一、簡介
1 聚類分析
聚類:
把相似資料并成一組(group)的方法,‘物以類聚,人以群分’
不需要類別標注的演算法,直接從資料中學習模式
所以,聚類是一種 資料探索 的分析方法,他幫助我們在大量資料中探索和發現資料結構
1.1 相似度與距離度量
定義距離來度量表示相似度:
歐式距離,曼哈頓距離,閔氏距離
距離與變數量綱的關系
變數標準化方法:
0-1 標準化
區間縮放法 (a,b)=(0,1)
類別變數onehot
1.2 聚類演算法及劃分方法
常見的兩類聚類演算法:
層次聚類演算法(Hierarchical)
基于劃分的方法(Partitional)
基于密度 和 基于模型
基于劃分的方法(Partitional):K-means(K均值)
1 隨機選取K個資料點作為‘種子’
2 根據資料點與‘種子’的距離大小進行類分配
3 更新類中心點的位置,以新的類中心點作為‘種子’
4 按照新的‘種子’對資料歸屬的類進行重新分配
5 更新類中心點(–>3–>4),不斷迭代,直到類中心點變得很小
2 聚類模型評估(優缺點)
優點: 演算法原理簡單,處理快
當聚類密集時,類與類之間區別明顯,效果好
缺點: K是事先給定的,K值選定難確定
對孤立點、噪聲敏感
結果不一定是全域最優,只能保證區域最優,
很難發現大小差別很大的簇及進行增量計算
結果不穩定,初始值選定對結果有一定的影響
計算量大
3 K-means 在 sklearn方法
sklearn.cluster.KMeans(
n_clusters = 8, #聚類個數,K值,默認8
init = 'k-means++',
n_init = 10,
max_iter = 300,
tol = 0.0001,
precompute_distances = 'auto',
verbose = 0,
random_state = None,
copy_x = True,
n_jobs = 1,
algorithm = 'auto'
)
一些重要的引數:
n_clusters = 8, #聚類個數,K值,默認8
init = 'k-means++', #初始化類中心點選擇方法,可選:
{
'k-means++', #是一種優化選擇方法,比較容易收斂
'random', #隨機選擇
an ndarray #可以通過輸入ndarray陣列手動指定中心點
}
max_iter: #最大迭代數
precompute_distances: #預計算距離,計算速度更快但占用更多記憶體,auto True
copy_x # True,原始資料不變,False直接在原始資料上做更改
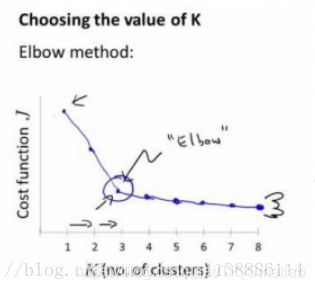
4 確定K值–肘部法則–SSE
最合適的K值
肘部法則(Elbow method):找到隨著K值變大,損失函式的拐點,
損失函式:各個類畸變程度(distortions)之和

SSE是每個屬性的SSE之和:
1. 對于所有的簇,某變數的SSE都很低,都意味著什么?
2. 如果只對一個簇很低,意味著什么?
3. 如果只對一個簇很高,意味著什么?
4. 如果對所有簇都很高,意味著什么?
5. 如何使用每個變數的SSE資訊改進聚類?
解答: 1. 說明該屬性本質上為常量,不能作為聚類依據,
2. 那么該屬性有助于該簇的定義
3. 那么該屬性為噪聲屬性
4. 那么該屬性 與 定義該屬性提供的資訊不一致,也意味著該屬性不利于簇的定義,
5. 消除對于所有簇都是 低的SSE(高的SSE)的屬性,因為這些屬性對聚類沒有幫助,
這些屬性在SSE的總和計算中引入了噪聲,
也可以對其中某些屬性用加權概率來計算,使該屬性有助于該簇的定義,
去除某些不利于該簇定義的影響因子(那些可能是噪聲),從而更有利于簇的聚類,
K-means 附加問題
1.處理空簇:如果資料量少,尋找替補質心,使SSE最小,如果資料量大,保留該空簇
2.離群點:不能洗掉,建議聚類之前離群檢測,分析看能否洗掉
3.降低SSE :將大的分散的簇再次拆開;引入新的簇將之前的大簇拆分,
4.增量更新質心:再次在質心附近尋找測驗點,看能否再次找到更優的質心,
5 模型評估指標–輪廓系數法–最近簇
聚類目的是讓“組內資料盡量相似”,而“組間資料差異明顯”,輪廓系數就是衡量方法,
針對每一條資料i
a(i)資料i與組內其它資料的平均距離
b(i)資料i與鄰組的資料的平均距離
5.1 輪廓系數

5.2 最近簇定義—平均輪廓系數 [0,1]:
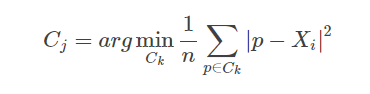
其中p是某個簇Ck中的樣本,即,用Xi到某個簇所有樣本平均距離作為衡量該點到該簇的距離后,
選擇離Xi最近的一個簇作為最近簇,
sklearn.metrics.silhouette_score
sklearn.metrics.silhouette_score(
X,
labels = 'euclidean',
sample_size = None,
random_state = None
)
一些重要的引數:
X: 聚類的輸入特征資料
labels:類標簽陣列
metrics:
sample_size:是否抽樣計算
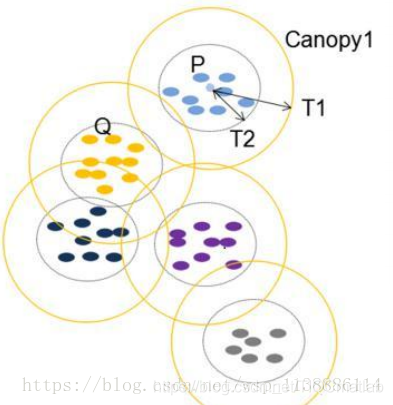
5.3、Canopy演算法配合初始聚類
1.聚類最耗費計算的地方是計算物件相似性的時候,Canopy聚類在第一階段選擇簡單、
計算代價較低的方法計算物件相似性,將相似的物件放在一個子集中,這個子集被叫做Canopy ,
通過一系列計算得到若干Canopy,Canopy之間可以是重疊的,但不會存在某個物件不屬于任何Canopy的情況,
可以把這一階段看做資料預處理;
2.在各個Canopy 內使用傳統的聚類方法(如K-means),不屬于同一Canopy 的物件之間不進行相似性計算,
(即,根據Canopy演算法產生的Canopies代替初始的K個聚類中心點,
由于已經將所有資料點進行Canopies有覆寫劃分,
在計算資料離哪個k-center最近時,不必計算其到所有k-centers的距離,
只計算和它在同一個Canopy下的k-centers這樣可以提高效率,
演算法程序:
1,首先選擇兩個距離閾值:T1和T2,其中T1 > T2
2,從list中任取一點P,用低計算成本方法快速計算點P與所有Canopy之間的距(如果當前不存在Canopy,則把點P作為一個Canopy),如果點P與某個Canopy距離在T1以內,則將點P加入到這個Canopy
3,如果點P曾經與某個Canopy的距離在T2以內,則需要把點P從list中洗掉,這一步是認為點P此時與這個Canopy已經夠近了,因此它不可以再做其它Canopy的中心了;
4,重復步驟2、3,直到list為空結束,
優缺點
1、Kmeans對噪聲抗干擾較弱,通過Canopy對比,將較小的NumPoint的Cluster直接去掉有利于抗干擾,
2、Canopy選擇出來的每個Canopy的centerPoint作為K會更精確,
3、只是針對每個Canopy的內做Kmeans聚類,減少相似計算的數量,
二、源代碼
function KmeansMain
close all;clear;clc;
%隨機生成亂數
mu = [0 0];
%協方差矩陣,對角為方差值0.3,0.35
var = [0.3 0; 0 0.35];
samNum = 200;
data = mvnrnd(mu, var, samNum);
a = figure;
plot(gca, data(:,1), data(:,2), '*', 'color', 'k');hold on;
classNum = [];%類數
iterNum = 0;%迭代次數
x = [];
centerPoint = [];
centerPointPathAarry = [];
h_plotCenterPoint = [];%中心點繪制handle
h_plotPath = [];%中心點路徑繪制handle
%centerPointPathAarry結構
%第1次迭代|中心點1(x,y)|中心點2(x,y)|中心點3(x,y)|中心點n(x,y)
%第2次迭代|中心點1(x,y)|中心點2(x,y)|中心點3(x,y)|中心點n(x,y)
h_slider = uicontrol(a,'Style', 'slider',...
'SliderStep',[0.02 0.02],...
'Min',0,'Max',50,'Value',0,...
'Position', [400 20 100 20],...
'Callback', {@classify,gca});
h_edit = uicontrol(a,'Style', 'edit',...
'String', '200',...
'Position', [80 20 40 20],...
'Callback', {@paintRandomPoint,gca});
uicontrol('Style', 'popup',...
'String', '自定義|隨機2點|隨機3點|隨機4點',...
'Position', [200 22 120 20],...
'Callback', {@SpsfPoit,gca});
h_t1 = uicontrol('Style','text','String','迭代', ...
'Position', [355 20 40 20]);
h_textClassNum = uicontrol('Style','text','String','中心點', ...
'Position', [140 20 55 20]);
uicontrol('Style','text','String','樣本點數:', ...
'Position', [25 20 50 20]);
h_textshow = uicontrol('Style','text','String','0','Position', [500 20 20 20]);
set(gca,'xtick',[],'ytick',[],...
'title',text('string','Kmeans演示腳本','color','k'));
xlim([-1.5 1.5]);ylim([-1.5 1.5]);
%%%%%%%%%%%%%%%%%%%%
function SpsfPoit(hObj,event,ax)
set(h_slider,'value',0); %清零滑動條,以實作從0迭代
cla;%清空axes
set(h_textshow,'string',0);%界面顯示的迭代次數清零
%句柄賦值為空
h_plotCenterPoint = [];
h_plotPath = [];
centerPointPathAarry = [];%軌跡歸零
plot(gca, data(:,1), data(:,2), '*', 'color', 'k');%樣本點顏色初始化
val = get(hObj, 'Value');%獲得popup menu的值
if val == 1
%選擇任意若干點作為中心點
[x, y] = ginput;
centerPoint = [x y];
[classNum, ~] = size(centerPoint);
repaintBeginPoint(h_plotCenterPoint, classNum, centerPoint);
elseif val == 2
%選擇任意2點作為中心點
centerPoint = rand(2, 2)*2-0.5;
[classNum, ~] = size(centerPoint);
repaintBeginPoint(h_plotCenterPoint, classNum, centerPoint);
elseif val == 3
%選擇任意3點作為中心點
centerPoint = rand(3, 2)*2-0.5;
[classNum, ~] = size(centerPoint);
repaintBeginPoint(h_plotCenterPoint, classNum, centerPoint);
elseif val == 4
%選擇任意4點作為中心點
centerPoint = rand(4,2)*2-0.5;
[classNum,~] = size(centerPoint);
repaintBeginPoint(h_plotCenterPoint, classNum, centerPoint);
end
[labelSample] = classifyAndShowAndLabel(classNum, centerPoint, data, samNum, gca);
centerPointPathAarry = [centerPointPathAarry; reshape(centerPoint', 1, classNum*2)];
set(h_textClassNum, 'string', [num2str(classNum) '個中心點']);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%迭代分類函式%%%%%%%%%%%%%%%%%%%%
function classify(hObj,event,ax)
iterNum = round(get(hObj, 'value'));
set(h_textshow, 'string', iterNum);
%根據起始點分類,并且為不同的類標記不同顏色,回傳帶標簽樣本資料
[labelSample] = classifyAndShowAndLabel(classNum, centerPoint, data, samNum, gca);
%重新獲得起始點矩陣centerPoint(x|y)
[centerPoint] = recalClassCenter(labelSample, classNum);
centerPointPathAarry = [centerPointPathAarry; reshape(centerPoint', 1, classNum*2)];
%重新繪制起始點centerPoint(x|y)到axes上
repaintBeginPoint(h_plotCenterPoint, classNum, centerPoint);
disp('path:');
disp(centerPointPathAarry);%將中心點的軌跡顯示出來
for i = 1:classNum
[selected_color] = colorMap(i, classNum);
h_plotPath(i)=plot(centerPointPathAarry(:, (i*2)-1), centerPointPathAarry(:,i*2), 'color', selected_color);
end
end
%%%%%%%%%%%%%%%函式部分%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%重新繪制起始點函式%%%%%%%%%
function repaintBeginPoint(handle_plo,classnum,R)
delete(h_plotCenterPoint);%清除繪制的中心點,并將句柄賦值為空
h_plotCenterPoint=[];
%重新繪制起始點,每個起始點的顏色不同
for i = 1:classnum
[selected_color] = colorMap(i, classnum);
h_plotCenterPoint(i) = plot(R(i,1), R(i,2), 'o', 'MarkerSize', 7, 'MarkerFaceColor', selected_color);
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%重新計算類重心%%%%%%%%%%%%%%%%%%%%%%
function [newCenterPoint]=recalClassCenter(labelSample,classNum)
%R為重新被計算的類中心
newCenterPoint=[];
%分類并且計算每個類的重心
for i=1:classNum
%取出所有標簽為i類的所有行,即第i類的所有點
classs=labelSample(labelSample(:,3)==i,:);
%有用的只有第一列和第二列,去除標簽列
classs=[classs(:,1),classs(:,2)];
%重新計算重心
classs_repoint=mean(classs);
newCenterPoint=[newCenterPoint;classs_repoint];
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%根據起始點分類,并且為不同的類標記不同顏色,回傳帶標簽樣本資料%%%%%%%%%
function [labelSample]=classifyAndShowAndLabel(classNum,centerPoint,data1,samNum,gca)
disArray=[];
for i=1:classNum
calproA=[centerPoint(i,:);data1(:,1),data1(:,2)];
Adist=pdist(calproA,'euclidean');
Adist=Adist(1:samNum)';
disArray=[disArray,Adist];
end
%拼接,得到距離矩陣,一列代表一個點到所有樣本點的距離
%disArray=[Adist Bdist];
%disp(disArray);
%獲取每一行最小值所在距離矩陣的列
%并和原樣本矩陣拼接為labelSample
%labelSample 表示被標記的原始樣本,每一行為一個樣本
%每一行的最后一列為標記值,在這里標記是距離哪個樣本點最近,
minn=min(disArray');
cols=[];
for i=1:length(minn)
[row,col] = find(disArray==minn(i));
cols(i)=col;
end
cols=cols';
labelSample=[data1(:,1),data1(:,2),cols];
%將不同類的點標上不同的顏色
for i=1:samNum
[selected_color]=colorMap(labelSample(i,3),classNum);
plot(gca,data1(i,1),data1(i,2),'*','color',selected_color);
end
end
三、運行結果
四、備注
完整代碼或者代寫添加QQ 1564658423
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278049.html
標籤:其他