
作者 | 馬超
出品 | CSDN(ID:CSDNnews)
昨日,在英偉達的新品發布會大會上,英偉達 CEO 黃仁勛如期拿出了首款 CPU 芯片 Grace,劍指 AI 云計算,其實筆者在之前的文章就曾指出,英偉達收購 ARM 預示著 N 廠必然進軍 CPU 領域,在云計算市場有所作為,而本次發布會上除了 Grace 之外,英偉達還發布了 Transformers 框架——NVIDIA Megatron;藥物研發加速庫 Clara Discovery 模型等產品,也側面印證了筆者的觀點,英偉達正在軟硬齊發為進軍云資料中心領域鋪平道路,

英偉達 CEO 黃仁勛,來源:NVIDIA GTC
無獨有偶,上周英特爾也發布了 10nm 的至強三代處理器,在新任 CEO 帕特.基辛格的帶領下,英特爾也要加強自身在云計算領域的優勢,不過在這場英特爾對陣英偉達的“雙英”大戰中,雙方的策略明顯不同,英特爾注重于全面,除了 AI 以外還在安全、虛擬化及調度能力以及存盤性能等等方面全線開花;但是英偉達則在專注于 AI 云及低功耗超級計算機幾個重要領域進行定點突破,
雖然目前還無法預測“雙英”大戰的結局,不過 AI 云計算的發展空間還是有目共睹的,從最新的 AI 發展趨勢來看,最新的人工智能模型對于算力的要求往往都是非常高,比如可以自動寫代碼的 GPT-3 其引數規模突破了 1000 億,而 GPT-3 的變種,可以將文字描述轉化為影像的跨模態生成模型 DALL.E,其模型引數數量更是達到了驚人的 1500 億,不少 AI 方面的科學家指出,越大的模型往往表現更好,擴大規模可能仍然是實作更好性能的方式,用黃仁勛在發布會上的話來說“三年間大規模預訓練模型的引數量增加了 3000 倍,我們估計在 2023 年會出現 100 萬億引數的模型,”目前資金實力一般的創業公司將越來越難以通過自身的算力去訓練最新、最好的 AI 模型,
從另一個角度講,AI 模型越來越大的趨勢也推進了 AI 與云的結合,只有充分發揮云計算降本增效的特性,才能降低門檻,促進 AI 行業創新性發展,也只有做好 AI 云,才能讓 AI 充分發揮威力,體現價值,我們看到本次英偉達圍繞著 AI 云計算,在 CPU、智能駕駛及配套軟體方面同都有不少的進展,接下來,本文將為大家逐一進行解讀,

Grace 打破記憶體與顯存之間的墻
由于 ARM 使用 RISC 風格的精簡指令集, ARM 核心在指令預測等方面同天然比 X86 更有優勢,能耗也比 X86 更低,當然這些都是 ARM 相對于 X86 的傳統優勢,本次 Grace 最大的創新點在于把 CPU 與 GPU 之間的通信速度提升了近 10 倍,根據黃仁勛的說法,“這是一萬名工程人員歷經幾年的研發成果,旨在滿足當前世界最先進應用程式的計算需求,其具備的計算性能和吞吐速率是以往任何架構所無法比擬的,”

CPU 和 GPU 的通信速度的重要性,可以用蘋果 M1 的例子來加以說明,我們知道蘋果 M1 顯卡與記憶體加在一起只有 16 個 G,對比上一代 Mac PRO 記憶體128G,光是顯存都有 16G,不過搭載 M1 的入門版 Mac 在進行影像處理等需要 CPU 與 GPU 進行協同的運算任務時,至少比上一代頂配的 Mac 性能高出近一倍,其中的秘決就是將記憶體與顯卡進行統一管理,從而大大提高了 CPU 與 GPU 的通信效率,
當然蘋果將記憶體與顯存混用的做法,在云計算這種多租戶共存的場景下并不太適用,但是現有 GPU 與 CPU 共享記憶體的做法效率確實不佳,在共享記憶體的方案下,CPU 和 GPU 必須輪流訪問記憶體,這就意味著他們要爭奪資料總線的使用權,因此 GPU 和 CPU 不得不輪流使用一個狹窄的通信管道來做資料交換,而英偉達的 Grace 在這方面做出了突破性的進展,
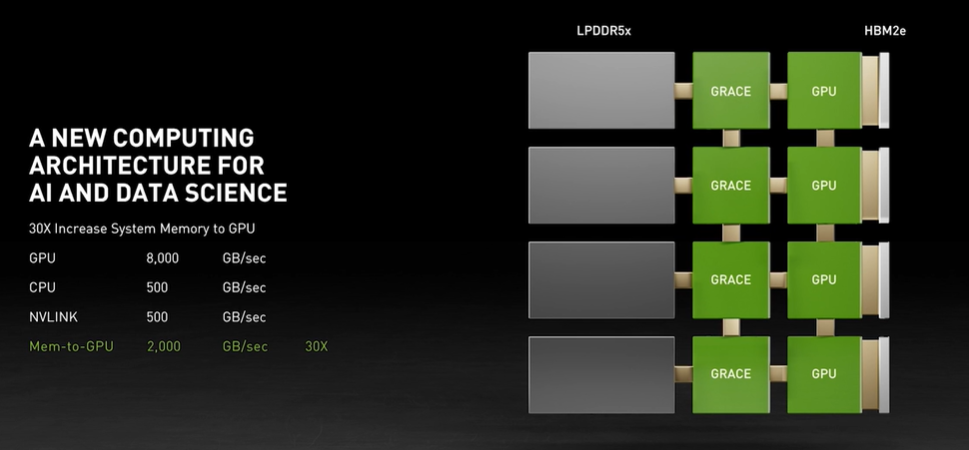
類似于 DMA 控制器在磁盤與記憶體之間搭建了一條快速通道一樣,Grace 體系中 GPU 核心與 CPU 核心之間的通信不需要 CPU 的調度,也不需要占用資料總線的帶寬,之前 CPU 必須將資料從其記憶體的區域復制到 GPU 使用的區域,而在 Grace 的加持下,CPU 只需要告訴GPU在記憶體的某位置有 30MB 的向量資料,然后就可以去做其它事了,GPU 則可以通過 Grace 復制通道迅速開始計算任務,
可以說 Grace 的快速能道基本還在筆者的射程范圍之內,而英偉達馬上要推出的 L5 級別自動駕駛芯片,就只能令人仰望了,

英偉達自動駕駛Orin-劍指L5的雄偉藍圖
鋼鐵俠馬斯克上周剛剛宣布特斯拉全新的自動駕駛系統 FSD Beta9.0 已經接近完成,有訊息稱 FSD 的自動駕駛能力要達到 L5 級,這真是一個震驚世界的訊息,因為目前特斯拉的 AutoPilot 還沒有達到 L3 的程度,
在業界公認的自動駕駛 L 級分類標準中,依據駕駛任務中 AI 與人類的角色分配以及有無設計運行條件限制等因素,將駕駛自動化分成 0 至 5 級,其中0級為應急輔助級在應急情況下幫助駕駛員進行輔助操作,在 0 級至 2 級自動駕駛中,監測路況并做出反應的任務都由駕駛員和系統共同完成,并需要駕駛員接管動態駕駛任務;3 級為有條件自動駕駛,4 級高度自動駕駛僅在特定條件下需要駕駛員參與;5 級完全自動駕駛的駕駛自動化系統在其設計運行條件內,能夠持續地執行全部動態駕駛任務和執行動態駕駛任務接管,駕駛員可以完全退化為乘客的角色,
L5 級別的自動駕駛看似不是從0到1的開創性作業,但從實踐上看,想真正實作全天候的自動駕駛難度極大,從谷歌的公開資料中我們可以知道一臺自動駕駛測驗車輛每天至少會產生10T的資料量,平均每分鐘都要處理幾百M的資料,而且自動駕駛的決策延時必須要控制得極低,汽車以80公里/小時的速度運行時其機械制動距離就接近30米,想保證安全留給自動駕駛的反應時間通常只有0.1秒,而且作何一點決策上的失誤都可能造成極其嚴重的后果,
簡單說 L5 級別的自動駕駛是一個每秒資料處理能力 1 個 G,資料處理延時不能超過0.1s,而且可靠性還不能低于 99.999999% 的極精密系統,再考慮其 AI 模型的上百億個引數,這個系統對于算力的要求是十分驚人的,不過更驚人的是黃仁勛表示英偉達就是要干這個,
根據計劃,英偉達將于 2022 年投產支持 L5 自動駕駛的汽車計算系統級芯片NVIDIA DRIVE Orin,與此同時英偉達還在發布會上展示了搭載 3 個 Orin 核心的 Hyperion 8 自動駕駛汽車平臺,據稱 Hyperion 8 是業內算力最強的自動駕駛汽車模板,當然這款芯片目前還沒有量產,也沒有具體細節的發布,因此筆者這里只能先對英偉達表示 Respect,

AI 軟體的背后:感知智能向認知智能的演進
從實作快速計算、記憶與存盤的“計算智能”,到識別處理語音、影像、視頻的“感知智能”,再到實作思考、理解、推理和解釋的“認知智能”,人工智能發展的終極目標是賦予機器人類的智慧,近年來,語音識別、人臉識別等“感知智能”技術已相對成熟,甚至在許多領域已經達到或超出了人類的水平,但這些技術僅在工具、模型層面實作了突破,對諸如需要專家知識、邏輯推理或者領域遷移等需要去思考、規劃、聯想、創作的復雜任務時,表現不佳,不過隨著大資料、云計算、深度學習等技術的蓬勃發展,探索在如何保持大資料智能優勢的同時,賦予機器常識和因果邏輯推理能力,實作“認知智能”,成為當下人工智能研究的核心,
從人機協作的角度上看,人類在處理抽象化、情緒化、非邏輯性的問題上有著不可逾越的優勢,而大量重復、海量計算和海量記憶則是人工智能的強項,而AI目前一個重要的發展方向就是讓人機兩者的強項聯合,取長補短,比如金融行業的呼叫中心需要分析客戶的語氣,在必要時引入人工服務;出行類 APP 遇到客戶說出某些關鍵詞時,則需要立刻與 110 人工報警臺聯動報警,這樣的大趨勢下也就更需要 AI 由單純的感知世界向認知世界去進行升級,我們看到阿里、騰訊的論文,近年來在 KDD 及 CVPR 這樣的 AI 頂會上獲得不俗的成績,多半也是源于對于認知智能的突破性貢獻,而英偉達本次推出的與 AI 系統對應的配套軟體中也順應了這一潮流,
本次發布的 Transformers 訓練框架 NVIDIA Megatron、Morpheus 資料中心安全平臺、新一代人工智能對話機器人 NVIDIA Jarvis、推薦系統是 NVIDIA Merlin、隱私保護加強的 AI 輔助套件 NVIDIA TAO,從本質上講都是認知智能的一種體現,
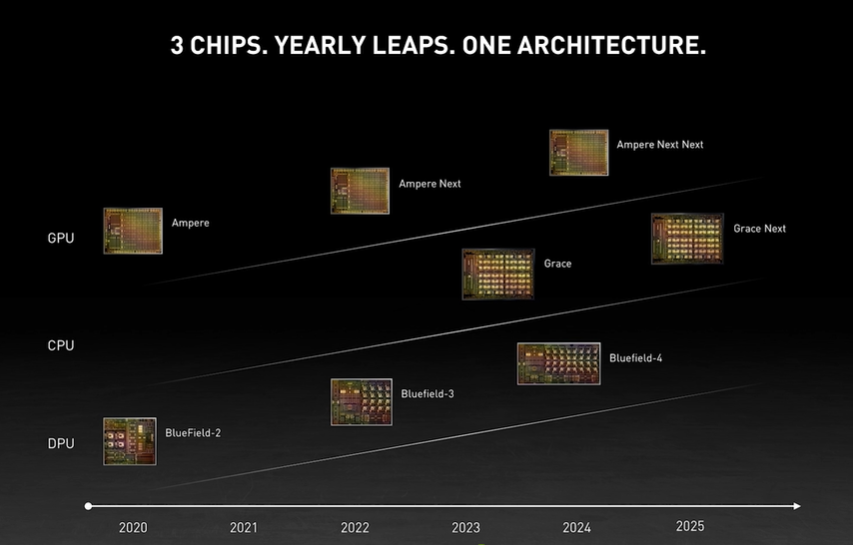
縱觀整場發布會,英偉達真可謂是 AI 與智能駕駛齊飛,CPU 與 GPU 跨界,新時代的計算機需要新的芯片、新的系統架構、新的網路、新的軟體和工具,英偉達全新的資料中心路線圖已包括 CPU、GPU 和 DPU 三類芯片,將英偉達也將被重新定義為三芯片公司,
2020-2021中國開發者調查報告重磅來襲,直接掃碼或微信搜索「CSDN」公眾號,后臺回復關鍵詞「開發者」,快速獲取完整的報告內容!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277458.html
標籤:AI
上一篇:藍橋杯軟體類競賽---手算題攻略
下一篇:十種方法實作影像資料集降維