Hbase介紹
hbase是bigtable的開源java版本,是建立在hdfs之上,提供高可靠性、高性能、列存盤、可伸縮、實時讀寫nosql的資料庫系統,
它介于nosql和RDBMS之間,僅能通過主鍵(row key)和主鍵的range來檢索資料,僅支持單行事務(可通過hive支持來實作多表join等復雜操作),
主要用來存盤結構化和半結構化的松散資料,
Hbase查詢資料功能很簡單,不支持join等復雜操作,不支持復雜的事務(行級的事務)
Hbase中支持的資料型別:byte[]
與hadoop一樣,Hbase目標主要依靠橫向擴展,通過不斷增加廉價的商用服務器,來增加計算和存盤能力,
HBase中的表一般有這樣的特點:
大:一個表可以有上十億行,上百萬列
面向列:面向列(族)的存盤和權限控制,列(族)獨立檢索,
稀疏:對于為空(null)的列,并不占用存盤空間,因此,表可以設計的非常稀疏,
結構圖如下:
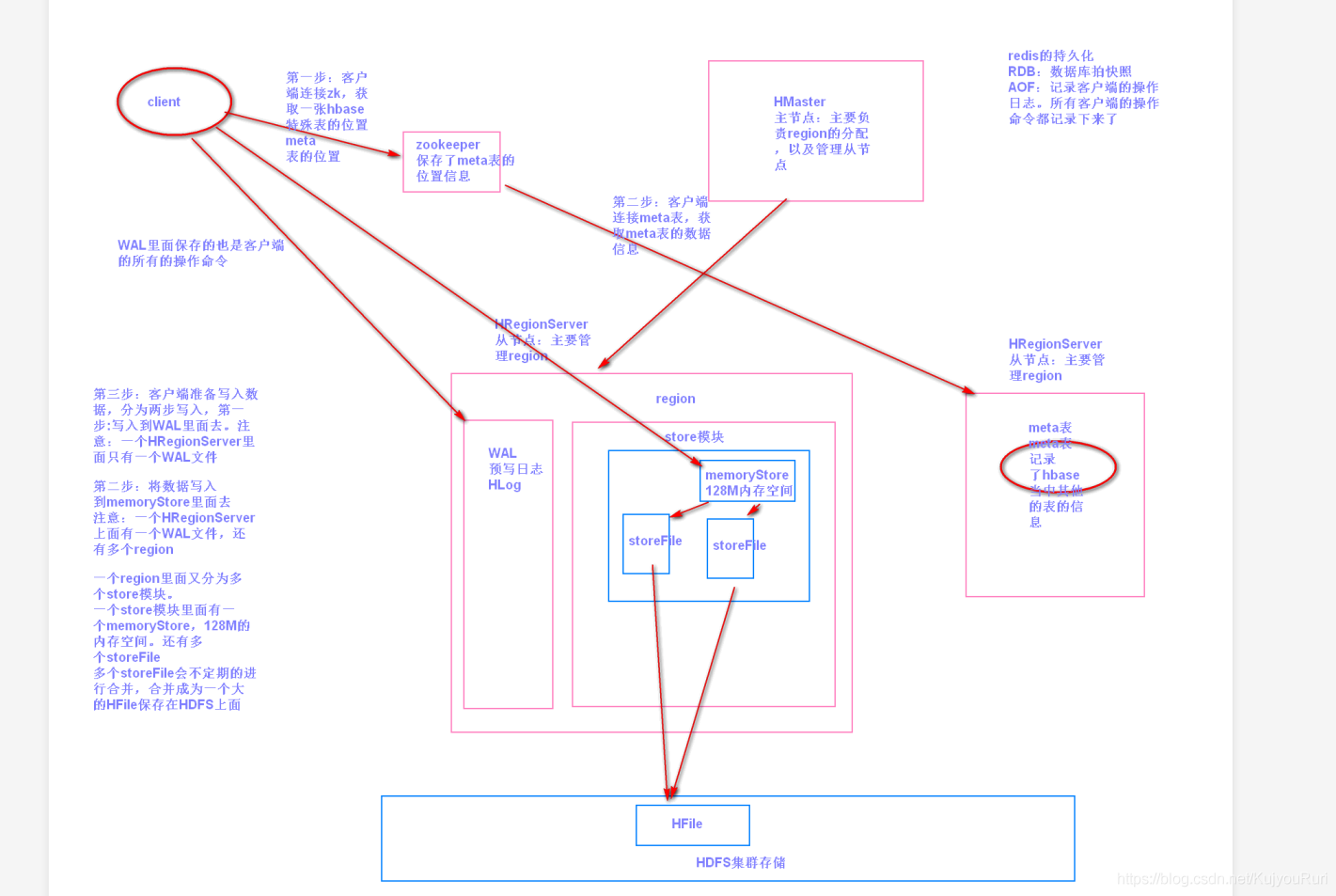
HMaster
功能:
- 監控RegionServer
- 處理RegionServer故障轉移
- 處理元資料的變更
- 處理region的分配或移除
- 在空閑時間進行資料的負載均衡
- 通過Zookeeper發布自己的位置給客戶端
RegionServer
功能:
1) 負責存盤HBase的實際資料
2) 處理分配給它的Region
3) 重繪快取到HDFS
4) 維護HLog
5) 執行壓縮
6) 負責處理Region分片
組件:
- Write-Ahead logs
HBase的修改記錄,當對HBase讀寫資料的時候,資料不是直接寫進磁盤,它會在記憶體中保留一段時間(時間以及資料量閾值可以設定),但把資料保存在記憶體中可能有更高的概率引起資料丟失,為了解決這個問題,資料會先寫在一個叫做Write-Ahead logfile的檔案中,然后再寫入記憶體中,所以在系統出現故障的時候,資料可以通過這個日志檔案重建, - HFile
這是在磁盤上保存原始資料的實際的物理檔案,是實際的存盤檔案, - Store
HFile存盤在Store中,一個Store對應HBase表中的一個列族, - MemStore
顧名思義,就是記憶體存盤,位于記憶體中,用來保存當前的資料操作,所以當資料保存在WAL中之后,RegsionServer會在記憶體中存盤鍵值對, - Region
Hbase表的分片,HBase表會根據RowKey值被切分成不同的region存盤在RegionServer中,在一個RegionServer中可以有多個不同的region,
Hbase的搭建
注意事項:HBase強依賴zookeeper和hadoop,安裝HBase之前一定要保證zookeeper和hadoop啟動成功,且服務正常運行
第一步:下載對應的HBase的安裝包
所有關于CDH版本的軟體包下載地址如下
http://archive.cloudera.com/cdh5/cdh/5/
HBase對應的版本下載地址如下
http://archive.cloudera.com/cdh5/cdh/5/hbase-1.2.0-cdh5.14.0.tar.gz
第二步:壓縮包上傳并解壓
將我們的壓縮包上傳到node01服務器的/export/softwares路徑下并解壓
cd /export/softwares/
tar -zxvf hbase-1.2.0-cdh5.14.0.tar.gz -C ../servers/
第三步:修改組態檔
第一臺機器進行修改組態檔
cd /export/servers/hbase-1.2.0-cdh5.14.0/conf
修改第一個組態檔hbase-env.sh
注釋掉HBase使用內部zk
vim hbase-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
export HBASE_MANAGES_ZK=false
修改第二個組態檔hbase-site.xml
修改hbase-site.xml
vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node01:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新變動,之前版本沒有.port,默認埠為60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/servers/zookeeper-3.4.5-cdh5.14.0/zkdatas</value>
</property>
</configuration>
修改第三個組態檔regionservers
vim regionservers
node01
node02
node03
創建back-masters組態檔,實作HMaster的高可用
cd /export/servers/hbase-1.2.0-cdh5.14.0/conf
vim backup-masters
node02
第四步:安裝包分發到其他機器
將我們第一臺機器的hbase的安裝包拷貝到其他機器上面去
cd /export/servers/
scp -r hbase-1.2.0-cdh5.14.0/ node02:$PWD
scp -r hbase-1.2.0-cdh5.14.0/ node03:$PWD
第五步:三臺機器創建軟連接
因為hbase需要讀取hadoop的core-site.xml以及hdfs-site.xml當中的組態檔資訊,所以我們三臺機器都要執行以下命令創建軟連接
ln -s /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/core-site.xml /export/servers/hbase-1.2.0-cdh5.14.0/conf/core-site.xml
ln -s /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml /export/servers/hbase-1.2.0-cdh5.14.0/conf/hdfs-site.xml
第六步:三臺機器添加HBASE_HOME的環境變數
vim /etc/profile
export HBASE_HOME=/export/servers/hbase-1.2.0-cdh5.14.0
export PATH=:$HBASE_HOME/bin:$PATH
第七步:HBase集群啟動
第一臺機器執行以下命令進行啟動
cd /export/servers/hbase-1.2.0-cdh5.14.0
bin/start-hbase.sh
警告提示:HBase啟動的時候會產生一個警告,這是因為jdk7與jdk8的問題導致的,如果linux服務器安裝jdk8就會產生這樣的一個警告,我們可以只是掉所有機器的hbase-env.sh當中的“HBASE_MASTER_OPTS”和“HBASE_REGIONSERVER_OPTS”配置 來解決這個問題,不過警告不影響我們正常運行,可以不用解決

我們也可以執行以下命令單節點進行啟動
啟動HMaster命令
bin/hbase-daemon.sh start master
啟動HRegionServer命令
bin/hbase-daemon.sh start regionserver
為了解決HMaster單點故障問題,我們可以在node02和node03機器上面都可以啟動HMaster節點的行程,以實作HMaster的高可用
bin/hbase-daemon.sh start master
第七步:頁面訪問
瀏覽器頁面訪問
http://node01:60010/master-status
HBase常用shell操作
1、進入HBase客戶端命令操作界面
$ bin/hbase shell
2、查看幫助命令
hbase(main):001:0> help
3、查看當前資料庫中有哪些表
hbase(main):002:0> list
4、創建一張表
創建user表,包含info、data兩個列族
hbase(main):010:0> create 'user', 'info', 'data'
或者
hbase(main):010:0> create 'user', {NAME => 'info', VERSIONS => '3'},{NAME => 'data'}
5、添加資料操作
向user表中插入資訊,row key為rk0001,列族info中添加name列標示符,值為xialaoshi
hbase(main):011:0> put 'user', 'rk0001', 'info:name', 'xialaoshi'
向user表中插入資訊,row key為rk0001,列族info中添加gender列標示符,值為male
hbase(main):012:0> put 'user', 'rk0001', 'info:gender', 'male'
向user表中插入資訊,row key為rk0001,列族info中添加age列標示符,值為25
hbase(main):013:0> put 'user', 'rk0001', 'info:age', 25
向user表中插入資訊,row key為rk0001,列族data中添加pic列標示符,值為text
hbase(main):014:0> put 'user', 'rk0001', 'data:pic', 'text'
6、查詢資料操作
1、通過rowkey進行查詢
獲取user表中row key為rk0001的所有資訊
hbase(main):015:0> get 'user', 'rk0001'
2、查看rowkey下面的某個列族的資訊
獲取user表中row key為rk0001,info列族的所有資訊
hbase(main):016:0> get 'user', 'rk0001', 'info'
3、查看rowkey指定列族指定欄位的值
獲取user表中row key為rk0001,info列族的name、age列標示符的資訊
hbase(main):017:0> get 'user', 'rk0001', 'info:name', 'info:age'
4、查看rowkey指定多個列族的資訊
獲取user表中row key為rk0001,info、data列族的資訊
hbase(main):018:0> get 'user', 'rk0001', 'info', 'data'
或者
hbase(main):019:0> get 'user', 'rk0001', {COLUMN => ['info', 'data']}
或者
hbase(main):020:0> get 'user', 'rk0001', {COLUMN => ['info:name', 'data:pic']}
指定rowkey與列值查詢
獲取user表中row key為rk0001,cell的值為zhangsan的資訊
hbase(main):030:0> get 'user', 'rk0001', {FILTER => "ValueFilter(=, 'binary:zhangsan')"}
指定rowkey與列值模糊查詢
獲取user表中row key為rk0001,列標示符中含有a的資訊
hbase(main):031:0> get 'user', 'rk0001', {FILTER => "(QualifierFilter(=,'substring:a'))"}
插入一批資料
hbase(main):032:0> put 'user', 'rk0002', 'info:name', 'fanbingbing'
hbase(main):033:0> put 'user', 'rk0002', 'info:gender', 'female'
hbase(main):034:0> put 'user', 'rk0002', 'info:nationality', '中國'
6、查詢所有資料
查詢user表中的所有資訊
scan 'user'
7、列族查詢
查詢user表中列族為info的資訊
scan 'user', {COLUMNS => 'info'}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 5}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 3}
8、多列族查詢
查詢user表中列族為info和data的資訊
scan 'user', {COLUMNS => ['info', 'data']}
scan 'user', {COLUMNS => ['info:name', 'data:pic']}
9、指定列族與某個列名查詢
查詢user表中列族為info、列標示符為name的資訊
scan 'user', {COLUMNS => 'info:name'}
10、指定列族與列名以及限定版本查詢
查詢user表中列族為info、列標示符為name的資訊,并且版本最新的5個
scan 'user', {COLUMNS => 'info:name', VERSIONS => 5}
11、指定多個列族與按照資料值模糊查詢
查詢user表中列族為info和data且列標示符中含有a字符的資訊
scan 'user', {COLUMNS => ['info', 'data'], FILTER => "(QualifierFilter(=,'substring:a'))"}
12、rowkey的范圍值查詢
查詢user表中列族為info,rk范圍是[rk0001, rk0003)的資料
scan 'people', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'}
13、指定rowkey模糊查詢
查詢user表中row key以rk字符開頭的
scan 'user',{FILTER=>"PrefixFilter('rk')"}
14、指定資料范圍值查詢(時間戳)
查詢user表中指定范圍的資料
scan 'user', {TIMERANGE => [1392368783980, 1392380169184]}
7、更新資料操作
1、更新資料值
更新操作同插入操作相同,利用put,只不過有資料就更新,沒資料就添加
1、更新版本號
將user表的info版本號改為5
hbase(main):050:0> alter 'user', NAME => 'info', VERSIONS => 5
8、洗掉資料以及洗掉表操作
1、指定rowkey以及列名進行洗掉
洗掉user表row key為rk0001,列標示符為info:name的資料
hbase(main):045:0> delete 'user', 'rk0001', 'info:name'
2、指定rowkey,列名以及欄位值進行洗掉
洗掉user表row key為rk0001,列標示符為info:name,timestamp為1392383705316的資料
hbase(main):045:0>delete 'user', 'rk0001', 'info:name', 1392383705316
3、洗掉一個列族
洗掉一個列族:
hbase(main):045:0>alter 'user', NAME => 'f1', METHOD => 'delete'
或
alter 'user', 'delete' => 'f1'
4、清空表資料
hbase(main):017:0> truncate 'user'
5、洗掉表
首先需要先讓該表為disable狀態,使用命令:
hbase(main):049:0> disable 'user'
然后才能drop這個表,使用命令:
hbase(main):050:0> drop 'user'
(注意:如果直接drop表,會報錯:Drop the named table. Table must first be disabled)
9、統計一張表有多少行資料
hbase(main):053:0> count 'user'
HBase的高級shell管理命令
1、status
例如:顯示服務器狀態
hbase(main):058:0> status 'node01'
2、whoami
顯示HBase當前用戶,例如:
hbase(main):058:0> whoami
3、list
顯示當前所有的表
4、count
統計指定表的記錄數,例如:
hbase> count 'hbase_book'
5、describe
hbase(main):058:0> describe 'table_name'
展示表結構資訊
6、exist
檢查表是否存在,適用于表量特別多的情況
hbase(main):058:0> exist 'table_name'
7、is_enabled、is_disabled
檢查表是否啟用或禁用
8、alter
該命令可以改變表和列族的模式,例如:
為當前表增加列族:
hbase> alter 'hbase_book', NAME => 'CF2', VERSIONS => 2
為當前表洗掉列族:
hbase(main):002:0> alter 'hbase_book', 'delete' => 'CF2'
9、disable
禁用一張表
hbase(main):002:0> disable 'table_name'
10、drop
洗掉一張表,記得在洗掉表之前必須先禁用
hbase(main):002:0> drop 'table_name'
11、truncate
禁用表-洗掉表-創建表
hbase(main):002:0> truncate 'table_name'
Hbase中JAVA API的撰寫使用
熟練掌握通過使用java代碼實作HBase資料庫當中的資料增刪改查的操作,特別是各種查詢,熟練運用
第一步:創建maven工程,匯入jar包
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*/RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
源代碼部分:
需求一:創建myuser表,帶有f1 和f2兩個列族
import com.sun.org.apache.bcel.internal.generic.NEW;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.Test;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class HBaseFirst {
@Test
public void createTable() throws IOException {
//連接hbase的服務端
Configuration configuration = HBaseConfiguration.create();
//設定hbase連接zk的地址
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
//獲取hbase資料庫連接物件 通信三要素:ip地址,埠號,傳輸協議
Connection connection = ConnectionFactory.createConnection(configuration);
//獲取管理員的物件,這個物件就是用于創建表,洗掉表等等
Admin admin = connection.getAdmin();
//創建一個表最少需要兩個條件,表名和列族名
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("myuser"));
//給表設定列族名
HColumnDescriptor f1 = new HColumnDescriptor("f1");
HColumnDescriptor f2 = new HColumnDescriptor("f2");
hTableDescriptor.addFamily(f1);
hTableDescriptor.addFamily(f2);
//創建表操作
admin.createTable(hTableDescriptor);
admin.close();
connection.close();
//獲取連接物件,來創建表操作
}
private Connection connection;
private Table table ;
獲取我們的表:
@BeforeTest
public void init() throws IOException {
//連接hbase集群
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
connection = ConnectionFactory.createConnection(configuration);
//獲取我們的表
table = connection.getTable(TableName.valueOf("myuser"));
}
向myuser表當中添加資料(hbase當中插入和更新是一樣的操作,如果rowkey不存在,那么就插入,如果rowkey存在,那么就更新)
@Test
public void addData() throws IOException {
//向表當中添加資料
//put 'user','rk0001','info:name','zhangsan'
//創建put物件,并指定rowkey
Put put = new Put("0001".getBytes());
put.addColumn("f1".getBytes(),"id".getBytes(), Bytes.toBytes(1));
put.addColumn("f1".getBytes(),"name".getBytes(), Bytes.toBytes("張三"));
put.addColumn("f1".getBytes(),"age".getBytes(), Bytes.toBytes(18));
put.addColumn("f2".getBytes(),"address".getBytes(), Bytes.toBytes("下北澤"));
put.addColumn("f2".getBytes(),"phone".getBytes(), Bytes.toBytes("1145141919810"));
//將我們構建好的put物件出入進去,就可以保存到hbase里面去了
table.put(put);
}
如果有多個鍵值插入新值,可以用list集合來更新或者插入:
List<Put> listPut = new ArrayList<Put>();
listPut.add(put);
listPut.add(put2);
listPut.add(put3);
listPut.add(put4);
listPut.add(put5);
listPut.add(put6);
myuser.put(listPut);
myuser.close();
}
查詢rowkey為0003的人
@Test
public void getDataByRowKey() throws IOException {
//獲取連接
//獲取對應的表
Get get = new Get(Bytes.toBytes("0003"));
//通過get來獲取資料 result里面封裝了我們的結果資料
Result result = table.get(get);
//列印結果資料.獲取這條資料所有的cell
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
//獲取列族名
byte[] family = cell.getFamily();
//獲取列名
byte[] qualifier = cell.getQualifier();
//獲取列值
byte[] value = cell.getValue();
String s1 = new String(family);
java.lang.String familyName = Bytes.toString(family);
//判斷,如果是id列和age列,轉換成為int型別輸出
if("f1".equals(familyName) && "id".equals(Bytes.toString(qualifier)) || "age".equals(Bytes.toString(qualifier))){
System.out.println("列族名稱為"+ familyName + "列名稱為" + Bytes.toString(qualifier) +"列值為====" + Bytes.toInt(value) );
}else{
System.out.println("列族名稱為"+ familyName + "列名稱為" + Bytes.toString(qualifier) +"列值為====" + Bytes.toString(value) );
}
}
}
查詢指定列族下面指定列的值:
@Test
public void getColumn() throws IOException {
Get get = new Get("0003".getBytes());
get.addColumn("f1".getBytes(), "name".getBytes());
get.addColumn("f2".getBytes(),"phone".getBytes());
Result result = table.get(get);
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
//獲取列族
byte[] family = cell.getFamily();
//獲取列名
byte[] qualifier = cell.getQualifier();
//獲取列值
byte[] value = cell.getValue();
System.out.println(Bytes.toString(value));
}
查詢指定列族下面的所有列:
@Test
public void getFamily() throws IOException {
Get get = new Get("0003".getBytes());
get.addFamily("f2".getBytes());
Result result = table.get(get);
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
//獲取列族
byte[] family = cell.getFamily();
//獲取列名
byte[] qualifier = cell.getQualifier();
//獲取列值
byte[] value = cell.getValue();
System.out.println(Bytes.toString(value));
}
}
通過rowkey的范圍值進行掃描, 掃描 0004 到0006的所有的資料
@Test
public void rangeRowkey() throws IOException {
Scan scan = new Scan();
/* scan.setStartRow("0004".getBytes());
scan.setStopRow("0006".getBytes());*/
//ResultScanner 里面封裝了我們多條資料
ResultScanner scanner = table.getScanner(scan);
//回圈遍歷ResultScanner 得到一個個的Result
for (Result result : scanner) {
//獲取資料的rowkey
byte[] row = result.getRow();
System.out.println("資料的rowkey為" + Bytes.toString(row));
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
byte[] family = cell.getFamily();
String familyName = Bytes.toString(family);
byte[] qualifier = cell.getQualifier();
byte[] value = cell.getValue();
//判斷,如果是id列和age列,轉換成為int型別輸出
if("f1".equals(familyName) && "id".equals(Bytes.toString(qualifier)) || "age".equals(Bytes.toString(qualifier))){
System.out.println("列族名稱為"+ familyName + "列名稱為" + Bytes.toString(qualifier) +"列值為====" + Bytes.toInt(value) );
}else{
System.out.println("列族名稱為"+ familyName + "列名稱為" + Bytes.toString(qualifier) +"列值為====" + Bytes.toString(value) );
}
}
}
過濾rowkey比0003還要小的資料
@Test
public void rowFilterStudy() throws IOException {
Scan scan = new Scan();
//通過rowFilter實作資料按照rowkey進行過濾
BinaryComparator binaryComparator = new BinaryComparator("0003".getBytes());
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.LESS, binaryComparator);
scan.setFilter(rowFilter);
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
byte[] row = result.getRow();
System.out.println("資料的rowkey為" + Bytes.toString(row));
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
byte[] family = cell.getFamily();
byte[] qualifier = cell.getQualifier();
byte[] value = cell.getValue();
//id列和age列是整型的資料
if("f1".equals(Bytes.toString(family)) && "id".equals(Bytes.toString(qualifier)) || "age".equals(Bytes.toString(qualifier)) ){
System.out.println("列族為" + Bytes.toString(family) + "列名為" + Bytes.toString(qualifier) + "列值為" + Bytes.toInt(value));
}else{
System.out.println("列族為" + Bytes.toString(family) + "列名為" + Bytes.toString(qualifier) + "列值為" + Bytes.toString(value));
}
}
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277817.html
標籤:其他
上一篇:Redis——Redis的事務