這周二應CSDN的友人約稿,我寫了一篇有關英偉達的首款CPU芯片Grace的文章叫板英特爾,英偉達集齊“三芯”,而話音未落人民日報就發布了龍芯的訊息《國產CPU歷史性跨越:龍芯推出自主指令系統架構》

不過由于筆者也并沒見到過搭建龍芯3號實物主機,因此只能從龍芯官方的材料中盡量解讀出一些干貨內容,供讀者們參考,
青出于藍而勝于藍,那些年MIPS教給龍芯的事
龍芯的全新自主知識產要指令集LA64,雖然目前已經演化出自己的風格了,但是LA64與MIPS之間的繼承關系還是非常明顯的,MIPS(Microprocessor without interlocked pipelined stages),中文翻譯是“無內部互鎖流水級的微處理器”,其關鍵思想是盡量利用軟體辦法避免流水線中的問題,而不使用硬體鎖,后面我們也會介紹龍芯本次有一個創新點就是取消了延時指令槽,不過延時槽的提出在二三十年前還是非常依靠的,
1981年斯坦福大學的第十任校長,馮諾依曼獎與圖靈獎的雙料得主,約翰·軒尼詩教授做出了世界第一款MIPS架構的處理器,現在軒尼詩教授又成了谷歌母公司Alphabet的董事長,能力水平業界公認,而且還有一點鮮為人知的優點,就是桃李滿天下,現任英特爾CEO帕特.基辛格在斯坦福念研究生時,當時的導師就是軒尼詩教授,可以說這是一位穩進計算機歷史前五名的大神級人物,
沒有爭議,MIPS世界上第一款真正實踐了精簡指令思想的處理器,上個月才將MIPS收入麾下的RISC-V,可是直到30年后的2010年才誕生,而與MIPS同場競技三十年的ARM,也是直到4年后才問世,
后來MIPS先打入了Play Station,性能強悍被人廣傳頌,后來又在作業站也就是目前我們所說的服務器領域大顯身手,1997年NEC的超算Cenju-4是MIPS的巔峰之作,這款超算具有很多非常超前的設計,而MIPS就是他的核心,

為應對MIPS系列芯片帶來的沖擊,2000年左右的英特爾上來推出Intel Architecture 64架構的安騰(Itanium)系列服務器級CPU,我們知道由于歷史原因X86系列的CPU始終都要保持向后兼容,也就是為286撰寫的程式,也要能完美運行在486上,不過286是16位而486卻是32位,讓兩個位長都不一樣的CPU運行同樣的程式,還不出問題,這可真是難為英特爾的程式員了,X86系列CPU經常要在各種保護模式、實模式之間來回橫跳,沒有過硬的技術功底,想弄明白X86的系統是如何加載引導的都十分困難,
不過正如龍芯在他們的宣傳材料中提到的一樣,安騰架構目前已經失敗了,同一家公司的指令集如果不能前后兼容,那后果是災難性的,因此我們看到龍芯沒有放棄與MIPS兼容,甚至推出了二進制轉譯指令集,以支持將MIPS、Arm、及X86的應用,全部翻譯成龍芯的指令,并使之性能為達到原生程式的100%、90%、80% 以上,
在了解到這點以后,下面筆者借龍芯本次宣傳材料上公開的匯編代碼,與對應的ARM代碼進行對照,帶大家近距離了解一下龍芯,
龍芯64近距離接觸
在本次龍芯的發布材料中公開了以下代碼
Int a;
Int test(void){
Return a;
}對應的匯編語言,
為了讓大家更好的理解龍芯的指令集,筆者在華為的鯤鵬平臺上用ARM版本的gcc編譯了上述代碼,
1.首先安裝反匯編工具 objdump命令如下:
yum install -y binutils2. 撰寫源檔案test.c,輸入以下內容
Int a;
Int test(void){
return a;
}3. 編譯.a庫檔案
aarch64-redhat-linux-gcc -g -o test test.c4. 查看對應匯編檔案
objdump -S test對應代碼如下:
00000000 <test>:
int a;
int test(void)
{return a;}
0: e52db004 push {fp} ; (str fp, [sp, #-4]!)
4: e28db000 add fp, sp, #0
8: e59f3010 ldr r3, [pc, #16] ; 20 <test+0x20>
c: e5933000 ldr r3, [r3]
10: e1a00003 mov r0, r3
14: e28bd000 add sp, fp, #0
18: e49db004 pop {fp} ; (ldr fp, [sp], #4)
1c: e12fff1e bx lr
20: 00000000 .word 0x00000000以上的匯編語言大致程序決議如下:
首先是push {fp} ; (str fp, [sp, #-4]!),其中SP是堆疊暫存器,首先將堆疊頂向上(sp-4)的地址傳給fp然后將fp入堆疊,接下來進行通過add fp, sp, #0進行sp的設定,再把r3傳給pc后的16位地址,mov r0,r3其中就是return a了,add sp, fp, #0和pop {fp} ; (ldr fp, [sp], #4)其實是開頭堆疊禎設定的反向操作,也就是恢復了呼叫現場,
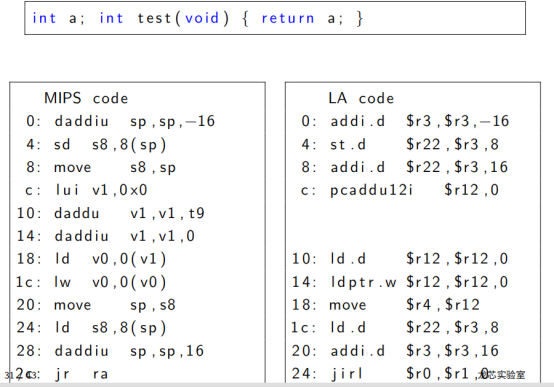
這段c代碼對應的龍芯匯編語言代碼如下:
LA code
0 : addi . d $r3 , $r3 ,?16
4 : s t . d $r22 , $r3 , 8
8 : addi . d $r22 , $r3 ,16
c : pcaddu12i $r12 , 0
10: l d . d $r12 , $r12 , 0
14: l d p t r .w $r12 , $r12 , 0
18: move $r4 , $r12
1c : l d . d $r22 , $r3 , 8
20: addi . d $r3 , $r3 ,16
24: j i r l $r0 , $r1 , 0根據龍芯的官方檔案其R3暫存器就是 sp暫存器,R22就是fp暫存器,因此其實作邏輯可以說既保持了與MIPS兼容又吸引了其它RISC風格的優點,而且MIPS在指令空間也真算是精打細算,為今后擴展到一些其它比如SIMD類的指令集做好準備,

繼承、優化、升級
根據龍芯的介紹,我們看到龍芯其它的儲保持RISC風格、更多可用暫存器等特點在沒看到實物之前我都很難評價,唯一可以說的是取消了延時指令槽,這可能是一個比較獨特的點,

而延時指令槽的產生要從指令流水線說起,一般來說想要執行一潭訓器指令,需要將任務分解成取指、譯碼、取運算元、執行以及取操作結果等若干步驟,而每個步驟都需要一次晶體震蕩才能推進,因此在流水線技術出現之前執行一條指令至少需要5到6次晶體震蕩周期才能完成

那么針對這樣的問題芯片設計人員就提出了參考工廠流水線機制的想法,因為取指、譯碼這些模塊其實都是獨立的,完成可以在同一時刻并行手,那么只要將多條指令的相關步驟放在同一時刻執行,比如指令1取指,指令2譯碼,指令3取運算元等等步驟同時執行,
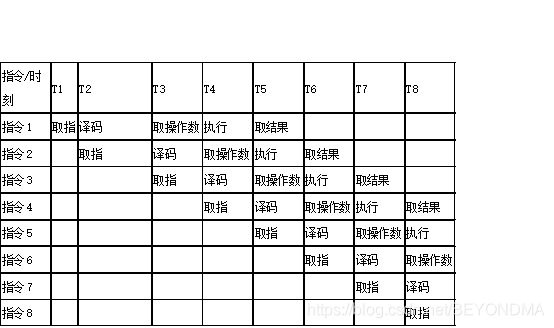
只要指令流水線就建立成型,自此以后每個震蕩周期T,都可以取到一個指令的結果了,也就是說平均每條指令就只需要一個震蕩周期就可以完成,這樣就能大幅提升CPU的運算速度,不過這也有一個缺點,就是要求CPU必須知道每條指令的執行順序,如果預測錯了流水線上某一條指令的執行順序,那么指令流水線上就會產生大量氣泡,如下圖:
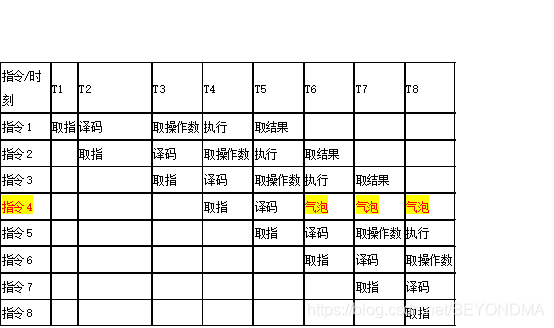
比如CPU在T6時刻發現指令4不應該被執行,那么T6到T8有關指令4的相關操作就會變成氣泡一樣的廢操作,從而大幅度降低CPU的執行效率,
而MIPS的延時槽所要做的就是分析指令間的關聯關系,在跳轉指令時,找出一條不受判斷跳轉影響的指令來執行,比如以下代碼中int b=0就是一條典型的與接下來的條件判斷沒有關系的,
Int test(void){
Int b=0//條件跳轉無關代碼
If (a>0){
//Do some thing without b;
}
else{
//Do some thing else with out b;
}在MIPS中盡可能用延時槽指令填充流水線以避免氣泡過多產生,不過我們看到現代CPU的方案在分支預測上已經有了長足的進步,包括c語言中也提供了likely修飾符來幫助CPU進行分支預測,用likely修飾符不改變任何邏輯,只是告訴CPU本分支被執行的可能很大,因此目前延時槽已經有點廢操作的感覺了,龍芯把這塊拿掉可以說是恰逢其時吧,
以上就是我能Get到的一些關鍵資訊,不一定準確僅供參考,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277660.html
標籤:其他