Developer&Author:Robit Wong, Apr 3rd 2021
User_Objects:搭建全分布環境過于占用電腦資源導致實驗行程困難的同學
Postscript:包含對云服務器搭建Hadoop偽分布的說明
CentOS虛擬機_搭建Hadoop偽分布環境
前言說明
在執行本教程前,需要具備以下條件
- Linux_CentOS 系統的靜態IP已設定完畢
- Linux_CentOS執行ping www.baidu.com 結果為真,即可接入互聯網
- 可通過SSH工具遠程登錄Linux_CentOS
- 已安裝好用的SSH遠程登錄管理工具(如Xshell [學生版不收費])
附:下載Xshell & Xftp 遠程登錄管理工具說明,這是極其好用的SSH遠程登錄管理工具
學生版申請頁面https://www.netsarang.com/zh/free-for-home-school/
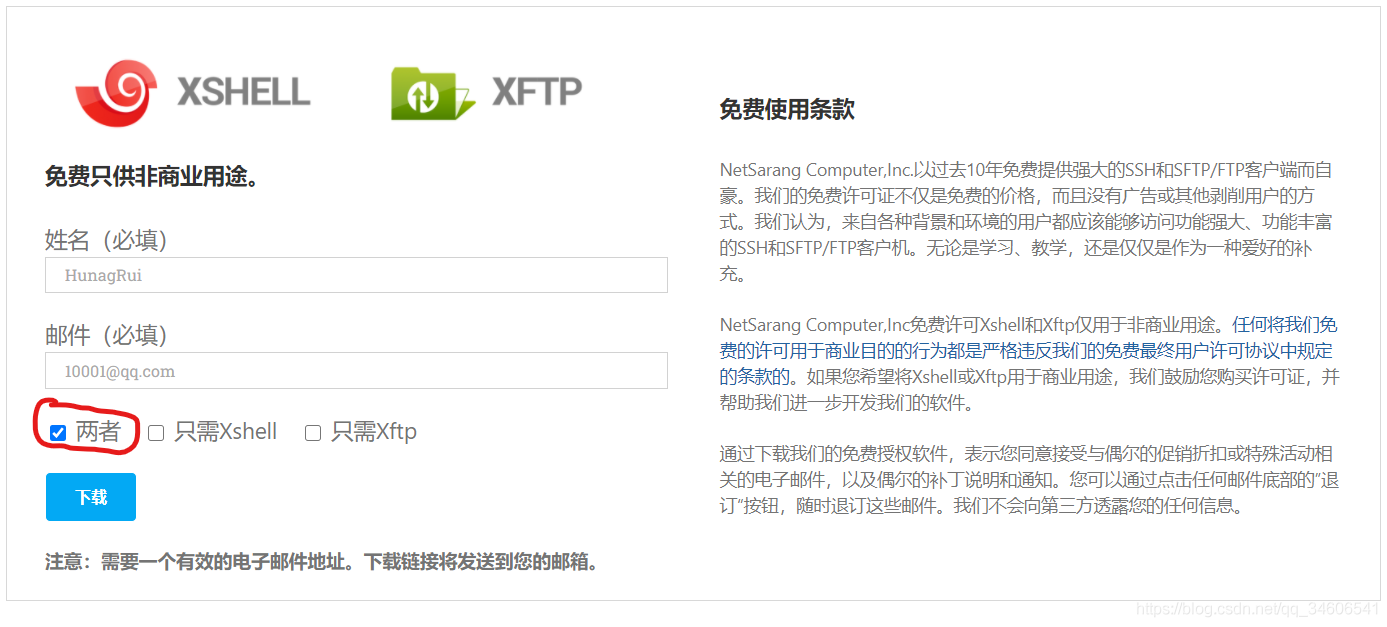
郵件一欄填寫自己的QQ郵箱即可,如標紅位置,選擇兩者,點擊下載后,你的郵箱會收到兩封郵件,這兩封郵件分別是Xshell和Xftp的免費下載使用鏈接,學生版性能無區別,只是限制Linux終端遠程登錄數量,Xftp是遠程檔案可視化管理工具,可方便下載或上傳或編輯檔案,Xshell則只是終端命令列工具,但可以通過Xshell內部直接點開Xftp并自動定位到當前作業目錄,非常方便,
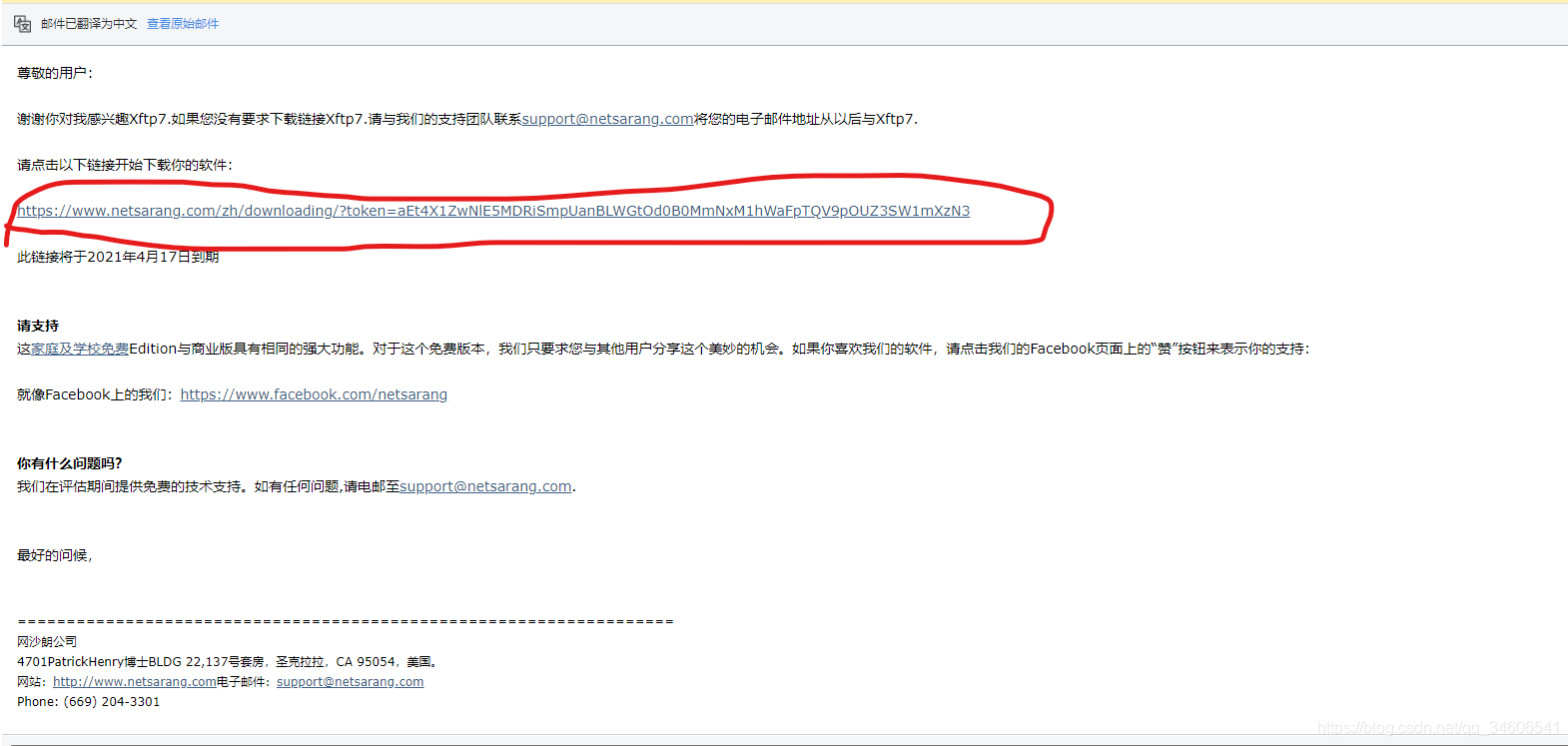
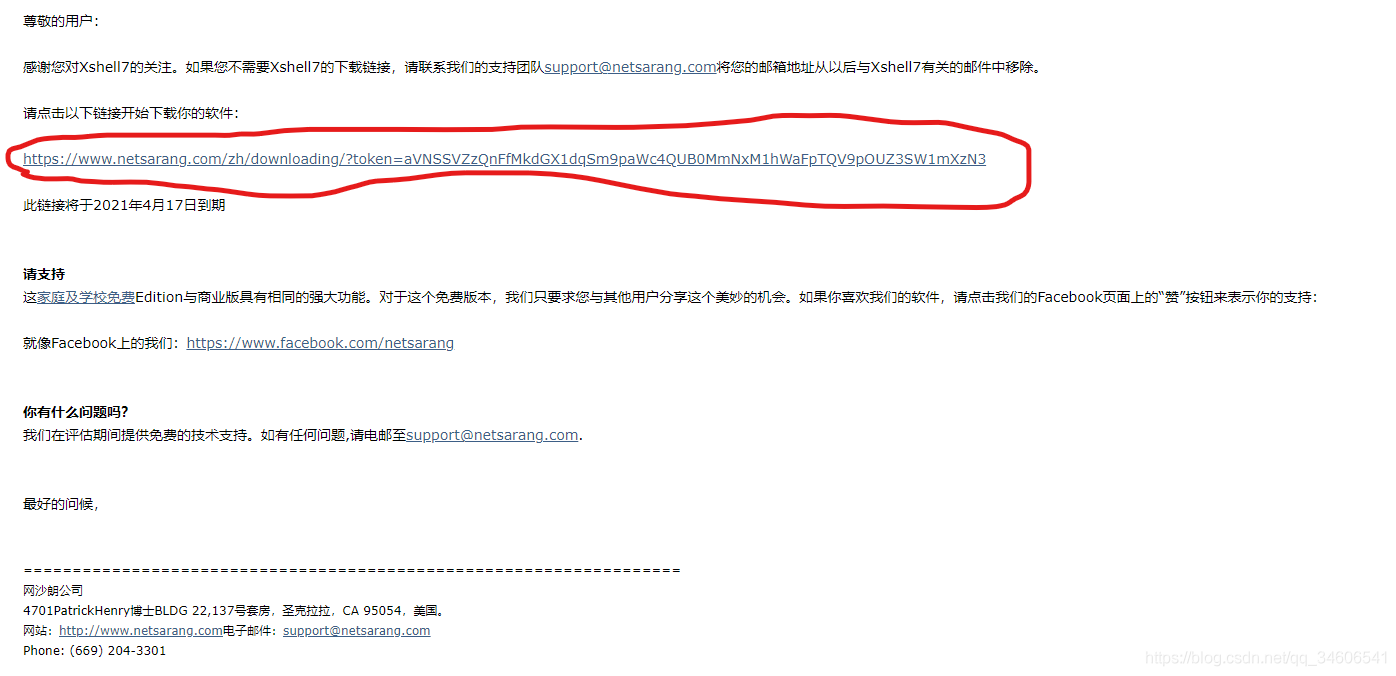
如上圖為軟體商發送的軟體下載鏈接,上圖郵件是自動翻譯后的界面,原始郵件是英文的,見標紅的地方,分別點擊即可開始下載兩個軟體,下載后正常安裝即可,關于Xshell和Xftp的使用請自行百度,不在贅述!
正式配置教程
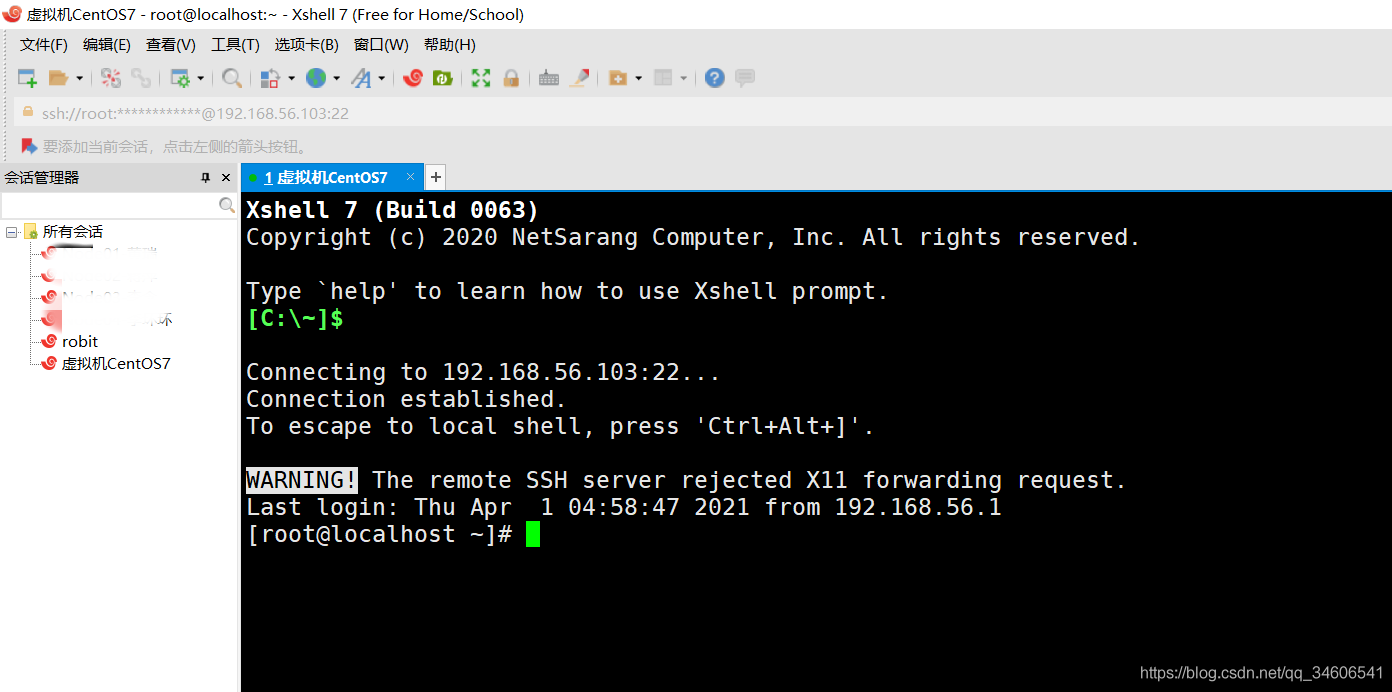
1、在虛擬機客戶端啟動CentOS后,無需在虛擬機客戶端完成Linux登錄,可直接通過Xshell SSH工具遠程登錄Linux,如下圖
2、配置/etc/hosts檔案
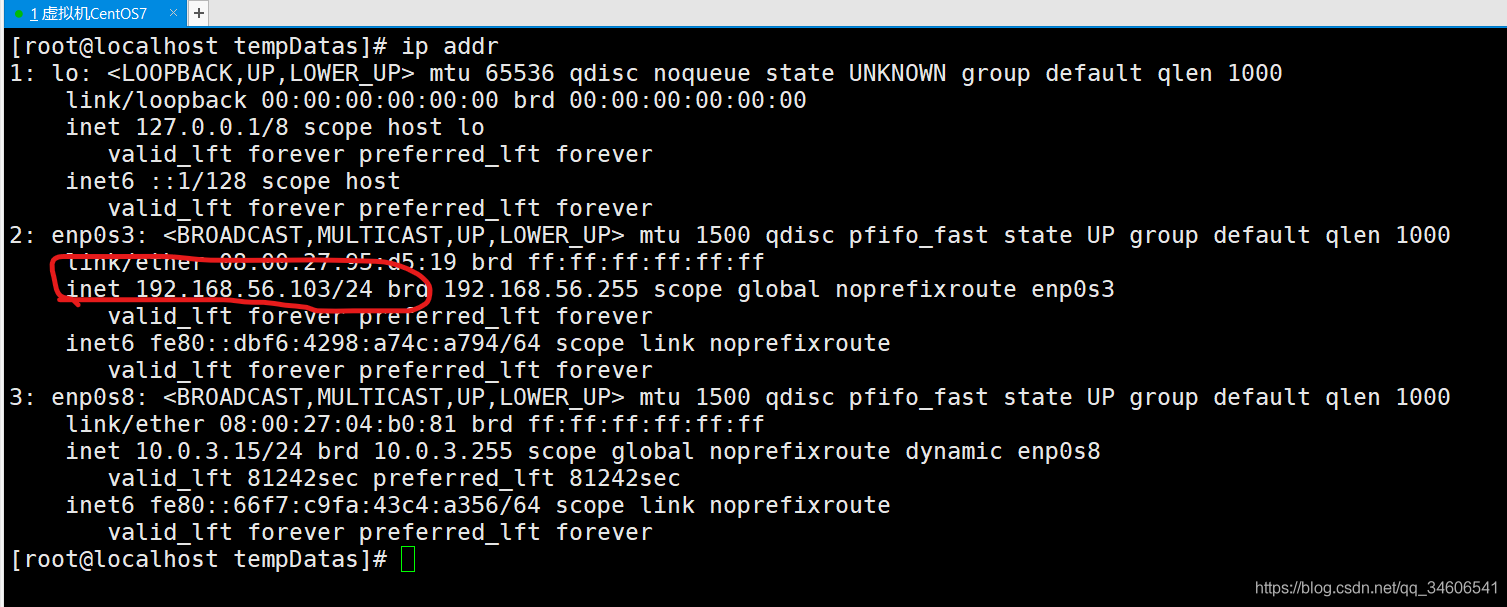
- 靜態IP查看命令ip addr,圈紅為靜態IP
- 主機名的修改可通過編輯 /etc/hostname檔案后重啟Linux系統(reboot)實作
vim /etc/hostname #編輯 /etc/hostname 檔案

注:重啟CentOS會斷開SSH遠程連接,重啟完成后,重新連接即可
- hosts檔案配置
#如我的靜態IP為192.168.56.103,主機名為mainMaster,則添加如下內容
192.168.56.103 mainMaster

提示:如果你使用的是云服務器部署hadoop偽分布,則將靜態IP改為你的內網IP,注意:不是公網IP,要不然你無法正常啟動Hadoop!!
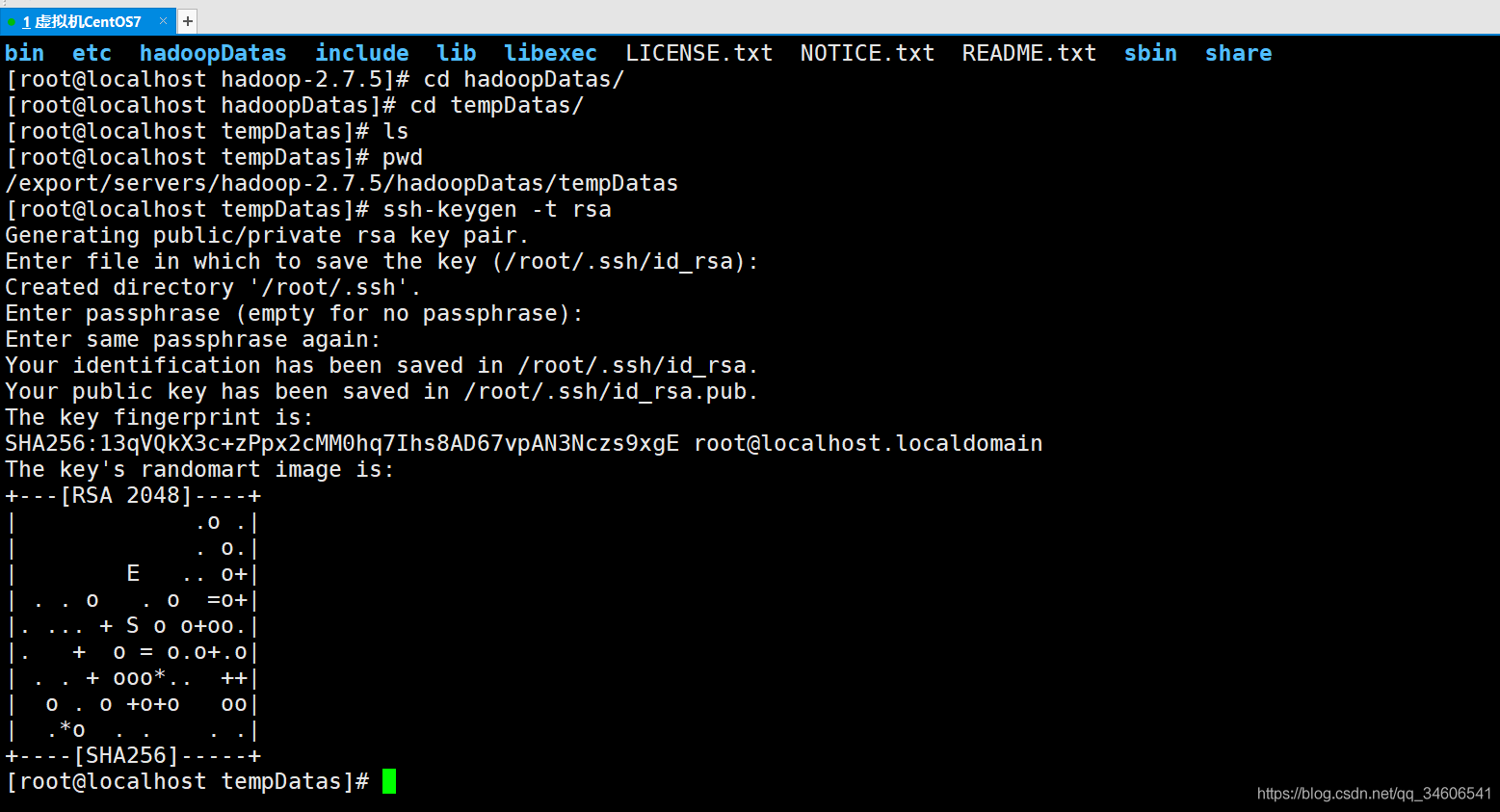
3、設定免密登錄
注:如果不設定免密登錄,在啟動或關閉Hadoop時你會不斷的輸入你的系統密碼,非常麻煩!!!
#鍵入如下命令,連續回車即可
ssh-keygen -t rsa
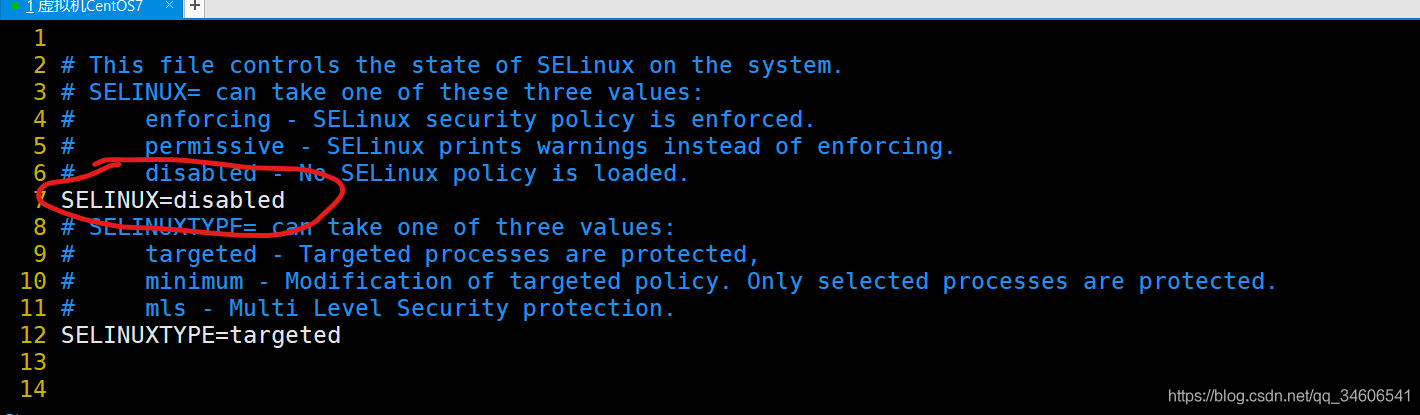
- 關閉SELinux
#鍵入如下命令關閉SELinux
vim /etc/selinux/config #打開組態檔
將SELINUX值修改設為disabled ,SELINUX=disabled,如下圖
- 拷貝公鑰
#拷貝公鑰,格式ssh-copy-id 你的主機名
#如我的主機名為mainMaster,所以鍵入如下命令即可完成公鑰拷貝
ssh-copy-id mainMaster

以上三步驟缺一不可,否則無法完成免密登錄
4、在root用戶下創建Hadoop作業目錄
mkdir -p /export/softwares #JDK和Hadoop軟體安裝包目錄
mkdir -p /export/servers #JDK和Hadoop軟體安裝目錄
- 進入/export/software目錄后,點擊紅圈標注位置即可打開Xftp檔案可視化管理工具,Xftp會自動定位到當前作業目錄
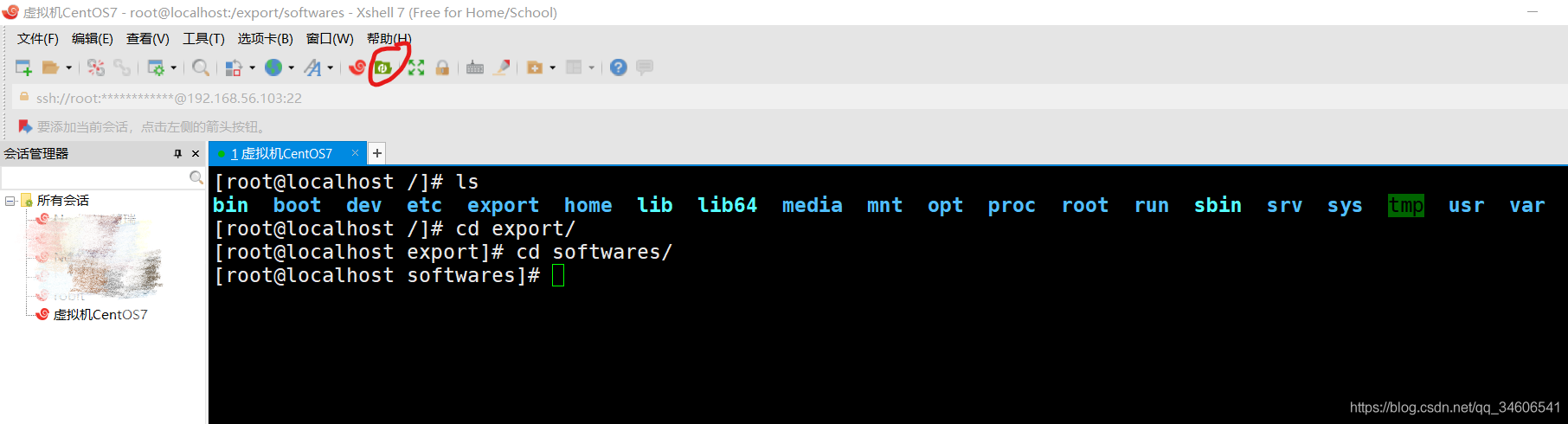
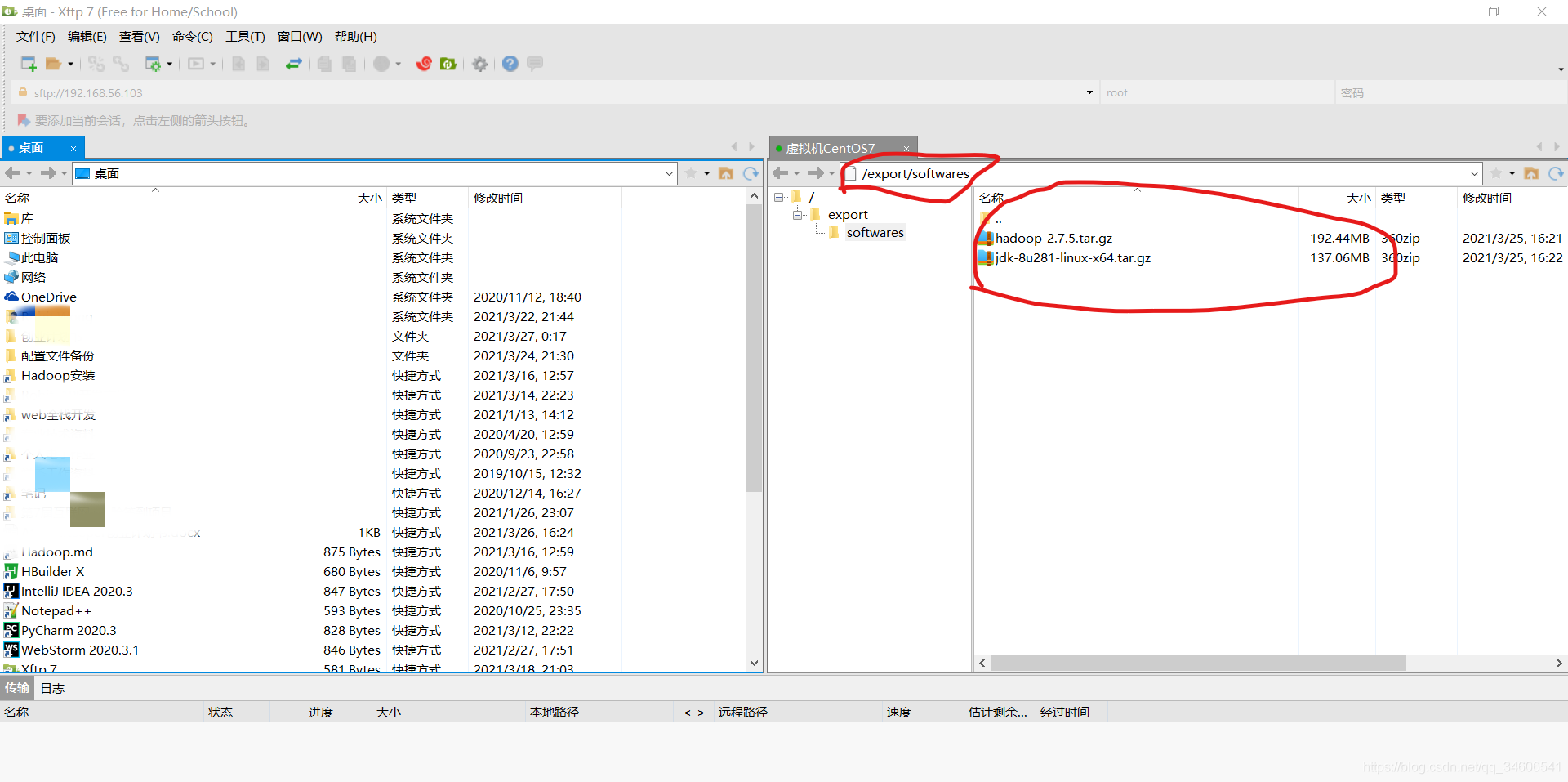
左邊是Windows目錄,右邊是Linux目錄,通過拖動檔案即可完成檔案傳輸,標紅的位置,即為上傳的JDK和Hadoop安裝目錄,這里選用版本為
- java version “1.8.0_281”
- Hadoop版本:2.7.5(已重新編譯)
注:Hadoop最好使用重編譯后的版本,這是為了后續學習更好使用Hadoop,無需知道太多理由!網上沒有資源,以下給出Hadoop和JDK的超星云盤下載鏈接,超星云盤下載速度快,下載完成后通過Xftp工具上傳到/export/softwares目錄即可
超星云盤下載鏈接: http://pan-yz.chaoxing.com/share/info/c8bc5aead19d0457 提取碼 : n7za69
百度網盤下載鏈接: https://pan.baidu.com/s/1Xv9xbQqTEvvM60joeVrd3A 提取碼 : iy46
5、解壓安裝JDK和Hadoop
進入/export/softwares目錄
cd /export/softwares #進入/export/softwares目錄

鍵入解壓命令解壓JDK和Hadoop
#解壓JDk安裝到/export/servers 目錄
tar zxvf jdk-8u281-linux-x64.tar.gz -C ../servers/
#解壓hadoop安裝到/export/servers 目錄
tar zxvf hadoop-2.7.5.tar.gz -C ../servers/
執行完成后進入/export/servers 目錄,可見JDK和Hadoop已成功安裝
cd ../export/servers #從softwares目錄進入/export/servers目錄

6、配置JDK及Hadoop環境變數
方法1:鍵入命令打開編輯 /etc/profile 檔案
#編輯環境變數檔案,沒有vim可使用vi或安裝vim
vim /etc/profile
或
vi /etc/profile
# vim是優點多于vi的Linux檔案編輯器,建議安裝使用
vim安裝配置教程 :https://www.php.cn/blog/detail/21541.html
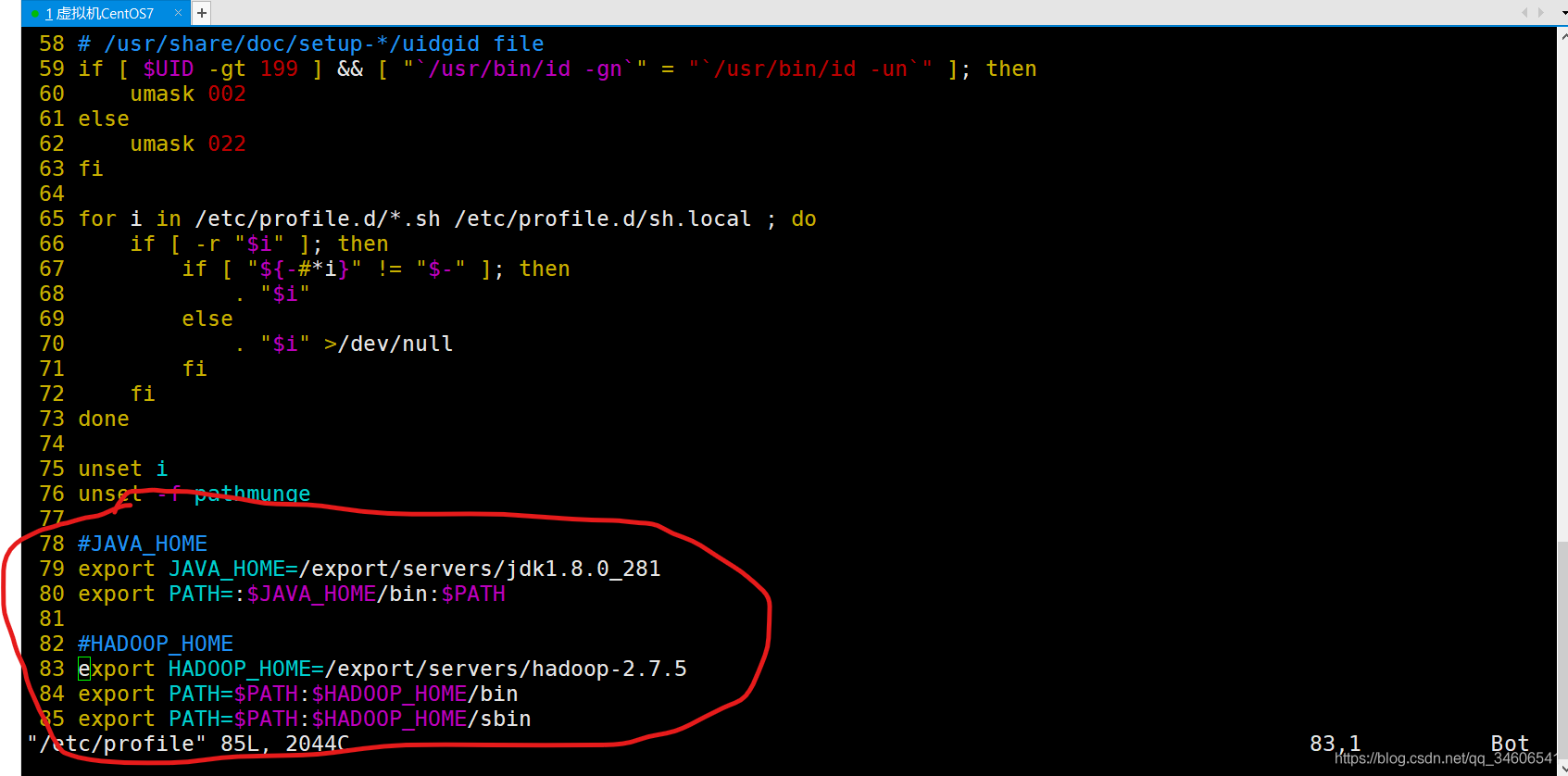
=======復制粘貼以下內容到/etc/profile 檔案末尾,保存退出即可!=========
#JAVA_HOME
export JAVA_HOME=/export/servers/jdk1.8.0_281
export PATH=:$JAVA_HOME/bin:$PATH
#HADOOP_HOME
export HADOOP_HOME=/export/servers/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
:wq #底行模式保存退出/etc/profile檔案
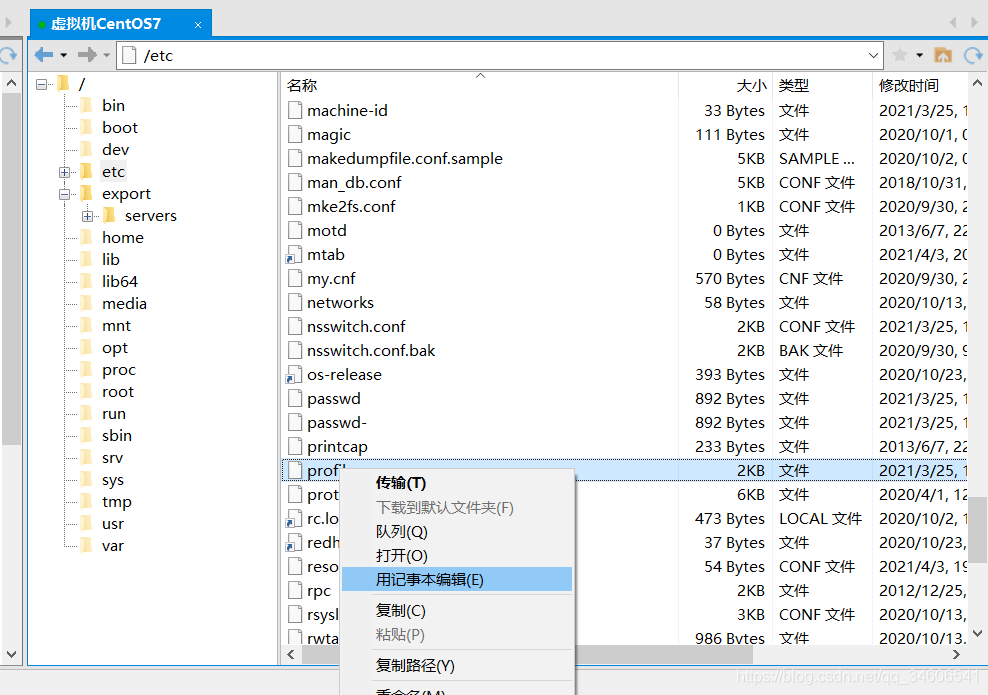
方法2:使用Xftp工具進入etc目錄,定位到profile檔案,點擊滑鼠右鍵,選擇“用記事本編輯”
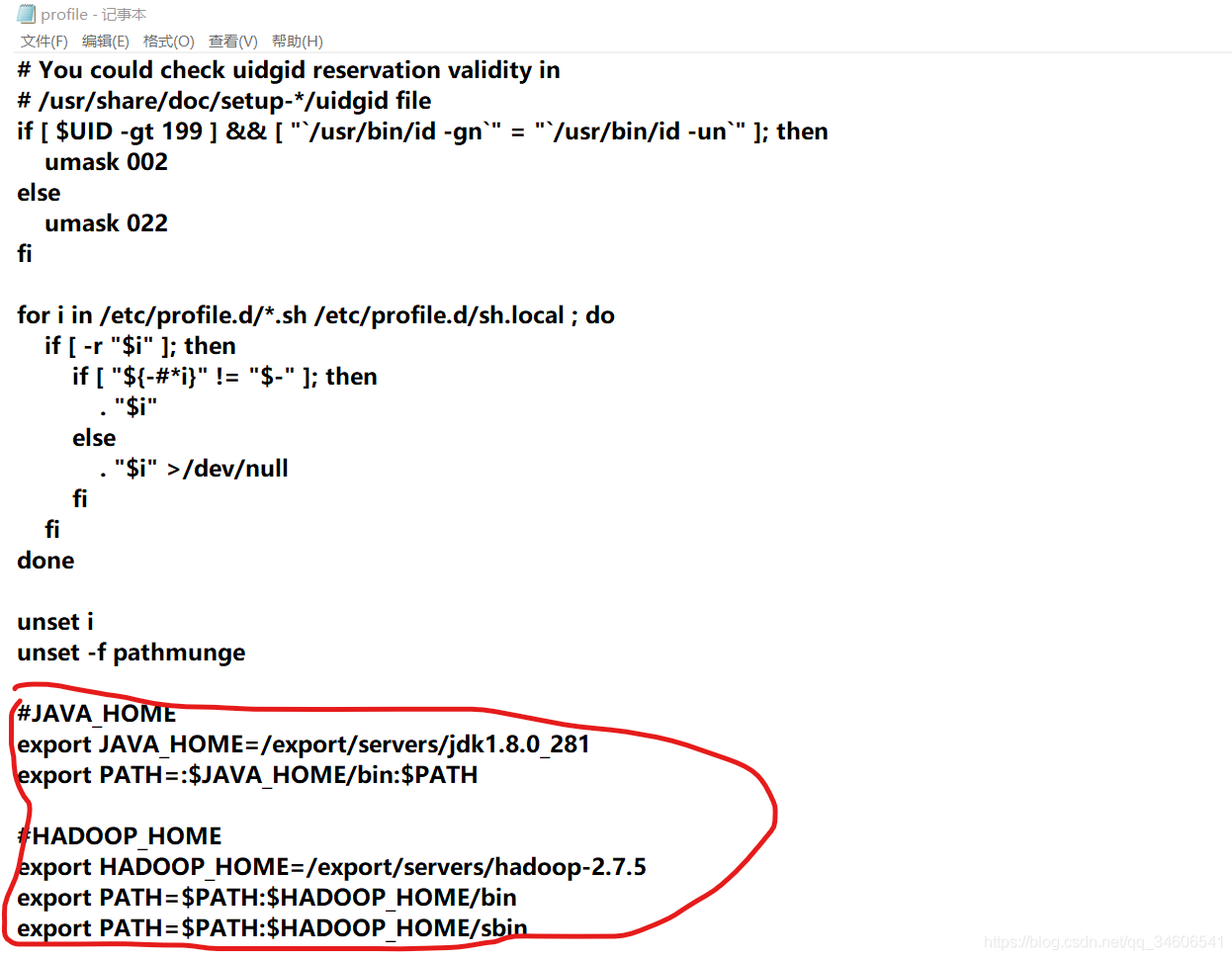
通過方法2,完成環境變數配置后,點擊記事本的保存即可退出,這種方法比較方便
- 鍵入如下命令使環境變數檔案即可生效
source /etc/profile #使環境變數檔案即可生效
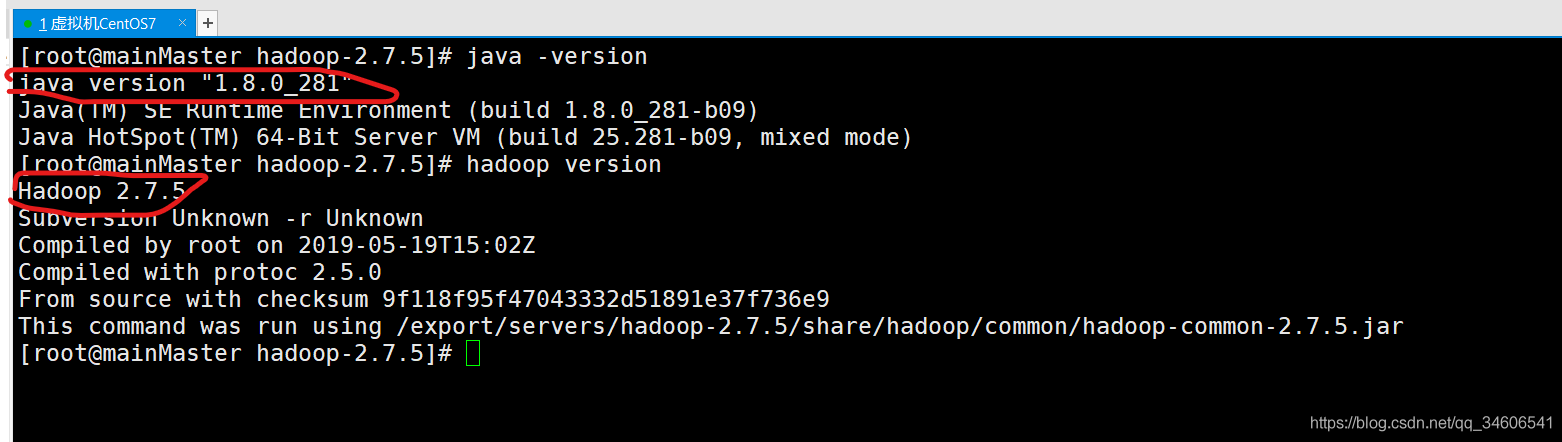
- 鍵入如下命令,可查看JDK和Hadoop的版本,如下圖則代表環境變數配置成功
java -version
hadoop version
7、配置Hadoop
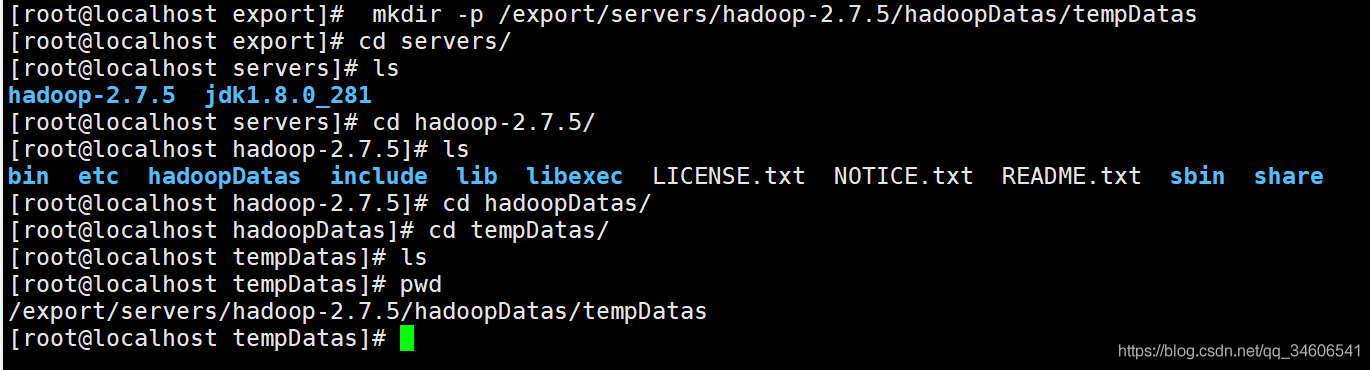
- 創建 hadoop的臨時資料檔案存盤目錄tempDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas
-
修改hadoop-env.sh檔案如下,添加Java路徑到如下位置
# The java implementation to use. export JAVA_HOME=/export/servers/jdk1.8.0_281

-
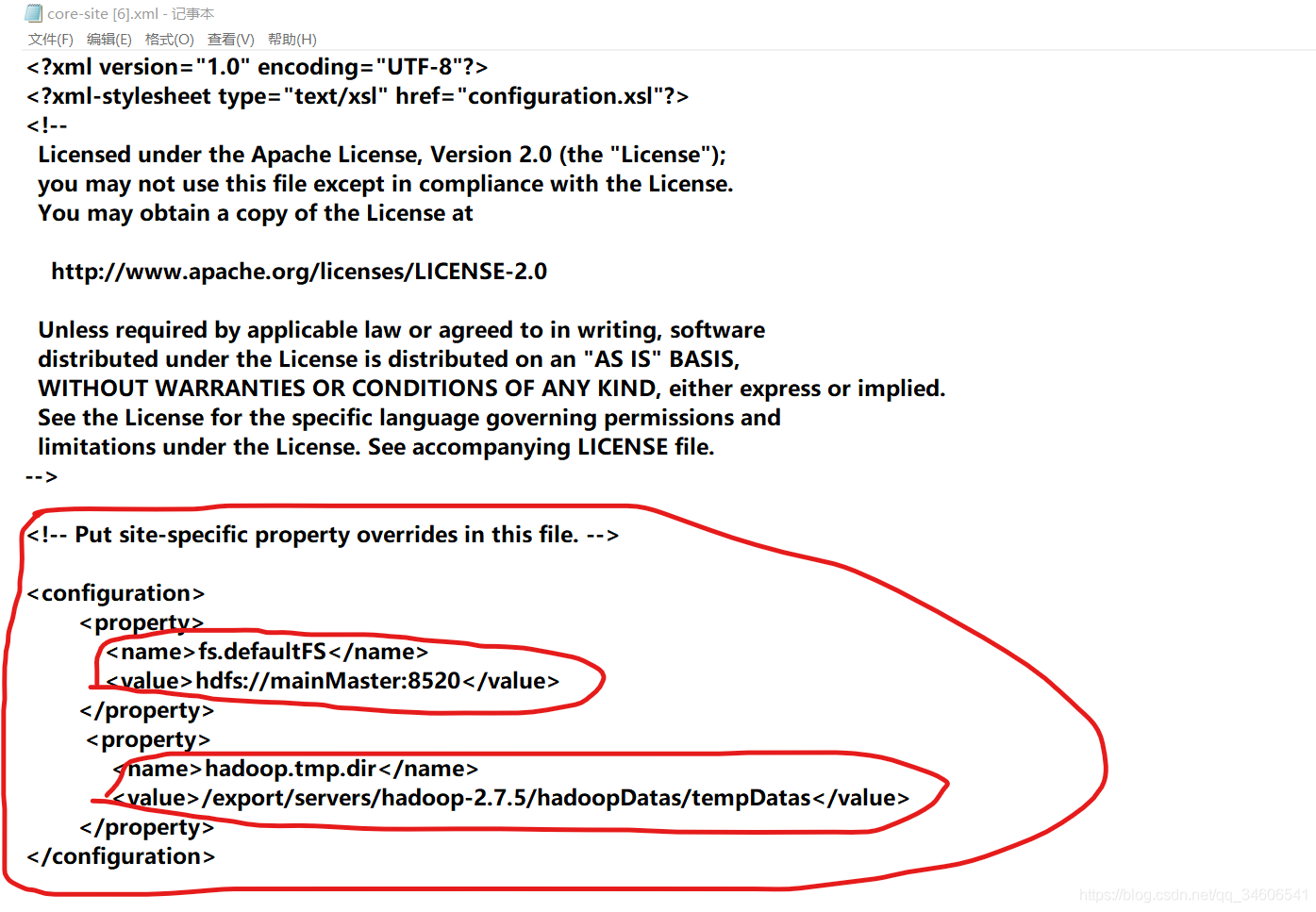
修改core-site.xml檔案如下
-
fs.defaultFS的值為hdfs://你的主機名:埠
-
hadoop.tmp.dir的值為hadoop的臨時資料檔案存盤目錄tempDatas
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mainMaster:8520</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/export/servers/hadoop-2.7.5/hadoopDatas/tempDatas</value> </property> </configuration> -
-
修改hdfs-site.xml檔案如下
-
dfs.replication的值為集群主機數量,由于這里是偽分布只有一臺主機,所以值為1,如果你是全分布有3臺主機,那么這個值就為3
-
dfs.namenode.http.address的值為你的主機名:50070,必須配置這個值,否則你無法通過50070埠訪問Hadoop網頁
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.client.use.datanode.hostname</name> <value>true</value> </property> <property> <name>dfs.datanode.use.datanode.hostname</name> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.http.address</name> <value>mainMaster:50070</value> </property> </configuration> -

-
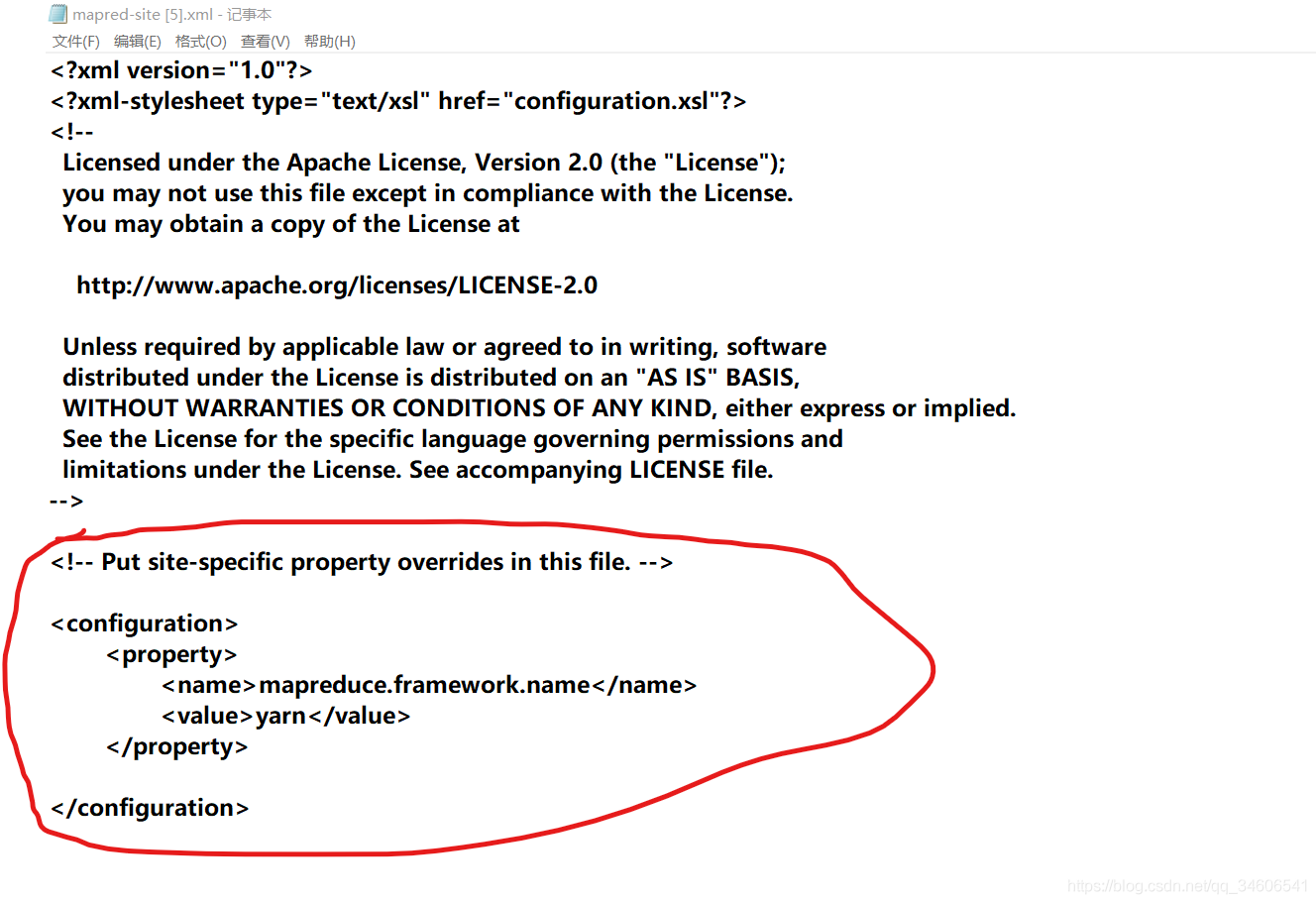
修改mapred-site.xml檔案如下,將mapred-site.xml.template檔案改名為mapred-site.xml即可
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
-
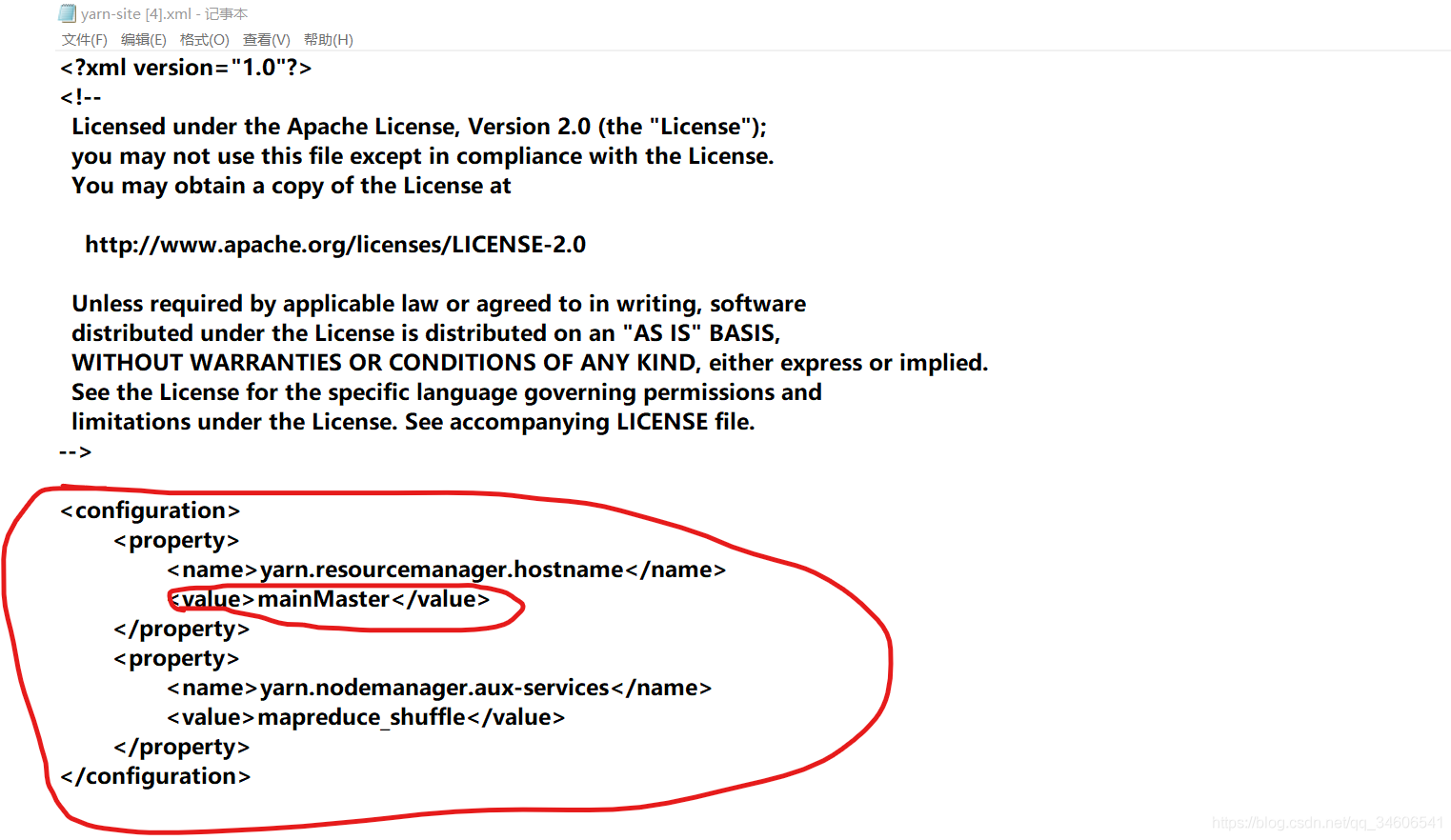
修改yarn-site.xml檔案如下
- yarn.resourcemanager.hostname的值為你的主機名
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>mainMaster</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
-
修改slaves檔案如下
你的主機名 #如我的主機名為 mainMaster,所以只需輸入 mainMaster保存退出即可

8、放開50070埠
此步驟作用等同于關閉防火墻,但比關閉防火墻更安全,推薦使用此方式
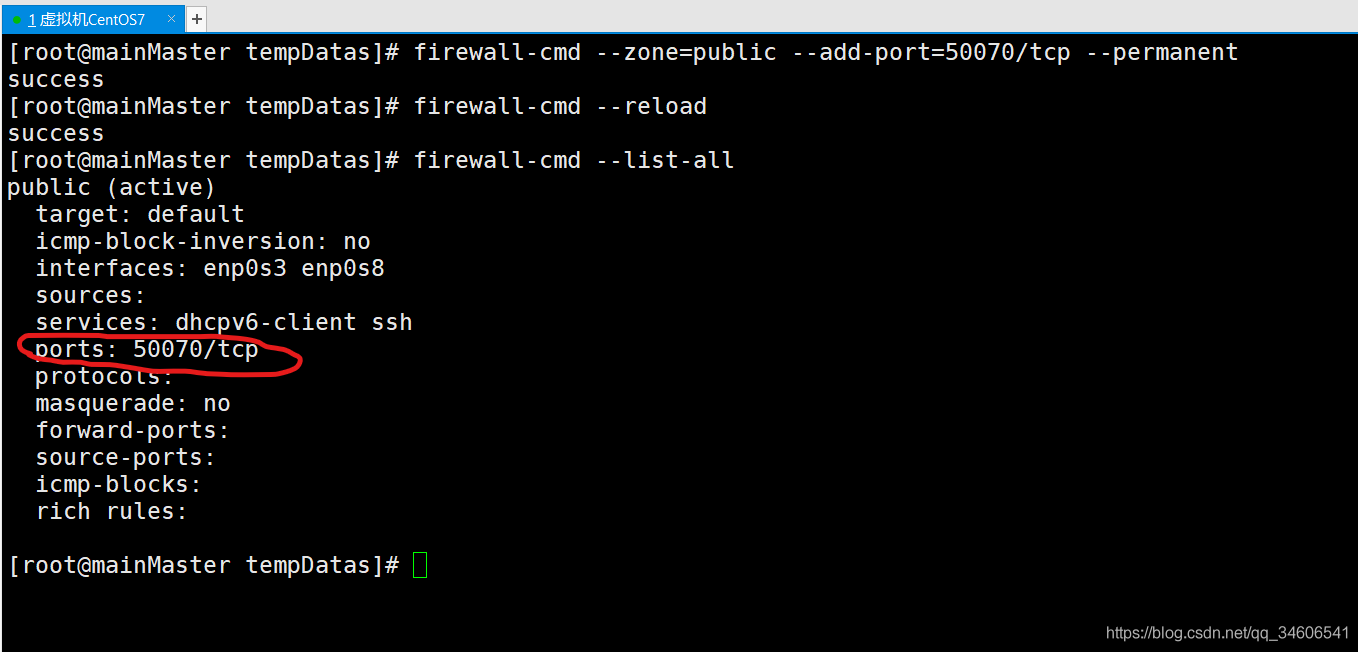
#防火墻放開50070埠
firewall-cmd --zone=public --add-port=50070/tcp --permanent
#多載防火墻,每放開一個新的埠都需要多載防火墻
firewall-cmd --reload
firewall-cmd --list-all #查看防火墻已放開的埠串列
執行以上三個命令后,可以發現CentOS已放開了50070埠
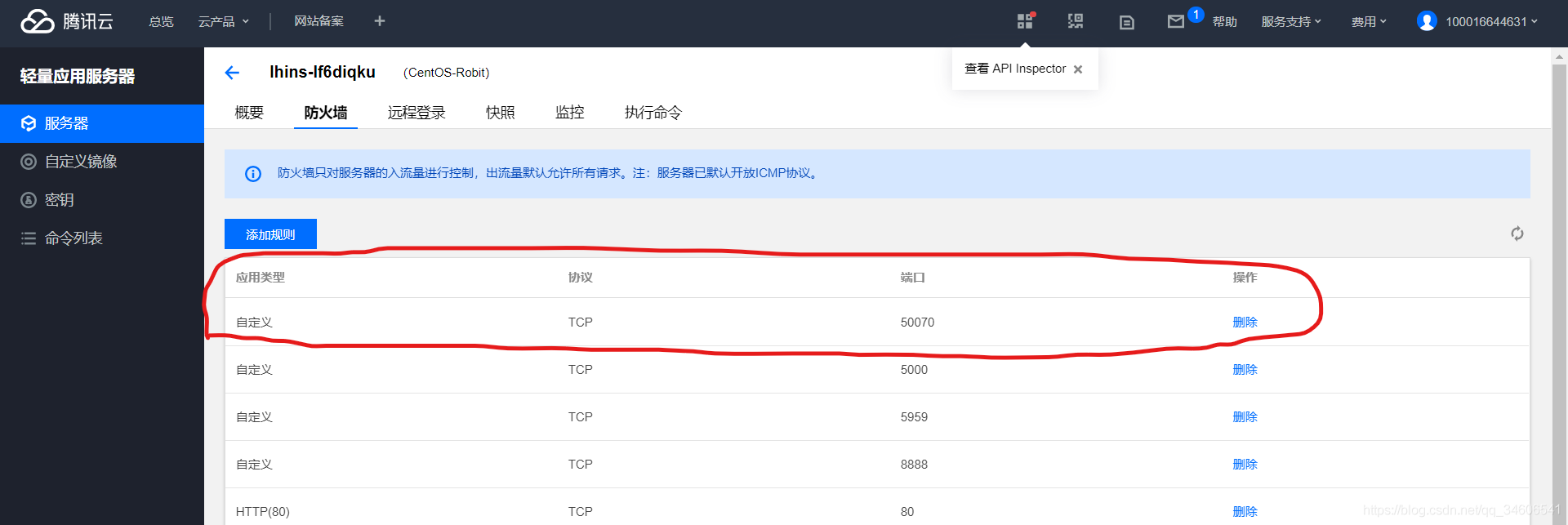
注:如果你使用的云服務器防火墻放開埠,那么你需要在云服務器控制臺安全組先放開50070埠后,在進入CentOS放開50070埠,如下圖,等于要放開兩道防火墻,這是云服務器服務商為了安全而在CentOS前又搞的一道安全防火墻,但本地虛擬機則只有一層CentOS防火墻
選作(不推薦):如果你喜歡關閉防火墻也可以,執行以下命令即可
systemctl stop firewalld #關閉CentOS防火墻
systemctl disable firewalld #開啟開機禁用防火墻
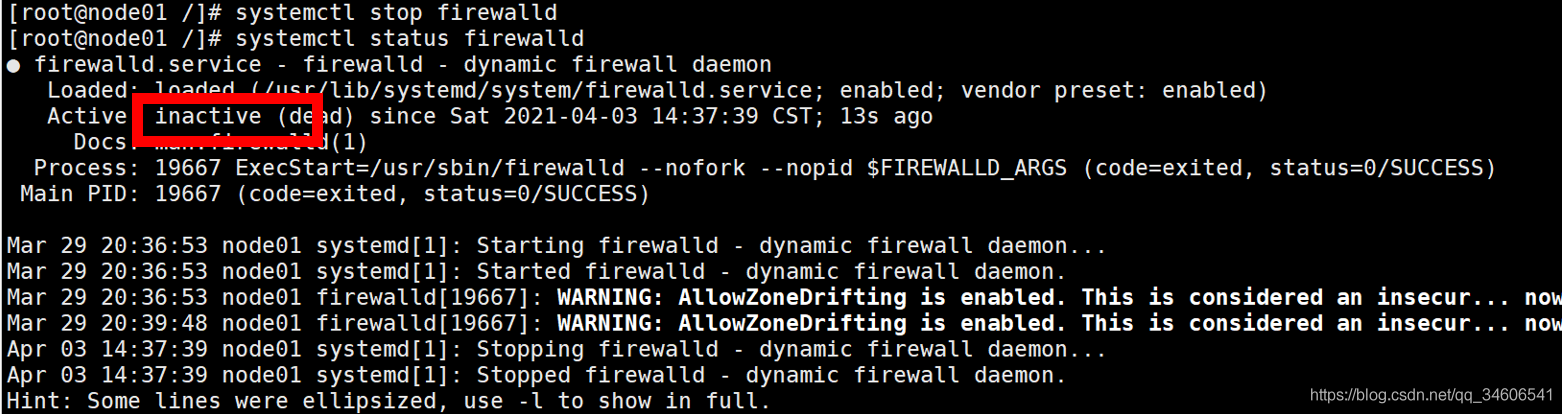
systemctl status firewalld #查看防火墻狀態確定是否關閉
如下圖,防火墻關閉了,防火墻狀態為inactive
9、啟動Hadoop集群
-
進入/export/servers/hadoop-2.7.5 目錄,否則無法啟動hadoop
cd /export/servers/hadoop-2.7.5 -
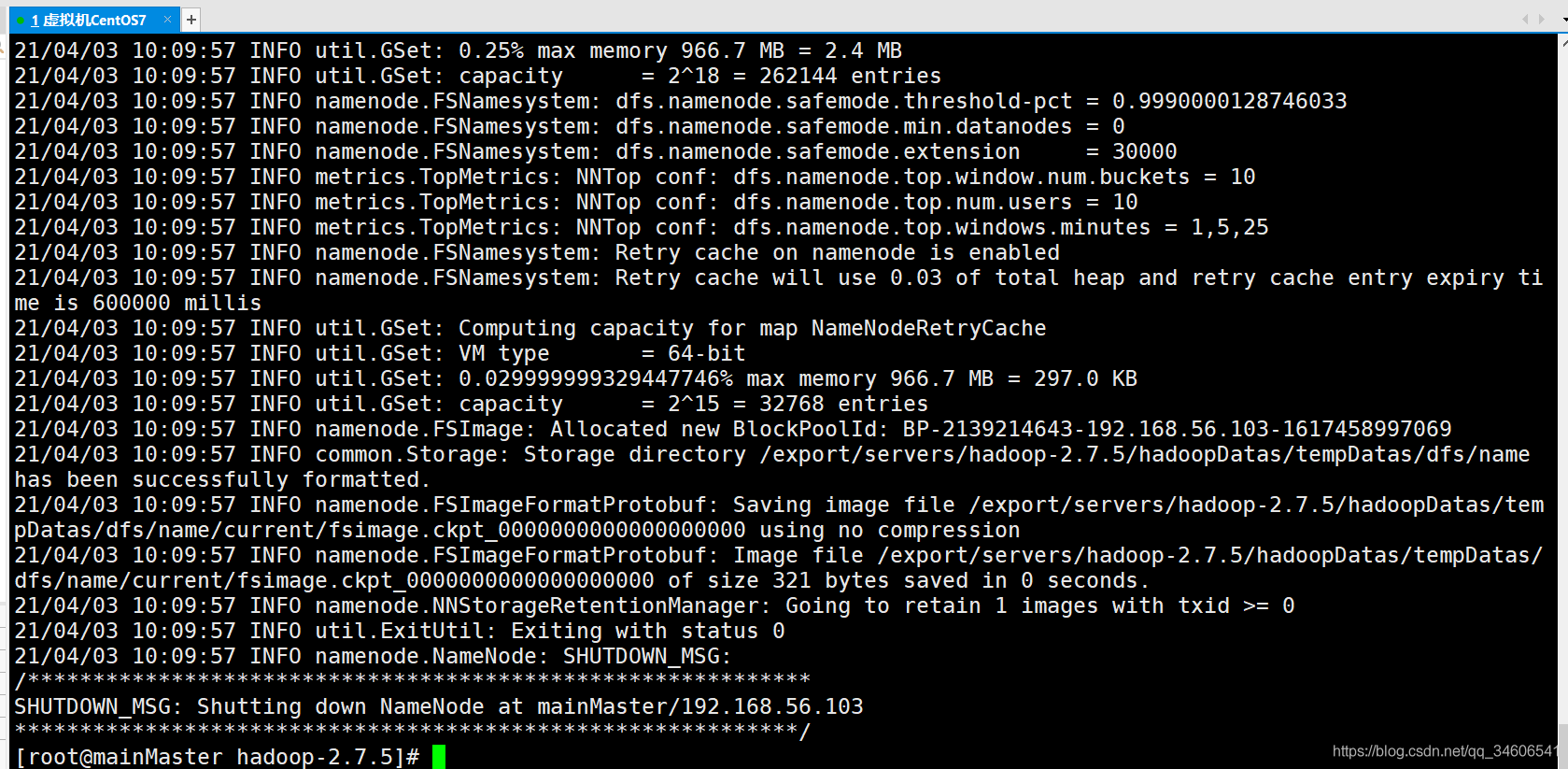
格式化namenode
#格式化namenode命令 hadoop namenode -format
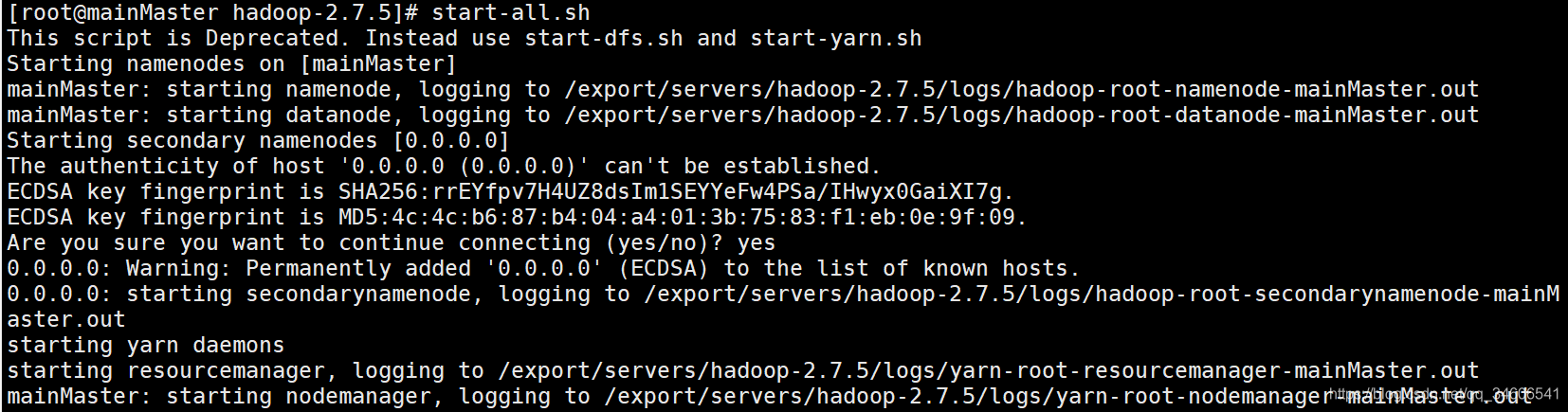
- 鍵入命令啟動hadoop
start-all.sh
- 鍵入jps命令查看啟動情況
jps
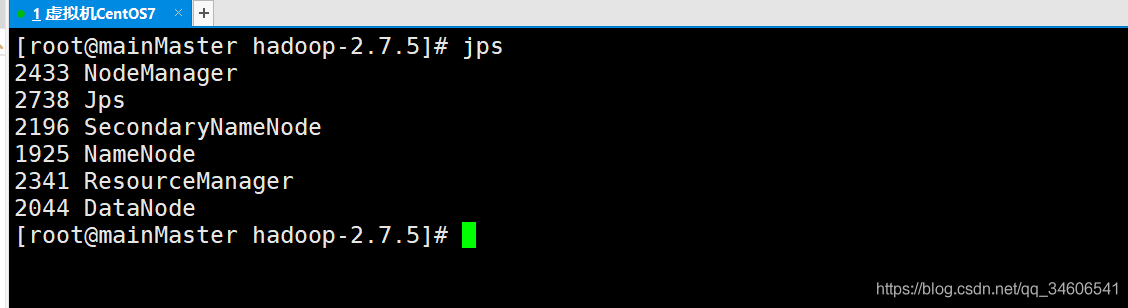
可見Hadoop偽分布啟動成功
- 瀏覽器訪問50070
=========虛擬機訪問格式==========
你的靜態IP:50070
#如我的靜態IP為192.168.56.103,所以瀏覽器訪問地址
192.168.56.103:50070
=========云服務器訪問格式========
你的公網IP:50070
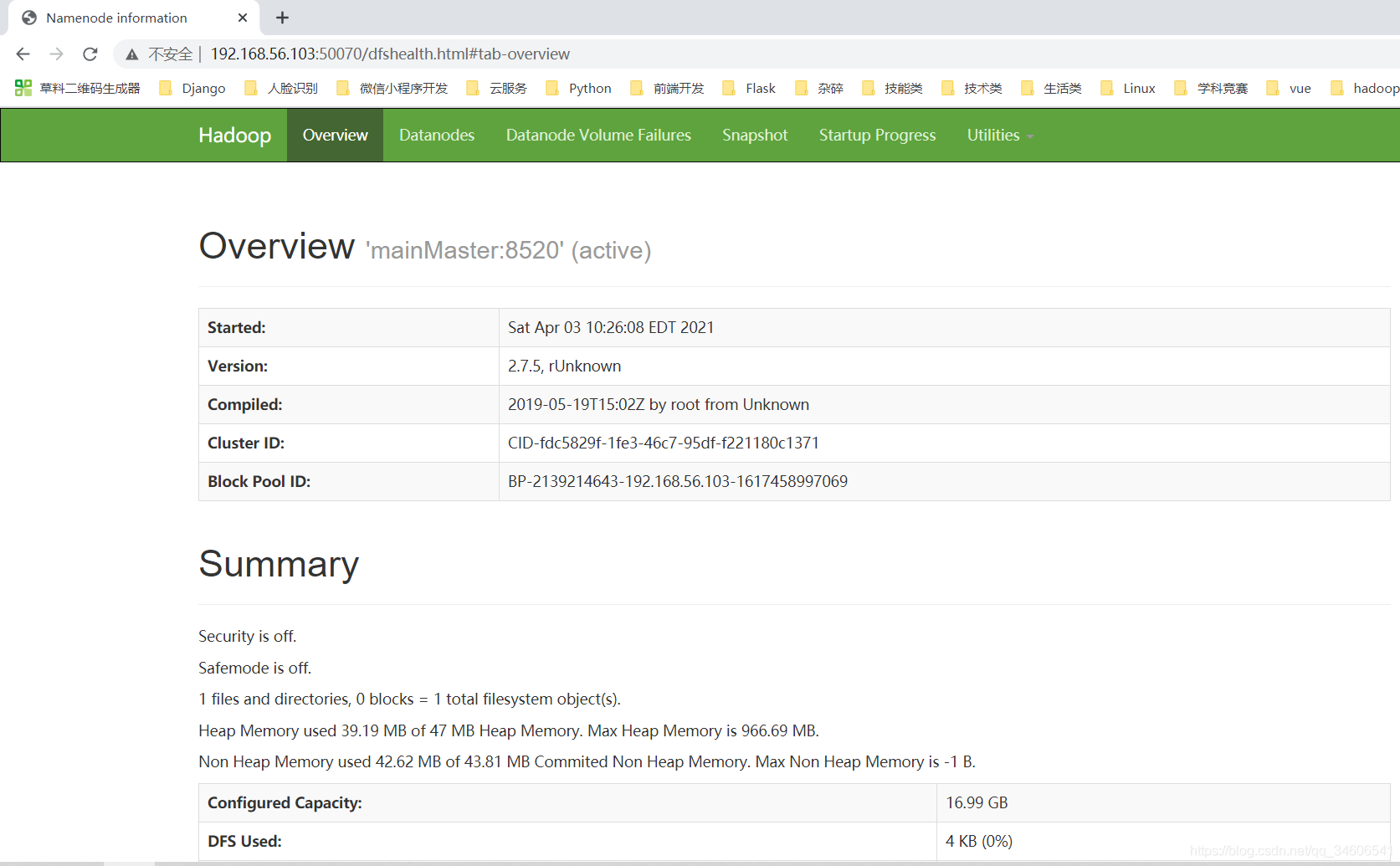
如圖可見訪問成功!這證明Hadoop在虛擬機的偽分布環境搭建成功
- 關閉Hadoop集群
stop-all.sh
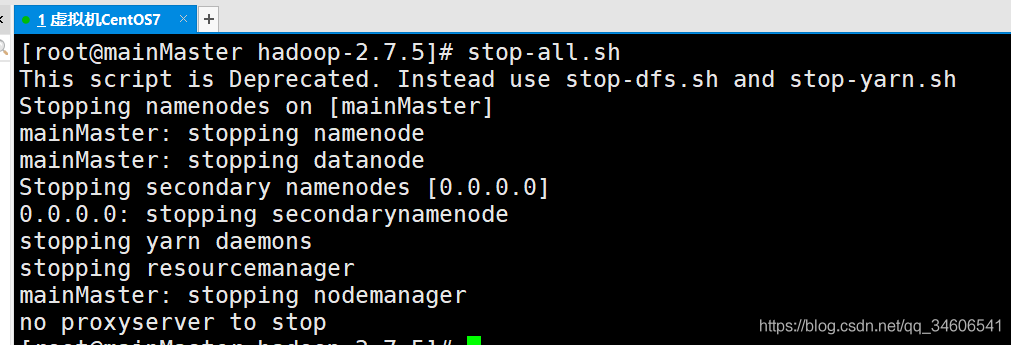
可見Hadoop集群已關閉!
如果你在啟動Hadoop程序中遇到錯誤!你可通過查看日志的方式查找問題并解決!值得注意的是,每當啟動Hadoop遇到錯誤時,你都需要鍵入命令stop-all.sh停止Hadoop啟動后,再進行日志的查找,基于日志指出的問題,通過百度查找解決方案,解決問題后需將 hadoop的臨時資料檔案存盤目錄tempDatas下的檔案清空,而后鍵入命令hadoop namenode -format重新格式化namenode后,再次鍵入命令start-all.sh啟動集群!
--------------------------------到這里Hadoop在虛擬機上的偽分布環境就搭建完成了-----------------------------
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/272856.html
標籤:其他
上一篇:MySQL資料庫與資料表的創建
下一篇:分布式架構淺談