URL
URL是Uniform Resource Locator的簡稱,是Internet上用于指定資料位置的表示方法,這些資料可以是影像、檔案、視頻、音頻、超鏈接等,可以認為URL是資料在Internet上的存取路徑,一個URL對應一個資料資源,例如:鏈家網的一個URL是https://sh.lianjia.com/ershoufang/107103462926.html,用瀏覽器的HTTP協議發送后從Internet上獲得回應如圖所示,也就是打開了網頁,
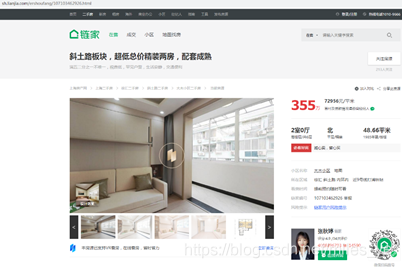
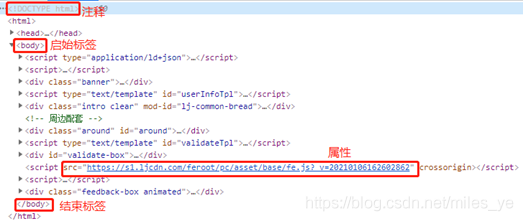
可以看到這個URL指向的是一個HTML檔案,HTML全稱是HyperText Markup Language,中文叫超文本標記語言,是一種標記網頁上各種資料位置的描述語言,上述鏈家URL的HTML檔案如圖所示,可以看到網頁上各種資料的位置都放在了標簽對(即尖括號)中,
有時發送的URL請求,也可能獲得如圖所示的出錯回應,

常見的URL請求回應狀態如表所示,回應除了有HTML檔案外,還會有JSON資料、二進制資料等,

網路爬蟲
網路爬蟲爬取的物件就是網頁資料,根據方式的不同網頁資料可以分為三種:
- 網站(website)
這是網路爬蟲最主要的獲取資料對像,國內可以爬取的網站有新聞類(如:環球網、鳳凰網、騰訊網)、社交類(如:新浪微博、人人網、水木社區)、購物類(如:淘寶、天貓、京東、拼多多)等, - 網站的API
API是Application Programming Interface的縮寫,即應用程式的介面,是不同程式模塊進行互動的地方,現在,API也是許多互聯網公司提供的資訊服務介面,是一種介面服務產品,例如提供天氣類API的和風天氣、提供微博類API的微博開放平臺, - 流量資料
流量資料是指用戶訪問網路產品或網頁時產生的資料,流量資料有頁面瀏覽量(Page View,簡稱PV)、訪客數(Unique Visitor,簡稱UV)、登錄時間、在線時長、人均流量、人均瀏覽時長等,
網路爬蟲的流程
- 獲取資料
網路爬蟲根據提供的URL佇列,向服務器發起請求(Request),服務器接收請求后回應(Response),并回傳網頁資料, - 決議資料
網路爬蟲把回傳的網頁資料決議成對應的HTML, - 提取資料
網路爬蟲利用正則運算式或第三方庫(如Scrapy、grab、PySpider)從HTML中提取出需要的資料, - 存盤資料
網路爬蟲把提取出的資料保存起來,便于日后使用和分析,
網路爬蟲搜索資源的策略主要有IP地址搜索策略、深度優先搜索策略和寬度優先搜索策略,
正則運算式決議網頁
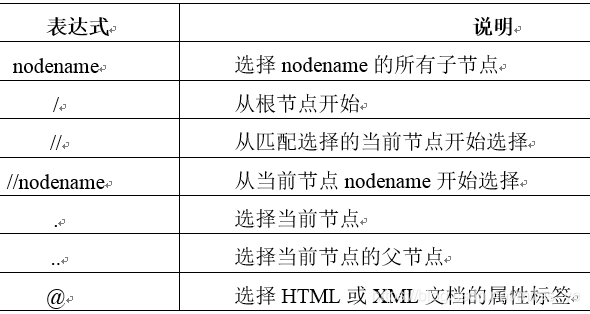
所謂決議網頁就是從網頁服務器回傳的資訊中提取想要資料的程序,常見的方式是使用正則運算式或者一些第三方開發正則運算式軟體庫,例如lxml、BeauifulSoup、requests-html等,這里使用名為lxml(https://lxml.de/)的正則運算式相關軟體庫中的XPath方式進行網頁決議,XPath中有些特殊用途的運算式說明如表所示,
正則運算式爬取資料
-
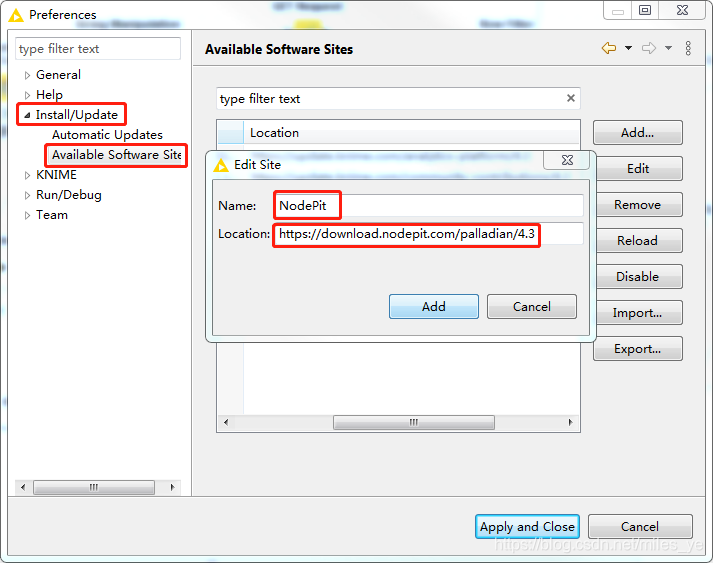
安裝URL決議包Palladian,安裝手冊在這里,Palladian包的全名為Palladian for KNIME (2.4.1.202103282119 Version),
-
在Table Creator節點中設定初始的URL,例如斗魚,并雙擊列頭,命名為url,
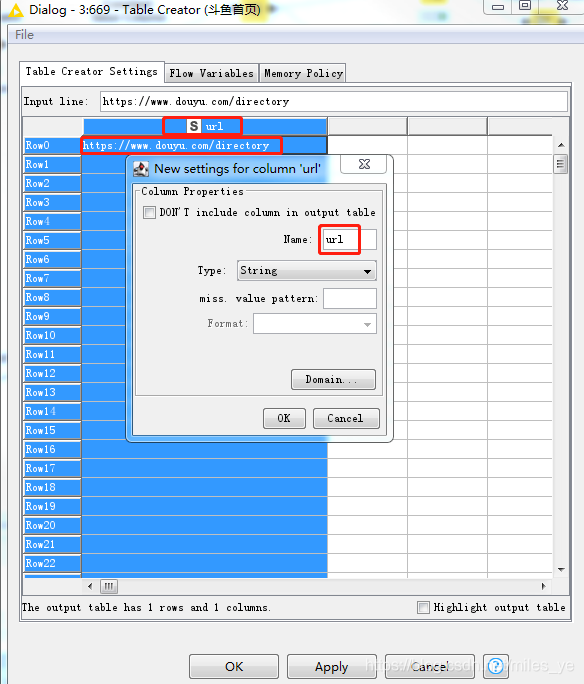
-
在HTTP Retriever節點中獲取URL,通過右擊HTTP Result Output進行查看,
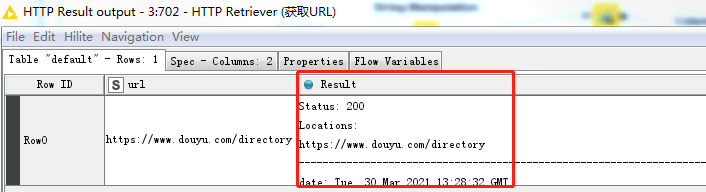
-
用HTML Parser節點進行語法分析,轉換為XML格式,
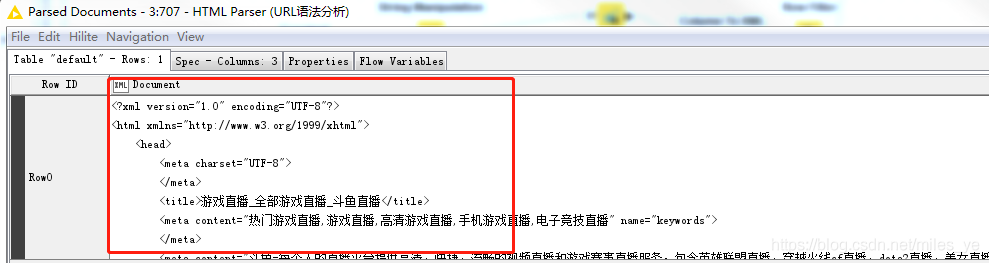
-
在XPath節點中設定如下,決議出游戲主頁網址(href)和游戲名稱(title),在XML檔案的489行附近,
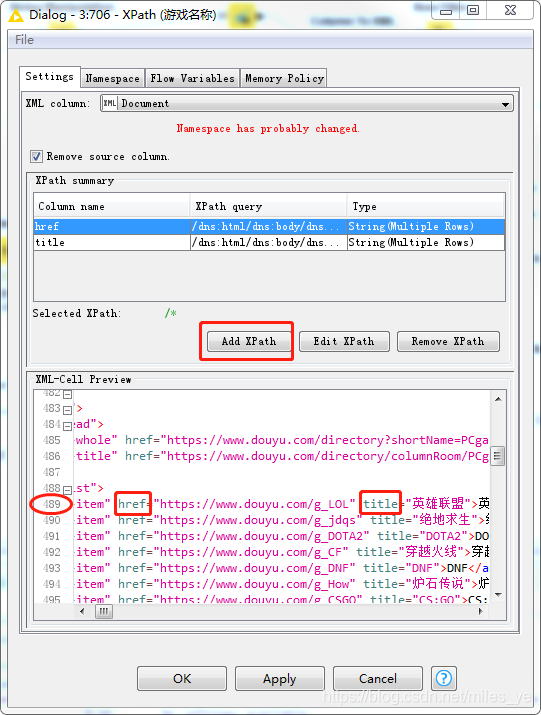
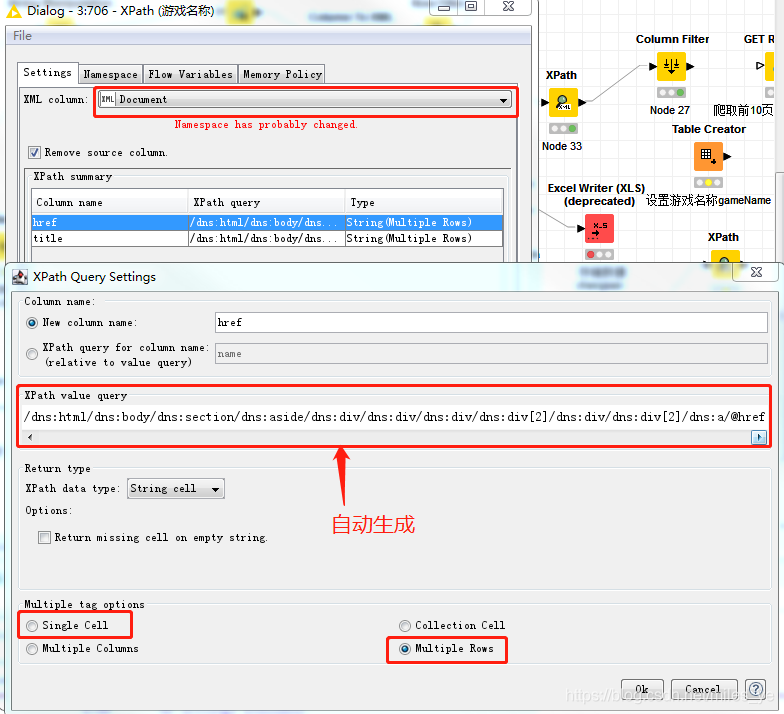
結果顯示為
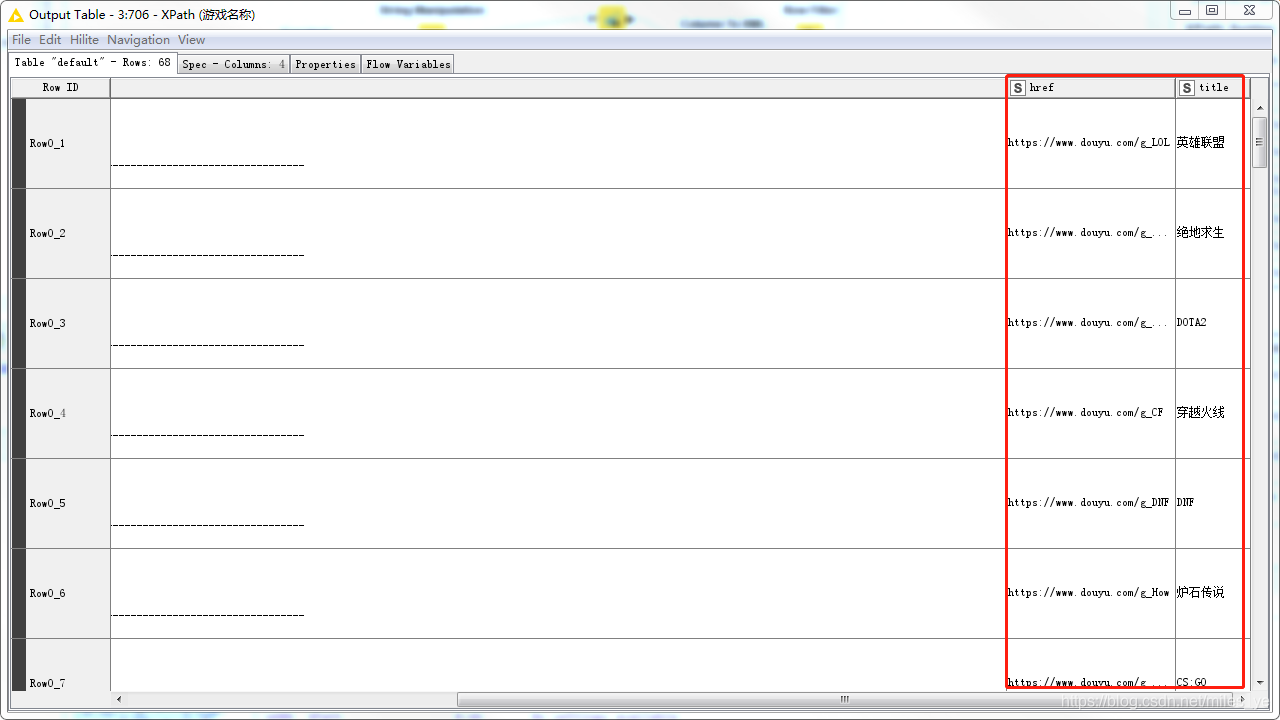
-
使用Column Filter節點只保留游戲主頁網址(href)和游戲名稱(title)列,
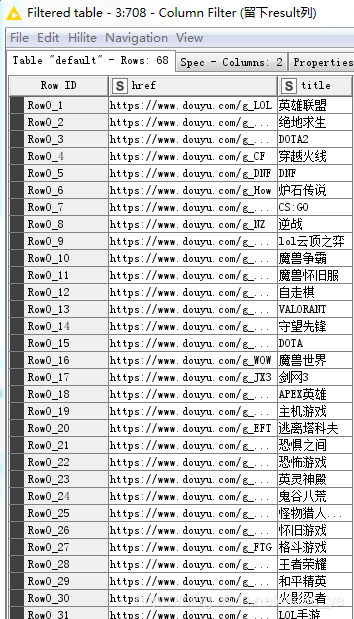
-
使用Regex Split節點用正則運算式獲取游戲名稱的縮寫,例如英雄聯盟的縮寫為LOL,
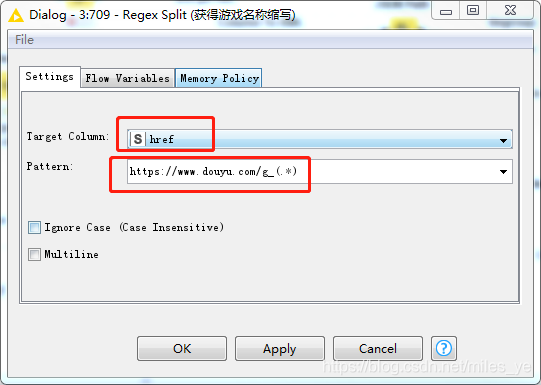
執行后,有一個WARN:1 input string(s) did not match the pattern or contained more groups than expected,問:為什么?怎么解決? -
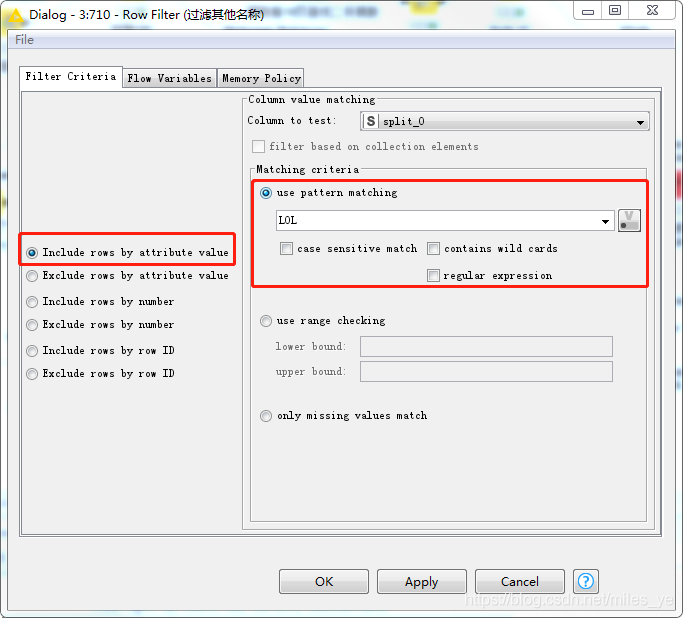
使用Row Filter過濾不需要分析的游戲名稱,只保留需要資料分析的游戲名稱,例如LOL
-
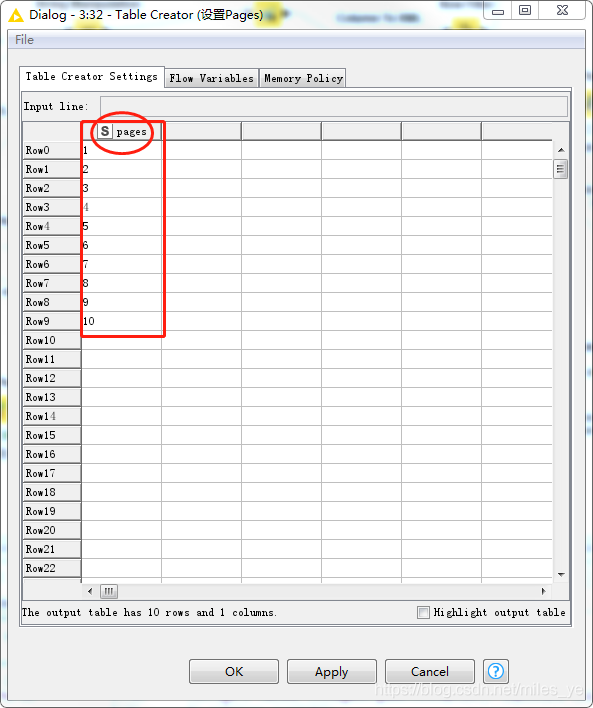
使用Table Creator節點,設定爬取的斗魚聊天室的網頁數,并且命名列變數名為pages,
-
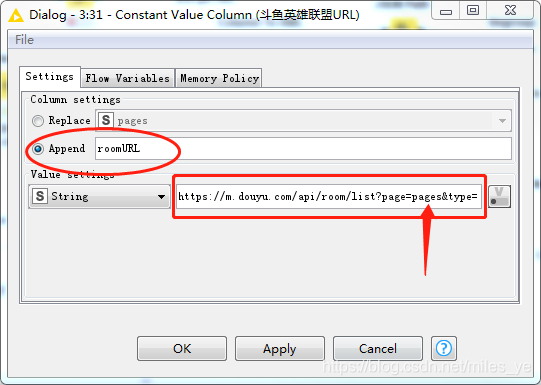
使用Constant Value Column節點設定斗魚聊天室URL,注意其中的pages就是Table Creator節點中命名的變數,并且將聊天室的URL以roomURL的變數名追加到資料集中,
-
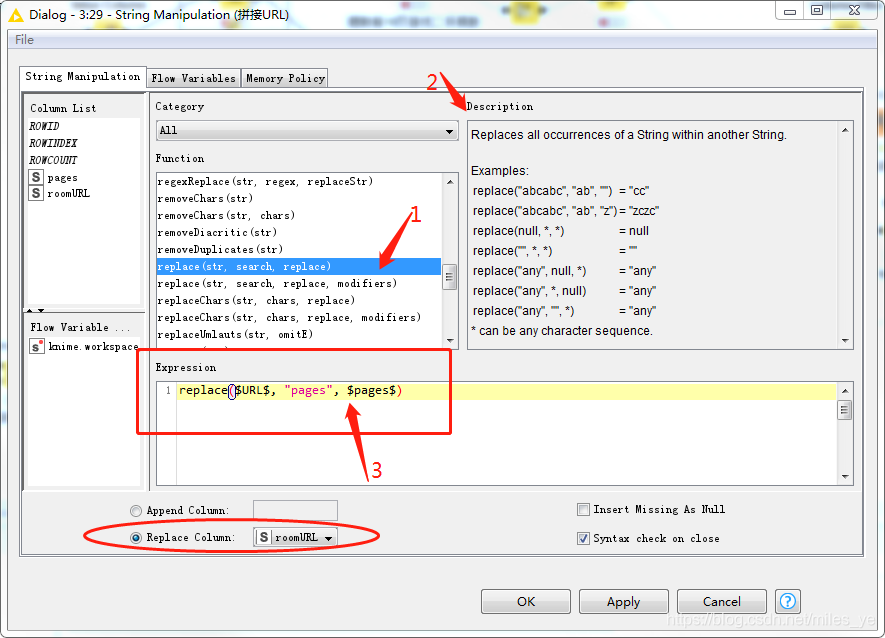
使用String Mnipulation節點將Pages和roomURL兩個變數拼接起來,
輸出結果如下:
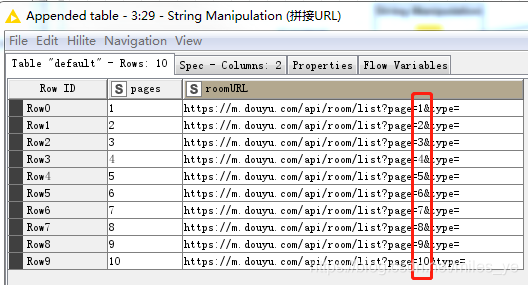
-
使用Cross Joiner節點,將步驟8和步驟11的2個輸出結果交叉式地拼接起來,執行后結果如下,
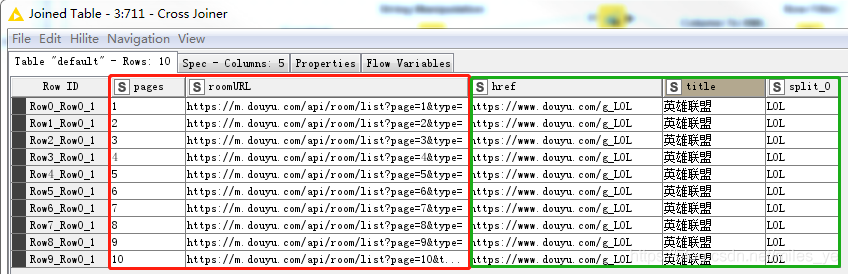
-
使用String Manipulation節點將roomURL(聊天室URL)和split_0(游戲名稱縮寫)連接起來,
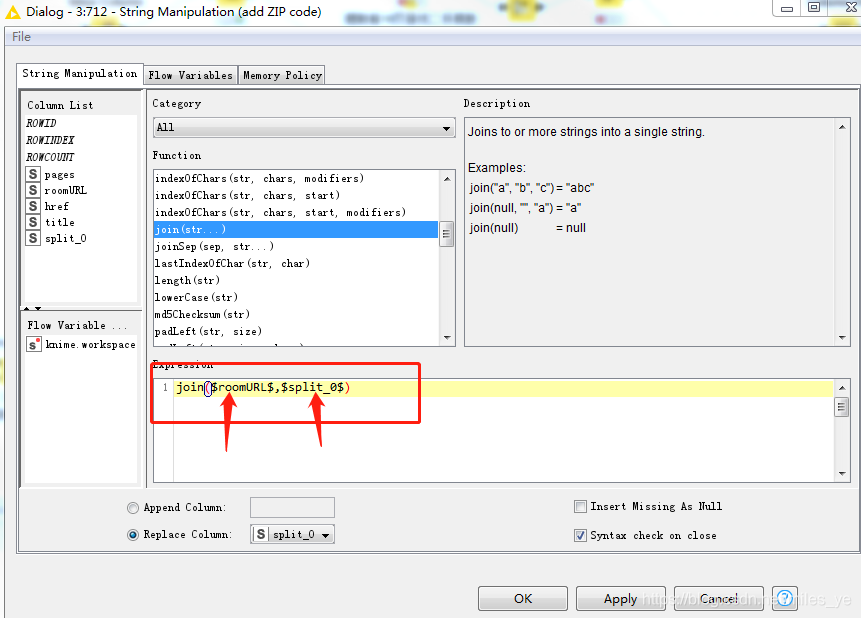
執行后的結果如下:
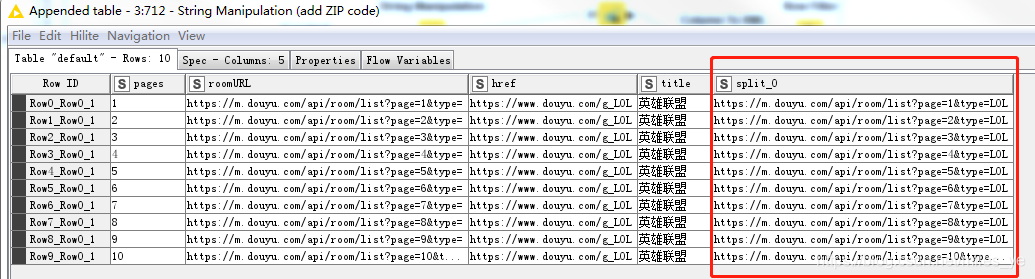
-
使用GET Request對獲取的10頁(Pages)游戲聊天內容進行爬取,
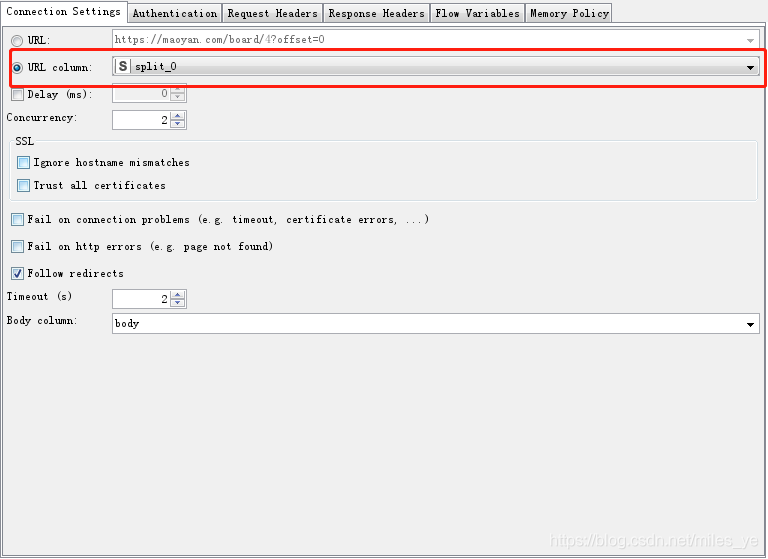
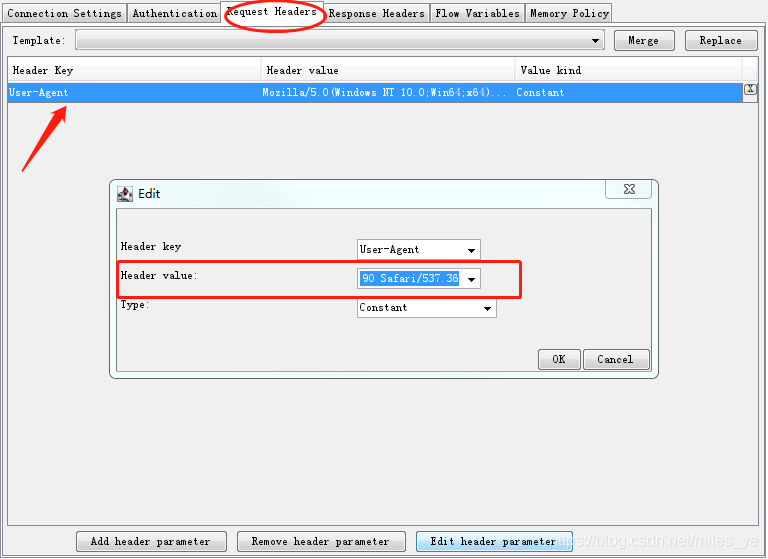
并在Request Headers頁設定User-Agent為Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36,以模擬瀏覽器(如Chrome)訪問網站,
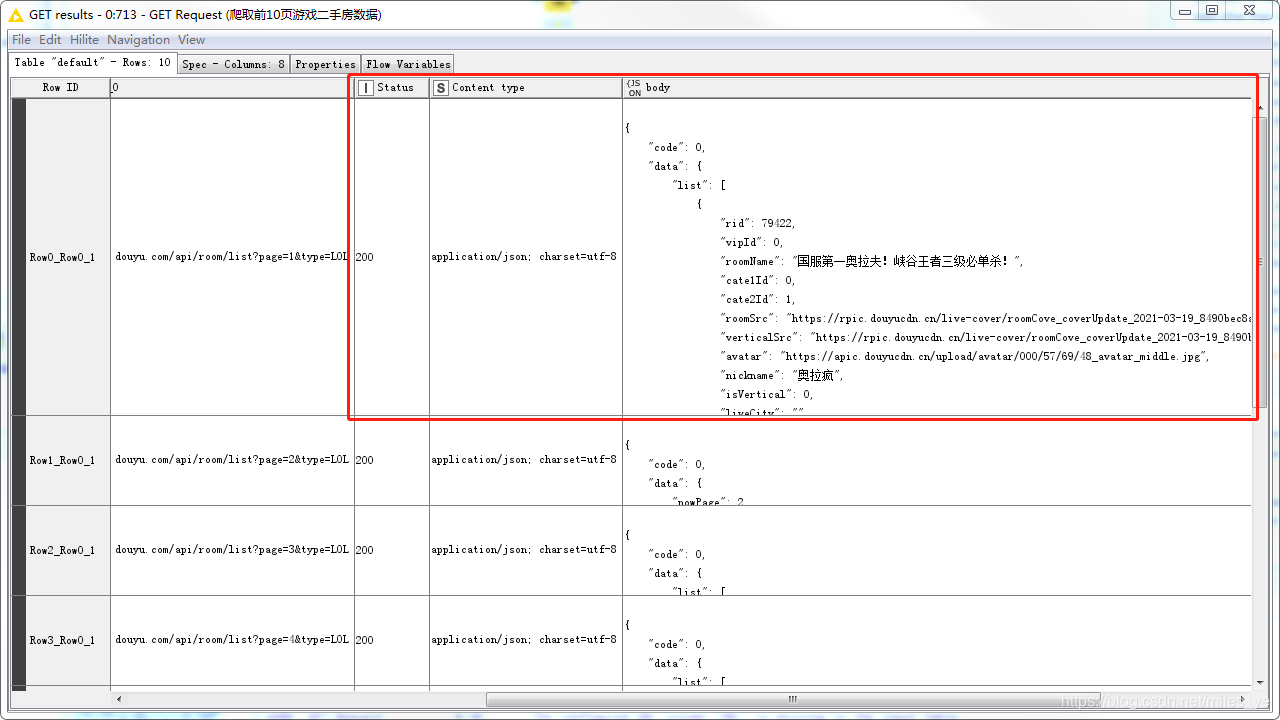
執行后GET Request節點,可以查看爬取的資料,
-
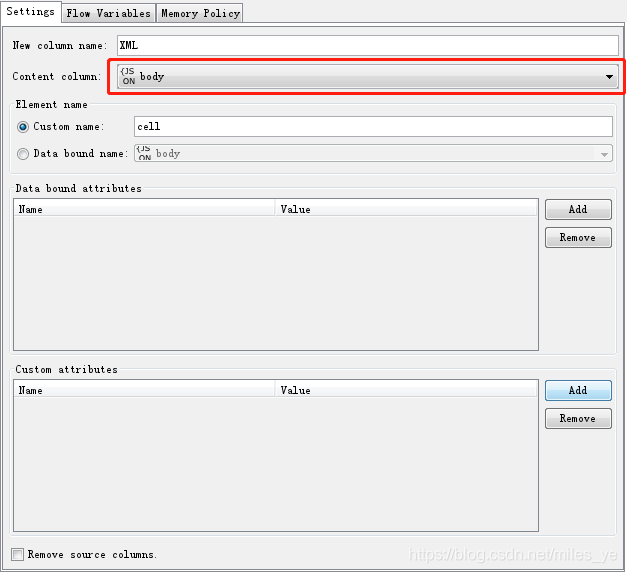
使用Column To XML節點,將{JSON}body列轉換為XML型別的列,
-
使用JSON Path節點,決議出聊天室編號roomID、聊天室名稱roomNames、在線人數hotSpots、主播網名nickNames,
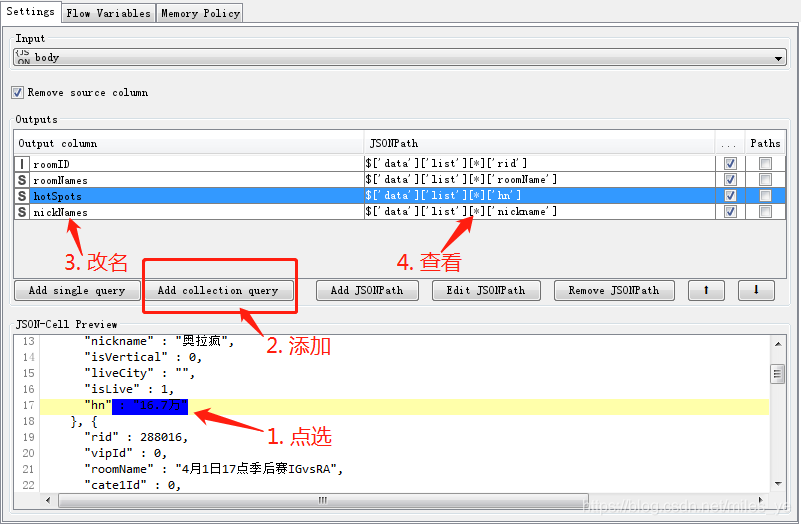
執行后的結果為:
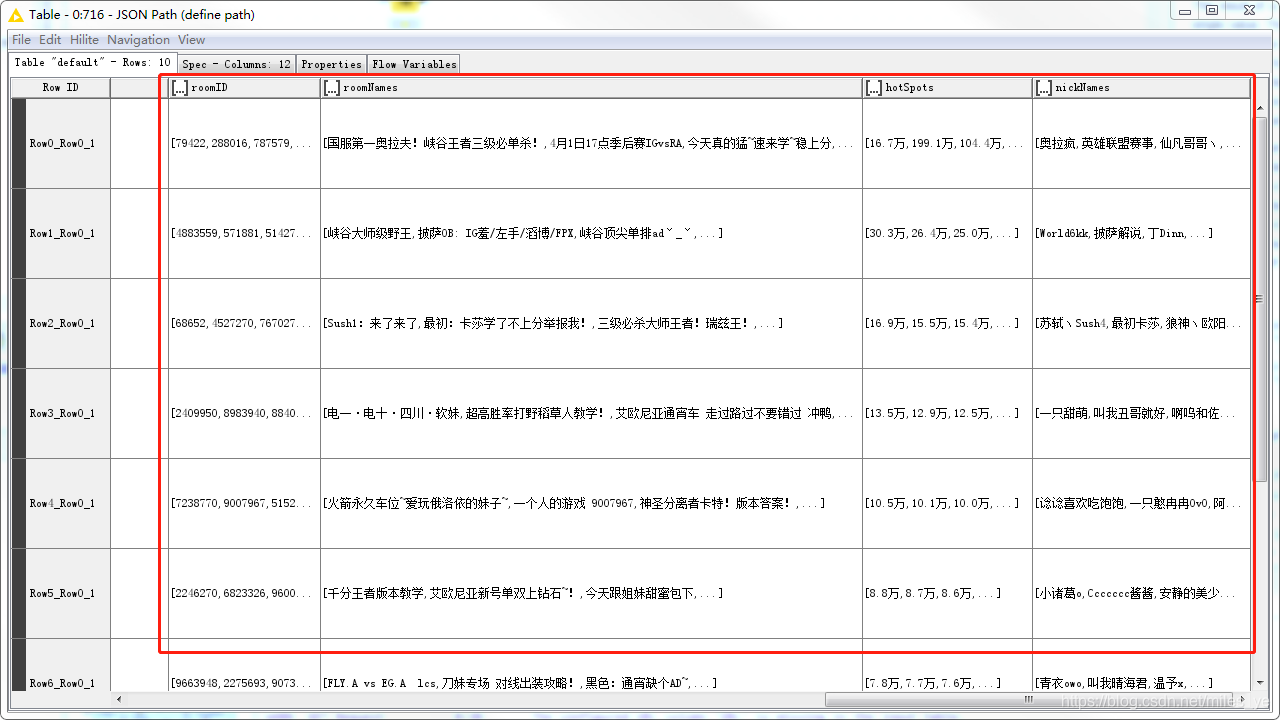
-
使用Ungroup節點將組合的資料分解開,
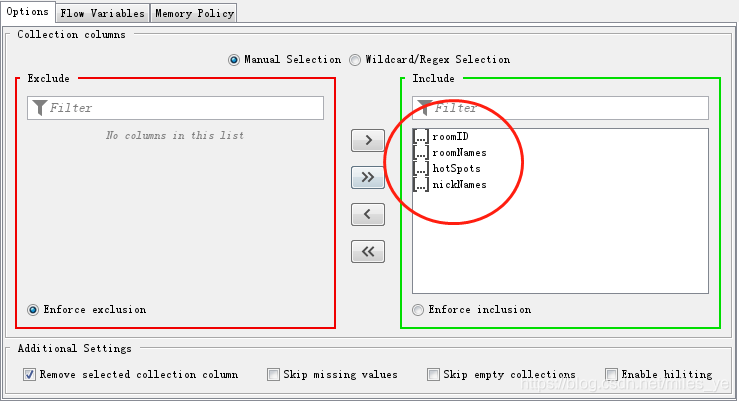
執行后的結果為:
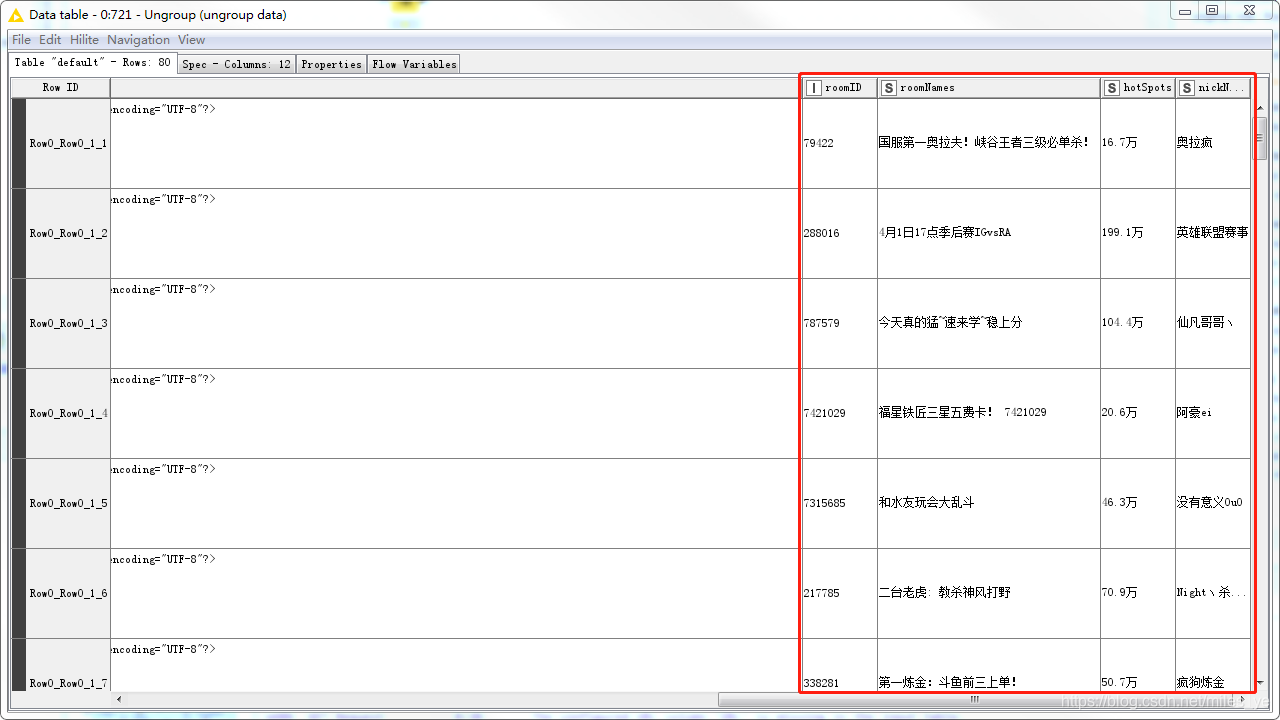
-
使用Excel Writer節點保存資料,完!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/273600.html
標籤:其他
上一篇:0行代碼,實作植物大戰僵尸腳本