三萬多字長文!讓你秒懂編譯原理(四)——第四章 語法分析—自上而下分析
系列文章傳送門:
萬字長文+獨家思維導圖!讓你秒懂編譯原理(一)——第一章 引論
萬字長文!讓你秒懂編譯原理(二)——第二章 高級語言及其語法描述
近三萬字長文!讓你秒懂編譯原理(三)——第三章 詞法分析
三萬多字長文!讓你秒懂編譯原理(四)——第四章 語法分析—自上而下分析
文章目錄
- 三萬多字長文!讓你秒懂編譯原理(四)——第四章 語法分析—自上而下分析
- 編譯程式總框
- 回顧
- 4.1 語法分析器的功能
- 語法分析器在編譯器中的地位
- 語法分析的方法:
- 自下而上分析法(Bottom-up)
- 自上而下分析法(Top-down)
- 4.2 自上而下分析(Bottom-up)及其面臨的問題
- 基本思想
- 匹配程序
- 多個產生式候選帶來的問題
- 4.3 LL(1)分析法
- 4.3.1 左遞回的消除
- 兩個候選
- 多個候選
- 4.3.2 消除回溯、提左因子
- FIRST集合
- 提取公共左因子:
- 4.3.3 LL(1)分析條件
- ε候選
- FOLLOW集合
- LL(1)文法
- LL(1)分析法
- FIRST集合和FOLLOW集合的構造
- FIRST集合的構造
- 構造每個文法符號的FIRST集合
- 構造任何符號串的FIRST集合
- FOLLOW集合的構造
- 舉例
- 構造FIRST集合(詳細步驟)
- 構造FOLLOW集合(詳細步驟)
- 4.4 遞回下降分析分析程式構造
- 文法的另一種表示法和轉換圖
- 擴充的巴科斯范式
- 語法圖
- 4.5 預測分析程式
- 預測分析程式作業原理
- 預測分析程序
- 總控程式的基本實作
- 預測分析示例
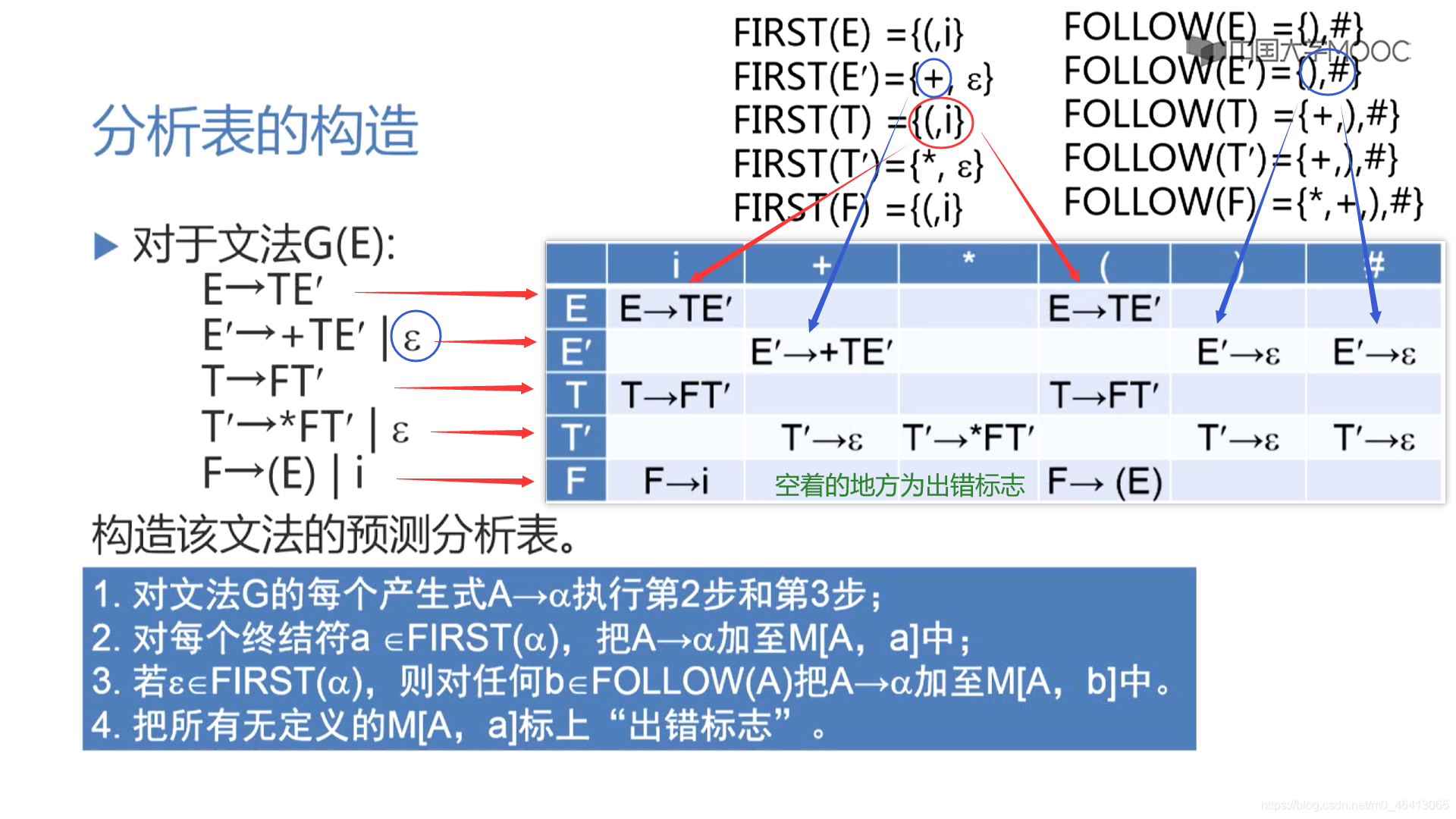
- 預測分析表的生成
- LL(1)文法與二義性
編譯程式總框
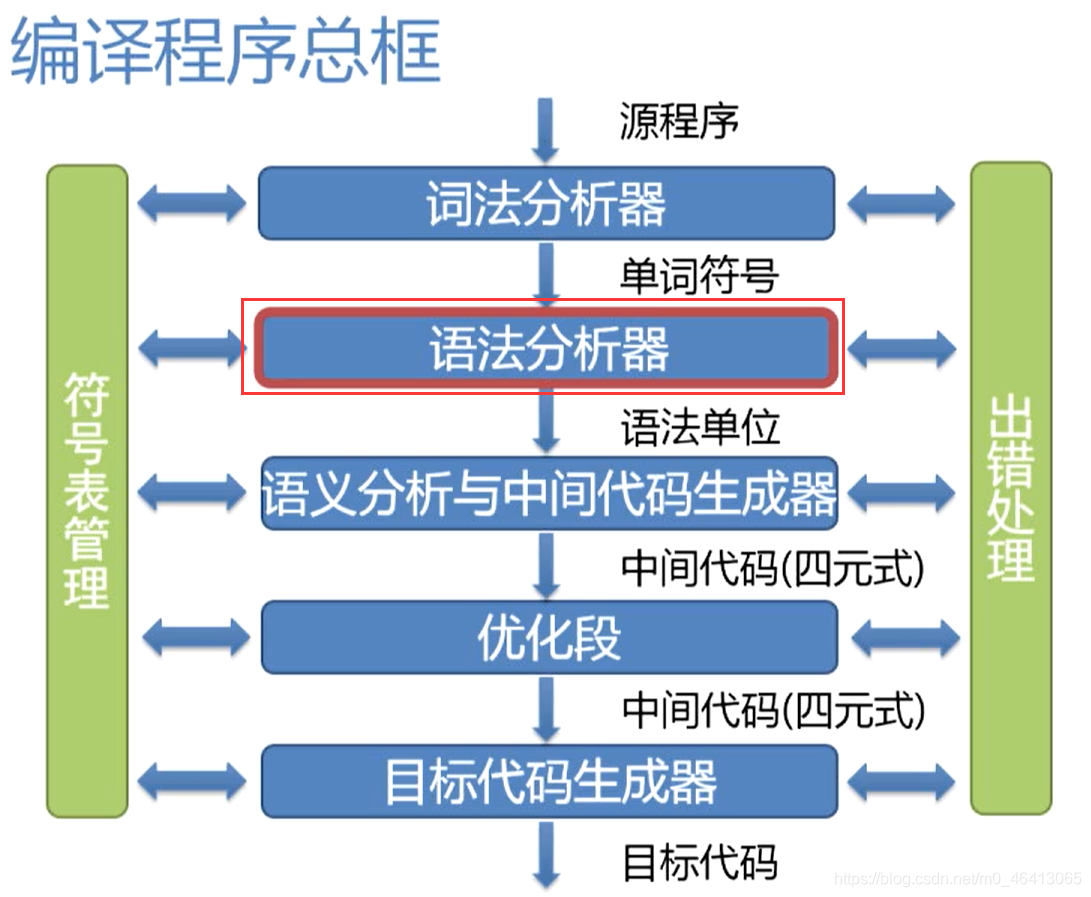
本章主要介紹語法分析的處理
要進行語法分析,必須對語言的語法結構進行描述,
回顧
- 采用正規式和有限自動機可以描述和識別語言的單詞符號;
- 用背景關系無關文法來描述語法規則,

注:
開始符S至少必須在某個產生式的左部出現一次,
產生式集合給出了一個非終結符的定義(→定義為)
說明這個非終結符由怎樣的非終結符和終結符構成
即只要左邊是非終結符,就能產生任何符
( V T ∪ V N ) (V_T∪V_N) (VT?∪VN?)表示終結符和非終結符組成的字符集合
( V T ∪ V N ) ? (V_T∪V_N)^* (VT?∪VN?)?表示該集合中的符號所組成的字的全體

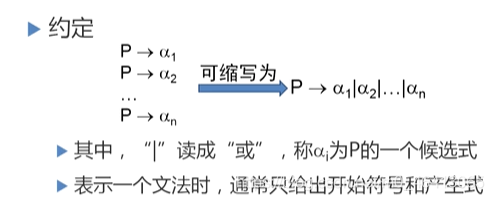
表示一個文法時,通常只給出開始符號和產生式,如上例,可表示為:
G(E): E → i | E+E | E*E | (E)

把一個字串中的一個終結符的一次出現(不是所有一起替換)替換成候選


句子也是句型

要證明是一個句子,必須證明它只有終結符,即只有{i,+,*,(,)},然后再證明他能從文法開始的符號推出來,



4.1 語法分析器的功能
- 語法分析的任務是分析一個文法的句子結構,
- 語法分析器的功能:按照文法的產生式(語言的語法規則),識別輸入符號串是否為一個句子(合式程式),
注:語法分析是編譯程式的核心部分
語法分析器在編譯器中的地位
編譯程式有詞法分析器、語法分析器、符號表等模塊,
編譯程式中起主導或驅動作用的是語法分析器
- 語法分析器需要下一個單詞的時候需要呼叫詞法分析器,即詞法分析子程式
- 詞法分析器從源程式當前位置開始處理
- 按照詞法規則,識別出一個單詞符號,將單詞符號回傳給語法分析程式
- 語法分析器拿到這個單詞后,繼續開展語法分析,得到一部分語法樹,交給編譯程式后續部分進行分析處理
- 如果分析處理不下去了,需要讀入下一個單詞的時候, 語法分析器就會繼續呼叫詞法分析器,取得下一個單詞,語法分析器就繼續作業下去
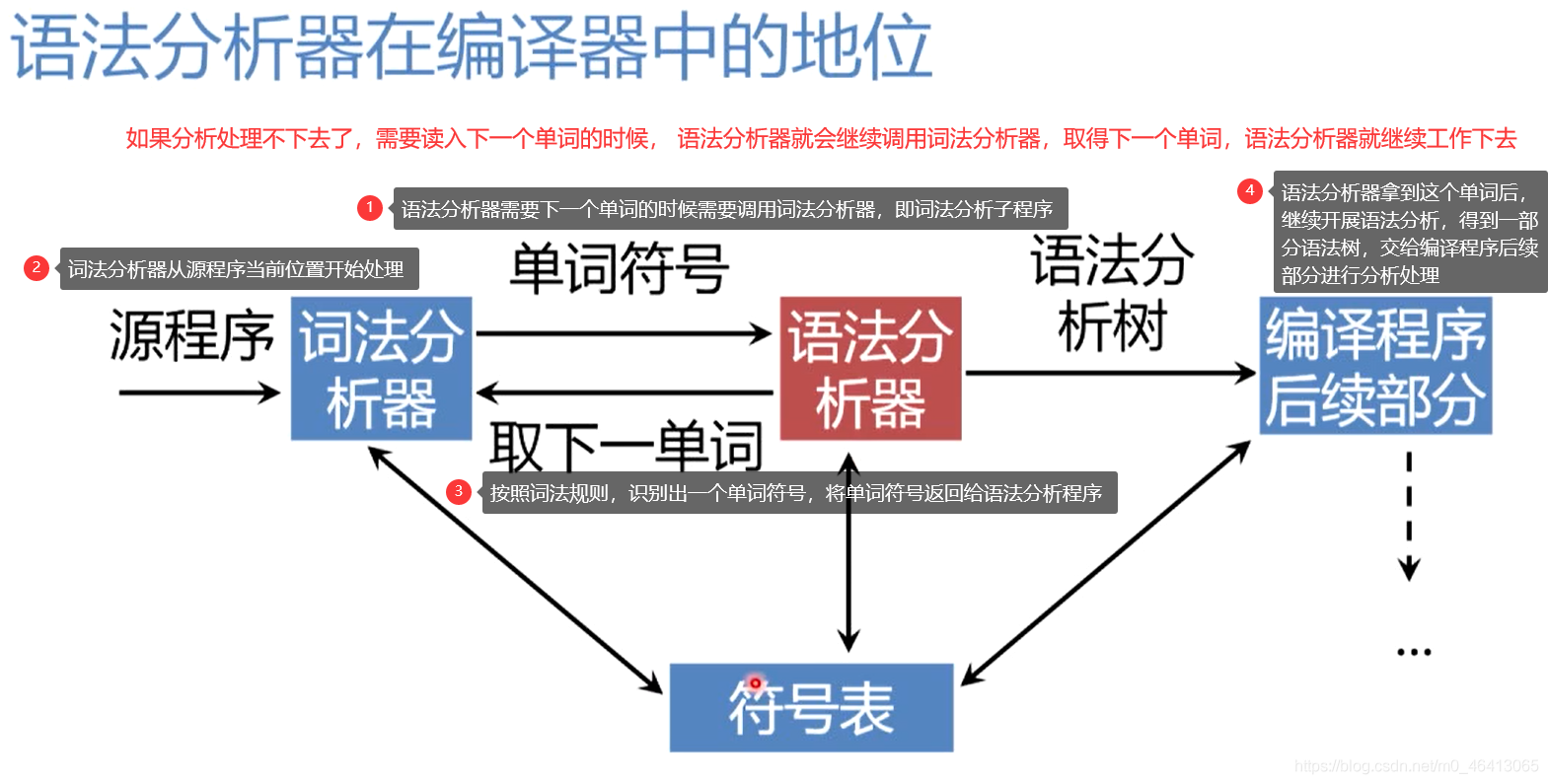
在整個分析程序中,語法分析器,詞法分析器都會跟符號表打交道,在符號表中記錄,訪問,修改編譯程序的資訊,所以語法分析器在編譯程式中處于主導地位
語法分析的方法:
自下而上分析法(Bottom-up)
- 基本思想:從輸入串開始,逐步進行“歸約”,直到文法的開始符號,即從樹末端開始,構造語法樹,
- 所謂歸約,是指根據文法的產生式規則,把產生式的右部替換成左部符號,
- 算符優先分析法:按照算符的優先關系和結合性質進行語法分析,適合分析運算式,
- LR分析法:規范歸約
自上而下分析法(Top-down)
-
基本思想:它從文法的開始符號出發,反復使用各種產生式,尋找"匹配"的推導,
-
遞回下降分析法:對每一語法變數(非終結符)構造一個相應的子程式,每個子程式識別一定的語法單位,通過子程式間的資訊反饋和聯合作用實作對輸入串的識別,
-
預測分析程式
優點:直觀、簡單和宜于手工實作 -
自上而下就是從文法的開始符號出發,向下推導,推出句子,
①帶“回溯”的
②不帶回溯的遞回子程式(遞回下降)分析方法, -
自上而下分析的主旨:對任何輸入串,試圖用一切可能的辦法,從文法開始符號(根結點)出發,自上而下地為輸入串建立一棵語法樹,或者說,為輸入串尋找一個最左推導,

4.2 自上而下分析(Bottom-up)及其面臨的問題
基本思想
- 從文法的開始符號出發,向下推導,推出句子
- 針對輸入串,試圖用一切可能的辦法,從文法開始符號(根結點)出發,自上而下地為輸入串建立一棵語法樹
匹配程序
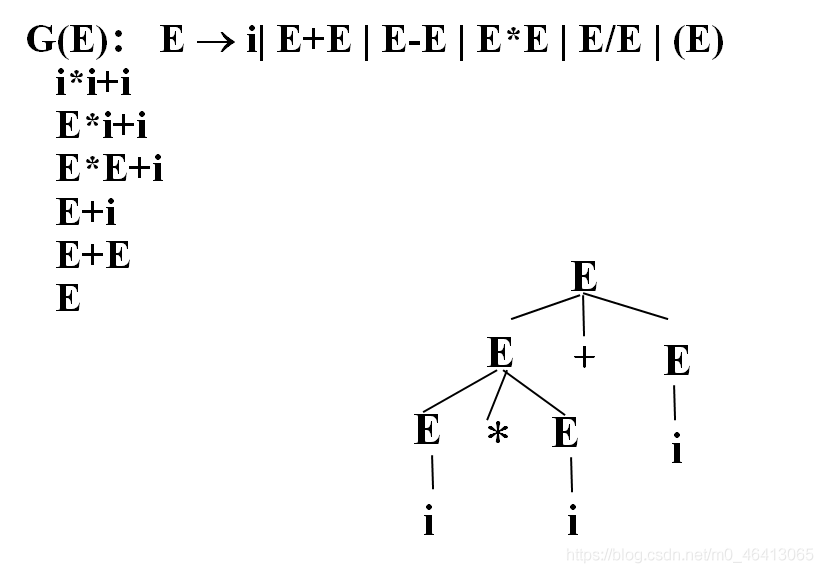
先由樹的根結點,從S出發,向下推導,從左到右跟x*y匹配,
有一個IP指標,相當于詞法分析器,每呼叫一次詞法分析器,就回傳一個單詞,指標就往前進一個,
從x開始推導,S本身無法跟x匹配,將S擴展為它的定義式x,A,y
x與x匹配(都是同一個終結符),匹配成功,
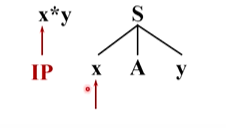
語法分析器前進,讀入下一個單詞 * ,語法樹由小x后面的符號開始,去跟輸入串后面的 * 匹配,因此匹配指標也向后移動,由x到A,A與*匹配,非終結符與一個終結符沒法直接匹配
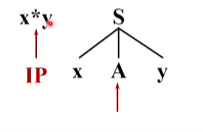
只能把這個非終結符替換成它的定義式,A有兩個定義式,選擇第一個候選**來擴展A,左邊的 *能夠與輸入串當前的單詞 * 匹配(兩個為同一個終結符)
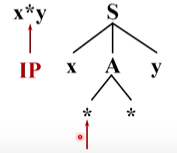
然后兩個指標均向后移動,注意到語法樹中第二個 * 和輸入串當前的單詞都是終結符,且不同, *沒辦法替換成別的符號,所以分析無法進行
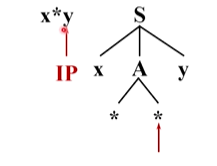
回溯,將A替換為第二個候選,兩個 * 匹配成功,前進
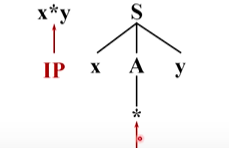
這時候輸入串指向y,語法樹也是指向y,匹配成功
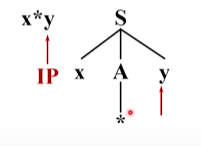
多個產生式候選帶來的問題
某個非終結符有多個產生式候選時,可能帶來如下問題:
- 回溯問題
- 分析程序中,當一個非終結符用某一個候選匹配成功時,這種匹配可能是暫時的,
- 出錯時,不得不 “回溯”,
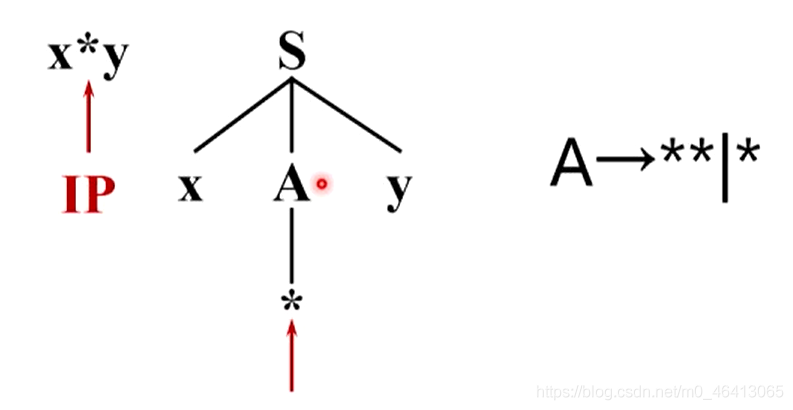
待回溯的分析程式設計起來非常麻煩,我們希望得到不需要回溯的分析程式,也就是確保我們每一次在多個候選做選擇的時候,都是唯一可能正確的
- 文法左遞回問題,
- 一個文法是含有左遞回的,如果存在非終結符P
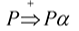
P經過一步/多步推導之后,能推出一個串,這個串以其自身開頭,后面可以是任意串,(左遞回)
從文法開始符號出發向下推導:
推導到P,并在左遞回的這條通路上依次擴展下去,向下擴展的程序中,單詞符號沒有讀入任何新的符號,沒有任何推進,但這個樹不斷向下增長
導致語法樹不斷生長,而單詞的語法樹不斷前進,最后導致整個分析器陷入死回圈,
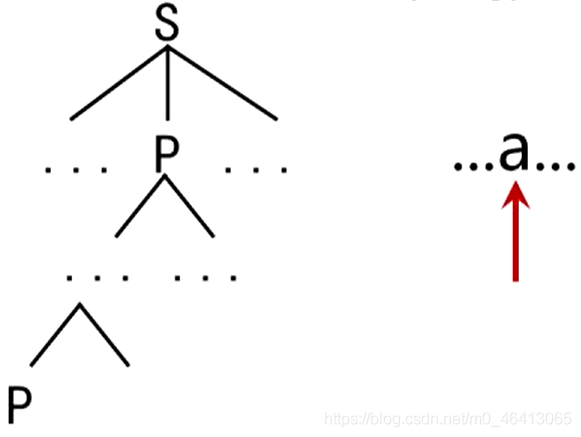
含有左遞回的文法將使自上而下的分析陷入無限回圈,
4.3 LL(1)分析法
構造不帶回溯的自上而下分析演算法
- 要消除文法的左遞回性
- 克服回溯
4.3.1 左遞回的消除
兩個候選

多個候選

E和T都有直接左遞回,
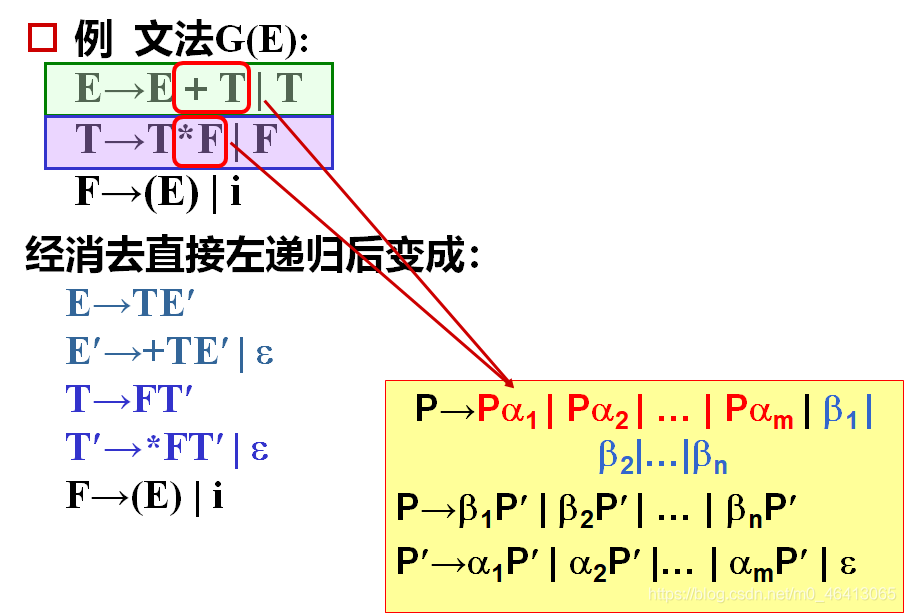

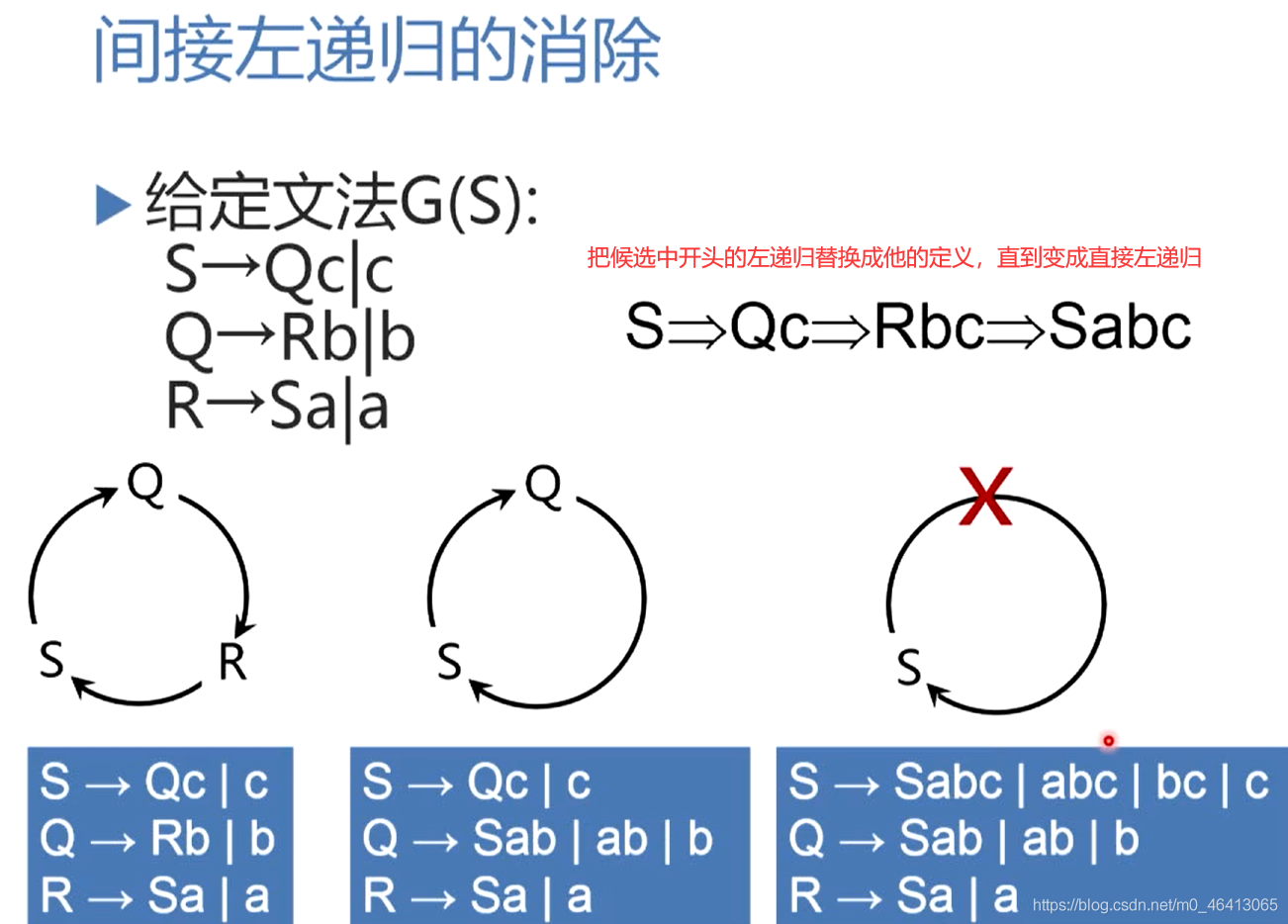
把候選中開頭的左遞回替換成他的定義,逐步減少定義種圈中的節點,最后變成自圈,從而變成直接左遞回,
構造一個回圈,使之達到這樣的一個目的:
使Pi的規則要么以終結符開頭,如果以非終結符開頭,只能以排在Pi后面的這些非終結符開頭,也就是說Pi的定義不能出現有在這個序列當中排在他前面的非終結符開頭的這種定義式(候選式)
在回圈體內嵌一個回圈j(1 ~ i-1),處理Pi的產生式,如果Pi定義候選以Pj開頭,將Pj替換成他的定義式,(當處理Pi的時候,P1 ~ Pi-1已經達到上述目標規則形式,也就是Pj的定義式符合上述:要么以終結符開頭,如果以非終結符開頭,只能以排在Pj后面的這些非終結符開頭),從而使Pi要么以終結符開頭,要么以Pj后面的非終結符開頭,當j一直回圈,Pi也達到目標規則形式:要么以終結符開頭,如果以非終結符開頭,只能以排在Pj后面的這些非終結符開頭
這個時候Pi如果有Pi開頭的候選極為直接左遞回,按照直接左遞回做法消除左遞回,








即:
4.3.2 消除回溯、提左因子
- 產生回溯的原因:
推導時,若產生式存在多個候選式,選擇哪個進行推導存在不確定性, - 為了消除回溯就必須保證:
對文法的任何非終結符,當要它去匹配輸入串時,能夠根據它所面臨的輸入符號準確地指派它的一個候選去執行任務,并且此候選的作業結果應是確信無疑的,
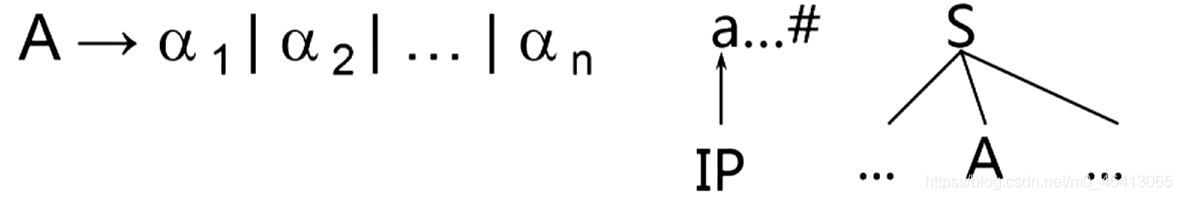
任務:根據當前的輸入符號a在當前A的所有候選中準確的指出一個候選去擴展A
如何選擇?
如果當前A的所有候選,有且只有一個是以a(當前單詞)開頭的話就毫不猶豫選擇這個候選,
即根據當前的單詞符號去看他出現在哪一個候選的開頭,如果有一個候選的開頭是終結符且恰好是該單詞符號的話就選它(a)
如果候選的開頭都是非終結符,非終結符能推出當前單詞開頭的(a)的串
FIRST集合

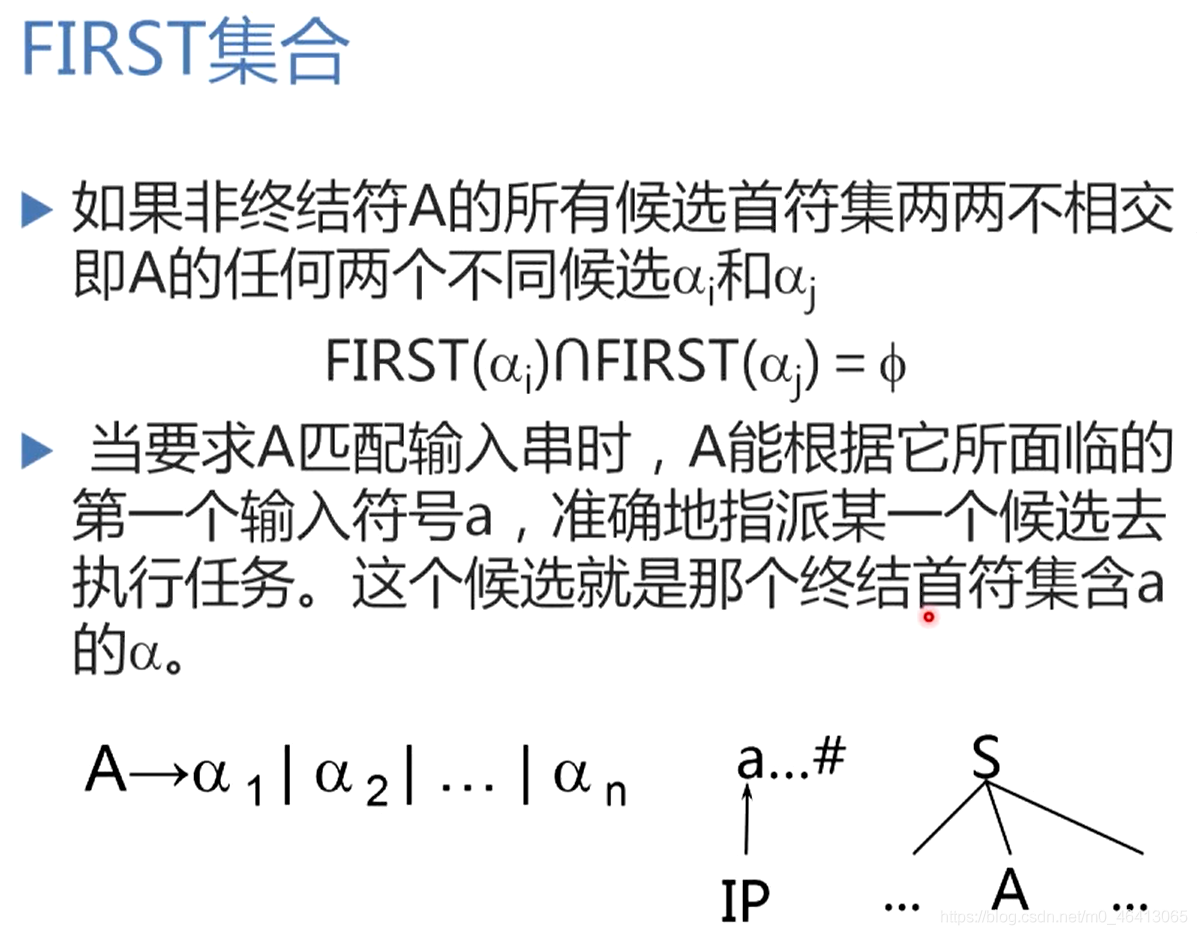

提取公共左因子:
一個文法可能開始并不具備,非終結符的首符集兩兩不相交的情況一開始可能不成立,因此我們需要用一個演算法進行改造——提取公共左因子,使得候選盡可能的不相交,

4.3.3 LL(1)分析條件
ε候選

開始時,當前符號為i,自上而下分析,從文法的開始符號開始E作為樹的根,向下擴展
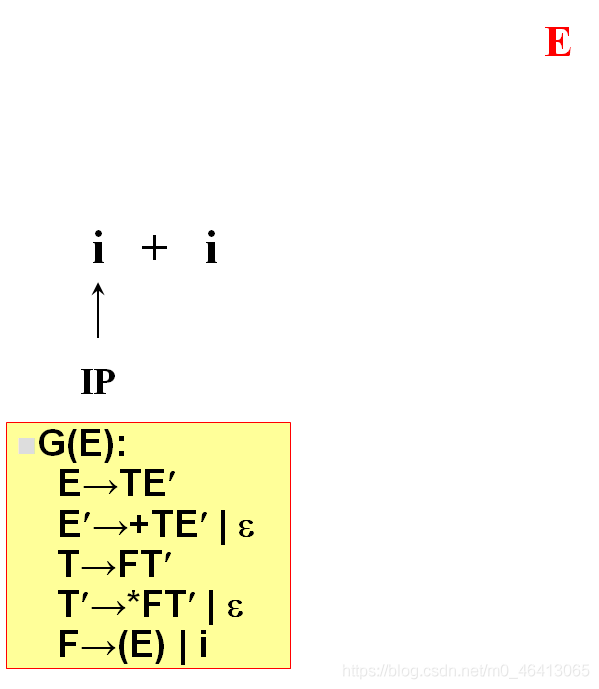
T,E’(唯一候選)
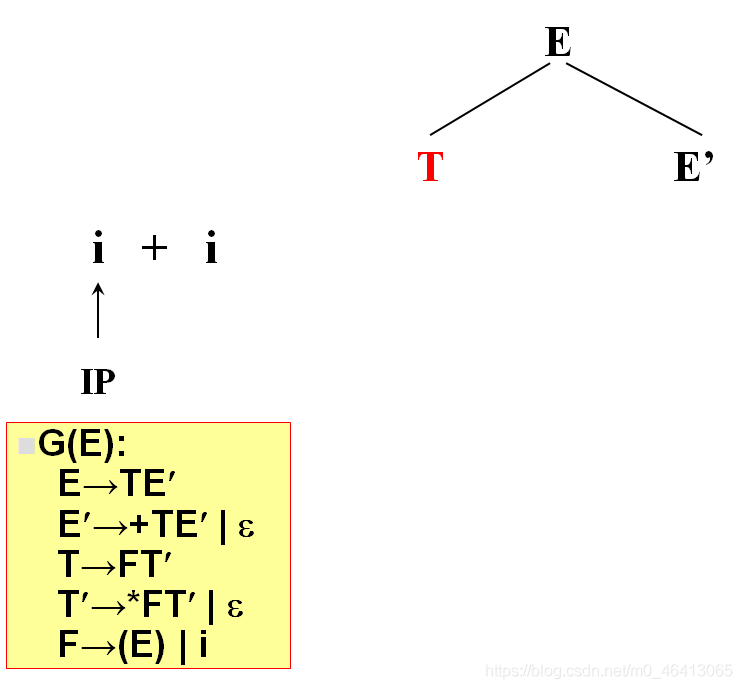
T為非終結符,對T進行擴展,T只有唯一的候選F,T’
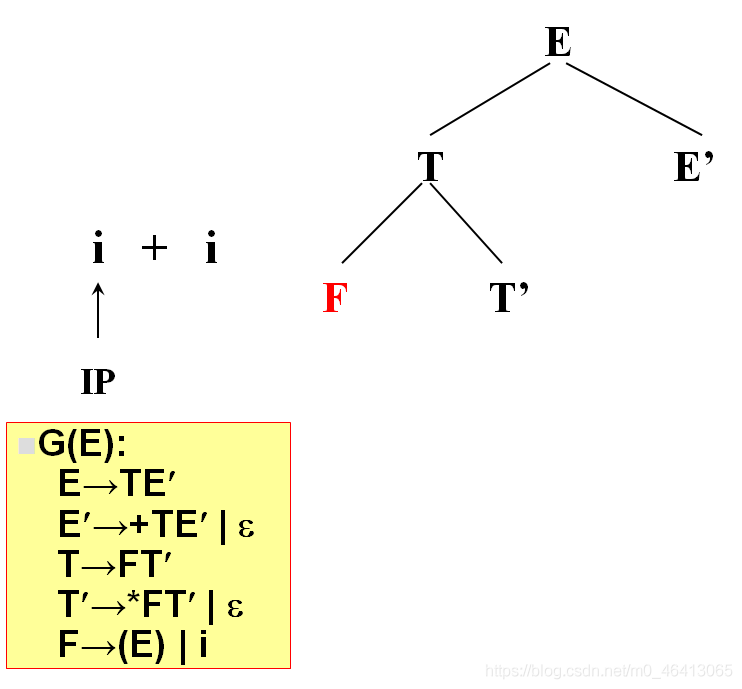
由F匹配i,F為非終結符,向下擴展,有兩個候選(E)和i,根據當前字符i,選候選,選擇依據為每個候選的FIRST集合,二者分別為(和i,i匹配,選i,與輸入單詞為同一個符號,匹配成功,讀入下一個符號
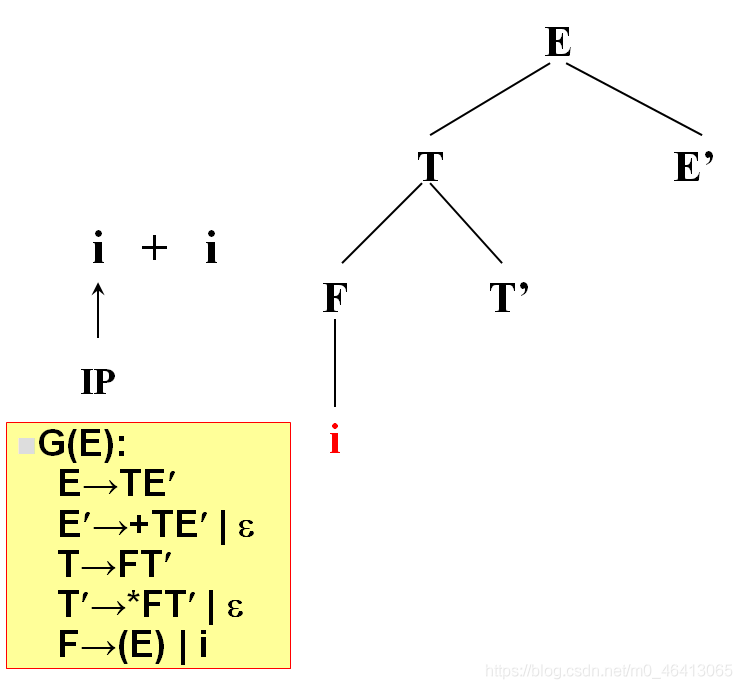
+由T’來匹配,T’有兩個候選,* FT’和ε,由于+無法與 * FT’匹配,因此只能選擇ε
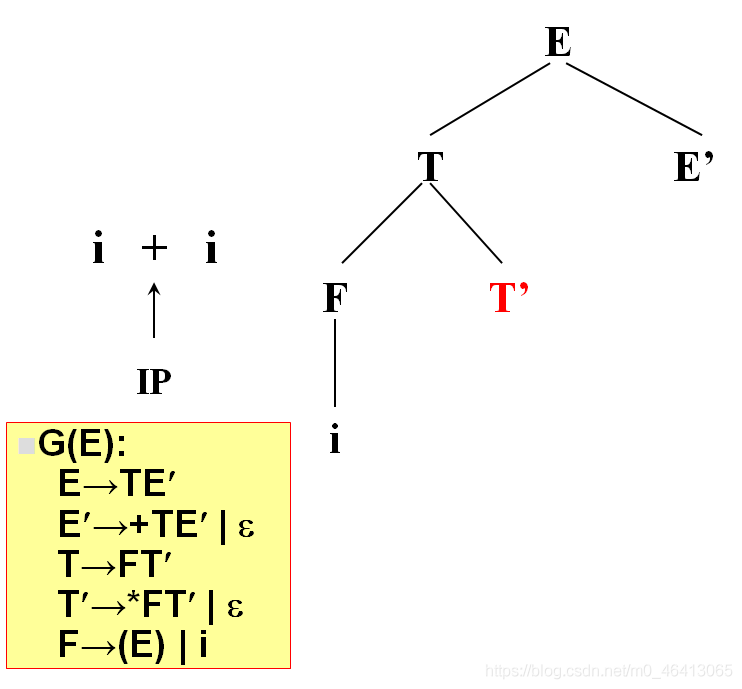
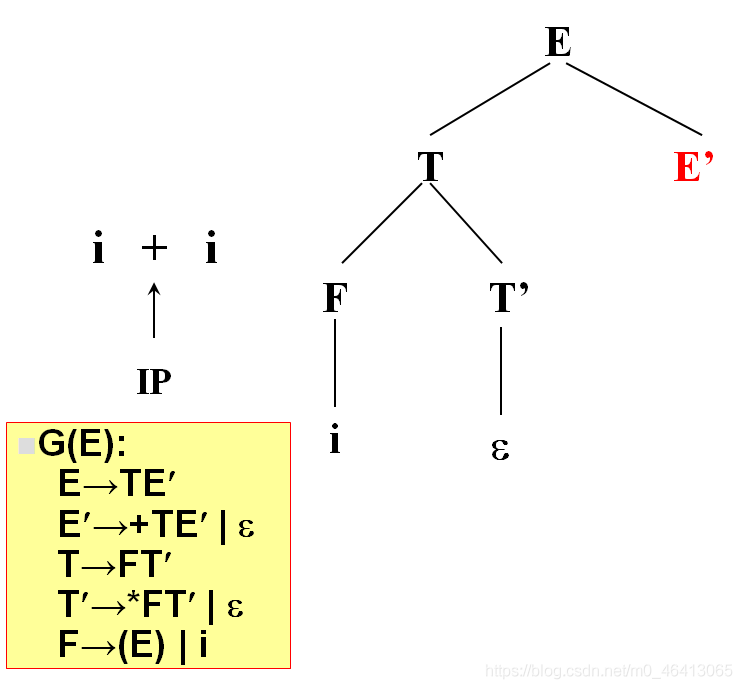
+由E’來匹配,E’有兩個候選,+TE’和ε,+與第一個候選的首符集相同,E’擴展成+TE’,
+匹配成功,讀入下一個字符,
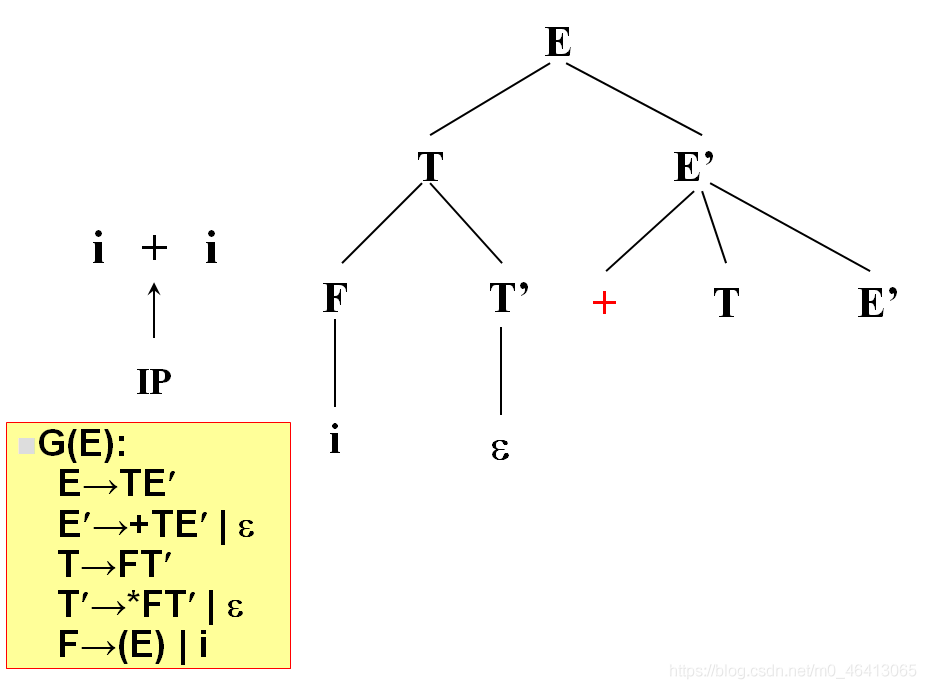
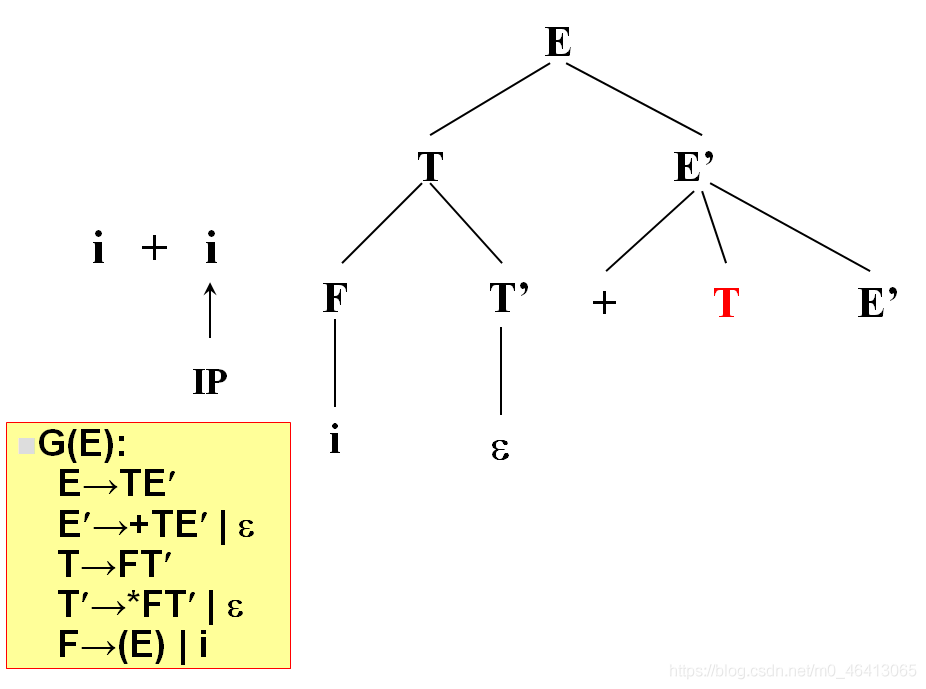
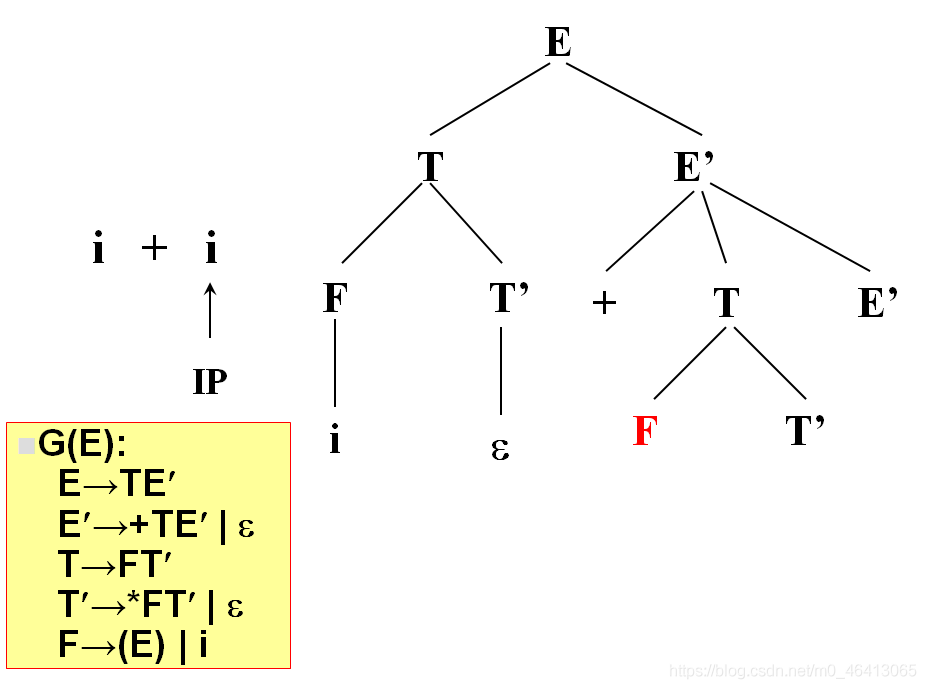
i與T匹配,T擴展FT’,F擴展為i與i匹配成功,
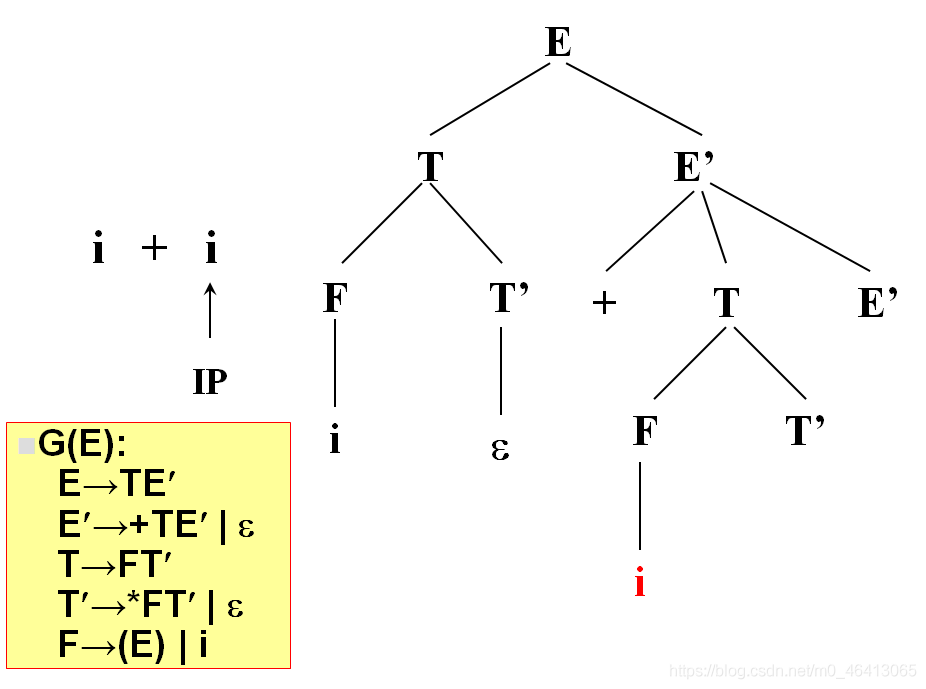
沒有字符了,因此后面都用ε匹配
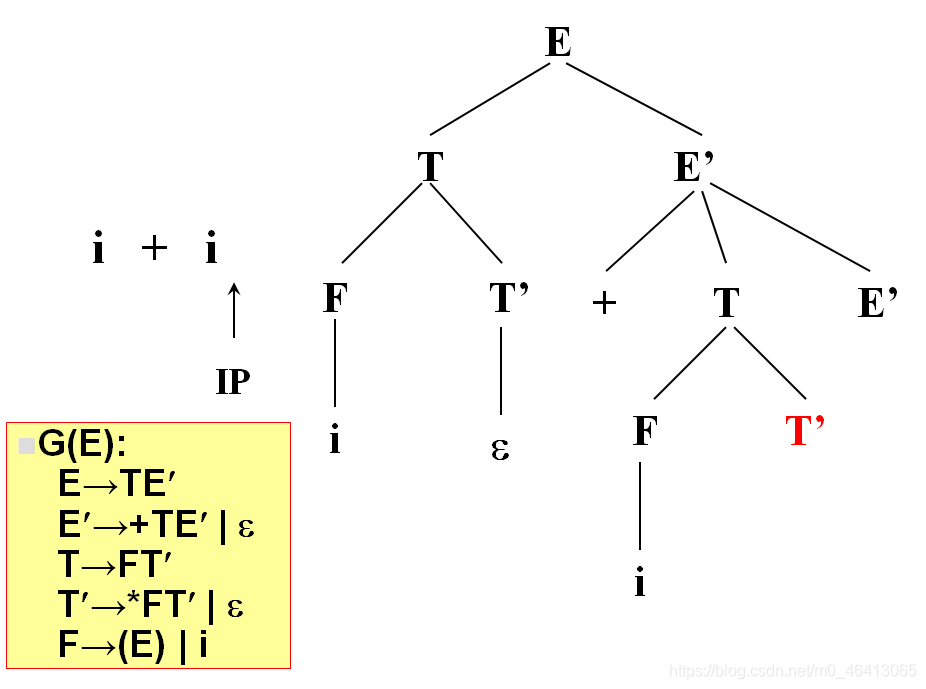
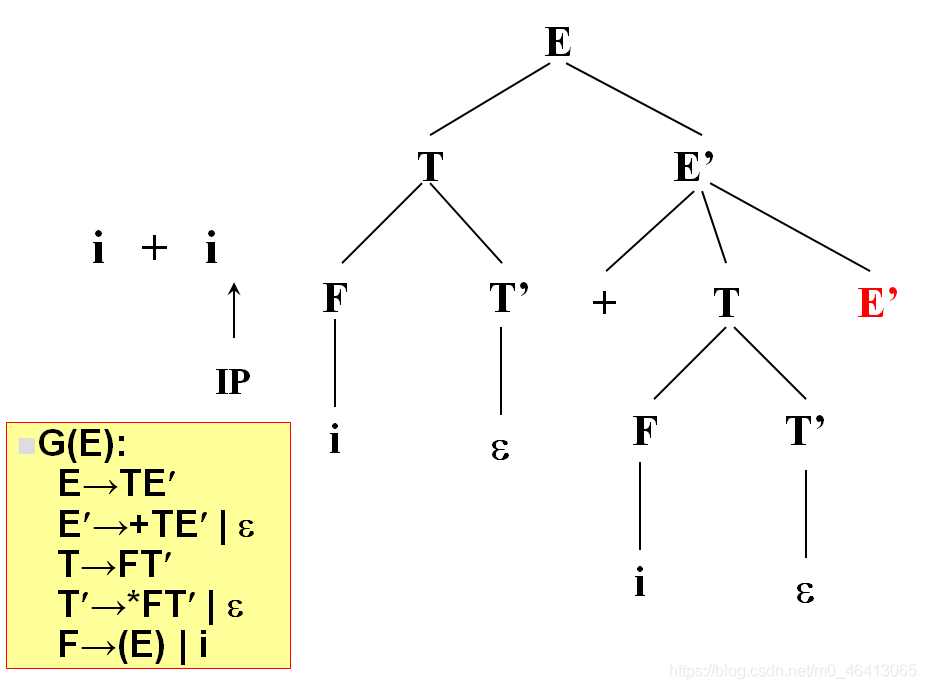
匹配完了,得到分析樹
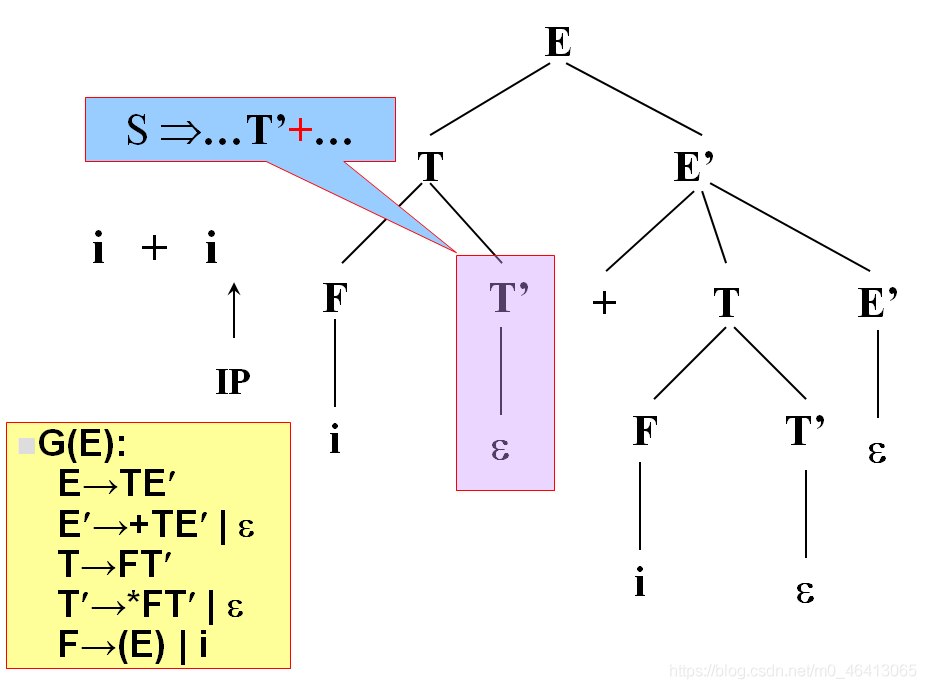
當T’替換成ε時,我希望T’不匹配任何一個單詞,即我希望+由T’后面的去匹配,也就是當時能匹配的成功的條件是:
這個文法存在一種句型,在這個句型里面,+能跟在T’后面,所以T’替換成ε,后面有人去匹配+
下面要把當前的終結符是不是在某一個句型里能跟在非終結符后面這個事情說清楚
定義集合——FOLLOW集合
FOLLOW集合
總結一下,如果一個非終結符A,A有多個候選,當面臨輸入符號a要用A去匹配的時候,且a不在A的任何一個首符集里面,但有一個候選是ε,或首符集有ε(候選推著推著就能變成ε,可以看成ε),但這個并不一定能把A替換成ε,
還有條件,要求a一定在某個句型的時候能夠跟在A的后面,才能選擇A的ε候選去擴展A
如果把和每個非終結符都有這種相關性的終結符構成一個集合——FOLLOW集合
能夠在某個句型里面,跟在A后面的終結符都在A的FOLLOW集合里面,
瞄著ε匹配的條件來的

注意:如果S能夠推出A結尾的一個串的句型,則#(句子末尾)也屬于A的FOLLOW集合,
LL(1)文法

一個文法先消除左遞回,再消除左公共因子,然后再驗證它是不是滿足這三個條件,滿足LL(1)文法的條件就可以用LL(1)分析法:
LL(1)分析法

每一個分析動作都是確定無疑的,這樣就不需要回溯,同時我們文法也沒有左遞回,也不用擔心陷入無限回圈,
FIRST集合和FOLLOW集合的構造
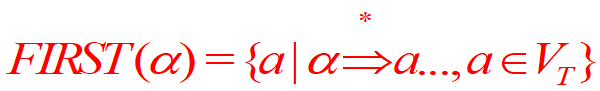
α的FIRST集合,是指這個串能夠推出的任意串中間,排在開頭位置的終結符構成的集合
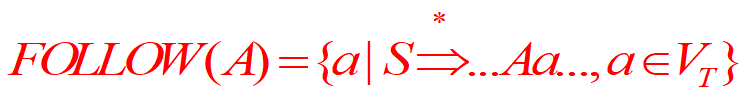
一個非終結符的FOLLOW集合是指在某個句型里面,能夠跟在非終結符后面的終結符構成的集合
FIRST集合的構造
對α的情況進行分類討論
- α長度是1,要么是終結符要么是非終結符
- α長度大于1,由n個符號構成,這n個符號長度要么是終結符,要么是非終結符
FIRST集合定義是基于推導的,如果要計算一個α的所有的FIRST集合里面的元素,理論上要遍歷非常大的推導空間,甚至是無窮大的推導空間,才能保證不會遺漏可能的終結符,
把對無窮推導可能的考察轉換為對有限產生式的反復掃描(因為推導程序都是對有限產生式的反復使用),對有限產生式的反復掃描從而找到FIRST集合里面的元素,
構造每個文法符號的FIRST集合

注,從第一個產生式開始,判斷三個條件,更新FIRST集合,再處理下一個產生式,再處理下一個產生式,到最后一個產生式,如果從第一個產生式到最后一個產生式的考察程序中,有任意一個符號的FIRST集合發生變化,都要重新從第一個產生式再次考察,直到考察到最后一個產生式,
直到從第一個產生式掃描到最后一個產生式,沒有任何一個FIRST集合發生變化了(哪怕只有一個符號的FIRST集合發生變化,都要重頭開始掃描)
構造任何符號串的FIRST集合
先把X1FIRST集合中的ε拿掉

FOLLOW集合的構造
一個非終結符的FOLLOW集合是指在任何一個句型當中能夠跟在非終結符后面的終結符構成的集合
FOLLOW集合的定義也是跟推導相關,也涉及到非常大都推導空間,或者是無窮大的推導空間的考察,他的構造的基本思想也是和FIRST集合一樣,把對無窮推導可能的考察轉換為對有限產生式的反復掃描(因為推導程序都是對有限產生式的反復使用),來計算每一個非終結符的FOLLOW集合,

注,從第一個產生式開始,進行掃描,看看滿足這三步中的哪一步,滿足哪一步就修改相應的FOLLOW集合,再處理下一個產生式,再處理下一個產生式,到最后一個產生式,如果從第一個產生式到最后一個產生式的考察程序中,只要有任意一個非終結符的FOLLOW集合發生變化,都要重新從第一個產生式開始到最后一個產生式再次掃描,直到從第一個產生式掃描到最后一個產生式,在整個這一遍的程序中沒有任何一個FOLLOW集合發生變化了(哪怕只有一個符號的FOLLOW集合發生變化,都有可能導致其他的發生變化,都要重頭開始掃描)
舉例

構造FIRST集合(詳細步驟)
回顧構造方案:

挨個分析,初始時 ,每個非終結符的FIRST集合為空

根據FIRST集合計算演算法
處理第一個產生式:E→TE’
符合演算法第3大步
第一小步:

則把FIRST(T)中的所有非ε-元素都加到FIRST(E)中;
但FIRST(T)目前沒有元素,沒法加
第二小步:
但FIRST(T)目前不確定有沒有ε,所以也沒有變化
處理第二個產生式:E’→+TE’| ε
根據第一個候選+TE’
將加號加入FIRST(E’)

根據第二個候選:ε


處理第三個產生式:T→FT’
符合演算法第3大步
第一小步:
則把FIRST(F)中的所有非ε-元素都加到FIRST(T’)中;
但FIRST(F)目前沒有元素,沒法加
處理第四個產生式:T’→FT’| ε
將加入FIRST(T’)

根據第二個候選:ε

處理第五個產生式(最后一個):F→(E)| i
將 ( 和 i 加入FIRST(F)中

再從頭到尾再把產生式掃描一遍
也就是第二遍的程序
在這一遍中
處理第三個產生式:T’→FT’
符合演算法第3大步
第一小步:
則把FIRST(F)中的所有非ε-元素都加到FIRST(T’)中;

其余沒變化,
也就是第二遍掃描,FIRST集合發生了變化,還得重新再掃描一遍
在第三遍掃描中
處理第一個產生式:E→TE’
符合演算法第3大步
第一小步:
則把FIRST(T)中的所有非ε-元素都加到FIRST(E)中;
第三遍的時候FIRST(E)發生了變化,因此再掃描一遍
第四遍掃描,所有FIRST集后都沒有發生變化,可以停止
構造FOLLOW集合(詳細步驟)
回顧構造方案:

對于非終結符 E
這是文法的開始符號,按照演算法的第一個步驟,#應該在E的FOLLOW集合中,然后看每個產生式的定義
E→TE’
符合演算法第二步驟模式:

α為空,B為T,E’為β
FIRST(E’)={+, ε}
FIRST(E’)/{ε}={+}
得到

注意,在求FOLLOW集合的程序中一個產生式可以套上演算法的2/3步多種模式,因此需要格外小心反復檢查
E→TE’
也符合演算法第3步驟模式:

意味著FOLLOW(E)集合中的元素要加到FOLLOW(E’)中

同時又符合第三步驟或的情況
E為A,α為空,B為T,E’為β
且正好ε∈FRIST(E’),所以到時候推到的時候E’可能會推沒了,因此FOLLOW E的也能FOLLOW T,所以演算法 FOLLOW(E)集合中的元素要加到FOLLOW(T)

對于E’定義:E’→+TE’| ε
符合演算法第二步驟模式:
α為+,B為T,E’為β
FIRST(E’)={+, ε}
FIRST(E’)/{ε}={+}
這個跟剛剛第一步的程序一樣,沒有變化
E→TE’
也符合演算法第3步驟模式:
A→αB模式,α為+T,B為E’
意味著FOLLOW(E‘)集合中的元素要加到FOLLOW(E’)中
A→αBβ模式,α為+,B為T,E’為β
FIRST(E’)中有ε,把FOLLOW(E‘)集合中的元素要加到FOLLOW(T)中
但上述兩步沒變化
E’還有一個候選式ε,它隊FOLLOW集合的運算沒有直接影響,
處理第三個產生式:T→FT’
這個告訴我們FOLLOW T的都可以FOLLOW T’
由演算法的第三步:
把FOLLOW(T)加入導FOLLOW(T’)中

由于ε∈FIRST(T’),由步驟3的第二種情況,
FOLLOW T的還能FOLLOW F

同時T→FT’還符合步驟2
即FIRST(T’)中的非空符號都能FOLLOW F

再檢查第4個產生式:T’→*FT’|ε
由演算法的2,3步發現沒有變化,
再檢查第5個產生式:F→(E)| i
根據演算法第二大步

根據演算法的第三大步
再進行第二遍檢查:
E→TE’
也符合演算法第3步驟模式:
意味著FOLLOW(E)集合中的元素要加到FOLLOW(E’)中

同時又符合第三步驟或的情況
E為A,α為空,B為T,E’為β
且正好ε∈FRIST(E’),所以到時候推到的時候E’可能會推沒了,因此FOLLOW E的也能FOLLOW T,所以演算法 FOLLOW(E)集合中的元素要加到FOLLOW(T)

對于E’定義:E’→+TE’| ε(第1,2遍都沒有任何變化)
符合演算法第二步驟模式:
α為+,B為T,E’為β
FIRST(E’)={+, ε}
FIRST(E’)/{ε}={+}
這個跟剛剛第一步的程序一樣,沒有變化
E→TE’
也符合演算法第3步驟模式:
A→αB模式,α為+T,B為E’
意味著FOLLOW(E‘)集合中的元素要加到FOLLOW(E’)中
A→αBβ模式,α為+,B為T,E’為β
FIRST(E’)中有ε,把FOLLOW(E‘)集合中的元素要加到FOLLOW(T)中
但上述兩步沒變化
E’還有一個候選式ε,它隊FOLLOW集合的運算沒有直接影響,
處理第三個產生式:T→FT’
這個告訴我們FOLLOW T的都可以FOLLOW T’
由演算法的第三步:
把FOLLOW(T)加入導FOLLOW(T’)中
由于ε∈FIRST(T’),由步驟3的第二種情況,FOLLOW T的還能FOLLOW F

同時T→FT’還符合步驟2
即FIRST(T’)中的非空符號都能FOLLOW F
沒有變化
再檢查第4個產生式:T’→*FT’|ε
由演算法的2,3步發現沒有變化,
再檢查第5個產生式:F→(E)| i
根據演算法第二大步
也沒有任何變化
由于第二遍FOLLOW集合發生變化,因此還需檢查第三遍
發現第三遍沒有變化,FOLLOW集合生成結束,

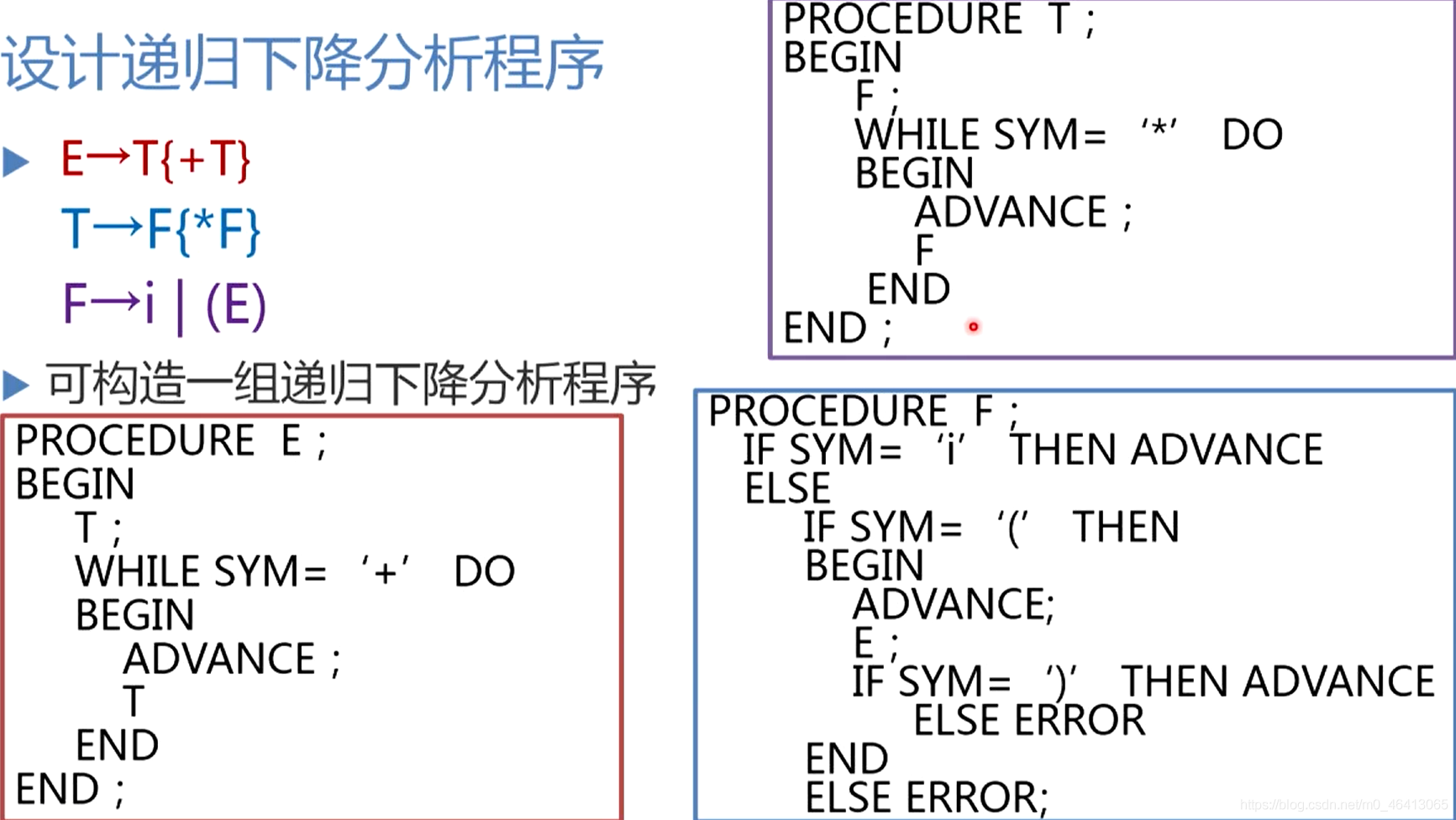
4.4 遞回下降分析分析程式構造
構造不帶回溯的自上而下分析程式
- 要消除文法的左遞回性
- 克服回溯

- 構造不帶回溯的自上而下分析器
- 分析程式由一組遞回程序組成,文法中每個非終結符對應一個程序;所以這樣的分析程式稱為遞回下降分析器,(因為文法的定義通常是遞回的)
定義全域程序和變數:
- ADVANCE,把輸入串指示器IP指向下一個輸入符號,即讀入一個單字符號
- SYM,IP當前所指的輸入符號
- ERROR,出錯處理子程式

看當前所指的輸入符號是不是在FIRST(TE’)中
- 如果當前所指的輸入符號是在FIRST(TE’)中
選擇TE’這個候選去擴展A 選擇這個候選去擴展A,相當于呼叫非終結符T所對應的子程式T去完成前一部分輸入串的匹配推導,
當T匹配擴展完了后,呼叫非終結符E’所對應的子程式E’去完成后續輸入串的匹配推導當T,E’都擴展匹配完了后,A就識別完了
如果當前所指的輸入符號不是在FIRST(TE’)中,則判斷當前單詞是不是在FIRST(BC)中,
- 如果當前所指的輸入符號是在FIRST(BC)中
選擇BC這個候選去擴展A,相應的推導/識別就通過呼叫語法單位B,C所對應的子程式來完成語法單位B,C的匹配,如果B,C匹配成功,A的匹配完畢,
如果當前單詞既不在FIRST(TE’)中,也不在FIRST(BC)中,那我們是不是該選擇ε呢?
按照LL(1)分析思路,應該首先判斷當前的單詞符號是不是在FOLLOW(A)中
- 如果當前的單詞符號是不是在FOLLOW(A)中
即可以把A替換成ε,選擇ε去擴展A相當于什么都不做,
- 如果當前單詞既不在FIRST(TE’)中,也不在FIRST(BC)中,也不在FOLLOW(A)中,就應該報錯,




文法的另一種表示法和轉換圖
擴充的巴科斯范式

引入上述元符號的文法亦稱擴充的巴科斯范式

語法圖
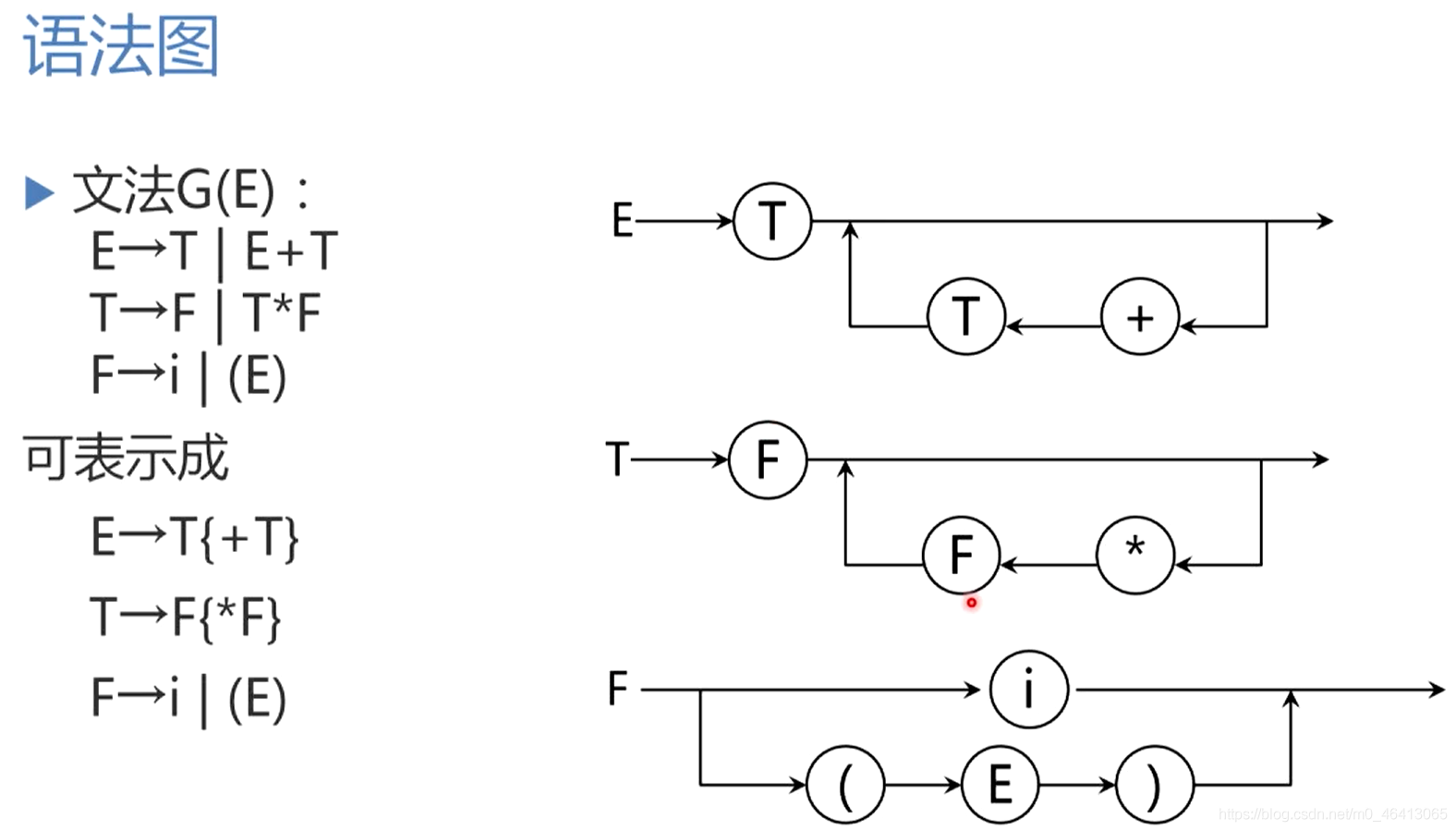
用巴科斯范式來描述文法對于實作遞回下降程式非常方便,
4.5 預測分析程式
預測分析程式作業原理
預測分析程式或LL(1)分析法:
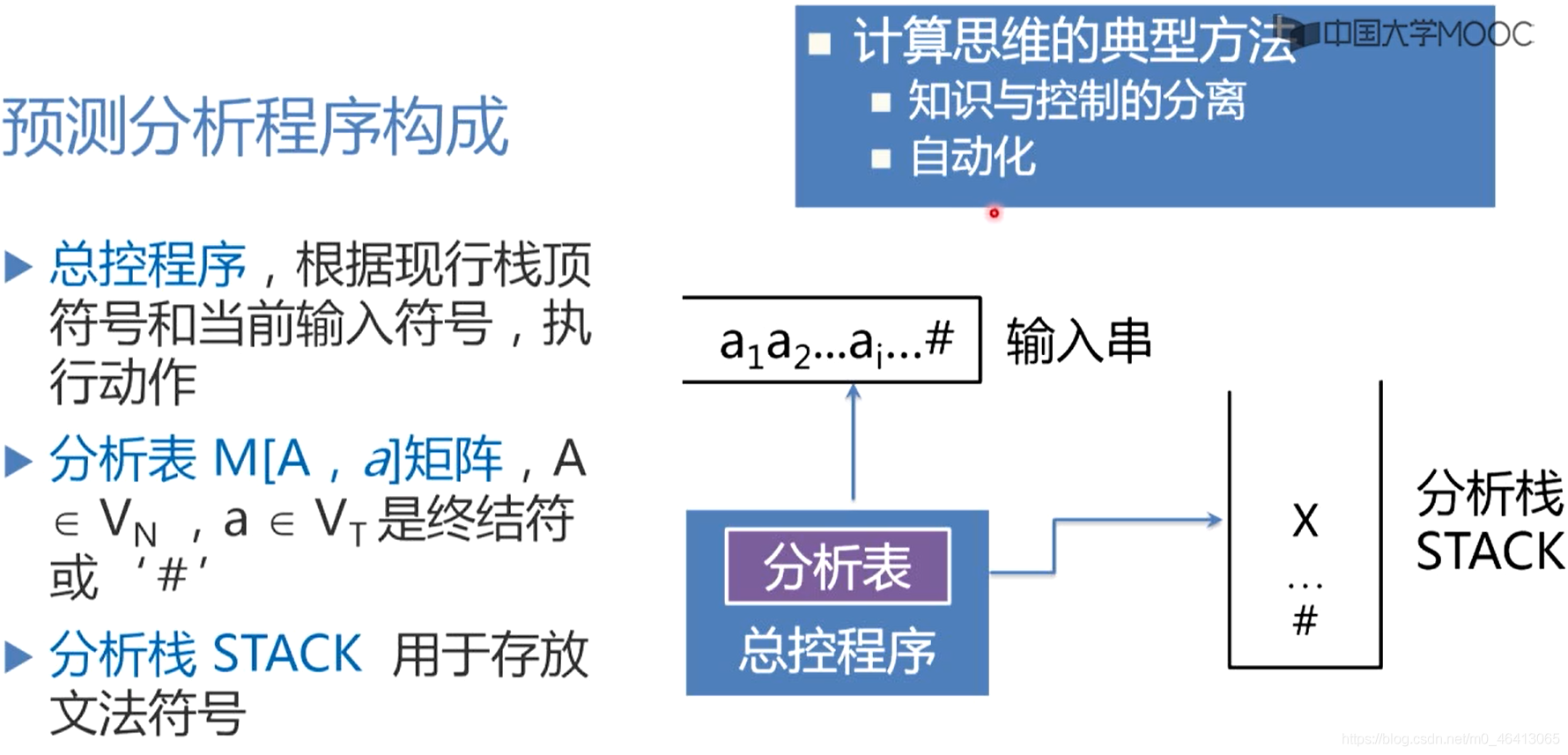
總控程式
通用的控制功能,總是根據現行堆疊頂符號和當前輸入符號,查找分析表,執行分析表指定的動作,
分析表
是一個二維矩陣,也稱為預測分析表,負責指導分析程式如何對堆疊頂符號進行操作,特別是指導分析程式面臨堆疊頂符號是非終結符的時候,預測/選擇非終結符是哪個候選,對它進行擴展,分析表是一個具有指導分析能力的資料結構,它是個二維矩陣,第一維下標是文法的非終結符,第二維的下標是文法的終結符(句末符#也看成一個特殊的終結符),而二維矩陣的元素指明了當堆疊頂是非終結符A,面臨輸入符號是終結符a時,應該執行什么動作,用哪個候選進行擴展,如果是進行擴展的話,分析程式就會把這個候選壓到堆疊里面,替換原來的非終結符,也就是說把堆疊頂的非終結符替換為它的候選,所以說總控程式總是根據現行堆疊頂的符號和當前的輸入符號,來操作分析堆疊STACK
分析堆疊 STACK 用于存放需要匹配的文法符號,注意,堆疊的底部有一個文法符號,表示堆疊的底,輸入串的最后,有一個#代邊輸入串的結束
注意,所有與語法相關的知識都在分析表中,控制程式/總控程式對不同的語法分析程式來說都是通用的
預測分析程序
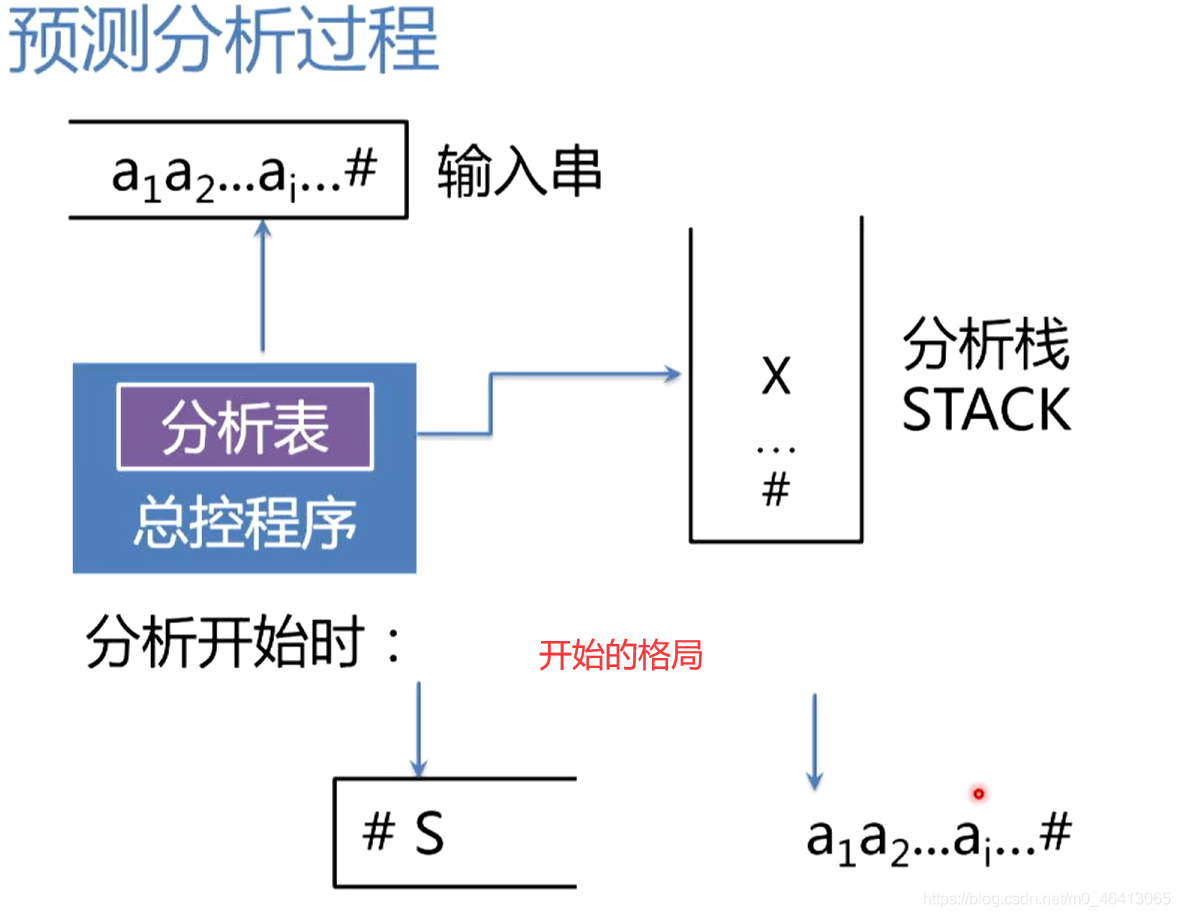
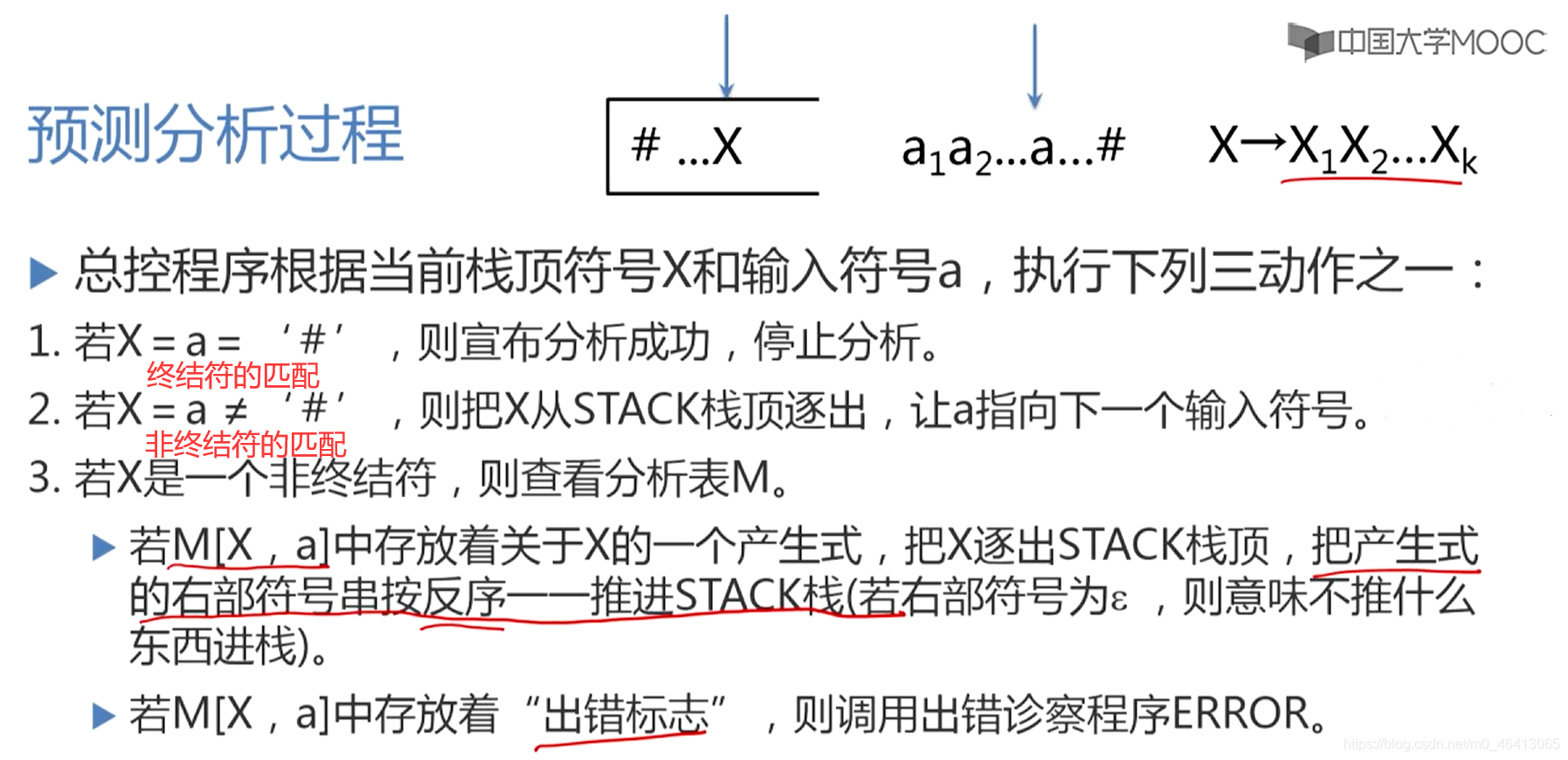
總控程式的基本實作


預測分析示例
看分析表,第一維的下標為非終結符,
第二維的下標都是終結符
每個格子里面要么是產生式,要么為空(意味著放的是出錯標志)
同一行放的是同一個非終結符的定義
(關于它的第一維下標的終結符的定義式)
通過四元組描述每一步分析程序變化:

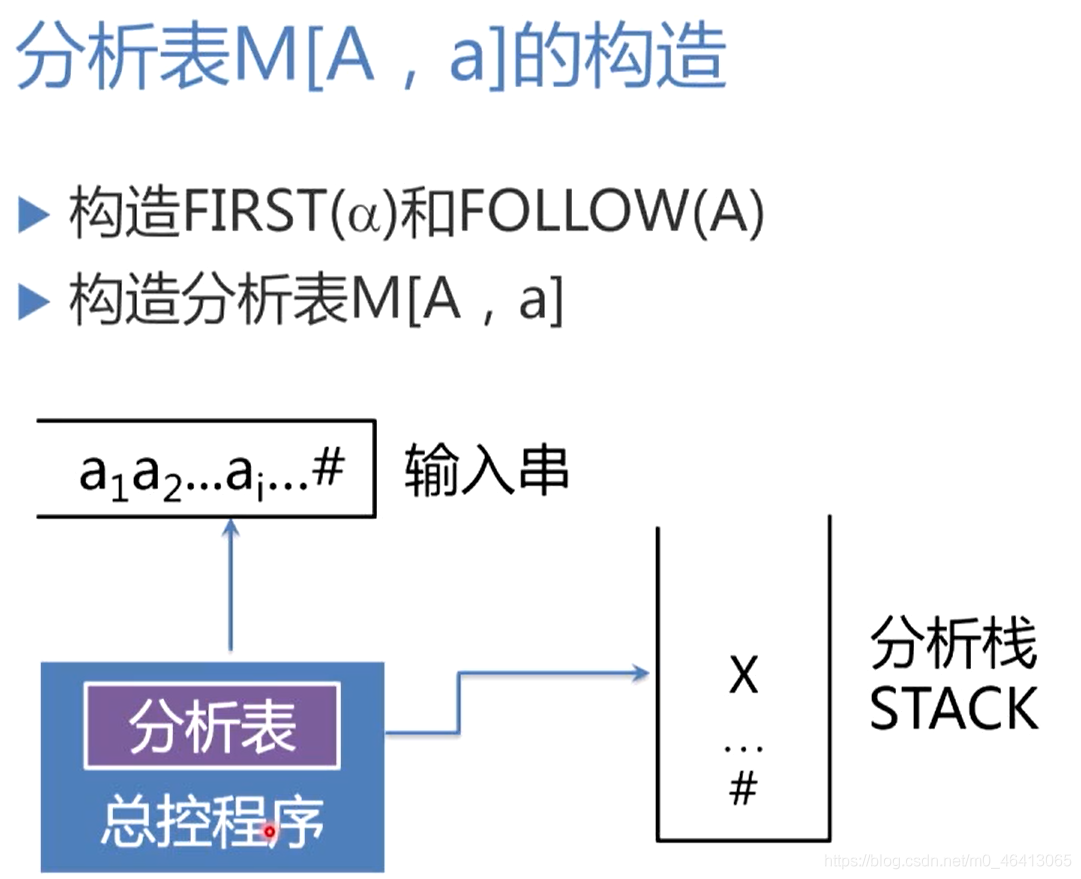
預測分析表的生成

LL(1)文法與二義性

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272826.html
標籤:AI