詞向量模型簡介
- 概述
- 詞向量維度
- Word2Vec
- CBOW 模型
- Skip-Gram 模型
- 負采樣模型
- 詞向量的訓練程序
- 1. 初始化詞向量矩陣
- 2. 神經網路反向傳播
概述
我們先來說說詞向量究竟是什么. 當我們把文本交給演算法來處理的時候, 計算機并不能理解我們輸入的文本, 詞向量就由此而生了. 簡單的來說, 詞向量就是將詞語轉換成數字組成的向量.
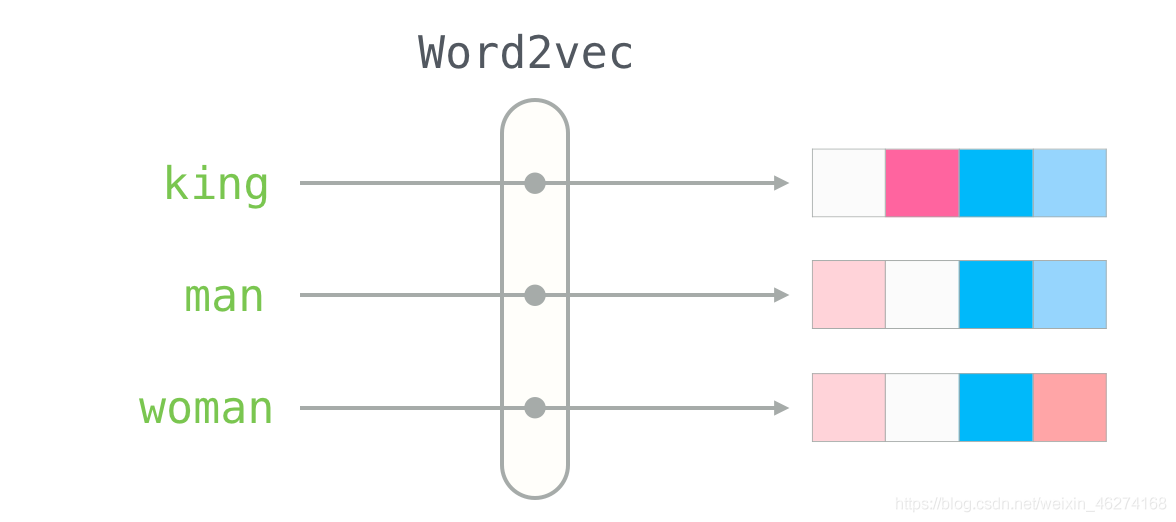
當我們描述一個人的時候, 我們會使用身高體重等種種指標, 這些指標就可以當做向量. 有了向量我們就可以使用不同方法來計算相似度.

那我們如何來描述語言的特征呢? 我們把語言分割成一個個詞, 然后在詞的層面上構建特征.
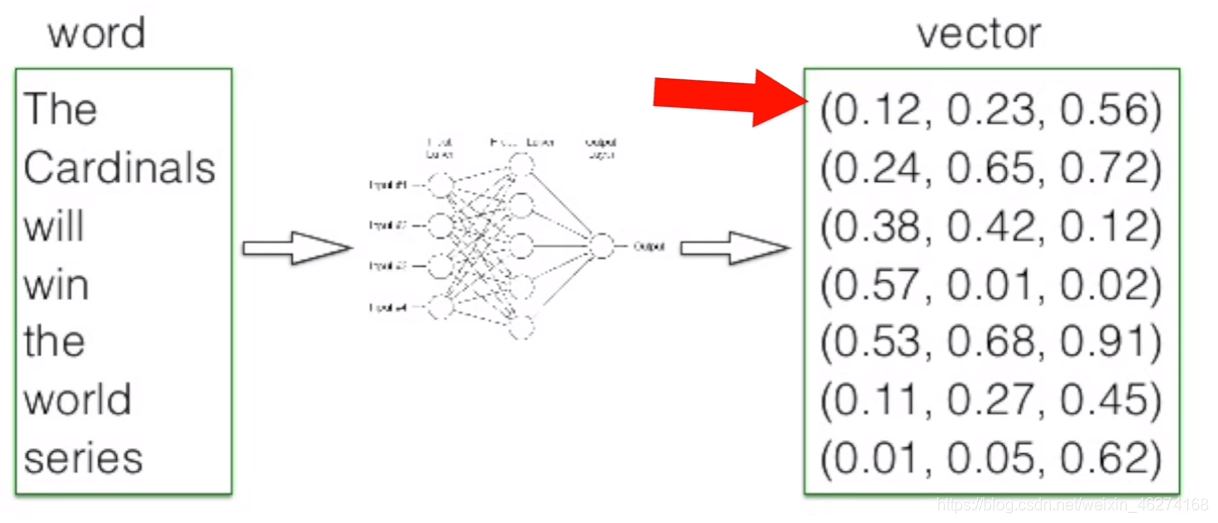
詞向量維度
詞向量的維度越高, 其所能提供的資訊也就越多, 計算結果的可靠性就更值得信賴.
50 維的詞向量:

用熱度圖表示一下:

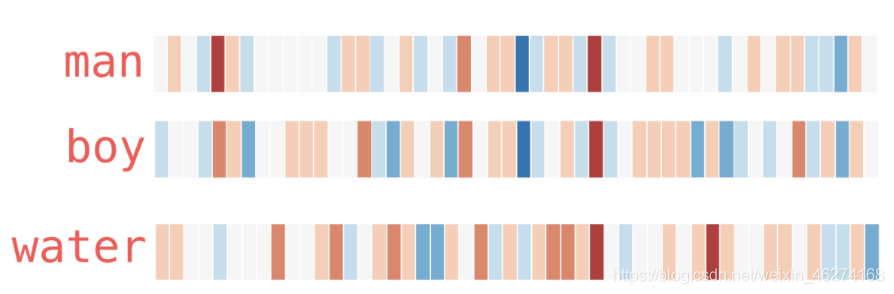
從上圖我們可以看出, 相似的詞在特征表達中比較相似. 由此也可以證明詞的特征是有意義的.
Word2Vec
Word2Vec 是一個經過預訓練的 2 層神經網路, 可以幫助我們將單詞轉換為向量. Word2Vec 分為兩種學習的方法: CBOW 和 Skip-Gram.
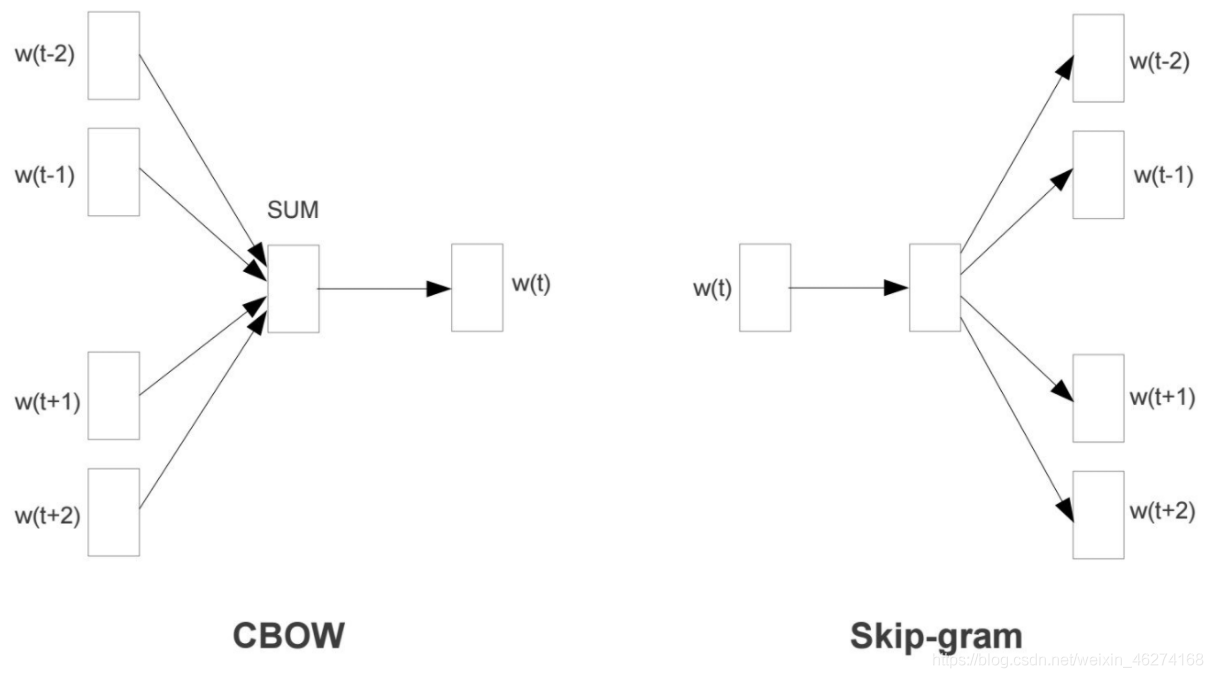
CBOW 模型
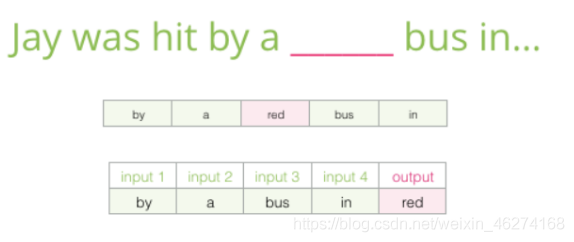
CBOW (Continuous Bag-of-Words) 是根據單詞周圍的背景關系來預測中間的詞. 如圖:
Skip-Gram 模型
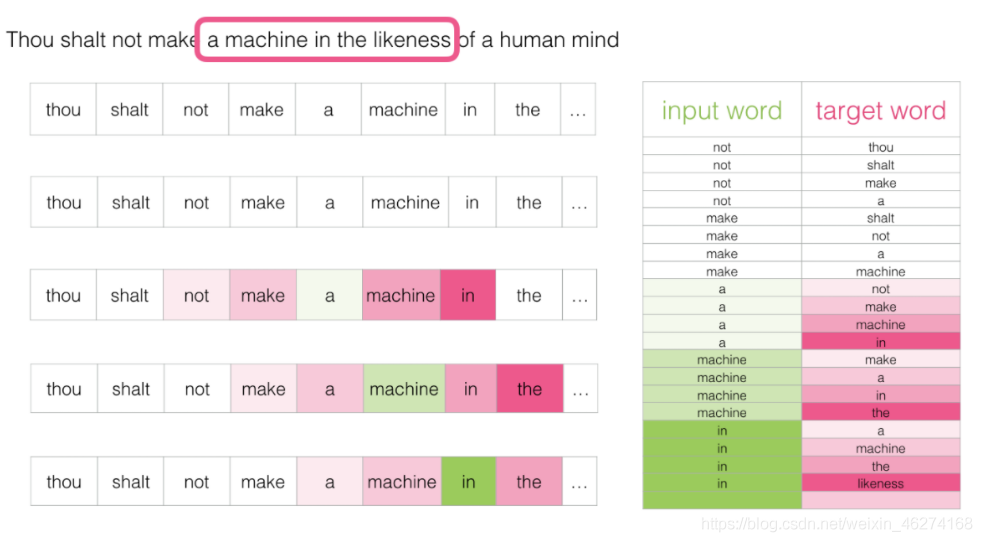
Skip-Gram 用于預測同一句子中當前單詞前后的特定范圍內的單詞.

Skip-Gram 所需的訓練資料集:
負采樣模型
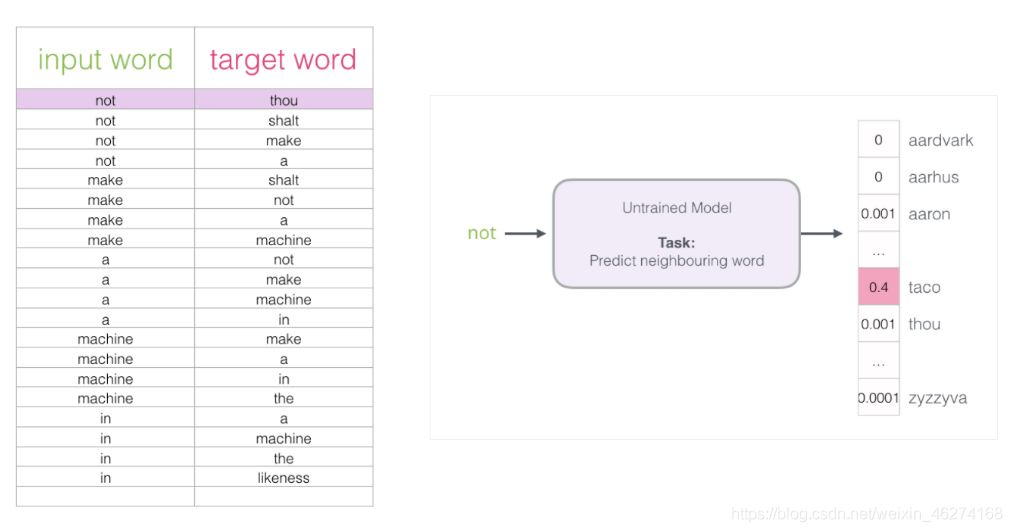
如果一個語料庫稍微大一些, 可能的結果簡直太多了. 詞向量模型的最后一層相當于 softmax (轉換為概率), 計算起來會非常耗時.
我們可以將輸入改成兩個單詞, 判斷這兩個詞是否為前后對應的輸入和輸出, 即一個二分類任務.
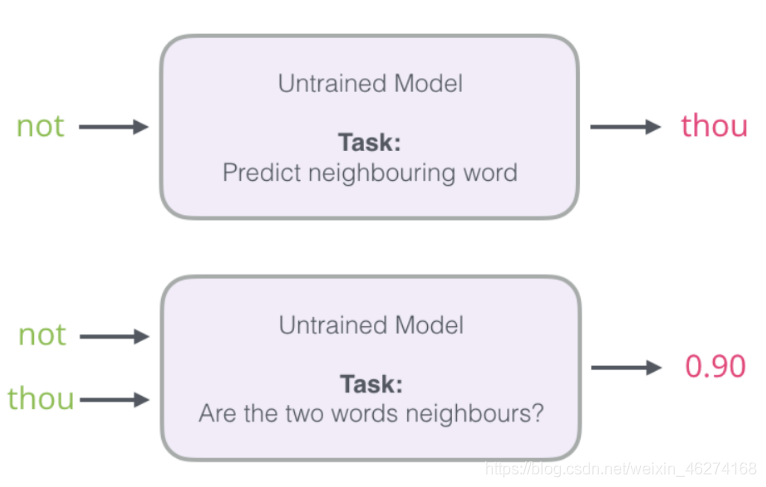
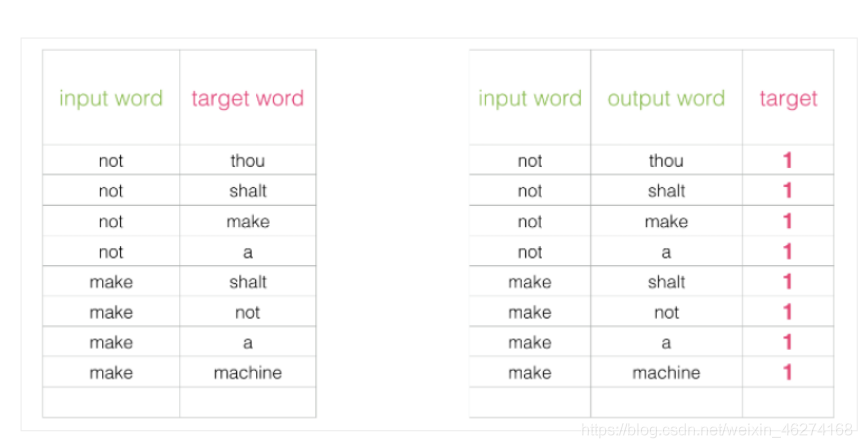
但是我們會發現一個問題, 此時的訓練集構建出來的標簽全為 1, 無法進行較好的訓練. 這時候負采樣模型就派上用場了. (默認為 5 個)

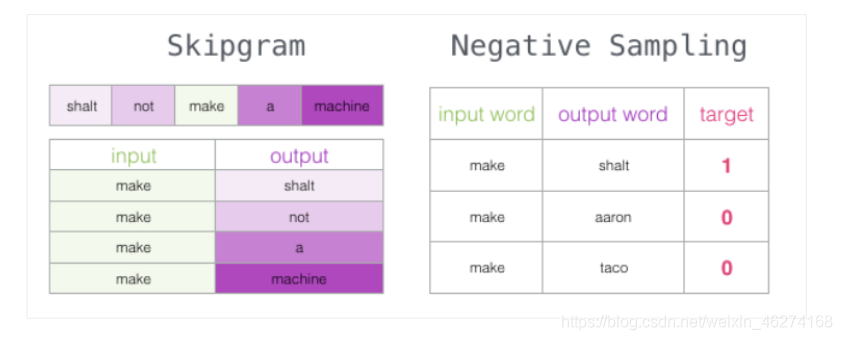
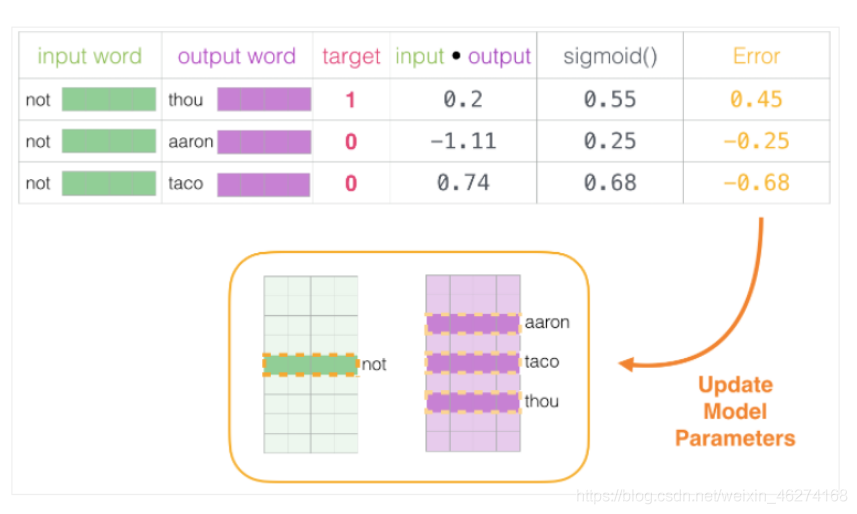
詞向量的訓練程序
1. 初始化詞向量矩陣
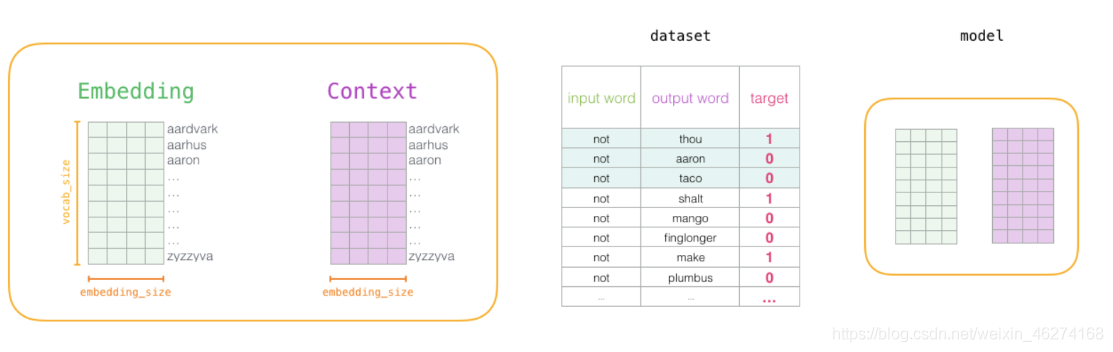
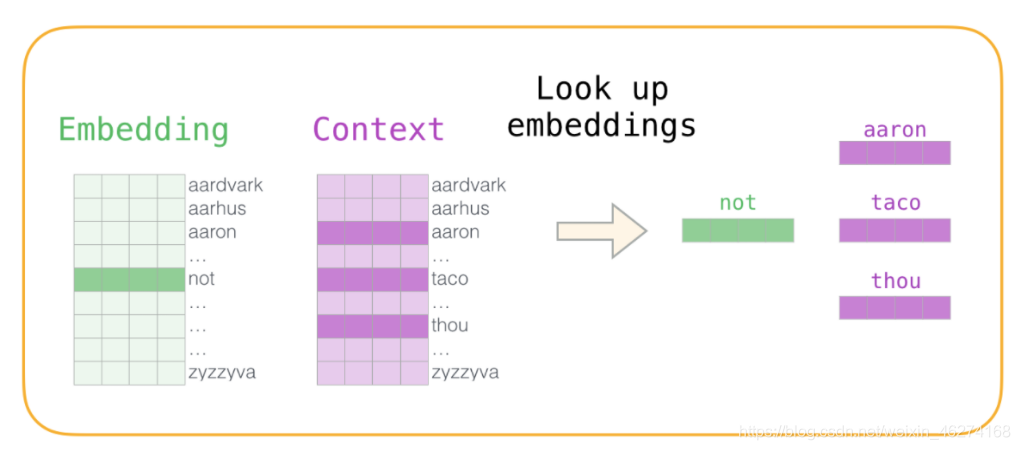
2. 神經網路反向傳播
通過神經網路反向傳播來計算更新. 此時不光更新權重引數矩陣 W, 也會更新輸入資料.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/267474.html
標籤:AI