在ANSI C的實作中,存在2種環境:翻譯環境和運行環境,
翻譯環境
在翻譯環境下,程式的編譯可以被分為編譯和鏈接2個部分,其中編譯還可以被分為預處理、編譯、匯編,下圖是程式的編譯程序,
- 組成一個程式的每個源檔案通過編譯器的編譯最終都會變成其對應的目標代碼
- 每個目標檔案由聯結器捆綁在一起,最終形成一個單一且完整的可執行程式
- 聯結器同時也會引入標準C函式庫中任何被該程式所用到的函式,而且它可以搜索程式員個人的程式庫, 將其需要的函式也鏈接到程式中
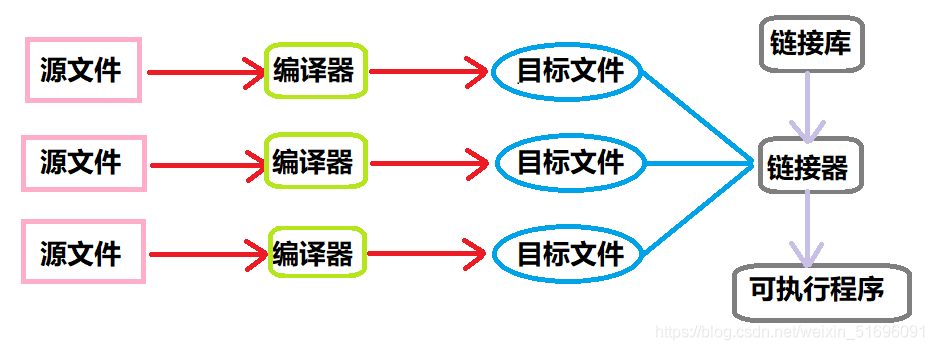
編譯和鏈接
接下來再通過一張圖去概括編譯的4個階段的具體內容,

預處理
預處理也被稱為預編譯,在預處理階段,主要進行以下4個步驟
- #include頭檔案的包含,顧名思義,就是將源檔案中所參考的頭檔案的所有內容放到源檔案之中,
- #define定義的常量的替換,如#define MAX 100,程式中所有出現MAX的位置,都會被替換成100這個整形,
- 條件編譯,所有的條件編譯指令在這一階段都會被判斷并作用,
- 注釋的洗掉,所有的注釋都會被替換成空格,
編譯
在這一階段,主要將C語言代碼翻譯成匯編代碼,除此之外還進行以下4個步驟:
- 詞法分析:從左至右逐個字符地對源程式進行掃描,產生單詞符號并把字串形式的源程式改造成為單詞符號串形式的中間程式,
- 語法分析:在詞法分析識別出正確的單詞符號串是否符合語言的語法規則,分析并識別各種語法成分,同時進行語法檢查和錯誤處理,為語意分析和代碼生成做準備,
- 語意分析:審查源程式有無語意錯誤,為代碼生成階段收集型別資訊,
- 符號匯總:進行符號的匯總,為在匯編期間形成符號表做準備,
運行環境
運行環境也叫執行環境,也就是程式的執行程序,
- 程式必須載入記憶體中,在有作業系統的環境中:一般這個由作業系統完成,在獨立的環境中,程式的載入必須 由手工安排,也可能是通過可執行代碼置入只讀記憶體來完成,
- 程式的執行便開始,接著便呼叫main函式,
- 開始執行程式代碼,這個時候程式將使用一個運行時堆疊,存盤函式的區域變數和回傳地址,程式同時也可以使用靜態記憶體,存盤于靜態記憶體中的變數在程式的整個執行程序一直保留他們的值,
- 終止程式,正常終止main函式;也有可能是意外終止,
函式多載
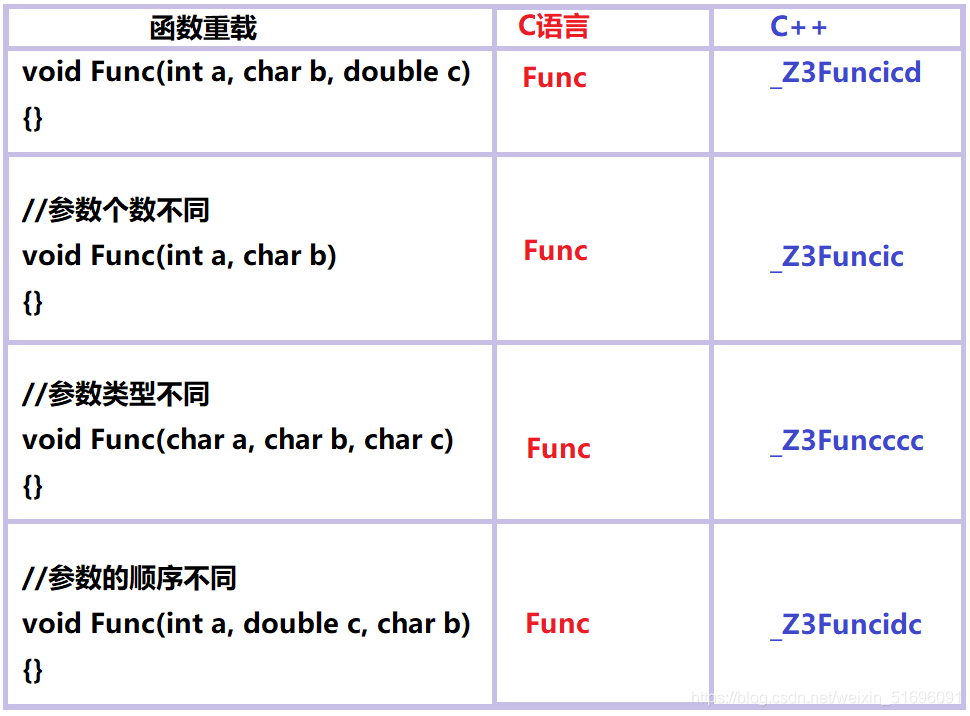
函式多載是函式的一種特殊情況,C++允許在同一作用域中宣告幾個功能類似的同名函式(C語言中不可以),這些函式的函式名必須相同,但是這些函式的形參串列 (引數個數、引數型別、引數順序)必須有至少1個不同,例如:
void Func(int a, char b, double c)
{}
//引數個數不同
void Func(int a, char b)
{}
//引數型別不同
void Func(char a, char b, char c)
{}
//引數的順序不同
void Func(int a, double c, char b)
{}為什么C++支持函式多載而C語言卻不支持?
這是由于在鏈接期間,C++對函式的命名規則可以區分出函式多載的函式,但是C語言的命名規則不可以,
下圖是程式在分別采用C語言的編譯和C++的編譯后的函式名的變化結果,我們可以看出C語言對于函式名沒有做什么修改,C++則不同,C++的命名規則是:_Z是每個函式名前面都需要加的,然后Z后面的數字代表這個函式名中有幾個字母,隨后跟著的是函式名,函式名后面是每個引數的縮寫,如:int --> i , char --> c , double --> d , int* --> pi等等,我們可以從C++的命名規則中分析出,在函式名相同的情況下,只要能夠讓每個函式在經過編譯后產生的函式名不同,那么它們就是函式多載,因此影響函式多載的因素如下:
- 函式引數的型別
- 函式引數的個數
- 函式引數的順序
注意:函式的回傳值是函式多載的必要不充分條件,即,函式多載的函式可以回傳值不同,但是回傳值不同的函式,不一定是函式多載,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272622.html
標籤:其他