萌新篇 —從零開始搭建自己的大資料環境
hadoop簡介
Hadoop是一個用Java撰寫的Apache開源框架,允許使用簡單的編程模型跨計算機集群分布式處理大型資料集,Hadoop框架作業的應用程式在跨計算機集群提供分布式存盤和計算的環境中作業,Hadoop旨在從單個服務器擴展到數千個機器,每個都提供本地計算和存盤,
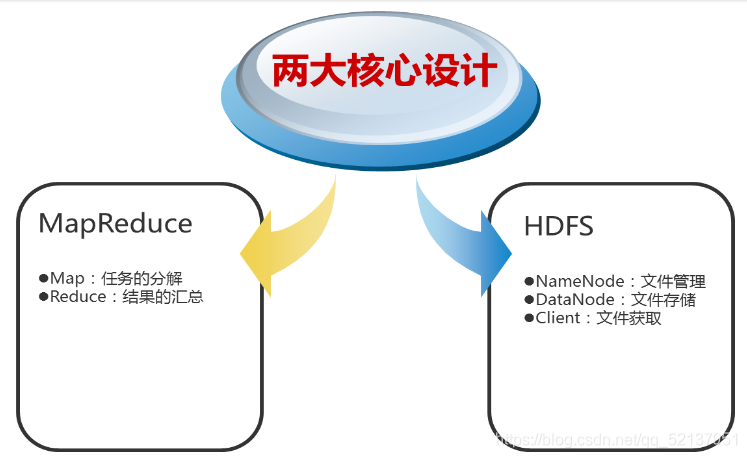
Hadoop框架包括以下四個模塊:
Hadoop Common: 這些是其他Hadoop模塊所需的Java庫和實用程式,這些庫提供檔案系統和作業系統級抽象,并包含啟動Hadoop所需的Java檔案和腳本,
Hadoop YARN: 這是一個用于作業調度和集群資源管理的框架,
Hadoop Distributed File System (HDFS?): 分布式檔案系統,提供對應用程式資料的高吞吐量訪問,
Hadoop MapReduce:這是基于YARN的用于并行處理大資料集的系統,
!
關于hadoop的詳細介紹可以參考官網或者參考這篇文章:點擊
前言
我事先創建好了opt檔案,該檔案里包含data,modules,software,tools,一般我把安裝包存放在sofeware解壓生成在modules,可以按照我這個方式去做,后期以便檔案好找,java環境自行先安裝建議使用1.8版本的,這里我就不示范了,程序使用的軟體Notepad++(在這里修改組態檔比較方便),MobaXterm_Personal_20.2(遠程登錄linux)FlashFPX(把檔案發送到linux上),
Hadoop2.x分布式集群配置-HDFS
1、下載地址
https://downloads.apache.org/hadoop/common/hadoop-2.10.1/
hadoop有兩種版本一種cdh版本,一種官網的如上,一般采用cdh版本的,它在版本兼容方面優于官網,還有盡量不要使用最新版本,最新版本在各方面集成上不如低的版本,
2、發送到虛擬機
采用FlashFPX鏈接虛擬機,把下載好的hadoop-2.10.1.tar.gz發送到虛擬機上,

3、給權限并解壓
chmod u+x hadoop-2.5.0.tar.gz 權限
tar -zxf hadoop-2.5.0.tar.gz -C /opt/modules/
-C /opt/modules/這個可加可不加,后面是解壓存放目錄,
4、檔案瘦身
cd hadoop-2.5.0 進入hadoop檔案
cd share 進入share檔案洗掉doc檔案 rm -rf doc
cd etc/hadoop/ 進入etc下的hadoop檔案洗掉.cmd檔案 rm -rf ./*.cmd
.cmd檔案在window環境下才使用的命令,在linux上用不上,可以洗掉,
5、組態檔
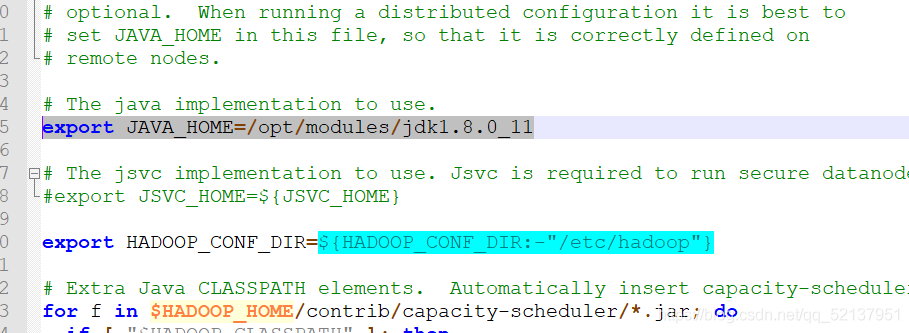
(1)、hadoop-env.sh,yarn-env.sh,配置java環境變數
echo $JAVA_HOME 查看路徑

export JAVA_HOME=/opt/modules/jdk1.8.0_11 修改hadoop-env.sh中的export將查找的java路徑復制上去
(2)、core-site.xml配置
<property>
<name>fs.defaultFS</name>
<value>hdfs://panda-pro01.xiong.com:9000</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>xiong</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.5.0/data/tmp</value>
</property>
注意修改自己的主機名,存放目錄可以自己創建存放位置,
(3)、hdfs-site.xml配置
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
(4)、slaves
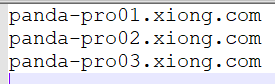
這里我配置的三臺機器,都有datanode,所以需要有三臺機器的主機名,
6、格式化
bin/hdfs namenode -format
7、打開web網站
ip地址+50070,如10.34.102.250:50070
或者hostname+50070如panda-pro01.xiong.com:50070
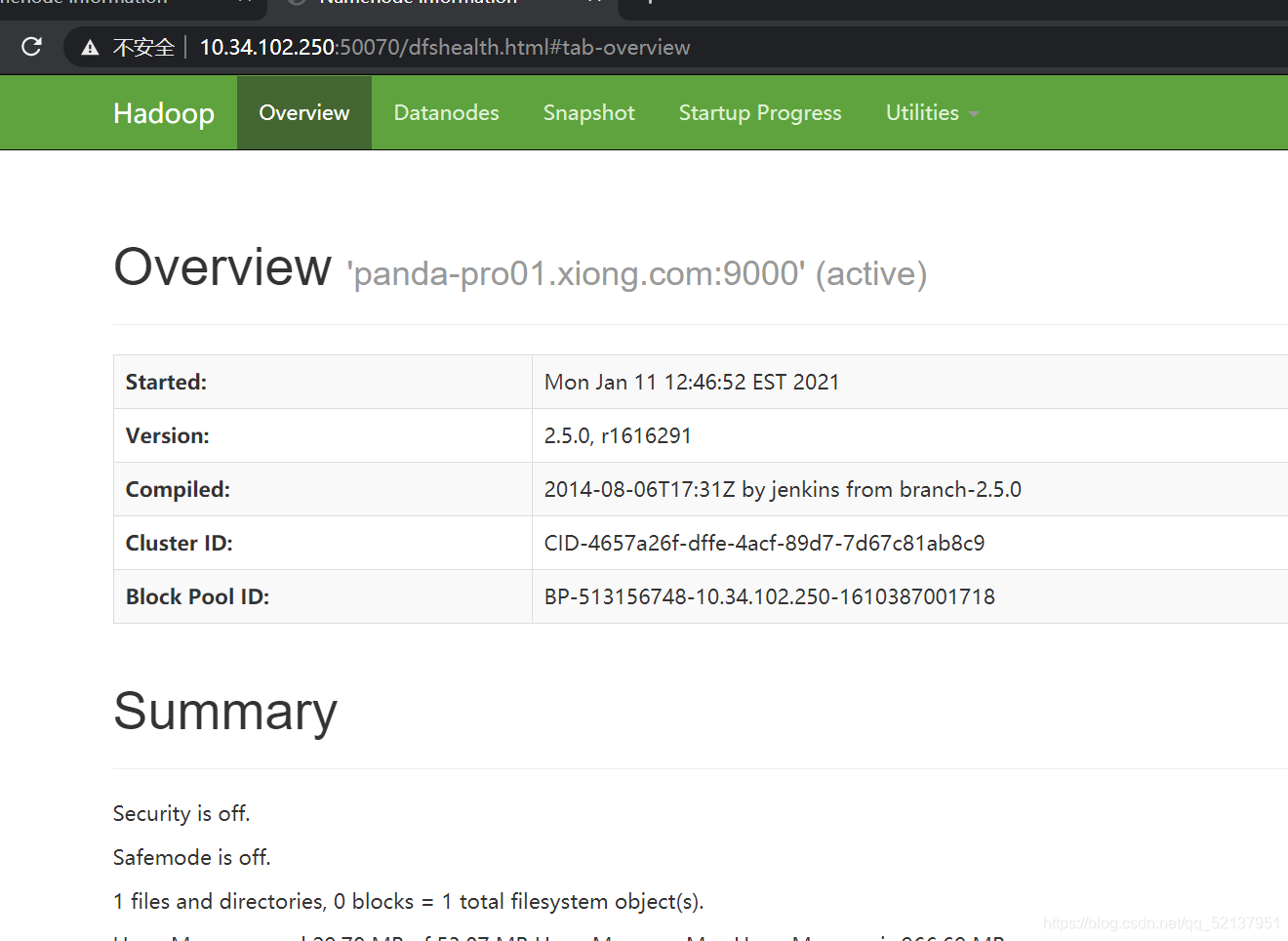
8、測驗
bin/hdfs dfs -mkdir -p /user/xiong/data/ 創建檔案夾

bin/hdfs dfs -put /opt/datas/demo.c /user/xiong/data/ 上傳一個檔案

bin/hdfs dfs -text /user/xiong/data/demo.c 獲取檔案

Hadoop2.x分布式集群配置-YARN
1、mapred-site.xml配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>panda-pro01.xiong.com:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>panda-pro01.xiong.com:10020</value>
</property>
2、yarn-site.xml配置
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>panda-pro01.xiong.com</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>10000</value>
</property>
yarn.log-aggregation-enable日志聚集,可以歷史服務器 Web 頁面查看各個 Map 和 Reduce 的日志,yarn.log-aggregation.retain-seconds在HDFS上聚集的日志最多保存多長時間,
3、測驗
先創建一個文本上面記錄一些單詞,隨便寫入,盡量重復一些, 以便測驗效果,
bin/hdfs dfs -mkdir -p /user/xiong/data/output/ 創建一個輸出目錄
bin/hdfs dfs -put /opt/datas/wc.input /user/xiong/data/ 上傳文本
4、啟動服務
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
5、進入web界面
ip地址+50070,如10.34.102.250:8088
或者hostname+50070如panda-pro01.xiong.com:8088
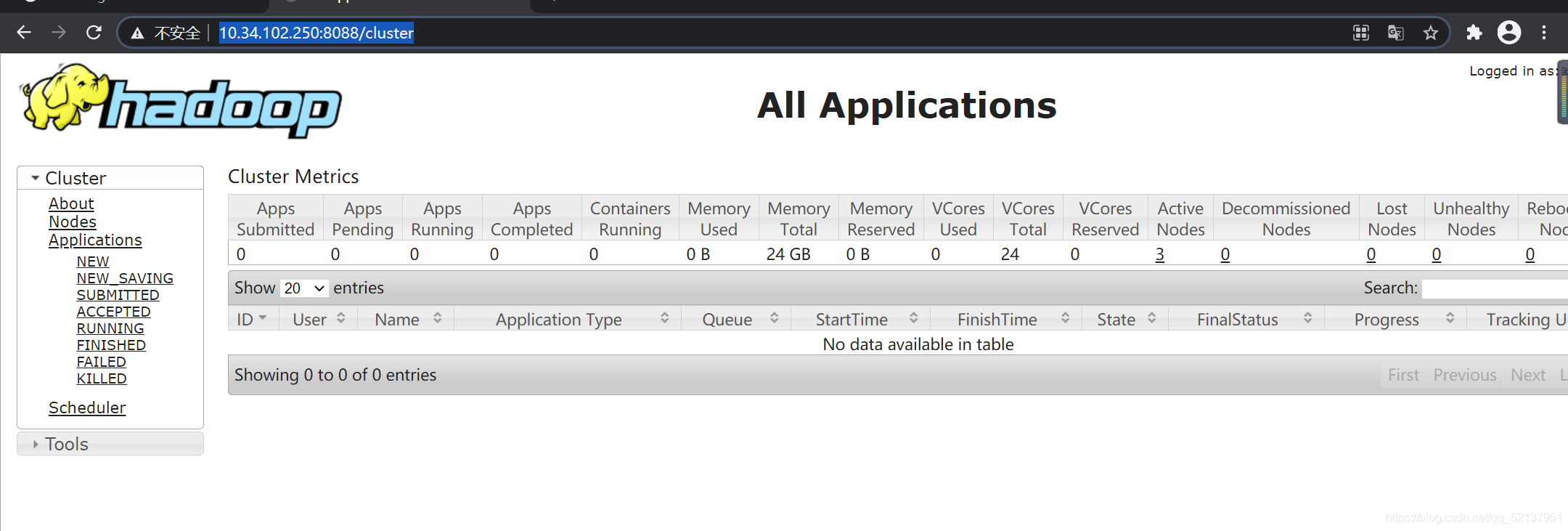
6、計算并顯示結果
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/xiong/data/wc.input /user/xiong/data/output/output_1
可以看到yarnweb界面有跑這個的任務,點擊history可以看到job日志,這就是上面配置mapred-site.xml檔案

生成的檔案如下,我們要獲得part檔案

bin/hdfs dfs -text /user/xiong/data/output/output_1/par* 獲取檔案并顯示結果

結束
關于hadoop的基本配置已介紹完畢,若有些細節沒有get到可以自行補充,本人萌新一枚,若有錯誤之處還請諒解,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272631.html
標籤:其他
上一篇:Maven下載與配置詳細教程