萌新篇 —從零開始搭建自己的大資料環境
文章目錄
- 萌新篇 —從零開始搭建自己的大資料環境
- 前言
- 一、hive簡介
- 二、hive的優點
- 3、配置hive
- 1.hive-env.sh.template和hive-log4j.properties.template修改名稱
- 2.hive-env.sh配置
- 3.hive-log4j.properties配置
- 4、在hdfs創建hive目錄
- 5、啟動
- 4、Hive與MySQL集成
- 1、在conf檔案中是創建hive-site.xml,填入
- 2、設定用戶的鏈接
- 3、啟動測驗
- 5、Hive與hbase集成
- 1、配置hive-site.xml
- 2、進入lib目錄
- 3、創建與HBase集成的Hive的表
- 總結
前言
我事先創建好了opt檔案,該檔案里包含data,modules,software,tools,一般我把安裝包存放在sofeware解壓生成在modules,可以按照我這個方式去做,后期以便檔案好找,mysql和hbase安裝參考我前面的文章,這里就不是范例,程序使用的軟體Notepad++(在這里修改組態檔比較方便)MobaXterm_Personal_20.2(遠程登錄linux)FlashFPX(把檔案發送到linux上),
一、hive簡介
hive是基于Hadoop的一個資料倉庫工具,用來進行資料提取、轉化、加載,這是一種可以存盤、查詢和分析存盤在Hadoop中的大規模資料的機制,hive資料倉庫工具能將結構化的資料檔案映射為一張資料庫表,并提供SQL查詢功能,能將SQL陳述句轉變成MapReduce任務來執行,Hive的優點是學習成本低,可以通過類似SQL陳述句實作快速MapReduce統計,使MapReduce變得更加簡單,而不必開發專門的MapReduce應用程式,hive十分適合對資料倉庫進行統計分析,
hive不適合用于聯機(online)事務處理,也不提供實時查詢功能,它最適合應用在基于大量不可變資料的批處理作業,hive的特點包括:可伸縮(在Hadoop的集群上動態添加設備)、可擴展、容錯、輸入格式的松散耦合,
二、hive的優點
1、避免了去寫 MapReduce,減少開發人員的學習成本
2、統一的元資料管理,可與 impala/ spark等共享元資料
3、易擴展(HDFS+ MapReduce:可以擴展集群規模;支持自定義函式)
4、資料的離線處理;比如:日志分析,海量結構化資料離線分析
5、Hive的執行延遲比較高,因此hve常用于資料分析的,對實時性要求不高的場合
6、Hive優勢在于處理大資料,對于處理小資料沒有優勢,因為Hive的執行延遲比較高
更詳細簡介,點這里
hive和hbase的區別
3、配置hive
1.hive-env.sh.template和hive-log4j.properties.template修改名稱
去掉.template
2.hive-env.sh配置
HADOOP_HOME=/opt/modules/hadoop 找到本機hadoop的位置pwd復制上去
export HIVE_CONF_DIR=/opt/modules/hive/conf
3.hive-log4j.properties配置
mkdir logs 在hive目錄下創建一個logs
cd logs
pwd 復制路徑
hive.log.dir=/opt/modules/hive-0.13.1-bin/logs
代碼如下(示例):
4、在hdfs創建hive目錄
1、bin/hdfs dfs -mkdir -p /user/hive/warehouse
2、bin/hdfs dfs -chmod g+w /user/hive/warehouse
3、bin/hdfs dfs -mkdir /tmp
4、bin/hdfs dfs -chmod g+w /tmp
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
5、啟動
bin/hive

4、Hive與MySQL集成
1、在conf檔案中是創建hive-site.xml,填入
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://panda-pro01.xiong.com/metastore?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.otion.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
2、設定用戶的鏈接
打開mysql:mysql -uroot -p123456
1、show databases;
2、use mysql;
3、show tables;
4、select host,user,authentication_string from user;
更新資訊
update user set Host='%' where User = 'root' and Host = 'localhost';
洗掉資訊
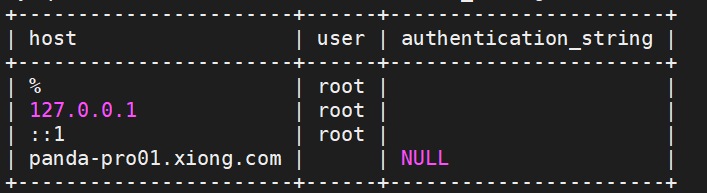
1、delete from user where user='root' and host='panda-pro01.xiong.com';
2、delete from user where user='root' and host='127.0.0.1';
3、delete from user where user='root' and host='::1';
4、select user,host,password from user;
洗掉后只剩

重繪資訊
flush privileges;
拷貝mysql-connector-java-5.1.48.jar到hive目錄下的lib中
下載地址
3、啟動測驗
首先啟動hdfs和yarn服務
1、創建一個資料檔案內容隨便寫,格式如下
0001 hadoop
0002 java
0003 yarn
0004 spark
2、啟動hive創建表
create table test(id int,name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
3、把檔案加載到表中
load data local inpath '/opt/datas/test.txt' into table text;
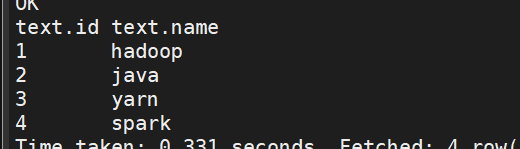
4、結果如下(select * from text)
5、提交任務給yarn
select count(1) from text;
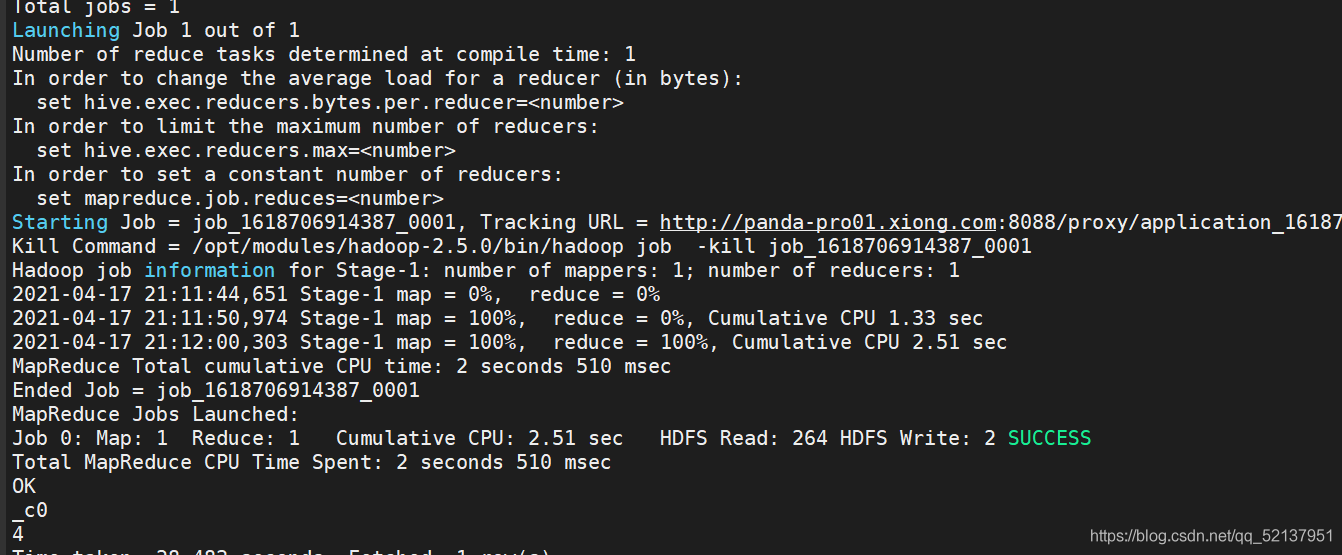
可以在yarn的web界面看到

5、Hive與hbase集成
1、配置hive-site.xml
<property>
<name>hbase.zookeeper.quorum</name>
<value>panda-pro01.xiong.com,panda-pro02.xiong.com,panda-pro03.xiong.com</value>
</property>
2、進入lib目錄
export HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2
export HIVE_HOME=/opt/modules/hive-0.13.1-bin/lib
-----------------不同版本號對應不同jar包,注意修改---------------------------------
ln -s $HBASE_HOME/lib/hbase-server-0.98.6-hadoop2.jar $HIVE_HOME/hbase-server-0.98.6-hadoop2.jar
ln -s $HBASE_HOME/lib/hbase-client-0.98.6-hadoop2.jar $HIVE_HOME/hbase-client-0.98.6-hadoop2.jar
ln -s $HBASE_HOME/lib/hbase-protocol-0.98.6-hadoop2.jar $HIVE_HOME/hbase-protocol-0.98.6-hadoop2.jar
ln -s $HBASE_HOME/lib/hbase-it-0.98.6-hadoop2.jar $HIVE_HOME/hbase-it-0.98.6-hadoop2.jar
ln -s $HBASE_HOME/lib/htrace-core-2.04.jar $HIVE_HOME/htrace-core-2.04.jar
ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-0.98.6-hadoop2.jar $HIVE_HOME/hbase-hadoop2-compat-0.98.6-hadoop2.jar
ln -s $HBASE_HOME/lib/hbase-hadoop-compat-0.98.6-hadoop2.jar $HIVE_HOME/hbase-hadoop-compat-0.98.6-hadoop2.jar
ln -s $HBASE_HOME/lib/high-scale-lib-1.1.1.jar $HIVE_HOME/high-scale-lib-1.1.1.jar
ln -s $HBASE_HOME/lib/hbase-common-0.98.6-hadoop2.jar $HIVE_HOME/hbase-common-0.98.6-hadoop2.jar
3、創建與HBase集成的Hive的表
hive (default)> CREATE EXTERNAL TABLE weblogs(
> id string,
> datatime string,
> userid string,
> searchname string,
> retorder string,
> cliorder string,
> cliurl string
> )
> STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
> WITH SERDEPROPERTIES (
> "hbase.columns.mapping" =
> ":key,info:datatime,info:userid,info:searchname,info:retorder,info:cliorder,info:cliurl")
> TBLPROPERTIES ("hbase.table.name" = "weblogs");
總結
關于hive基本配置就到這里了,作者萌新一位,如有不足之處還請見諒,如對你有幫助,點一點關注,謝謝咯,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277483.html
標籤:其他
上一篇:論文《Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Componet-Level ...》閱讀
下一篇:關于離線開發平臺的優化思路