@BP神經網路演算法python 底層
TOC
大家好,我是朱位元
本節 主要講解的是BP神經網路演算法流程以及代碼復現
下面幾張圖片主要是我學習程序的一些筆記,希望對大家的學習有一定的幫助,

##這里主要解釋了梯度下降原理和3層網路的構建程序以及BP演算法流程,利用鏈式法則對誤差函式求偏導數的程序(演算法的數學原理)




接下來是我簡單構建的一個3層神經網路的代碼程序,
此處我存在一個疑惑,當sigmoid函式遇到標簽分類是【1,2,3】此類大于1的資料時,sigmoid函式是不是就失效了
在此,我想到一個有局限性的解決方法:對原excel的檔案進行提前處理,比如對iris資料集 我將標簽值和資料值都除以10,使得資料的值域位于【0:1】之間,這樣做的訓練效果比較好,能夠適應sigmoid函式的局限性
但是這樣的方法對于一些值域差距比較大的資料集適用性比較差,比如win資料集 長度4000寬度5 對資料值的預處理比較麻煩,因此這是我的一個疑惑點!
(ps:我也是在學習神經網路的程序中,如果有大神希望能幫我解決這個疑惑0,0)
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
def getdata(fpath):
'''
定義getdata 獲取訓練集資料
'''
#fpath = r'd:iris.xls'
object = pd.read_excel(fpath)
object = shuffle(object)
m1 = object.iloc[0:120, 0:5]
k3 = []
k4=[]
o=[]
m2 = m1.values.tolist()
k1 = object.iloc[0:120, 0:5]
k2 = k1.values.tolist()
for i in k2:
k3.append(i)
for i in k3:
o.append([i[4]])
labelset = np.array(o)
for i in k3:
k4.append(i[0:4])
dataset = np.array(k4)
return dataset, labelset,
def gettest(fpath):
'''
定義測驗集資料
這里主要是取了 第120-150行的資料(前面已經使用shuffle函式進行打亂順序)
'''
#fpath = r'd:iris.xls'
object = pd.read_excel(fpath)
object = shuffle(object)
m1 = object.iloc[120:150, 0:5]
m2 = m1.values.tolist()
k1 = object.iloc[120:150, 0:5]
k2 = k1.values.tolist()
k3 = []
k4 = []
for i in k2:
k3.append(i)
o = []
for i in k3:
o.append([i[4]])
labeltrain = np.array(o)
for i in k3:
k4.append(i[0:4])
datatrain = np.array(k4)
print(datatrain,labeltrain)
return datatrain,labeltrain
def prime_time(x, y, z):
'''
x,y,z主要是input層 hide層 output層 的神經元個數
這里主要提供的是各個層的隨機權重值
'''
value1 = np.random.randint(-5, 5, (1, y)).astype(np.float64)
value2 = np.random.randint(-5, 5, (1, z)).astype(np.float64)
weight1 = np.random.randint(-5, 5, (x, y)).astype(np.float64)
weight2 = np.random.randint(-5, 5, (y, z)).astype(np.float64)
return weight1, weight2, value1, value2
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def trainning_process(dataset, labelset, weight1, weight2, value1, value2):
'''
這個程序是訓練程序
主要對應的內容是 對e和w值利用鏈式法則求偏導數 然后利用損失函式對權重和偏執進行不斷修正
'''
learning_rate = 0.01#學習率
for i in range(len(dataset)):
# 輸入資料
inputset = np.mat(dataset[i]).astype(np.float64)
# 資料標簽
outputset = np.mat(labelset[i]).astype(np.float64)
# 隱層輸入
input1 = np.dot(inputset, weight1).astype(np.float64)
# 隱層輸出
output2 = sigmoid(input1 - value1).astype(np.float64)
# 輸出層輸入
input2 = np.dot(output2, weight2).astype(np.float64)
# 輸出層輸出
output3 = sigmoid(input2 - value2).astype(np.float64)
update_b = np.multiply(output3, 1 - output3)
update_a = np.multiply(update_b, outputset - output3)
update_c = np.dot(update_a, np.transpose(weight2))
update_d = np.multiply(output2, 1 - output2)
update_e = np.multiply(update_c, update_d)
value1_change = -learning_rate * update_e
value2_change = -learning_rate * update_a
weight1_change = learning_rate* np.dot(np.transpose(inputset), update_e )
weight2_change = learning_rate * np.dot(np.transpose(output2), update_a)
value1 += value1_change
value2 += value2_change
weight1 += weight1_change
weight2 += weight2_change
return weight1, weight2, value1, value2
def testing(dataset, labelset, weight1, weight2, value1, value2):
'''
這是測驗的程序
回傳的是一個記數器 只要predict - true_value的絕對值<0.04 我們就算預測成功
'''
rightcount = 0
for i in range(len(dataset)):#這里是訓練權重和偏執的程序
inputset = np.mat(dataset[i]).astype(np.float64)
outputset = np.mat(labelset[i]).astype(np.float64)
output2 = sigmoid(np.dot(inputset, weight1) - value1)
output3 = sigmoid(np.dot(output2, weight2) - value2)
print(output3)
# 確定其預測標簽
if abs(output3[0][0]-labelset[i][0]) <0.04:
rightcount =rightcount+1
# 輸出預測結果
result = rightcount/len(labelset)
print("Acurracy ={:.4f} ".format(result))
if __name__ == '__main__':
dataset, labelset = getdata( r'd:iri1.xls')
weight1, weight2, value1, value2 = prime_time(len(dataset[0]), len(dataset[0]), 1)
datatrain,labeltrain = gettest(r'd:iri1.xls')
for i in range(20000):
weight1, weight2, value1, value2 = trainning_process(dataset, labelset, weight1, weight2, value1, value2)
rate = testing(datatrain, labeltrain, weight1, weight2, value1, value2)
```python
在這里插入代碼片
```
最后,iris資料集有需要的童鞋可以私信我哦,sklearn庫里面也可以呼叫,
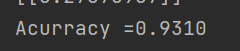
我這里主要用的是pandas來匯入exel表的資料,訓練結果還算不錯,有準確率有93.1%-97.0%
機器學習小白,希望和大家一起學習進步!
這里是參考
《機器學習》周志華
bilibili浙江大學胡浩基老師機器學習研究生課程
bilibili 致敬大神 深度學習課程
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272825.html
標籤:AI