論文解讀與個人理解:Spatial-Temporal Multi-Cue Network for Continuous Sign Language Recognition
- Abstract
- 1?Introduction
- 2?Related Work
- 3?Proposed Approach
- 3.1?Framework Overview
- 3.2?Spatial Multi-Cue Representation
- 3.3?Temporal Multi-Cue Modelling
- 4?Experiments
- 4.1?Dataset and Evaluation
- 4.2?Implementation Details
- 4.3?Framework Effectiveness Study
- 4.4?State-of-the-art Comparison
- 5?Conclusion
- Paper原文鏈接點擊下載
- Paper原始碼(暫無)
- (2020-連續-RGB-手形-頭-關節/RGB-CSL/PHOENIX2014/PHOENIX204T)
| 年份 | 識別型別 | 輸入資料型別 | 手動特征 | 非手動特征 | Fullframe | 資料集 | 識別物件 |
|---|---|---|---|---|---|---|---|
| 2020 | 連續陳述句 | RGB | Shape(手形) | Head(頭) | Bodyjoints(身體關節)、RGB | Phoenix14、Phoenix14-T、CSL | DGS(德語)、CSL(漢語) |
Abstract
Despite the recent success of deep learning in continuous sign language recognition (CSLR), deep models typically focus on the most discriminative features, ignoring other potentially non-trivial and informative contents. Such characteristic heavily constrains their capability to learn implicit visual grammars behind the collaboration of different visual cues (i,e., hand shape, facial expression and body posture). By injecting multi-cue learning into neural network design, we propose a spatial-temporal multi-cue (STMC) network to solve the vision-based sequence learning problem. Our STMC network consists of a spatial multi-cue (SMC) module and a temporal multi-cue (TMC) module. The SMC module is dedicated to spatial representation and explicitly decomposes visual features of different cues with the aid of a self-contained pose estimation branch. The TMC module models temporal correlations along two parallel paths, i.e., intra-cue and inter-cue, which aims to preserve the uniqueness and explore the collaboration of multiple cues. Finally, we design a joint optimization strategy to achieve the end-to-end sequence learning of the STMC network. To validate the effectiveness, we perform experiments on three large-scale CSLR benchmarks: PHOENIX-2014, CSL and PHOENIX-2014-T. Experimental results demonstrate that the proposed method achieves new state-of-the-art performance on all three benchmarks.
盡管深度學習最近在連續手語識別(CSLR)方面取得了成功,但深度模型通常專注于最具區別性的特征,而忽略了其他潛在的非瑣碎和資訊內容,這種特征嚴重限制了他們在不同視覺線索協同作用下學習內隱視覺語法的能力,(比如手的形狀、面部表情和身體姿勢),通過在神經網路設計中注入多線索學習,我們提出了一種 spatial-temporal multi-cue (STMC) 網路來解決基于視覺的 sequence 學習問題,STMC網路由 spatial multi-cue (SMC) 模塊和 temporal multi-cue (TMC) 模塊組成,SMC 模塊致力于 spatial representation,并借助 self-contained pose estimation branch 明確分解不同 cues 的視覺特征,TMC模塊沿兩條平行 paths ( intra-cue 和 inter-cue)建立時間相關性模型,旨在保持線索的獨特性,并探討多種線索之間的協作關系,最后,我們設計了一個聯合優化策略來實作STMC網路的端到端的序列學習,為了驗證該方法的有效性,在PHOENIX-2014、CSL和PHOENIX-2014-T三種大規模CSLR基準上進行了實驗,實驗結果表明,該方法在這三個資料集上都達到了目前最高的性能水平,
| 研究物件 | 手型、面部表情、身體姿勢 |
|---|---|
| 研究方法 | spatial-temporal multi-cue (STMC) 網路(由 spatial multi-cue (SMC) 模塊和temporal multi-cue (TMC) 模塊組成) |
| STMC網路 | spatial-temporal multi-cue 時空多線索,將多線索學習和神經網路相結合 |
| SMC模塊 | Spatial Multi-Cue 空間多線索,用于空間表示,并借助一個獨立的姿勢估計模塊來分解不同線索的視覺特征 |
| TMC模塊 | Temporal Multi-Cue 時間多線索,沿兩個平行路徑對時間相關性進行建模 |
| STMC端到端學習 | 聯合優化策略 |
| 資料集 | PHOENIX-2014 、PHOENIX- 2014-T 、CSL |
| 資料集 | 驗證集(Dev)WER(Word Error Rate) | 測驗集(Test) WER(越低越好) |
|---|---|---|
| PHOENIX-2014 | 21.1 | 20.7 |
| PHOENIX- 2014-T | 19.6 | 21.0 |
| 資料集 | Split I | Split II |
|---|---|---|
| CSL | 2.1 | 28.6 |
在CSL上的評估標準和其他兩個資料集不一樣,猜測:可能在CSL上的效果不理想,就換了評價標準,需要在原始碼上驗證,
訓練集、驗證集(dev)和測驗集
- 在模型訓練的時候通常將我們所得的資料分成3部分:訓練集、dev驗證集和測驗集
- dev用來統計的那一評估指標、調節引數,選擇演算法;而test用來在最后整體評估模型性能
- dev和訓練集一起被輸入到模型演算法中,但又不參與模型訓練,可以一邊訓練一邊根據dev查看指標
- dev和測驗集都是用來評估模型好壞,但dev只能用來統計單一評估指標;而測驗集能夠提供更多的評估模型指標,如混淆矩陣、roc、召回率、F1 Score等
- dev可以用來快速評估指標的,并及時做出引數調整,但不全面;而測驗集能提供一個模型的完整評估報告,能更好的從多個角度評價模型的性能,缺點是比較費時,一般在dev把引數調整差不多后,才會用到測驗集
- dev和測驗集要保持同一分布
- 大資料時代以前,通常將資料按照8:1:1劃分資料集,大資料時代(百萬數量級),通常可以將資料按照98:1:1的比例劃分
————————————————
原文鏈接:https://blog.csdn.net/weixin_43821376/article/details/103777454
1?Introduction
Sign language is the primary language of the deaf community. To facilitate the daily communication between the deaf-mute and the hearing people, it is significant to develop sign language recognition (SLR) techniques. Recently, SLR has gained considerable attention for its abundant visual information and systematic grammar rules (Cui, Liu, and Zhang 2017; Huang et al. 2018; Koller et al. 2019; Pu, Zhou, and Li 2019; Li et al. 2019). In this paper, we concentrate on continuous SLR (CSLR), which aims to translate a series of signs to the corresponding sign gloss sentence.
手語是聾人群體的主要語言,為了方便聾啞人與聽障人的日常交流,發展手語識別技術具有重要意義,近年來,手語識別因其豐富的視覺資訊和系統的語法規則而受到廣泛關注(Cui, Liu, and Zhang 2017;黃等2018;Koller等人2019;普,周,李2019;Li et al. 2019),本文主要研究連續手語識別(CSLR),它的目的是將一系列的手語翻譯成相應的口語,
- CSLR:continuous sign language recognition 連續手語識別
?? Sign language mainly relies on, but not limits to, hand gestures. To effectively and accurately express the desired idea, sign language simultaneously leverages both manual elements from hands and non-manual elements from the face and upper-body posture (Koller, Forster, and Ney 2015). To be specific, manual elements include the shape, position, orientation and movement of both hands, while non-manual elements include the eye gaze, mouth shape, facial expression and body pose. Human visual perception allows us to process and analyze these simultaneous yet complex information without much effort. However, with no expert knowledge, it is difficult for a deep neural network to discover the implicit collaboration of multiple visual cues automatically. Especially for CSLR, the transitions between sign glosses may come with temporal variations and switches of different cues.
??手語主要依靠手勢但不僅僅只依靠手勢,為了準確有效地表達思想,手語同時利用了手部的手動特征和面部與上半身姿勢的非手動特征(Koller, Forster, and Ney 2015),具體來說,手動特征包括雙手的形狀、位置、方向和運動,非手動元素包括眼睛注視、嘴型、面部表情和身體姿勢,人類的視覺感知使我們能夠輕而易舉地同時處理和分析這些復雜的資訊,然而,在缺乏專業知識的情況下,深度神經網路很難自動發現多種視覺線索的隱式協作,尤其對于 CSLR 來說,sign glosses 的先后順序和不同部位的相互切換深深影響著手語翻譯的效果,
- Sign glosses:手勢光澤???
闡明CSRL的難度:我可以借鑒"The Significance of Facial Features For Automatic Sign Language Recognition”中用圖片的方式來說明
??To explore multi-cue information, some methods rely on external tools. For example, an off-the-shelf detector is utilized for hand detection, together with a tracker to cope with shape variation and occlusion (Cihan Camgoz et al. 2017; Huang et al. 2018). Some methods adopt multi-stream networks with inferred labels (i.e., mouth shape labels, hand shape labels) to guide each stream to focus on individual visual cue (Koller et al. 2019). Despite their improvement, they mostly suffer two limitations: First, external tools impede the end-to-end learning on the differentiable structure of neural networks. Second, off-the-shelf tools and multi-stream networks bring repetitive feature extraction of the same region, incurring expensive computational overhead for such a video-based translation task.
??為了探索多線索資訊,一些依賴于外部工具的方法,例如,一種現成的檢測器被用于手部檢測,同時還有一個跟蹤器來處理形狀變化和遮擋(Cihan Camgoz et al. 2017;黃等,2018),一些方法采用帶有推測標簽的多流網路(如口形標簽、手形標簽)引導每個流關注手語視覺線索(Koller et al. 2019),盡管有所改進,但它們大多存在兩個局限性:一是外部工具阻礙了對神經網路可微結構的端到端學習,其次,現成的工具和多流網路帶來了同一區域的重復特征提取,提高了計算開銷,
舉其他方法的例子:要最近幾年的研究,不可是太久以前的研究,沒說服力
| 年份 | 論文 | 方法 | 缺點 |
|---|---|---|---|
| 2017 | Cihan Camgoz, N.; Hadfield, S.; Koller, O.; and Bowden, R. 2017.Subunets: end-to-end hand shape and continuous sign language recognition. In ICCV | 現成的檢測器被用于手部檢測 | 外部工具阻礙了對神經網路可微結構的端到端學習 |
| 2018 | Cihan Camgoz, N.; Hadfield, S.; Koller, O.; Ney, H.; and Bowden,R. 2018. Neural sign language translation. In CVPR. | 跟蹤器來處理形狀變化和遮擋 | 外部工具阻礙了對神經網路可微結構的端到端學習 |
| 2019 | Koller, O.; Camgoz, C.; Ney, H.; and Bowden, R. 2019. Weakly supervised learning with multi-stream cnn-lstm-hmms to discover sequential parallelism in sign language videos. TPAMI. | 用帶有推測標簽的多流網路(如口形標簽、手形標簽)引導每個流關注手語視覺線索 | 多流網路帶來了同一區域的重復特征提取,提高了計算開銷, |
??To temporally exploit multi-cue features, an intuitive idea is to concatenate features and feed them into a temporal fusion module. In action recognition, two-stream fusion shows significant performance improvement by fusing temporal features of RGB and optical flow (Simonyan and Zisserman 2014; Feichtenhofer, Pinz, and Zisserman 2016). Nevertheless, the aforementioned fusion approaches are based on two counterpart features in terms of the representation capability. But when it turns to multiple diverse cues with unequal feature importance, how to fully exploit the synergy between strong features and weak features still leaves a challenge. Moreover, for deep learning based methods, neural networks tend to merely focus on strong features for quick convergence, potentially omitting other informative cues, which limits the further performance improvement.
??為了利用短暫的多線索特征,一種直觀的想法是將特征連接起來,并將它們輸入一個時間融合模塊,在動作識別方面,通過融合RGB和 optical flow 的時間特征,雙流融合顯著提高了性能(Simonyan and Zisserman 2014;Feichtenhofer, Pinz和Zisserman 2016),然而,上述的融合方法在表示能力方面是基于兩個對等的特征,但當它轉向多個不同的特征重要性不等的線索時,如何充分利用強特征和弱特征之間的協同作用仍然是一個挑戰,此外,對于基于深度學習的方法,神經網路往往只關注強特征以快速收斂,可能忽略其他資訊線索,這限制了進一步的性能改進,
- optical flow:光流???
同一時間段里多個部位如何協同問題:比如中國手語中的“聚餐”,在一個短暫的時間段里要識別 雙手,頭,嘴,
| 問題 | 年份 | 論文 | 方法 | 優點 | 缺點 |
|---|---|---|---|---|---|
| 同一時間段里多個部位如何協同 | 2008 | The Significance of Facial Features for Automatic Sign Language Recognition | 將手動特征和面部特征合并到一個特征向量 z t = [ x t , y t ] \boldsymbol{z}_{t}=\left[\boldsymbol{x}_{t}, \boldsymbol{y}_{t}\right] zt?=[xt?,yt?] | 暫不知,猜:用此方法來構建特征,再用深度學習來訓練會不會有效果 | 猜:需要把手動特征和面部特征用公式表示,計算難,難以實作 |
| 2014 | Simonyan, K., and Zisserman, A. 2014. Two-stream convolutional networks for action recognition in videos. In NeurIPS. | 將特征連接起來,通過融合RGB和 optical flow 的時間特征 | 性能顯著提高 | 此融合方法在表達能力方面是基于兩個對等的特征,但當它轉向多個不同的特征重要性不等的線索時,強特征和弱特征之間的協同作用仍然是一個挑戰 | |
| 同上 | 2016 | Feichtenhofer, C.; Pinz, A.; and Zisserman, A. 2016. Convolutional two-stream network fusion for video action recognition. In CVPR. | 同上 | 同上 | 同上 |
基于深度學習的方法,神經網路往往只關注強特征以快速收斂,可能忽略其他資訊線索,這限制了進一步的性能改進,
??To address the above difficulties, we propose a novel spatial-temporal multi-cue (STMC) framework. In the SMC module, we add two extra deconvolutional layers (Zeiler et al. 2010; Xiao, Wu, and Wei 2018) for pose estimation on the top layer of our backbone. A soft-argmax trick (Chapelle and Wu 2010) is utilized to regress the positions of keypoints and make it differentiable for subsequent operations in the temporal part. The spatial representations of other cues are acquired by the reuse of feature maps from the middle layer. Based on the learned spatial representations, we decompose the temporal modelling part into the intra-cue path and inter-cue path in the TMC module. The inter-cue path fuses the temporal correlations between different cues with temporal convolutional (TCOV) layers. The intra-cue path models the internal temporal dependency of each cue and feeds them to the inter-cue path at different time scales. To fully exploit the potential of STMC network, we design a joint optimization strategy with connectionist temporal classification (CTC) (Graves et al. 2006) and keypoint regression, making the whole structure end-to-end trainable.
??針對上述問題,我們提出了一種新的時空多線索(STMC)框架,在 SMC 模塊中,我們增加了兩個額外的反卷積層(Zeiler et al. 2010;Xiao, Wu, and Wei 2018),用于框架頂層的姿態估計,利用一種 soft-argmax 技巧(Chapelle and Wu 2010)對關鍵點的位置進行回歸,使其在短暫的時間內可微,通過對中間層特征圖的重復使用,獲得其他線索的空間表示,基于學習到的空間表示,我們在 TMC 模塊中將時間建模部分分解為線索內路徑和線索間路徑,線索間路徑利用時間卷積(TCOV)層融合不同線索之間的時間相關性,線索內路徑對每個線索的內部時間依賴性進行建模,并以不同的時間尺度將它們提供給線索間路徑,為了充分挖掘 STMC 網路的潛力,我們設計了一個結合 connectionist temporal classification (CTC) (Graves et al. 2006)和關鍵點回歸的聯合優化策略,使整個結構端到端可訓練,
| 問題 | 年份 | 論文 | 方法 |
|---|---|---|---|
| 框架頂層的姿態估計 | 2010 | 在 SMC 模塊中加兩個反卷積層 | Zeiler, M. D.; Krishnan, D.; Taylor, G. W.; and Fergus, R. 2010. Deconvolutional networks. In CVPR |
| 同上 | 2018 | Xiao, B.; Wu, H.; and Wei, Y. 2018. Simple baselines for human pose estimation and tracking. In ECCV. | 同上 |
| 對關鍵點的位置進行回歸,使其在短暫的時間內可微 | 2010 | Chapelle, O., and Wu, M. 2010. Gradient descent optimization of smoothed information retrieval metrics. Information Retrieval. | soft-argmax |
| 獲得其他線索的空間表示 | 對中間層特征圖的重復使用 | ||
| 融合不同線索之間的時間相關性 | 時間卷積層 TCOV (temporal convolutional) | ||
| 可端到端訓練 | 2006 | Graves, A.; Fern′andez, S.; Gomez, F.; and Schmidhuber, J. 2006. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In ICML. | 將connectionist temporal classification (CTC) 與關鍵點回歸結合的聯合優化策略 |
用以前(2012年之前)的方法或結合以前的方法來解決新問題
??Our main contributions are summarized as follows:
- We design an SMC module with a self-contained pose estimation branch. It provides multi-cue features in an end-to-end fashion and maintains efficiency at the same time.
- We propose a TMC module composed of stacked TMC blocks. Each block includes intra-cue and inter-cue paths to preserve the uniqueness and explore the synergy of different cues at the same time.
- A joint optimization strategy is proposed for the end-to-end sequence learning of our STMC network.
- Through extensive experiments, we demonstrate that our STMC network surpasses previous state-of-the-art models on three publicly available CSLR benchmarks.
??我們的主要貢獻總結如下: - 設計了一個具有自包含姿態估計分支的SMC模塊,它以端到端的方式提供多線索特性,同時保持效率,
- 我們提議一個由堆疊的TMC塊組成的TMC模塊,每個塊包括線索內路徑和線索間路徑,以保持不同線索的獨特性,同時探索不同線索的協同性,
- 對STMC網路的端到端序列學習提出了一種聯合優化策略,
- 通過廣泛的實驗,我們證明了我們的STMC網路在三個公開可用的CSLR基準上超越了以前最先進的模型,
2?Related Work
In this section, we briefly review the related work on sign language recognition and multi-cue fusion.
在本節中,我們簡要回顧了手語識別和多線索融合的相關作業,
??A CSLR system usually consists of two parts: video representation and sequence learning. Early works utilize handcrafted features (Cooper and Bowden 2009; Buehler, Zisser-man, and Everingham 2009; Yin, Chai, and Chen 2016) for SLR. Recently, deep learning based methods have been applied to SLR for their strong representation capability. 2D convolutional neural networks (2D-CNN) and 3D convolutional neural networks (3D-CNN) (Ji et al. 2013; Qiu, Yao, and Mei 2017) are employed for modelling the appearance and motion in sign language videos. In (Cui, Liu, and Zhang 2017), Cui et al. propose to combine 2D-CNN with temporal convolutional layers for spatial-temporal representation. In (Molchanov et al. 2016; Pu, Zhou, and Li 2018; Zhou, Zhou, and Li 2019; Wei et al. 2019), 3D-CNN is adopted to learn motion features in sign language.
??一個CSLR系統通常由兩個部分組成:視頻表示和序列學習,早期作品使用手工制作的特征(Cooper and Bowden 2009;Buehler, Zisser-man,和Everingham 2009;Yin, Chai, Chen(2016),近年來,基于深度學習的方法因其較強的表示能力而被應用到手語識別中,2D卷積神經網路(2D-CNN)和3D卷積神經網路(3D-CNN) (Ji et al. 2013;Qiu, Yao, and Mei 2017)在手語視頻中使用外觀和動作作為特征的模型,在(Cui, Liu, and Zhang 2017)中,Cui等人提出將2D-CNN與時間卷積層相結合進行時空表示,在(Molchanov等人2016;Pu, Zhou, and Li 2018; Zhou, Zhou, and Li 2019; Wei et al. 2019),采用3D-CNN學習手語的動作特征,
本段首句:一個CSLR系統通常由兩個部分組成:視頻表示和序列學習,承接本章首段“在本節中,我們簡要回顧了手語識別和多線索融合的相關作業,”然后,介紹了以往對 CSRL 系統中視頻表示對研究作業,
| 年份 | 論文 | 方法 |
|---|---|---|
| 2009 | Cooper, H., and Bowden, R. 2009. Learning signs from subtitles: A weakly supervised approach to sign language recognition. In CVPR. | 使用手工制作的特征 |
| 2009 | Buehler, P.; Zisserman, A.; and Everingham, M. 2009. Learning sign language by watching tv (using weakly aligned subtitles). In CVPR. | 使用手工制作的特征 |
| 2016 | Yin, F.; Chai, X.; and Chen, X. 2016. Iterative reference driven metric learning for signer independent isolated sign language recognition. In ECCV. | 使用手工制作的特征 |
| 2013 | Ji, S.; Xu,W.; Yang, M.; and Yu, K. 2013. 3D convolutional neural networks for human action recognition. TPAMI 35(1):221–231. | 使用2D卷積神經網路(2D-CNN)和3D卷積神經網路搭建以外觀和動作為特征的模型 |
| 2017 | Qiu, Z.; Yao, T.; and Mei, T. 2017. Learning spatio-temporal representation with pseudo-3d residual networks. In ICCV. | 使用2D卷積神經網路(2D-CNN)和3D卷積神經網路搭建以外觀和動作為特征的模型 |
| 2017 | Cui, R.; Liu, H.; and Zhang, C. 2017. Recurrent convolutional neural networks for continuous sign language recognition by staged optimization. In CVPR. | 將2D-CNN與時間卷積層相結合進行時空表示 |
| 2016 | Molchanov, P.; Yang, X.; Gupta, S.; Kim, K.; Tyree, S.; and Kautz, J. 2016. Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network. In CVPR. | 采用3D-CNN學習手語的動作特征 |
| 2018 | Pu, J.; Zhou, W.; and Li, H. 2018. Dilated convolutional network with iterative optimization for continuous sign language recognition. In IJCAI. | 采用3D-CNN學習手語的動作特征 |
| 2019 | Zhou, H.; Zhou, W.; and Li, H. 2019. Dynamic pseudo label decoding for continuous sign language recognition. In ICME. | 采用3D-CNN學習手語的動作特征 |
??Sequence learning in CSLR is to learn the correspondence between video sequence and sign gloss sequence. Koller et al. (Koller, Ney, and Bowden 2016; Koller, Zargaran, and Ney 2017; Koller et al. 2018) propose to integrate 2D-CNNs with hidden markov models (HMM) to model the state transitions. In (Cihan Camgoz et al. 2017; Wang et al. 2018;Cui, Liu, and Zhang 2017; Cui, Liu, and Zhang 2019), connectionist temporal classification (CTC) (Graves et al. 2006) algorithm is employed as a cost function for CSLR, which is able to process unsegmented input data. In (Huang et al. 2018; Guo et al. 2018), the attention-based encoder-decoder model (Bahdanau, Cho, and Bengio 2014) is adopted to deal with CSLR in the way of neural machine translation.
??CSLR中的序列學習是學習視頻序列和 sign gloss 序列之間的對應關系,Koller等人(Koller, Ney和Bowden 2016;Koller, Zargaran和Ney 2017;Koller等人2018年)提出將2D-CNNs與隱馬爾可夫模型(HMM)集成,以對狀態轉換進行建模,在 (Cihan Camgoz et al. 2017; Wang et al. 2018;Cui, Liu, and Zhang 2017; Cui, Liu, and Zhang 2019)CSLR 采用 connectionist temporal classification (CTC) (Graves et al. 2006)演算法作為代價函式,能夠處理未分割的輸入資料,在 (Huang et al. 2018;Guo et al. 2018),中采用基于注意力機制的編碼-解碼器模型(Bahdanau, Cho, and Bengio 2014)的神經機器翻譯方式處理CSLR,
本段首句:CSLR 中的序列學習是學習視頻序列和 sign gloss 序列之間的對應關系,承接上一段首句“一個CSLR系統通常由兩個部分組成:視頻表示和序列學習,”然后,介紹了 以往對 CSRL 中序列學習的研究作業,
| 年份 | 論文 | 方法 |
|---|---|---|
| 2016 | Koller, O.; Zargaran, O.; Ney, H.; and Bowden, R. 2016. Deep sign: hybrid cnn-hmm for continuous sign language recognition. In BMVC. | 將2D-CNNs與隱馬爾可夫模型(HMM)集成,以對狀態轉換進行建模 |
| 2017 | Koller, O.; Zargaran, S.; and Ney, H. 2017. Re-sign: re-aligned end-to-end sequence modelling with deep recurrent cnn-hmms. In CVPR. | 將2D-CNNs與隱馬爾可夫模型(HMM)集成,以對狀態轉換進行建模 |
| 2018 | Koller, O.; Zargaran, S.; Ney, H.; and Bowden, R. 2018. Deep sign: enabling robust statistical continuous sign language recognition via hybrid cnn-hmms. IJCV 126(12):1311–1325. | 將2D-CNNs與隱馬爾可夫模型(HMM)集成,以對狀態轉換進行建模 |
| 2017 | Cui, R.; Liu, H.; and Zhang, C. 2017. Recurrent convolutional neural networks for continuous sign language recognition by staged optimization. In CVPR. | 在 CSRL 中采用 connectionist temporal classification (CTC) 演算法作為代價函式,能夠處理未分割的輸入資料, |
| 2017 | Cihan Camgoz, N.; Hadfield, S.; Koller, O.; and Bowden, R. 2017. Subunets: end-to-end hand shape and continuous sign language recognition. In ICCV. | 在 CSRL 中采用 connectionist temporal classification (CTC) 演算法作為代價函式,能夠處理未分割的輸入資料, |
| 2018 | Wang, S.; Guo, D.; Zhou, W.-g.; Zha, Z.-J.; and Wang, M. 2018. Connectionist temporal fusion for sign language translation. In ACM MM. | 在 CSRL 中采用 connectionist temporal classification (CTC) 演算法作為代價函式,能夠處理未分割的輸入資料, |
| 2019 | Cui, R.; Liu, H.; and Zhang, C. 2019. A deep neural framework for continuous sign language recognition by iterative training. TMM 21(7):1880–1891. | 在 CSRL 中采用 connectionist temporal classification (CTC) 演算法作為代價函式,能夠處理未分割的輸入資料, |
| 2006 | Graves, A.; Fern′andez, S.; Gomez, F.; and Schmidhuber, J. 2006. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In ICML. | 提出connectionist temporal classification (CTC) |
| 2014 | Bahdanau, D.; Cho, K.; and Bengio, Y. 2014. Neural machine translation by jointly learning to align and translate. In ICLR. | 提出基于注意力機制的編碼-解碼器模型 |
| 2018 | Huang, J.; Zhou, W.; Zhang, Q.; Li, H.; and Li, W. 2018. Videobased sign language recognition without temporal segmentation. In AAAI. | 采用基于注意力機制的編碼-解碼器模型的神經機器翻譯方式處 CSLR |
| 2018 | Guo, D.; Zhou, W.; Li, H.; and Wang, M. 2018. Hierarchical lstm for sign language translation. In AAAI. | 采用基于注意力機制的編碼-解碼器模型的神經機器翻譯方式處 CSLR |
??The multiple cues of sign language can be separated into categories of multi-modality and multi-semantic. Early works about multi-modality utilize physical sensors to collect the 3D space information, such as depth and infrared maps (Molchanov et al. 2016; Liu et al. 2017). With the development of flow estimation, Cui et al. (Cui, Liu, and Zhang 2019) explore the multi-modality fusion of RGB and optical flow and achieve state-of-the-art performance on PHOENIX-2014 database. In contrast, multi-semantic refers to human body parts with different semantics. Early works use hand-crafted features from segmented hands, tracked body-parts and trajectories for recognition (Buehler, Zisser-man, and Everingham 2009; Pfister, Charles, and Zisserman 2013; Koller, Forster, and Ney 2015). In (Cihan Camgoz et al. 2017; Huang et al. 2018), feature sequence of hand patches captured by a tracker is fused with feature sequence of full-frames for further sequence prediction. In (Koller et al. 2019), Koller et al. propose to infer weak mouth labels from spoken German annotations and weak hand labels from SL dictionaries. These weak labels are used to establish the state synchronization in HMM of different cues, including full-frame, hand shape and mouth shape. Unlike previous methods, we propose an end-to-end differentiable network for multi-cue fusion with joint optimization, which achieves excellent performance.
??手語的多種線索可分為多模態和多語意兩大類,關于多模態的早期作業是利用物理傳感器來收集三維空間資訊,如深度和紅外地圖(Molchanov et al. 2016; Liu et al. 2017),隨著流量估計技術的發展,Cui等(Cui, Liu, and Zhang 2019)探索了RGB光流的多模態融合,并在PHOENIX-2014資料庫上實作了最先進的性能,而多語意指的是具有不同語意的人體部位,早期的研究使用了 hand-crafted features :分割手部,跟蹤身體的部分肢體和軌跡識別(Buehler, Zisser-man, and Everingham 2009;Pfister, Charles和Zisserman 2013;Koller, Forster和Ney, 2015年),在(Cihan Camgoz et al. 2017;(Huang et al. 2018),將跟蹤器捕獲的手部貼片特征序列與全幀特征序列融合,進一步進行序列預測,在(Koller et al. 2019)中,Koller et al.提出從德語口語注釋推斷弱口標簽,從SL詞典推斷弱手標簽,這些弱標簽用于在HMM中建立不同線索的狀態同步,包括全幀、手形和嘴形,與以往的方法不同,我們提出了一種基于聯合優化的端到端可微網路用于多線索融合,取得了良好的性能,
本段首句:手語的多種線索可分為多模態和多語意兩大類,承接本章首段“在本節中,我們簡要回顧了手語識別和多線索融合的相關作業,”然后,介紹了以往對手語識別中多線索融合的研究作業,
| 年份 | 論文 | 方法(解決 SRL 多線索中的多模態問題) |
|---|---|---|
| 2016 | Molchanov, P.; Yang, X.; Gupta, S.; Kim, K.; Tyree, S.; and Kautz, J. 2016. Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network. In CVPR. | 利用物理傳感器來收集三維空間資訊,比如:depth and infrared maps |
| 2017 | Liu, Z.; Chai, X.; Liu, Z.; and Chen, X. 2017. Continuous gesture recognition with hand-oriented spatiotemporal feature. In ICCV. | 利用物理傳感器來收集三維空間資訊,比如:depth and infrared maps |
| 2019 | Cui, R.; Liu, H.; and Zhang, C. 2019. A deep neural framework for continuous sign language recognition by iterative training. TMM 21(7):1880–1891. | 探索了RGB光流的多模態融合,并在PHOENIX-2014資料庫上實作了最先進的性能 |
| 年份 | 論文 | 方法(解決 SRL 多線索中的多語意問題) |
|---|---|---|
| 2009 | Buehler, P.; Zisserman, A.; and Everingham, M. 2009. Learning sign language by watching tv (using weakly aligned subtitles). In CVPR. | 使用了 hand-crafted features :分割手部,跟蹤身體的部分肢體和軌跡識別 |
| 2013 | Pfister, T.; Charles, J.; and Zisserman, A. 2013. Large-scale learning of sign language by watching tv (using co-occurrences). In BMVC. | 使用了 hand-crafted features :分割手部,跟蹤身體的部分肢體和軌跡識別 |
| 2015 | Koller, O.; Forster, J.; and Ney, H. 2015. Continuous sign language recognition: Towards large vocabulary statistical recognition systems handling multiple signers. CVIU 141:108–125. | 使用了 hand-crafted features :分割手部,跟蹤身體的部分肢體和軌跡識別 |
| 2017 | Cihan Camgoz, N.; Hadfield, S.; Koller, O.; and Bowden, R. 2017. Subunets: end-to-end hand shape and continuous sign language recognition. In ICCV. | 將跟蹤器捕獲的手部貼片特征序列與全幀特征序列融合,進一步進行序列預測 |
| 2018 | Huang, J.; Zhou, W.; Zhang, Q.; Li, H.; and Li, W. 2018. Videobased sign language recognition without temporal segmentation. In AAAI. | 將跟蹤器捕獲的手部貼片特征序列與全幀特征序列融合,進一步進行序列預測 |
| 2019 | Koller, O.; Camgoz, C.; Ney, H.; and Bowden, R. 2019. Weakly supervised learning with multi-stream cnn-lstm-hmms to discover sequential parallelism in sign language videos. TPAMI. | 從德語口語注釋推斷弱口標簽,從SL詞典推斷弱手標簽,這些弱標簽用于在HMM中建立不同線索的狀態同步,包括全幀、手形和嘴形 |
3?Proposed Approach
In this section, we first introduce the overall architecture of the proposed method. Then we elaborate the key components in our framework, including the spatial multi-cue (SMC) module and temporal multi-cue (TMC) module. Finally, we detail the sequence learning part and the joint loss optimization of our spatial-temporal multi-cue (STMC) framework.
在本節中,我們首先介紹所提方法的整體架構,然后詳細闡述了該框架的關鍵組成部分,包括空間多線索模塊和時間多線索模塊,最后,我們詳細介紹了序列學習部分和聯合損失優化的時空多線索(STMC)框架,
3.1?Framework Overview
Given a video
x
=
{
x
t
}
t
=
1
T
\mathbf{x}=\left\{x_{t}\right\}_{t=1}^{T}
x={xt?}t=1T?with T frames, the target of CSLR task is to predict its corresponding sign gloss sequence
?
=
{
?
i
}
i
=
1
L
\ell=\left\{\ell_{i}\right\}_{i=1}^{L}
?={?i?}i=1L? with L words. As illustrated in Figure 1, our framework consists of three key modules, i.e., spatial representation, temporal modelling and sequence learning. First, each frame is processed by an SMC module to generate spatial features of multiple cues, including full-frame, hand, face and pose. Then, a TMC module is leveraged to capture the temporal correlations of intra-cue features and inter-cue features at different time steps and time scales. Finally, the whole STMC network equipped with bidirectional Long-Short Term Memory (BLSTM) (Hochreiter and Schmidhuber 1997) encoders utilizes connectionist temporal classification (CTC) for sequence learning and inference.
CSLR 的目的是使視頻幀 X 與手語字 L 相對應,如圖1所示,我們的框架由三個關鍵模塊組成,即空間表示、時間建模和序列學習,首先,利用 SMC 模塊對每一幀進行處理,生成包括全幀、手、臉和姿態等多種線索的空間特征; 然后,利用TMC模塊捕捉線索內特征和線索間特征在不同時間步長和時間尺度上的時間相關性,最后,整個 STMC 網路配備了雙向長期記憶(BLSTM) (Hochreiter and Schmidhuber 1997)編碼器,利用連接主義者時間分類(CTC)進行序列學習和推理,  Figure 1: An overview of the proposed STMC framework. The SMC module is firstly utilized to decompose spatial features of visual cues for T frames in a video. Strips with different colors represent feature sequences of different cues. Then, the feature sequences of cues are fed into the TMC module with stacked TMC blocks and temporal pooling (TP) layers. The output of TMC module consists of feature sequence in the inter-cue path and feature sequences of N cues in the intra-cue path, which are processed by BLSTM encoders and CTC layers for sequence learning and inference. Here, N denotes the number of cues.
Figure 1: An overview of the proposed STMC framework. The SMC module is firstly utilized to decompose spatial features of visual cues for T frames in a video. Strips with different colors represent feature sequences of different cues. Then, the feature sequences of cues are fed into the TMC module with stacked TMC blocks and temporal pooling (TP) layers. The output of TMC module consists of feature sequence in the inter-cue path and feature sequences of N cues in the intra-cue path, which are processed by BLSTM encoders and CTC layers for sequence learning and inference. Here, N denotes the number of cues.
圖1:建議的 STMC 框架的概述,首先利用 SMC 模塊對視頻 T 幀的視覺線索進行空間特征分解,不同顏色的條帶代表不同線索的特征序列,然后,將線索特征序列輸入基于 temporal pooling (TP) 層和 TMC blocks 的 TMC 模塊,TMC模塊的輸出由線索間路徑的特征序列和線索內路徑的 N 個線索的特征序列組成,通過 BLSTM 編碼器和 CTC 層進行序列學習和推理,這里,N 表示線索的數量,
T
×
H
×
W
×
3
\mathrm{T} \times \mathrm{H} \times \mathrm{W} \times 3
T×H×W×3:T幀 × H高 × W寬 × 3通道(RGB
SMC:Spatial Multi-Cue (SMC) 空間多線索
T
×
(
C
1
+
?
+
C
N
)
\mathrm{T} \times\left(C_{1}+\cdots+C_{N}\right)
T×(C1?+?+CN?):T幀 × (線索1 + 線索2 +…+ 線索N);本文的線索可以理解為特征部位,比如,線索1是 Full-frame;線索2是 手形 Shape;線索3是 面部表情 Head;線索4是 姿勢 Bodyjoints,
-
TMC Block:Temporal Multi-Cue Block 時間多線索塊
-
TP:Temporal Pooling 時序池化
2 × T 2 \times \mathrm{T} 2×T :2 × T幀 ???
2 × C 2 \times \mathrm{C} 2×C:2 × C個線索 ???
4 × C 4 \times \mathrm{C} 4×C:4 × C個線索 ???
BLSTM:bidirectional Long-Short Term Memory 雙向長短時記憶,詳情參考 作者: herosunly
CTC:connectionist temporal classification 連接主義時間分類 ,用來解決輸入序列和輸出序列難以一一對應的問題,詳情參考 作者:yudonglee
-
Inference:Friday is expected with sunshine
識別出:周五有可能出太陽, -
Optimization:Joint Loss
優化:加入損失函式
3.2?Spatial Multi-Cue Representation
In spatial representation module, 2D-CNN is adopted to generate multi-cue features of full-frame, hands, face and pose. Here, we select VGG-11 model (Simonyan and Zisserman 2015) as the backbone network, considering its simple but effective neural architecture design. As depicted in Figure 2, the operations in SMC are composed of three steps: pose estimation, patch cropping and feature generation.
在空間表示模塊中,采用 2D-CNN 生成全幀、手、臉、姿態的多線索特征,在這里,我們選擇 VGG-11 模型(Simonyan and Zisserman 2015)作為骨干網,考慮到其簡單而有效的神經結構設計,如圖2所示,SMC 的操作包括姿態估計、patch 裁剪和 feature 生成三個步驟,
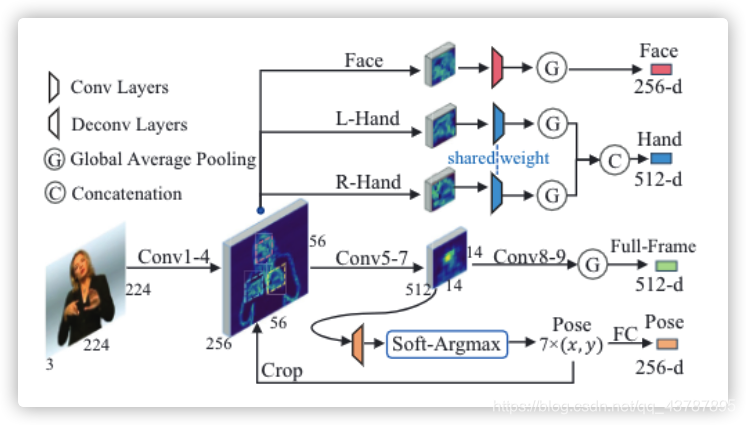
Figure 2: The SMC Module. The keypoints are estimated for patch cropping of face and hands. The output of SMC includes features from full-frame, hands, face and pose.
圖2:SMC 模塊,估計出人臉和手的關鍵點并進行 patch 裁剪,SMC 的輸出包括全幀圖、手、臉、姿態等特征,
模型選擇:VGG-11(2015年 Simonyan, K., and Zisserman, A. 2015. Very deep convolutional networks for large-scale image recognition. In ICLR.)作為骨干網路
- crop:修剪
Pose Estimation.?Deconvolutional networks (Zeiler et al. 2010) are widely used in pixel-wise prediction. For pose estimation, two deconvolutional layers are added after the 7-th convolutional layer of VGG-11. The stride of each layer is 2. So, the feature maps are 4× upsampled from the resolution 14×14 to 56×56. The output is fed into a point-wise convolutional layer to generate K predicted heat maps. In each heat map, the position of its corresponding keypoint is expected to show the highest response value. Here, K is set to 7 for keypoints at the upper body, including the nose, both shoulders, both elbows and both wrists.
姿態估計.?反卷積網路(Zeiler et al. 2010)廣泛應用于像素級預測,對于姿態估計,在VGG-11的第7個卷積層之后增加了2個反卷積層,每一層的步長為2,因此,從14×14到56×56的解析度對特征圖進行了4倍的更新采樣,輸出反饋入各個點的卷積層,以生成K個預測熱圖,在每一張熱圖中,期望其對應的關鍵點的位置表現出最高的回應值,在這里,上半身的關鍵部位K值設為7,包括鼻子、肩膀、肘部和手腕,
??To make the keypoint prediction differentiable for subsequent sequence learning, a soft-argmax layer is applied on K these heat maps. Denoting K heat maps as
h
=
{
h
k
}
k
=
1
K
\mathbf{h}=\left\{h_{k}\right\}_{k=1}^{K}
h={hk?}k=1K?, each heat map
h
k
∈
R
H
×
W
h_{k} \in \mathbb{R}^{H \times W}
hk?∈RH×W is passed through a spatial softmax function as follows,
???????????????
p
i
,
j
,
k
=
e
h
i
,
j
,
k
∑
i
=
1
H
∑
j
=
1
W
e
h
i
,
j
,
k
p_{i, j, k}=\frac{e^{h_{i, j, k}}}{\sum_{i=1}^{H} \sum_{j=1}^{W} e^{h_{i, j, k}}}
pi,j,k?=∑i=1H?∑j=1W?ehi,j,k?ehi,j,k??,??????(1)
where
h
i
,
j
,
k
h_{i, j, k}
hi,j,k? is the value of heat map
h
k
h_{k}
hk? at position
(
i
,
j
)
(i, j)
(i,j) and
p
i
,
j
,
k
p_{i, j, k}
pi,j,k? is the probability of keypoint k at position
(
i
,
j
)
(i, j)
(i,j). Afterwards, the expected values of coordinates along x-axis and y-axis over the whole probability map are calculated as follows,
???????????????
(
x
^
,
y
^
)
k
=
(
∑
i
=
1
H
∑
j
=
1
W
i
?
1
H
?
1
p
i
,
j
,
k
,
∑
i
=
1
H
∑
j
=
1
W
j
?
1
W
?
1
p
i
,
j
,
k
)
(\hat{x}, \hat{y})_{k}=\left(\sum_{i=1}^{H} \sum_{j=1}^{W} \frac{i-1}{H-1} p_{i, j, k}, \sum_{i=1}^{H} \sum_{j=1}^{W} \frac{j-1}{W-1} p_{i, j, k}\right)
(x^,y^?)k?=(∑i=1H?∑j=1W?H?1i?1?pi,j,k?,∑i=1H?∑j=1W?W?1j?1?pi,j,k?),??????(2)
Here,
J
k
=
(
x
^
,
y
^
)
k
∈
[
0
,
1
]
J_{k}=(\hat{x}, \hat{y})_{k} \in[0,1]
Jk?=(x^,y^?)k?∈[0,1] is the normalized predicted position of keypoint k. The corresponding position of
(
x
,
y
)
(x, y)
(x,y) in a
H
×
W
H \times W
H×W feature map is
(
x
^
(
H
?
1
)
+
1
,
y
^
(
W
?
1
)
+
1
)
(\hat{x}(H-1)+1, \hat{y}(W-1)+1)
(x^(H?1)+1,y^?(W?1)+1).
??為了使關鍵點預測可微,便于后續序列學習,在這些K個預測熱圖上應用了soft-argmax層,K個預測的熱圖表示為
h
=
{
h
k
}
k
=
1
K
\mathbf{h}=\left\{h_{k}\right\}_{k=1}^{K}
h={hk?}k=1K?,每張熱圖的
h
k
∈
R
H
×
W
h_{k} \in \mathbb{R}^{H \times W}
hk?∈RH×W 是通過如下的 空間 softmax 函式計算的,
?????????????
p
i
,
j
,
k
=
e
h
i
,
j
,
k
∑
i
=
1
H
∑
j
=
1
W
e
h
i
,
j
,
k
p_{i, j, k}=\frac{e^{h_{i, j, k}}}{\sum_{i=1}^{H} \sum_{j=1}^{W} e^{h_{i, j, k}}}
pi,j,k?=∑i=1H?∑j=1W?ehi,j,k?ehi,j,k??,??????(1)
其中,
h
i
,
j
,
k
h_{i, j, k}
hi,j,k? 是熱圖
h
k
h_{k}
hk? 在點
(
i
,
j
)
(i, j)
(i,j) 處的值,
p
i
,
j
,
k
p_{i, j, k}
pi,j,k? 是關鍵點 K 在
(
i
,
j
)
(i, j)
(i,j) 的概率,然后,如下計算整個概率圖上x軸坐標和y軸坐標的期望值:
?????????????
(
x
^
,
y
^
)
k
=
(
∑
i
=
1
H
∑
j
=
1
W
i
?
1
H
?
1
p
i
,
j
,
k
,
∑
i
=
1
H
∑
j
=
1
W
j
?
1
W
?
1
p
i
,
j
,
k
)
(\hat{x}, \hat{y})_{k}=\left(\sum_{i=1}^{H} \sum_{j=1}^{W} \frac{i-1}{H-1} p_{i, j, k}, \sum_{i=1}^{H} \sum_{j=1}^{W} \frac{j-1}{W-1} p_{i, j, k}\right)
(x^,y^?)k?=(∑i=1H?∑j=1W?H?1i?1?pi,j,k?,∑i=1H?∑j=1W?W?1j?1?pi,j,k?),??????(2)
這里的
J
k
=
(
x
^
,
y
^
)
k
∈
[
0
,
1
]
J_{k}=(\hat{x}, \hat{y})_{k} \in[0,1]
Jk?=(x^,y^?)k?∈[0,1] 是關鍵預測點k的歸一化,
(
x
,
y
)
(x, y)
(x,y)在
H
×
W
H \times W
H×W 特征圖中對應的點為
(
x
^
(
H
?
1
)
+
1
,
y
^
(
W
?
1
)
+
1
)
(\hat{x}(H-1)+1, \hat{y}(W-1)+1)
(x^(H?1)+1,y^?(W?1)+1),
Patch Cropping.?In CSLR, the perception of detailed visual cues is vital, including eye gaze, facial expression, mouth shape, hand shape and orientations of hands. Our model takes predicted positions of the nose and both wrists as the center points of the face and both hands. The patches are cropped from the output (56 × 56 × C4) of 4-th convolutional layer of VGG-11. The cropping sizes are fixed to 24 × 24 for both hands and 16 × 16 for the face. It’s large enough to cover body parts of a signer whose upper body is visible to the camera. The center point of each patch is clamped into a range to ensure that the patch would not cross the border of the original feature map.
貼片裁剪.?在CSLR中,對眼睛注視、面部表情、嘴型、手型和手的方向等視覺細節資訊的感知至關重要,我們的模型以鼻子和兩個手腕的預測位置作為臉和雙手的中心點,從VGG-11的第四卷積層輸出(56 × 56 × C4)中裁剪貼片,雙手裁剪尺寸固定為24 × 24,臉部裁剪尺寸固定為16 × 16,它足夠大,可以覆寫一個上半身可以被攝像頭看到的手語者的身體部分,將每個的中心點夾入一個范圍內,以保證貼片不會越過原始特征圖的邊界,
Feature Generation. ?After K keypoints are predicted, they are flattened to a 1D-vector with dimension 2K and passed through two fully-connected (FC) layers with ReLU to get the feature vector of pose cue. Then, feature maps of the face and both hands are cropped and processed by several convolutional layers, separately. Most sign gestures rely on the cooperation of both hands. So we use weight-sharing convolutional layers for both hands. The outputs of them are concatenated along the channel-dimension. Finally, we perform global average pooling over all the feature maps with spatial dimension to form feature vectors of different cues.
提取特征.?對K個關鍵點進行預測后,將其平化為維數為2K的一維向量,并通過兩個全連接層(FC)用ReLU作為激活函式得到姿態線索的特征向量,然后,分別通過多個卷積層對人臉和雙手的特征圖進行裁剪處理,因為大多數手語都是依靠雙手的配合,所以我們用于提取雙手的卷積層共享權重,它們的輸出沿著通道維度連接,最后,我們對所有空間維度的特征圖進行全域平均池化,形成不同線索的特征向量,
All features are extracted by passing frames
x
=
{
x
t
}
t
=
1
T
\mathbf{x}=\left\{x_{t}\right\}_{t=1}^{T}
x={xt?}t=1T? through our spatial multi-cue (SMC) module as follows,
????????????????
{
{
f
t
,
n
}
n
=
1
N
,
{
J
t
,
k
}
k
=
1
K
}
t
=
1
T
=
{
Ω
θ
(
x
t
)
}
t
=
1
T
\left\{\left\{f_{t, n}\right\}_{n=1}^{N},\left\{J_{t, k}\right\}_{k=1}^{K}\right\}_{t=1}^{T}=\left\{\Omega_{\theta}\left(x_{t}\right)\right\}_{t=1}^{T}
{{ft,n?}n=1N?,{Jt,k?}k=1K?}t=1T?={Ωθ?(xt?)}t=1T?,??????(3)
where
Ω
θ
(
?
)
\Omega_{\theta}(\cdot)
Ωθ?(?) denotes SMC module and
θ
\theta
θ denotes the parameters of it.
J
t
,
k
∈
R
2
J_{t, k} \in \mathbb{R}^{2}
Jt,k?∈R2 is the position of keypoint k at the t-th frame.
f
t
,
n
∈
R
C
n
f_{t, n} \in \mathbb{R}^{C_{n}}
ft,n?∈RCn? is the feature vector of visual cue n at the t-th frame. In this paper, we set N = 4, which represents visual cues of full-frame, hand, face and pose, respectively.
傳遞幀
x
=
{
x
t
}
t
=
1
T
\mathbf{x}=\left\{x_{t}\right\}_{t=1}^{T}
x={xt?}t=1T? 通過我們的空間多線索(spatial multi-cue, SMC)模塊來提取所有特征,如下所示:
????????????????
{
{
f
t
,
n
}
n
=
1
N
,
{
J
t
,
k
}
k
=
1
K
}
t
=
1
T
=
{
Ω
θ
(
x
t
)
}
t
=
1
T
\left\{\left\{f_{t, n}\right\}_{n=1}^{N},\left\{J_{t, k}\right\}_{k=1}^{K}\right\}_{t=1}^{T}=\left\{\Omega_{\theta}\left(x_{t}\right)\right\}_{t=1}^{T}
{{ft,n?}n=1N?,{Jt,k?}k=1K?}t=1T?={Ωθ?(xt?)}t=1T?,??????(3)
這里的
Ω
θ
(
?
)
\Omega_{\theta}(\cdot)
Ωθ?(?) 代表 SMC 模型,
θ
\theta
θ 是 SMC 模型的引數,
J
t
,
k
∈
R
2
J_{t, k} \in \mathbb{R}^{2}
Jt,k?∈R2 是關鍵點k在第t個坐標系的位置,
f
t
,
n
∈
R
C
n
f_{t, n} \in \mathbb{R}^{C_{n}}
ft,n?∈RCn? 是第 t 幀中視覺線索 n 的特征向量,在本文中,我們設 N = 4,分別表示全幀、手、臉和姿態的視覺線索,
輸入 T 幀 尺寸為 H × W 的 包含 3 通道的 RGB 影像,比如將 T 幀個 3×244×244 的影像輸入到 SMC 模塊,經 SMC 模塊中的 VGG-11 網路中 1–4 層網路處理得到 T 幀個 256×56×56 的影像,然后對影像進姿態估計,裁剪出面部、雙手,并用 5–7 層網路提取到 signer 整體姿態得到 T 幀個 512×14×14 的影像,然后在第 7 層網路后加 2 層步長為 2 的反卷積層,然后將得到的特征圖進行整張圖的一個均值池化,形成一個特征點,將這些特征點組成最后 512 維的特征向量即為 Full-Frame 特征向量,而在經過 1–4 層網路處理得到 T 幀個 256×56×56 的影像,并對影像進姿態估計,裁剪出面部、雙手,對裁剪出的面部、雙手都輸入 ? 層卷積網路,并將得到的特征圖進行整張圖的一個均值池化,形成一個特征點,將這些特征點組成最后的特征向量,其中左右手共享權重,并在 ? 層卷積后 Concatenation 在一起,最終得到 256 維的面部特征向量和 512 維的雙手特征向量,用 5–7 層網路提取到 signer 整體姿態得到 T 幀個 512×14×14 的影像經過 ? 層反卷積層后輸入到 Soft-Aramax 得到 7 個姿態的關鍵點,然后將其平化為維數為 2×7 個一維向量,并通過兩個全連接層 (FC) 用 ReLU 作為激活函式得到姿態特征 256 維的特征向量,得到的 7 個姿態的關鍵點反饋到第 4 層后的 256×56×56 的影像,對其進行修剪,
Soft-Aramax:結合 softmax 函式(一種指數歸一化函式) ,達到argmax的目的(尋找引數最大值的索引),同時使得程序可導,詳情參考 1?詳情參考 2
3.3?Temporal Multi-Cue Modelling
Instead of simple fusion, our proposed temporal multi-cue (TMC) module intends to integrate spatiotemporal information from two aspects, intra-cue and inter-cue. The intra-cue path captures the unique features of each visual cue. The inter-cue path learns the combination of fused features from different cues at different time scales. Then, we define a TMC block to model the operations between the two paths as follows,
????????????????
(
o
l
,
f
l
)
=
Block
?
l
(
o
l
?
1
,
f
l
?
1
)
\left(o_{l}, f_{l}\right)=\operatorname{Block}_{l}\left(o_{l-1}, f_{l-1}\right)
(ol?,fl?)=Blockl?(ol?1?,fl?1?),??????(4)
where
(
o
l
?
1
,
f
l
?
1
)
\left(o_{l-1}, f_{l-1}\right)
(ol?1?,fl?1?) and
(
o
l
,
f
l
)
\left(o_{l}, f_{l}\right)
(ol?,fl?) are the input pair and output pair of the
l
l
l-th block.
o
l
∈
R
T
×
C
o
o_{l} \in \mathbb{R}^{T \times C_{o}}
ol?∈RT×Co? denotes the feature matrix of the inter-cue path.
f
l
∈
R
T
×
C
f
f_{l} \in \mathbb{R}^{T \times C_{f}}
fl?∈RT×Cf? denotes the feature matrix of the intra-cue path which is the concatenation of vectors from different cues along channel-dimension. As the first input pair,
o
1
=
f
1
=
[
f
1
,
1
,
f
1
,
2
,
?
?
,
f
1
,
N
]
o_{1}=f_{1}=\left[f_{1,1}, f_{1,2}, \cdots, f_{1, N}\right]
o1?=f1?=[f1,1?,f1,2?,?,f1,N?], where
[
?
]
[\cdot]
[?] is the concatenating operation and N is the number of cues.
我們提出的時序多線索(TMC)模塊并不是簡單的融合,而是從線索內和線索間兩個方面整合時空資訊,線索內路徑捕捉每個視覺線索的獨特特征,線索間路徑學習融合特征在不同時間尺度下的融合特征,然后,我們定義一個 TMC 塊來建模兩條路徑之間的操作,如下所示:
????????????????
(
o
l
,
f
l
)
=
Block
?
l
(
o
l
?
1
,
f
l
?
1
)
\left(o_{l}, f_{l}\right)=\operatorname{Block}_{l}\left(o_{l-1}, f_{l-1}\right)
(ol?,fl?)=Blockl?(ol?1?,fl?1?),??????(4)
這里的
(
o
l
?
1
,
f
l
?
1
)
\left(o_{l-1}, f_{l-1}\right)
(ol?1?,fl?1?) 和
(
o
l
,
f
l
)
\left(o_{l}, f_{l}\right)
(ol?,fl?) 是第
l
l
l 個TMC模塊的輸入對和輸出對,
o
l
∈
R
T
×
C
o
o_{l} \in \mathbb{R}^{T \times C_{o}}
ol?∈RT×Co? 表示線索間路徑的特征矩陣,
f
l
∈
R
T
×
C
f
f_{l} \in \mathbb{R}^{T \times C_{f}}
fl?∈RT×Cf? 表示線索內路徑的特征矩陣,它是不同線索向量沿通道維數的拼接,作為第一對輸入對,
o
1
=
f
1
=
[
f
1
,
1
,
f
1
,
2
,
?
?
,
f
1
,
N
]
o_{1}=f_{1}=\left[f_{1,1}, f_{1,2}, \cdots, f_{1, N}\right]
o1?=f1?=[f1,1?,f1,2?,?,f1,N?],其中
[
?
]
[\cdot]
[?] 代表連接操作,N是線索的數量,
??The detailed operations inside each TMC block are shown in Figure 3 and can be decomposed into two paths as follows. ( C is the number of output channels in each path)
??每個TMC塊內的詳細操作如圖3所示,可以將其分解為如下兩條路徑,(C為每條路徑的輸出通道數)
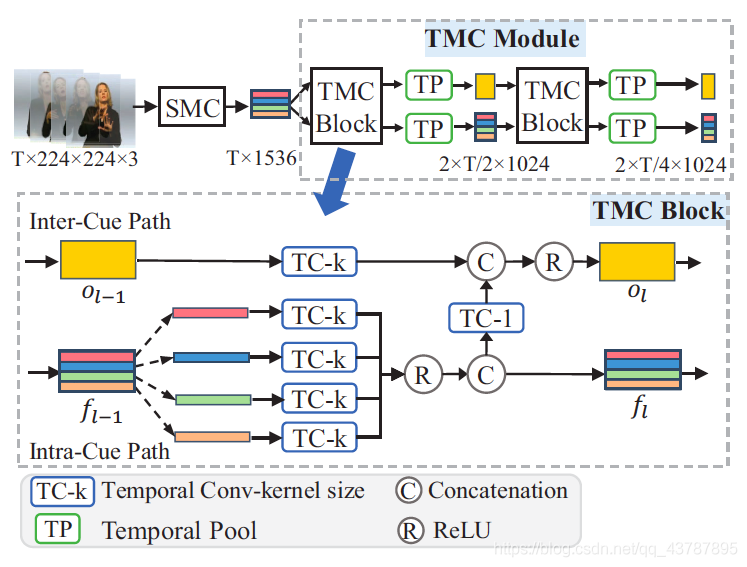
????????????Figure 3: The TMC Module.
- Temporal Conv-kernel size:時序卷積核大小
- Temporal Pool:時序池
Temporal Convolutional Networks 時序卷積網路 參考鏈接 - Concatenation:連接
- ReLU:ReLU激活函式
- o l ? 1 o_{l-1} ol?1? :第 l ? 1 l-1 l?1 個 TMC 模塊的輸入
-
f
l
?
1
f_{l-1}
fl?1? :第
l
?
1
l-1
l?1 個 TMC 模塊的輸出
Intra-Cue Path.?The first path is to provide unique features of different cues at different time scales. The temporal transformation inside each cue is performed as follows,
???????????????? f l , n = ReLU ? ( K k C N ( f l ? 1 , n ) ) , f_{l, n}=\operatorname{ReLU}\left(\mathcal{K}_{k}^{\frac{C}{N}}\left(f_{l-1, n}\right)\right), fl,n?=ReLU(KkNC??(fl?1,n?)),??????(5)
???????????????? f l = [ f l , 1 , f l , 2 , ? ? , f l , ∣ N ] f_{l}=\left[f_{l, 1}, f_{l, 2}, \cdots, f_{l, \mid N}\right] fl?=[fl,1?,fl,2?,?,fl,∣N?].$??????(6)
Here, f l , n ∈ R T × C N f_{l, n} \in \mathbb{R}^{T \times \frac{C}{N}} fl,n?∈RT×NC? denotes the feature matrix of n-th cue. K k C N \mathcal{K}_{k}^{\frac{C}{N}} KkNC?? denotes the kernel of a temporal convolution, where k is the temporal kernel size and C N \frac{C}{N} NC? is the number of output channels.
線索內路徑.?第一種路徑是在不同的時間尺度上提供不同線索的獨特特征,每個線索內部的時序轉換程序如下:
???????????????? f l , n = ReLU ? ( K k C N ( f l ? 1 , n ) ) , f_{l, n}=\operatorname{ReLU}\left(\mathcal{K}_{k}^{\frac{C}{N}}\left(f_{l-1, n}\right)\right), fl,n?=ReLU(KkNC??(fl?1,n?)),??????(5)
???????????????? f l = [ f l , 1 , f l , 2 , ? ? , f l , ∣ N ] f_{l}=\left[f_{l, 1}, f_{l, 2}, \cdots, f_{l, \mid N}\right] fl?=[fl,1?,fl,2?,?,fl,∣N?].$??????(6)
這里的 f l , n ∈ R T × C N f_{l, n} \in \mathbb{R}^{T \times \frac{C}{N}} fl,n?∈RT×NC? 代表第 n 條線索的特征矩陣, K k C N \mathcal{K}_{k}^{\frac{C}{N}} KkNC?? 是時序卷積的核,這里的 k 是時序核大小, C N \frac{C}{N} NC? 是輸出通道的數量,
Inter-Cue Path. ?The second path is to perform the temporal
transformation on the inter-cue feature from the previous block and fuse information from the intra-cue path as follows,
????????????????
o
l
=
ReLU
?
(
[
K
k
C
2
(
o
l
?
1
)
,
K
1
C
2
(
f
l
)
]
)
o_{l}=\operatorname{ReLU}\left(\left[\mathcal{K}_{k}^{\frac{C}{2}}\left(o_{l-1}\right), \mathcal{K}_{1}^{\frac{C}{2}}\left(f_{l}\right)\right]\right)
ol?=ReLU([Kk2C??(ol?1?),K12C??(fl?)]),$??????(7)
where
K
1
C
2
\mathcal{K}_{1}^{\frac{C}{2}}
K12C?? is a point-wise temporal convolution.It serves as a project matrix between the two paths. Note that
f
l
f_{l}
fl? is the output of intra-cue path in the present block.
線索間路徑.?第二種路徑是對上一個塊的線索間特征進行短暫的變換,并從線索內路徑融合資訊,
????????????????
o
l
=
ReLU
?
(
[
K
k
C
2
(
o
l
?
1
)
,
K
1
C
2
(
f
l
)
]
)
o_{l}=\operatorname{ReLU}\left(\left[\mathcal{K}_{k}^{\frac{C}{2}}\left(o_{l-1}\right), \mathcal{K}_{1}^{\frac{C}{2}}\left(f_{l}\right)\right]\right)
ol?=ReLU([Kk2C??(ol?1?),K12C??(fl?)]),??????(7)
這里的
K
1
C
2
\mathcal{K}_{1}^{\frac{C}{2}}
K12C?? 是一個 point-wise 時序卷積,它充當兩條路徑之間的過渡矩陣,
f
l
f_{l}
fl? 是當前塊的線索內路徑的輸出,
??After each block, a temporal max-pooling with stride 2 and kernel size 2 is performed. In this paper, we use two blocks in the TMC module. The kernel size k of all temporal convolutions is set to 5, except the point-wise one. The number of output channels C in each path is set to 1024.
??在每個塊之后,執行步長為2、卷積核大小為 2 的時序最大池化操作,在本文中,我們在 TMC 模塊中使用了兩個模塊,所有時序卷積的核大小 k 都設定為 5,除了 point-wise 的卷積,每條路徑的輸出通道量 C 設為1024,
3.4?Sequence Learning and Inference
With the proposed SMC and TMC module, the network can generate inter-cue feature sequence
o
=
{
o
t
}
t
=
1
T
′
\mathbf{o}=\left\{o_{t}\right\}_{t=1}^{T^{\prime}}
o={ot?}t=1T′? and N intra-cue feature sequences
f
n
=
{
f
t
,
n
}
t
=
1
T
′
\mathbf{f}_{n}=\left\{f_{t, n}\right\}_{t=1}^{T^{\prime}}
fn?={ft,n?}t=1T′?. Here,
T
′
T^{\prime}
T′ is the temporal length of the final output of the TMC module. The question then is how to utilize these two feature sequences to accomplish the sequence learning and inference.
利用所提出的 SMC 和 TMC 模塊,網路可以生成線索間特征序列
o
=
{
o
t
}
t
=
1
T
′
\mathbf{o}=\left\{o_{t}\right\}_{t=1}^{T^{\prime}}
o={ot?}t=1T′? 和 N 個線索內特征序列
f
n
=
{
f
t
,
n
}
t
=
1
T
′
\mathbf{f}_{n}=\left\{f_{t, n}\right\}_{t=1}^{T^{\prime}}
fn?={ft,n?}t=1T′?,其中
T
′
T^{\prime}
T′ 是 TMC 模塊最終輸出的時序長度,接下來的問題是如何利用這兩個特征序列來完成序列的學習和推理,
BLSTM Encoder. ?Recurrent neural networks (RNN) can use their internal state to model the state transitions in the sequence of inputs. Here, we use RNN to map the spatial-temporal feature sequence to its sign gloss sequence. RNN takes the feature sequence as input and generates
T
′
T^{\prime}
T′ hidden states as follows,
????????????????
h
t
=
RNN
?
(
h
t
?
1
,
o
t
)
h_{t}=\operatorname{RNN}\left(h_{t-1}, o_{t}\right)
ht?=RNN(ht?1?,ot?),??????(8)
in which
h
t
h_{t}
ht? is the hidden state at time step t and the initial state
h
0
h_{0}
h0? is a fixed all-zero vector. In our approach, we choose the bidirectional Long Short-Term Memory (BLSTM) (Sutskever, Vinyals, and Le 2014) unit as the recurrent unit for its ability in processing long-term dependencies. BLSTM concatenates forward and backward hidden states from bidirectional inputs. Afterward, the hidden state of each time step is passed through a fully-connected layer and a softmax layer,
????????????????
a
t
=
W
?
h
t
+
b
,
y
t
,
j
=
e
a
t
,
j
∑
k
e
a
t
,
k
a_{t}=W \cdot h_{t}+b, \quad y_{t, j}=\frac{e^{a_{t, j}}}{\sum_{k} e^{a_{t, k}}}
at?=W?ht?+b,yt,j?=∑k?eat,k?eat,j??,??????(9)
where
y
t
,
j
y_{t, j}
yt,j? is the probability of label j at time step t. In CSLR task, label j comes from a given vocabulary.
雙向長短時記憶編碼?回圈神經網路(RNN)可以利用其內部狀態對輸入序列中的狀態轉換進行建模,在這里,我們使用 RNN 將時空特征序列映射到其對應的手語注釋序列,RNN以特征序列為輸入,生成
T
′
T^{\prime}
T′ 個隱藏狀態,如下所示:
????????????????
h
t
=
RNN
?
(
h
t
?
1
,
o
t
)
h_{t}=\operatorname{RNN}\left(h_{t-1}, o_{t}\right)
ht?=RNN(ht?1?,ot?),??????(8)
其中,
h
t
h_{t}
ht? 是時間步長為 t 時的隱藏狀態,初始狀態
h
0
h_{0}
h0? 默認為零向量,在我們的方法中,我們選擇雙向長短期記憶(BLSTM) (Sutskever, Vinyals,和Le 2014)單元作為其處理長期依賴的回圈單元,BLSTM連接雙向輸入的前向和后向隱藏狀態,然后,每個時序步長的隱藏狀態經過一個全連接層和一個 softmax 層,
????????????????
a
t
=
W
?
h
t
+
b
,
y
t
,
j
=
e
a
t
,
j
∑
k
e
a
t
,
k
a_{t}=W \cdot h_{t}+b, \quad y_{t, j}=\frac{e^{a_{t, j}}}{\sum_{k} e^{a_{t, k}}}
at?=W?ht?+b,yt,j?=∑k?eat,k?eat,j??,??????(9)
這里的
y
t
,
j
y_{t, j}
yt,j? 是標簽 j 在時間步長設為 t 時出現的概率,在 CSLR 任務中,標簽 j 來自給定的詞匯表,
BLSTM:Bi-directional Long Short-Term Memory的縮寫,是由前向LSTM與后向LSTM組合而成,LSTM和BLSTM在自然語言處理任務中都常被用來建模背景關系資訊, 參考鏈接
Connectionist Temporal Classification.?Our model employs connectionist temporal classification (CTC) (Graves et al. 2006) to tackle the problem of mapping video sequence
o
=
{
o
t
}
t
=
1
T
′
\mathbf{o}=\left\{o_{t}\right\}_{t=1}^{T^{\prime}}
o={ot?}t=1T′? to ordered sign gloss sequence
?
=
{
?
i
}
i
=
1
L
\ell=\left\{\ell_{i}\right\}_{i=1}^{L}
?={?i?}i=1L?
(
L
≤
T
)
(L \leq T)
(L≤T), where the explicit alignment between them is unknown.The objective of CTC is to maximize the sum of probabilities of all possible alignment paths between input and target sequence.
我們的模型使用了連接時序分類(CTC) (Graves等人2006)來解決將視頻序列
o
=
{
o
t
}
t
=
1
T
′
\mathbf{o}=\left\{o_{t}\right\}_{t=1}^{T^{\prime}}
o={ot?}t=1T′? 映射到手語注釋序列
?
=
{
?
i
}
i
=
1
L
\ell=\left\{\ell_{i}\right\}_{i=1}^{L}
?={?i?}i=1L?
(
L
≤
T
)
(L \leq T)
(L≤T) 的問題,其中它們之間的顯式對齊是未知的,CTC 的目標是使輸入序列和目標序列之間所有可能的 alignment paths 的概率之和最大,
??CTC creates an extended vocabulary
V
\mathcal{V}
V with a blank label “
?
?
?”, where
V
=
V
origin
∪
{
?
}
\mathcal{V}=\mathcal{V}_{\text {origin }} \cup\{-\}
V=Vorigin ?∪{?}. The blank label represents stillness and transitions which have no precise meaning. Denote the alignment path of the input sequence as
π
=
{
π
t
}
t
=
1
T
′
\pi=\left\{\pi_{t}\right\}_{t=1}^{T^{\prime}}
π={πt?}t=1T′?, where label
π
t
∈
V
\pi_{t} \in \mathcal{V}
πt?∈V . The probability of alignment path
π
\pi
π given the input sequence is defined as follows,
????????????????
p
(
π
∣
o
)
=
∏
t
=
1
T
′
p
(
π
t
∣
o
)
=
∏
t
=
1
T
′
y
t
,
π
t
p(\pi \mid \mathbf{o})=\prod_{t=1}^{T^{\prime}} p\left(\pi_{t} \mid \mathbf{o}\right)=\prod_{t=1}^{T^{\prime}} y_{t, \pi_{t}}
p(π∣o)=∏t=1T′?p(πt?∣o)=∏t=1T′?yt,πt??.??????(10)
??CTC 創建帶有空白標簽 “
?
?
?”的擴展詞匯表
V
\mathcal{V}
V,這里的
V
=
V
origin
∪
{
?
}
\mathcal{V}=\mathcal{V}_{\text {origin }} \cup\{-\}
V=Vorigin ?∪{?},空白的標簽代表 stillness and transitions,沒有確切的意義,將輸入序列的 alignment path 表示為
π
=
{
π
t
}
t
=
1
T
′
\pi=\left\{\pi_{t}\right\}_{t=1}^{T^{\prime}}
π={πt?}t=1T′?,其中標簽
π
t
∈
V
\pi_{t} \in \mathcal{V}
πt?∈V,給定輸入序列, alignment path
π
\pi
π 的概率定義為:
????????????????
p
(
π
∣
o
)
=
∏
t
=
1
T
′
p
(
π
t
∣
o
)
=
∏
t
=
1
T
′
y
t
,
π
t
p(\pi \mid \mathbf{o})=\prod_{t=1}^{T^{\prime}} p\left(\pi_{t} \mid \mathbf{o}\right)=\prod_{t=1}^{T^{\prime}} y_{t, \pi_{t}}
p(π∣o)=∏t=1T′?p(πt?∣o)=∏t=1T′?yt,πt??.??????(10)
??Define a many-to-one mapping operation
B
\mathcal{B}
B which removes all blanks and repeated words in the alignment path (e.g.,
B
(
I
I
?
m
i
s
s
?
?
y
o
u
)
=
I
,
\mathcal{B}(I I-m i s s--y o u)=I,
B(II?miss??you)=I, miss,
y
o
u
y o u
you). In this way, we calculate the conditional probability of sign gloss sequence
?
\ell
? as the sum of probabilities of all paths that can be mapped to
?
\ell
? via
B
\mathcal{B}
B :
????????????????
p
(
?
∣
o
)
=
∑
π
∈
B
?
1
(
?
)
p
(
π
∣
o
)
p(\ell \mid \mathbf{o})=\sum_{\pi \in \mathcal{B}^{-1}(\ell)} p(\pi \mid \mathbf{o})
p(?∣o)=∑π∈B?1(?)?p(π∣o).??????(11)
where
B
?
1
(
?
)
=
{
π
∣
B
(
π
)
=
?
}
\mathcal{B}^{-1}(\boldsymbol{\ell})=\{\pi \mid \mathcal{B}(\pi)=\boldsymbol{\ell}\}
B?1(?)={π∣B(π)=?} is the inverse operation of
B
\mathcal{B}
B. Finally, the CTC losses of inter-cue feature sequence
O
\mathbf{O}
O and intra-cue feature sequence
f
n
\mathbf{f}_{\mathbf{n}}
fn? are defined as follows,
????????????????
L
C
T
C
?
o
=
?
ln
?
p
(
?
∣
o
)
\mathcal{L}_{\mathrm{CTC}-\mathbf{o}}=-\ln p(\ell \mid \mathbf{o})
LCTC?o?=?lnp(?∣o).??????(12)
????????????????
L
C
T
C
?
f
n
=
?
ln
?
p
(
?
∣
f
n
)
\mathcal{L}_{\mathrm{CTC}-\mathbf{f}_{n}}=-\ln p\left(\ell \mid \mathbf{f}_{n}\right)
LCTC?fn??=?lnp(?∣fn?).??????(13)
定義一個多對一的映射操作
B
\mathcal{B}
B,用來洗掉 alignment path 中的所有空格和重復的單詞(比如,
B
(
I
I
?
m
i
s
s
?
?
y
o
u
)
=
I
,
\mathcal{B}(I I-m i s s--y o u)=I,
B(II?miss??you)=I, miss,
y
o
u
y o u
you),這樣,我們計算 sign gloss 序列
?
\ell
? 的條件概率為可以通過
B
\mathcal{B}
B 映射到
?
\ell
? 的所有路徑的概率之和:
????????????????
p
(
?
∣
o
)
=
∑
π
∈
B
?
1
(
?
)
p
(
π
∣
o
)
p(\ell \mid \mathbf{o})=\sum_{\pi \in \mathcal{B}^{-1}(\ell)} p(\pi \mid \mathbf{o})
p(?∣o)=∑π∈B?1(?)?p(π∣o).??????(11)
其中,
B
?
1
(
?
)
=
{
π
∣
B
(
π
)
=
?
}
\mathcal{B}^{-1}(\boldsymbol{\ell})=\{\pi \mid \mathcal{B}(\pi)=\boldsymbol{\ell}\}
B?1(?)={π∣B(π)=?} 是
B
\mathcal{B}
B 的逆運算,最后,連接時序分類模型CTC中 inter-cue feature sequence
O
\mathbf{O}
O 的損失函式和 intra-cue feature sequence
f
n
\mathbf{f}_{\mathbf{n}}
fn? 的損失函式定義如下:
????????????????
L
C
T
C
?
o
=
?
ln
?
p
(
?
∣
o
)
\mathcal{L}_{\mathrm{CTC}-\mathbf{o}}=-\ln p(\ell \mid \mathbf{o})
LCTC?o?=?lnp(?∣o).??????(12)
????????????????
L
C
T
C
?
f
n
=
?
ln
?
p
(
?
∣
f
n
)
\mathcal{L}_{\mathrm{CTC}-\mathbf{f}_{n}}=-\ln p\left(\ell \mid \mathbf{f}_{n}\right)
LCTC?fn??=?lnp(?∣fn?).??????(13)
CTC:connectionist temporal classification 連接主義時間分類 ,用來解決輸入序列和輸出序列難以一一對應的問題,參考前文
Joint Loss Optimization.?During the training process, we take the optimization of the inter-cue path as the primary objective. To provide the information of each individual cue for fusion, the intra-cue path plays an auxiliary role. Hence, the objective function of the entire STMC framework is given as follows,
????????????????
L
=
L
C
T
C
?
o
+
α
∑
n
L
C
T
C
?
f
n
+
L
R
β
\mathcal{L}=\mathcal{L}_{\mathrm{CTC}-\mathrm{o}}+\alpha \sum_{n} \mathcal{L}_{\mathrm{CTC}-\mathbf{f}_{n}}+\mathcal{L}_{\mathrm{R}}^{\beta}
L=LCTC?o?+α∑n?LCTC?fn??+LRβ?.??????(14)
Here,
α
\alpha
α and
β
\beta
β are hyper-parameters, where
α
\alpha
α is to balance the ratio of auxiliary loss for the intra-cue path, and
β
\beta
β is to make the regression loss
L
R
\mathcal{L}_{\mathrm{R}}
LR? of pose estimation have the same order of magnitudes with others. Given the estimated keypoints
J
t
,
k
∈
R
2
J_{t, k} \in \mathbb{R}^{2}
Jt,k?∈R2 which is calculated in Eq. 3, its corresponding ground-truth is
J
^
\hat{J}
J^, and the smooth-L1 (Girshick 2015) loss function of pose estimation branch is calculated as follows,
????????????????
L
R
β
=
1
2
T
K
∑
t
∑
k
∑
i
∈
(
x
,
y
)
smooth
?
L
1
β
(
J
t
,
k
,
i
?
J
^
t
,
k
,
i
)
\mathcal{L}_{\mathrm{R}}^{\beta}=\frac{1}{2 T K} \sum_{t} \sum_{k} \sum_{i \in(x, y)} \operatorname{smooth}_{L_{1}} \beta\left(J_{t, k, i}-\hat{J}_{t, k, i}\right)
LRβ?=2TK1?t∑?k∑?i∈(x,y)∑?smoothL1??β(Jt,k,i??J^t,k,i?),??????(15)
in which,
????????????????
smooth
?
L
1
(
x
)
=
{
0.5
x
2
if
∣
x
∣
<
1
∣
x
∣
?
0.5
otherwise
\operatorname{smooth}_{L_{1}}(x)=\left\{\begin{array}{ll} 0.5 x^{2} & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise } \end{array}\right.
smoothL1??(x)={0.5x2∣x∣?0.5? if ∣x∣<1 otherwise ?.??????(16)
聯合優化損失.?在訓練程序中,我們以優化 inter-cue path 為主要目標,在融合程序中,inter-cue path 起著輔助作用,為融合提供各個線索的資訊,因此,整個 STMC 框架的目標函式如下:
????????????????
L
=
L
C
T
C
?
o
+
α
∑
n
L
C
T
C
?
f
n
+
L
R
β
\mathcal{L}=\mathcal{L}_{\mathrm{CTC}-\mathrm{o}}+\alpha \sum_{n} \mathcal{L}_{\mathrm{CTC}-\mathbf{f}_{n}}+\mathcal{L}_{\mathrm{R}}^{\beta}
L=LCTC?o?+α∑n?LCTC?fn??+LRβ?.??????(14)
這里的
α
\alpha
α 和
β
\beta
β 是超引數,其中
α
\alpha
α 是為平衡 intra-cue path 的輔助損耗比,
β
\beta
β 是使姿態估計的回歸損失
L
R
\mathcal{L}_{\mathrm{R}}
LR? 與其他的具有相同的數量級,根據估計關鍵點
J
t
,
k
∈
R
2
J_{t, k} \in \mathbb{R}^{2}
Jt,k?∈R2 (
J
t
,
k
∈
R
2
J_{t, k} \in \mathbb{R}^{2}
Jt,k?∈R2 是關鍵點k在第t個坐標系的位置),其對應的ground-truth為
J
^
\hat{J}
J^,pose 估計分支的損失函式smooth-L1 (Girshick 2015)計算如下:
????????????????
L
R
β
=
1
2
T
K
∑
t
∑
k
∑
i
∈
(
x
,
y
)
smooth
?
L
1
β
(
J
t
,
k
,
i
?
J
^
t
,
k
,
i
)
\mathcal{L}_{\mathrm{R}}^{\beta}=\frac{1}{2 T K} \sum_{t} \sum_{k} \sum_{i \in(x, y)} \operatorname{smooth}_{L_{1}} \beta\left(J_{t, k, i}-\hat{J}_{t, k, i}\right)
LRβ?=2TK1?t∑?k∑?i∈(x,y)∑?smoothL1??β(Jt,k,i??J^t,k,i?),??????(15)
in which,
????????????????
smooth
?
L
1
(
x
)
=
{
0.5
x
2
if
∣
x
∣
<
1
∣
x
∣
?
0.5
otherwise
\operatorname{smooth}_{L_{1}}(x)=\left\{\begin{array}{ll} 0.5 x^{2} & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise } \end{array}\right.
smoothL1??(x)={0.5x2∣x∣?0.5? if ∣x∣<1 otherwise ?.??????(16)
Inference.?For inference, we pass video frames through
the SMC and TMC modules. Only the inter-cue feature sequence and its BLSTM encoder are used to generate the posterior probability distribution of glosses at all time steps.We use the beam search decoder (Hannun et al. 2014) to search the most probable sequence within an acceptable range.
推理?為了進行推理,我們將視頻幀傳入 SMC 和 TMC 模塊,只使用inter-cue feature sequence 及其 BLSTM 編碼器來生成所有時間步長的gloss后驗概率分布,我們使用集束搜索解碼器(Hannun等人,2014)在可接受的范圍內搜索最可能的序列,
4?Experiments
4.1?Dataset and Evaluation
Dataset.?We evaluate our method on three datasets, including PHOENIX-2014 (Koller, Forster, and Ney 2015), CSL (Huang et al. 2018; Guo et al. 2018) and PHOENIX- 2014-T (Cihan Camgoz et al. 2018).
資料集.?我們在三個資料集上評估我們的方法,包括PHOENIX-2014 (Koller, Forster, and Ney 2015), CSL (Huang et al. 2018; Guo et al. 2018) and PHOENIX- 2014-T (Cihan Camgoz et al. 2018),
??PHOENIX-2014?is a publicly available German Sign Language dataset, which is the most popular benchmark for CSLR. The corpus was recorded from broadcast news about the weather. It contains videos of 9 different signers with a vocabulary size of 1295. The split of videos for Train, Dev and Test is 5672, 540 and 629, respectively. Our method is evaluated on the multi-signer database.
??PHOENIX-2014?是一個公開可用的德語手語資料集,它是CSLR最廣泛的測驗基準,這些語料庫是從廣播的天氣新聞中記錄下來的,它包含9個不同的 signers 視頻,詞匯量大小為1295,Train、Dev和Test的視頻分割分別為5672、540和629,我們的方法在 multi-signer 資料庫上進行了評估,
??CSL?is a Chinese Sign Language dataset, which has 100 sign language sentences about daily life with 178 words. Each sentence is performed by 50 signers and there are 5000 videos in total. For pre-training, it also provides a matched isolated Chinese Sign Language database, which contains 500 words. Each word is performed 10 times by 50 signers.
??CSL?是一個中文手語資料庫,包含100個關于日常生活的手陳述句子,包含178個單詞,每句話都由50名 signers,總共有5000個視頻,在訓練前,它還提供了一個匹配的孤立的中文手語資料庫,包含500個單詞,每個單詞由50個 signers 執行10次,
??PHOENIX-2014-T?is an extended version of PHOENIX-2014 and has two-stage annotations for new videos. One is sign gloss annotations for CSLR task. Another is German translation annotations for sign language translation (SLT) task. The split of videos for Train, Dev and Test is 7096, 519 and 642, respectively. It has no overlap with the previous version between Train, Dev and Test set. The vocabulary size is 1115 for sign gloss and 3000 for German.
??PHOENIX-2014-T?是PHOENIX- 2014的擴展版,在擴充的視頻中有兩種的注釋,一個是CSLR任務的 sign gloss 注釋,另一種是用于手語翻譯(SLT)任務的德語翻譯注釋,Train、Dev和Test的視頻分割分別為7096、519和642,它與之前的版本(Train, Dev和Test set)沒有重疊,sign gloss 的詞匯量是1115,德語是3000,
Pose Annotation.?To obtain the keypoint positions for training, we use the publicly available HRNet (Sun et al. 2019) toolbox to estimate the positions of 7 keypoints in upper-body for all frames on three databases. The toolbox gives 2D coordinates (x, y) in the pixel coordinate system. We thus represent each normalized keypoint with a tuple of (x, y) and record it as an array of 7 tuples.
姿勢注釋.?為了獲得用于訓練的關鍵點位置,我們使用開源的HRNet(Sun等人,2019年)工具箱來估計三個資料庫上所有幀中上半身的7個關鍵點的位置,工具箱給出了像素坐標系中的2維坐標 (x,y),因此我們用 (x,y) 陣列來表示每個歸一化后的關鍵點,并將其記錄為一個由7個元組組成的陣列,
Evaluation.?In CSLR, Word Error Rate (WER) is used as the metric of measuring the similarity between two sentences (Koller, Forster, and Ney 2015). It measures the least operations of substitution (sub), deletion (del) and insertion (ins) to transform the hypothesis to the reference:

評估.?在CSLR中,單詞錯誤率(Word Error Rate, WER)作為衡量兩個句子之間相似性的度量標準(Koller, Forster, and Ney 2015),它度量的是替換(sub)、洗掉(del)和插入(ins)的最小運算操作:
評價標準:WER(越低越好)
4.2?Implementation Details
In our experiments, the input frames are resized to 224×224. For data augmentation in one video, we add random crop at the same location of all frames, random discard of 20% frames and random flip of all frames. For inter-cue features, the number of output channels after TCOVs and BLSTM are all set to 1024. There are 4 visual cues. For each intra-cue feature, the number of output channels after TCOVs and BLSTM are all set to 256.
在我們的實驗中,輸入幀被調整為224×224,為了在視頻中增強資料,我們在所有幀的同一位置進行隨機裁剪,隨機丟棄20%的幀,并隨機翻轉所有幀,對于 inter-cue 特征,在TCOVs和BLSTM之后的輸出通道數都設定為 1024,有 4 種視覺線索,對于每個 intra-cue 特征, 在TCOVs和BLSTM之后的輸出通道數都設定為256,
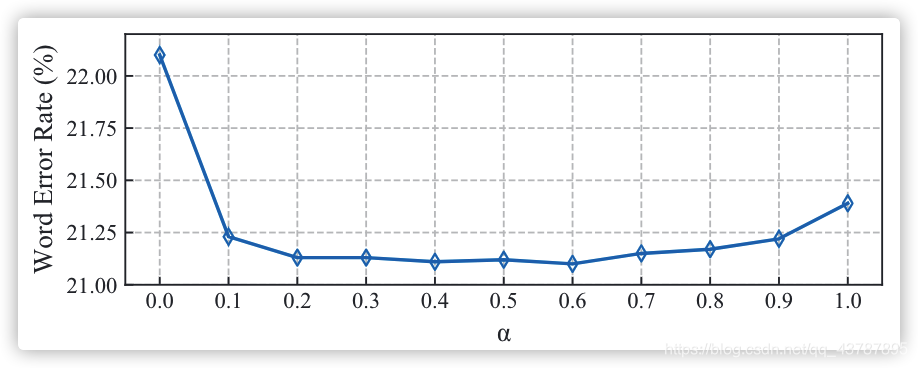
Following the previous methods (Koller, Zargaran, and Ney 2017; Pu, Zhou, and Li 2019; Cui, Liu, and Zhang 2019), we utilize a staged optimization strategy. First, we train a VGG11-based network as DNF (Cui, Liu, and Zhang 2019) and use it to decode pseudo labels for each clip. Then,we add a fully-connected layer after each output of the TMC module. The STMC network without BLSTM is trained with cross-entropy and smooth-L1 loss by SGD optimizer. The batch size is 24 and the clip size is 16. Finally, with fine-tuned parameters from the previous stage, our full STMC network is trained end-to-end under joint loss optimization. We use Adam optimizer with learning rate
5
×
1
0
?
5
5 \times 10^{-5}
5×10?5 and set the batch size to 2. In all experiments, we set
α
\alpha
α to 0.6 and
β
\beta
β to 30. In fact, the experiment results are insensitive to the slight change of
α
\alpha
α (see Fig. 4), except
α
\alpha
α = 0.
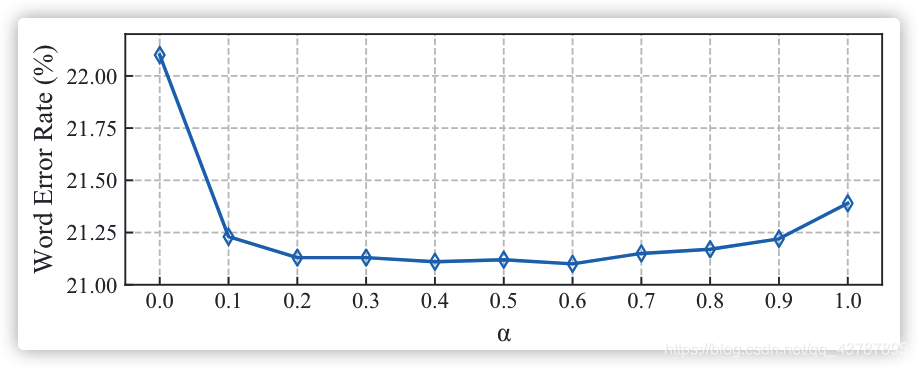
??????Figure 4: The effect of weight parameter
α
\alpha
α in Eq. 14.
參考已有的方法 (Koller, Zargaran, and Ney 2017; Pu, Zhou, and Li 2019; Cui, Liu, and Zhang 2019),我們采用了分階段的優化策略,首先,將基于VGG11的網路訓練為DNF(Cui,Liu和Zhang2019),并使用它來解碼每個剪輯的偽標簽,然后,我們在 TMC 模塊的每個輸出之后添加一個全連接層,利用 SGD 優化器對不含 BLSTM 的 STMC 網路進行交叉熵和平滑L1損失訓練,最后,通過對前一層引數的微調,我們對整個 STMC 網路進行了端到端的聯合損失優化訓練,使用學習速率為
5
×
1
0
?
5
5 \times 10^{-5}
5×10?5 的 ADAM 優化器,將 batch size 設定為2,在所有的實驗中,我們將
α
\alpha
α 設定為0.6,
β
\beta
β 設定為30,事實上,實驗結果表示
α
\alpha
α 的大小對實驗的結果影響不大(見圖4),除了
α
\alpha
α = 0時,
??????圖 4:
α
\alpha
α 引數權重在Eq. 14.中的影響
??Our network architecture is implemented in PyTorch. For finetuning, we train the STMC network without BLSTM for 25 epochs. Afterward, the whole STMC network is trained end-to-end for 30 epochs. For inference, the beam width is set to 20. Experiments are run on 4 GTX 1080Ti GPUs.
??我們的網路架構是在PyTorch中實作的,為了進行微調,我們對沒有 BLSTM 的 STMC 網路進行了25次迭代訓練,之后,對整個 STMC 網路進行30次端到端的訓練,關于實驗,beam width 設定為20,實驗在 4 個 GTX 1080Ti GPU上運行,
優化策略的評價指標:WER(Word Error Rate)
4.3?Framework Effectiveness Study
For a fair comparison, experiments in this subsection are conducted on PHOENIX-2014, which is the most popular dataset in CSLR.
為了實驗結果便于比較,本小節的實驗是在CSLR中最流行的資料集PHOENIX-2014上進行的,
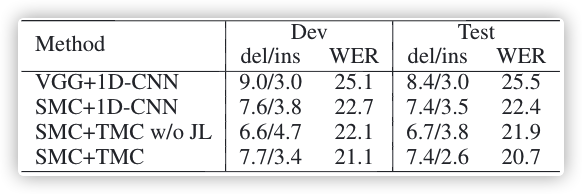
Module Analysis?We analyze the effectiveness of each module in our proposed approach. In Table 1, different combinations of spatial and temporal modules are evaluated. The baseline model is composed of VGG11 and 1D-CNN with a BLSTM encoder. With the aid of multi-cue features, the SMC module provides about 3% improvement compared with baseline on the test set. However, with no extra guidance, the TMC module doesn’t show expected gain by replacing the 1D-CNN. With joint loss optimization, the intra-cue path is guided by CTC loss to learn temporal dependency of each cue and provides 1.6% and 1.7% extra gain on the dev set and test set, compared with 1D-CNN. Compared with the baseline model, our STMC network reduces the WER on the test set by 4.8%.
??????Table 1: Evaluation of different module combinations (thelower the better).
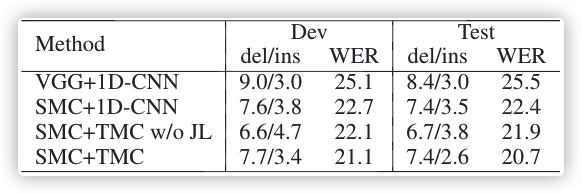
模塊分析?我們分析了我們所提出的方法中每個模塊的有效性,表 1 評估了空間和時間模塊的不同組合,baseline model 模型由VGG11和帶有BLSTM編碼器的1D-CNN組成,在 multi-cue 特征的幫助下,SMC 模塊在測驗集上比 baseline 提高了約3%,但是,在沒有額外引導的情況下,TMC 模塊在替換 1D-CNN 時并沒有表現出預期的效果,通過聯合損耗優化,由 CTC 損失引導的 intra-cue path 學習每個線索的時間依賴性,與1D-CNN 相比,在 dev 集和 test 集上提高了 1.6% 和 1.7% ,與 baseline 模型相比,我們的 STMC 網路在測驗集上 WER 降低了的 4.8%,
??????表 1:評估不同的模塊組合(越低越好)
Intra-Cue and Inter-Cue Paths?With further optimization, the BLSTM encoder of each cue in the intra-cue path can also serve as an individual sequence predictor. In Table 2, WERs of different encoders in both paths are evaluated on the dev set. Among the four cues, the performance of pose is worst. With only the position and orientation of joints in upper-body, it’s difficult to distinguish the subtle variations in the appearance of sign gestures. The performance of hand is superior to that of face, while full-frame achieves relatively better performance. By leveraging the synergy of different cues, the inter-cue path shows the lowest WER.
??????Table 2: Evaluation of different paths in TMC on Dev set.

Intra-Cue and Inter-Cue Paths?通過進一步的優化,intra-cue path 中每個線索的 BLSTM 編碼器也可以作為一個單獨的序列預測器,在表 2 中,我們在 dev 集上評估了兩種路徑下不同編碼器的方案,在四種線索中,姿勢的表現是最差的,由于只有上半身關節的位置和方向,很難區分手勢外觀的細微變化,手的性能優于臉,而全幀的性能相對較好,通過利用不同線索的協同作用,inter-cue path 的 WER 最低,
??????表2:在 Dev 集上評估 TMC 中的不同 paths Inference Time?To clarify the effectiveness of the self-contained pose estimation branch, we evaluate the inference time in Table 3. The inference time depends on the video length. In average, it takes around 8 seconds (25FPS) for a sign sentence. For a fair comparison, we evaluate the inference time of 200 frames on a single GPU. Compared with introducing an external VGG-11 based model for pose estimation, our self-contained branch saves around 44% inference time. It’s notable that our framework with the self-contained branch still shows slightly better performance than an off-the-shelf model. We argue that the differentiable pose estimation branch plays the role of regularization and then alleviate the overfitting of neural networks.
Inference Time?To clarify the effectiveness of the self-contained pose estimation branch, we evaluate the inference time in Table 3. The inference time depends on the video length. In average, it takes around 8 seconds (25FPS) for a sign sentence. For a fair comparison, we evaluate the inference time of 200 frames on a single GPU. Compared with introducing an external VGG-11 based model for pose estimation, our self-contained branch saves around 44% inference time. It’s notable that our framework with the self-contained branch still shows slightly better performance than an off-the-shelf model. We argue that the differentiable pose estimation branch plays the role of regularization and then alleviate the overfitting of neural networks.
??????Table 3: Comparison of inference time. (PE: an external VGG11-based model for pose estimation)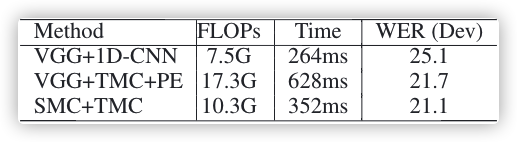
實驗時間?為了闡明 self-contained 姿態估計 branch 的有效性,我們在表 3 中測驗了實驗時間,實驗時間取決于視頻的長度,平均一個 sign sentence 大約需要8秒(25幀/秒),為了進行公平的比較,我們在單個 GPU 上測驗了 200 幀的實驗時間,與引入了基于VGG-11的姿態估計模型相比,我們的 self-contained branch 省了約44%的實驗時間,值得注意的是,帶有 self-contained branch 的框架也比現成的模型擁有更好的性能,我們認為 differentiable pose estimation branch 起到了調整的作用,從而防止了神經網路的過擬合,
??????Table 3:實驗時間比較,(PE:基于 VGG11 的外部姿態估計模型)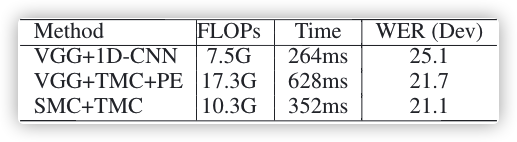
這里的評估標準要找有利于自己的指標,并且要看和誰比,在什么基礎上有了多少提升,
- del/ins:
- WER:通用硬指標
- Time:
- FLOPs:
- Cue:full、hand、face、pose
Qualitative Analysis?Figure 5 shows an example generated by different cues. It’s clear to see that the result of the inter-cue path can effectively learn correlations of multiple cues and make a better prediction.
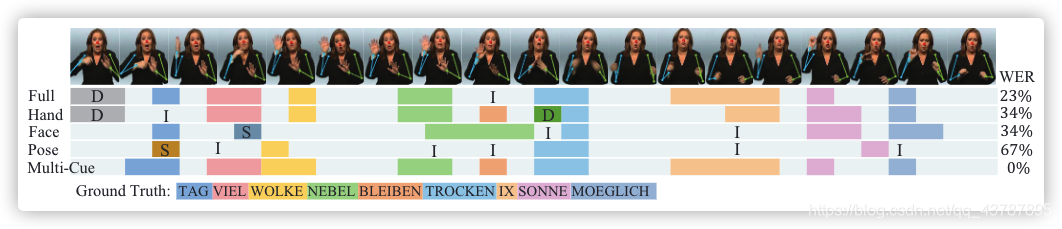
??????Figure 5: A qualitative result of different cues with estimated poses (zoom in) from Dev set (D: delete, I: insert, S: substitute).
定量分析?圖5顯示了由不同 cues 生成的示例,可見,inter-cue path 的結果可以有效地學習多個線索的相關性,并做出更好的預測,
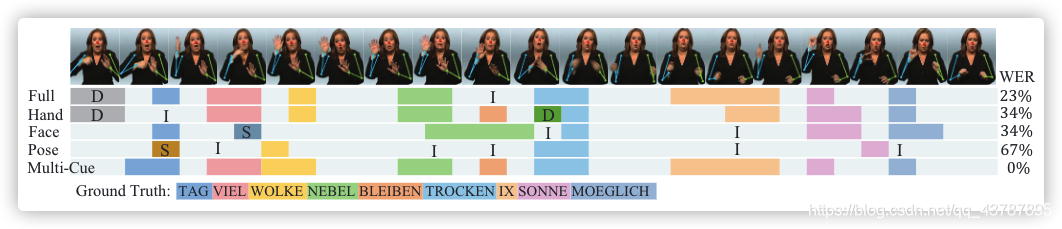
??????圖5:Dev集合(D:洗掉,I:插入,S:替換)中不同線索與估計姿勢(放大)的定性結果
4.4?State-of-the-art Comparison
Evaluation on PHOENIX-2014.?In Table 4, we compare our approach with methods on PHOENIX-2014. CMLLR and 1-Mio-Hands belong to traditional HMM-based model with hand-crafted features. In SubUNets and LS-HAN, full-frame features are fused with features of hand patches, which are captured by an external tracker. In CNN-LSTM-HMM, two-stream networks are trained with weak hand labels and sign gloss labels, respectively. Our STMC out-performs two recent multi-cue methods, i.e., LS-HAN and CNN-LSTM-HMM by 17.6% and 5.3%. Moreover, compared with DNF which explores the fusion of RGB and optical flow modality, STMC still surpasses this best competitor by 2.2%. Based on the RGB modality, we propose a novel STMC framework and achieves 20.7% WER on the test set, a new state-of-the-art result on PHOENIX-2014.
??????Table 4: Comparison with methods on PHOENIX-2014 (the lower the better).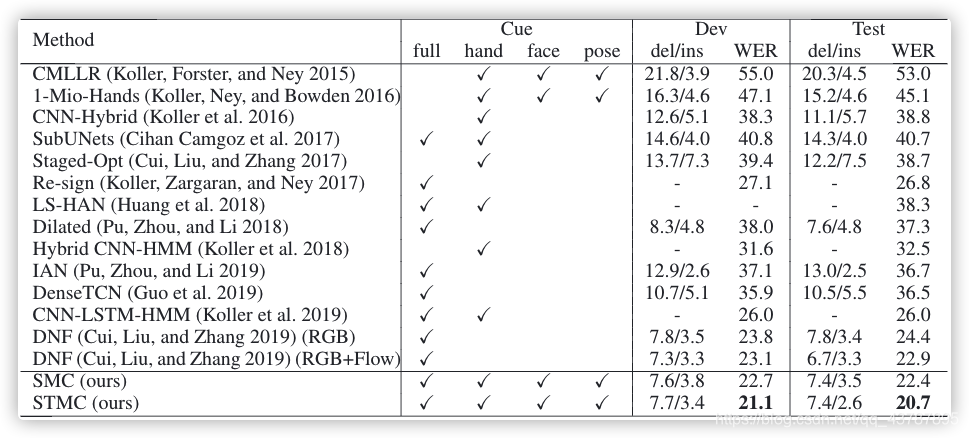
在 PHOENIX-2014 上的評估?在表4中,將我們的方法與在 PHOENIX-2014 上做過的方法進行了比較,CMLLR 和 1-Mio-Hands 是基于 HMM 的傳統模型,具有hand-crafted 的特點,在 SubUNets 和 LS-HAN 中,將 full-frame 特征與外部跟蹤器捕獲的 hand patches 特征融合在一起,在 CNN-LSTM-HMM 中,分別用 weak hand labels 和 sign gloss labels 訓練雙流網路,我們的 STMC 比兩種最新的 multi-cue 方法 LS-HAN 和 CNN-LSTM-HMM 分別高出 17.6% 和 5.3%,此外,與探索 RGB 與 optical flow modality 融合的DNF相比,STMC 也比 DNF 最佳結果高出 2.2%,基于 RGB modality,我們提出了一個新的 STMC 框架,并在測驗集上獲得了 20.7% 的WER,這是 PHOENIX-2014 上的最新成果,
??????表 4:在 PHOENIX-2014 上的方法比較(越低越好)
Evaluation on CSL.?In Table 5, we evaluate our approach on CSL under two settings. CSL dataset contains a smaller vocabulary compared with PHOENIX-2014. Following the works of (Huang et al. 2018; Guo et al. 2018), the dataset is split by two strategies in Table 5. Split I is a signer independent test: the train and test sets share the same sentences with no overlap of signers. Split II is an unseen sentence test: the train and test sets share the same signers and vocabulary with no overlap of same sentences. Between two settings, Split II is more challenging for that recognizing unseen combinations of words is difficult in CSLR. In IAN, their alignment algorithm of CTC decoder and LSTM decoder shows notable improvement, compared with previous methods. Benefiting from multi-cue learning, our STMC framework outperforms the best competitor on CSL by 4.1% on WER.
??????Table 5: Comparison with methods on CSL.
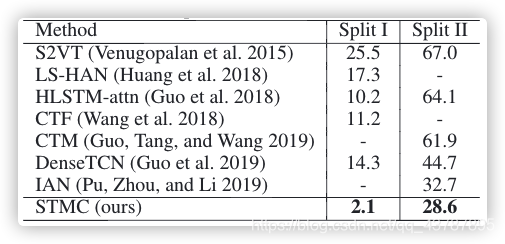
在 CSL 上的評估?在表5中,我們在兩種設定下評估 CSL 上的方法,與 PHOENIX-2014 相比,CSL 資料集包含的詞匯量更小,(Huang et al. 2018;Guo et al. 2018),表5將資料集分為兩種策略,Split I 是一個 signer 獨立的測驗:訓練集和測驗集共享相同的句子,沒有 signers 重疊,Split II 是一個 unseen sentence 測驗:訓練集和測驗集共享相同的 signers 和詞匯,沒有重復的句子,在兩種設定中,Split II 更具有挑戰性,因為在 CSLR 中很難識別 unseen sentence,在 IAN 中,CTC 解碼器和 LSTM 解碼器的 alignment 演算法與之前的方法相比有了顯著的改進,利用多線索學習的優勢,我們的 STMC 框架在 CSL 上的表現優于最佳競爭對手的4.1%,
??????表5:與在 CSL 上的方法比較
Evaluation on PHOENIX-2014-T.?In Table 6, we provide a result of our method on PHOENIX-2014-T. As a newly proposed dataset (Cihan Camgoz et al. 2018) for sign language translation, PHOENIX-2014-T provides an extended database with sign gloss annotation and spoken German annotation. CNN-LSTM-HMM utilizes spoken German annotation to infer the weak mouth shape labels for each video. It provides results of multi-cue sequential parallelism, including full-frame, hand and mouth. Our method surpasses all three combinations of CNN-LSTM-HMM.
??????Table 6: Comparison with methods on PHOENIX-2014-T.(f: full-frame, m: mouth, h: hand)

在 PHOENIX-2014-T 上的評估?表6給出了我們的方法在 PHOENIX-2014-T 的結果,PHOENIX-2014-T 作為一個新提出的手語翻譯資料集(Cihan Camgoz et al. 2018),提供了一個擴展的資料庫,包括手語注釋和德語口語注釋,CNN-LSTM-HMM利用德語口語注釋來推斷每個視頻的弱嘴型標簽,它提供了多線索順序并行的結果,包括全幀,手和嘴,我們的方法超過了 CNN-LSTM-HMM 的所有三種組合,
??????表 6:與在 PHOENIX-2014-T 上方法的比較,(f: full-frame, m: mouth, h: hand)
5?Conclusion
In this paper, we present a novel multi-cue framework for CSLR, which aims to learn spatial-temporal correlations of visual cues in an end-to-end fashion. In our framework, a spatial multi-cue module is designed with a self-contained pose estimation branch to decompose spatial multi-cue features. Moreover, we propose a temporal multi-cue module composed of the intra-cue and inter-cue paths, which aims to preserve the uniqueness of each cue and explore the synergy of different cues at the same time. A joint optimization strategy is proposed to accomplish multi-cue sequence learning. Extensive experiments on three large-scale CSLR datasets demonstrate the superiority of our STMC framework.
在本文中,我們提出了一個新的基于多線索的 CSLR 框架,該框架旨在以端到端的方式學習視覺線索的時空相關性,在我們的框架中,設計了一個空間多線索模塊,包含一個獨立的姿態估計分支來分解空間多線索特征,此外,我們提出了一個由intra-cue paths 和 inter-cue paths 組成的時序多線索模塊,旨在保持每條線索的唯一性,同時探索不同線索在同一時間內的協同作用,提出了一種聯合優化策略來完成多線索序列學習,在三個大規模 CSLR 資料集上的大量實驗證明了我們的 STMC 框架的優越性,
??Acknowledgments.?This work was supported in part to Dr. Wengang Zhou by NSFC under contract No. 61632019 & No. 61822208 and Youth Innovation Promotion Association CAS (No. 2018497), and in part to Dr. Houqiang Li by NSFC under contract No. 61836011.
??致謝?國家自然科學基金面上專案(No. 61632019 & No. 61822208);中國科學院青年創新促進會面上專案(No. 2018497);國家自然科學基金面上專案(No. 61836011)李后強博士資助,
Paper原文鏈接點擊下載
Paper原始碼(暫無)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/273720.html
標籤:其他
上一篇:Java基礎學習總結筆記<5>進制(原碼,反碼,補碼)
下一篇:了解時間復雜度