文章目錄
- 一、大資料
- 1、大資料的定義
- 2、大資料的特點
- 3、大資料行業應用
- 4、Hadoop 與大資料
- 5、其他大資料處理平臺
- 6、大資料人才
- 二、什么是 Hadoop
- 1、Hadoop 簡介
- 2、Hadoop 的發展歷史
- 3、Hadoop 的特點
- 三、Hadoop 核心
- 1、分布式檔案系統——HDFS
- 2、分布式計算框架——MapReduce
- 3、集群資源管理器——YARN
- 四、Hadoop 常用組件
- 五、Hadoop 在國內外的應用情況
一、大資料
隨著近來計算機技術和互聯網的發展,大資料 這個名詞越來越多地進入到我們的視野中,大資料的快速發展也無時刻影響著我們的生活,
1、大資料的定義
大資料從字面來理解就是 大量的資料,日常生活離不開資料,可以說每時每刻都在產生著資料,例如,一分鐘可以做些什么事呢?在日常生活中,一分鐘可能連一頁書都看不完,但是一分鐘內產生的資料卻是龐大的,據統計,在一分鐘內,YouTube 用戶上傳 300 小時的新視頻,電子郵件用戶發送 2.4 億條資訊,Google 收到超過 278 萬個搜索查詢,Facebook 用戶點贊 4166 667 次,消費者在網購上花費 272070 美元,Twitter 用戶發布 347222 條推文,Instagram 用戶每分鐘發布 123060 張照片,Netflix 用戶觀看 77160 個小時的視頻,微信紅包的收發 1527777 個,
這些資料還在不停地增長,那么大資料究竟是什么?國際頂級權威咨詢機構麥肯錫 說:“大資料指的是所涉及的資料集規模已經超過了傳統資料庫軟體獲取、存盤、管理和分析的能力,這是一個被故意設計成的具有主觀性的定義,并且是一個關于多大的資料集才能被認為是大資料的可變定義,即并不定義大于一個特定數字的 TB 才叫大資料,因為隨著技術的不斷發展,符合大資料標志的資料集容量也會增長;并且定義隨不同行業也有變化,這也依賴于在一個特定行業通常使用何種軟體和資料集有多大,因此,大資料在今天不同行業中的范圍可以從幾十 TB 到幾 PB”,
從上面的定義中可以看出:
- 多大的資料才算大資料,這并沒有一個明確的界定,且不同行業有不同的標準,
- 大資料不僅僅只是大,它還包含了資料集規模已經超過了傳統資料庫軟體獲取、存盤、分析和管理能力這一層意思,
- 大資料不一定永遠是大資料,大資料的標準是可變的,在 20 年前 1GB 的資料也可以叫大資料,可見,隨著計算機硬體技術的發展,符合大資料標志的資料集容量也會增長,
現在所說的大資料實際上更多是從應用的層面,比如某公司搜集、整理了大量的用戶行為資訊,然后通過資料分析手段對這些資訊進行分析從而得出對公司有利用價值的結果,比如,頭條、熱搜的產生,就是建立在對海量用戶的閱讀資訊的搜集、分析之上,這就是大資料在現實中的具體體現,
2、大資料的特點
IBM 提出大資料具有 5V 特點,分別為:Volume(大量)、Velocity(高速)、Variety(多樣)、Value(低價值密度)、Veracity(真實性),下面具體說明此 5V 特點,
- Volume:巨大的資料量,采集、存盤和計算的量都非常大,大資料的起始計量單位至少是 PB(1000TB)、EB(100萬TB)或ZB(10億TB),
8 bit = 1 Byte 一位元組 1024 B = 1 KB (KiloByte) 千位元組 1024 KB = 1 MB (MegaByte) 兆位元組 1024 MB = 1 GB (GigaByte) 吉位元組 1024 GB = 1 TB (TeraByte) 太位元組 1024 TB = 1 PB (PetaByte) 拍位元組 1024 PB = 1 EB (ExaByte) 艾位元組 1024 EB = 1 ZB (ZetaByte) 澤位元組 1024 ZB = 1 YB (YottaByte) 堯位元組 1024 YB = 1BB(Brontobyte)珀位元組 1024 BB = 1 NB (NonaByte) 諾位元組 1024 NB = 1 DB (DoggaByte)刀位元組 - Velocity:因為要保證資料的時效性,資料增長速度和處理速度必須要迅速,比如搜索引擎要求幾分鐘前的新聞都能夠被用戶查詢到,個性化推薦演算法盡可能要求實時完成推薦,這是大資料區別于傳統資料挖掘的顯著特征,
- Variety:種類和來源多樣化,包括結構化、半結構化和非結構化資料,具體表現為網路日志、音頻、視頻、圖片、地理位置資訊等,多型別的資料對資料的處理能力提出了更高的要求,
- Value:資料價值密度相對較低,隨著互聯網以及物聯網的廣泛應用,資訊感知無處不在,資訊海量,但價值密度較低,那么如何結合業務邏輯并通過強大的機器演算法來挖掘資料價值,是大資料時代最需要解決的問題,
- Veracity:資料的準確性和可信賴度,即為資料的質量,
3、大資料行業應用
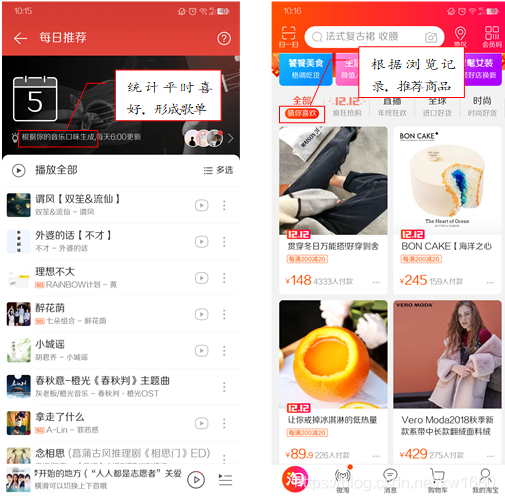
通過上面的介紹,讀者或許并不能直觀地理解何為大資料,下面通過幾個大資料的應用案例來更形象地了解大資料,在日常生活中,最常見的大資料應用的例子就是手機中各種社交、娛樂、購物類的 App,例如聽歌類 App 有 每日推薦 版塊,此版塊中的歌曲就是根據用戶平時聽歌型別或者同一歌手演唱的歌曲而來的;使用淘寶 App,瀏覽商品后,主頁顯示或者推送的都是類似商品,如下圖所示,類似的 App 有很多,可見大資料已經廣泛融入了我們的日常生活中,
除了手機 App,大資料的應用已經滲透到各行各業中,
(1) 醫療大資料,除了較早前就開始利用大資料的互聯網公司,醫療行業是讓大資料分析最先發揚光大的傳統行業之一,Seton Healthcare 是采用 IBM 最新沃森技術醫療保健內容分析預測的首個客戶,該技術允許企業找到大量病人相關的臨床醫療資訊,通過大資料處理,更好地分析病人的資訊,在加拿大多倫多的一家醫院,針對早產嬰兒,每秒鐘有超過 3000 次的資料讀取,通過這些資料分析,醫院能夠提前知道哪些早產兒出現問題并且有針對性地采取措施,避免早產嬰兒夭折,同時大資料讓更多的創業者更方便地開發產品,比如通過社交網路來收集資料的健康類 App,也許未來數年后,它們搜集的資料能讓醫生給你的診斷變得更為精確,比方說不是通用的 成人每日三次,一次一片,而是檢測到你的血液中藥劑已經代謝完成會自動提醒你再次服藥,等等,
(2) 金融大資料,大資料在金融行業應用范圍較廣,典型的案例有花旗銀行利用 IBM 沃森電腦為財富管理客戶推薦產品;美國銀行利用客戶點擊資料集為客戶提供特色服務,如設定競爭的信用額度;招商銀行利用客戶刷卡、存取款、電子銀行轉賬、微信評論等行為資料進行分析,每周給客戶發送針對性廣告資訊,里面有顧客可能感興趣的產品和優惠資訊,大資料在金融行業的應用可以總結為以下五個方面:
- 精準營銷:依據客戶消費習慣、地理位置、消費時間進行推薦,
- 風險管控:依據客戶消費和現金流提供信用評級或融資支持,利用客戶社交行為記錄實施信用卡反欺詐,
- 決策支持:利用決策樹技術進抵押貸款管理,利用資料分析報告實施產業信貸風險控制,
- 效率提升:利用金融行業全域資料了解業務運營薄弱點,利用大資料技術加快內部資料處理速度,
- 產品設計:利用大資料計算技術為財富客戶推薦產品,利用客戶行為資料設計滿足客戶需求的金融產品,
(3) 交通大資料,目前,交通的大資料應用主要在兩個方面,一方面可以利用大資料傳感器資料來了解車輛通行密度,合理進行道路規劃包括單行線路規劃;另一方面可以利用大資料來實作即時信號燈調度,提高已有線路運行能力,科學的安排信號燈是一個復雜的系統工程,必須利用大資料計算平臺才能計算出一個較為合理的方案,科學的信號燈安排將會提高 30% 左右已有道路的通行能力,在美國,政府依據某一路段的交通事故資訊來增設信號燈,使交通事故率降低了 50% 以上,依靠大資料將會提高航班管理的效率,航空公司利用大資料可以提高上座率,降低運行成本,鐵路利用大資料可以有效安排客運和貨運列車,提高效率、降低成本,
(4) 教育大資料,在課堂上,資料不僅可以幫助改善教育教學,在重大教育決策制定和教育改革方面,大資料更有用武之地,美國利用資料來診斷處在輟學危險期的學生、探索教育開支與學生學習成績提升的關系、探索學生缺課與成績的關系,比如美國某州公立中小學的資料分析顯示,在語文成績上,教師高考分數和學生成績呈現顯著的正相關,也就是說,教師的高考成績與他們現在所教幼ò肝上的學生學習成績有很明顯的關系;教師的高考成績越好,學生的語文成績也越好,這個關系讓我們進一步探討其背后真正的原因,其實,教師高考成績高低在某種程度上是教師的某個特點在起作用,而正是這個特點對教好學生起著至關重要的作用,因此教師的高考分數可以作為挑選教師的一個指標,如果有了充分的資料,便可以發掘更多的教師特征和學生成績之間的關系,從而為挑選教師提供更好的參考,
大資料還可以幫助家長和教師甄別出孩子的學習差距,提供有效的學習方法,比如,美國的麥格勞·希爾教育出版集團就開發出了一種預測評估工具,幫助學生評估他們已有的知識和達標測驗所需程度的差距,進而指出學生有待提高的地方,評估工具可以讓教師跟蹤學生學習情況,從而找到學生的學習特點和方法,有些學生適合按部就班,有些則更適合圖式資訊和整合資訊的非線性學習,這些都可以通過大資料搜集和分析很快識別出來,從而為教育教學提供堅實的依據,
(5) 商業大資料,全球零售業的巨頭沃爾瑪也通過大資料獲益,公司在對消費者購物行為進行分析時發現,男性顧客在購買嬰兒尿片時,常常會順便搭配幾瓶啤酒來犒勞自己,于是推出了將啤酒和尿布捆綁銷售的促銷手段,如今,這一 啤酒+尿布 的資料分析成果也成了大資料技術應用的經典案例,
大家可以百度一下 買披薩的故事,深入了解大資料,
基于大資料應用的行業實體數不勝數,并且都為各個行業帶來了可觀的效益,甚至改善了人們的生活水平,隨著大資料的應用越來越廣泛,應用的行業也越來越多,我們每日都可以看到大資料的一些新穎的應用,從而幫助人們從中獲取到真正有用的價值,
4、Hadoop 與大資料
大資料目前分為四大塊:大資料技術、大資料工程、大資料科學和大資料應用,其中云計算是屬于大資料技術的范疇,是一種通過 Internet 以服務的方式提供動態可伸縮的虛擬化的資源的計算模式,它利用由大量計算節點構成的可動態調整的虛擬化計算資源,通過并行化和分布式計算技術,實作業務質量的可控的大資料處理的計算技術,
那么這種計算模式如何實作呢,Hadoop 的來臨解決了這個問題,作為云計算技術中的佼佼者,Hadoop 以其低成本和高效率的特性贏得了市場的認可,下圖顯示了云計算、大資料和 Hadoop 的關系,
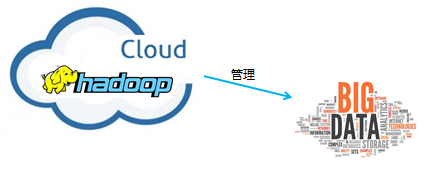
Hadoop 是用一種可靠、高效、可擴展的方式存盤、管理大資料,Hadoop 及其生態圈為管理、挖掘大資料提供了一套成熟可靠的解決方案,從功能上說,Hadooop 可以稱作一個 大資料管理和分析平臺,
Hadoop 是一個開源的大資料分析軟體,或者說編程模式,它是通過分布式的方式處理大資料的,因為開源的原因現在很多企業都在運用 hadoop 的技術來解決一些大資料的問題,在資料倉庫方面 hadoop 是非常強大的,但在資料集市以及實時的分析展現層面上,hadoop 也有著明顯的不足,
5、其他大資料處理平臺
大資料技術正滲透到各行各業,作為資料分布式處理系統的典型代表,Hadoop 已成為該領域的主要核心,但 Hadoop 并不等于大資料,它只是一個成功的分布式系統,用于處理離線資料,大資料領域中還有許多其他型別的處理系統,除了 Hadoop 之外,Storm 和 Apache Spark 也是優秀的大資料處理平臺,下面分別介紹,
(1) Storm,在介紹 Storm 之前,首先介紹一下什么是流式資料,在現實生活中,很多資料都屬于流式資料,即計算的輸入并不是一個檔案,而是源源不斷的資料流,如網上實時交易所產生的資料,用戶需要對這些資料進行分析,否則資料的價值會隨著時間的流逝而消失,Storm 是一個成熟的分布式流計算平臺,擅長流處理或者復雜事件處理,Storm 有以下幾個關鍵特性:
- 使用場景廣泛,
- 具備良好的伸縮性,
- 保證資料無丟失,
- 例外健壯,
- 具備良好的容錯性,
- 支持多語言編程,
需要注意的是,Storm 采用的計算模型不是 MapReduce,同時 MapReduce 也已經被證明不適合做流處理,另外,Storm 運行在 YARN 之上,從這個角度來說,它屬于 Hadoop 組件,
(2) Apache Spark,Apache Spark 是一個基于記憶體計算的開源的集群計算系統,目的是讓資料分析更加快速,Spark 非常小巧玲瓏,由加州伯克利大學 AMP 實驗室的 Matei 為主的小團隊所開發,使用的語言是 Scala,專案核心部分的代碼只有 63 個 Scala 檔案,非常短小精悍,
Spark是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,這些不同之處使 Spark 在負載方面表現得更加優越,換句話說,Spark 啟用了記憶體分布資料集,除了能夠提供互動式查詢外,它還可以優化迭代作業負載,
Spark 還引進了名為彈性分布式資料集(RDD)的抽象,RDD 是分布在一組節點中的只讀物件集合,這些集合是彈性的,如果資料集一部分丟失,則可以對它們進行重建,RDD 的計算速度在特定場景下大幅度領先 MapReduce,Spark 的主要優勢包括以下幾個方面:
- 提供了一套支持 DAG 的分布式并行計算的編程框架,減少多次計算之間中間結果寫到 HDFS 的開銷,
- 提供 Cache 極致來支持需要反復迭代計算或者多次資料共享,減少資料讀取的 I/O 開銷,
- 使用多執行緒池模型來減少任務啟動開銷,減少 Shuffle 程序中不必要的 Sort 操作以及減少磁盤 I/O 操作,
- 廣泛的資料集操作型別,
目前 Spark 的發展勢頭十分迅猛,圍繞 Spark 的生態圈已初具規模,如下圖所示:
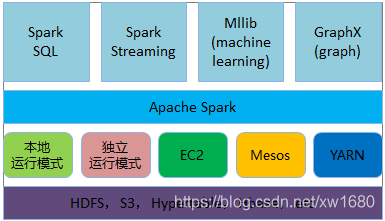
其中 Spark SQL 為支持 SQL 的結構化查詢工具,Spark Streaming 為 Spark 的流計算框架,MLlib 集成了主流機器學習演算法,GraphX 則是 Spark 的圖計算框架,
Spark 具有很強的適應性,能夠讀取 HDFS、S3、HBase 等為持久層讀寫原生資料,能夠以 Mesos、YARN 和自身攜帶的 Standalone 作為資源管理器調度 job,來完成 Spark 應用程式的計算,
與 Hadoop 類似,Spark 支持單節點集群或多節點集群,對于多節點操作,Spark 依賴于 Mesos 集群管理器,Mesos 為分布式應用程式的資源共享和隔離提供了一個有效平臺,該設定允許 Spark 與 Hadoop 共存于節點的一個共享池中,
官方資料介紹 Spark 可以將 Hadoop 集群中的應用在記憶體中的運行速度提升 100 倍,甚至能夠將應用在磁盤上的運行速度提升 10 倍,
6、大資料人才
大資料行業越來越受歡迎,同時對大資料人才的能力和要求也日益增加,大資料都有哪些崗位?學習大資料需要具備哪些能力?下面一一為大家介紹,大資料從業者的崗位包括以下方面:
-
首席資料官,首席資料官(Chief Data Officer,簡稱 CDO)和資料科學家(或稱資料分析師)是企業所需的大資料人才的典型代表,CDO 主要是負責根據企業的業務需求、選擇數據庫以及資料抽取、轉換和分析等工具,進行相關的資料挖掘、資料處理和分析,并且根據資料分析的結果戰略性地對企業未來的業務發展和運營提供相應的建議和意見,通過 CDO 加強資料管控,可提高對業務風險的控制水平,是企業應對經濟、金融危機的重要措施,
一位合格的 CDO 須具備五種能力:統計學、數學的能力;洞悉網路產業和發展趨勢的能力;IT 設備和技術選型的能力;商業運營的能力;管理和溝通的能力,他們不僅要關注系統架構中所承載的內容,更要擔任企業決策和資料分析匯整的樞紐;要熟悉面向服務的架構(SOA)、商業智能(BI)、大規模資料集成系統、資料存盤交換機制,以及資料庫、可擴展標記語言(XML)、電子資料交換(EDI)等系統架構;要深入了解企業的業務狀況和所處的產業背景,清楚地了解組織的資料源、大小和結構等,才可將資料資料與業務狀態聯合起來分析,并提出相對應的市場和產品策略,
-
資料科學家(資料分析師),資料科學家是指能采用科學方法、運用資料挖掘工具對復雜多量的數字、符號、文字、網址、音頻或視頻等資訊進行數字化重現與認識,并能尋找新的資料洞察的工程師或專家,一個優秀的資料科學家需要具備的素質有:資料采集、數學演算法、數學軟體、資料分析、預測分析、市場應用、決策分析等,
資料科學家應當能夠熟練使用統計工具,為了提高作業效率,資料科學家要熟練使用一種或多種分析工具,Excel 是當前最為流行的小規模資料處理工具,SAS 工具也在廣泛應用,而以 Hadoop 為代表的資料管理工具,也越來越廣泛地應用于資料業務中,
-
大資料開發工程師,大資料開發工程師應具備:良好的數學背景、很強的計算機編程能力,除此之外,還應具有特定應用領域或行業的知識,大資料開發工程師這個角色很重要的一點是,不能脫離市場,因為大資料只有和特定領域的應用結合起來才能產生價值,不能只懂資料,還要有商業頭腦,不論對零售、醫藥、游戲還是旅游等行業,都能對其中某些領域有良好的裂解,最好與企業的業務方向一致,
對于一名優秀的大資料開發工程師,除了上面列出三點能力要求外,還有一個非常重要的要求,即必須深入理解大資料系統架構,各個組件的基本原理,實作機制甚至其中涉及的演算法等,只有這樣,他們才能構建一個強大且穩定的分布式集群系統,并充分利用其分布式存盤和并行計算能力來處理大資料,
對大多數企業來說,因為 Hadoop 開源且高效,所以形成了以 Hadoop 為核心的大資料生態系統,那么大資料開發工程師,就必須深入理解以 Hadoop 為核心的大資料生態系統的系統構架,原理及開發應用,并具有充分的優化經驗,才能利用 Hadoop 處理大規模資料,甚至在 Hadoop 平臺上開發特定應用的新組件,當然,大資料開發工程師還需要具有大資料采集、大資料預處理、大資料存盤與管理、分析挖掘與展現應用等大資料相關技術,
-
大資料運維工程師,企業除了大資料分析人才、開發人才外,還需要有資料采集、管理、運維方面的人才,由于大資料系統是一個非常復雜的系統,大資料運維工程師應掌握非常多的內容:熟悉 Java、Python、Shell 等語言;熟悉 Hadoop 作業原理,對 HDFS、MapReduce 運行程序有深入理解,有 MapReduce 開發經驗,熟悉資料倉庫體系構架,熟悉資料建模;熟悉至少一種資料庫,如 MySQL、Oracle、SQL Server,熟練使用 SQL 語言,懂 SQL 調優;熟悉大資料生態圈及其他技術,如 HBase、Storm、Spark、Impala 等技術,
二、什么是 Hadoop
1、Hadoop 簡介
Hadoop 是 Apache 軟體基金會 旗下的一個 開源分布式計算平臺,以分布式檔案系統 HDFS(Hadoop Distributed File System) 和 MapReduce(Google MapReduce 的開源實作) 為核心的 Hadoop,為用戶提供了系統底層透明的分布式基礎構架,
HDFS 的高容錯性、高伸縮性、高性能等優點允許用戶將 Hadoop 部署在廉價的硬體上,形成分布式系統,它負責資料的分布式存盤和備份,檔案寫入后只能讀取,不能修改;MapReduce 分布式編程模型允許用戶在不了解分布式系統底層細節的情況下開發并行應用程式,包括 Map(映射)和 Reduce(規約)兩個程序,
用戶可以利用 Hadoop 輕松地組織計算機資源,從而搭建自己的分布式計算平臺,并且可以充分利用集群的計算和存盤能力,完成海量資料的處理,
簡而言之,Hadoop 是適合大資料的分布式存盤和計算的平臺,狹義上來說,hadoop 就是單獨指代 hadoop 這個軟體;廣義上來說,hadoop 指代大資料的一個生態圈,包括很多其他的軟體,從上面的 Hadoop 介紹可以總結出 Hadoop 具有如下幾個概念,
- Hadoop 是一個框架,
- Hadoop 適合處理大規模資料,
- Hadoop 被部署在一個集群上,
2、Hadoop 的發展歷史
Hadoop 的發展距今不足 20 年,不能算是一個有豐厚底蘊或是新興的技術,但是為大資料做出的貢獻是巨大的,下面介紹 Hadoop 的發展歷史,
(1)Hadoop 的起源
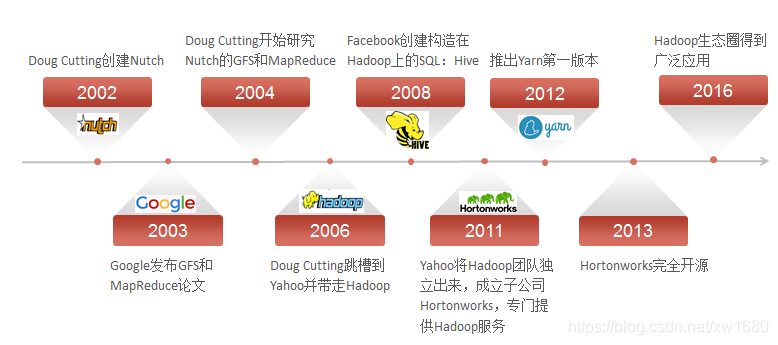
Hadoop 最早起源于 Lucene 的子專案 Nutch,Nutch 的設計目標是構建一個大型的全網搜索引擎,包括網頁抓取、索引、查詢等功能,但隨著抓取網頁數量的增加,遇到了嚴重的可擴展性問題——如何解決數十億網頁的存盤和索引問題,2003年、2004年谷歌發表的三篇論文為該問題提供了可行的解決方案:
1、分布式檔案系統(GFS),可用于處理海量網頁的存盤,
2、分布式計算框架(MapReduce),可用于處理海量網頁的索引計算問題,
3、分布式資料存盤系統(BigTable),用來處理海量的資料的一種非關系型的資料庫,
谷歌雖然沒有將其核心技術開源,但是這三篇論文已經向開源社區的 大牛們 指明了方向,一位大牛:Doug Cutting,使用 Java 語言對 Google 的云計算核心技術(主要是 GFS 和 MapReduce )做了開源的實作,使 Nutch 性能飆升,隨后 Yahoo 招聘 Doug Cutting 繼續完善 Hadoop 專案,2005年,Hadoop 作為 Lucene 的子專案 Nutch 的一部分正式引入 Apache 基金會,2006年2月被分離出來,成為一套完整獨立的軟體,起名為 Hadoop,到2008年1月,Hadoop 成為 Apache 頂級專案(同年,cloudera 公司成立,全球知名企業級資料管理和資料分析平臺提供商),迎來了它的快速發展期,
Hadoop 的成長程序為:Lucene ? Nutch ? Hadoop
Hadoop的核心組件的演變關系:
GFS–>HDFS
Google MapReduce–>Hadoop MapReduce
BigTable–>HBase
(2)Hadoop的發展歷程,Hadoop 的發展歷程如下圖所示:
接下來看一下 Hadoop 的發行版,什么叫發行版呢?舉一個大家接觸比較多的例子,目前手機作業系統有兩大陣營,一個是蘋果的 IOS,還有一個是谷歌的 Android,IOS 是閉源的,也就不存在多個發行版了,如果你基于 IOS 改造一下,弄一個新的手機系統出來,會被蘋果告破產的,所以 IOS 是沒有其它發行版的,只有官方這一個版本,
Android 是開源的,所以基于這個系統,很多手機廠商都會對它進行封裝改造,因為這些手機廠商會感覺原生的 Android 系統的界面看起來比較 low,或者某一些功能不太適合中國人的使用習慣,所以他們就會進行改造,例如國內的魅族、小米、錘子這些手機廠商都基于 Android 打造了自己的手機作業系統,那這些就是 Android 系統的一些發行版,
那針對 Hadoop 也是一樣的,目前 Hadoop 已經演變為大資料的代名詞,形成了一套完善的大資料生態系統,并且 Hadoop 是 Apache 開源的,它的開源協議決定了任何人都可以對其進行修改,并作為開源或者商業版進行發布/銷售,
所以目前 Hadoop 發行版非常的多,有華為發行版、Intel 發行版、Cloudera 發行版 CDH、Hortonworks 發行版 HDP,這些發行版都是基于 Apache Hadoop 衍生出來的,在這里我們挑幾個重點的分析一下:
首先是官方原生版本:Apache Hadoop,Apache 是一個 IT 領域的公益組織,類似于紅十字會,Apache 這個組織里面的軟體都是開源的,大家可以隨便使用,隨便修改,后續博主博文中的學習筆記 99% 的大資料技術框架都是 Apache 開源的,所以在這里我們會學習原生的 Hadoop,只要掌握了原生 Hadoop 使用,后期想要操作其它發行版的 Hadoop 也是很簡單的,其它發行版都是會兼容原生 Hadoop 的,這一點讀者不用擔心, 原生 Hadoop 的缺點是沒有技術支持,遇到問題需要自己解決,或者通過官網的社區提問,但是回復一般比較慢,也不保證能解決問題, 還有一點就是原生 Hadoop 搭建集群的時候比較麻煩,需要修改很多組態檔,如果集群機器過多的話,針對運維人員的壓力是比較大的,這塊等后面讀者自己在搭建集群的時候大家就可以感受到了,
那接著往下面看 Cloudera Hadoop(CDH),注意了,CDH 是一個商業版本,它對官方版本做了一些優化,提供收費技術支持,提供界面操作,方便集群運維管理 CDH 目前在企業中使用的還是比較多的,雖然 CDH 是收費的,但是 CDH 中的一些基本功能是不收費的,可以一直使用,高級功能是需要收費才能使用的,如果不想付費,也能湊合著使用,
還有一個比較常用的是 HortonWorks(HDP),它呢,是開源的,也提供的有界面操作,方便運維管理,一般互聯網公司偏向于使用這個,注意了,再爆一個料,最新訊息,目前 HDP 已經被 CDH 收購,都是屬于一個公司的產品,后期 HDP 是否會合并到 CDH 中,還不得而知,具體還要看這個公司的運營策略了,
最終的建議:建議在實際作業中搭建大資料平臺時選擇 CDH 或者 HDP,方便運維管理,要不然,管理上千臺機器的原生 Hadoop 集群,運維同學是會哭的,注意了,學習程序中我們使用原生 Hadoop,在最后博主會說一下 CDH 和 HDP 的使用,
目前 Hadoop 經歷了三個大的版本

從 1.x 到 2.x 再到 3.x,每一個大版本的升級都帶來了一些質的提升,下面我們先從架構層面分析一下這三大版本的變更:

從 Hadoop1.x 升級到 Hadoop2.x,架構發生了比較大的變化,這里面的 HDFS 是分布式存盤,MapRecue 是分布式計算,咱們前面說了 Hadoop 解決了分布式存盤和分布式計算的問題,對應的就是這兩個模塊,在 Hadoop2.x 的架構中,多了一個模塊 YARN,這個是一個負責資源管理的模塊,那在 Hadoop1.x 中就不需要進行資源管理嗎?也是需要的,只不過是在 Hadoop1.x 中,分布式計算和資源管理都是 MapReduce 負責的,從 Hadoop2.x 開始把資源管理單獨拆分出來了,拆分出來的好處就是,YARN 變成了一個公共的資源管理平臺,在它上面不僅僅可以跑 MapReduce 程式,還可以跑很多其他的程式,只要你的程式滿足 YARN 的規則即可,Hadoop 的這一步棋走的是最好的,這樣自己搖身一變就變成了一個公共的平臺,由于它起步早,占有的市場份額也多,后期其它新興起的計算框架一般都會支持在 YARN 上面運行,這樣 Hadoop 就保證了自己的地位,后面學習筆記中的Spark、Flink 等計算框架都是支持在 YARN 上面執行的,并且在實際作業中也都是在 YARN 上面執行,Hadoop3.x 的架構并沒有發生什么變化,但是它在其他細節方面做了很多優化,在這里我挑幾個常見點說一下:
- 最低 Java 版本要求從 Java7 變為 Java8
- 在 Hadoop 3.x 中,HDFS 支持糾刪碼,糾刪碼是一種比副本存盤更節省存盤空間的資料持久化存盤方法,使用這種方法,相同容錯的情況下可以比之前節省一半的存盤空間,詳細介紹在這里: https://hadoop.apache.org/docs/r3.0.0/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html
- Hadoop 2.x 中的 HDFS 最多支持兩個 NameNode,一主一備,而 Hadoop3.x 中的 HDFS 支持多個 NameNode,一主多備,詳細介紹在這里: https://hadoop.apache.org/docs/r3.0.0/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html
- MapReduce 任務級本地優化,MapReduce 添加了映射輸出收集器的本地化實作的支持,對于密集型的洗牌操作(shuffle-intensive)jobs,可以帶來 30% 的性能提升,詳細介紹在這里: https://issues.apache.org/jira/browse/MAPREDUCE-2841
- 修改了多重服務的默認埠,Hadoop 2.x 中一些服務的埠和 Hadoop3 中是不一樣的
總結: Hadoop 3.x 和 2.x 之間的主要區別在于新版本提供了更好的優化和可用性,詳細的優化點也可以參考官網內容: https://hadoop.apache.org/docs/r3.0.0/index.html
(3)Hadoop 的名字起源,Hadoop 名字不是一個縮寫的單詞,而是一個人為造出來的詞,是以 Hadoop 之父 Doug Cutting 兒子的毛絨玩具象命名的,所以 Hadoop 的標志為一頭小象,如下圖所示:

所以我們需要不斷努力地學習,等以后我們也達到這種高度的時候,在實作一個框架的時候用自己的名字來命名那就很炫酷了,
3、Hadoop 的特點
Hadoop 是一個能夠讓用戶輕松架構和使用的分布式計算平臺,用戶可以輕松地在 Hadoop 上開發和運行處理海量資料的應用程式,它主要有以下幾個優點:
- 高可靠性,資料存盤不僅有多個備份,而且集群設定在不同機器上,可以防止一個節點宕機而造成的機器損壞,
- 高擴展性,Hadoop 是在可用的計算機集群間分配資料并完成計算任務,為集群添加新的節點并不復雜,所以集群可以很容易進行節點的擴展,擴大集群,
- 高效性,Hadoop 能夠在節點之間動態地移動資料,在資料所在節點進行并發處理,并保證各個節點的動態平衡,因此處理速度非常快,
- 高容錯性,Hadoop 的分布式檔案系統 HDFS 在存盤檔案時會在多個節點或多臺機器上存盤檔案的備份副本,當讀取該檔案出錯或某一臺機器宕機了,系統會呼叫其他節點上的備份檔案,保存程式順利運行,如果啟動的任務失敗,Hadoop 會重新運行該任務或啟用其他任務來完成這個任務沒有完成的部分,
- 低成本,Hadoop 是開源的,不需要支付任何費用即可下載安裝使用,節省了購買軟體的成本,此外,Hadoop 依賴于社區服務,因此它的成本比較低,任何人都可以使用,
- 可構建在廉價機器上,Hadoop 對機器的配置要求不高,大部分普通商用服務器就可以滿足要求,
三、Hadoop 核心
在上面介紹過,以 Hadoop 為中心形成了一個生態圈,如下圖所示:
1、分布式檔案系統——HDFS
1、HDFS 架構及簡介
HDFS(Hadoop Distributed File System)是 Hadoop 專案的核心子專案,主要負責集群資料的存盤與讀取,HDFS 是一個主/從(Master/Slave) 體系結構的分布式檔案系統,HDFS 支持傳統的層次型檔案組織結構,用戶或者應用程式可以創建目錄,然后將檔案保存在這些目錄中,檔案系統名字空間的層次結構和大多數現有的檔案系統類似,可以通過檔案路徑對檔案執行創建、讀取、更新和洗掉操作,但是由于分布式存盤的性質,它又和傳統的檔案系統有明顯的區別,HDFS 的基本架構如下圖所示:
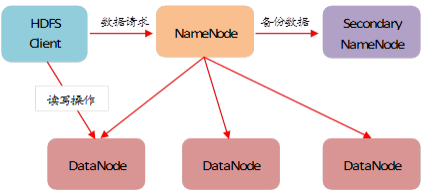
HDFS 檔案系統主要包括一個 NameNode、一個 Secondary NameNode 和多個 DataNode,其中 NameNode、Secondary NameNode 運行在 Master 節點,DataNode 運行在 Slave 節點上,下面分別介紹,
- 元資料,元資料不是具體的檔案內容,它有三類重要資訊:第一類是檔案和目錄自身的屬性資訊,例如檔案名、目錄名、父目錄資訊、檔案大小、創建時間和修改時間等;第二類記錄檔案內容存盤的相關資訊,例如檔案分塊情況、副本個數、每個副本所在的DataNode資訊等;第三類用來記錄HDFS中所有DataNode的資訊,用于DataNode管理,
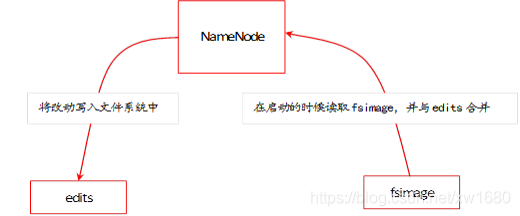
- NameNode,NameNode 用于存盤元資料以及處理客戶端發出的請求,在 NameNode 中存放元資料的檔案是 fsimage 檔案,在系統運行期間,所有對元資料的操作都保存在記憶體中,并被持久化到另一個檔案 edits 中,當 NameNode 啟動的時候,fsimage 會被加載到記憶體,然后對記憶體里的資料執行 edits 所記錄的操作,以確保記憶體所保留的資料處于最新的狀態,fsimage與edits資料保存的程序如下圖所示:
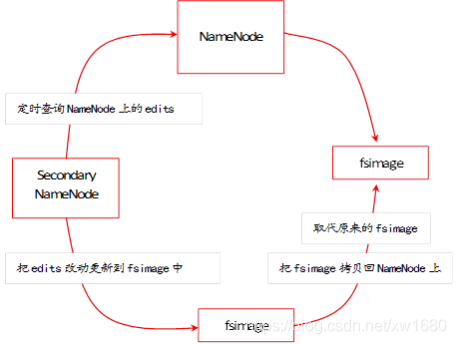
- Secondary NameNode,Secondary NameNode 用于備份 NameNode 的資料,周期性將 edits 檔案合并到 fsimage 檔案并在本地備份,將新的 fsimage 檔案存盤到 NameNode,取代原來的 fsimage,洗掉 edits 檔案,創建一個新的 edits 繼續存盤檔案修改狀態,Secondary NameNode 的作業程序如下圖所示:
- DataNode,DataNode 是真正存盤資料的地方,在 DataNode 中,檔案以資料塊的形式進行存盤,當檔案傳到 HDFS 端時以 128MB 的資料塊將檔案進行切割,將每個資料塊存到不同的或相同的 DataNode 并且備份副本,一般默認 3 個,NameNode 會負責記錄檔案的分塊資訊,確保在讀取該檔案時可以找到并整合所有塊,
- 資料塊,檔案在上傳到 HDFS 時根據系統默認檔案塊大小把檔案分成一個個資料塊,Hadoop 2.x 開始默認 128MB 為一個資料塊,比如要存盤大小為 129MB 的檔案時,則被分成兩個資料塊來存盤,資料塊會被存盤到各個節點,每個資料塊都會備份副本,
2、HDFS分布式原理
分布式系統會劃分成多個子系統或模塊,各自運行在不同的機器上,子系統或模塊之間通過網路通信進行協作,實作最終的整體功能,利用多個節點共同協作完成一項或多項具體業務功能的系統就是分布式系統,
那什么是分布式檔案系統呢?分布式檔案系統是分布式系統的一個子集,其解決的問題就是資料存盤,也就是說,分布式檔案系統是橫跨在多臺計算機上的存盤系統,存盤在分布式檔案系統上的資料自動分布在不同的節點上,
而 HDFS 作為一個分布式檔案系統,主要體現在以下三個方面,
HDFS 并不是單機檔案系統,它是分布在多個集群節點上的檔案系統,節點之間通過網路通信進行協作,提供多個節點的檔案資訊,讓每個用戶都可以看到檔案系統的檔案,讓多機器上的多用戶分享檔案和存盤空間,
檔案存盤時被分布在多個節點上,需注意資料存盤不是以檔案為單位進行存盤的,而是將一個檔案分成一個或多個資料塊存盤,而資料塊在存盤時并不是都存盤在一個節點上,而是被分布存盤在各個節點中,并且資料塊會在其他節點存盤副本,
資料從多個節點讀取,讀取一個檔案時,從多個節點中找到該檔案的資料塊,分布讀取所有資料塊,直到最后一個資料塊讀取完畢,
3、HDFS特點
首先介紹 HDFS 的優點,
- 高容錯性,HDFS上傳的資料自動保存多個副本,可以通過增加副本的資料來增加它的容錯性,如果某一個副本丟失,HDFS 會復制其他機器上的副本,而我們不必關注它的實作,
- 適合大資料的處理,HDFS 能夠處理 GB、TB 甚至 PB 級別的資料,規模達百萬,數量非常大,(1PB=1024TB、1TB=1014GB)
- 流式資料訪問,HDFS 以流式資料訪問模式來存盤超大檔案,一次寫入,多次讀取,即檔案一旦寫入,則不能修改,只能增加,這樣可以保持資料的一致性,
除此之外,HDFS 有以下的缺點,
- 不適合低延遲資料訪問,如果要處理一些用戶要求時間比較短的低延遲應用請求,則 HDFS 不適合,因為 HDFS 是為了處理大型資料集分析任務而設計的,目的是為達到高的資料吞吐量,但這是以高延遲作為代價來換取的,
- 無法高效存盤大量小檔案,因為 NameNode 會把檔案系統的元資料放置在記憶體中,所以檔案系統所能容納的檔案數目是由 NameNode 的記憶體大小來決定的,即每存入一個檔案都會在 NameNode 中寫入檔案資訊,如果寫入大多小檔案的話,NameNode 記憶體會被占滿而無法寫入檔案資訊,而與多個小檔案大小相同的單一檔案只會寫入一次檔案資訊到記憶體中,所以更適合大檔案存盤,
- 不支持多用戶寫入及任意修改檔案,在 HDFS 的一個檔案中只有一個寫入者,而且寫操作只能在檔案末尾完成,即只能執行追加操作,目前 HDFS 還不支持多個用戶對同一檔案的寫操作,以及在檔案任意位置進行修改,
2、分布式計算框架——MapReduce
(1)MapReduce 簡介
MapReduce 是 Hadoop 核心計算框架,適用于大規模資料集(大于1TB)并行運算的編程模型,包括 Map(映射)和 Reduce(規約) 兩部分,
當啟動一個 MapReduce 任務時,Map 端會讀取 HDFS 上的資料,將資料映射成所需要的鍵值對型別并傳到 Reduce 端,Reduce 端接收 Map 端傳過來的鍵值對型別的資料,根據不同鍵進行分組,對每一組鍵相同的資料進行處理,得到新的鍵值對并輸出到 HDFS,這就是 MapReduce 的核心思想,
(2)MapReduce作業原理
MapReduce 作業執行流程如下圖所示:
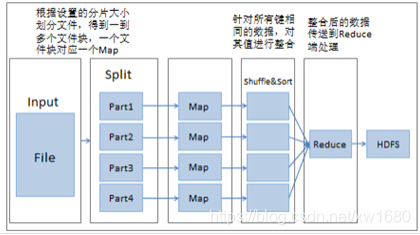
一個完整的 MapReduce 程序包含資料的輸入與分片、Map 階段資料處理、Reduce 階段資料處理、資料輸出等階段,下面分別介紹,
-
讀取輸入資料,MapReduce 程序中的資料是從 HDFS 分布式檔案系統中讀取的,檔案在上傳到 HDFS 時,一般按照 128MB 分成了幾個資料塊,所以在運行 MapReduce 程式時,每個資料塊都會生成一個 Map,但是也可以通過重新設定檔案分片大小調整 Map 的個數,在運行 MapReduce 時會根據所設定的分片大小對檔案重新分割(Split),一個分片大小的資料塊就會對應一個Map,
-
Map 階段,程式有一個或多個 Map,由默認存盤或分片個數決定,針對 Map 階段,資料以鍵值對的形式讀入,鍵的值一般為每行首字符與檔案最初始位置的偏移量,即中間所隔字符個數,值為這一行的資料記錄,根據需求對鍵值對進行處理,映射成新的鍵值對,將新的鍵值對傳到 Reduce 端,
-
Shuffle/Sort 階段:此階段是指從 Map 輸出開始,傳送 Map 輸出到 Reduce 作為輸入的程序,該程序會將同一個 Map 中輸出的鍵相同的資料先進行一步整合,減少傳輸的資料量,并且在整合后將資料按照鍵排序,
-
Reduce 階段:Reduce 任務也可以有多個,按照 Map 階段設定的資料磁區確定,一個磁區資料被一個 Reduce 處理,針對每一個 Reduce 任務,Reduce 會接收到不同 Map 任務傳來的資料,并且每個 Map 傳來的資料都是有序的,一個 Reduce 任務中的每一次處理都是針對所有鍵相同的資料,對資料進行規約,以新的鍵值對輸出到 HDFS,
根據上述內容分析,MapReduce 的本質可以用一張圖完整地表現出來,如下圖所示:
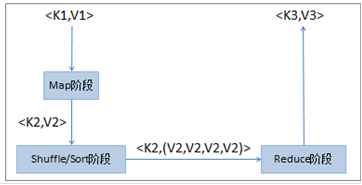
MapReduce 的本質就是把一組鍵值對 <K1,V1> 經過 Map 階段映射成新的鍵值對 <K2,V2>,接著經過 Shuffle/Sort 階段進行排序和 洗牌,把鍵值對排序,同時把相同的鍵值整合,最后經過 Reduce 階段,把整合后的鍵值對組進行邏輯處理,輸出新的鍵值對 <K3,V3>,
3、集群資源管理器——YARN
(1)YARN 簡介
Hadoop 的 MapReduce 架構稱為 YARN(Yet Another Resource Negotiator,另一種資源協調者),是效率更高的資源管理核心,
(2)YARN 的基本構架
YARN 主要包含三大模塊:Resource Manager(RM)、Node Manager(NM)、Application Master(AM),其中,Resource Manager 負責所有資源的監控、分配和管理;Application Master 負責每一個具體應用程式的調度和協調;Node Manager 負責每一個節點的維護,對于所有的 applications,RM 擁有絕對的控制權和對資源的分配權,而每個 AM 則會和 RM 協商資源,同時和 Node Manager 通信來執行和監控 task,YARN 的框架圖如下圖所示:
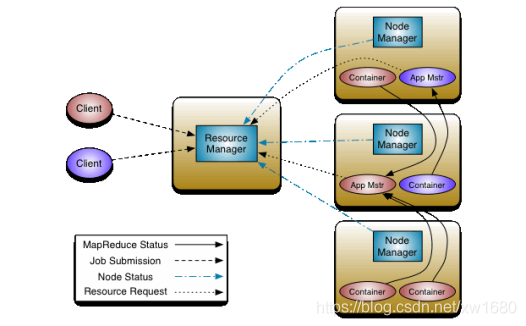
從上圖中可以看出:
- 在 Client 客戶端,用戶會向 Resource Manager 請求執行運算(或執行任務),
- 在 NameNode 會有 Resource Manager 統籌管理運算的請求,
- 在其他的 DataNode 會有 Node Manager 負責運行,以及監督每一個任務(task),并且向 Resource Manager 匯報狀態,
四、Hadoop 常用組件
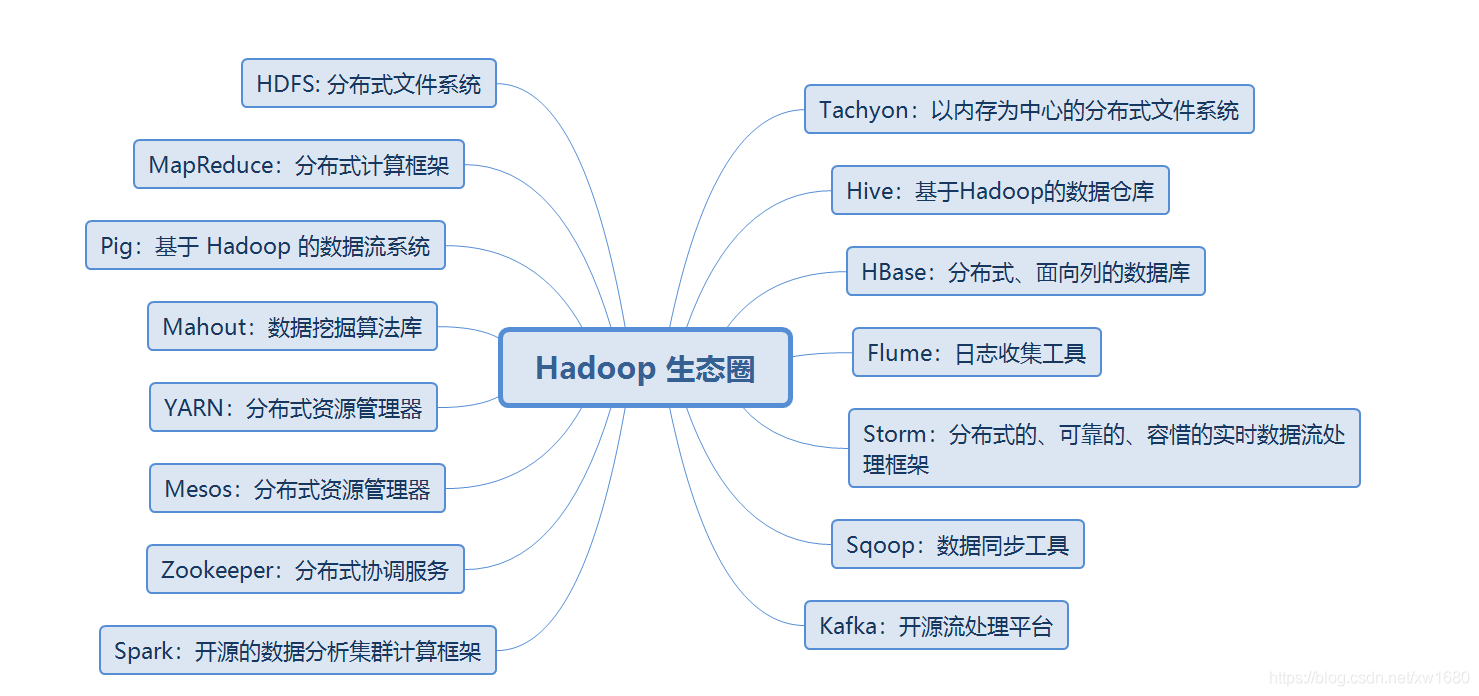
除了上面介紹的 Hadoop 三大核心組件之外,Hadoop 生態圈中還有許多組件,這些組件各有特點,共同為 Hadoop 的相關工程服務,由于大部分組建的 LOGO 選用了動物圖形,因此 Hadoop 的生態系統就像是一群動物在狂歡,如下圖所示:
下面介紹 Hadoop 的常用組件,為了方便理解以下按照功能進行了分類,并且把較為流行的排在了前面介紹,如下表所示:

五、Hadoop 在國內外的應用情況
Hadoop 是一個開源的高效云計算基礎架構平臺,其不僅僅在云計算領域用途廣泛,還可以支撐搜索引擎服務,作為搜索引擎底層的基礎架構系統,同時在海量資料處理、資料挖掘、機器學習、科學計算等領域都越來越受到青睞,
在國外,Hadoop 的應用十分廣泛,例如 Yahoo、Facebook、Adobe、IBM等等,例如,Yahoo 是 Hadoop 的最大支持者,Yahoo 的 Hadoop 應用主要包括:廣告分析系統、用戶行為分析、Web 搜索、反垃圾郵件系統等,Facebook 使用 Hadoop 存盤內部日志與多維資料,并以此作為報告、分析和機器學習的資料源,Adobe 主要使用 Hadoop 及 HBase,用于支撐社會服務計算,以及結構化的資料存盤和處理,
而國內,互聯網公司是 Hadoop 在國內的主要使用力量,有以下公司:阿里巴巴、百度、騰訊、網易、金山、華為、中國移動等,阿里巴巴、騰訊都是國內最先使用 Hadoop 的公司,
中科研究所舉辦過幾次 Hadoop 技術大會,加速了 Hadoop 在國內的發展,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272632.html
標籤:其他
上一篇:從零開始搭建自己的大資料環境