| 網頁右邊,向下滑有目錄索引,可以根據標題跳轉到你想看的內容 |
|---|
| 如果右邊沒有就找找左邊 |
| 主文章鏈接https://blog.csdn.net/grd_java/article/details/115639179 |
|---|
| 第一章:環境搭建https://blog.csdn.net/grd_java/article/details/115693312 |
還沒有搭建環境的可以參考第一章:環境搭建,當然不搭建你也可以看圖片學習
| 宣告:此文是學習尚硅谷Hadoop3.1.x課程的學習筆記 |
|---|
| 尚硅谷視瞥澩地址:https://www.bilibili.com/video/BV1Qp4y1n7EN?p=34&spm_id_from=pageDriver |
一、概述
1、HDFS的產生背景和定義
HDFS 產生背景
- 隨著資料量越來越大,在一個作業系統存不下所有的資料,那么就分配到更多的作業系統管理的磁盤中,但是不方便管理和維護,迫切
需要一種系統來管理多臺機器上的檔案,這就是分布式檔案管理系統,HDFS 只是分布式檔案管理系統中的一種,HDFS 定義
一個檔案系統,用于存盤檔案,通過目錄樹來定位檔案;其次,它是分布式的,由很多服務器聯合起來實作其功能,集群中的服務器有各自的角色,適用場景
適合一次寫入,多次讀出的場景,一個檔案經過創建、寫入和關閉之后就不需要改變,唯一的改變,就只有追加內容和洗掉內容,無法修改存盤的檔案
2、優缺點
優點
- 高容錯性
- 適合處理大資料
- 資料規模:能夠處理資料規模達到GB、TB、甚至
PB級別的資料- 檔案規模:能夠處理
百萬規模以上的檔案數量,數量相當之大
可構建在廉價機器上,通過多副本機制,提高可靠性缺點
不適合低延時資料訪問,比如毫秒級的存盤資料,是做不到的無法高效的對大量小檔案進行存盤
- 存盤大量小檔案的話,它會占用NameNode大量的記憶體來存盤檔案目錄和塊資訊,這樣是不可取的,因為NameNode的記憶體總是有限的
- 小檔案存盤的尋址時間會超過讀取時間,它違反了HDFS的設計目標
- 不支持并發寫入、檔案隨機修改
- 一個檔案只能有一個寫,不允許多個執行緒同時寫
僅支持資料append(追加),不支持檔案的隨機修改
3、組成
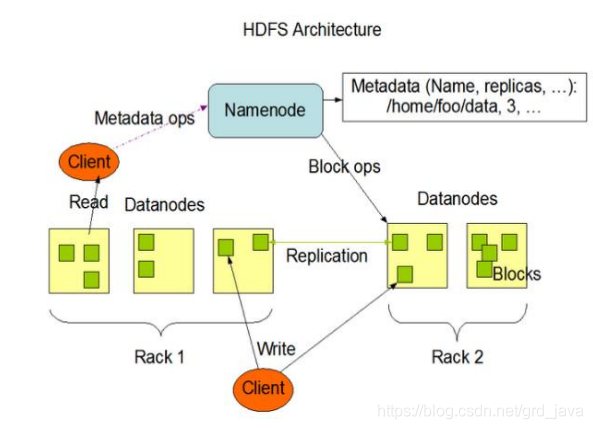
NameNode(nn):就是Master,它是一個主管、管理者
- 管理HDFS的名稱空間,所有檔案元資料都存在這里,(檔案名之類的)
- 配置副本策略(記錄每個檔案有幾個副本)
- 管理資料塊(Block)映射資訊(一個大檔案通常分成多個資料塊,這些資料塊統一由NameNode記錄管理,每個資料塊還有不等量副本,也由NameNode管理)
- 處理客戶端讀寫請求
DataNode:就是Slave,NameNode下達命令,DataNode執行實際的操作
- 存盤實際的資料塊
- 執行資料塊的讀/寫操作
- Client:就是客戶端
- 檔案切分,檔案上傳HDFS的時候,Client將檔案切分成一個一個的Block,然后進行上傳,一般最大128M或256M一個資料塊
- 與NameNode互動,獲取檔案的位置資訊,就是NameNode先出個方案,你這檔案應該往哪存
- 與DataNode互動,讀取或者寫入資料,根據NameNode的方案,和對應DataNode交涉,存盤資料
- Client提供一些命令來管理HDFS,比如NameNode格式化
- Client可以通過一些命令來訪問HDFS,比如對HDFS增刪查改操作
Secondary NameNode:并非NameNode的熱備,當NameNode掛掉的時候,它并不能馬上替換NameNode并提供服務
- 輔助NameNode,分擔其作業量,比如定期合并Fsimage和Edits,并推送給NameNode
- 在緊急情況下,可輔助恢復NameNode
4、檔案塊大小
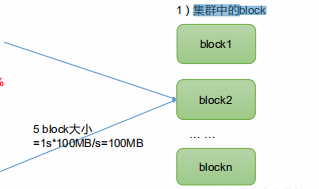
HDFS中的檔案在物理上是分塊存盤(Block),塊的大小可以通過配置引數( dfs.blocksize)來規定,
默認大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M,如果有個1KB的資料,也會分配128M的塊,但是并不會直接占用128M空間,而是塊最大128M,實際上還是塊中資料的大小
- 集群中的block
- 如果尋址時間約為10ms,即查找到目標block的時間為10ms
尋址時間為傳輸時間的1%時,則為最佳狀態,(專家)因此,傳輸時間=10ms/0.01=1000ms=1s- 而目前磁盤的傳輸速率普遍為100MB/s,所以我們一般選擇最接近的128m作為塊最大空間,而公司有錢用固態硬碟可達到300M/s資料,選擇256m作為塊空間大小
為什么塊的大小不能設定太小也不能設定太大
- HDFS的塊設定
太小,會增加尋址時間,程式一直在找塊的開始位置,比如一個檔案100m,分了100個1m的塊,光尋址就要100次,尋址完了才開始獲取資料- 如果塊設定的
太大,從磁盤傳輸資料的時間會明顯大于定位這個塊開始位置所需的時間,導致程式在處理這塊資料時,會非常慢,我們要遵循尋址時間正好是傳輸時間的1%的原則HDFS塊的大小設定主要取決于磁盤傳輸速率,普通機械硬碟,我們用128m設定塊大小,固態硬碟,用256m
二、shell相關操作
- 基本語法
兩條命令都可以
1. hadoop fs 具體命令
2. hdfs dfs 具體命令
- 常用命令查看方式
--查看hadoop,就是hdfs的相關命令
[hadoop100@hadoop102 hadoop-3.1.3]$ bin/hadoop fs
--使用-help查看指定命令的引數,比如下面查詢rm命令的引數
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -help rm
- 常用命令介紹
- 啟動hadoop集群
- 創建一個sanguo檔案夾,-mkdir
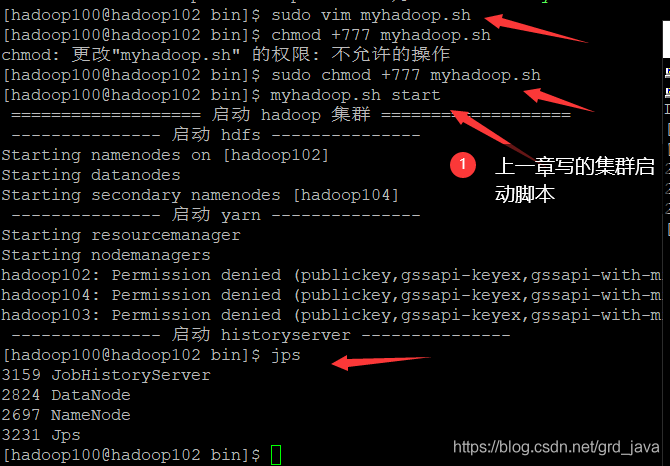

[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /sanguo
- 從本地
剪切到HDFS,-moveFormLocal
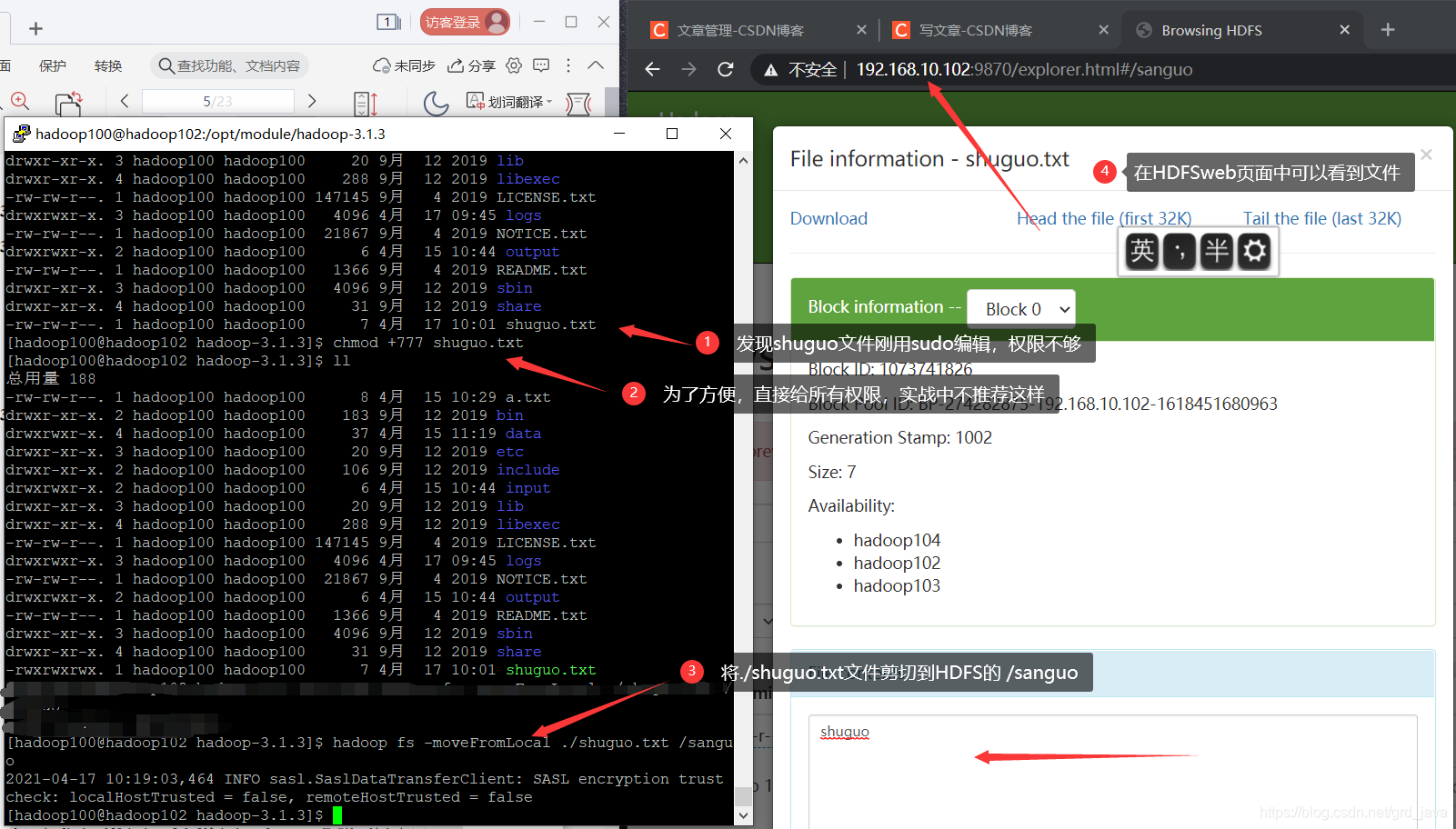
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo
- 從本地檔案系統中拷貝檔案到 HDFS 路徑去,-copyFromLocal
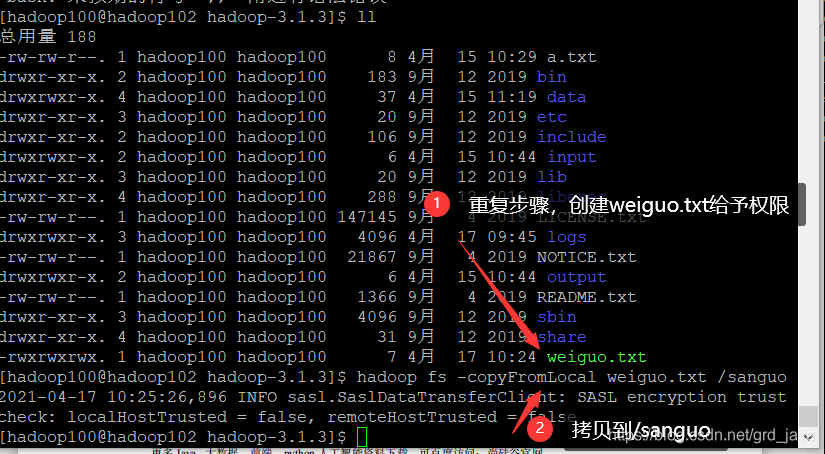
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo
- -put,等同于copyFromLocal,生產環境更多的用put命令
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo
- 追加一個檔案到已經存在的檔案末尾,-appendToFile
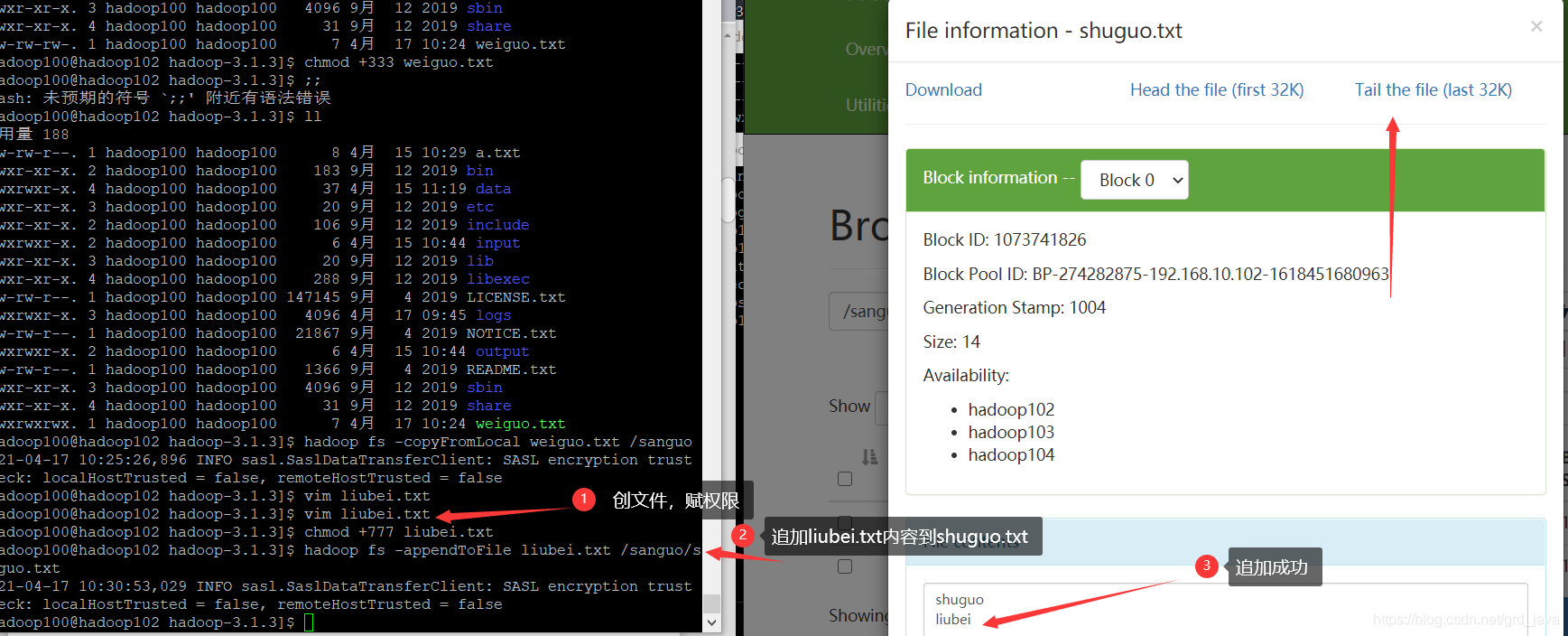
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
- 下載,從HDFS拷貝到本地,-copyToLocal,-get
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
- 一些直接操作HDFS的命令
1)-ls: 顯示目錄資訊
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo
2)-cat:顯示檔案內容
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt
3)-chgrp、-chmod、-chown:Linux 檔案系統中的用法一樣,修改檔案所屬權限
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -chown hadoop100:hadoop100 /sanguo/shuguo.txt
4)-mkdir:創建路徑
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
5)-cp:從 HDFS 的一個路徑拷貝到 HDFS 的另一個路徑
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo
6)-mv:在 HDFS 目錄中移動檔案
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt/jinguo
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo
7)-tail:顯示一個檔案的末尾 1kb 的資料
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt
8)-rm:洗掉檔案或檔案夾
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt
9)-rm -r:遞回洗掉目錄及目錄里面內容
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo
10)-du 統計檔案夾的大小資訊
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo
27 81 /jinguo
說明:27 表示檔案大小;81 表示 27*3 個副本;/jinguo 表示查看的目錄
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo
14 42 /jinguo/shuguo.txt
7 21 /jinguo/weiguo.txt
6 18 /jinguo/wuguo.tx
11)-setrep:設定 HDFS 中檔案的副本數量
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt
這里設定的副本數為10只是記錄在 NameNode 的元資料中,是否真的會有這么多副本,還得
看 DataNode 的數量,因為目前只有 3 臺設備,最多也就 3 個副本,只有節點數的增加到 10臺時,
副本數才能達到 10
三、HDFS的客戶端API
1、搭建客戶端環境
| 先搞到編譯后的hadoop客戶端 |
|---|
| 我將資源上傳到了這里,免費下載即可 |
| https://download.csdn.net/download/grd_java/16728142 |
| 或者到github上下載https://github.com/cdarlint/winutils |
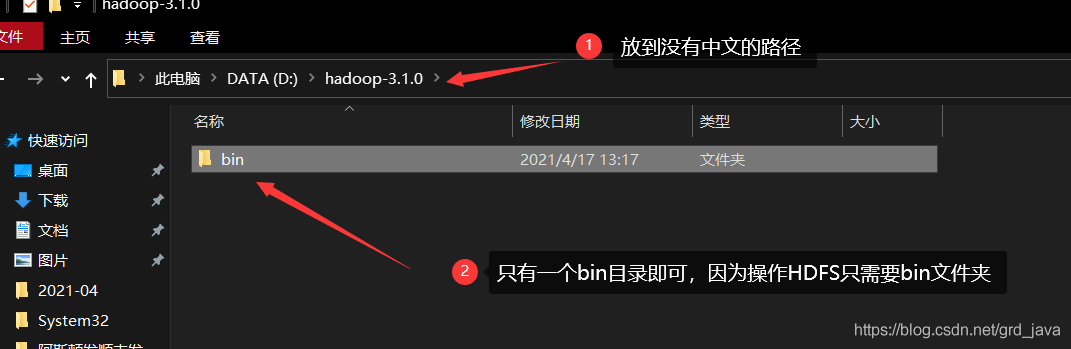
| 配置環境變數 |
|---|
| 運行 |
|---|
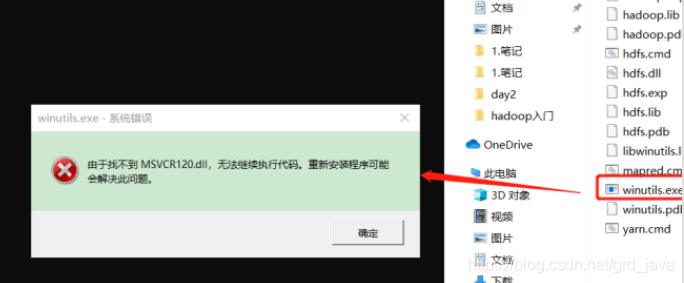
如果報如下錯誤,說明缺少微軟運行庫(正版系統往往有這個問題),百度對應的微軟運行庫安裝包雙擊安裝即可
2、使用IDEA創建MAVEN專案
- 創建Maven專案,因為相關依賴
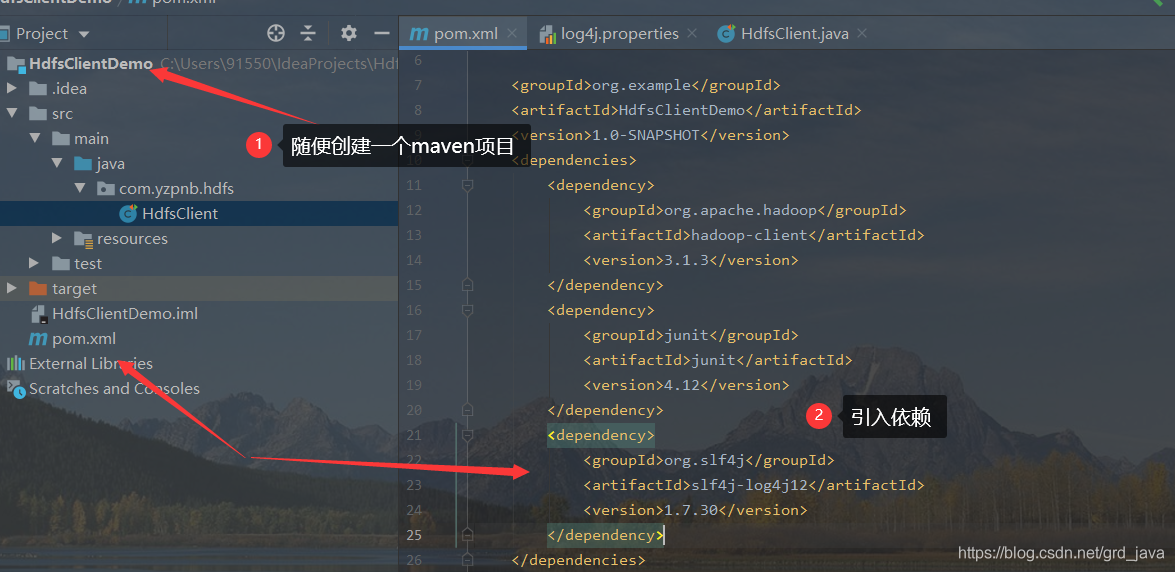
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
- 在專案的 src/main/resources 目錄下,新建一個檔案,命名為“log4j.properties”
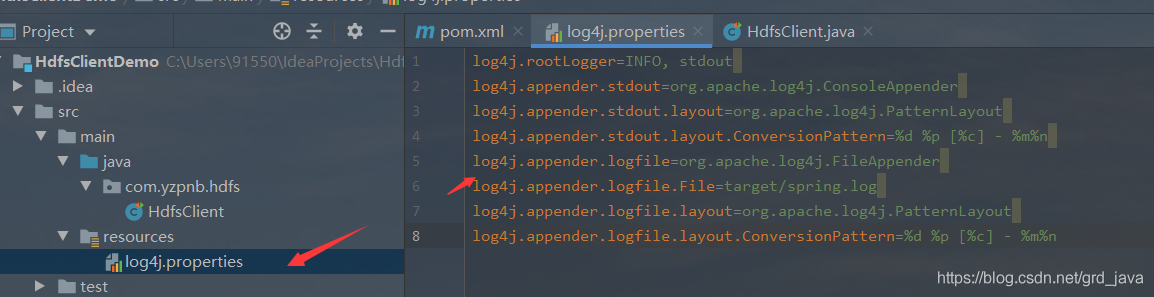
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
3、遠程創建目錄
- 撰寫java代碼
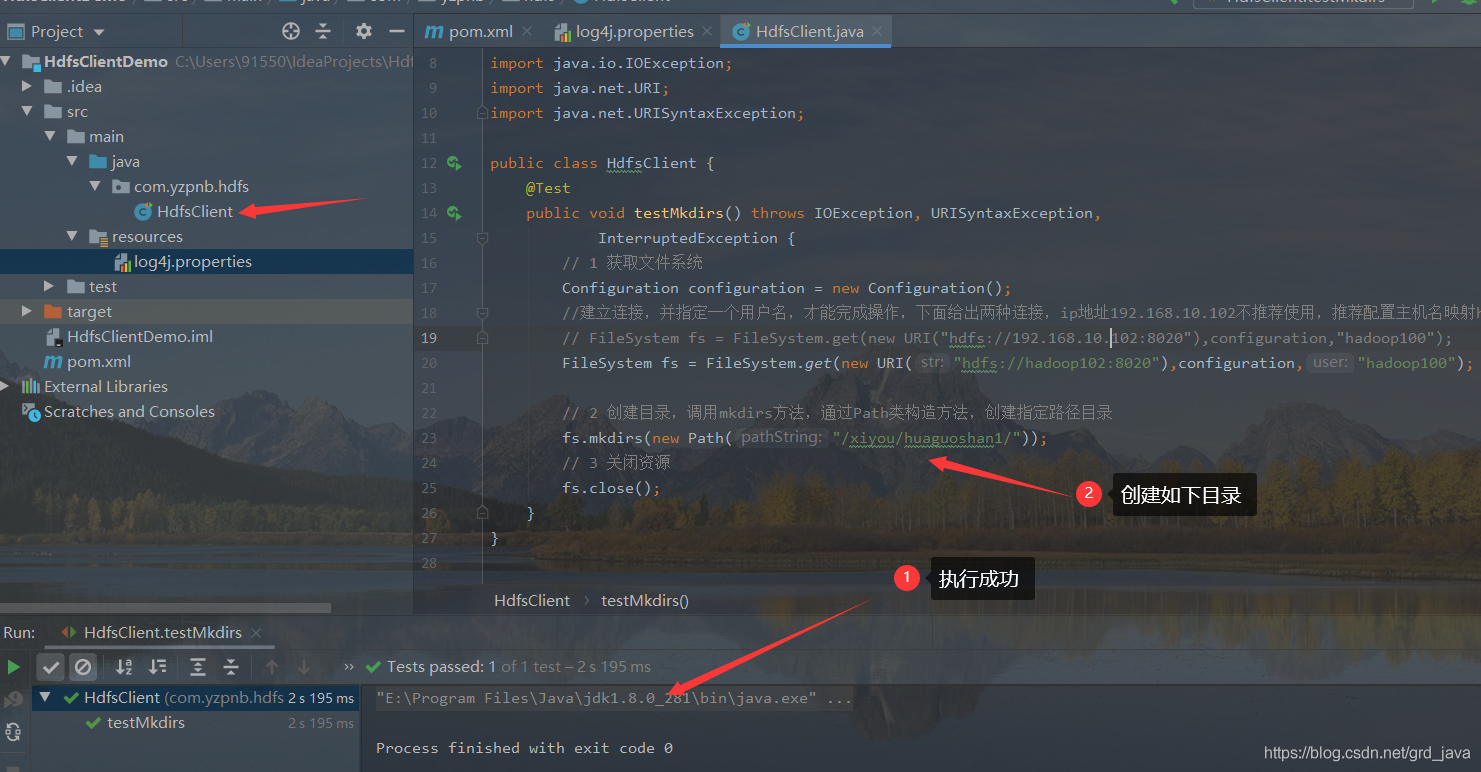
package com.yzpnb.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsClient {
@Test
public void testMkdirs() throws IOException, URISyntaxException,
InterruptedException {
// 1 獲取檔案系統
Configuration configuration = new Configuration();
//建立連接,并指定一個用戶名(默認用windows默認用戶,不一致肯定報錯的),才能完成操作,下面給出兩種連接,ip地址192.168.10.102不推薦使用,推薦配置主機名映射hadoop102
// FileSystem fs = FileSystem.get(new URI("hdfs://192.168.10.102:8020"),configuration,"hadoop100");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),configuration,"hadoop100");
// 2 創建目錄,呼叫mkdirs方法,通過Path類構造方法,創建指定路徑目錄
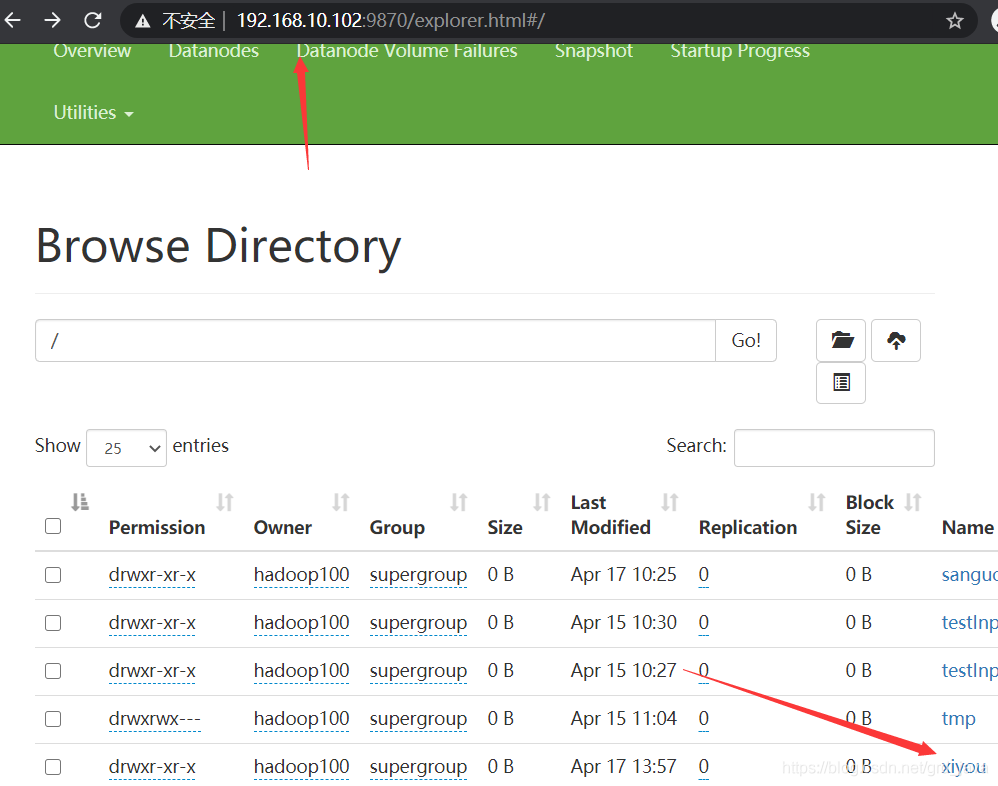
fs.mkdirs(new Path("/xiyou/huaguoshan1/"));
// 3 關閉資源
fs.close();
}
}
- 執行結果
4、資料的上傳和下載
1、 HDFS檔案上傳(測驗引數優先級)
- 創建一個用來上傳的檔案
- 撰寫代碼執行
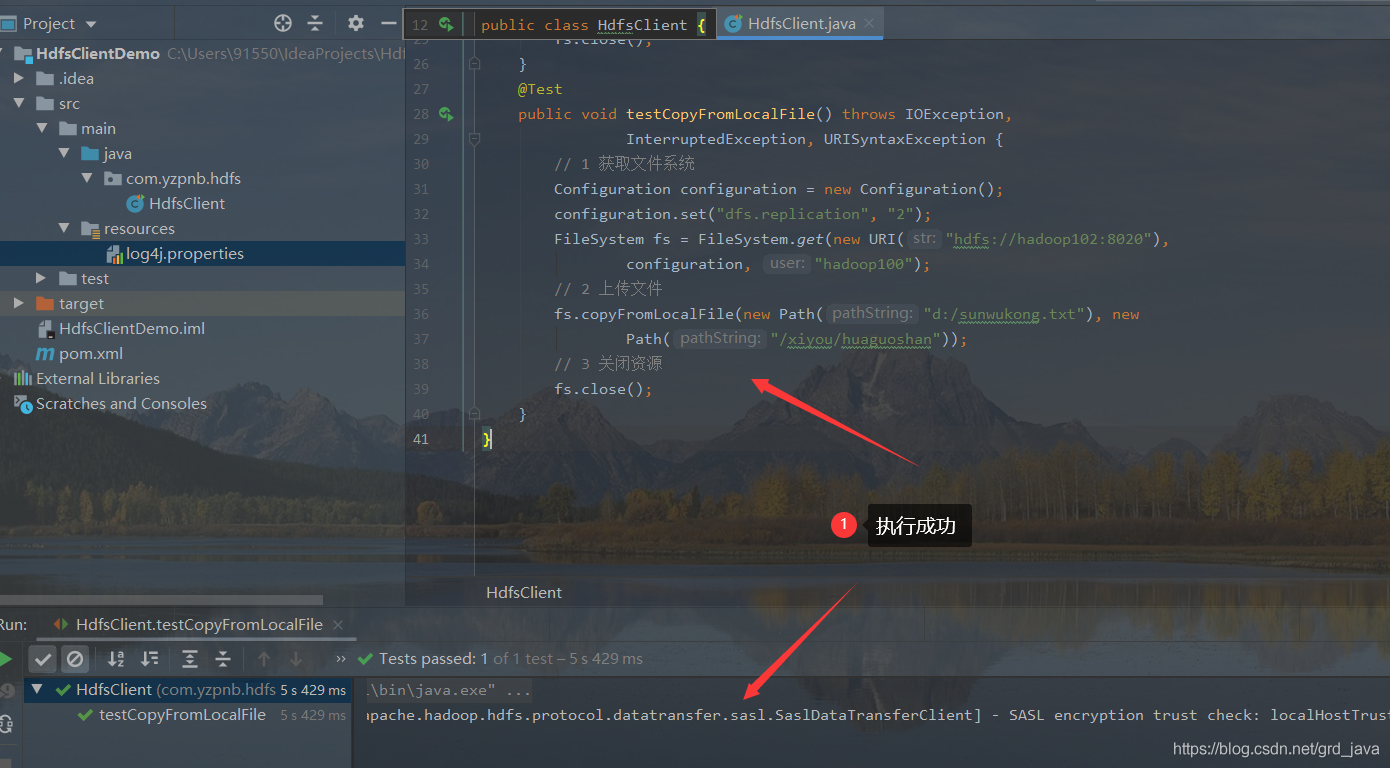
@Test
public void testCopyFromLocalFile() throws IOException,
InterruptedException, URISyntaxException {
// 1 獲取檔案系統
Configuration configuration = new Configuration();
configuration.set("dfs.replication", "2");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2 上傳檔案下面代碼省略了引數一:是否洗掉源資料,引數二:是否允許覆寫
fs.copyFromLocalFile(new Path("d:/sunwukong.txt"), new
Path("/xiyou/huaguoshan"));
// 3 關閉資源
fs.close();
}
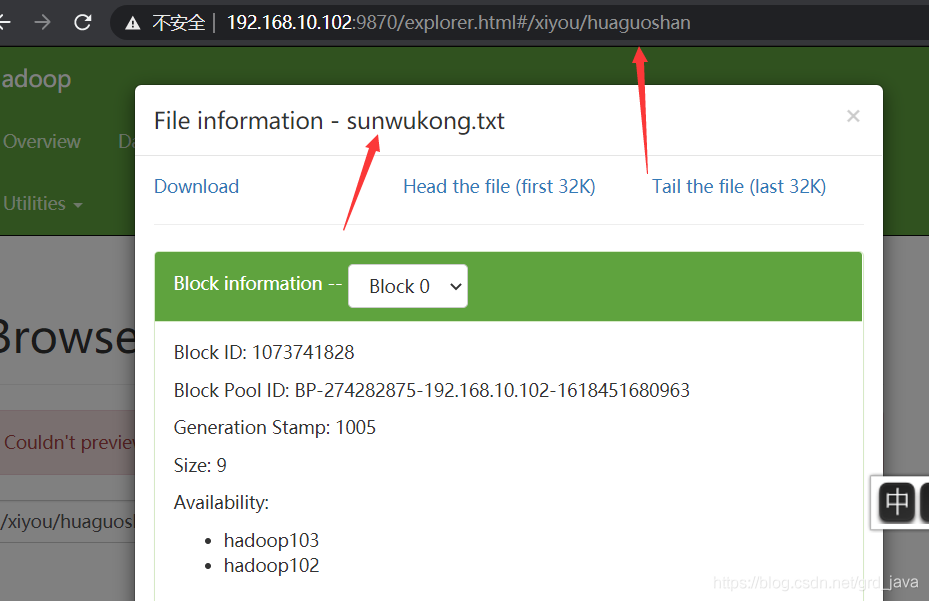
- 結果
- 引數優先級測驗(比如我客戶端代碼中有xml組態檔,服務器中也有相同的xml組態檔,那么,客戶端代碼執行時以誰為準呢?)
- 引數優先級
引數優先級排序:(1)客戶端代碼中設定的值 >(2)ClassPath 下的用戶自定義組態檔 >(3)然后是服務器的自定義配置(xxx-site.xml)>(4)服務器的默認配置(xxx-default.xml)
- 將 hdfs-site.xml 拷貝到專案的 resources 資源目錄下,利用dfs.replication配置副本數量,查看是客戶端配置的1生效了,還是服務器配置的3生效
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
2、 檔案下載
- 撰寫測驗代碼(如果執行如下代碼,下載不了檔案,有可能是你電腦的微軟支持的運行庫少,需要安裝一下微軟運行庫,另外
你可能會在下載的檔案旁邊看到.crc后綴的檔案,它是校驗檔案是否傳輸錯誤的,HDFS發送資料時,對檔案加密,結果保存到crc檔案,然后將crc和源資料一同發送,客戶端收到后,同樣對檔案加密,查看結果和crc檔案是否一致)
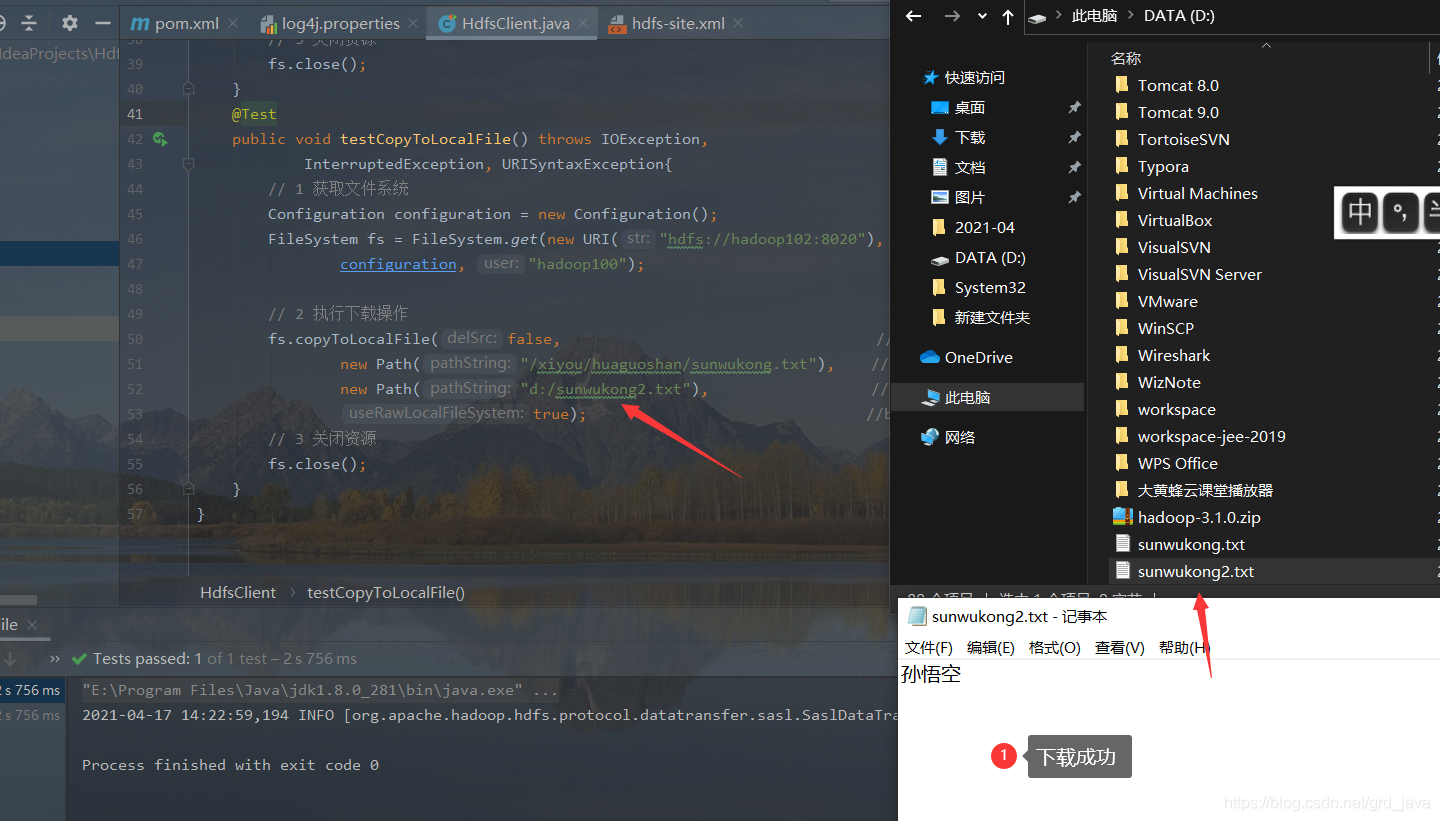
@Test
public void testCopyToLocalFile() throws IOException,
InterruptedException, URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2 執行下載操作
fs.copyToLocalFile(false, //boolean delSrc 指是否將原檔案洗掉
new Path("/xiyou/huaguoshan/sunwukong.txt"), //Path src 指要下載的檔案路徑
new Path("d:/sunwukong2.txt"), //Path dst 指將檔案下載到的路徑
true); //boolean useRawLocalFileSystem 是否開啟檔案校驗
// 3 關閉資源
fs.close();
}
3、 檔案更名和移動
- 撰寫代碼并測驗
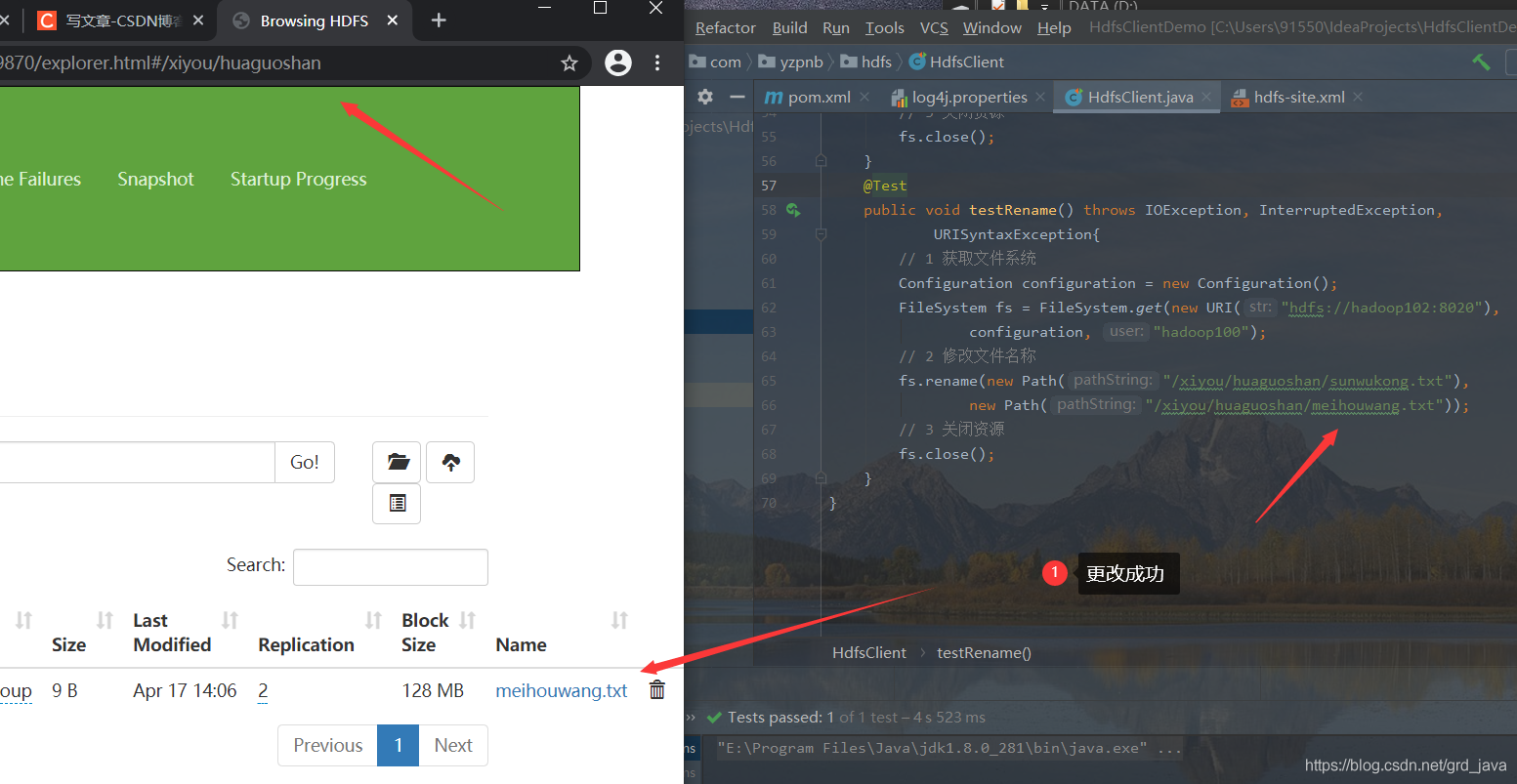
@Test
public void testRename() throws IOException, InterruptedException,
URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2 修改檔案名稱
fs.rename(new Path("/xiyou/huaguoshan/sunwukong.txt"),
new Path("/xiyou/huaguoshan/meihouwang.txt"));
// 3 關閉資源
fs.close();
}
4、洗掉檔案和目錄
- 撰寫代碼運行
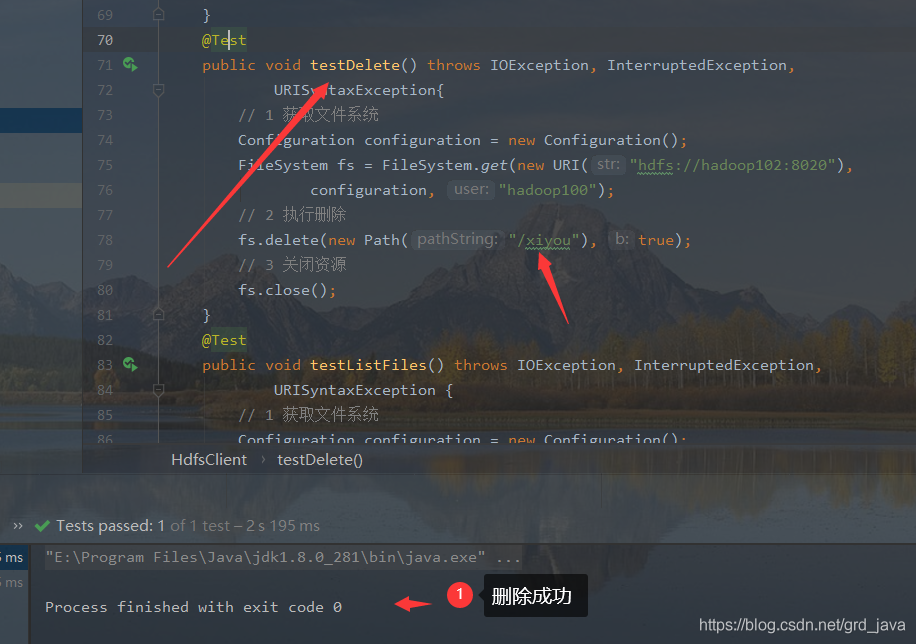
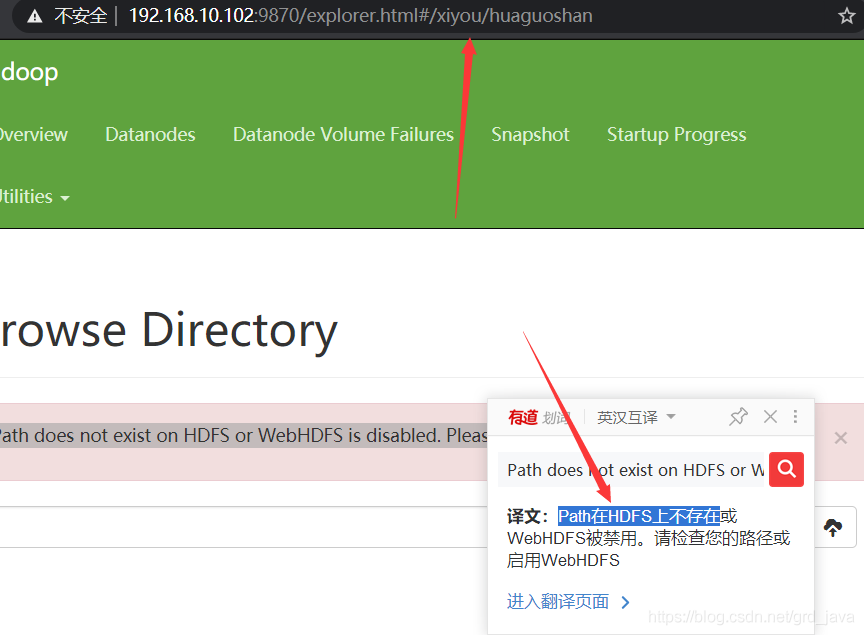
@Test
public void testDelete() throws IOException, InterruptedException,
URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2 執行洗掉,引數1:洗掉路徑,引數2:是否遞回洗掉,不遞回的話,洗掉不了它里面 的檔案
fs.delete(new Path("/xiyou"), true);
// 3 關閉資源
fs.close();
}
5、 HDFS 檔案詳情查看
- 撰寫代碼運行
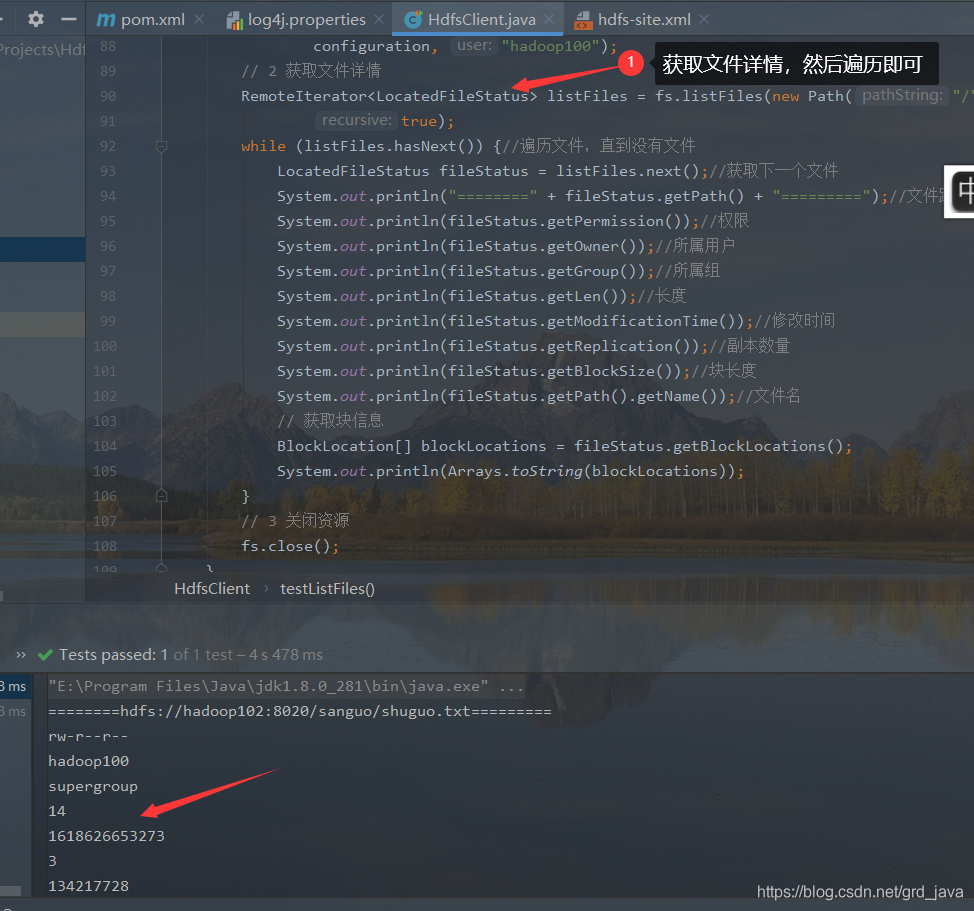
@Test
public void testListFiles() throws IOException, InterruptedException,
URISyntaxException {
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2 獲取檔案詳情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"),
true);
while (listFiles.hasNext()) {//遍歷檔案,直到沒有檔案
LocatedFileStatus fileStatus = listFiles.next();//獲取下一個檔案
System.out.println("========" + fileStatus.getPath() + "=========");//檔案路徑
System.out.println(fileStatus.getPermission());//權限
System.out.println(fileStatus.getOwner());//所屬用戶
System.out.println(fileStatus.getGroup());//所屬組
System.out.println(fileStatus.getLen());//長度
System.out.println(fileStatus.getModificationTime());//修改時間
System.out.println(fileStatus.getReplication());//副本數量
System.out.println(fileStatus.getBlockSize());//塊長度
System.out.println(fileStatus.getPath().getName());//檔案名
// 獲取塊資訊
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
// 3 關閉資源
fs.close();
}
6、HDFS 檔案和檔案夾判斷
- 撰寫代碼并運行
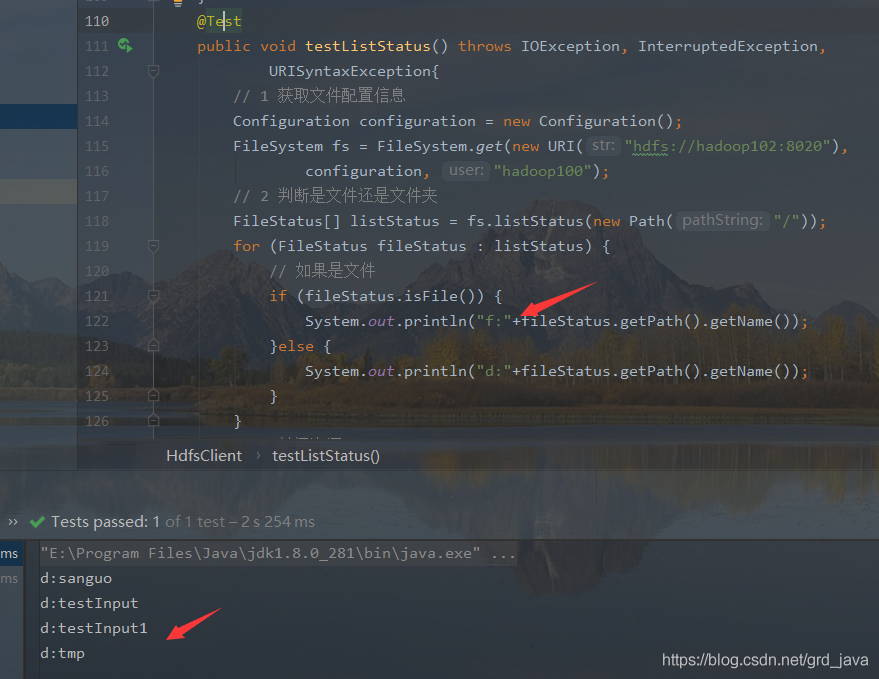
@Test
public void testListStatus() throws IOException, InterruptedException,
URISyntaxException{
// 1 獲取檔案配置資訊
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2 判斷是檔案還是檔案夾
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
// 如果是檔案
if (fileStatus.isFile()) {
System.out.println("f:"+fileStatus.getPath().getName());
}else {
System.out.println("d:"+fileStatus.getPath().getName());
}
}
// 3 關閉資源
fs.close();
}
四、HDFS的讀寫流程
1、寫流程
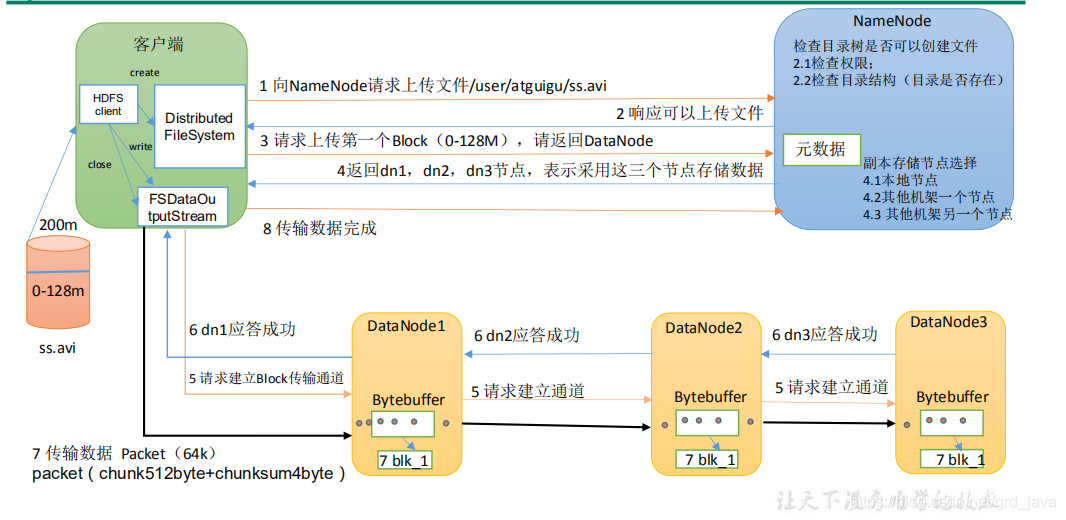
- 檔案寫入剖析
- 客戶端通過 Distributed FileSystem 模塊向 NameNode 請求上傳檔案,NameNode 檢查目標檔案是否已存在,父目錄是否存在
- NameNode 回傳是否可以上傳
- 客戶端請求第一個 Block 上傳到哪幾個 DataNode 服務器上
- NameNode 回傳 3 個 DataNode 節點,分別為 dn1、dn2、dn3
- 客戶端通過 FSDataOutputStream 模塊請求 dn1 上傳資料,dn1 收到請求會繼續呼叫dn2,然后 dn2 呼叫 dn3,將這個通信管道建立完成
- dn1、dn2、dn3 逐級應答客戶端
- 客戶端開始往 dn1 上傳第一個 Block(先從磁盤讀取資料放到一個本地記憶體快取),以 Packet 為單位,dn1 收到一個 Packet 就會傳給 dn2,dn2 傳給 dn3;dn1
每傳一個 packet會放入一個應答佇列等待應答,- 當一個 Block 傳輸完成之后,客戶端再次請求 NameNode 上傳第二個 Block 的服務器,(重復執行 3-7 步)
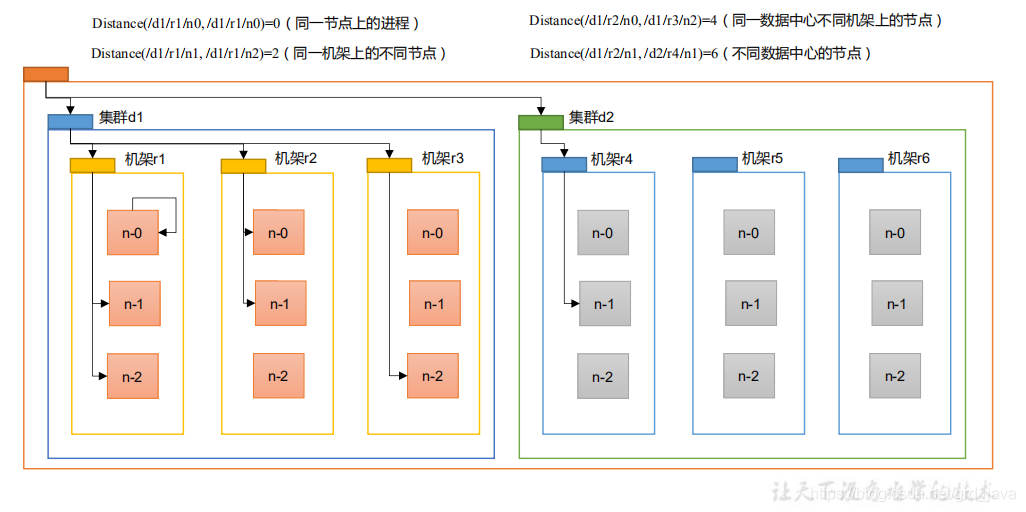
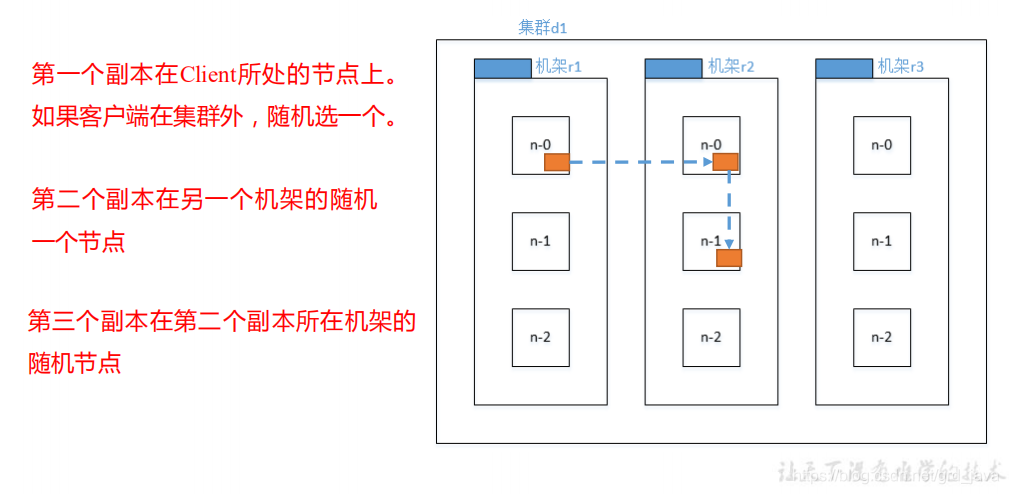
- 網路拓撲-節點距離計算
在 HDFS 寫資料的程序中,NameNode 會選擇距離待上傳資料最近距離的 DataNode 接收資料,那么這個最近距離怎么計算呢?
節點距離:兩個節點到達最近的共同祖先的距離總和- 根據下圖決議
- 假設有資料中心 d1 機架 r1 中的節點 n1,該節點可以表示為/d1/r1/n1,利用這種q標記,這里給出四種距離描述
- 機架感知(副本存盤節點選擇)
- 官方檔案:http://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
- 根據原始碼查看(Crtl + n 查找 BlockPlacementPolicyDefault,在該類中查找 chooseTargetInOrder 方法)
- 副本節點的選擇
總體依據,就近和可靠原則
2、讀資料
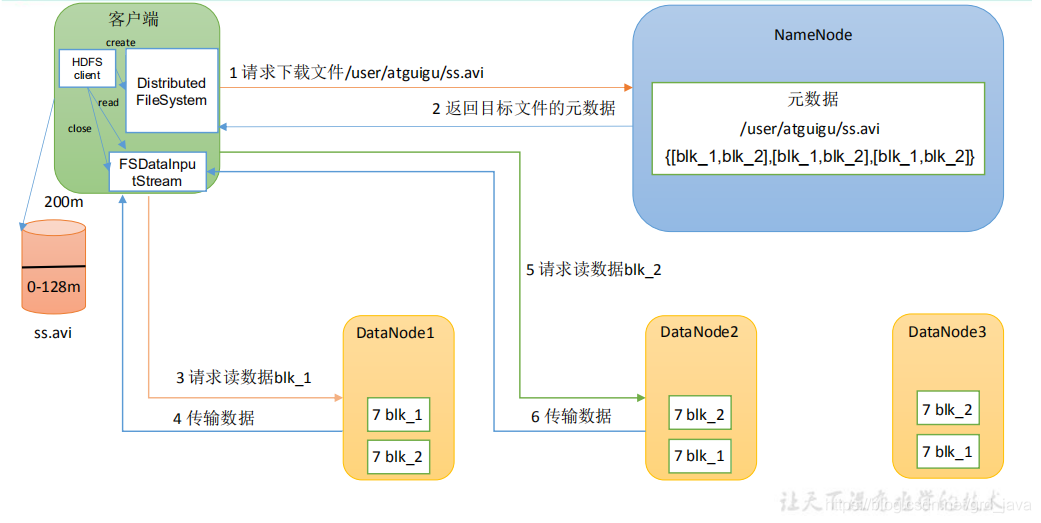
- 流程
先就近原則讀,當處理能力到上限,就去副本所在服務器讀
- 客戶端通過 DistributedFileSystem 向 NameNode 請求下載檔案,NameNode 通過查詢元資料,找到檔案塊所在的 DataNode 地址
- 挑選一臺 DataNode(就近原則,然后隨機)服務器,請求讀取資料
3.DataNode 開始傳輸資料給客戶端(從磁盤里面讀取資料輸入流,以 Packet 為單位來做校驗)
4.客戶端以 Packet 為單位接收,先在本地快取,然后寫入目標檔案
五、NN和2NN(NameNode 和 SecondaryNameNode)
1、作業機制
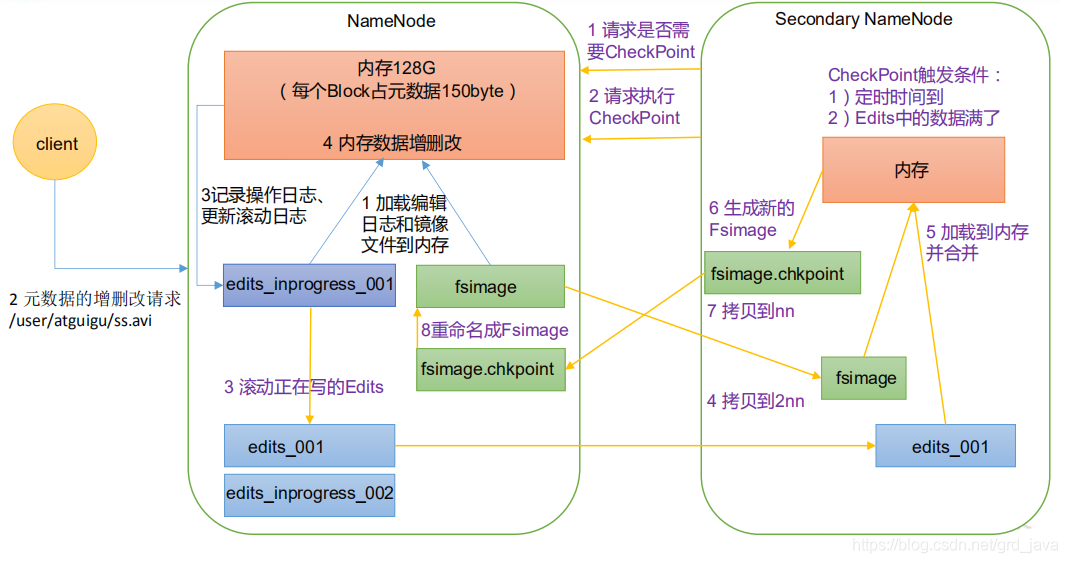
- NameNode中的元資料存盤在哪
- 存盤在記憶體,但是為了斷電不丟失,產生了在磁盤中備份元資料的FsImage,但是同時更新FsImage效率又會低,因此引入Edits檔案,只進行追加操作,元資料有更新等操作時,同時會進行追加,但是Edits會越來越大,因此引入一個新節點,SecondaryNamenod,專門用于FsImage和Edits合并

| NameNode作業機制 |
|---|
- 第一階段:NameNode 啟動
- 第一次啟動 NameNode 格式化后,創建 Fsimage 和 Edits 檔案,如果不是第一次啟動,直接加載編輯日志和鏡像檔案到記憶體
- 客戶端對元資料進行增刪改的請求
- NameNode 記錄操作日志,更新滾動日志
- NameNode 在記憶體中對元資料進行增刪改
- 第二階段:Secondary NameNode 作業
- Secondary NameNode 詢問 NameNode 是否需要 CheckPoint,直接帶回 NameNode是否檢查結果,
- Secondary NameNode 請求執行 CheckPoint
- NameNode 滾動正在寫的 Edits 日志
- 將滾動前的編輯日志和鏡像檔案拷貝到 Secondary NameNode
- Secondary NameNode 加載編輯日志和鏡像檔案到記憶體,并合并,
- 生成新的鏡像檔案 fsimage.chkpoint
- 拷貝 fsimage.chkpoint 到 NameNode
- NameNode 將 fsimage.chkpoint 重新命名成 fsimage,
2、 Fsimage和Edits
- 概念
- Fsimage檔案:HDFS檔案系統元資料的一個
永久性的檢查點,其中包含HDFS檔案系統的所有目錄和檔案inode的序列化資訊,- Edits檔案:存放HDFS檔案系統的所有更新操作的路徑,檔案系統客戶端執行的所有寫操作首先會被記錄到Edits檔案中
- seen_txid檔案保存的是一個數字,就是最后一個edits_的數字
- 每次NameNode
啟動的時候都會將Fsimage檔案讀入記憶體,加 載Edits里面的更新操作,保證記憶體中的元資料資訊是最新的、同步的,可以看成NameNode啟動的時候就將Fsimage和Edits檔案進行了合并,
- oiv 查看 Fsimage 檔案


[hadoop100@hadoop102 current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
基本語法如下
hdfs oiv -p 檔案型別 -i 鏡像檔案 -o 轉換后檔案輸出路徑
實操:
[hadoop100@hadoop102 current]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/name/current
[hadoop100@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xml
[hadoop100@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/fsimage.xml
- oev查看Edits檔案


基本語法
hdfs oev -p 檔案型別 -i 編輯日志 -o 轉換后檔案輸出路徑
實操:
[hadoop100@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xml
[hadoop100@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/edits.xml
- CheckPoint時間設定
- 通常情況下,SecondaryNameNode 每隔一小時執行一次(參考下面hdfs-default.xml的默認配置)
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
</property>
- 一分鐘檢查一次操作次數,當操作次數達到 1 百萬時,SecondaryNameNode 執行一次
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作動作次數</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60s</value>
<description> 1 分鐘檢查一次操作次數</description>
</property
六、Datanode
1、 DataNode作業機制
- 一個資料塊在 DataNode 上以檔案形式存盤在磁盤上,包括兩個檔案,一個是資料本身,一個是元資料包括資料塊的長度,塊資料的校驗和,以及時間戳
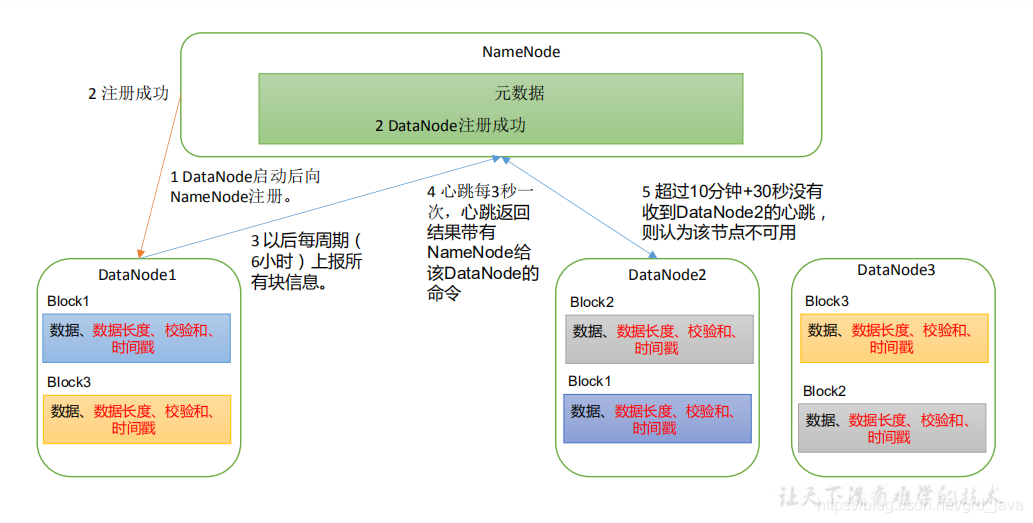
- DataNode 啟動后向 NameNode 注冊,通過后,周期性(6 小時)的向 NameNode 上報所有的塊資訊
- 心跳是每 3 秒一次,心跳回傳結果帶有 NameNode 給該 DataNode 的命令如復制塊資料到另一臺機器,或洗掉某個資料塊,如果超過 10 分鐘沒有收到某個 DataNode 的心跳,則認為該節點不可用
- 集群運行中可以安全加入和退出一些機器


2、資料完整性
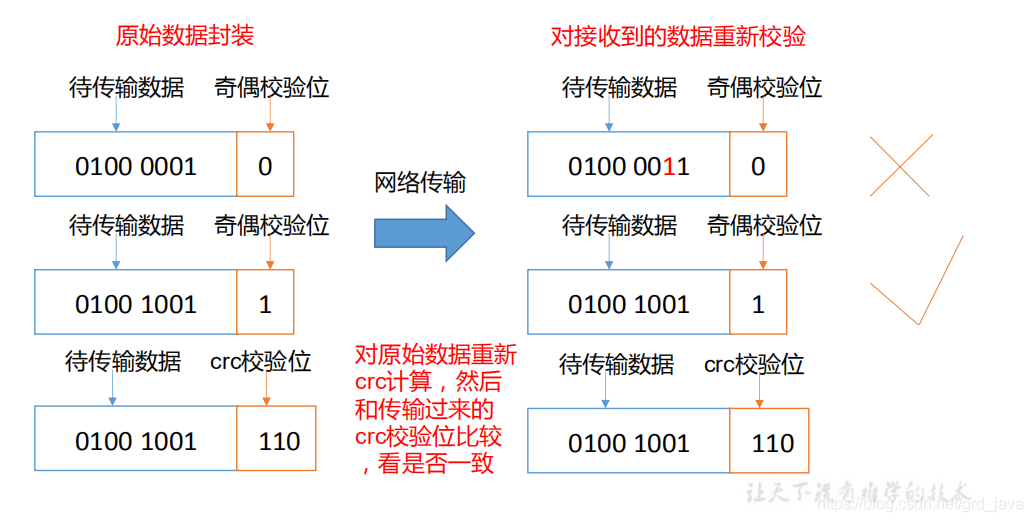
- 如果電腦磁盤里面存盤的資料是控制高鐵信號燈的紅燈信號(1)和綠燈信號(0),但是存盤該資料的磁盤壞了,一直顯示是綠燈,是否很危險?同理 DataNode 節點上的資料損壞了,卻沒有發現,是否也很危險,那么如何解決呢?
- DataNode 節點保證資料完整性的方法
- 當 DataNode 讀取 Block 的時候,它會計算 CheckSum
- 如果計算后的 CheckSum,與 Block 創建時值不一樣,說明 Block 已經損壞
- Client 讀取其他 DataNode 上的 Block
- 常見的校驗演算法 crc(32),md5(128),sha1(160)
- DataNode 在其檔案創建后周期驗證 CheckSum
3、掉線時限引數設定
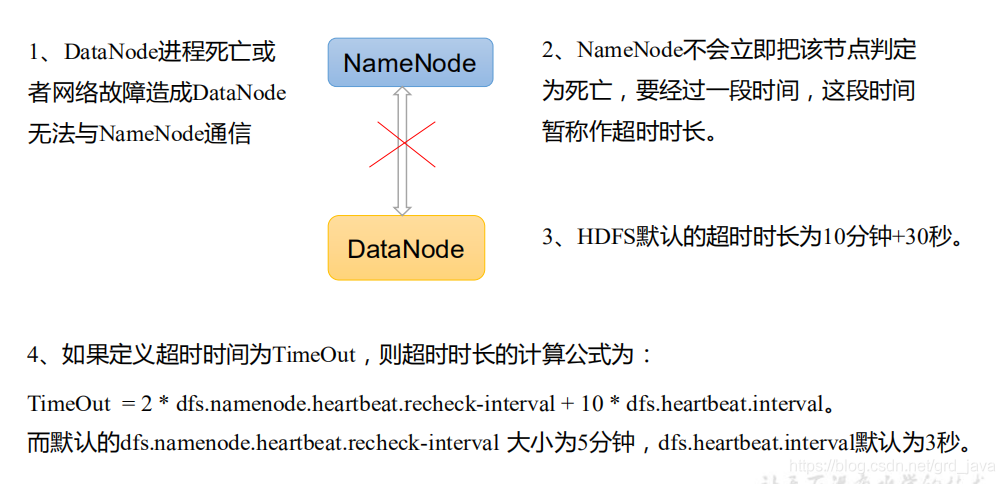
- hdfs-site.xml 組態檔中的 heartbeat.recheck.interval 的單位為毫秒,dfs.heartbeat.interval 的單位為秒

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277820.html
標籤:其他