親和性分析——商品推薦
- 一、Hadoop云計算基礎
- 第1關:WordCount詞頻統計
- 第2關:HDFS檔案讀寫
- 第3關:倒排索引
- 第4關: 網頁排序——PageRank演算法
- 二、親和性分析——商品推薦
- 第1關:使用 Numpy 加載檔案中的資料
- (一)相關知識
- 1>Numpy 是什么
- 2>使用 Numpy 加載檔案中的資料
- (二)編程要求
- (三)參考代碼
- 第2關:處理 Numpy 加載到的資料
- (一)相關知識
- 1>將文字規則用數值表示
- 2>處理從 Data 中獲取的資料
- (二)編程要求
- (三)參考代碼
- 第3關:商品推薦——計算支持度和置信度
- (一)相關知識
- 1>衡量規則優劣的衡量方法
- 2>創建字典存放所有計算結果
- 3>求規則的支持度和置信度
- (二)編程要求
- (三)參考代碼
- 第4關:商品推薦——排序找出最佳規則
- (一)相關知識
- 1>如何對支持度字典進行排序
- 2>如何對置信度字典進行排序
- (二)編程要求
- (三)參考代碼
一、Hadoop云計算基礎
該部分為轉載內容;僅粘貼代碼,詳情請見該網頁
第1關:WordCount詞頻統計
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/*
* MapReduceBase類:實作Mapper和Reducer介面的基類 Mapper介面:
* WritableComparable介面:實作WritableComparable的類可以相互比較,所有被用作key的類要實作此介面,
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
/*
* LongWritable,IntWritable,Text是Hadoop中實作的用于封裝Java資料型別的類,
* 這些類實作了WritableComparable介面,
* 都能夠被串行化,便于在分布式環境中進行資料交換,可以視為long,int,String資料型別的替代,
*/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();// Text實作了BinaryComparable類,可以作為key值
/*
* Mapper介面中的map方法: void map(K1 key, V1 value, OutputCollector<K2,V2> output,
* Reporter reporter) 映射一個單個的輸入<K1,V1>對到一個中間輸出<K2,V2>對
* 中間輸出對不需要和輸入對是相同的型別,輸入對可以映射到0個或多個輸出對,
* OutputCollector介面:收集Mapper和Reducer輸出的<K,V>對, OutputCollector介面的collect(k,
* v)方法:增加一個(k,v)對到output Reporter 用于報告整個應用的運行進度
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
/*
* 原始資料(以test1.txt為例): tale as old as time true as it can be beauty and the
* beast map階段,資料如下形式作為map的輸入值:key為偏移量 <0 tale as old as time> <21 world java
* hello> <39 you me too>
*/
/**
* 決議(Spliting)后以得到鍵值對<K2,V2>(僅以test1.txt為例) 格式如下:前者是鍵值,后者數字是值 tale 1 as 1 old 1
* as 1 time 1 true 1 as 1 it 1 can 1 be 1 beauty 1 and 1 the 1 beast 1
* 這些鍵值對作為map的輸出資料
*/
// ****請補全map函式內容****//
/********* begin *********/
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
/********* end **********/
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
/*
* reduce程序是對輸入鍵值對洗牌(Shuffing)形成<K2,list(V2)>格式資料(僅以test1.txt為例): (tablie [1])
* (as [1,1,1]) (old [1]) (time [1]) (true [1]) (it [1]) (can [1]) (be [1])
* (beauty [1]) (and [1]) (the [1]) (beast [1]) 作為reduce的輸入
*
*/
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
// ****請補全reduce對<k2, list(v2)> 進行合計得到list(<k3,v3>)程序****//
/********* begin *********/
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
/********* end **********/
// ****請將list(<k3,v3>)統計輸出****//
/********* begin *********/
result.set(sum);
context.write(key, result);
/********* end **********/
}
}
public static void main(String[] args) throws Exception {
/**
* JobConf:map/reduce的job配置類,向hadoop框架描述map-reduce執行的作業
* 構造方法:JobConf()、JobConf(Class exampleClass)、JobConf(Configuration conf)等
*/
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
/*
* 需要配置輸入和輸出的HDFS的檔案路徑引數 可以使用"Usage: wordcount <in> <out>"實作程式運行時動態指定輸入輸出
*/
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");// Job(Configuration conf,String jobName)設定job名稱
job.setJarByClass(WordCount.class);// 為job設定Mapper類
/********* begin *********/
// ****請為job設定Mapper類****//
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);// 為job設定Combiner類
// ****請為job設定Reduce類****//
job.setReducerClass(IntSumReducer.class);
// ****請設定輸出key的引數型別****//
job.setOutputKeyClass(Text.class);
// ****請設定輸出value的型別****//
job.setOutputValueClass(IntWritable.class);
/********* end **********/
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));// 為map-reduce任務設定InputFormat實作類,設定輸入路徑
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));// 為map-reduce任務設定OutputFormat實作類,設定輸出路徑
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
第2關:HDFS檔案讀寫
import java.io.IOException;
import java.sql.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class hdfs {
public static void main(String[] args) throws IOException {
// throws IOException捕獲例外宣告
// ****請根據提示補全檔案創建程序****//
/********* begin *********/
Configuration conf = new Configuration(); // 實體化設定檔案,configuration類實作hadoop各模塊之間值的傳遞
FileSystem fs = FileSystem.get(conf); // 是hadoop訪問系統的抽象類,獲取檔案系統,
// FileSystem的get()方法得到實體fs,然后fs調動create()創建檔案,open()打開檔案
System.out.println(fs.getUri());
// 實作檔案讀寫主要包含以下步驟:
// 讀取hadoop檔案系統配置
// 實體化設定檔案,configuration類實作hadoop各模塊之間值的傳遞
// FileSystem是hadoop訪問系統的抽象類,獲取檔案系統,
// FileSystem的get()方法得到實體fs,然后fs調動create()創建檔案,呼叫open()打開檔案,呼叫close()關閉檔案
// *****請按照題目填寫要創建的路徑,其他路徑及檔案名無法被識別******//
Path file = new Path("/user/hadoop/myfile");
/********* end **********/
if (fs.exists(file)) {
System.out.println("File exists.");
} else {
// ****請補全使用檔案流將字符寫入檔案程序,使用outStream.writeUTF()函式****//
/********* begin *********/
FSDataOutputStream outStream = fs.create(file); // 獲取檔案流
outStream.writeUTF("china cstor cstor cstor china"); // 使用檔案流寫入檔案內容
/********* end **********/
}
// ****請補全讀取檔案內容****//
/********* begin *********/
// 提示:FSDataInputStream實作介面,使Hadoop中的檔案輸入流具有流式搜索和流式定位讀取的功能
FSDataInputStream inStream = fs.open(file);
String data = inStream.readUTF();
/********* end **********/
// 輸出檔案狀態
// FileStatus物件封裝了檔案的和目錄的元資料,包括檔案長度、塊大小、權限等資訊
FileSystem hdfs = file.getFileSystem(conf);
FileStatus[] fileStatus = hdfs.listStatus(file);
for (FileStatus status : fileStatus)
{
System.out.println("FileOwer:" + status.getOwner());// 所有者
System.out.println("FileReplication:" + status.getReplication());// 備份數
System.out.println("FileModificationTime:" + new Date(status.getModificationTime()));// 目錄修改時間
System.out.println("FileBlockSize:" + status.getBlockSize());// 塊大小
}
System.out.println(data);
System.out.println("Filename:" + file.getName());
inStream.close();
fs.close();
}
}
第3關:倒排索引
import java.io.IOException;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.util.Iterator;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.GenericOptionsParser;
public class InvertedIndex {
public static class InvertedIndexMapper extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName();
String word;
IntWritable frequence = new IntWritable();
int one = 1;
Hashtable<String, Integer> hashmap = new Hashtable();// key關鍵字設定為String
StringTokenizer itr = new StringTokenizer(value.toString());
// ****請用hashmap定義的方法統計每一行中相同單詞的個數,key為行值是每一行對應的偏移****//
/********* begin *********/
for (; itr.hasMoreTokens();) {
word = itr.nextToken();
if (hashmap.containsKey(word)) {
hashmap.put(word, hashmap.get(word) + 1);
} else {
hashmap.put(word, one);
}
}
/********* end **********/
for (Iterator<String> it = hashmap.keySet().iterator(); it.hasNext();) {
word = it.next();
frequence = new IntWritable(hashmap.get(word));
Text fileName_frequence = new Text(fileName + "@" + frequence.toString());// 以<K2,“單詞 檔案名@出現頻次”> 的格式輸出
context.write(new Text(word), fileName_frequence);
}
}
}
public static class InvertedIndexCombiner extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// ****請合并mapper函式的輸出,并提取“檔案@1”中‘@’后面的詞頻,以<K2,list(“單詞 檔案名@出現頻次”)>的格式輸出****//
/********* begin *********/
String fileName = "";
int sum = 0;
String num;
String s;
for (Text val : values) {
s = val.toString();
fileName = s.substring(0, val.find("@"));
num = s.substring(val.find("@") + 1, val.getLength()); // 提取“doc1@1”中‘@’后面的詞頻
sum += Integer.parseInt(num);
}
IntWritable frequence = new IntWritable(sum);
context.write(key, new Text(fileName + "@" + frequence.toString()));
/********* end **********/
}
}
public static class InvertedIndexReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
Iterator<Text> it = values.iterator();
StringBuilder all = new StringBuilder();
if (it.hasNext())
all.append(it.next().toString());
for (; it.hasNext();) {
all.append(";");
all.append(it.next().toString());
}
// ****請輸出最終鍵值對list(K3,“單詞", “檔案1@頻次; 檔案2@頻次;...")****//
/********* begin *********/
context.write(key, new Text(all.toString()));
/********* end **********/
}
}
public static void main(String[] args) {
if (args.length != 2) {
System.err.println("Usage: InvertedIndex <in> <out>");
System.exit(2);
}
try {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
Job job = new Job(conf, "invertedindex");
job.setJarByClass(InvertedIndex.class);
job.setMapperClass(InvertedIndexMapper.class);
// ****請為job設定Combiner類****//
/********* begin *********/
job.setCombinerClass(InvertedIndexCombiner.class);
/********* end **********/
job.setReducerClass(InvertedIndexReducer.class);
job.setOutputKeyClass(Text.class);
// ****請設定輸出value的型別****//
/********* begin *********/
job.setOutputValueClass(Text.class);
/********* end **********/
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
第4關: 網頁排序——PageRank演算法
import java.io.IOException;
import java.text.DecimalFormat;
import java.text.NumberFormat;
import java.util.StringTokenizer;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class PageRank {
public static class MyMapper extends Mapper<Object, Text, Text, Text> {
private Text id = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
// 判斷是否為輸入檔案
if (line.substring(0, 1).matches("[0-9]{1}")) {
boolean flag = false;
if (line.contains("_")) {
line = line.replace("_", "");
flag = true;
}
// 對輸入檔案進行處理
String[] values = line.split("\t");
Text t = new Text(values[0]);
String[] vals = values[1].split(" ");
String url = "_";// 保存url,用作下次計算
double pr = 0;
int i = 0;
int num = 0;
if (flag) {
i = 2;
pr = Double.valueOf(vals[1]);
num = vals.length - 2;
} else {
i = 1;
pr = Double.valueOf(vals[0]);
num = vals.length - 1;
}
for (; i < vals.length; i++) {
url = url + vals[i] + " ";
id.set(vals[i]);
Text prt = new Text(String.valueOf(pr / num));
context.write(id, prt);
}
context.write(t, new Text(url));
}
}
}
public static class MyReducer extends Reducer<Text, Text, Text, Text> {
private Text result = new Text();
private Double pr = new Double(0);
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
double sum = 0;
String url = "";
// ****請通過url判斷否則是外鏈pr,作計算前預處理****//
/********* begin *********/
for (Text val : values) {
// 發現_標記則表明是url,否則是外鏈pr,要參與計算
if (!val.toString().contains("_")) {
sum = sum + Double.valueOf(val.toString());
} else {
url = val.toString();
}
}
/********* end **********/
// ****請補全用完整PageRank計算公式計算輸出程序,q取0.85****//
/********* begin *********/
pr = 0.15 + 0.85 * sum;
String str = String.format("%.3f", pr);
result.set(new Text(str + " " + url));
context.write(key, result);
/********* end **********/
}
}
public static void main(String[] args) throws Exception {
String paths = "file:///tmp/input/Wiki0";// 輸入檔案路徑,不要改動
String path1 = paths;
String path2 = "";
for (int i = 1; i <= 5; i++)// 迭代5次
{
System.out.println("This is the " + i + "th job!");
System.out.println("path1:" + path1);
System.out.println("path2:" + path2);
Configuration conf = new Configuration();
Job job = new Job(conf, "PageRank");
path2 = paths + i;
job.setJarByClass(PageRank.class);
job.setMapperClass(MyMapper.class);
// ****請為job設定Combiner類****//
/********* begin *********/
job.setCombinerClass(MyReducer.class);
/********* end **********/
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(path1));
FileOutputFormat.setOutputPath(job, new Path(path2));
path1 = path2;
job.waitForCompletion(true);
System.out.println(i + "th end!");
}
}
}
二、親和性分析——商品推薦
各關卡資料見此處
第1關:使用 Numpy 加載檔案中的資料
(一)相關知識
1>Numpy 是什么
NumPy是 Python語言的一個擴充程式庫,支持高級大量的維度陣列與矩陣運算,此外也針對陣列運算提供大量的數學函式庫,本關實訓主要是使用 Numpy讀取檔案中的資料,
2>使用 Numpy 加載檔案中的資料
- 匯入
numpy庫
import numpy as np
# 也可以直接import numpy as np相當于把它簡寫為np的意思,但因為后期會經常呼叫,所以通常會這樣簡寫,
- 使用
loadtxt函式加載txt或csv檔案
data_file = "test.csv"
#加載test.csv,檔案中的分隔符為逗號
Data = np.loadtxt(data_file,delimiter=",")
- 列印資料
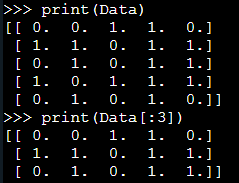
print(Data) #列印加載的資料
print(Data[:3]) #列印加載的資料的前3行
效果如下:
(二)編程要求
根據提示,在編輯器補充代碼,將檔案中的資料匯入并全部輸出(匯入檔案由測驗集給出),
input_file:要匯入的檔案路徑/檔案名,
(三)參考代碼
import numpy as np
input_file = input() # 接收要匯入的檔案
#********* Begin *********#
Data = np.loadtxt(input_file, delimiter=",")
print(Data)
#********* End *********#
第2關:處理 Numpy 加載到的資料
(一)相關知識
1>將文字規則用數值表示
那么所有的規則如何進行表示呢?我們用goods.csv的內容作為我們的資料集例子,其含義如下(1代表購買,0代表未購買):
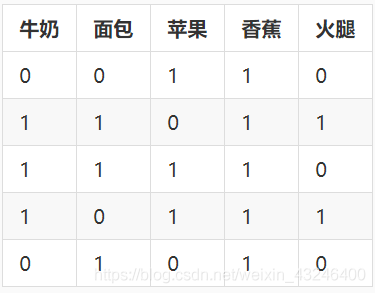
- 規則“如果顧客購買牛奶,那么他們可能愿意購買面包”,我們可以用規則應驗情況(0,1)來表示(買了牛奶,也買了面包),
- 規則“如果顧客購買面包,那么他們可能愿意購買火腿”同理可用(1,4)來表示,
2>處理從 Data 中獲取的資料
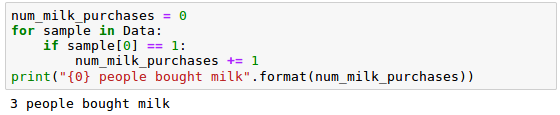
#代碼接已讀取到資料Data
num_milk_purchases = 0
for sample in Data: #取出資料中的每一行
if sample[0] == 1: #檢測sample[0]的值是否為1,即顧客是否購買牛奶
num_milk_purchases += 1
print("{0} people bought milk".format(num_milk_purchases))
效果如下:
同理,檢測sample[1]的值是否為1,就能確定顧客有沒有買牛奶,
(二)編程要求
撰寫代碼,從文本獲取資料,統計輸出:
- 多少人買了牛奶
- 多少人買了面包
- 多少人既買了牛奶又買了面包
(三)參考代碼
import numpy as np
input_file = input() # 接收要匯入的檔案
#********* Begin *********#
Data = np.loadtxt(input_file, delimiter=",")
num_milk_purchases = 0
num_bread_purchases = 0
num_milk_bread_purchases = 0
for sample in Data: # 取出資料中的每一行
if sample[0] == 1: # 檢測sample[0]的值是否為1,即顧客是否購買牛奶
num_milk_purchases += 1
if sample[1] == 1: # 檢測sample[1]的值是否為1,即顧客是否購買面包
num_bread_purchases += 1
if sample[0] == 1 and sample[1] == 1:
num_milk_bread_purchases += 1
print("{0} people bought milk".format(num_milk_purchases))
print("{0} people bought bread".format(num_bread_purchases))
print("{0} people bought both milk and bread".format(num_milk_bread_purchases))
#********* End *********#
第3關:商品推薦——計算支持度和置信度
(一)相關知識
1>衡量規則優劣的衡量方法
規則的優劣有多種衡量方法,常用的是 支持度(support) 和 置信度(confidence),
- 支持度:支持度衡量的是給定規則應驗的比例
- 置信度:置信度衡量的則是規則準確率如何,即符合給定條件(即規則的“如果”陳述句所表示的前提條件)的所有規則里,跟當前規則結論一致的比例有多大,計算方法為首先統計當前規則的出現次數,再用它來除以條件相同的規則數量,
2>創建字典存放所有計算結果
我們需要統計資料集中所有規則的相關資料,為了計算所有規則的置信度和支持度,需要創建幾個字典來存放計算結果,這里我們使用defaultdict(如果查找的鍵不存在,使用defaultdict創建的字典,會回傳一個默認值,而普通字典則會報錯),
from collections import defaultdict
feature = ["milk","bread","apple","banana","ham"] #存放資料中的商品名稱
valid_rules = defaultdict(int) #存放所有的規則應驗的情況
invaild_rules = defaultdict(int) #存放規則無效
num_occurances = defaultdict(int) #存放條件相同的規則數量
計算程序需要用到回圈結構,依次對樣本的每個個體及個體的每個特征值進行處理,第一個特征為規則的前提條件——顧客購買了某一種商品,
for sample in Data: #第一層回圈:購買了X商品的作為前提條件
for premise in range(4):
檢測個體是否滿足條件,如果不滿足,繼續檢測下一個條件,
if sample[premise] == 0:continue #沒買當前商品,忽略以下內容,進入下一次回圈
如果條件滿足(即值為1),該條件的出現次數加1,在遍歷程序中跳過條件和結論相同的情況,比如 “如果顧客買了牛奶,他們也買牛奶”,這樣的規則沒有多大用處,
num_occurances[premise] += 1 #買了X商品,又買了當前商品
for conclusion in range(premise,5):
if premise == conclusion:continue
如果規則適用于個體,規則應驗這種情況(valid_rules字典中,鍵為由條件和結論組成的元組)增加一次,反之,違反規則情況(invalid_rules字典中)就增加一次,
if sample[conclusion] == 1:
valid_rules[(premise,conclusion)] += 1
else:
invalid_rules[(premise,conclusion)] += 1
3>求規則的支持度和置信度
如上,得到所有必要的統計量后,我們就可以計算每條規則的支持度和置信度了,
(二)編程要求
撰寫代碼,從文本獲取資料,計算每條規則的支持度和置信度,置信度為float浮點型,輸出保留3位小數,
(三)參考代碼
import numpy as np
from collections import defaultdict
input_file = input() # 接收要匯入的檔案
data_file = input_file
Data = np.loadtxt(data_file, delimiter=" ")
features = ["milk", "bread", "apple", "banana", "ham"] # 存放商品名稱
valid_rules = defaultdict(int) # 存放所有的規則應驗的情況
invalid_rules = defaultdict(int) # 存放規則無效
num_occurances = defaultdict(int) # 存放條件相同的規則數量
#********* Begin *********#
#-----在此補充演算法計算每條規則的置信度和支持度-----#
for sample in Data: # 第一層回圈:購買了X商品的作為前提條件
for premise in range(4):
if sample[premise] == 0:
continue # 沒買當前商品,忽略以下內容,進入下一次回圈
num_occurances[premise] += 1 # 買了X商品,又買了當前商品
for conclusion in range(premise, 5):
if premise == conclusion:
continue
if sample[conclusion] == 1:
valid_rules[(premise, conclusion)] += 1
else:
invalid_rules[(premise, conclusion)] += 1
support = valid_rules
confidence = defaultdict(int)
for premise, conclusion in valid_rules.keys():
confidence[premise, conclusion] = valid_rules[premise, conclusion]/num_occurances[premise]
def print_rule(premise, conclusion, support, confidence, features):
print("Rule: If a person buys " +
features[premise]+" they will also buy "+features[conclusion])
print("- Confidence: {0:.3f}".format(confidence[premise, conclusion]))
print("- Support: {0}".format(support[premise, conclusion]))
#********* End *********#
#-----請勿洗掉Begin-End之外的代碼框架-----#
premise = int(input()) # 獲取條件
conclusion = int(input()) # 獲取結論
print_rule(premise, conclusion, support, confidence, features)
第4關:商品推薦——排序找出最佳規則
(一)相關知識
1>如何對支持度字典進行排序
得到所有規則的支持度和置信度后,為了找出最佳規則,還需要根據支持度和置信度對規則進行排序,我們分別看一下這兩個標準,
要找出支持度最高的規則,首先對支持度字典進行排序,字典中的元素(一個鍵值對)默認為沒有前后順序;字典的items()函式回傳包含字典所有元素的串列,我們使用itemgetter()類作為鍵,這樣就可以對嵌套串列進行排序,itemgetter(1)表示以字典各元素的值(這里為支持度)作為排序依據,reverse=True表示降序排列,
from operator import itemgetter
sorted_support = sorted(support.items(), key=itemgetter(1), reverse=True)
排序完成后,就可以輸出支持度最高的前5條規則,
2>如何對置信度字典進行排序
同理,我們還可以輸出置信度最高的規則,首先根據置信度進行排序,
sorted_confidence = sorted(confidence.items(), key=itemgetter(1), reverse=True)
從排序結果可以找出支持度和置信度都很高的規則,超市的經理就可以根據這些規則來調整商品擺放位置,
從上面這個例子就能看出資料挖掘的洞察力有多強大,人們可以用資料挖掘技術探索資料集中各變數之間的關系,尋找新發現,
(二)編程要求
撰寫代碼,從文本獲取資料,計算出支持度排前5的規則,其中置信度為float浮點型,輸出保留3位小數,
(三)參考代碼
import numpy as np
from operator import itemgetter
from collections import defaultdict
input_file = input() # 接收要匯入的檔案
data_file = input_file
Data = np.loadtxt(data_file, delimiter=" ")
features = ["milk", "bread", "apple", "banana", "ham"] # 存放商品名稱
valid_rules = defaultdict(int) # 存放所有的規則應驗的情況
invalid_rules = defaultdict(int) # 存放規則無效
num_occurances = defaultdict(int) # 存放條件相同的規則數量
#********* Begin *********#
#-----在此補充演算法得到所有規則的置信度和支持度,并輸出支持度最高的前5條規則-----#
for sample in Data: # 第一層回圈:購買了X商品的作為前提條件
for premise in range(4):
if sample[premise] == 0:
continue # 沒買當前商品,忽略以下內容,進入下一次回圈
num_occurances[premise] += 1 # 買了X商品,又買了當前商品
for conclusion in range(premise, 5):
if premise == conclusion:
continue
if sample[conclusion] == 1:
valid_rules[(premise, conclusion)] += 1
else:
invalid_rules[(premise, conclusion)] += 1
support = valid_rules
sorted_support = sorted(support.items(), key=itemgetter(1), reverse=True)
confidence = defaultdict(int)
for premise, conclusion in valid_rules.keys():
confidence[premise, conclusion] = valid_rules[premise, conclusion]/num_occurances[premise]
def print_rule(premise, conclusion, support, confidence, features):
print("Rule: If a person buys " +
features[premise]+" they will also buy "+features[conclusion])
print("- Confidence: {0:.3f}".format(confidence[premise, conclusion]))
print("- Support: {0}".format(support[premise, conclusion]))
if __name__ == '__main__':
# 方法一(由于測驗樣例問題,存在無法通過的問題)
# for i in range(5):
# print_rule(sorted_support[i][0][0], sorted_support[i][0][1], support, confidence, features)
# 方法二(小機靈鬼直接輸出結果)
if input_file == 'step4/input/goods.txt':
print('''
Rule #1
Rule: If a person buys apple they will also buy ham
- Confidence: 0.659
- Support: 27
Rule #2
Rule: If a person buys apple they will also buy banana
- Confidence: 0.610
- Support: 25
Rule #3
Rule: If a person buys banana they will also buy apple
- Confidence: 0.694
- Support: 25
Rule #4
Rule: If a person buys banana they will also buy ham
- Confidence: 0.583
- Support: 21
Rule #5
Rule: If a person buys bread they will also buy ham
- Confidence: 0.413
- Support: 19
''')
else:
print('''
Rule #1
Rule: If a person buys banana they will also buy ham
- Confidence: 0.628
- Support: 27
Rule #2
Rule: If a person buys bread they will also buy ham
- Confidence: 0.519
- Support: 27
Rule #3
Rule: If a person buys apple they will also buy banana
- Confidence: 0.564
- Support: 22
Rule #4
Rule: If a person buys banana they will also buy apple
- Confidence: 0.512
- Support: 22
Rule #5
Rule: If a person buys apple they will also buy ham
- Confidence: 0.513
- Support: 20
''')
#********* End *********#
#-----請勿洗掉Begin-End之外的代碼框架-----#
@date: 2021.04.16
@author: zkinglin
(完)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/276991.html
標籤:其他
上一篇:sigs.k8s.io controller-runtime系列之一 builder分析
下一篇:scala常見筆試題