一、佇列
① 佇列實作原始碼分析
- 在原始碼中搜索 dispatch_queue_create 關鍵字,可以在 queue.c 中發現:
dispatch_queue_t
dispatch_queue_create(const char *label, dispatch_queue_attr_t attr)
{
return _dispatch_lane_create_with_target(label, attr,
DISPATCH_TARGET_QUEUE_DEFAULT, true);
}
- 進入 _dispatch_lane_create_with_target 中:
DISPATCH_NOINLINE
static dispatch_queue_t
_dispatch_lane_create_with_target(const char *label, dispatch_queue_attr_t dqa,
dispatch_queue_t tq, bool legacy)
{
// 創建 dqai
dispatch_queue_attr_info_t dqai = _dispatch_queue_attr_to_info(dqa);
// 規范化引數,例如qos, overcommit, tq 和 Initialize the queue
...
// 拼接佇列名稱
const void *vtable;
dispatch_queue_flags_t dqf = legacy ? DQF_MUTABLE : 0;
if (dqai.dqai_concurrent) { // vtable表示類的型別
// OS_dispatch_queue_concurrent
vtable = DISPATCH_VTABLE(queue_concurrent);
} else {
vtable = DISPATCH_VTABLE(queue_serial);
}
....
// 創建佇列,并初始化
dispatch_lane_t dq = _dispatch_object_alloc(vtable,
sizeof(struct dispatch_lane_s)); // alloc
// 根據dqai.dqai_concurrent的值,就能判斷佇列 是 串行 還是并發
_dispatch_queue_init(dq, dqf, dqai.dqai_concurrent ?
DISPATCH_QUEUE_WIDTH_MAX : 1, DISPATCH_QUEUE_ROLE_INNER |
(dqai.dqai_inactive ? DISPATCH_QUEUE_INACTIVE : 0)); // init
// 設定佇列label識別符號
dq->dq_label = label;// label賦值
dq->dq_priority = _dispatch_priority_make((dispatch_qos_t)dqai.dqai_qos, dqai.dqai_relpri);// 優先級處理
...
// 類似于類與元類的系結,不是直接的繼承關系,而是類似于模型與模板的關系
dq->do_targetq = tq;
_dispatch_object_debug(dq, "%s", __func__);
return _dispatch_trace_queue_create(dq)._dq; // 研究dq
}
- 通過 _dispatch_queue_attr_to_info 方法傳入 dqa(即佇列型別,串行、并發等)創建 dispatch_queue_attr_info_t 型別的物件 dqai,用于存盤佇列的相關屬性資訊:
dispatch_queue_attr_info_t
_dispatch_queue_attr_to_info(dispatch_queue_attr_t dqa)
{
dispatch_queue_attr_info_t dqai = { };
if (!dqa) return dqai;
#if DISPATCH_VARIANT_STATIC
if (dqa == &_dispatch_queue_attr_concurrent) {
dqai.dqai_concurrent = true;
return dqai;
}
#endif
if (dqa < _dispatch_queue_attrs ||
dqa >= &_dispatch_queue_attrs[DISPATCH_QUEUE_ATTR_COUNT]) {
DISPATCH_CLIENT_CRASH(dqa->do_vtable, "Invalid queue attribute");
}
size_t idx = (size_t)(dqa - _dispatch_queue_attrs);
dqai.dqai_inactive = (idx % DISPATCH_QUEUE_ATTR_INACTIVE_COUNT);
idx /= DISPATCH_QUEUE_ATTR_INACTIVE_COUNT;
dqai.dqai_concurrent = !(idx % DISPATCH_QUEUE_ATTR_CONCURRENCY_COUNT);
idx /= DISPATCH_QUEUE_ATTR_CONCURRENCY_COUNT;
dqai.dqai_relpri = -(int)(idx % DISPATCH_QUEUE_ATTR_PRIO_COUNT);
idx /= DISPATCH_QUEUE_ATTR_PRIO_COUNT;
dqai.dqai_qos = idx % DISPATCH_QUEUE_ATTR_QOS_COUNT;
idx /= DISPATCH_QUEUE_ATTR_QOS_COUNT;
dqai.dqai_autorelease_frequency =
idx % DISPATCH_QUEUE_ATTR_AUTORELEASE_FREQUENCY_COUNT;
idx /= DISPATCH_QUEUE_ATTR_AUTORELEASE_FREQUENCY_COUNT;
dqai.dqai_overcommit = idx % DISPATCH_QUEUE_ATTR_OVERCOMMIT_COUNT;
idx /= DISPATCH_QUEUE_ATTR_OVERCOMMIT_COUNT;
return dqai;
}
- 設定佇列相關聯的屬性,qos, overcommit, tq 和 Initialize the queue 的實作如下:
//
// Step 1: Normalize arguments (qos, overcommit, tq)
//
dispatch_qos_t qos = dqai.dqai_qos;
#if !HAVE_PTHREAD_WORKQUEUE_QOS
if (qos == DISPATCH_QOS_USER_INTERACTIVE) {
dqai.dqai_qos = qos = DISPATCH_QOS_USER_INITIATED;
}
if (qos == DISPATCH_QOS_MAINTENANCE) {
dqai.dqai_qos = qos = DISPATCH_QOS_BACKGROUND;
}
#endif // !HAVE_PTHREAD_WORKQUEUE_QOS
_dispatch_queue_attr_overcommit_t overcommit = dqai.dqai_overcommit;
if (overcommit != _dispatch_queue_attr_overcommit_unspecified && tq) {
if (tq->do_targetq) {
DISPATCH_CLIENT_CRASH(tq, "Cannot specify both overcommit and "
"a non-global target queue");
}
}
if (tq && dx_type(tq) == DISPATCH_QUEUE_GLOBAL_ROOT_TYPE) {
// Handle discrepancies between attr and target queue, attributes win
if (overcommit == _dispatch_queue_attr_overcommit_unspecified) {
if (tq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT) {
overcommit = _dispatch_queue_attr_overcommit_enabled;
} else {
overcommit = _dispatch_queue_attr_overcommit_disabled;
}
}
if (qos == DISPATCH_QOS_UNSPECIFIED) {
qos = _dispatch_priority_qos(tq->dq_priority);
}
tq = NULL;
} else if (tq && !tq->do_targetq) {
// target is a pthread or runloop root queue, setting QoS or overcommit
// is disallowed
if (overcommit != _dispatch_queue_attr_overcommit_unspecified) {
DISPATCH_CLIENT_CRASH(tq, "Cannot specify an overcommit attribute "
"and use this kind of target queue");
}
} else {
if (overcommit == _dispatch_queue_attr_overcommit_unspecified) {
// Serial queues default to overcommit!
overcommit = dqai.dqai_concurrent ?
_dispatch_queue_attr_overcommit_disabled :
_dispatch_queue_attr_overcommit_enabled;
}
}
if (!tq) {
tq = _dispatch_get_root_queue(
qos == DISPATCH_QOS_UNSPECIFIED ? DISPATCH_QOS_DEFAULT : qos,
overcommit == _dispatch_queue_attr_overcommit_enabled)->_as_dq;
if (unlikely(!tq)) {
DISPATCH_CLIENT_CRASH(qos, "Invalid queue attribute");
}
}
//
// Step 2: Initialize the queue
//
if (legacy) {
// if any of these attributes is specified, use non legacy classes
if (dqai.dqai_inactive || dqai.dqai_autorelease_frequency) {
legacy = false;
}
}
- 通過 DISPATCH_VTABLE 拼接佇列名稱,即 vtable,其中 DISPATCH_VTABLE 是宏定義,佇列的型別是通過 OS_dispatch + 佇列型別 queue_concurrent 拼接而成的;
-
- 創建以下佇列DISPATCH_QUEUE_SERIA、DISPATCH_QUEUE_CONCURRENT、dispatch_get_main_queue、dispatch_get_global_queue:
// OS_dispatch_queue_serial
dispatch_queue_t serial = dispatch_queue_create("YDW", DISPATCH_QUEUE_SERIAL);
// OS_dispatch_queue_concurrent
// OS_dispatch_queue_concurrent
dispatch_queue_t conque = dispatch_queue_create("YDW", DISPATCH_QUEUE_CONCURRENT);
// DISPATCH_QUEUE_SERIAL max && 1
// queue 物件 alloc init class
dispatch_queue_t mainQueue = dispatch_get_main_queue();
// 多個集合
dispatch_queue_t globQueue = dispatch_get_global_queue(0, 0);
NSLog(@"%@-%@-%@-%@", serial, conque, mainQueue, globQueue);
-
- 串行佇列型別:OS_dispatch_queue_serial,除錯結果如下:
(lldb) po object_getClass(serial)
OS_dispatch_queue_serial
-
- 并發佇列型別:OS_dispatch_queue_concurrent,除錯結果如下:
(lldb) po object_getClass(conque)
OS_dispatch_queue_concurrent
-
- DISPATCH 的定義如下:
#define DISPATCH_VTABLE(name) DISPATCH_OBJC_CLASS(name)
#define DISPATCH_OBJC_CLASS(name) (&DISPATCH_CLASS_SYMBOL(name))
#define DISPATCH_CLASS(name) OS_dispatch_##name
- 通過 alloc+init 初始化佇列,即 dq,其中在 _dispatch_queue_init 傳參中根據dqai.dqai_concurrent 的布林值,就能判斷佇列是串行還是并發,我們知道 vtable 表示的是佇列型別,因此也可以說明佇列也是物件;
-
- 進入 _dispatch_object_alloc -> _os_object_alloc_realized 方法中,可以看到設定了 isa 的指向,這里也可以驗證佇列也是物件:
inline _os_object_t
_os_object_alloc_realized(const void *cls, size_t size)
{
_os_object_t obj;
dispatch_assert(size >= sizeof(struct _os_object_s));
while (unlikely(!(obj = calloc(1u, size)))) {
_dispatch_temporary_resource_shortage();
}
// 設定 isa 指向
obj->os_obj_isa = cls;
return obj;
}
- 進入 _dispatch_queue_init 方法,佇列型別是 dispatch_queue_t,并設定佇列的相關屬性:
// Note to later developers: ensure that any initialization changes are
// made for statically allocated queues (i.e. _dispatch_main_q).
static inline dispatch_queue_class_t
_dispatch_queue_init(dispatch_queue_class_t dqu, dispatch_queue_flags_t dqf,
uint16_t width, uint64_t initial_state_bits)
{
uint64_t dq_state = DISPATCH_QUEUE_STATE_INIT_VALUE(width);
dispatch_queue_t dq = dqu._dq;
dispatch_assert((initial_state_bits & ~(DISPATCH_QUEUE_ROLE_MASK |
DISPATCH_QUEUE_INACTIVE)) == 0);
if (initial_state_bits & DISPATCH_QUEUE_INACTIVE) {
dq->do_ref_cnt += 2; // rdar://8181908 see _dispatch_lane_resume
if (dx_metatype(dq) == _DISPATCH_SOURCE_TYPE) {
dq->do_ref_cnt++; // released when DSF_DELETED is set
}
}
dq_state |= initial_state_bits;
dq->do_next = DISPATCH_OBJECT_LISTLESS;
// 串行還是并發
dqf |= DQF_WIDTH(width);
os_atomic_store2o(dq, dq_atomic_flags, dqf, relaxed);
dq->dq_state = dq_state;
dq->dq_serialnum =
os_atomic_inc_orig(&_dispatch_queue_serial_numbers, relaxed);
return dqu;
}
- 通過 _dispatch_trace_queue_create 對創建的佇列進行處理,其中_dispatch_trace_queue_create 是 _dispatch_introspection_queue_create 封裝的宏定義,最后會回傳處理過的_dq;
dispatch_queue_class_t
_dispatch_introspection_queue_create(dispatch_queue_t dq)
{
dispatch_queue_introspection_context_t dqic;
size_t sz = sizeof(struct dispatch_queue_introspection_context_s);
if (!_dispatch_introspection.debug_queue_inversions) {
sz = offsetof(struct dispatch_queue_introspection_context_s,
__dqic_no_queue_inversion);
}
dqic = _dispatch_calloc(1, sz);
dqic->dqic_queue._dq = dq;
if (_dispatch_introspection.debug_queue_inversions) {
LIST_INIT(&dqic->dqic_order_top_head);
LIST_INIT(&dqic->dqic_order_bottom_head);
}
dq->do_finalizer = dqic;
_dispatch_unfair_lock_lock(&_dispatch_introspection.queues_lock);
LIST_INSERT_HEAD(&_dispatch_introspection.queues, dqic, dqic_list);
_dispatch_unfair_lock_unlock(&_dispatch_introspection.queues_lock);
DISPATCH_INTROSPECTION_INTERPOSABLE_HOOK_CALLOUT(queue_create, dq);
if (DISPATCH_INTROSPECTION_HOOK_ENABLED(queue_create)) {
_dispatch_introspection_queue_create_hook(dq);
}
return upcast(dq)._dqu;
}
- 進入 _dispatch_introspection_queue_create_hook -> dispatch_introspection_queue_get_info -> _dispatch_introspection_lane_get_info 中可以看出,與我們自定義的類還是有區別的,創建佇列在底層的實作是通過模板創建的:
DISPATCH_ALWAYS_INLINE
static inline dispatch_introspection_queue_s
_dispatch_introspection_lane_get_info(dispatch_lane_class_t dqu)
{
dispatch_lane_t dq = dqu._dl;
bool global = _dispatch_object_is_global(dq);
uint64_t dq_state = os_atomic_load2o(dq, dq_state, relaxed);
dispatch_introspection_queue_s diq = {
.queue = dq->_as_dq,
.target_queue = dq->do_targetq,
.label = dq->dq_label,
.serialnum = dq->dq_serialnum,
.width = dq->dq_width,
.suspend_count = _dq_state_suspend_cnt(dq_state) + dq->dq_side_suspend_cnt,
.enqueued = _dq_state_is_enqueued(dq_state) && !global,
.barrier = _dq_state_is_in_barrier(dq_state) && !global,
.draining = (dq->dq_items_head == (void*)~0ul) ||
(!dq->dq_items_head && dq->dq_items_tail),
.global = global,
.main = dx_type(dq) == DISPATCH_QUEUE_MAIN_TYPE,
};
return diq;
}
② 佇列實作流程總結
- 佇列創建方法 dispatch_queue_create 中的引數二(即佇列型別),決定了下層中 max & 1(用于區分是串行還是并發),其中1表示串行;
- queue 也是一個物件,也需要底層通過 alloc + init 創建,并且在 alloc 中也有一個class,這個 class 是通過宏定義拼接而成,并且同時會指定 isa 的指向;
- 創建佇列在底層的處理是通過模板創建的,其型別是 dispatch_introspection_queue_s 結構體,
③ 佇列實作流程示意圖
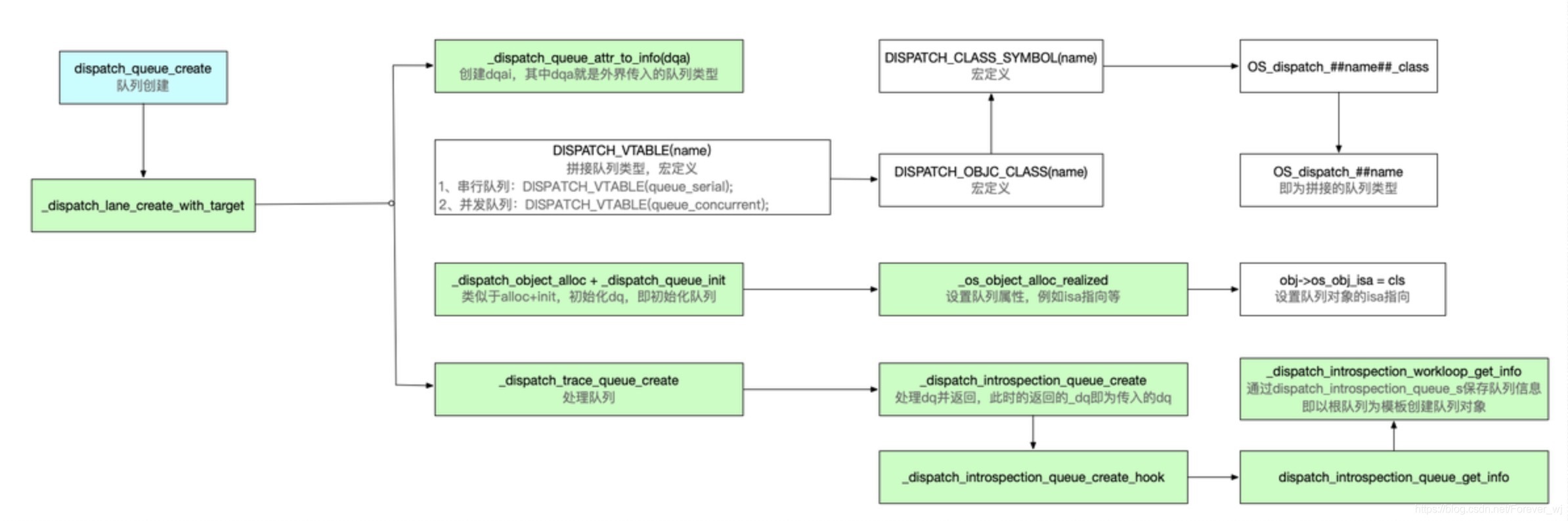
二、函式
① 異步函式
- 進入 dispatch_async 的原始碼實作,主要有兩個函式:_dispatch_continuation_init 任務包裝函式,_dispatch_continuation_async 并發處理函式,如下所示:
#ifdef __BLOCKS__
void
dispatch_async(dispatch_queue_t dq, dispatch_block_t work)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME;
dispatch_qos_t qos;
qos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);
_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);
}
#endif
- 進入 _dispatch_continuation_init 原始碼實作,可以看到,主要業務是包裝任務,并設定執行緒的回程函式,相當于初始化:
DISPATCH_ALWAYS_INLINE
static inline dispatch_qos_t
_dispatch_continuation_init(dispatch_continuation_t dc,
dispatch_queue_class_t dqu, dispatch_block_t work,
dispatch_block_flags_t flags, uintptr_t dc_flags)
{
// 拷貝任務
void *ctxt = _dispatch_Block_copy(work);
dc_flags |= DC_FLAG_BLOCK | DC_FLAG_ALLOCATED;
if (unlikely(_dispatch_block_has_private_data(work))) {
dc->dc_flags = dc_flags;
// 賦值
dc->dc_ctxt = ctxt;
// will initialize all fields but requires dc_flags & dc_ctxt to be set
return _dispatch_continuation_init_slow(dc, dqu, flags);
}
// 封裝work - 異步回呼
dispatch_function_t func = _dispatch_Block_invoke(work);
if (dc_flags & DC_FLAG_CONSUME) {
// 回呼函式賦值 - 同步回呼
func = _dispatch_call_block_and_release;
}
return _dispatch_continuation_init_f(dc, dqu, ctxt, func, flags, dc_flags);
}
- 分析說明:
-
- 通過 _dispatch_Block_copy 拷貝任務;
-
- 通過 _dispatch_Block_invoke 封裝任務,其中 _dispatch_Block_invoke 是個宏定義,根據以上分析得知是異步回呼:
#define _dispatch_Block_invoke(bb) \
((dispatch_function_t)((struct Block_layout *)bb)->invoke)
-
- 如果是同步的,則回呼函式賦值為 _dispatch_call_block_and_release;
-
- 通過 _dispatch_continuation_init_f 方法將回呼函式賦值,即 f 就是 func,將其保存在屬性中:
DISPATCH_ALWAYS_INLINE
static inline dispatch_qos_t
_dispatch_continuation_init_f(dispatch_continuation_t dc,
dispatch_queue_class_t dqu, void *ctxt, dispatch_function_t f,
dispatch_block_flags_t flags, uintptr_t dc_flags)
{
pthread_priority_t pp = 0;
dc->dc_flags = dc_flags | DC_FLAG_ALLOCATED;
dc->dc_func = f;
dc->dc_ctxt = ctxt;
// in this context DISPATCH_BLOCK_HAS_PRIORITY means that the priority
// should not be propagated, only taken from the handler if it has one
if (!(flags & DISPATCH_BLOCK_HAS_PRIORITY)) {
pp = _dispatch_priority_propagate();
}
_dispatch_continuation_voucher_set(dc, flags);
return _dispatch_continuation_priority_set(dc, dqu, pp, flags);
}
- 進入 _dispatch_continuation_async 的原始碼實作,如下所示:
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_async(dispatch_queue_class_t dqu,
dispatch_continuation_t dc, dispatch_qos_t qos, uintptr_t dc_flags)
{
#if DISPATCH_INTROSPECTION
if (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {
_dispatch_trace_item_push(dqu, dc); // 跟蹤日志
}
#else
(void)dc_flags;
#endif
return dx_push(dqu._dq, dc, qos); // 與dx_invoke一樣,都是宏
}
-
- 其中,最主要的是 dx_push(dqu._dq, dc, qos),dx_push 是宏定義,如下所示:
#define dx_push(x, y, z) dx_vtable(x)->dq_push(x, y, z)
-
- dq_push 需要根據佇列的型別,執行不同的函式:
DISPATCH_VTABLE_INSTANCE(workloop,
.do_type = DISPATCH_WORKLOOP_TYPE,
.do_dispose = _dispatch_workloop_dispose,
.do_debug = _dispatch_queue_debug,
.do_invoke = _dispatch_workloop_invoke,
.dq_activate = _dispatch_queue_no_activate,
.dq_wakeup = _dispatch_workloop_wakeup,
.dq_push = _dispatch_workloop_push,
);
DISPATCH_VTABLE_SUBCLASS_INSTANCE(queue_serial, lane,
.do_type = DISPATCH_QUEUE_SERIAL_TYPE,
.do_dispose = _dispatch_lane_dispose,
.do_debug = _dispatch_queue_debug,
.do_invoke = _dispatch_lane_invoke,
.dq_activate = _dispatch_lane_activate,
.dq_wakeup = _dispatch_lane_wakeup,
.dq_push = _dispatch_lane_push,
);
DISPATCH_VTABLE_SUBCLASS_INSTANCE(queue_concurrent, lane,
.do_type = DISPATCH_QUEUE_CONCURRENT_TYPE,
.do_dispose = _dispatch_lane_dispose,
.do_debug = _dispatch_queue_debug,
.do_invoke = _dispatch_lane_invoke,
.dq_activate = _dispatch_lane_activate,
.dq_wakeup = _dispatch_lane_wakeup,
.dq_push = _dispatch_lane_concurrent_push,
);
DISPATCH_VTABLE_SUBCLASS_INSTANCE(queue_global, lane,
.do_type = DISPATCH_QUEUE_GLOBAL_ROOT_TYPE,
.do_dispose = _dispatch_object_no_dispose,
.do_debug = _dispatch_queue_debug,
.do_invoke = _dispatch_object_no_invoke,
.dq_activate = _dispatch_queue_no_activate,
.dq_wakeup = _dispatch_root_queue_wakeup,
.dq_push = _dispatch_root_queue_push,
);
#if DISPATCH_USE_PTHREAD_ROOT_QUEUES
DISPATCH_VTABLE_SUBCLASS_INSTANCE(queue_pthread_root, lane,
.do_type = DISPATCH_QUEUE_PTHREAD_ROOT_TYPE,
.do_dispose = _dispatch_pthread_root_queue_dispose,
.do_debug = _dispatch_queue_debug,
.do_invoke = _dispatch_object_no_invoke,
.dq_activate = _dispatch_queue_no_activate,
.dq_wakeup = _dispatch_root_queue_wakeup,
.dq_push = _dispatch_root_queue_push,
);
#endif // DISPATCH_USE_PTHREAD_ROOT_QUEUES
DISPATCH_VTABLE_SUBCLASS_INSTANCE(queue_mgr, lane,
.do_type = DISPATCH_QUEUE_MGR_TYPE,
.do_dispose = _dispatch_object_no_dispose,
.do_debug = _dispatch_queue_debug,
#if DISPATCH_USE_MGR_THREAD
.do_invoke = _dispatch_mgr_thread,
#else
.do_invoke = _dispatch_object_no_invoke,
#endif
.dq_activate = _dispatch_queue_no_activate,
.dq_wakeup = _dispatch_mgr_queue_wakeup,
.dq_push = _dispatch_mgr_queue_push,
);
DISPATCH_VTABLE_SUBCLASS_INSTANCE(queue_main, lane,
.do_type = DISPATCH_QUEUE_MAIN_TYPE,
.do_dispose = _dispatch_lane_dispose,
.do_debug = _dispatch_queue_debug,
.do_invoke = _dispatch_lane_invoke,
.dq_activate = _dispatch_queue_no_activate,
.dq_wakeup = _dispatch_main_queue_wakeup,
.dq_push = _dispatch_main_queue_push,
);
#if DISPATCH_COCOA_COMPAT
DISPATCH_VTABLE_SUBCLASS_INSTANCE(queue_runloop, lane,
.do_type = DISPATCH_QUEUE_RUNLOOP_TYPE,
.do_dispose = _dispatch_runloop_queue_dispose,
.do_debug = _dispatch_queue_debug,
.do_invoke = _dispatch_lane_invoke,
.dq_activate = _dispatch_queue_no_activate,
.dq_wakeup = _dispatch_runloop_queue_wakeup,
.dq_push = _dispatch_lane_push,
);
#endif
DISPATCH_VTABLE_INSTANCE(source,
.do_type = DISPATCH_SOURCE_KEVENT_TYPE,
.do_dispose = _dispatch_source_dispose,
.do_debug = _dispatch_source_debug,
.do_invoke = _dispatch_source_invoke,
.dq_activate = _dispatch_source_activate,
.dq_wakeup = _dispatch_source_wakeup,
.dq_push = _dispatch_lane_push,
);
DISPATCH_VTABLE_INSTANCE(channel,
.do_type = DISPATCH_CHANNEL_TYPE,
.do_dispose = _dispatch_channel_dispose,
.do_debug = _dispatch_channel_debug,
.do_invoke = _dispatch_channel_invoke,
.dq_activate = _dispatch_lane_activate,
.dq_wakeup = _dispatch_channel_wakeup,
.dq_push = _dispatch_lane_push,
);
#if HAVE_MACH
DISPATCH_VTABLE_INSTANCE(mach,
.do_type = DISPATCH_MACH_CHANNEL_TYPE,
.do_dispose = _dispatch_mach_dispose,
.do_debug = _dispatch_mach_debug,
.do_invoke = _dispatch_mach_invoke,
.dq_activate = _dispatch_mach_activate,
.dq_wakeup = _dispatch_mach_wakeup,
.dq_push = _dispatch_lane_push,
);
#endif // HAVE_MACH
- 除錯執行函式
-
- 由于是并發佇列,可以通過增加 _dispatch_lane_concurrent_push 符號斷點,看看是否會執行:
dispatch_queue_t conque = dispatch_queue_create("com.YDW.Queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(conque, ^{
NSLog(@"異步函式");
});
- 運行可以看到,確實執行了 _dispatch_lane_concurrent_push;
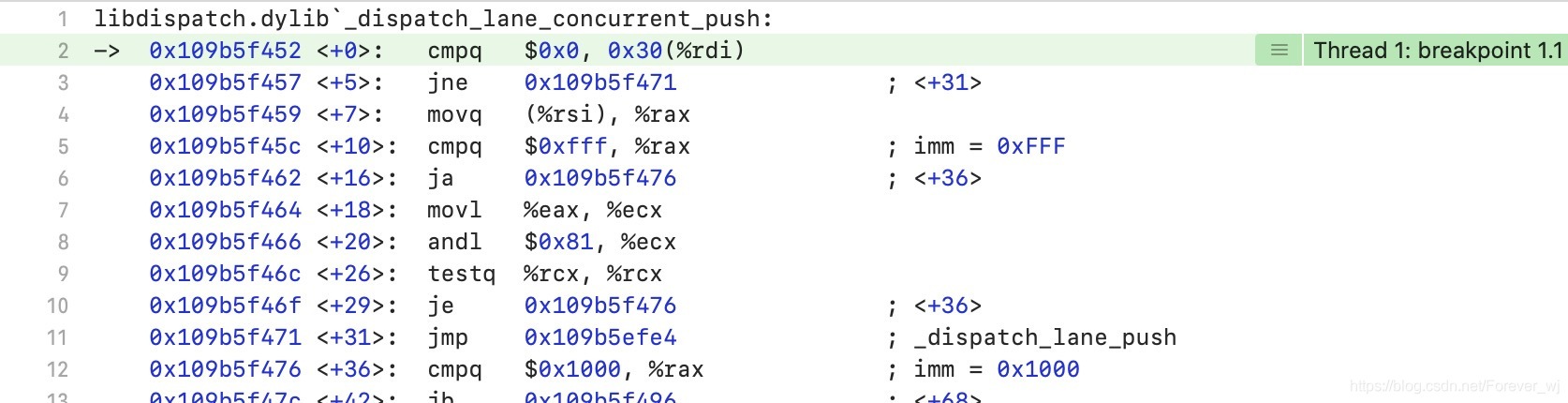
- 我們進入 _dispatch_lane_concurrent_push 原始碼,可以發現有兩步,繼續通過符號斷點 _dispatch_continuation_redirect_push 和 _dispatch_lane_push 除錯,可以看到 執行了 _dispatch_continuation_redirect_push;
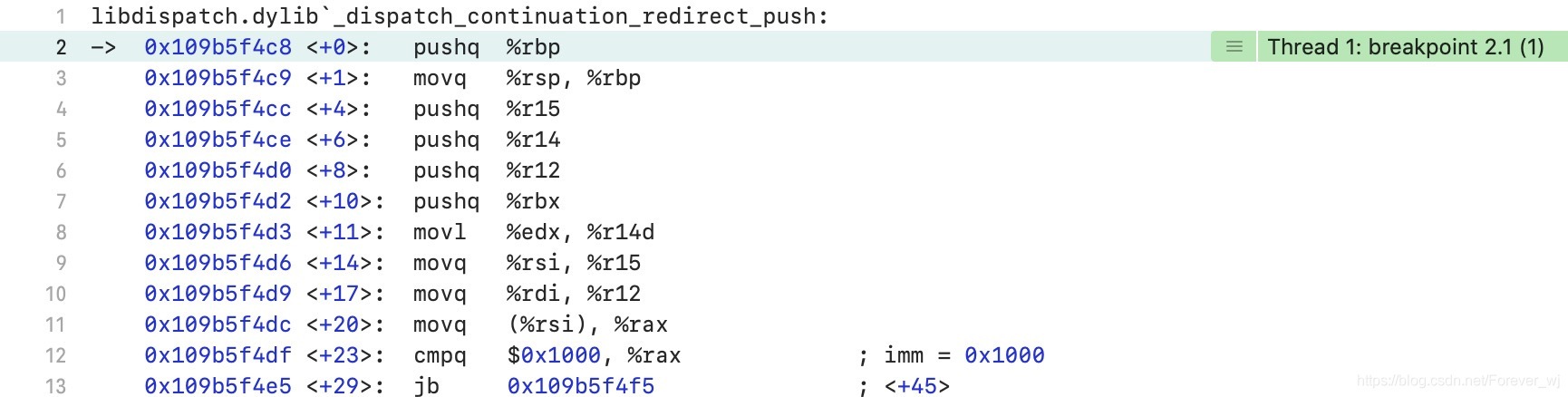
- 繼續進入 _dispatch_continuation_redirect_push 原始碼,繼續執行了 dx_push,即產生了“遞回”,綜合前面佇列創建時可知,佇列也是一個物件,有父類、根類,所以會遞回執行到根類的方法:
DISPATCH_NOINLINE
static void
_dispatch_continuation_redirect_push(dispatch_lane_t dl,
dispatch_object_t dou, dispatch_qos_t qos)
{
if (likely(!_dispatch_object_is_redirection(dou))) {
dou._dc = _dispatch_async_redirect_wrap(dl, dou);
} else if (!dou._dc->dc_ctxt) {
// find first queue in descending target queue order that has
// an autorelease frequency set, and use that as the frequency for
// this continuation.
dou._dc->dc_ctxt = (void *)
(uintptr_t)_dispatch_queue_autorelease_frequency(dl);
}
dispatch_queue_t dq = dl->do_targetq;
if (!qos) qos = _dispatch_priority_qos(dq->dq_priority);
// 遞回
dx_push(dq, dou, qos);
}
- 接下來,通過根類的 _dispatch_root_queue_push 符號斷點,來驗證猜想是否正確,從運行結果看出,猜想完全正確,
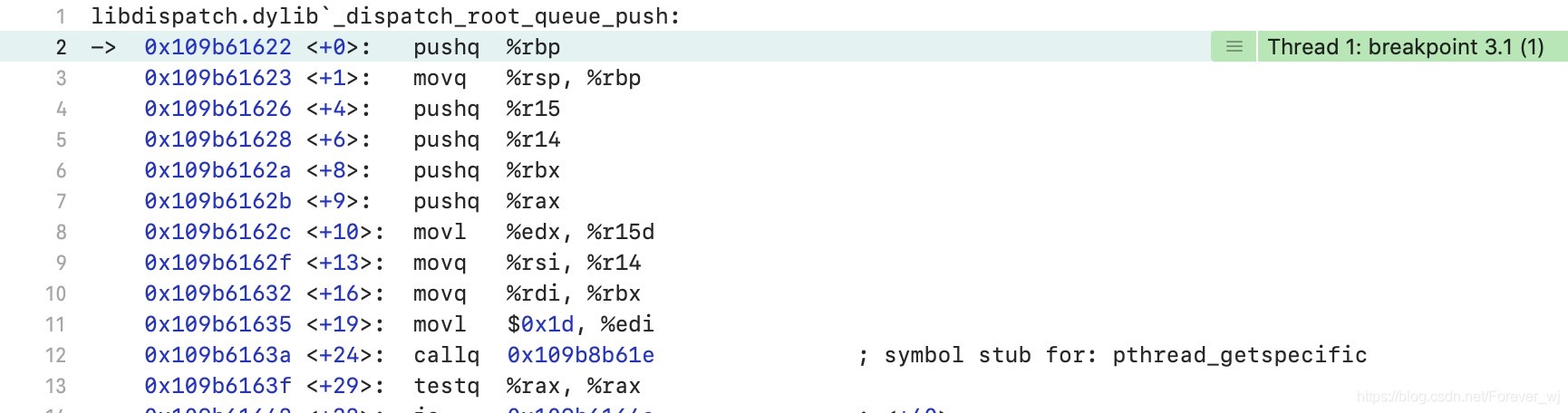
- 繼續進入 _dispatch_root_queue_push -> _dispatch_root_queue_push_inline ->_dispatch_root_queue_poke -> _dispatch_root_queue_poke_slow 原始碼,符號斷點繼續可以驗證,查看該方法的原始碼實作,主要有兩步:
-
- 通過 _dispatch_root_queues_init 方法注冊回呼;
-
- 通過 do-while 回圈創建執行緒,使用 pthread_create 方法;
DISPATCH_NOINLINE
static void
_dispatch_root_queue_poke_slow(dispatch_queue_global_t dq, int n, int floor)
{
int remaining = n;
int r = ENOSYS;
_dispatch_root_queues_init();
...
// do-while回圈創建執行緒
do {
_dispatch_retain(dq); // released in _dispatch_worker_thread
while ((r = pthread_create(pthr, attr, _dispatch_worker_thread, dq))) {
if (r != EAGAIN) {
(void)dispatch_assume_zero(r);
}
_dispatch_temporary_resource_shortage();
}
} while (--remaining);
...
}
- 進入 _dispatch_root_queues_init 原始碼實作,發現它是一個 dispatch_once_f 單例,其中傳入的 func 是 _dispatch_root_queues_init_once:
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_root_queues_init(void)
{
dispatch_once_f(&_dispatch_root_queues_pred, NULL, _dispatch_root_queues_init_once);
}
- 進入 _dispatch_root_queues_init_once 的原始碼,其內部不同事務的呼叫句柄都是_dispatch_worker_thread2:
#pragma clang diagnostic push
#pragma clang diagnostic ignored "-Wunreachable-code"
if (unlikely(!_dispatch_kevent_workqueue_enabled)) {
#if DISPATCH_USE_KEVENT_SETUP
cfg.workq_cb = _dispatch_worker_thread2;
r = pthread_workqueue_setup(&cfg, sizeof(cfg));
#else
r = _pthread_workqueue_init(_dispatch_worker_thread2,
offsetof(struct dispatch_queue_s, dq_serialnum), 0);
#endif // DISPATCH_USE_KEVENT_SETUP
#if DISPATCH_USE_KEVENT_WORKLOOP
} else if (wq_supported & WORKQ_FEATURE_WORKLOOP) {
#if DISPATCH_USE_KEVENT_SETUP
cfg.workq_cb = _dispatch_worker_thread2;
cfg.kevent_cb = (pthread_workqueue_function_kevent_t) _dispatch_kevent_worker_thread;
cfg.workloop_cb = (pthread_workqueue_function_workloop_t) _dispatch_workloop_worker_thread;
r = pthread_workqueue_setup(&cfg, sizeof(cfg));
#else
r = _pthread_workqueue_init_with_workloop(_dispatch_worker_thread2,
(pthread_workqueue_function_kevent_t)
_dispatch_kevent_worker_thread,
(pthread_workqueue_function_workloop_t)
_dispatch_workloop_worker_thread,
offsetof(struct dispatch_queue_s, dq_serialnum), 0);
#endif // DISPATCH_USE_KEVENT_SETUP
#endif // DISPATCH_USE_KEVENT_WORKLOOP
#if DISPATCH_USE_KEVENT_WORKQUEUE
} else if (wq_supported & WORKQ_FEATURE_KEVENT) {
#if DISPATCH_USE_KEVENT_SETUP
cfg.workq_cb = _dispatch_worker_thread2;
cfg.kevent_cb = (pthread_workqueue_function_kevent_t) _dispatch_kevent_worker_thread;
r = pthread_workqueue_setup(&cfg, sizeof(cfg));
#else
r = _pthread_workqueue_init_with_kevent(_dispatch_worker_thread2,
(pthread_workqueue_function_kevent_t)
_dispatch_kevent_worker_thread,
offsetof(struct dispatch_queue_s, dq_serialnum), 0);
#endif // DISPATCH_USE_KEVENT_SETUP
#endif
} else {
DISPATCH_INTERNAL_CRASH(wq_supported, "Missing Kevent WORKQ support");
}
#pragma clang diagnostic pop
if (r != 0) {
DISPATCH_INTERNAL_CRASH((r << 16) | wq_supported,
"Root queue initialization failed");
}
#endif // DISPATCH_USE_INTERNAL_WORKQUEUE
}
- 其block回呼執行的流程為:_dispatch_root_queues_init_once ->_dispatch_worker_thread2 -> _dispatch_root_queue_drain -> _dispatch_root_queue_drain -> _dispatch_continuation_pop_inline -> _dispatch_continuation_invoke_inline -> _dispatch_client_callout -> dispatch_call_block_and_release,通過 bt 列印堆疊資訊,如下:
(lldb) bt
* thread #3, queue = 'com.YDW.Queue', stop reason = breakpoint 1.1
* frame #0: 0x00000001073d6367 函式與佇列`__29-[ViewController viewDidLoad]_block_invoke(.block_descriptor=0x00000001073d9108) at ViewController.m:23:9
frame #1: 0x00000001076477ec libdispatch.dylib`_dispatch_call_block_and_release + 12
frame #2: 0x00000001076489c8 libdispatch.dylib`_dispatch_client_callout + 8
frame #3: 0x000000010764b316 libdispatch.dylib`_dispatch_continuation_pop + 557
frame #4: 0x000000010764a71c libdispatch.dylib`_dispatch_async_redirect_invoke + 779
frame #5: 0x000000010765a508 libdispatch.dylib`_dispatch_root_queue_drain + 351
frame #6: 0x000000010765ae6d libdispatch.dylib`_dispatch_worker_thread2 + 135
frame #7: 0x00007fff611639f7 libsystem_pthread.dylib`_pthread_wqthread + 220
frame #8: 0x00007fff61162b77 libsystem_pthread.dylib`start_wqthread + 15
(lldb)
- 特別說明:單例的 block 回呼和異步函式的 block 回呼是不同的:
- 單例中,block 回呼中的 func 是 _dispatch_Block_invoke(block);
- 而異步函式中,block 回呼中的 func 是 dispatch_call_block_and_release,
- 綜上所述,異步函式的底層實作:將異步任務拷貝并封裝,并設定回呼函式 func,再通過 dx_push 遞回,會重定向到根佇列,然后通過 pthread_creat 創建執行緒,最后通過 dx_invoke 執行 block 回呼(注意 dx_push 和 dx_invoke 是成對的),

② 同步函式
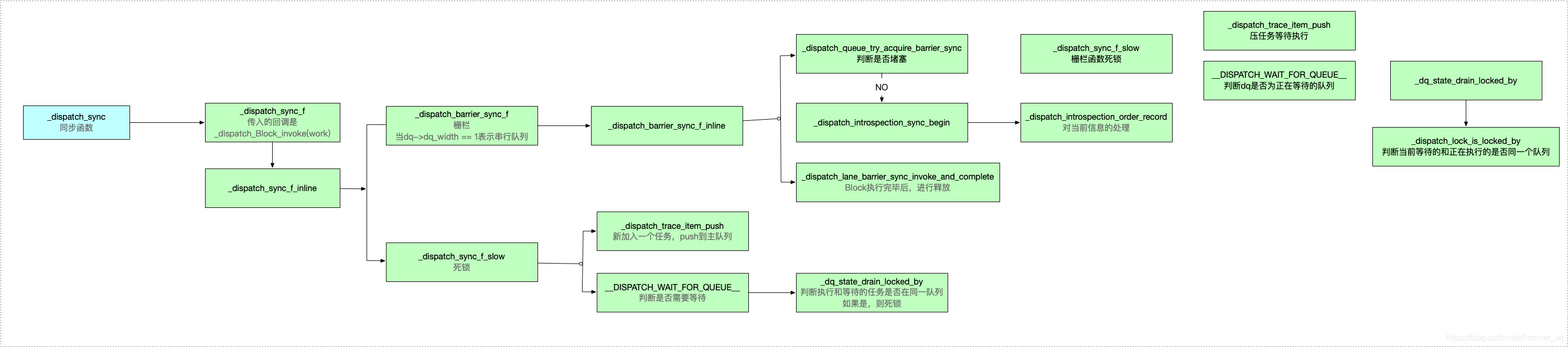
- 進入 dispatch_sync 原始碼實作,其底層的實作是通過柵欄函式實作的:
DISPATCH_NOINLINE
void
dispatch_sync(dispatch_queue_t dq, dispatch_block_t work)
{
uintptr_t dc_flags = DC_FLAG_BLOCK;
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_sync_block_with_privdata(dq, work, dc_flags);
}
_dispatch_sync_f(dq, work, _dispatch_Block_invoke(work), dc_flags);
}
- 進入 _dispatch_sync_f 原始碼:
DISPATCH_NOINLINE
static void
_dispatch_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func,
uintptr_t dc_flags)
{
_dispatch_sync_f_inline(dq, ctxt, func, dc_flags);
}
- 查看 _dispatch_sync_f_inline 原始碼,其中 width = 1 表示是串行佇列;
- 柵欄:_dispatch_barrier_sync_f,可以得出同步函式的底層實作其實是同步柵欄函式;
- 死鎖:_dispatch_sync_f_slow,如果存在相互等待的情況,就會造成死鎖,
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
if (likely(dq->dq_width == 1)) {// 表示是串行佇列
return _dispatch_barrier_sync_f(dq, ctxt, func, dc_flags);//柵欄
}
if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {
DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");
}
dispatch_lane_t dl = upcast(dq)._dl;
// Global concurrent queues and queues bound to non-dispatch threads
// always fall into the slow case, see DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE
if (unlikely(!_dispatch_queue_try_reserve_sync_width(dl))) {
return _dispatch_sync_f_slow(dl, ctxt, func, 0, dl, dc_flags);//死鎖
}
if (unlikely(dq->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func, dc_flags);
}
_dispatch_introspection_sync_begin(dl); // 處理當前資訊
_dispatch_sync_invoke_and_complete(dl, ctxt, func DISPATCH_TRACE_ARG(
_dispatch_trace_item_sync_push_pop(dq, ctxt, func, dc_flags))); // block執行并釋放
}
- 進入 _dispatch_sync_f_slow,當前的主佇列是掛起阻塞:
DISPATCH_NOINLINE
static void
_dispatch_sync_f_slow(dispatch_queue_class_t top_dqu, void *ctxt,
dispatch_function_t func, uintptr_t top_dc_flags,
dispatch_queue_class_t dqu, uintptr_t dc_flags)
{
dispatch_queue_t top_dq = top_dqu._dq;
dispatch_queue_t dq = dqu._dq;
if (unlikely(!dq->do_targetq)) {
return _dispatch_sync_function_invoke(dq, ctxt, func);
}
pthread_priority_t pp = _dispatch_get_priority();
struct dispatch_sync_context_s dsc = {
.dc_flags = DC_FLAG_SYNC_WAITER | dc_flags,
.dc_func = _dispatch_async_and_wait_invoke,
.dc_ctxt = &dsc,
.dc_other = top_dq,
.dc_priority = pp | _PTHREAD_PRIORITY_ENFORCE_FLAG,
.dc_voucher = _voucher_get(),
.dsc_func = func,
.dsc_ctxt = ctxt,
.dsc_waiter = _dispatch_tid_self(),
};
_dispatch_trace_item_push(top_dq, &dsc);
__DISPATCH_WAIT_FOR_QUEUE__(&dsc, dq);
if (dsc.dsc_func == NULL) {
dispatch_queue_t stop_dq = dsc.dc_other;
return _dispatch_sync_complete_recurse(top_dq, stop_dq, top_dc_flags);
}
_dispatch_introspection_sync_begin(top_dq);
_dispatch_trace_item_pop(top_dq, &dsc);
_dispatch_sync_invoke_and_complete_recurse(top_dq, ctxt, func,top_dc_flags
DISPATCH_TRACE_ARG(&dsc));
}
- 往一個佇列中加入任務,會 push 加入主佇列,進入 _dispatch_trace_item_push:
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_trace_item_push(dispatch_queue_class_t dqu, dispatch_object_t _tail)
{
if (unlikely(DISPATCH_QUEUE_PUSH_ENABLED())) {
_dispatch_trace_continuation(dqu._dq, _tail._do, DISPATCH_QUEUE_PUSH);
}
_dispatch_trace_item_push_inline(dqu._dq, _tail._do);
_dispatch_introspection_queue_push(dqu, _tail);
}
- 進入__DISPATCH_WAIT_FOR_QUEUE__,判斷dq是否為正在等待的佇列,然后給出一個狀態state,然后將dq的狀態和當前任務依賴的佇列進行匹配:
DISPATCH_NOINLINE
static void
__DISPATCH_WAIT_FOR_QUEUE__(dispatch_sync_context_t dsc, dispatch_queue_t dq)
{
// 判斷dq是否為正在等待的佇列
uint64_t dq_state = _dispatch_wait_prepare(dq);
if (unlikely(_dq_state_drain_locked_by(dq_state, dsc->dsc_waiter))) {
DISPATCH_CLIENT_CRASH((uintptr_t)dq_state,
"dispatch_sync called on queue "
"already owned by current thread");
}
// Blocks submitted to the main thread MUST run on the main thread, and
// dispatch_async_and_wait also executes on the remote context rather than
// the current thread.
//
// For both these cases we need to save the frame linkage for the sake of
// _dispatch_async_and_wait_invoke
_dispatch_thread_frame_save_state(&dsc->dsc_dtf);
if (_dq_state_is_suspended(dq_state) ||
_dq_state_is_base_anon(dq_state)) {
dsc->dc_data = DISPATCH_WLH_ANON;
} else if (_dq_state_is_base_wlh(dq_state)) {
dsc->dc_data = (dispatch_wlh_t)dq;
} else {
_dispatch_wait_compute_wlh(upcast(dq)._dl, dsc);
}
if (dsc->dc_data == DISPATCH_WLH_ANON) {
dsc->dsc_override_qos_floor = dsc->dsc_override_qos =
(uint8_t)_dispatch_get_basepri_override_qos_floor();
_dispatch_thread_event_init(&dsc->dsc_event);
}
dx_push(dq, dsc, _dispatch_qos_from_pp(dsc->dc_priority));
_dispatch_trace_runtime_event(sync_wait, dq, 0);
if (dsc->dc_data == DISPATCH_WLH_ANON) {
_dispatch_thread_event_wait(&dsc->dsc_event); // acquire
} else {
_dispatch_event_loop_wait_for_ownership(dsc);
}
if (dsc->dc_data == DISPATCH_WLH_ANON) {
_dispatch_thread_event_destroy(&dsc->dsc_event);
// If _dispatch_sync_waiter_wake() gave this thread an override,
// ensure that the root queue sees it.
if (dsc->dsc_override_qos > dsc->dsc_override_qos_floor) {
_dispatch_set_basepri_override_qos(dsc->dsc_override_qos);
}
}
}
- 繼續進入 _dq_state_drain_locked_by -> _dispatch_lock_is_locked_by 原始碼,如果當前等待的和正在執行的是同一個佇列,即判斷執行緒ID是否相等,如果相等,則會造成死鎖,如下:
DISPATCH_ALWAYS_INLINE
static inline bool
_dispatch_lock_is_locked_by(dispatch_lock lock_value, dispatch_tid tid)
{
// equivalent to _dispatch_lock_owner(lock_value) == tid
// 異或操作:相同為0,不同為1,如果相同,則為0,0 &任何數都為0
// 即判斷 當前要等待的任務 和 正在執行的任務是否一樣,通俗的意思就是執行和等待的是否在同一佇列
return ((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0;
}
- 綜上所述,同步函式的底層實作實際是同步柵欄函式;同步函式中如果當前正在執行的佇列和等待的是同一個佇列,形成相互等待的局面,則會造成死鎖,
- 同步函式的底層實作流程如下:
三、單例
① 單例的使用
- 在日常開發中,我們一般使用 GCD 的 dispatch_once 來創建單例,如下所示:
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
NSLog(@"這是一個單例!!");
});
- 那么,單例的流程只執行一次,底層是如何控制的,為什么只能執行一次?單例的 block 是在什么時候進行呼叫的?
② 原始碼分析
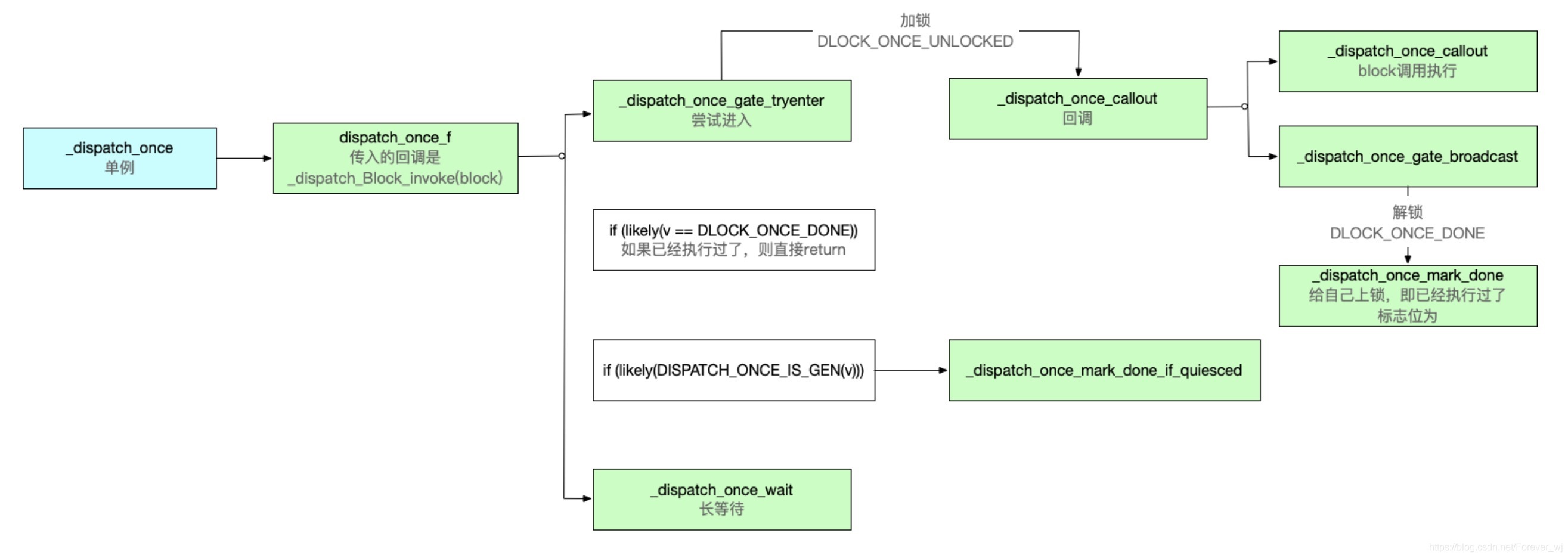
- 進入 dispatch_once 原始碼,可以看到一個 dispatch_once_f 方法實作:
#ifdef __BLOCKS__
void
// 引數1:onceToken,它是一個靜態變數,由于不同位置定義的靜態變數是不同的,所以靜態變數具有唯一性
// 引數2:block回呼
dispatch_once(dispatch_once_t *val, dispatch_block_t block)
{
dispatch_once_f(val, block, _dispatch_Block_invoke(block));
}
#endif
- 繼續進入 dispatch_once_f 原始碼,其中的 val 是外界傳入的 onceToken 靜態變數,而 func 是 _dispatch_Block_invoke(block),其底層實作如下所示:
DISPATCH_NOINLINE
void
dispatch_once_f(dispatch_once_t *val, void *ctxt, dispatch_function_t func)
{
dispatch_once_gate_t l = (dispatch_once_gate_t)val;
#if !DISPATCH_ONCE_INLINE_FASTPATH || DISPATCH_ONCE_USE_QUIESCENT_COUNTER
uintptr_t v = os_atomic_load(&l->dgo_once, acquire);//load
if (likely(v == DLOCK_ONCE_DONE)) { // 已經執行過了,直接回傳
return;
}
#if DISPATCH_ONCE_USE_QUIESCENT_COUNTER
if (likely(DISPATCH_ONCE_IS_GEN(v))) {
return _dispatch_once_mark_done_if_quiesced(l, v);
}
#endif
#endif
if (_dispatch_once_gate_tryenter(l)) { // 嘗試進入
return _dispatch_once_callout(l, ctxt, func);
}
return _dispatch_once_wait(l); // 無限次等待
}
- dispatch_once_f 實作原始碼,分析如下:
- 將val,也即為靜態變數轉換為 dispatch_once_gate_t 型別的變數 l;
- 通過 os_atomic_load 獲取此時的任務的識別符號 v;
- 如果 v 等于 DLOCK_ONCE_DONE,表示任務已經被執行,直接 return;
- 如果任務執行,加鎖失敗,則執行 _dispatch_once_mark_done_if_quiesced 函式,再次進行存盤,將識別符號置為 DLOCK_ONCE_DONE;
- 否則,則通過 _dispatch_once_gate_tryenter 嘗試進入任務,即解鎖,然后執行 _dispatch_once_callout 執行 block 回呼;
- 如果此時有任務正在執行,再次進來一個任務2,則通過 _dispatch_once_wait 函式讓任務2進入無限次等待,
- 進入 _dispatch_once_gate_tryenter 解鎖方法實作,可以看到它是通過 os_atomic_cmpxchg 方法進行對比,如果比較沒有問題,則進行加鎖,即任務的識別符號置為 DLOCK_ONCE_UNLOCKED:
DISPATCH_ALWAYS_INLINE
static inline bool
_dispatch_once_gate_tryenter(dispatch_once_gate_t l)
{
// 首先對比,然后進行改變
return os_atomic_cmpxchg(&l->dgo_once, DLOCK_ONCE_UNLOCKED,
(uintptr_t)_dispatch_lock_value_for_self(), relaxed);
}
- 進入 _dispatch_once_callout 回呼,它主要通過 _dispatch_client_callout:block 回呼執行,以及 _dispatch_once_gate_broadcast:進行廣播:
DISPATCH_NOINLINE
static void
_dispatch_once_callout(dispatch_once_gate_t l, void *ctxt,
dispatch_function_t func)
{
// block呼叫執行
_dispatch_client_callout(ctxt, func);
// 進行廣播:告訴別人已有歸屬,不要再找尋
_dispatch_once_gate_broadcast(l);
}
- 進入 _dispatch_client_callout 原始碼,主要就是執行 block 回呼,其中的 f 等于 _dispatch_Block_invoke(block),即異步回呼:
#undef _dispatch_client_callout
void
_dispatch_client_callout(void *ctxt, dispatch_function_t f)
{
@try {
return f(ctxt);
}
@catch (...) {
objc_terminate();
}
}
- 進入 _dispatch_once_gate_broadcast -> _dispatch_once_mark_done 原始碼,它主要就是給 dgo->dgo_once 賦一個值,然后將任務的識別符號為DLOCK_ONCE_DONE,即解鎖;
DISPATCH_ALWAYS_INLINE
static inline uintptr_t
_dispatch_once_mark_done(dispatch_once_gate_t dgo)
{
// 如果不相同,直接改為相同,然后上鎖 -- DLOCK_ONCE_DONE
return os_atomic_xchg(&dgo->dgo_once, DLOCK_ONCE_DONE, release);
}
- 看完單例的底層原始碼實作,我們就可以解釋上面的問題:
-
- 單例只執行一次的原理:GCD 單例中,有兩個重要引數,onceToken 和 block,其中 onceToken 是靜態變數,具有唯一性,在底層被封裝成了 dispatch_once_gate_t 型別的變數 l,l 主要是用來獲取底層原子封裝性的關聯,即變數 v,通過 v 來查詢任務的狀態,如果此時 v 等于 DLOCK_ONCE_DONE,說明任務已經處理過一次了,則不會再繼續執行,直接 return;
-
- block 呼叫時機:如果此時任務沒有執行過,則會在底層通過 C++ 函式的比較,將任務進行加鎖,即任務狀態置為 DLOCK_ONCE_UNLOCK(目的是為了保證當前任務執行的唯一性,防止在其它地方有多次定義),加鎖之后進行block回呼函式的執行,執行完成后,將當前任務解鎖,將當前的任務狀態置為 DLOCK_ONCE_DONE,在下次進來時,就不會在執行,會直接回傳;
-
- 多執行緒影響:如果在當前任務執行期間,有其它任務進來,會進入無限次等待,原因是當前任務已經獲取了鎖,進行了加鎖,那么其它任務是無法獲取鎖的,
- 單例的底層分析流程如下:
四、柵欄函式
① 柵欄函式說明
- GCD 中常用的柵欄函式,主要有兩種:同步柵欄函式dispatch_barrier_sync(在主執行緒中執行):前面的任務執行完畢才會執行柵欄函式之后的任務,但是同步柵欄函式會堵塞執行緒,影響后面的任務執行;異步柵欄函式 dispatch_barrier_async:前面的任務執行完畢才會繼續執行柵欄函數的之后的任務,
- 柵欄函式最直接的作用就是控制任務執行順序,使同步執行,
- 柵欄函式只能控制同一并發佇列;
- 同步柵欄添加進入佇列的時候,當前執行緒會被鎖死,直到同步柵欄之前的任務和同步柵欄任務本身執行完畢時,當前執行緒才會打開然后繼續執行下一句代碼,
- 在使用柵欄函式時,使用自定義佇列才有意義,如果用的是串行佇列或者系統提供的全域并發佇列,這個柵欄函式的作用等同于一個同步函式的作用,沒有任何意義,
② 柵欄函式使用
- 現在總共有4個任務,其中前2個任務有依賴關系,即任務1執行完,執行任務2,此時可以使用柵欄函式;
- 異步柵欄函式:
-
- 使用異步柵欄函式如下所示:
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.YDW.queue", DISPATCH_QUEUE_CONCURRENT);
// 異步函式
dispatch_async(concurrentQueue, ^{
NSLog(@"任務1");
});
// 柵欄函式
dispatch_barrier_async(concurrentQueue, ^{
NSLog(@"任務2");
});
// 異步函式
dispatch_async(concurrentQueue, ^{
NSLog(@"任務3");
});
NSLog(@"任務4");
-
- 執行結果如下所示:
2021-03-31 19:52:08.355734+0800 GCD[98653:3157789] 任務4
2021-03-31 19:52:08.355882+0800 GCD[98653:3157142] 任務1
2021-03-31 19:52:08.356001+0800 GCD[98653:3157142] 任務2
2021-03-31 19:52:08.356011+0800 GCD[98653:3157789] 任務3
-
- 由此,異步柵欄函式不會阻塞主執行緒 ,異步堵塞的是佇列;
- 同步柵欄函式:
-
- 使用同步柵欄函式如下所示:
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.YDW.queue", DISPATCH_QUEUE_CONCURRENT);
// 異步函式
dispatch_async(concurrentQueue, ^{
NSLog(@"任務1");
});
// 柵欄函式
dispatch_barrier_sync(concurrentQueue, ^{
NSLog(@"任務2");
});
// 異步函式
dispatch_async(concurrentQueue, ^{
NSLog(@"任務3");
});
NSLog(@"任務4");
-
- 執行結果如下:
2021-03-31 19:52:08.355734+0800 GCD[98653:3157789] 任務1
2021-03-31 19:52:08.355882+0800 GCD[98653:3157142] 任務2
2021-03-31 19:52:08.356001+0800 GCD[98653:3157142] 任務4
2021-03-31 19:52:08.356011+0800 GCD[98653:3157789] 任務3
-
- 因此,同步柵欄函式會堵塞主執行緒,同步堵塞是當前的執行緒,
- 柵欄函式除了用于任務有依賴關系時,同時還可以用于資料安全,
-
- 現有如下的代碼,執行會出現什么問題?
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.YDW.queue", DISPATCH_QUEUE_CONCURRENT);
NSMutableArray *array = [NSMutableArray array];
for (int i = 0; i < 10000; i++) {
dispatch_async(concurrentQueue, ^{
[array addObject:[NSString stringWithFormat:@"%d",i]];
});
}
- 可以看到,程式出現了崩潰,崩潰原因如下:
malloc: *** error for object 0x7fe0ae809400: pointer being freed was not allocated
malloc: *** set a breakpoint in malloc_error_break to debug
- 這是因為資料在不斷的 retain 和 release,在資料還沒有 retain 完畢時,然后又已經開始了 release,相當于加了一個空資料,進行 release,從而閃退,那么怎么解決呢?
-
- 使用柵欄函式就可以解決問題,如下所示:
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.YDW.queue", DISPATCH_QUEUE_CONCURRENT);
NSMutableArray *array = [NSMutableArray array];
for (int i = 0; i < 10000; i++) {
dispatch_async(concurrentQueue, ^{
dispatch_barrier_async(concurrentQueue, ^{
[array addObject:[NSString stringWithFormat:@"%d",i]];
});
});
}
-
- 使用互斥鎖 synchronized 也可以解決,如下:
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.YDW.queue", DISPATCH_QUEUE_CONCURRENT);
NSMutableArray *array = [NSMutableArray array];
for (int i = 0; i < 10000; i++) {
dispatch_async(concurrentQueue, ^{
@synchronized (self) {
[array addObject:[NSString stringWithFormat:@"%d", i]];
};
});
}
-
- 這里需要注意:
- 如果柵欄函式中使用全域佇列, 運行會崩潰,原因是系統也在用全域并發佇列,使用柵欄同時會攔截系統的,所以會出現崩潰;
- 如果將自定義并發佇列改為串行佇列,即 serial ,串行佇列本身就是有序同步,此時加柵欄會浪費性能;
- 柵欄函式只會阻塞一次,
- 這里需要注意:
③ 底層分析
- 異步柵欄函式:進入 dispatch_barrier_async 原始碼,其底層的實作與 dispatch_async 類似:
#ifdef __BLOCKS__
void
dispatch_barrier_async(dispatch_queue_t dq, dispatch_block_t work)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME | DC_FLAG_BARRIER;
dispatch_qos_t qos;
qos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);
_dispatch_continuation_async(dq, dc, qos, dc_flags);
}
#endif
- 同步柵欄函式:
-
- 進入 dispatch_barrier_sync 原始碼,如下:
void
dispatch_barrier_sync(dispatch_queue_t dq, dispatch_block_t work)
{
uintptr_t dc_flags = DC_FLAG_BARRIER | DC_FLAG_BLOCK;
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_sync_block_with_privdata(dq, work, dc_flags);
}
_dispatch_barrier_sync_f(dq, work, _dispatch_Block_invoke(work), dc_flags);
}
-
- 進入 _dispatch_barrier_sync_f -> _dispatch_barrier_sync_f_inline 原始碼:
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_barrier_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
dispatch_tid tid = _dispatch_tid_self();// 獲取執行緒的id,即執行緒的唯一標識
...
// 判斷執行緒狀態,需不需要等待,是否回收
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) { // 柵欄函式死鎖
return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl, // 沒有回收
DC_FLAG_BARRIER | dc_flags);
}
// 驗證target是否存在,如果存在,加入柵欄函式的遞回查找 是否等待
if (unlikely(dl->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func,
DC_FLAG_BARRIER | dc_flags);
}
_dispatch_introspection_sync_begin(dl);
_dispatch_lane_barrier_sync_invoke_and_complete(dl, ctxt, func
DISPATCH_TRACE_ARG(_dispatch_trace_item_sync_push_pop(
dq, ctxt, func, dc_flags | DC_FLAG_BARRIER))); // 執行
}
-
- 其中,_dispatch_queue_try_acquire_barrier_sync 實作如下:
DISPATCH_ALWAYS_INLINE DISPATCH_WARN_RESULT
static inline bool
_dispatch_queue_try_acquire_barrier_sync(dispatch_queue_class_t dq, uint32_t tid)
{
return _dispatch_queue_try_acquire_barrier_sync_and_suspend(dq._dl, tid, 0);
}
- 進入 _dispatch_queue_try_acquire_barrier_sync_and_suspend:
DISPATCH_ALWAYS_INLINE DISPATCH_WARN_RESULT
static inline bool
_dispatch_queue_try_acquire_barrier_sync_and_suspend(dispatch_lane_t dq,
uint32_t tid, uint64_t suspend_count)
{
uint64_t init = DISPATCH_QUEUE_STATE_INIT_VALUE(dq->dq_width);
uint64_t value = DISPATCH_QUEUE_WIDTH_FULL_BIT | DISPATCH_QUEUE_IN_BARRIER |
_dispatch_lock_value_from_tid(tid) |
(suspend_count * DISPATCH_QUEUE_SUSPEND_INTERVAL);
uint64_t old_state, new_state;
return os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, acquire, {
uint64_t role = old_state & DISPATCH_QUEUE_ROLE_MASK;
if (old_state != (init | role)) {
os_atomic_rmw_loop_give_up(break);
}
new_state = value | role;
});
}
-
- 通過 _dispatch_introspection_sync_begin 對向前資訊進行處理:
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_introspection_sync_begin(dispatch_queue_class_t dq)
{
if (!_dispatch_introspection.debug_queue_inversions) return;
_dispatch_introspection_order_record(dq._dq);
}
-
- 通過 _dispatch_lane_barrier_sync_invoke_and_complete 執行 block 并釋放:
DISPATCH_NOINLINE
static void
_dispatch_lane_barrier_sync_invoke_and_complete(dispatch_lane_t dq,
void *ctxt, dispatch_function_t func DISPATCH_TRACE_ARG(void *dc))
{
_dispatch_sync_function_invoke_inline(dq, ctxt, func);
_dispatch_trace_item_complete(dc);
if (unlikely(dq->dq_items_tail || dq->dq_width > 1)) {
return _dispatch_lane_barrier_complete(dq, 0, 0);
}
// Presence of any of these bits requires more work that only
// _dispatch_*_barrier_complete() handles properly
//
// Note: testing for RECEIVED_OVERRIDE or RECEIVED_SYNC_WAIT without
// checking the role is sloppy, but is a super fast check, and neither of
// these bits should be set if the lock was never contended/discovered.
const uint64_t fail_unlock_mask = DISPATCH_QUEUE_SUSPEND_BITS_MASK |
DISPATCH_QUEUE_ENQUEUED | DISPATCH_QUEUE_DIRTY |
DISPATCH_QUEUE_RECEIVED_OVERRIDE | DISPATCH_QUEUE_SYNC_TRANSFER |
DISPATCH_QUEUE_RECEIVED_SYNC_WAIT;
uint64_t old_state, new_state;
// similar to _dispatch_queue_drain_try_unlock
// 對下層狀態的釋放
os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, release, {
new_state = old_state - DISPATCH_QUEUE_SERIAL_DRAIN_OWNED;
new_state &= ~DISPATCH_QUEUE_DRAIN_UNLOCK_MASK;
new_state &= ~DISPATCH_QUEUE_MAX_QOS_MASK;
if (unlikely(old_state & fail_unlock_mask)) {
os_atomic_rmw_loop_give_up({
// 通知 barrier 執行完畢
return _dispatch_lane_barrier_complete(dq, 0, 0);
});
}
});
if (_dq_state_is_base_wlh(old_state)) {
_dispatch_event_loop_assert_not_owned((dispatch_wlh_t)dq);
}
}
-
- 同步柵欄函式底層流程總結:
- 通過 _dispatch_tid_self 獲取執行緒ID;
- 通過 _dispatch_queue_try_acquire_barrier_sync 判斷執行緒狀態;
- 通過 _dispatch_queue_try_acquire_barrier_sync_and_suspend 進行釋放;
- 通過 _dispatch_sync_recurse 遞回查找柵欄函式的 target;
- 通過 _dispatch_introspection_sync_begin 對向前資訊進行處理;
- 通過 _dispatch_lane_barrier_sync_invoke_and_complete 執行 block 并釋放,
- 同步柵欄函式底層流程總結:
五、信號量
① dispatch_semaphore_create 創建
- 信號量的作用一般是用來使任務同步執行,類似于互斥鎖,用戶可以根據需要控制GCD最大并發數,一般使用如下:
// 信號量
dispatch_semaphore_t sem = dispatch_semaphore_create(1);
dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER);
dispatch_semaphore_signal(sem);
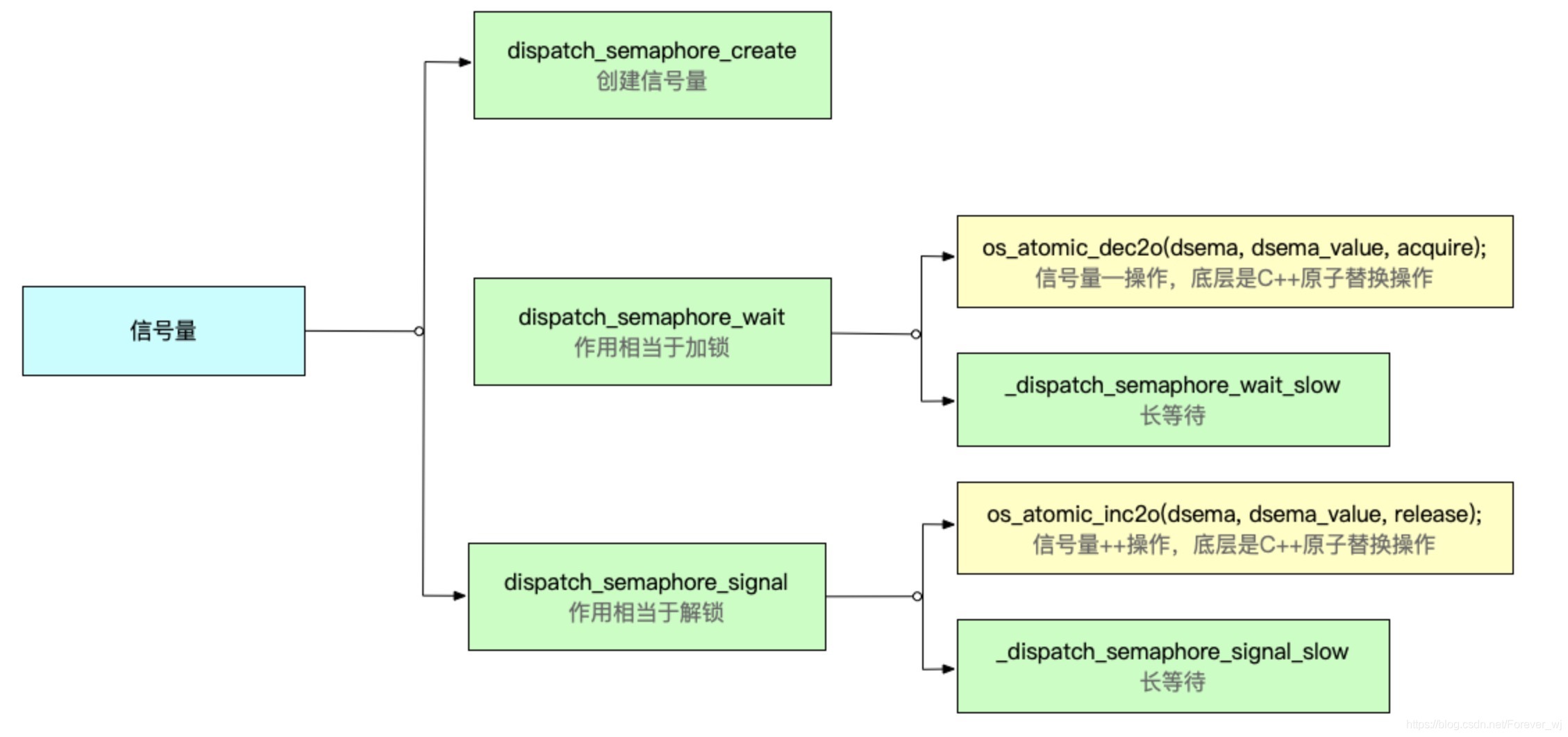
- 創建的底層實作,主要是初始化信號量,并設定GCD的最大并發數,其最大并發數必須大于0,如下所示:
dispatch_semaphore_t
dispatch_semaphore_create(long value)
{
dispatch_semaphore_t dsema;
// If the internal value is negative, then the absolute of the value is
// equal to the number of waiting threads. Therefore it is bogus to
// initialize the semaphore with a negative value.
if (value < 0) {
return DISPATCH_BAD_INPUT;
}
dsema = _dispatch_object_alloc(DISPATCH_VTABLE(semaphore),
sizeof(struct dispatch_semaphore_s));
dsema->do_next = DISPATCH_OBJECT_LISTLESS;
dsema->do_targetq = _dispatch_get_default_queue(false);
dsema->dsema_value = value;
_dispatch_sema4_init(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
dsema->dsema_orig = value;
return dsema;
}
② dispatch_semaphore_wait 加鎖
- 該函式的實作,其主要作用是對信號量 dsema 通過 os_atomic_dec2o 進行了–操作,其內部是執行的 C++ 的 atomic_fetch_sub_explicit 方法:
- 如果value 大于等于0,表示操作無效,即執行成功;
- 如果value 等于LONG_MIN,系統會拋出一個 crash;
- 如果value 小于0,則進入長等待,
long
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout)
{
// dsema_value 進行 -- 操作
long value = os_atomic_dec2o(dsema, dsema_value, acquire);
if (likely(value >= 0)) { // 表示執行操作無效,即執行成功
return 0;
}
return _dispatch_semaphore_wait_slow(dsema, timeout); // 長等待
}
- 其中,os_atomic_dec2o 的宏定義轉換如下:
os_atomic_inc2o(p, f, m)
os_atomic_sub2o(p, f, 1, m)
_os_atomic_c11_op((p), (v), m, sub, -)
_os_atomic_c11_op((p), (v), m, add, +)
({ _os_atomic_basetypeof(p) _v = (v), _r = \
atomic_fetch_##o##_explicit(_os_atomic_c11_atomic(p), _v, \
memory_order_##m); (__typeof__(_r))(_r op _v); })
// 傳值代入
os_atomic_dec2o(dsema, dsema_value, acquire);
os_atomic_sub2o(dsema, dsema_value, 1, m)
os_atomic_sub(dsema->dsema_value, 1, m)
_os_atomic_c11_op(dsema->dsema_value, 1, m, sub, -)
_r = atomic_fetch_sub_explicit(dsema->dsema_value, 1),
等價于 dsema->dsema_value - 1
- 進入 _dispatch_semaphore_wait_slow 的原始碼實作,當 value 小于 0 時,根據等待事件 timeout 做出不同操作:
DISPATCH_NOINLINE
static long
_dispatch_semaphore_wait_slow(dispatch_semaphore_t dsema,
dispatch_time_t timeout)
{
long orig;
_dispatch_sema4_create(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
switch (timeout) {
default:
if (!_dispatch_sema4_timedwait(&dsema->dsema_sema, timeout)) {
break;
}
// Fall through and try to undo what the fast path did to
// dsema->dsema_value
case DISPATCH_TIME_NOW:
orig = dsema->dsema_value;
while (orig < 0) {
if (os_atomic_cmpxchgvw2o(dsema, dsema_value, orig, orig + 1,
&orig, relaxed)) {
return _DSEMA4_TIMEOUT();
}
}
// Another thread called semaphore_signal().
// Fall through and drain the wakeup.
case DISPATCH_TIME_FOREVER:
_dispatch_sema4_wait(&dsema->dsema_sema);
break;
}
return 0;
}
③ dispatch_semaphore_signal 解鎖
- dispatch_semaphore_signal 實作原理,核心是通過 os_atomic_inc2o 函式對 value 進行 ++ 操作,os_atomic_inc2o 內部是通過 C++ 的 atomic_fetch_add_explicit,如果value 大于 0,表示操作無效,即執行成功;如果value 等于0,則進入長等待:
long
dispatch_semaphore_signal(dispatch_semaphore_t dsema)
{
// signal 對 value 是 ++
long value = os_atomic_inc2o(dsema, dsema_value, release);
if (likely(value > 0)) { // 回傳0,表示當前的執行操作無效,相當于執行成功
return 0;
}
if (unlikely(value == LONG_MIN)) {
DISPATCH_CLIENT_CRASH(value,
"Unbalanced call to dispatch_semaphore_signal()");
}
return _dispatch_semaphore_signal_slow(dsema); // 進入長等待
}
- os_atomic_dec2o 的宏定義轉換如下:
os_atomic_inc2o(p, f, m)
os_atomic_add2o(p, f, 1, m)
os_atomic_add(&(p)->f, (v), m)
_os_atomic_c11_op((p), (v), m, add, +)
({ _os_atomic_basetypeof(p) _v = (v), _r = \
atomic_fetch_##o##_explicit(_os_atomic_c11_atomic(p), _v, \
memory_order_##m); (__typeof__(_r))(_r op _v); })
// 傳值如下:
os_atomic_inc2o(dsema, dsema_value, release);
os_atomic_add2o(dsema, dsema_value, 1, m)
os_atomic_add(&(dsema)->dsema_value, (1), m)
_os_atomic_c11_op((dsema->dsema_value), (1), m, add, +)
_r = atomic_fetch_add_explicit(dsema->dsema_value, 1), // 等價于 dsema->dsema_value + 1
④ dispatch_semaphore 底層實作流程
- dispatch_semaphore_create 主要初始化信號量;
- dispatch_semaphore_wait 是對信號量的 value 進行–,即加鎖操作;
- dispatch_semaphore_signal 是對信號量的 value 進行++,即解鎖操作,
六、調度組
① dispatch_group_create 創建組
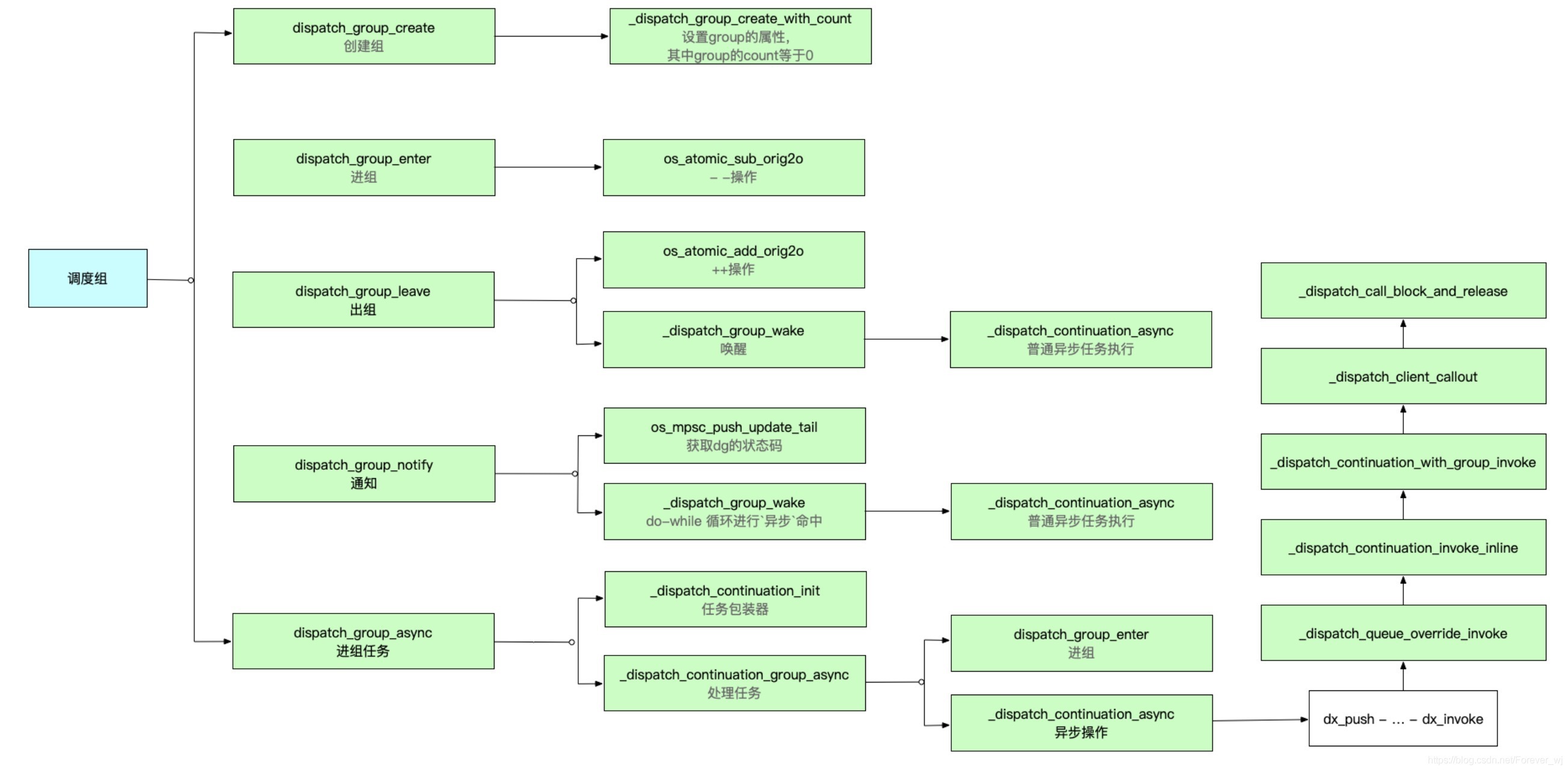
- 進入 dispatch_group_create 原始碼:
dispatch_group_t
dispatch_group_create(void)
{
return _dispatch_group_create_with_count(0);
}
- 進入 _dispatch_group_create_with_count 原始碼,主要是對 group 物件屬性賦值,并回傳 group 物件,n 等于 0;
DISPATCH_ALWAYS_INLINE
static inline dispatch_group_t
_dispatch_group_create_with_count(uint32_t n)
{
// 創建group物件,型別為OS_dispatch_group
dispatch_group_t dg = _dispatch_object_alloc(DISPATCH_VTABLE(group),
sizeof(struct dispatch_group_s));
// group物件賦值
dg->do_next = DISPATCH_OBJECT_LISTLESS;
dg->do_targetq = _dispatch_get_default_queue(false);
if (n) {
os_atomic_store2o(dg, dg_bits,
(uint32_t)-n * DISPATCH_GROUP_VALUE_INTERVAL, relaxed);
os_atomic_store2o(dg, do_ref_cnt, 1, relaxed);
}
return dg;
}
② dispatch_group_enter 進組
- 進入 dispatch_group_enter 原始碼,通過 os_atomic_sub_orig2o 對 dg->dg.bits 作 – 操作,對數值進行處理:
void
dispatch_group_enter(dispatch_group_t dg)
{
// The value is decremented on a 32bits wide atomic so that the carry
// for the 0 -> -1 transition is not propagated to the upper 32bits.
uint32_t old_bits = os_atomic_sub_orig2o(dg, dg_bits, // 原子遞減 0 -> -1
DISPATCH_GROUP_VALUE_INTERVAL, acquire);
uint32_t old_value = old_bits & DISPATCH_GROUP_VALUE_MASK;
if (unlikely(old_value == 0)) { // 如果old_value
_dispatch_retain(dg);
}
if (unlikely(old_value == DISPATCH_GROUP_VALUE_MAX)) { // 到達臨界值,會報crash
DISPATCH_CLIENT_CRASH(old_bits,
"Too many nested calls to dispatch_group_enter()");
}
}
- 其中當 old_value == DISPATCH_GROUP_VALUE_MAX,到達臨界值,會報crash, DISPATCH_GROUP_VALUE_MAX 的定義如下:
#define DISPATCH_GROUP_GEN_MASK 0xffffffff00000000ULL
#define DISPATCH_GROUP_VALUE_MASK 0x00000000fffffffcULL
#define DISPATCH_GROUP_VALUE_INTERVAL 0x0000000000000004ULL
#define DISPATCH_GROUP_VALUE_1 DISPATCH_GROUP_VALUE_MASK
#define DISPATCH_GROUP_VALUE_MAX DISPATCH_GROUP_VALUE_INTERVAL
#define DISPATCH_GROUP_HAS_NOTIFS 0x0000000000000002ULL
#define DISPATCH_GROUP_HAS_WAITERS 0x0000000000000001ULL
③ dispatch_group_leave 出組
- 進入 dispatch_group_leave 原始碼:
void
dispatch_group_leave(dispatch_group_t dg)
{
// The value is incremented on a 64bits wide atomic so that the carry for
// the -1 -> 0 transition increments the generation atomically.
uint64_t new_state, old_state = os_atomic_add_orig2o(dg, dg_state,// 原子遞增 ++
DISPATCH_GROUP_VALUE_INTERVAL, release);
uint32_t old_value = (uint32_t)(old_state & DISPATCH_GROUP_VALUE_MASK);
// 根據狀態,喚醒
if (unlikely(old_value == DISPATCH_GROUP_VALUE_1)) {
old_state += DISPATCH_GROUP_VALUE_INTERVAL;
do {
new_state = old_state;
if ((old_state & DISPATCH_GROUP_VALUE_MASK) == 0) {
new_state &= ~DISPATCH_GROUP_HAS_WAITERS;
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
} else {
// If the group was entered again since the atomic_add above,
// we can't clear the waiters bit anymore as we don't know for
// which generation the waiters are for
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
}
if (old_state == new_state) break;
} while (unlikely(!os_atomic_cmpxchgv2o(dg, dg_state,
old_state, new_state, &old_state, relaxed)));
return _dispatch_group_wake(dg, old_state, true);//喚醒
}
//-1 -> 0, 0+1 -> 1,即多次leave,會報crash,簡單來說就是enter-leave不平衡
if (unlikely(old_value == 0)) {
DISPATCH_CLIENT_CRASH((uintptr_t)old_value,
"Unbalanced call to dispatch_group_leave()");
}
}
- 分析說明:
-
- 1 到 0,即++操作;
-
- 根據狀態,do-while 回圈,喚醒執行 block 任務;
-
- 如果0 + 1 = 1,enter-leave 不平衡,即 leave 多次呼叫,會 crash,
- 進入 _dispatch_group_wake 原始碼,do-while 回圈進行異步命中,呼叫 _dispatch_continuation_async 執行:
DISPATCH_NOINLINE
static void
_dispatch_group_wake(dispatch_group_t dg, uint64_t dg_state, bool needs_release)
{
uint16_t refs = needs_release ? 1 : 0;
if (dg_state & DISPATCH_GROUP_HAS_NOTIFS) {
dispatch_continuation_t dc, next_dc, tail;
// Snapshot before anything is notified/woken <rdar://problem/8554546>
dc = os_mpsc_capture_snapshot(os_mpsc(dg, dg_notify), &tail);
do {
dispatch_queue_t dsn_queue = (dispatch_queue_t)dc->dc_data;
next_dc = os_mpsc_pop_snapshot_head(dc, tail, do_next);
_dispatch_continuation_async(dsn_queue, dc,
_dispatch_qos_from_pp(dc->dc_priority), dc->dc_flags); // block任務執行
_dispatch_release(dsn_queue);
} while ((dc = next_dc)); // do-while回圈,進行異步任務的命中
refs++;
}
if (dg_state & DISPATCH_GROUP_HAS_WAITERS) {
_dispatch_wake_by_address(&dg->dg_gen); // 地址釋放
}
if (refs) _dispatch_release_n(dg, refs); // 參考釋放
}
- 進入 _dispatch_continuation_async 原始碼:
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_async(dispatch_queue_class_t dqu,
dispatch_continuation_t dc, dispatch_qos_t qos, uintptr_t dc_flags)
{
#if DISPATCH_INTROSPECTION
if (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {
_dispatch_trace_item_push(dqu, dc); // 跟蹤日志
}
#else
(void)dc_flags;
#endif
return dx_push(dqu._dq, dc, qos); // 與dx_invoke一樣,都是宏
}
④ dispatch_group_notify 通知
- 進入 dispatch_group_notify 原始碼,如果 old_state 等于 0,就可以進行釋放:
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_group_notify(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dsn)
{
uint64_t old_state, new_state;
dispatch_continuation_t prev;
dsn->dc_data = dq;
_dispatch_retain(dq);
// 獲取dg底層的狀態標識碼,通過os_atomic_store2o獲取的值,即從dg的狀態碼 轉成了 os底層的state
prev = os_mpsc_push_update_tail(os_mpsc(dg, dg_notify), dsn, do_next);
if (os_mpsc_push_was_empty(prev)) _dispatch_retain(dg);
os_mpsc_push_update_prev(os_mpsc(dg, dg_notify), prev, dsn, do_next);
if (os_mpsc_push_was_empty(prev)) {
os_atomic_rmw_loop2o(dg, dg_state, old_state, new_state, release, {
new_state = old_state | DISPATCH_GROUP_HAS_NOTIFS;
if ((uint32_t)old_state == 0) { // 如果等于0,則可以進行釋放了
os_atomic_rmw_loop_give_up({
return _dispatch_group_wake(dg, new_state, false); // 喚醒
});
}
});
}
}
- 其中 os_mpsc_push_update_tail 定義如下,用于獲取 dg 的狀態碼:
#define os_mpsc_push_update_tail(Q, tail, _o_next) ({ \
os_mpsc_node_type(Q) _tl = (tail); \
os_atomic_store2o(_tl, _o_next, NULL, relaxed); \
os_atomic_xchg(_os_mpsc_tail Q, _tl, release); \
})
⑤ dispatch_group_async
- 進入 dispatch_group_async 原始碼,主要是包裝任務和異步處理任務:
#ifdef __BLOCKS__
void
dispatch_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_block_t db)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME | DC_FLAG_GROUP_ASYNC;
dispatch_qos_t qos;
// 任務包裝器
qos = _dispatch_continuation_init(dc, dq, db, 0, dc_flags);
// 處理任務
_dispatch_continuation_group_async(dg, dq, dc, qos);
}
#endif
- 進入 _dispatch_continuation_group_async 原始碼,主要集成 dispatch_group_enter 進組操作:
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dc, dispatch_qos_t qos)
{
dispatch_group_enter(dg); // 進組
dc->dc_data = dg;
_dispatch_continuation_async(dq, dc, qos, dc->dc_flags); // 異步操作
}
- 進入 _dispatch_continuation_async 原始碼,執行常規的異步函式底層操作,既然有 enter,肯定有 leave,可以猜測 block 執行之后隱性的執行 leave,現有如下代碼:
dispatch_group_t group = dispatch_group_create();
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_group_enter(group);
dispatch_async(queue, ^{
sleep(1);
NSLog(@"任務1");
dispatch_group_leave(group);
});
dispatch_group_enter(group);
dispatch_async(queue, ^{
NSLog(@"任務2");
dispatch_group_leave(group);
});
dispatch_group_async(group, queue, ^{
NSLog(@"任務5");
});
dispatch_group_notify(group, queue, ^{
NSLog(@"任務3");
});
NSLog(@"任務4");
- 列印堆疊資訊:
(lldb) bt
* thread #6, queue = 'com.apple.root.default-qos', stop reason = breakpoint 1.1
* frame #0: 0x00000001053c7517 函式與佇列`__29-[ViewController viewDidLoad]_block_invoke_2(.block_descriptor=0x00000001053ca128) at ViewController.m:35:9
frame #1: 0x00000001056387ec libdispatch.dylib`_dispatch_call_block_and_release + 12
frame #2: 0x00000001056399c8 libdispatch.dylib`_dispatch_client_callout + 8
frame #3: 0x000000010563bfe2 libdispatch.dylib`_dispatch_queue_override_invoke + 1444
frame #4: 0x000000010564b508 libdispatch.dylib`_dispatch_root_queue_drain + 351
frame #5: 0x000000010564be6d libdispatch.dylib`_dispatch_worker_thread2 + 135
frame #6: 0x00007fff611639f7 libsystem_pthread.dylib`_pthread_wqthread + 220
frame #7: 0x00007fff61162b77 libsystem_pthread.dylib`start_wqthread + 15
(lldb)
- 可以看到 libdispatch.dylib`_dispatch_client_callout + 8,我們查看 _dispatch_client_callout 的呼叫,可以看到在 _dispatch_continuation_with_group_invoke 中,因此可以驗證 dispatch_group_async 底層是 enter-leave;
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_with_group_invoke(dispatch_continuation_t dc)
{
struct dispatch_object_s *dou = dc->dc_data;
unsigned long type = dx_type(dou);
if (type == DISPATCH_GROUP_TYPE) { // 如果是調度組型別
_dispatch_client_callout(dc->dc_ctxt, dc->dc_func); // block回呼
_dispatch_trace_item_complete(dc);
dispatch_group_leave((dispatch_group_t)dou); // 出組
} else {
DISPATCH_INTERNAL_CRASH(dx_type(dou), "Unexpected object type");
}
⑥ dispatch_group 底層實作流程
- enter-leave 需要成對出現;
- dispatch_group_enter 在底層是通過 C++ 函式,對 group 的 value 進行 – 操作(即0 -> -1);
- dispatch_group_leave 在底層是通過 C++ 函式,對 group 的 value 進行 ++ 操作(即-1 -> 0);
- dispatch_group_notify 在底層主要是判斷 group 的 state 是否等于0,當等于0時發出通知;
- block 任務的喚醒,可以通過 dispatch_group_leave,也可以通過 dispatch_group_notify;
- dispatch_group_async 等同于 enter - leave,其底層的實作就是 enter-leave,
七、原始碼下載
本文是在原始碼 libdispatch.dylib 中探索分析的,原始碼的下載地址:macOS 10.15 - Source,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272788.html
標籤:其他
上一篇:學會LeetCood三道題
下一篇:3.變數與常量