Hadoop檔案安裝時的問題
- 在Hadoop安裝時,要配置JAVA環境變數,注意要下載與之后操作相對應的版本,否則會出現很多問題,
- 下載Hadoop檔案,注意要如同1一樣,要下載與JAVA版本相對于的版本,否則會出現不可以呼叫的問題,
Hadoop偽分布式時的問題
<configuration> </configuration>
按照安裝教程進行偽分布式配置的修改組態檔時,要注意<configuration> </configuration>這個標簽只有一個,而原檔案中以有這個標簽,只需將教程中的其他內容復制到里面就行了,否則將會如下的錯誤報告,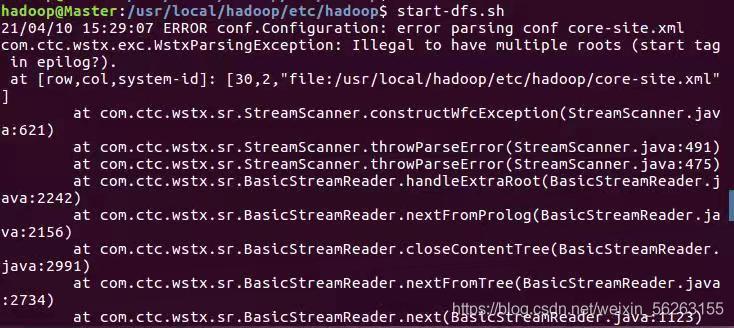
- 其次,在修改組態檔中如果不是復制內容,而是手打的話,就需要完完全全按照教程中輸入相應代碼,以下是容易打錯的地方:1.data >>> date 2.
**<property> </property>**每一段的完成都需要有這樣的格式3.**<name></name>**也是如此 4.**<value></value>**也是如此,
Hadoop集群配置時出現的常見問題
- 為方便起見,我們可以對先前的hadoop虛擬機進行復制,克隆出兩個相同的虛擬機,來作為Master節點和Slave節點,但要注意兩者要有用不同的MAC地址,同時要修改
sudo vim /etc/hostname中的主機名,改為Master和Slave,在進行集群配置的時候,要注意將兩個節點(Master和Slave)兩個虛擬機同時打開,兩者才能互通,這是最基本的前提, - 在配置集群環境的時候,如修改配置
core-site.xml檔案的時候,也要注意Hadoop偽分布式出現的相關問題, - 最容易但也很簡單出現的問題(我因此忽略這個小細節,除錯了很多時間在其他沒有錯誤的地方,浪費了很多時間):slaves檔案的配置,注意在集群配置中,這個檔案中只需要留存一個主機名,將Master節點中的slaves檔案里面的內容改為Slave,這樣才能將資料節點賦予Slave節點,讓其擁有
datanode,否則如下圖的情況,
- 在集群配置時,可能會因為一些原因,而多次使用
hdfs namenode -format多次初始化會讓Slave節點啟動datanode失敗,因為多次初始化,使得Namenode會產生新的clusterid,導致與datanode上的culsterid不一致,使得Slave節點啟動datanode失敗,對此我采用了兩種方法去解決:1 .洗掉hadoop目錄下的data和logs檔案夾,重新初始化, 2. 找到Slave節點上的clusterid和Master上的clusterid,將Slave節點上的clusterid改成與Master上的一致即可,
這些就是我在使用hadoop時出現的常見問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277819.html
標籤:其他