:
-
為不同型別的畫像和行為設定不同的初值 \(w_0\);
-
當用戶對物品產生行為時:
- 取出該物品所有可用維度的畫像;
- 根據畫像型別和行為型別設定興趣度初值 \(w_0\), 即重置為最大值;
- 將各維度畫像按照興趣度排序存盤在興趣串列中;
-
每次更新用戶的畫像興趣度時, 對所有畫像維度的興趣度進行衰減更新, 更新后低于所設定的閾值就從串列中洗掉, 并將剩余結果進行排序, 以減少后期讀寫壓力;
-
在使用用戶畫像時, 首先從存盤串列中讀取對應維度的畫像, 并使用時間差進行時間衰減更新, 然后在下游流程中使用;
缺點:
- 個性化程度不足, 初值 \(w_0\) 和衰減速度 \(\alpha\) 對所有用戶都一樣;
- 難易實作興趣度加強, 每次的重置最大值, 導致無法根據前置行為而加強興趣度;
- 無法體現不同畫像維度之間的相互影響;
-
分析模型預測法
將用戶對某個維度畫像的興趣投射到具體行為上, 把這個行為產生與否建模成二分類問題;
-
向量(嵌入)表示類畫像方法
資料特點: N 維的稠密連續向量, 作為一個整體對待;
函式: 輸入是代表用戶物件畫像歷史行為的若干向量表示的畫像資料; 輸出是一個或多個代表用戶當前興趣的向量;
- 對歷史行為對應的向量取一個平均向量作為當前的興趣向量;
- 對近期不同的行為給與不同的權重, 帶權平均; 注意力機制;
用戶畫像擴展
除了基于歷史興趣給出當前興趣, 需要一些其他方法對用戶興趣進行發散擴展, 保證推薦具有一定的新鮮度和驚喜度;
- 基于行為的畫像關聯挖掘
一跳相似度, 如果有大量用戶同時訪問了兩個物品, 基于此計算出兩者之間的相似度;
基于行為的相關性演算法缺陷:
- 稀疏型嚴重
- 覆寫率低
- 對冷啟動不友好
- 只是記憶發生過的事實, 沒有學習到事實背后的根本原因
-
基于知識圖譜的相關性計算推理
基于路徑的方法
- 精準性
- 多樣性
- 可解釋性
-
用戶畫像和排序特征的關系
用戶畫像的維度都可作為排序特征;
所有的排序特征也可以用作用戶畫像;
本質都是區別用戶和物品的關系;
區別: 用戶畫像看重可解釋性, 排序特征對可解釋性要求不高(例如為了降低特征維度, 會對原始特征用 PCA 等方法降維, 降維后可解釋性就大打折扣);
用戶畫像系統的架構演進
組成部分
用戶畫像系統 = 物品畫像 + 基于物品畫像使用各種演算法生成的用戶畫像
三個子模塊:
- 生產模塊, 使用具體演算法生產出具體的畫像資料, 關注用戶畫像資料生產的效率, 覆寫率和可擴展性等;
- 傳輸模塊, 對接上下兩個模塊的資料和流程, 關注銜接是否自然流暢, 能夠更好的封裝屏蔽兩個系統中與業務無關的部分;
- 輸出模塊, 負責資料對外呼叫或提供服務的模塊, 關注系統的可用性, 資料的新鮮度, 呼叫的靈活性等;
野蠻生長期
通常每人都會負責生成, 存盤, 提供呼叫以及維護等資料的全生命周期;(起步階段必要經歷, 但是不宜時間過長, 會留下技術債)
存在問題:
- 生效時間不統一
- 使用方式不統一
- 管理升級不統一
統一用戶畫像系統架構
物品畫像系統的架構:
- 資料生產和資料服務功能分離;
- 抽象通用邏輯, 減少冗余, 提高復用性;
- 對新的畫像標簽資料做到兼容性強和可擴展;
- 提高資料時效性, 盡量實時生成并提供資料;
- 提供不同種類的資料服務;
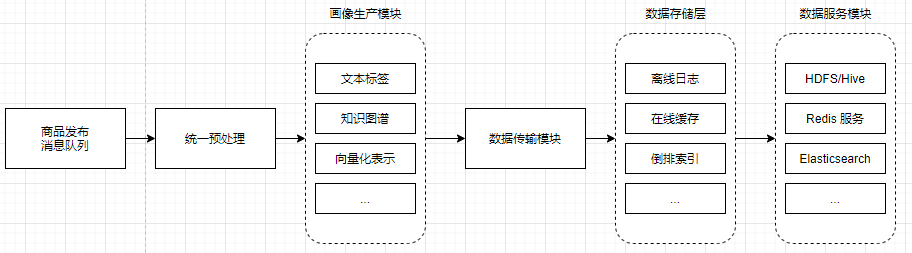
畫像生產模塊, 統一接收同樣格式的輸入, 給出同樣格式的輸出, 即統一的介面實作;
用戶畫像系統的結構:
- 基于上面物品畫像資料和不同的連接演算法生成用戶畫像資料
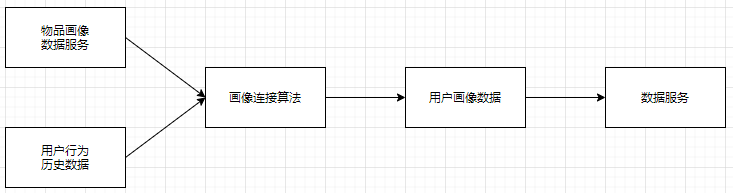
畫像演算法對于處理的是何種畫像資料應該是無感知的;
最后的資料服務模塊是必要的, 由于寫入的資料并不是可直接使用的資料;
本文僅作為讀書筆記使用!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/267329.html
標籤:其他
上一篇:Picgo + Gitee +Typora(自動上傳)搭建markdown免費圖庫
下一篇:與情預測股票