論文《Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention》閱讀
- 論文概況
- Introduction
- Preliminaries
- Attentive Collaborative Filtering
- 總結
論文概況
這篇文章是新加坡國立大學何向南老師團隊關于推薦系統方向的一篇論文,提出基于item和component層面的多媒體注意力模型ACF,被SIGIR 2017錄用,文章主要聚焦在多媒體(視頻/影像)推薦和注意力兩方面,
本文的公式比較多,建議對照原文查看,這里只對文中的公式進行決議,建議對照原文查看,旨在節省各位同學的寶貴科研時間,方便同學快速了解ACF模型,
論文地址:ACF
代碼地址未公開
Introduction
本文應用場景是多媒體推薦,作者給出了在影像和視頻方面的推薦方案,
作者首先給出item和component的定義,item就是推薦場景中較常見的推薦物品;component在文中作者將其稱為影像的某塊區域或者視頻中的某一幀,
針對影像來說,使用CV屆比較知名的何凱明的ResNet-152模型res5c層的輸出作為影像特征,將772048轉為49*2048,也就是本文所說的component,共49個2048維不同區域構成了component,
針對視頻,同樣適用ResNet-152模型,將pool5層的輸出作為每一幀的特征,這里作者針對4.3節中所說的“ x l ? x_{l*} xl?? 代表每個不同item具有變長”也沒有進一步說明,但是批處理必須有定長,需要padding或者截斷,作者也沒有說明他們具體是如何操作的,歡迎評論區大家參與討論,
Preliminaries
這里作者介紹了BPR損失和平方差損失的區別,總結來說,針對implicit feedback場景,BPR表達能力更好一些,因為在資料集中標0的互動場景,不一定是user不喜歡這個item,也有可能是沒看到,
Attentive Collaborative Filtering
首先,本文的總體架構圖如下:
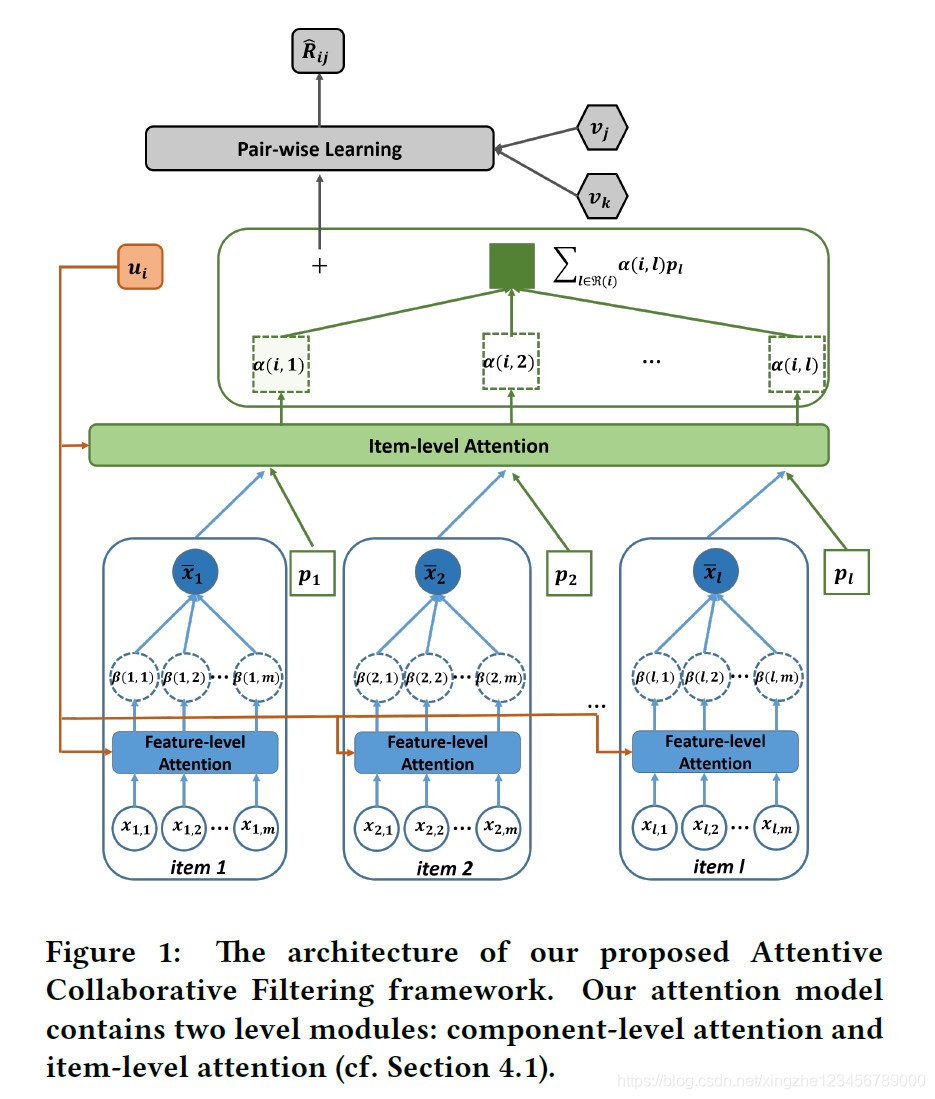
從這張圖可以看到,
u
u
u 、
v
v
v 、
p
p
p 分別表示用戶、item、item的輔助向量,都是latent vector,屬于learnable variables,向量
x
ˉ
\bar{x}
xˉ 表示注意力組合之后的各個component的總體表示,
公式(5)表示user和item之間的interaction模擬,使用BPR損失的方式完成,公式中使用 u i + ∑ l ∈ R ( i ) α ( i , l ) p l u_i+\sum\limits_{l\in\mathcal{R}(i)}\alpha(i,\ l)p_l ui?+l∈R(i)∑?α(i, l)pl? 表示用戶本身的latent vector 加上注意力加權的輔助vector,
公式(5)只有 α ( i , l ) \alpha(i,\ l) α(i, l) 是還沒有計算的,由公式(9)可知 α ( i , l ) \alpha(i,\ l) α(i, l) 是由 a ( i , l ) a(i,\ l) a(i, l) 通過softmax歸一化后得到的,
a ( i , l ) a(i,\ l) a(i, l) 由公式(8)可知,是由 u i u_i ui? 、 v l v_l vl? 、 p l p_l pl?、 x ˉ l \bar{x}_l xˉl? 共同決定的,公式(8)是component-level注意力的計算方法,通過這個兩層MLP層來計算,代表著用戶 u 對 物體 i 針對所有 組件(component)的注意之和, u i u_i ui? 、 v l v_l vl? 、 p l p_l pl?都是初始化后需要模型優化的引數,公式(8)的計算又落到了 x ˉ l \bar{x}_l xˉl? 的頭上,
由公式(12)可知, x ˉ l \bar{x}_l xˉl? 是component向量在component-level 注意力加權之和,
x l m x_{lm} xlm?是由ResNet-152學習到的輸入特征,其中, β ( i , l , m ) \beta(i,\ l,\ m) β(i, l, m) 代表用戶i 對 物體l 的 組成部分 m 的注意力,這個注意力 β ( i , l , m ) \beta(i,\ l,\ m) β(i, l, m)是通過 b ( i , l , m ) b(i,\ l,\ m) b(i, l, m) 經過softmax歸一化后得到的,而 b ( i , l , m ) b(i,\ l,\ m) b(i, l, m) ,由公式(10)可知,則是通過一個兩層的MLP計算得到的,輸入包括 u i u_i ui?, x l m x_{lm} xlm?,代表用戶 u 對 組成部分 x l m x_{lm} xlm? 的注意力大小,
總結
本文提出了基于item層和component層的Attention機制用于處理多媒體領域的推薦任務,提出了注意力協同過濾模型ACF,
本文總體架構圖畫得非常清晰,可以很清晰地了解整體架構,
一些個人觀點:本文符號表示稍微有點混亂,和主流文章符號不太相同,經常對錯號,同時文章對于component-level 和 item-level attention有一個empirical的介紹,但是具體為什么選用2層MLP進行計算沒有進行解釋,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277482.html
標籤:其他