文章目錄
- 1. 載入各種資料科學以及可視化庫
- 2. 載入資料
- 2.1. 特征集
- 2.2. 簡略觀察資料
- 3.資料總覽
- 3.1. 通過describe()對于特征進行一些統計描述
- 3.2. 通過info()來熟悉資料型別
- 4. 判斷資料缺失和例外
- 4.1. 查看每列的存在nan情況
- 4.2. 查看缺失值的分布情況
- 4.3. 查看有效值的占比情況
- 4.4. 例外值處理
- 4.5. 無效資料處理
- 5. 了解預測值的分布
- 5.1. 總體分布概況
- 5.2. 查看skewness and kurtosis
- 偏度(Skewness)
- 峰度(Kurtosis)
- 5.3. 查看預測值的具體頻數
- 5.4. log變換
想要看更加舒服的排版、更加準時的推送
關注公眾號“不太靈光的程式員”
干貨推送,微信隨時解答你的疑問 😃😃😃
資料挖掘前我們要去熟悉資料,了解變數間的相互關系以及變數與預測值之間的存在關系,借助可視化工具幫助我們更好的進行分析,
根據賽題代碼要求創建了目錄,下載資料我們可以發現,已經區分了訓練集和測驗集,
下面我們一起來分析二手車交易資料,
1. 載入各種資料科學以及可視化庫
- 資料科學庫 pandas、numpy、scipy;
- 可視化庫 matplotlib、seabon;
沒有安裝的 使用 pip install 安裝
# coding=gbk
import numpy as np
import pandas as pd
# 繪圖函式庫
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
# 展示完整資料集
pd.set_option('display.expand_frame_repr', False)
2. 載入資料
二手車的訓練資料集資料有15W個樣本,該資料集一共包含31個變數,其中15個匿名特征變數,
price 二手車交易價格(預測目標)
CSV_FILE_PATH = '../data/used_car_train_20200313.csv'
# 讀取csv, 檔案分隔符是空格
df = pd.read_csv(CSV_FILE_PATH, sep=' ')
2.1. 特征集
| Field | Description |
|---|---|
| SaleID | 交易ID,唯一編碼 |
| name | 汽車交易名稱,已脫敏 |
| regDate | 汽車注冊日期,例如20160101,2016年01月01日 |
| model | 車型編碼,已脫敏 |
| brand | 汽車品牌,已脫敏 |
| bodyType | 車身型別:豪華轎車:0,微型車:1,廂型車:2,大巴車:3,敞篷車:4,雙門汽車:5,商務車:6,攪拌車:7 |
| fuelType | 燃油型別:汽油:0,柴油:1,液化石油氣:2,天然氣:3,混合動力:4,其他:5,電動:6 |
| gearbox | 變速箱:手動:0,自動:1 |
| power | 發動機功率:范圍 [ 0, 600 ] |
| kilometer | 汽車已行駛公里,單位萬km |
| notRepairedDamage | 汽車有尚未修復的損壞:是:0,否:1 |
| regionCode | 地區編碼,已脫敏 |
| seller | 銷售方:個體:0,非個體:1 |
| offerType | 報價型別:提供:0,請求:1 |
| creatDate | 汽車上線時間,即開始售賣時間 |
| price | 二手車交易價格(預測目標) |
| v系列特征 | 匿名特征,包含v0-14在內15個匿名特征 |
2.2. 簡略觀察資料
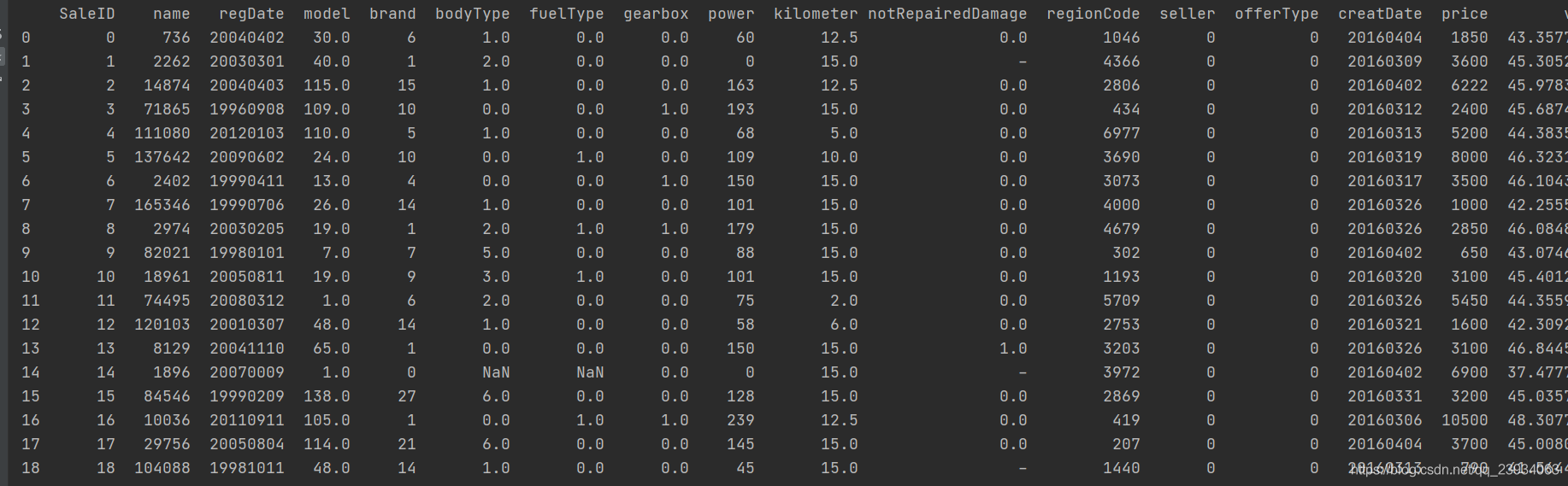
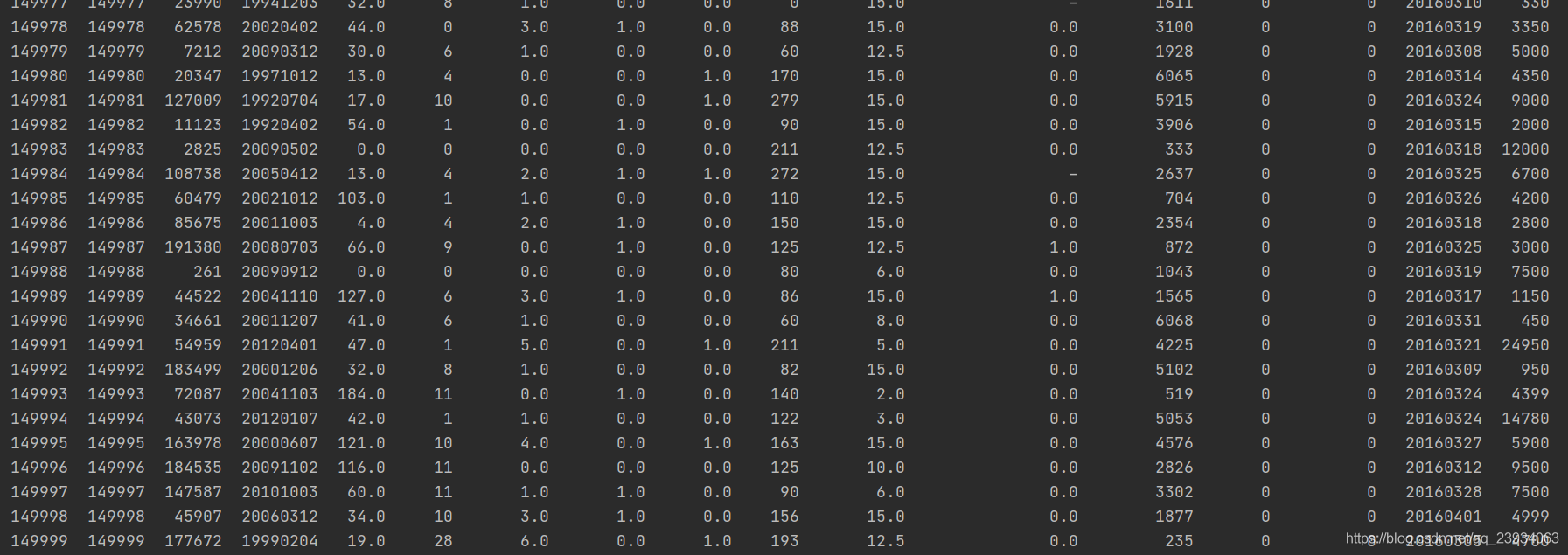
要養成看資料集的head()以及shape的習慣,這會讓你每一步更放心,導致接下里的連串的錯誤, 如果對自己的pandas等操作不放心,建議執行一步看一下,這樣會有效的方便你進行理解函式并進行操作,
# 資料集前后50條資料
print(df.head(50))
print(df.tail(50))
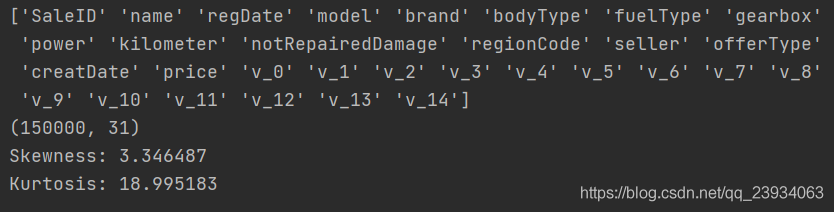
# 資料列名
print(df.columns.values)
# 獲取資料的 總行數 和 列數
print(df.shape)
3.資料總覽
3.1. 通過describe()對于特征進行一些統計描述
describe種有每列的統計量,個數count、平均值mean、方差std、最小值min、中位數25% 50% 75% 、以及最大值,
看這個資訊主要是瞬間掌握資料的大概的范圍以及每個值的例外值的判斷, 比如有的時候會發現999 9999 -1 等值這些其實都是nan的另外一種表達方式,有的時候需要注意下,
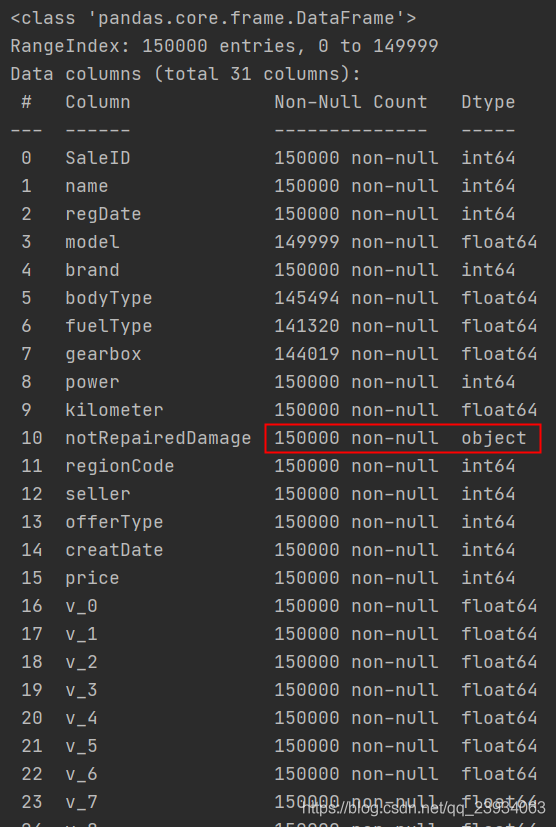
3.2. 通過info()來熟悉資料型別
info()函式用于提供一個資料集的基本資訊(或者總結),
通常在讀取一個資料表后,我們可以使用該函式來查看資料表的一些基本資訊,
info 通過info來了解資料每列的type,有助于了解是否存在除了nan以外的特殊符號例外,
- <class ‘pandas.core.frame.DataFrame’>: 是說資料型別為DataFrame
RangeIndex: 32 entries, 0 to 31: 有32條資料(32行),索引為0-31 - Data columns (total 12 columns): 該資料幀有12列
- column: 每列資料的列名
- Non-Null count: 每列資料的資料個數,缺失值NaN不作計算,可以看出上面disp和drat兩列資料都有缺失值
- Dtype: 資料的型別
# 通過describe()對于特征進行一些統計描述
print(df.describe())

# 通過info()來熟悉資料型別
print(df.info())
4. 判斷資料缺失和例外
通過以上兩句可以很直觀的了解哪些列存在 nan, 并可以把nan的個數列印,主要的目的在于 nan存在的個數是否真的很大,
如果很小一般選擇填充,如果使用lgb等樹模型可以直接空缺,讓樹自己去優化,但如果nan存在的過多、可以考慮刪掉,
4.1. 查看每列的存在nan情況
# 查看每列的存在nan情況
print(pd.isnull(df))
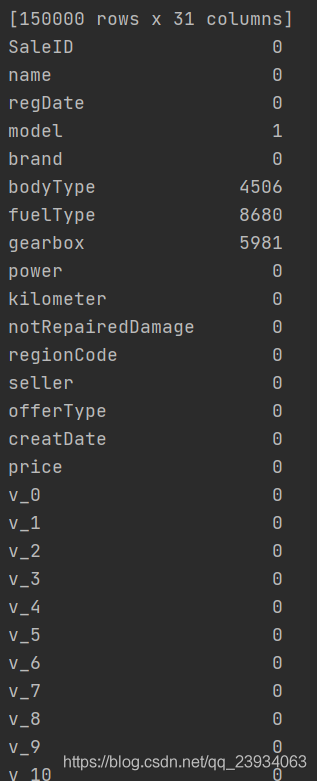
# 查看每列的存在nan值的記錄數
print(df.isnull().sum())
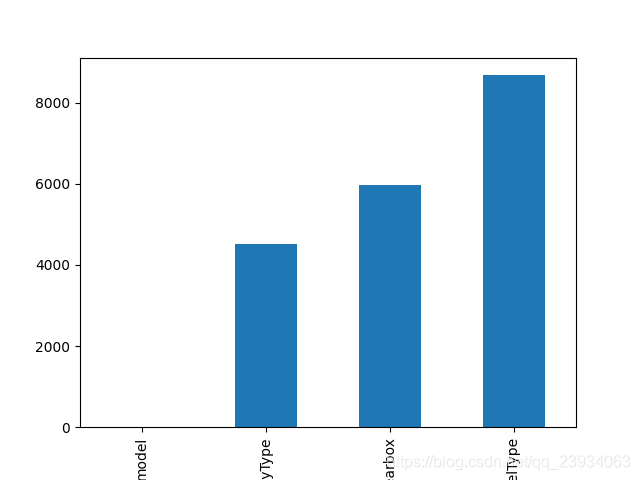
# nan可視化
missing = df.isnull().sum()
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()
plt.show()

4.2. 查看缺失值的分布情況
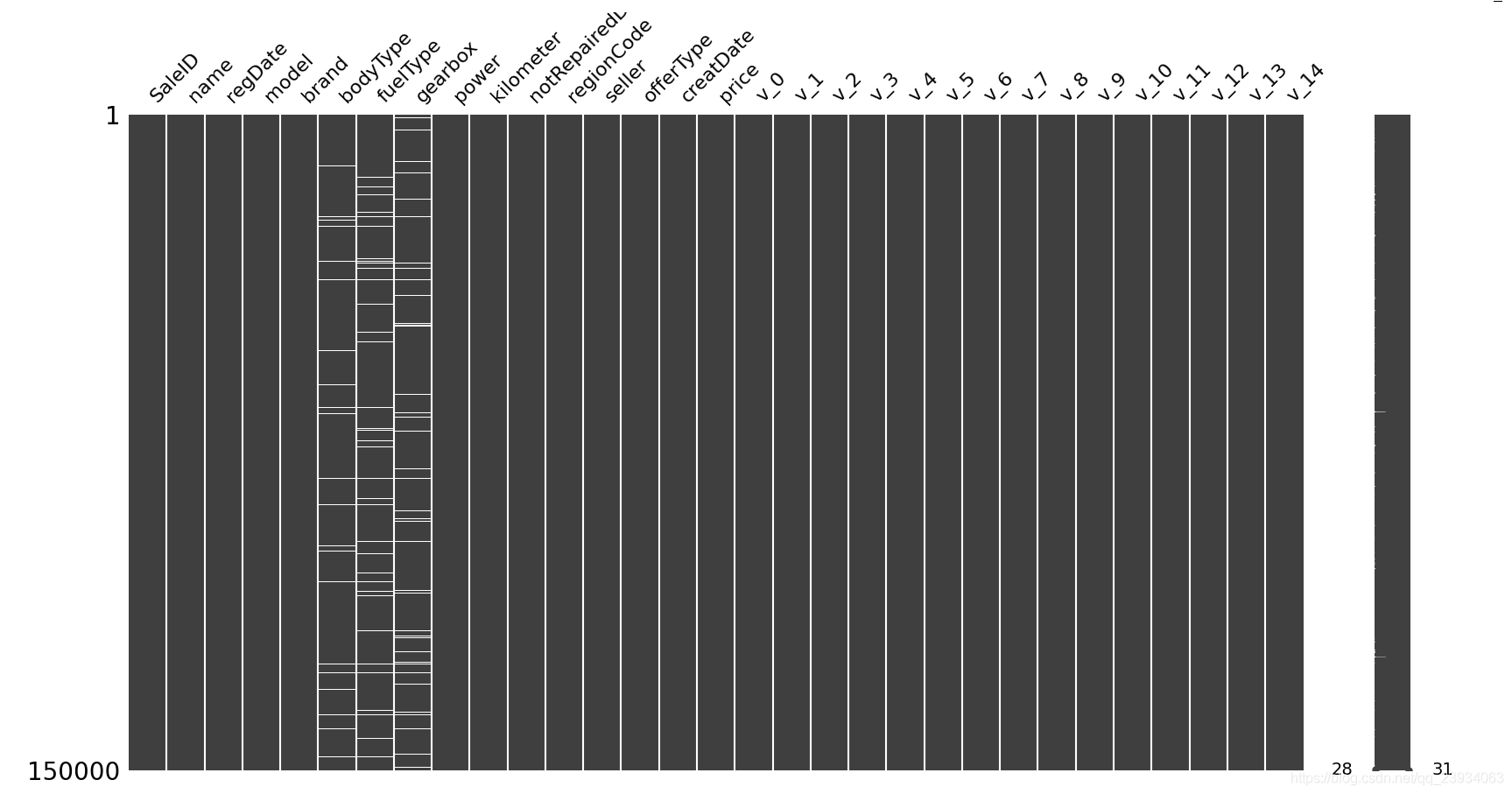
# 可視化看下預設值
# 缺失值的分布情況
msno.matrix(df.sample(150000))
plt.show()
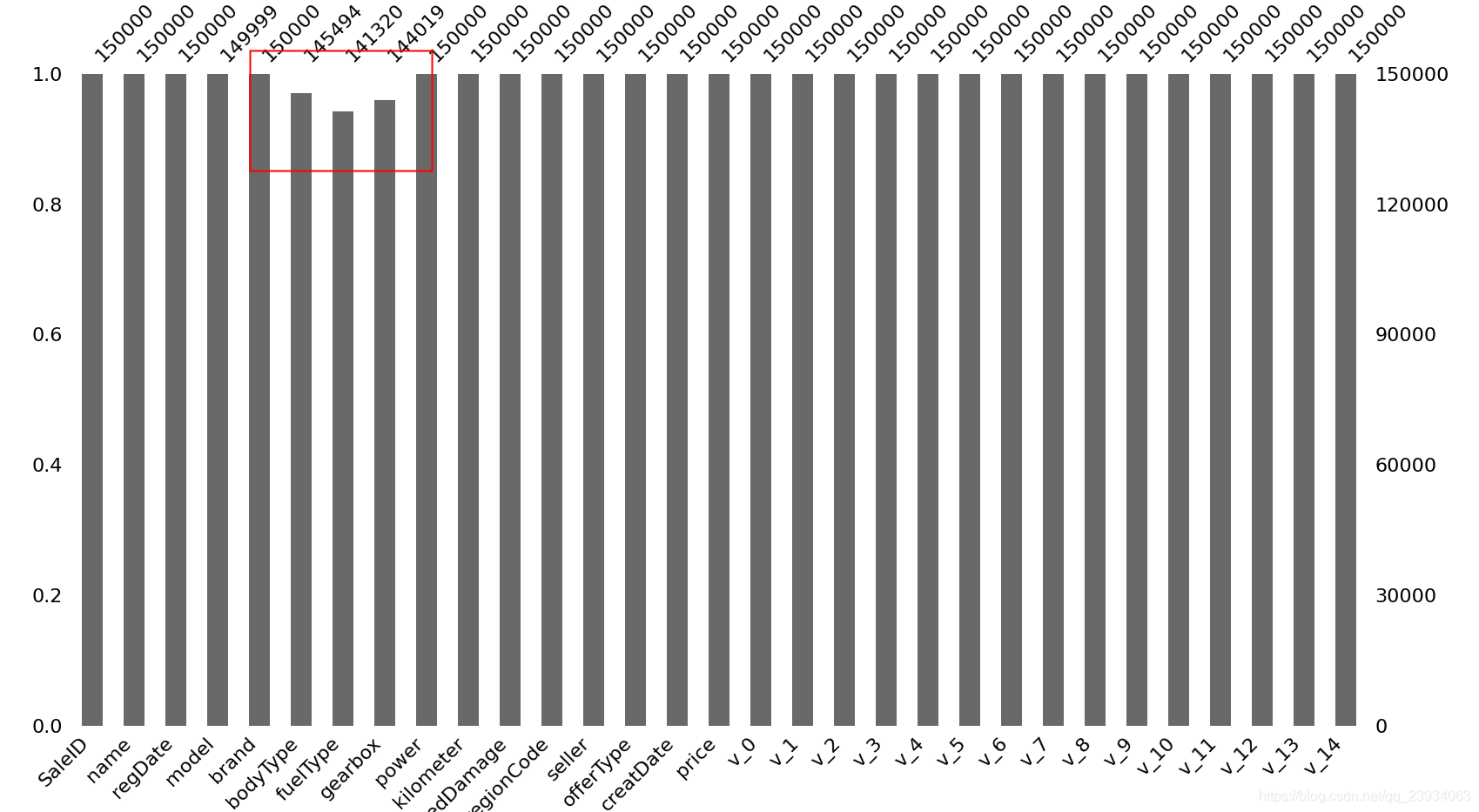
4.3. 查看有效值的占比情況
可視化有四列有預設model、bodyType、fuelType、notRepairedDamage, notRepairedDamage預設得最多
# 有效值的占比情況
msno.bar(df.sample(150000))
plt.show()
4.4. 例外值處理
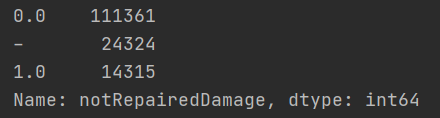
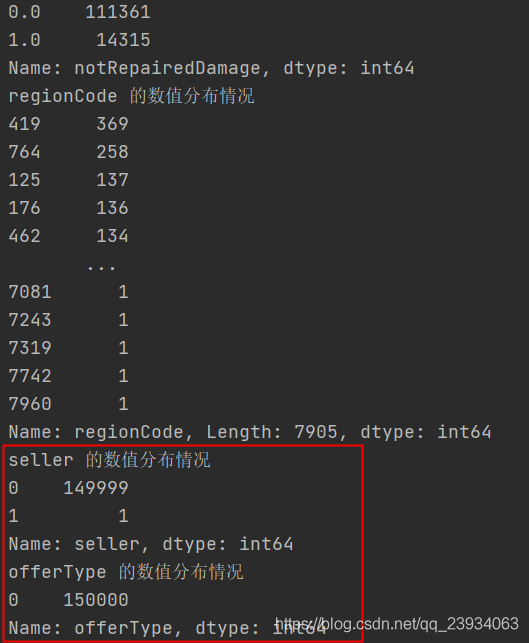
可以發現除了notRepairedDamage為object型別,是資料格式不一致,這里我們使用value_counts查看notRepairedDamage幾個不同值的情況,
可以看出來’-'也為空缺值,因為很多模型對nan有直接的處理,這里我們先不做處理,先替換成nan,
print(df['notRepairedDamage'].value_counts())
df['notRepairedDamage'].replace('-', np.nan, inplace=True)
print(df['notRepairedDamage'].value_counts())
處理前
處理后

4.5. 無效資料處理
以下兩個類別(seller、offerType)特征嚴重傾斜,一般不會對預測有什么幫助,故這邊先刪掉,當然你也可以繼續挖掘,但是一般意義不大,
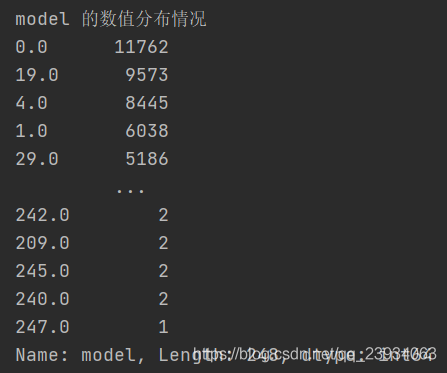
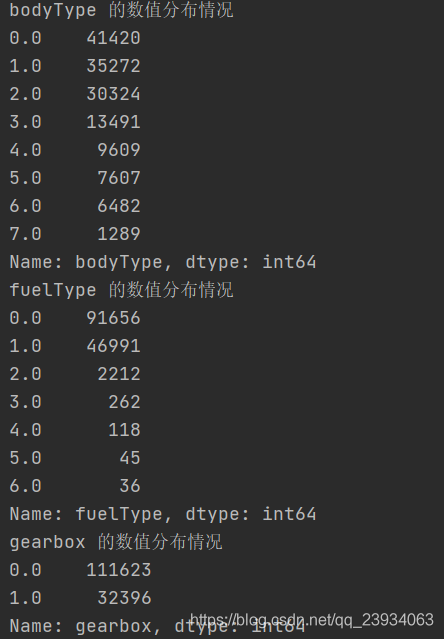
# 分別查看一下每個特征的資料分布情況
for columns in df.columns.values:
print(f"{columns} 的數值分布情況")
print(df[columns].value_counts())
del df["seller"]
del df["offerType"]
5. 了解預測值的分布
5.1. 總體分布概況
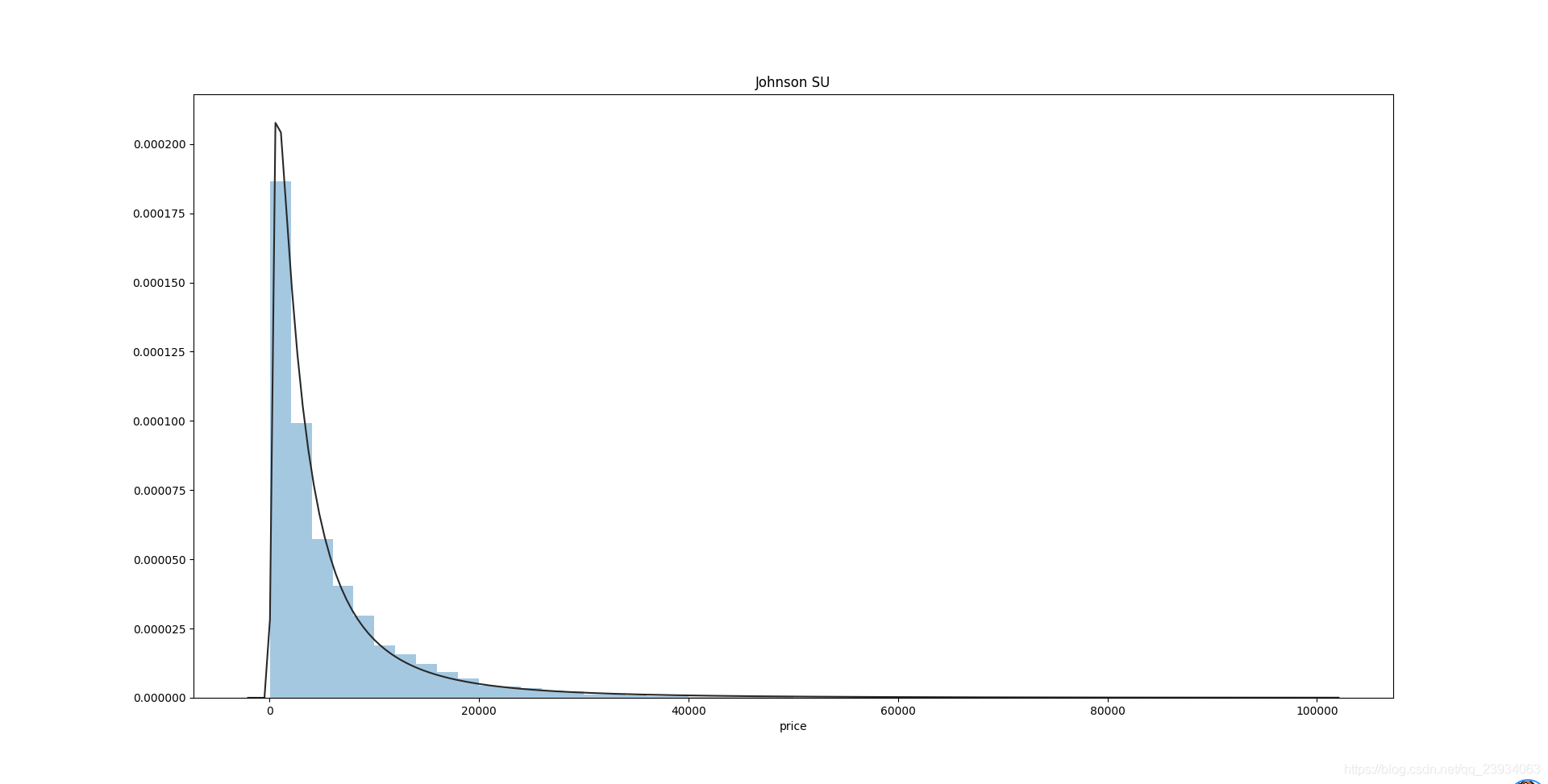
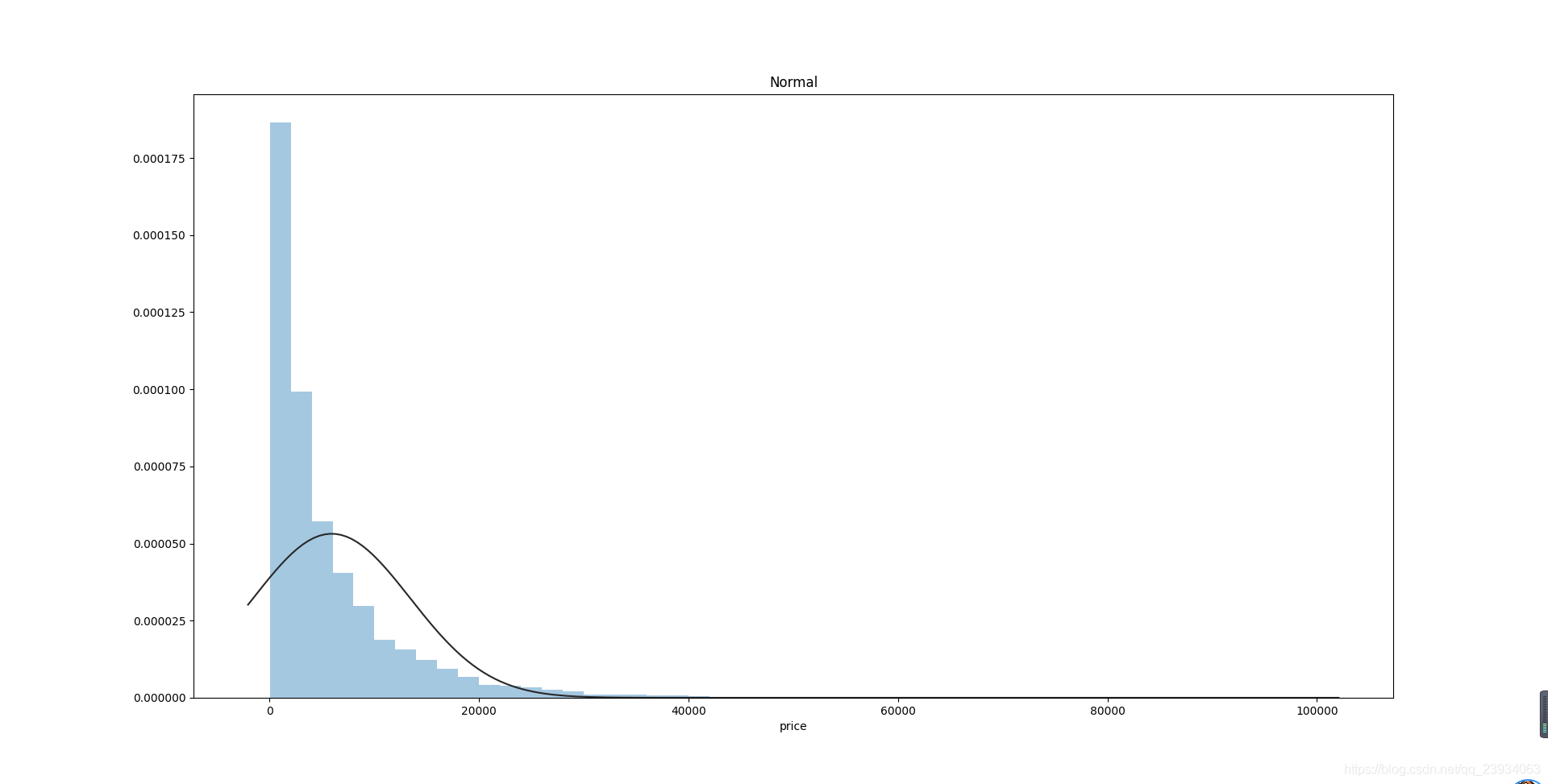
價格不服從正態分布,所以在進行回歸之前,它必須進行轉換,
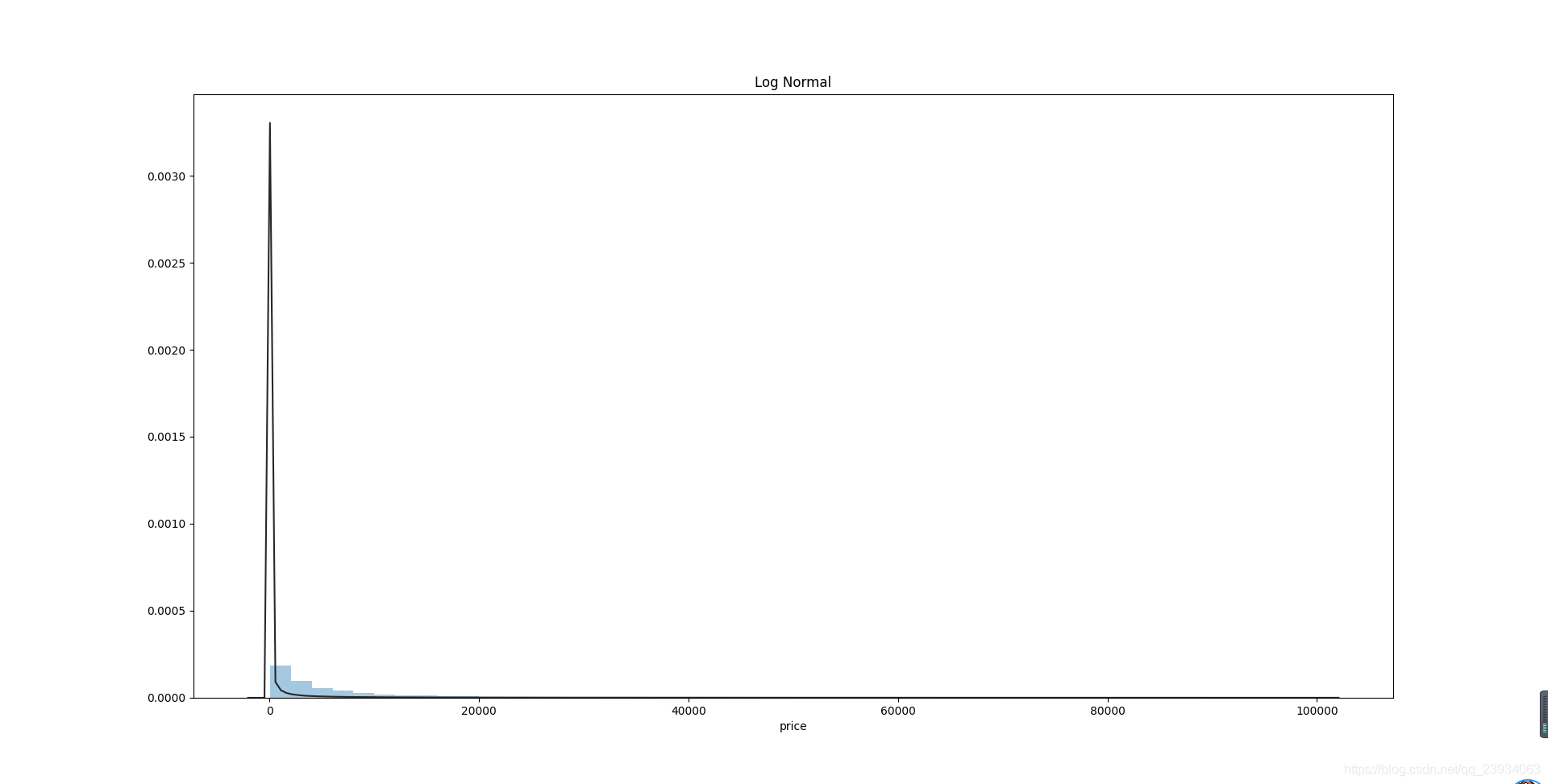
雖然對數變換做得很好,但最佳擬合是無界約翰遜分布
# print(df['price'])
import scipy.stats as st
# 總體分布概況
y = df['price']
# 無界約翰遜分布 johnsonsu
plt.figure(1)
plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu)
# 正態分布norm
plt.figure(2)
plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
# 對數正態分布 lognorm
plt.figure(3)
plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)
plt.show()
5.2. 查看skewness and kurtosis
偏度(Skewness)
Skewness 偏度是描述資料分布形態的統計量,其描述的是某總體取值分布的對稱性,簡單來說就是資料的不對稱程度,,
偏度是三階中心距計算出來的,
(1)Skewness = 0 ,分布形態與正態分布偏度相同,
(2)Skewness > 0 ,正偏引數值較大,為正偏或右偏,長尾巴拖在右邊,資料右端有較多的極端值,
(3)Skewness < 0 ,負偏引數值較大,為負偏或左偏,長尾巴拖在左邊,資料左端有較多的極端值,
(4)數值的絕對值越大,表明資料分布越不對稱,偏斜程度大,
峰度(Kurtosis)
Kurtosis峰度是描述某變數所有取值分布形態陡緩程度的統計量,簡單來說就是資料分布頂的尖銳程度,
峰度是四階標準矩計算出來的,
(1)Kurtosis=0 與正態分布的陡緩程度相同,
(2)Kurtosis>0 比正態分布的高峰更加陡峭——尖頂峰
(3)Kurtosis<0 比正態分布的高峰來得平臺——平頂峰
# 查看skewness
print("Skewness: %f" % df['price'].skew())
# 查看Kurtosis
print("Kurtosis: %f" % df['price'].kurt())
sns.distplot(df['price'])
plt.show()
sns.distplot(df.skew(), color='blue', axlabel='Skewness')
plt.show()
sns.distplot(df.kurt(), color='orange', axlabel='Kurtness')
plt.show()

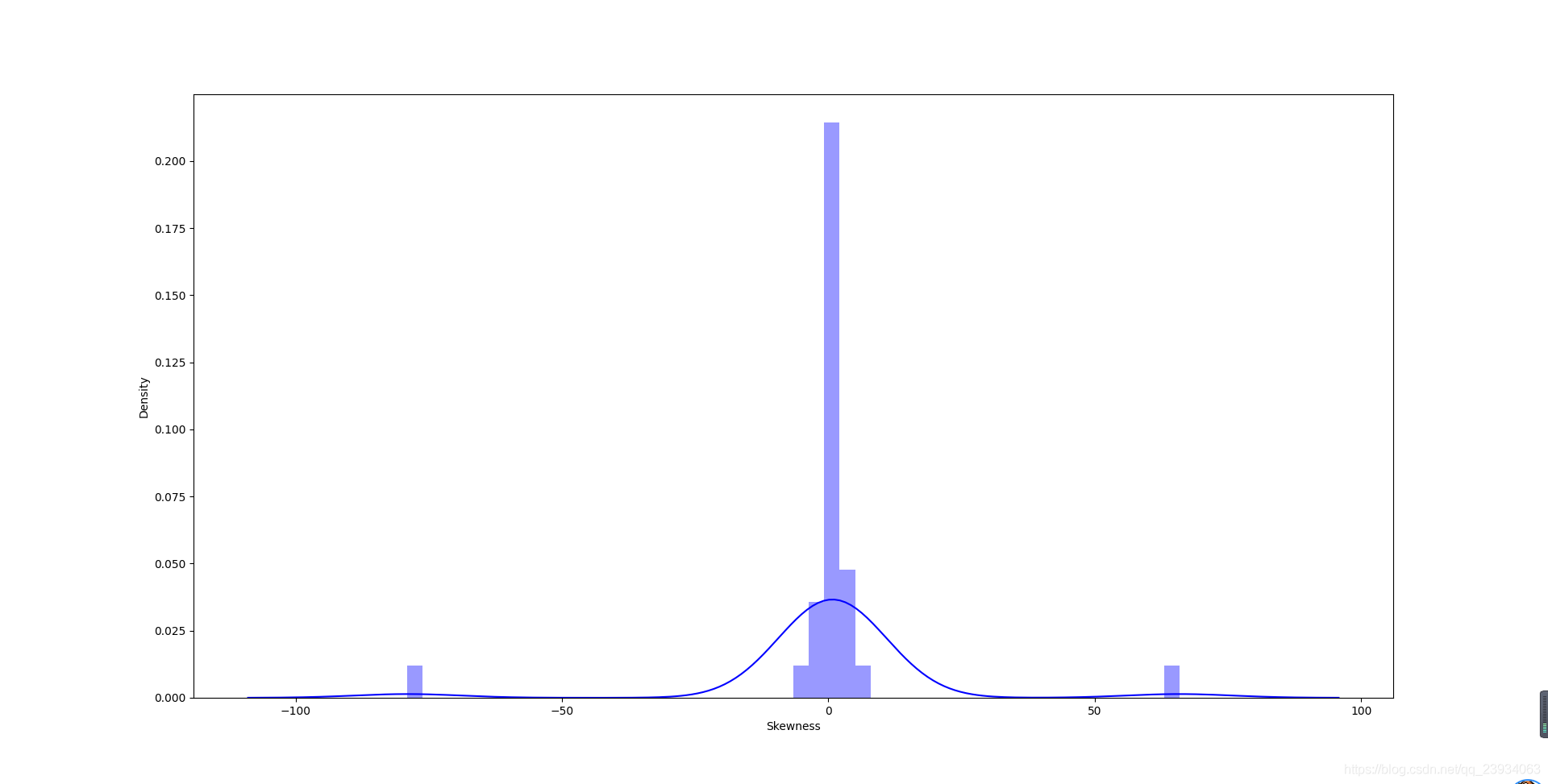
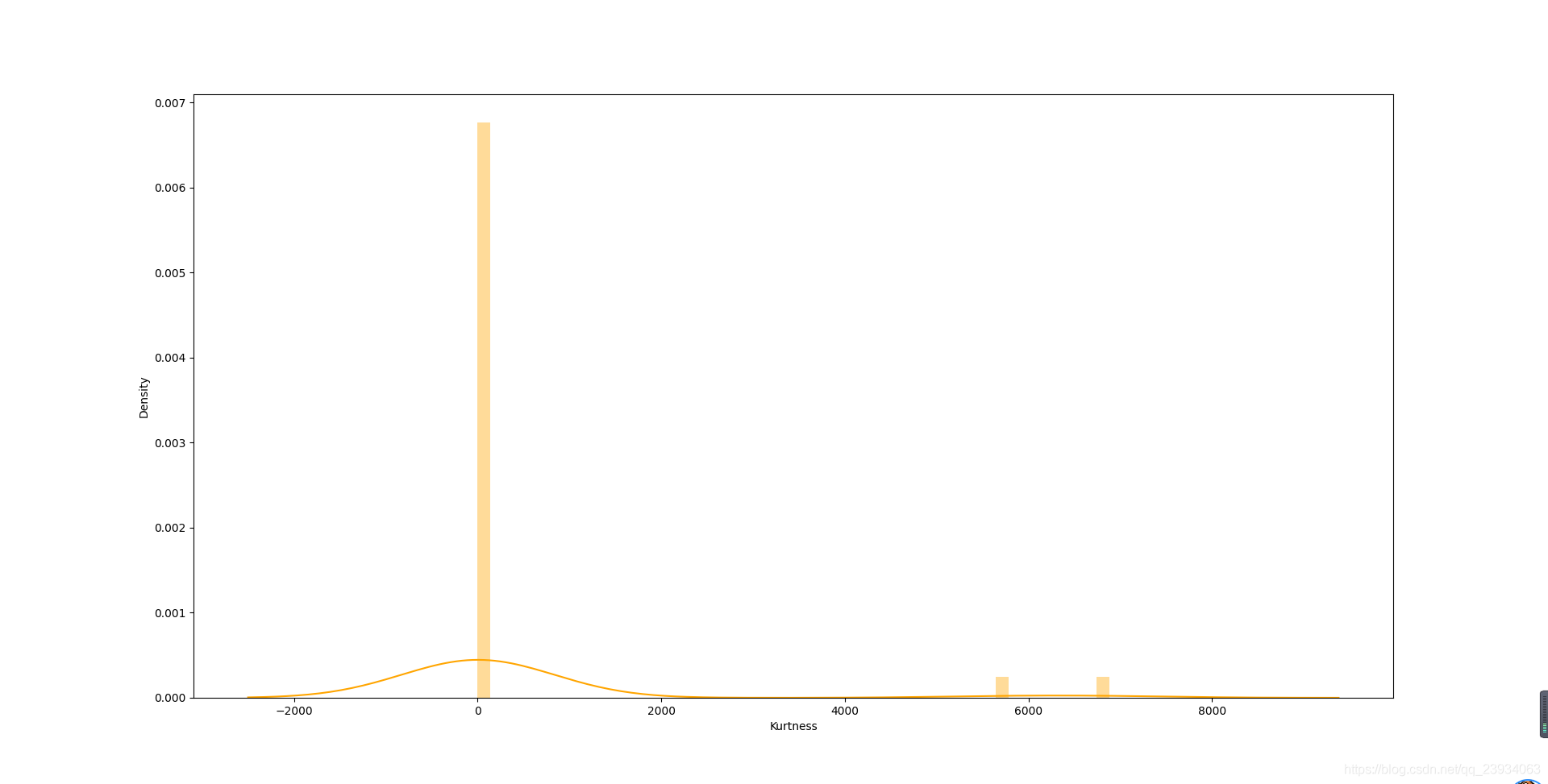
5.3. 查看預測值的具體頻數
# 特征與標簽組合的散點可視化 沒有意義
df = df[["price", "fuelType", "gearbox", "power"]]
sns.pairplot(data=df, diag_kind='hist', hue='price')
plt.show()
# 查看預測值的具體頻數
plt.hist(df['price'], orientation='vertical', histtype='bar', color='red')
plt.show()
查看頻數, 大于20000得值極少,其實這里也可以把這些當作特殊得值(例外值)直接用填充或者刪掉,再前面進行,
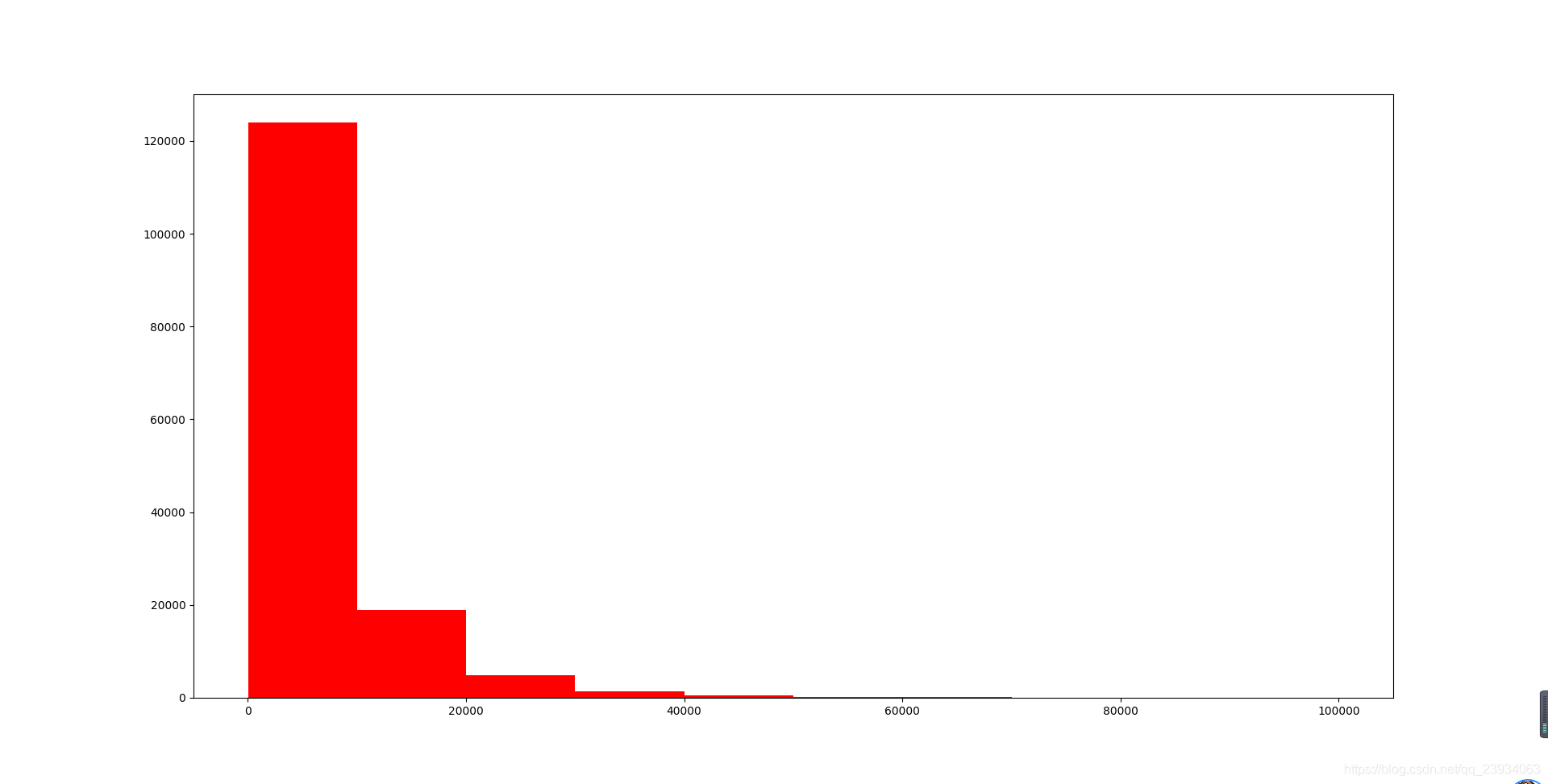
5.4. log變換
log變換 z之后的分布較均勻,可以進行log變換進行預測,這也是預測問題常用的trick,
對于一些標簽和特征來說,分布不一定符合正態分布,而在實際的運算程序中則需要資料能夠符合正態分布,
因此我們需要對特征進行log變化,使得資料在一定程度上可以符合正態分布,
進行log變化,就是對資料使用np.log(data+1) 加上1的目的是為了防止資料等于0,而不能進行log變化,
fig, ax = plt.subplots()
plt.hist(np.log(df['price']), orientation='vertical', bins=30, histtype='bar', color='#A9C5D3')
# 對log收入特征做直方圖,標出中位數線的位置,即均值
plt.axvline(np.log(df['price']).quantile(), color='red', label='quantile line')
plt.legend(fontsize=18, loc='best')
plt.show()
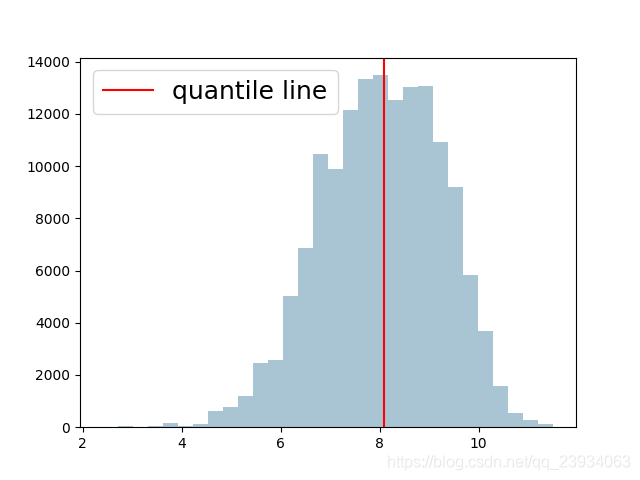
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/276163.html
標籤:其他
上一篇:一文了解 HDFS 及其組成框架