百度PaddleOCR字符識別推理部署(C++)
因作業專案需要用到PaddleOCR字符識別,踩過的一些坑,在此記錄,便于后面的人少踩些坑
一、前期準備作業:
(1)OpenCV4.2.0(可以使用其他版本,一定要先把CV庫配置好,不然會出錯)
(2)下載Cmake 3.17.5(可以使用其他Cmake版本)
(3)Visual Studio 2017(可以使用其他vs版本,根據自己的情況來定)
(4)分別下載PaddleOCR專案、PaddleOCR模型、PaddleOCR預測庫
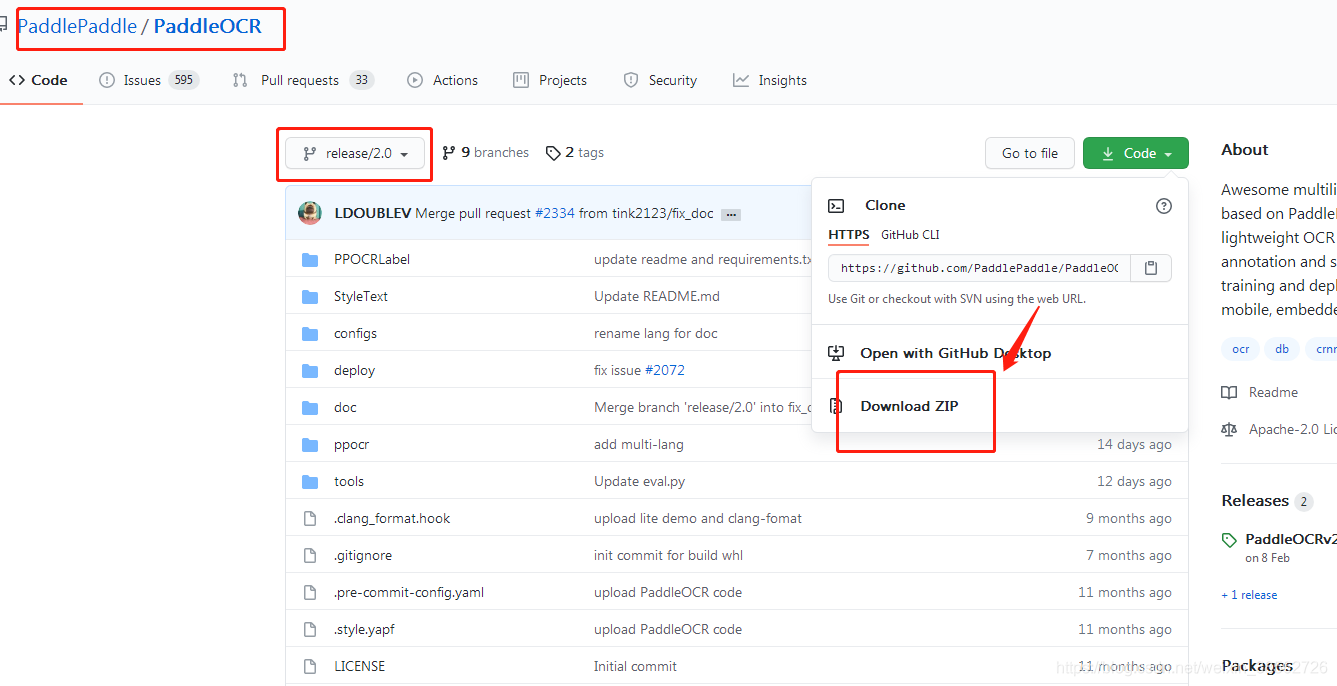
a.下載PaddleOCR推理專案:https://github.com/PaddlePaddle/PaddleOCR 如圖:
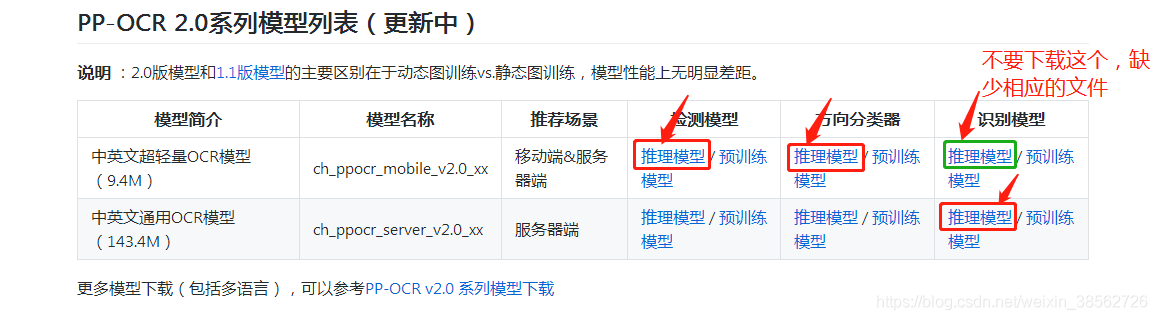
b.下載 PaddleOCR模型:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/README_ch.md 如圖:
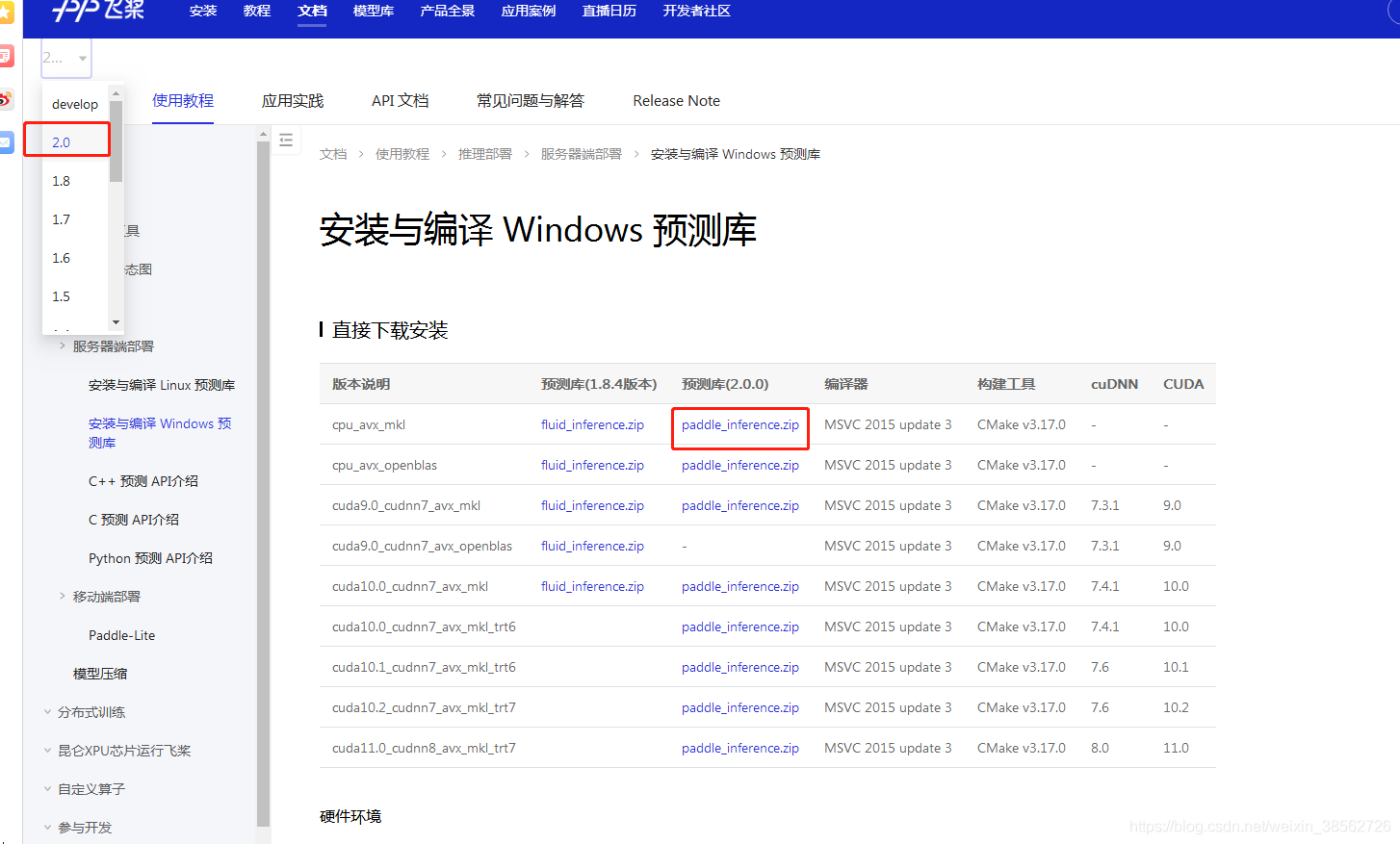
c.下載paddle_reference預測庫:https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/05_inference_deployment/inference/windows_cpp_inference.html 如圖:
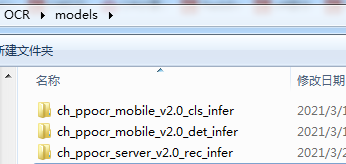
(5)步驟(4)下載的檔案分別為:
PaddleOCR推理專案:PaddleOCR-release-2.0;
PaddleOCR模型:總共有三個檔案夾(ch_ppocr_mobile_v2.0_cls_infer、 ch_ppocr_mobile_v2.0_det_infer、ch_ppocr_server_v2.0_rec_infer),為了方便,可以分別命名為cls、det、rec,將三個檔案放在同一個檔案夾下models
(三個檔案下都有檔案inference.pdiparams、inference.pdiparams.info、inference.pdmodel)
 檔案名更新為:
檔案名更新為: 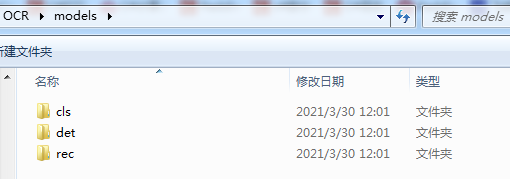
下載好之后的檔案如下,放在E盤符根目錄下OCR檔案夾:
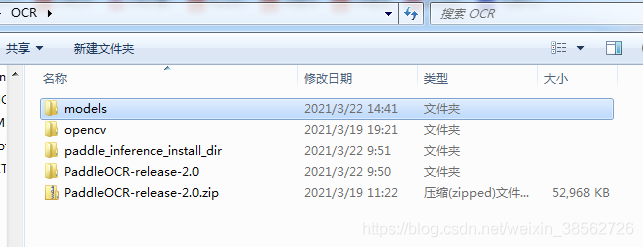
二、使用Cmake進行編譯PaddleOCR
在E:\OCR\PaddleOCR-release-2.0\deploy\cpp_infer檔案路徑下創建一個空檔案夾build,用于編譯,
cmake配置如下(讀者可以參考我自己的,因為我沒有使用到GPU,所以就沒有設定CUDA_LIB和CUDNN_LIB的路徑,有需要的可以自己試一下):
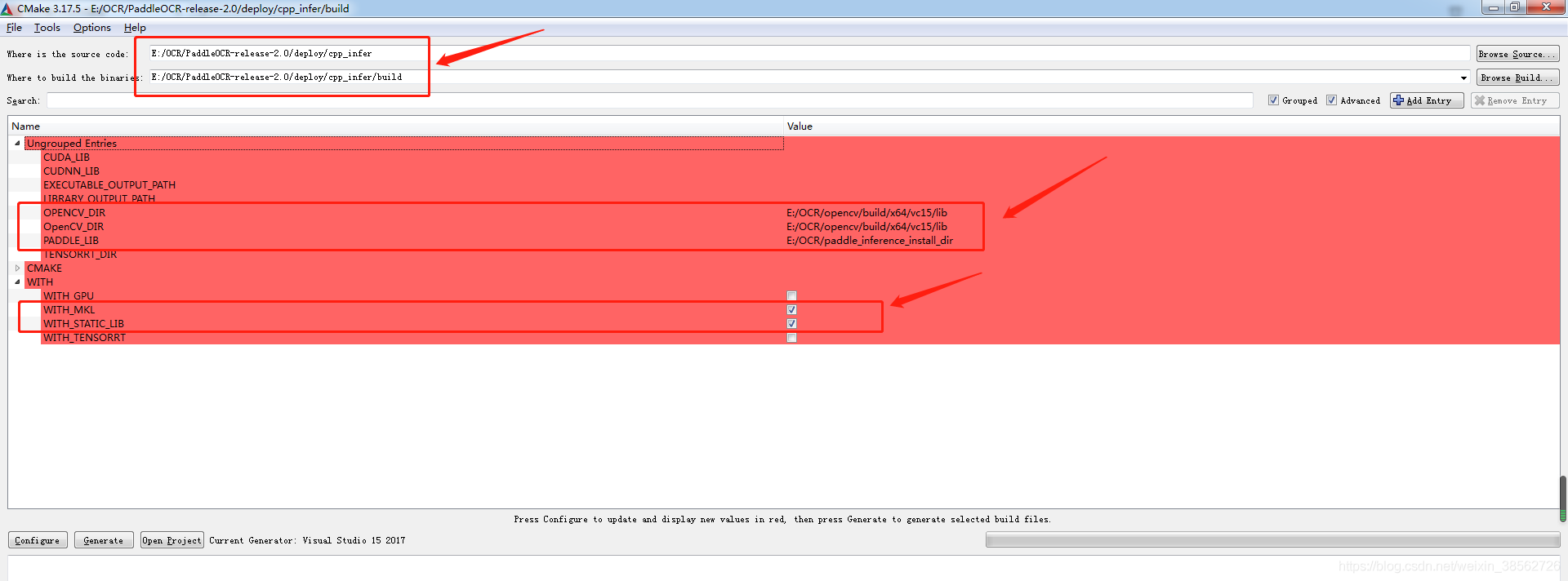
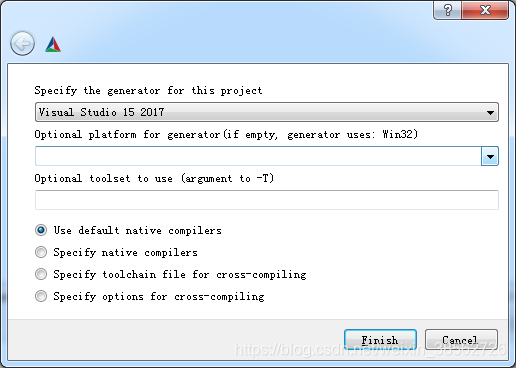
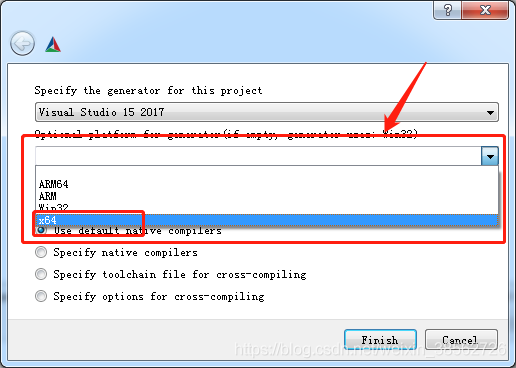
注意這里有個小坑:箭頭所指的地方要選擇x64,否則會出現“LNK1112 模塊計算機型別“X64”與目標計算機型別“X86”沖突,就算你改為x64還是出錯,所以一定要小心這里(如下圖)
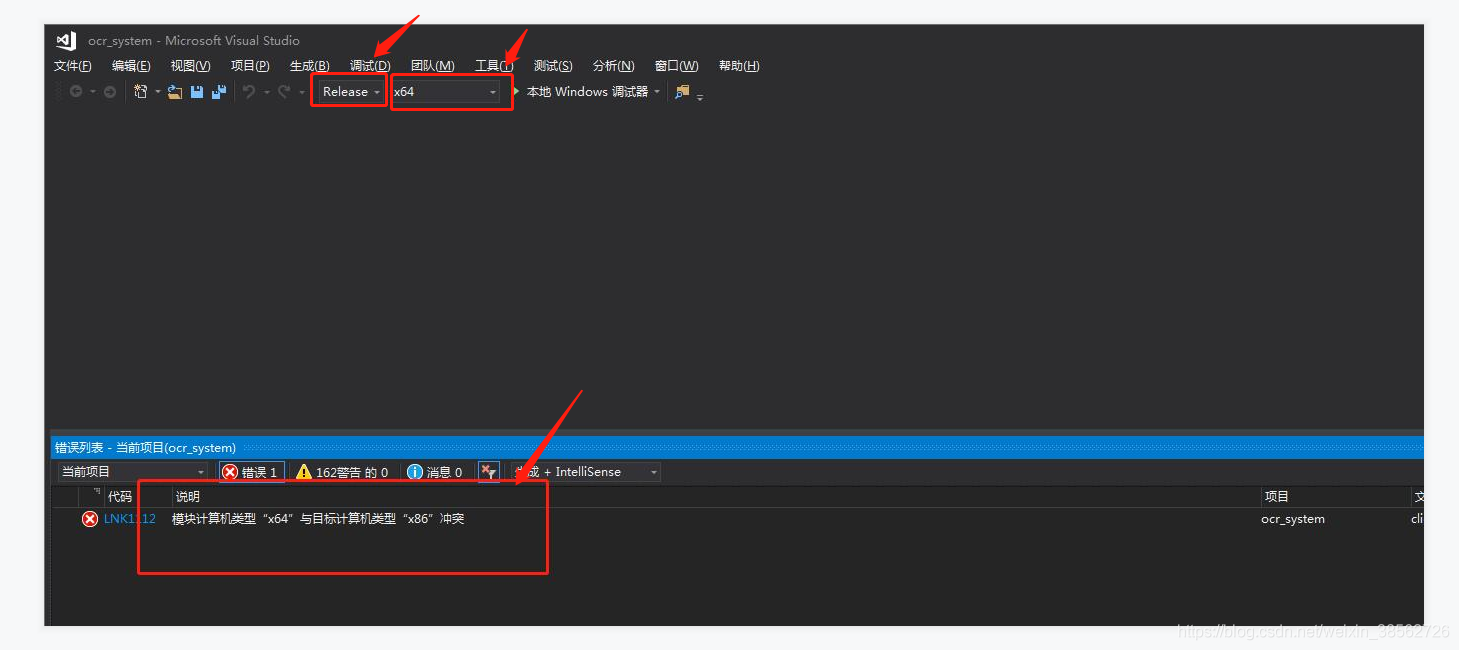
解決的辦法:config時彈出Optional platform for generator,選中x64即可 ,cmake會默認win32(其實后面小括號已經提示了,容易忽略的地方)
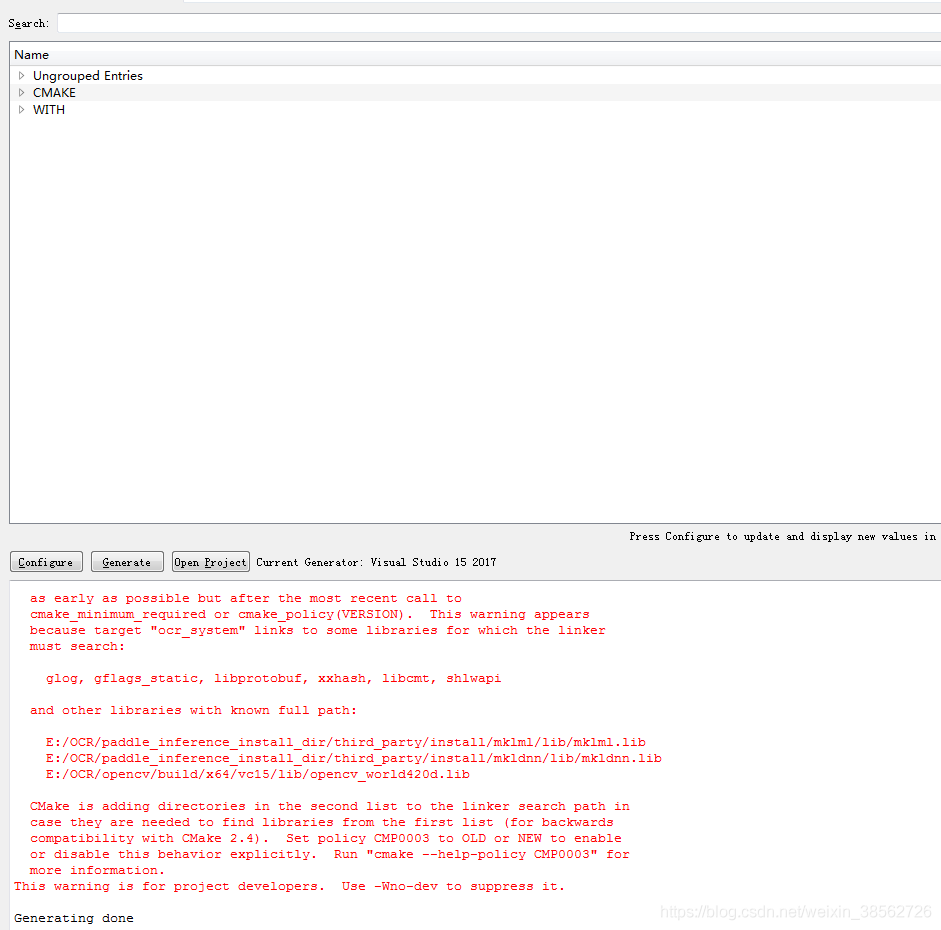
點擊configure和generate,彈出configuring done, generating done!,說明cmake編譯這步成功完成
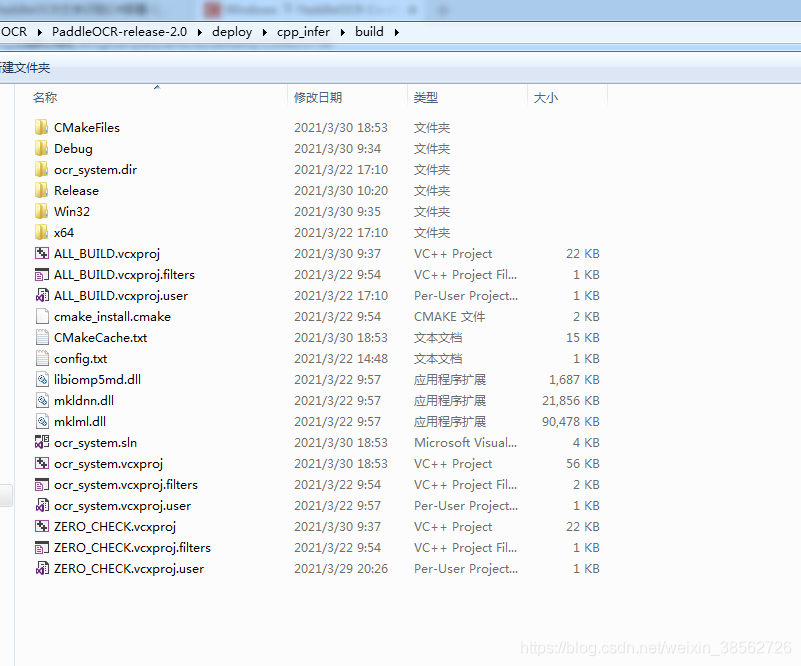
然后在E:\OCR\PaddleOCR-release-2.0\deploy\cpp_infer\build檔案夾下生產ocr_system.sln專案工程(如圖所示):
三、ocr_system.sln專案工程配置
在檔案路徑 E:\OCR\PaddleOCR-release-2.0\deploy\cpp_infer\build,打開ocr_system.sln,配置和平臺分別選擇release和x64位平臺(與cmake對應起來),如下圖所示:
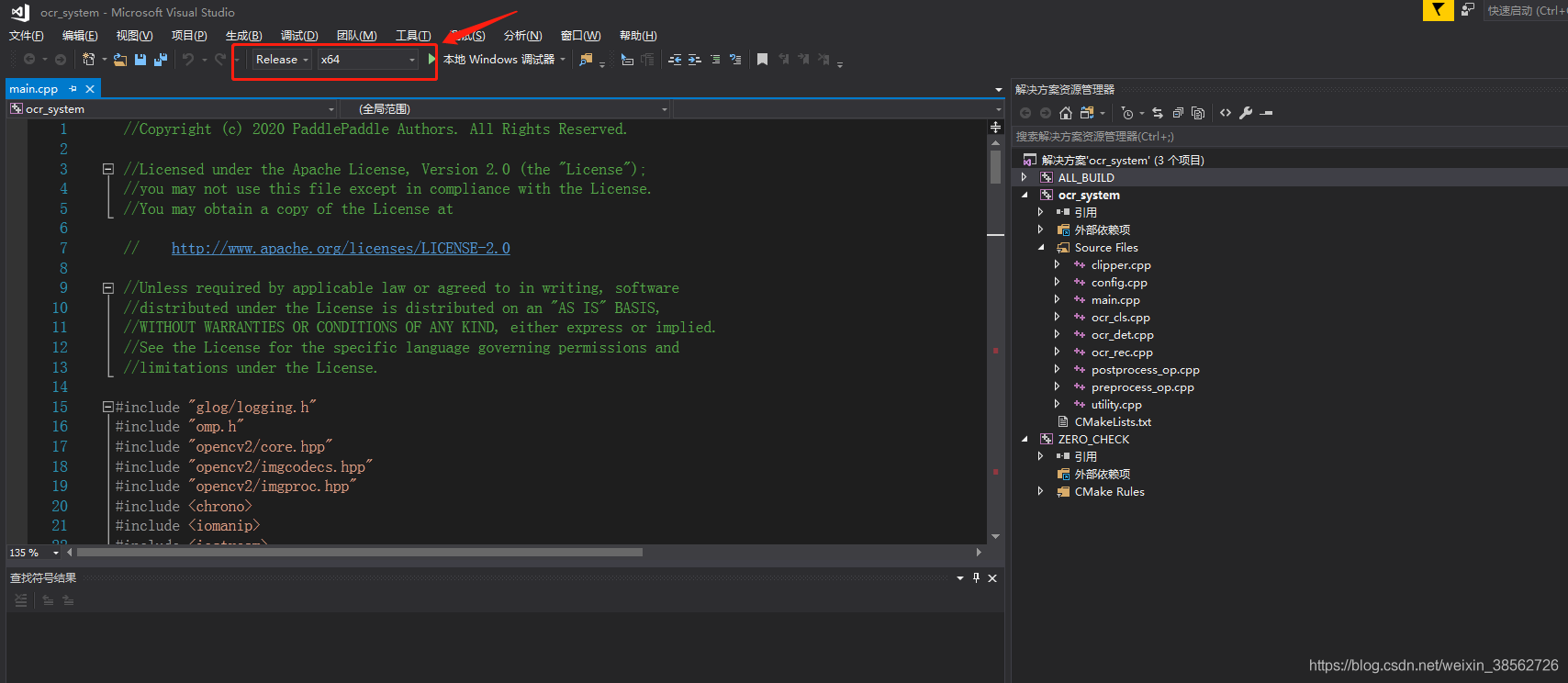
右擊專案ocr_system,屬性中配置工程,C/C++附件包含目錄:
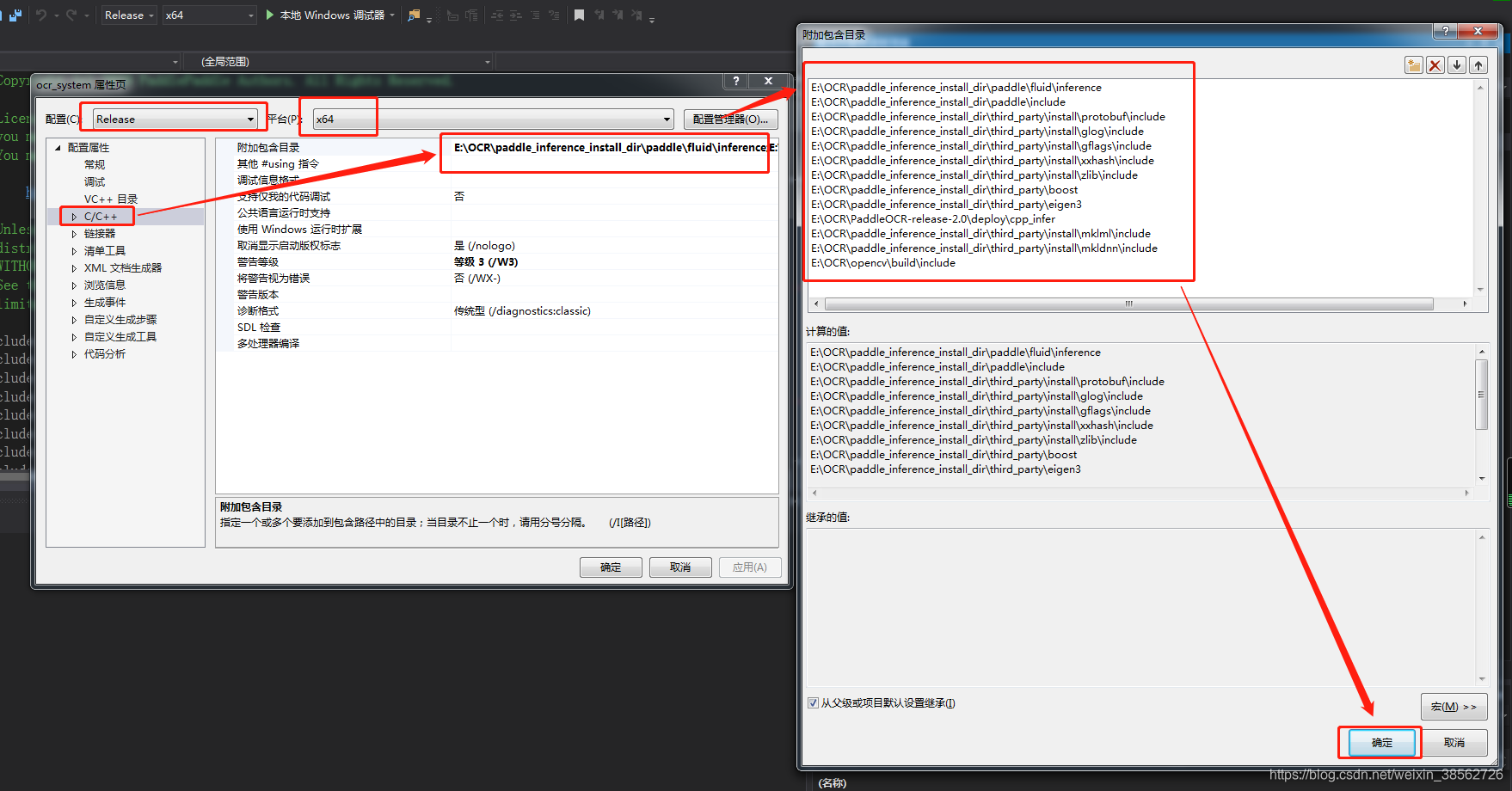
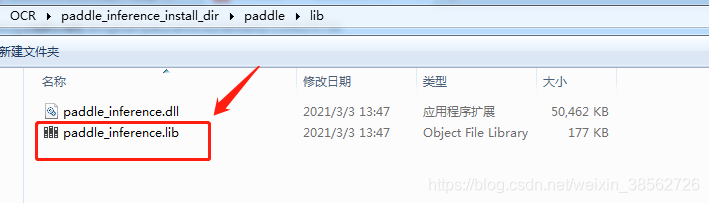
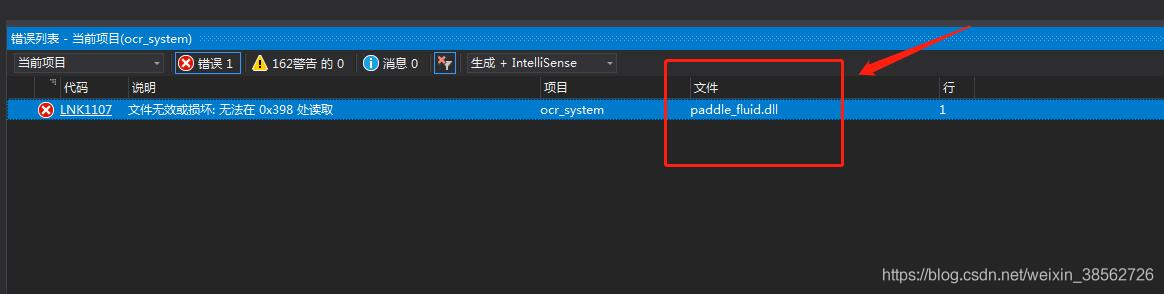
聯結器->輸入->附加依賴項:(注意這里有個坑:依賴項第一行自動配置出錯,應該將paddle_fluid.lib改為paddle_inference.lib,因為E:\OCR\paddle_inference_install_dir\paddle\lib路徑下沒有paddle_fluid.lib,不改否則會出錯,彈出錯誤“LNK1107 檔案無效或損壞:無法在0x398處讀取”)
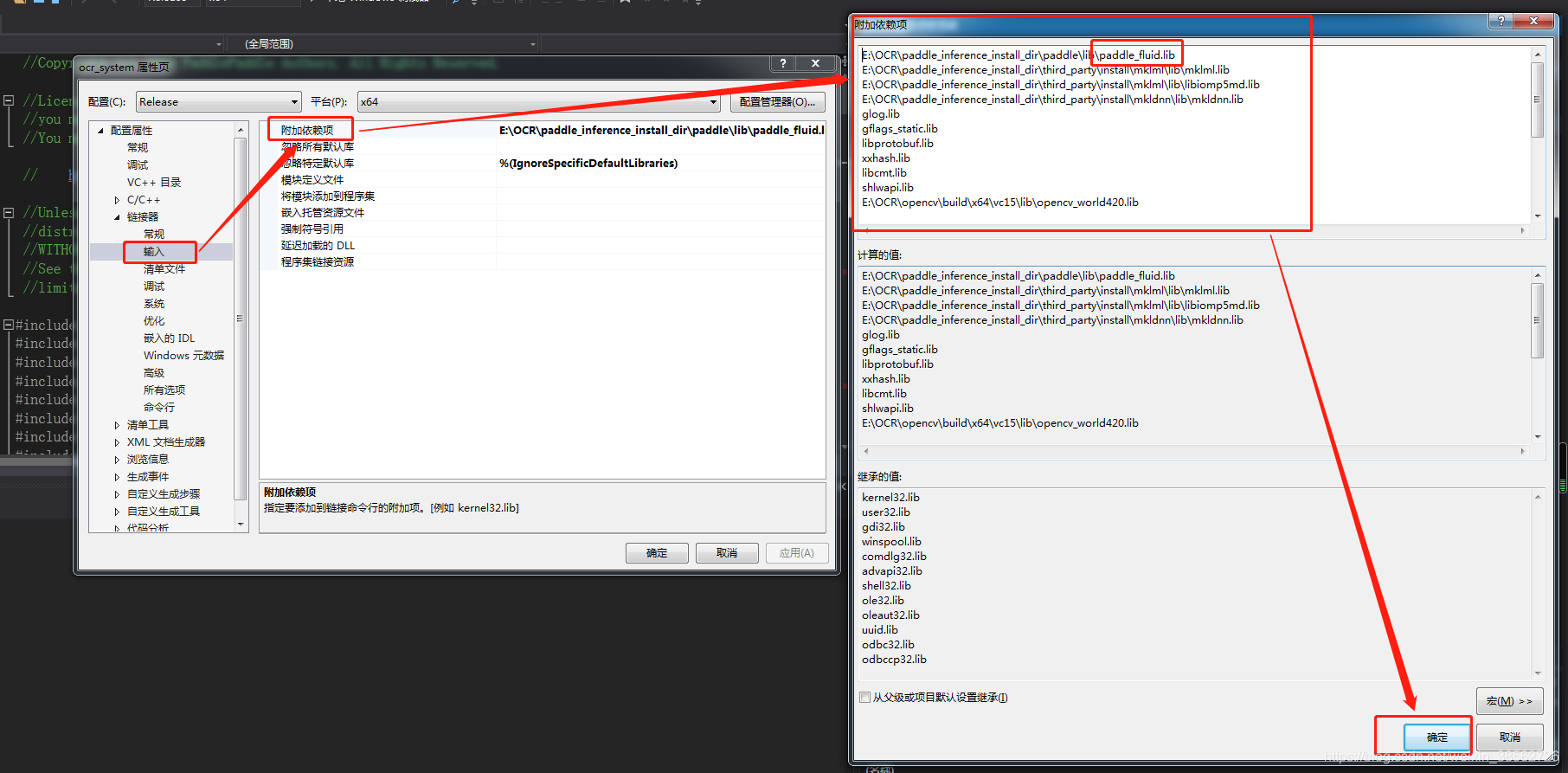
配置完成之后就可以生成解決方案了:右擊ocr_system->僅用于專案->僅生成ocr_system(B),生成ok,如下圖:
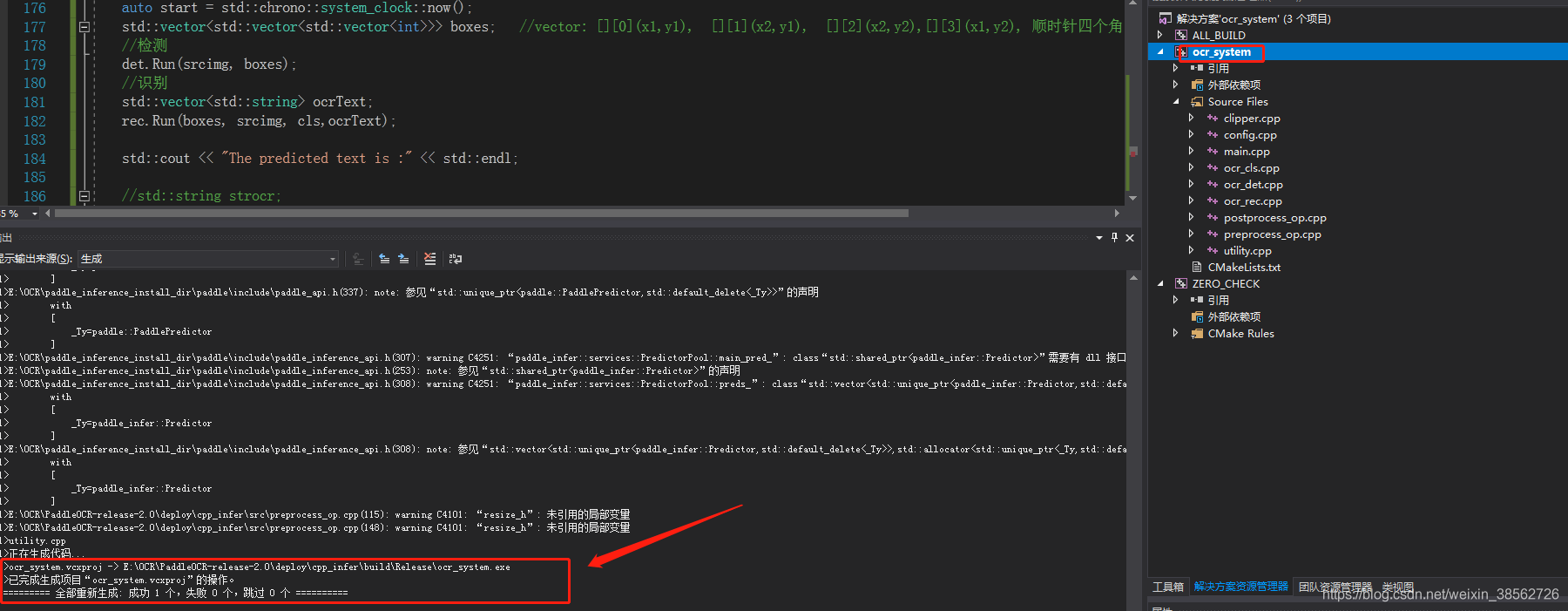
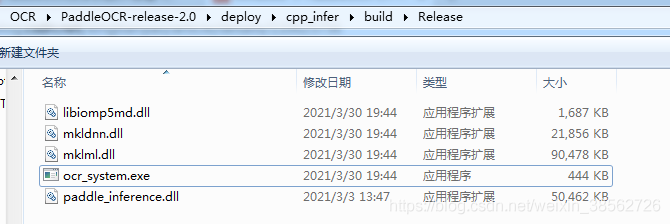
在 E:\OCR\PaddleOCR-release-2.0\deploy\cpp_infer\build\Release下生成exe可執行檔案(ocr_system.exe):
(注意需要把E:\OCR\paddle_inference_install_dir\paddle\lib檔案路徑下的paddle_fluid.dll 檔案拷貝過來)
四、運行配置的程式
在運行ocr_system.exe之前需要修改一下config.txt檔案內容:
修改配置E:\OCR\PaddleOCR-release-2.0\deploy\cpp_infer\tools
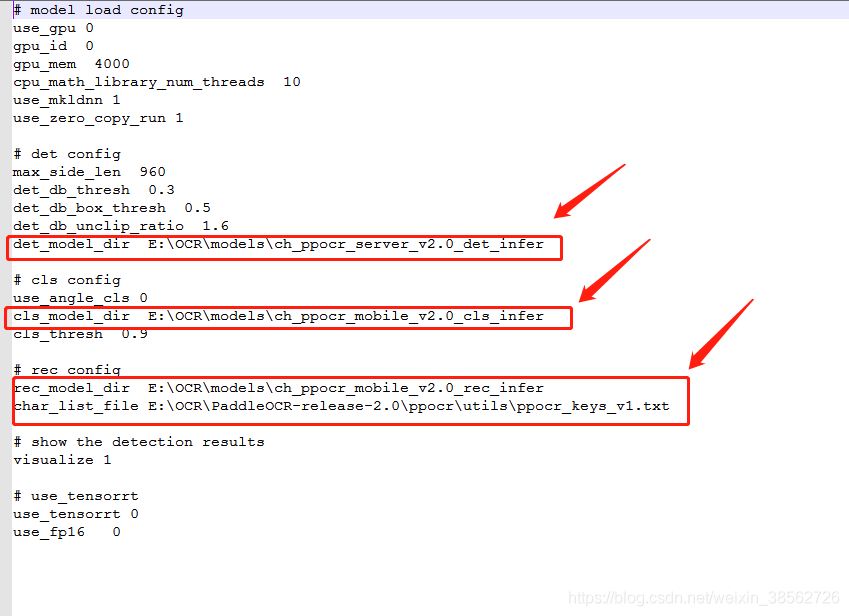
檔案修改的引數:
det_model_dir(檢測模型路徑) E:\OCR\models\ch_ppocr_server_v2.0_det_infer 這里修改成 E:\OCR\models\det
cls_model_dir (角度模型路徑) E:\OCR\models\ch_ppocr_mobile_v2.0_cls_infer 這里修改成 E:\OCR\models\cls
rec_model_dir (識別模型路徑) E:\OCR\models\ch_ppocr_mobile_v2.0_rec_infer 這里修改成 E:\OCR\models\rec
char_list_file(字典路徑) E:\OCR\PaddleOCR-release-2.0\ppocr\utils\ppocr_keys_v1.txt (路徑可以不修改,根據自己的實際情況定,也可以放在models路徑下)
配置到此就結束了
五、測驗一下是否配置成功
1、運行cmd,命令列cd 到可執行檔案目錄下:E:\OCR\PaddleOCR-release-2.0\deploy\cpp_infer\build\Release
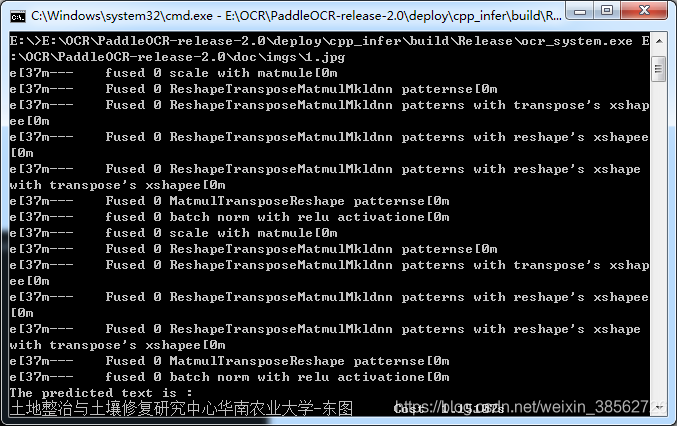
2、執行:ocr_system.exe E:\OCR\PaddleOCR-release-2.0\doc\imgs\1.jpg

結果如下,說明配置成功:
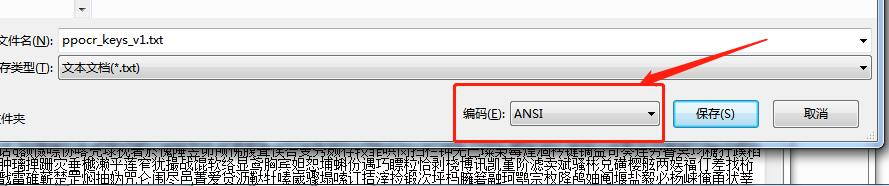
注意:1、如果識別中文時出現亂碼的話,需要對ppocr_keys_v1.txt的編碼格式由utf-8修改成ANSI格式即可,具體方法可以直接使用記事本修改,如圖:
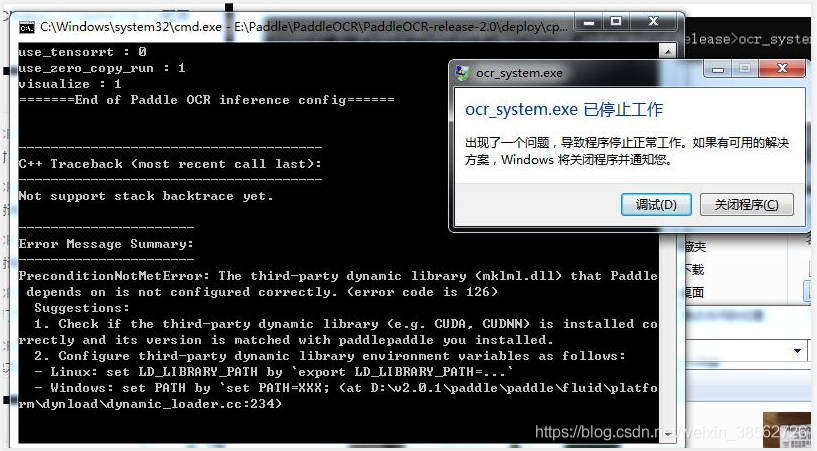
2、出現如下圖的問題:一般是專案屬性沒配對,找不到dll檔案,一定要核對好路徑
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/271905.html
標籤:其他
上一篇:初窺Java門徑(上)