ElasticSearch
- ElasticSearch
- 一、ES概述
- 二、對比ES
- 1.Solr簡介
- 2.Lucene簡介
- 3.ES和Solr對比
- 三、安裝ES
- 1.下載:
- 2.安裝:
- 四、安裝Kibana
- 1.了解ELK
- 2.安裝kibana
- 五、ES核心概念
- 1.檔案
- 2.型別
- 3.索引
- 4.倒排索引
- 5.總結
- 六、IK分詞器插件
- 七、Rest風格-ES操作詳解
- 關于索引的操作
- 1.基本測驗
- 2.GET命令
- 3.修改索引
- 4.洗掉檔案
- 關于檔案的操作
- 1.基本操作
- 2.復雜操作
- 查詢總結
ElasticSearch
為啥要學ElasticSearch?---->搜索引擎
SQL:like查詢,模糊搜索,那如果大資料量呢?—>撰寫索引—>分布式全文搜索引擎(百度、github、淘寶電商)
一、ES概述
ElasticSearch是基于Lucene做了一些封裝和增強(十分簡單!!!)
Elasticsearch 是一個分布式、RESTful風格的搜索和資料分析引擎,能夠解決不斷涌現出的各種用例, 作為 Elastic Stack 的核心,它集中存盤您的資料,幫助您發現意料之中以及意料之外的情況,
Elasticsearch 的底層是開源庫 Lucene,但是,你沒法直接用 Lucene,必須自己寫代碼去呼叫它的介面,Elastic 是 Lucene 的封裝,提供了 REST API 的操作介面,開箱即用,
ELK:Elasticsearch、Logstash、Kibana
特點:
- 全文搜索
- 結構化搜索
- 分析
二、對比ES
1.Solr簡介
采用Java開發,基于Luncene的全文搜索服務器,同時對其進行了擴展(擴展了面向抽象編程的地方,比如分詞器,查詢),提供了比Lucene更為豐富的查詢語言(比如,過濾器),同時實作了可配置(跟hadoop整合,之前索引結構寫在代碼中,現在提前定義好)、可擴展并對查詢性能進行了優化,并且提供了一個完善的功能管理界面,是一款非常優秀的全文搜索引擎,
服務器 占用一個埠來提供服務 比如 可以加快取
Solr是一個獨立的企業級搜索應用服務器,它對外提供類似于Web-service的API介面,用戶可以通過http請求,向搜索引擎服務器提交一定格式的XML檔案,生成索引;也可以通過Http G SolrJ操作提出查找請求(也可以提交json格式),并得到XML格式的回傳結果,
2.Lucene簡介
Lucene是apache軟體基金會的一個專案,是一個開放源代碼的全文檢索引擎工具包,但它不是一個完整的全文檢索引擎,而是一個全文檢索引擎的架構,提供了完整的查詢引擎和索引引擎,部分文本分析引擎(英文與德文兩種西方語言),Lucene的目的是為軟體開發人員提供一個簡單易用的工具包,以方便的在目標系統中實作全文檢索的功能,或者是以此為基礎建立起完整的全文檢索引擎,Lucene是一套用于全文檢索和搜尋的開源程式庫,由Apache軟體基金會支持和提供,Lucene提供了一個簡單卻強大的應用程式介面,能夠做全文索引和搜尋,在Java開發環境里Lucene是一個成熟的免費開源工具,就其本身而言,Lucene是當前以及最近幾年最受歡迎的免費Java資訊檢索程式庫,
3.ES和Solr對比
ElasticSearch優點:
- Elasticsearch是分布式的,不需要其他組件,分發是實時的,被叫做”Push replication”,
- Elasticsearch 完全支持 Apache Lucene 的接近實時的搜索,
- 處理多租戶(multitenancy)不需要特殊配置,而Solr則需要更多的高級設定,
- Elasticsearch 采用 Gateway 的概念,使得完備份更加簡單,
- 各節點組成對等的網路結構,某些節點出現故障時會自動分配其他節點代替其進行作業
ElasticSearch缺點:
- 只有一名開發者(當前Elasticsearch GitHub組織已經不只如此,已經有了相當活躍的維護者)
- 還不夠自動(不適合當前新的Index Warmup API)
==============================================================
Solr優點:
- Solr有一個更大、更成熟的用戶、開發和貢獻者社區,
- 支持添加多種格式的索引,如:HTML、PDF、微軟 Office 系列軟體格式以及 JSON、XML、CSV 等純文本格式,
- Solr比較成熟、穩定,
- 不考慮建索引的同時進行搜索,速度更快,
Solr缺點:
- 建立索引時,搜索效率下降,實時索引搜索效率不高,
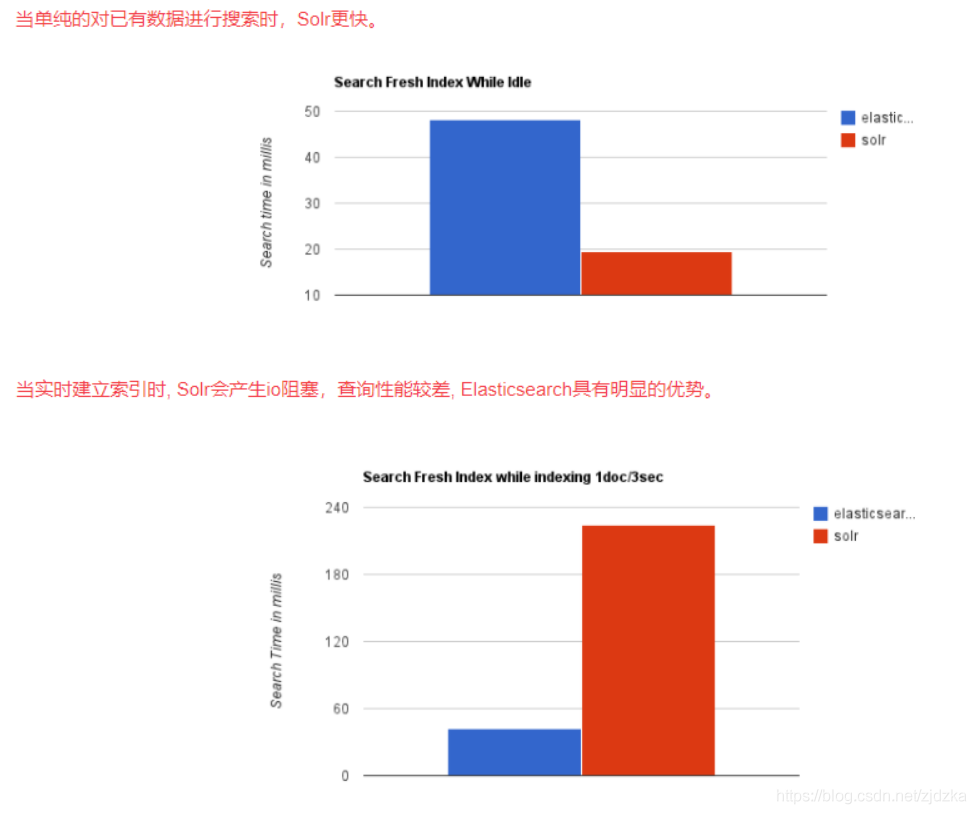
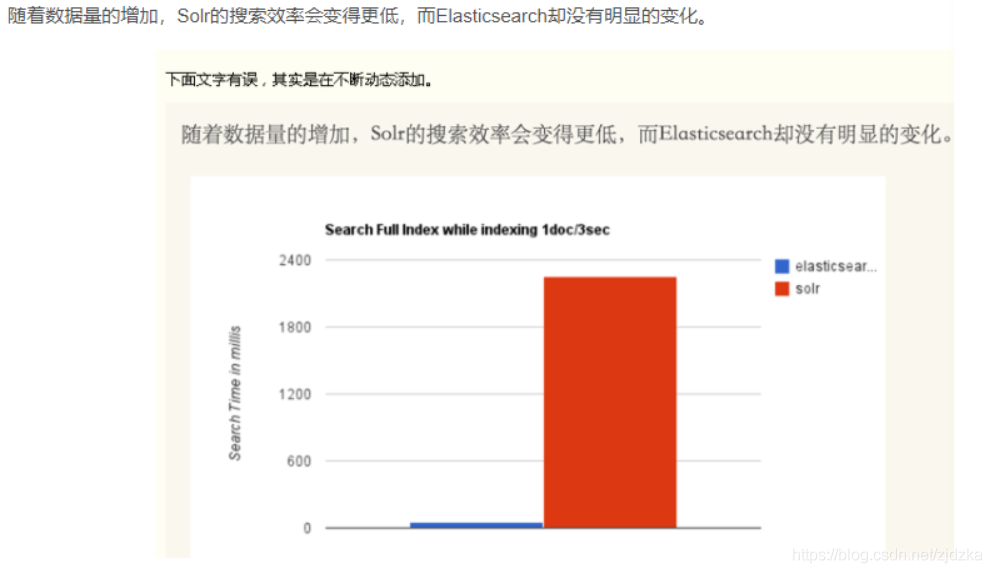
- 二者安裝都很簡單;
- Solr 利用 Zookeeper 進行分布式管理,而 Elasticsearch 自身帶有分布式協調管理功能;
- Solr 支持更多格式的資料,而 Elasticsearch 僅支持json檔案格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高級功能多有第三方插件提供;
- Solr 在傳統的搜索應用中表現好于 Elasticsearch,但在處理實時搜索應用時效率明顯低于 Elasticsearch,
三、安裝ES
宣告:JDK1.8以上—>最低要求
ES客戶端,頁面工具!----->基于java開發的和我們之后對應的java的核心jar包!版本對應!
1.下載:
https://www.elastic.co/cn/
先在windows下學習!
2.安裝:
解壓
熟悉目錄
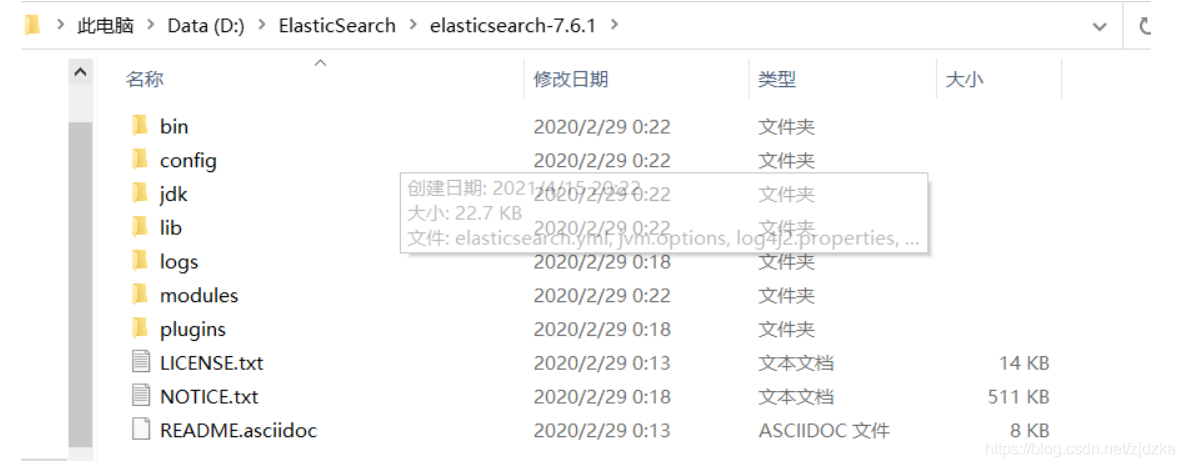
-
bin:啟動檔案
-
config:組態檔
- log4j2 日志組態檔
- jvm.options java虛擬機配置
- elasticsearch.yml es組態檔–>默認9200埠
-
jdk
-
lib 相關jar包
-
logs 日志
-
modules 功能模塊
-
plugins 插件!
啟動
雙擊bin目錄下的.bat檔案
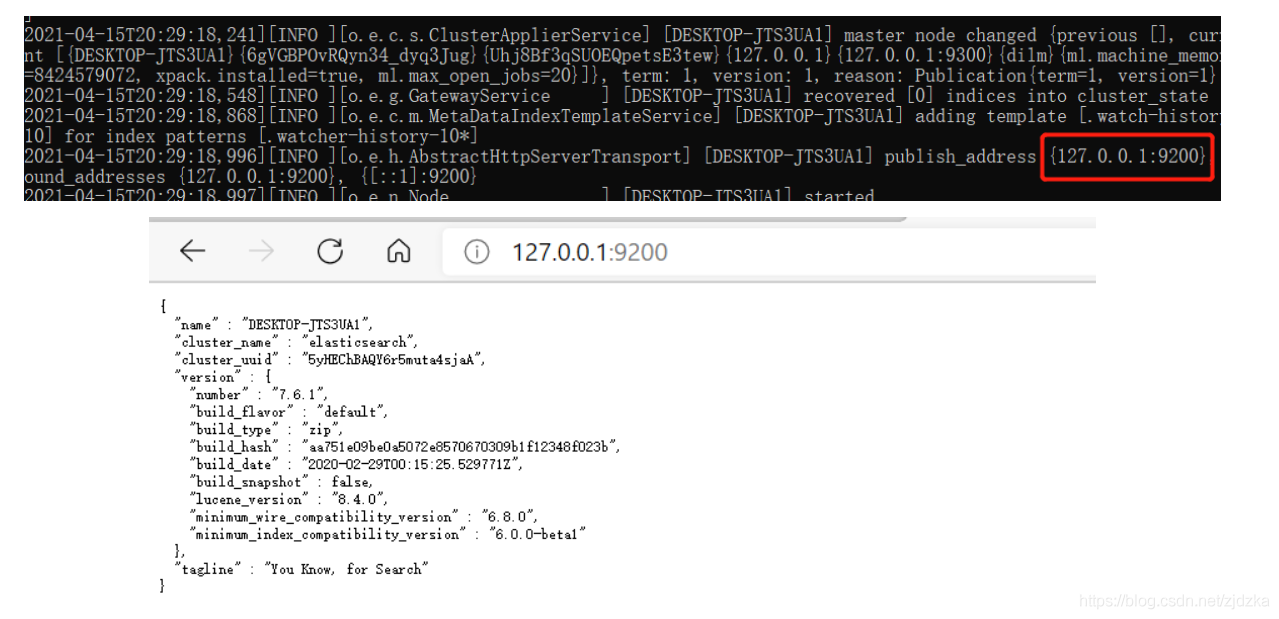
安裝可視化插件 head
發現問題:跨域問題,
可視化工具提供的埠是9100
而我們的ES則是9200,不互通
解決方法:在ES的組態檔中,修改跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
啟動測驗:cmd命令下–npm run start
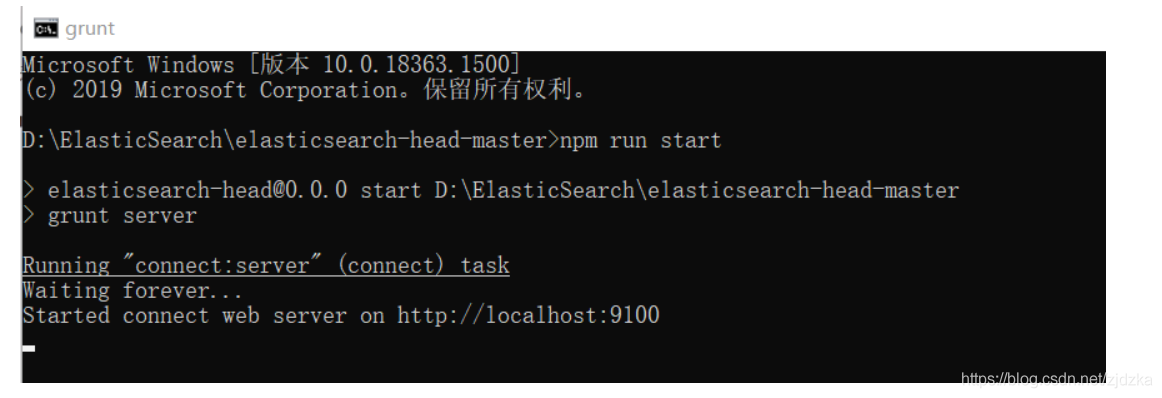
網頁測驗:
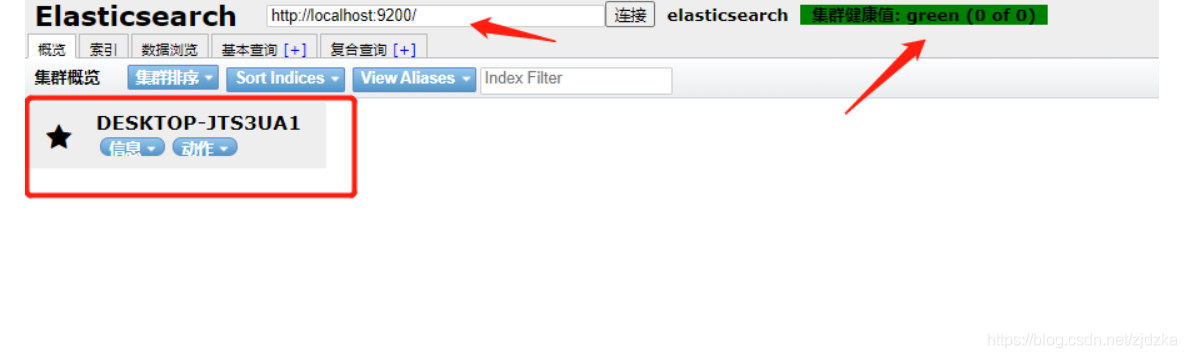
目前可以把ES的索引理解成資料庫!
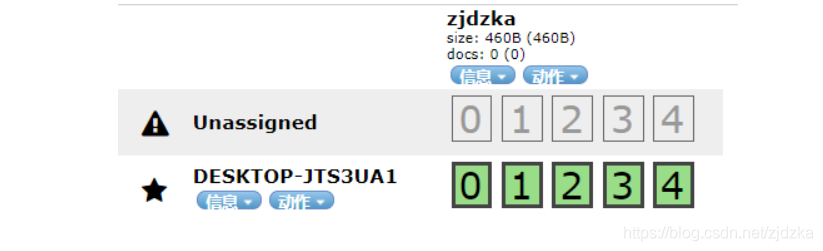
檔案就相當于庫中的資料!
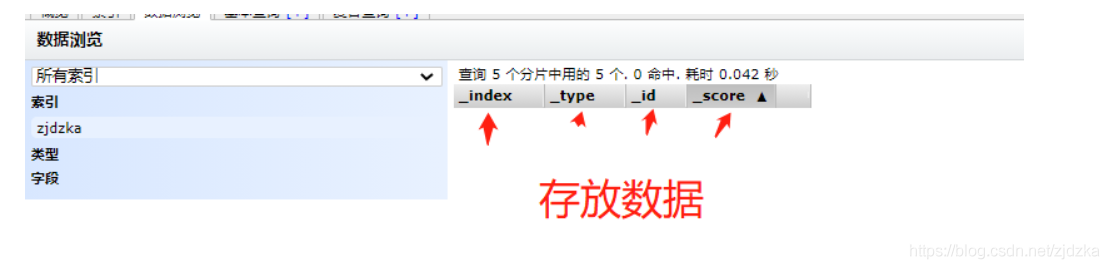
這個head我們就理解成資料展示工具
我們后面所有的查詢,可以去kibana去做
四、安裝Kibana
1.了解ELK
ELK 是elastic公司提供的一套完整的日志收集以及展示的解決方案,是三個產品的首字母縮寫,分別是ElasticSearch、Logstash 和 Kibana,
ElasticSearch簡稱ES,它是一個實時的分布式搜索和分析引擎,它可以用于全文搜索,結構化搜索以及分析,它是一個建立在全文搜索引擎 Apache Lucene 基礎上的搜索引擎,使用 Java 語言撰寫,
Logstash是一個具有實時傳輸能力的資料收集引擎,用來進行資料收集(如:讀取文本檔案)、決議,并將資料發送給ES,
Kibana為 Elasticsearch 提供了分析和可視化的 Web 平臺,它可以在 Elasticsearch 的索引中查找,互動資料,并生成各種維度表格、圖形,
2.安裝kibana
Kibana是一個開源的分析和可視化平臺,設計用于和Elasticsearch一起作業,
你用Kibana來搜索,查看,并和存盤在Elasticsearch索引中的資料進行互動,
你可以輕松地執行高級資料分析,并且以各種圖示、表格和地圖的形式可視化資料,
Kibana使得理解大量資料變得很容易,它簡單的、基于瀏覽器的界面使你能夠快速創建和共享動態儀表板,實時顯示Elasticsearch查詢的變化,
官網:https://www.elastic.co/cn/kibana
kibana版本必須和ES版本一致
目錄結構:
啟動:
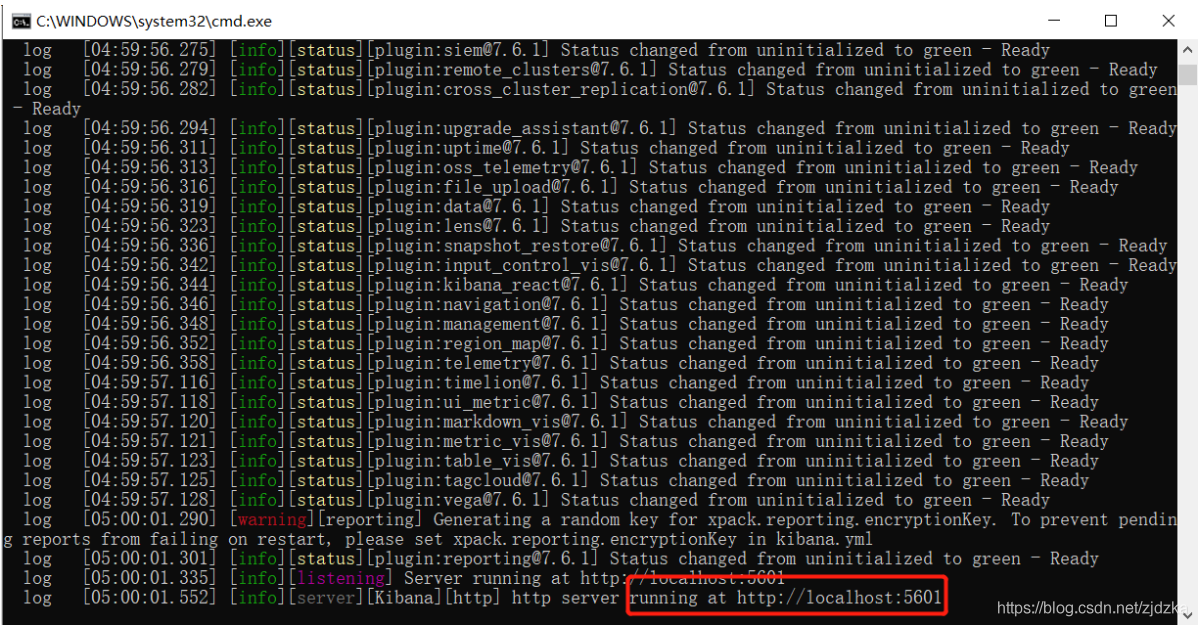
訪問測驗:
開發工具:
Post、curl、head、谷歌插件等
之后所有的操作都在這里進行撰寫!
漢化:
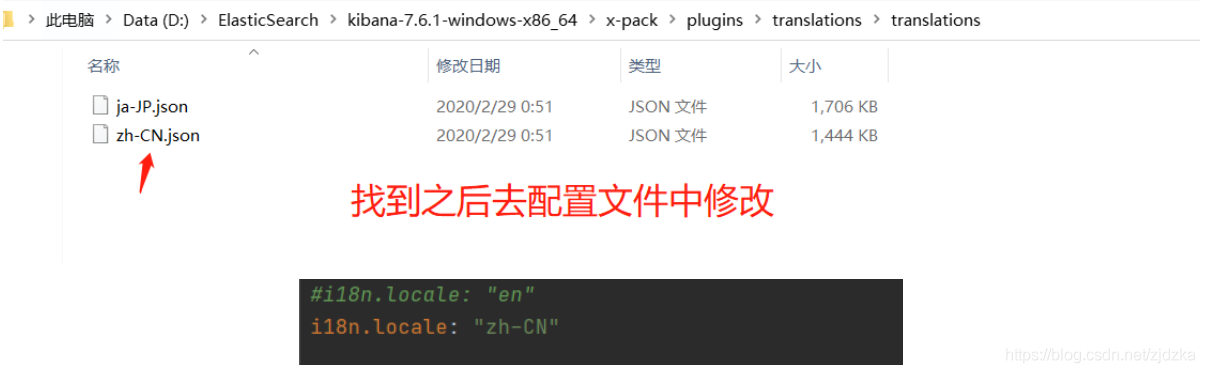
漢化后展示:
五、ES核心概念
集群,節點,索引,型別,檔案,分片,映射是什么?
elasticsearch是面向檔案,關系型資料庫和elasticsearch客觀的對比!一切都是json
| Relational DB | Elasticsearch |
|---|---|
| 資料庫(database) | 索引(indices) |
| 表(tables) | types |
| 行(rows) | documents |
| 欄位(columns) | fields |
物理設計:
elasticsearch在后臺把每個索引劃分成多個分片,每個分片可以在集群中的不同服務器間遷移
一個人就是一個集群!默認集群名就是elasticsearch
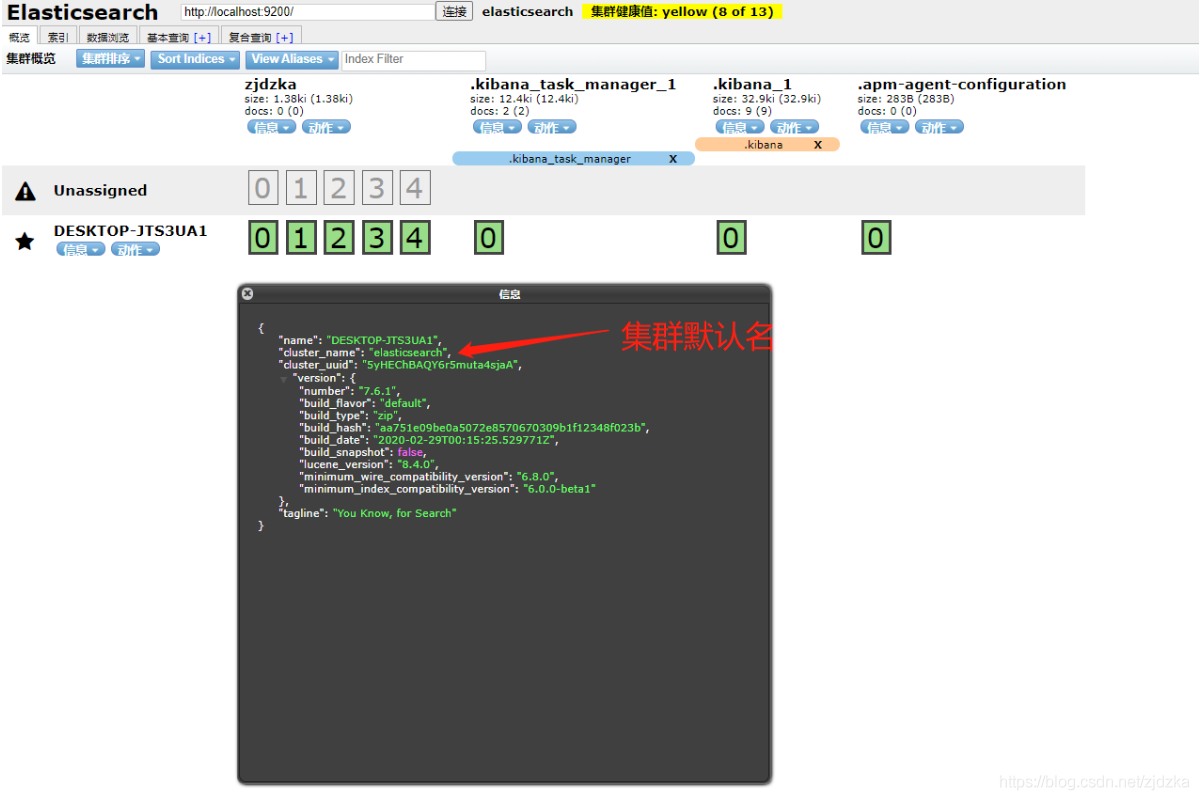
邏輯設計:
一個索引型別中,包含多個檔案,當我們索引一篇檔案時,可以通過這樣的一個順序找到它:索引-》型別-》檔案id,通過這個組合我們就能索引到某個具體的檔案,注意:ID不必是整數,實際上它是一個字串,
1.檔案
檔案
就是我們的一條條的記錄
之前說elasticsearch是面向檔案的,那么就意味著索引和搜索資料的最小單位是檔案, elasticsearch中,檔案有幾個重要屬性:
- 自我包含, 一篇檔案同時包含欄位和對應的值,也就是同時包含key:value !
- 可以是層次型的,一個檔案中包含自檔案,復雜的邏輯物體就是這么來的! {就是一 個json物件! fastjson進行自動轉換!}
- 靈活的結構,檔案不依賴預先定義的模式,我們知道關系型資料庫中,要提前定義欄位才能使用,在elasticsearch中,對于欄位是非常靈活的,有時候,我們可以忽略該欄位,或者動態的添加一個新的欄位,
盡管我們可以隨意的新增或者忽略某個欄位,但是,每個欄位的型別非常重要,比如一一個年齡欄位型別,可以是字串也可以是整形,因為elasticsearch會保存欄位和型別之間的映射及其他的設定,這種映射具體到每個映射的每種型別,這也是為什么在elasticsearch中,型別有時候也稱為映射型別,
2.型別
型別
型別是檔案的邏輯容器,就像關系型資料庫一樣,表格是行的容器,型別中對于欄位的定 義稱為映射,比如name映射為字串型別,我們說檔案是無模式的 ,它們不需要擁有映射中所定義的所有欄位,比如新增一個欄位,那么elasticsearch是怎么做的呢?elasticsearch會自動的將新欄位加入映射,但是這個欄位的不確定它是什么型別, elasticsearch就開始猜,如果這個值是18 ,那么elasticsearch會認為它是整形,但是elasticsearch也可能猜不對 ,所以最安全的方式就是提前定義好所需要的映射,這點跟關系型資料庫殊途同歸了,先定義好欄位,然后再使用,別整什么幺蛾子,
3.索引
索引
就是資料庫!
索引是映射型別的容器, elasticsearch中的索引是一個非常大的檔案集合,索引存盤了映射型別的欄位和其他設定,然后它們被存盤到了各個分片上了,我們來研究下分片是如何作業的,
物理設計:節點和分片如何作業
一個集群至少有一 個節點,而一個節點就是一-個elasricsearch行程 ,節點可以有多個索引默認的,如果你創建索引,那么索引將會有個5個分片( primary shard ,又稱主分片)構成的,每一個主分片會有-一個副本( replica shard ,又稱復制分片)
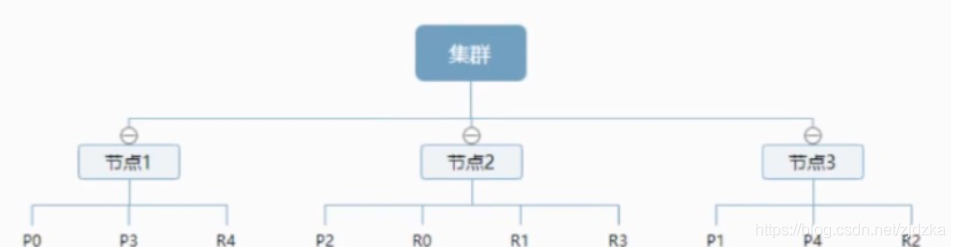
上圖是一個有3個節點的集群,可以看到主分片和對應的復制分片都不會在同-個節點內,這樣有利于某個節點掛掉了,資料也不至于丟失,實際上, 一個分片是一個Lucene索引, -一個包含倒排索引的檔案目錄,倒排索引的結構使得elasticsearch在不掃描全部檔案的情況下,就能告訴你哪些檔案包含特定的關鍵字,不過,等等,倒排索引是什么鬼?
4.倒排索引
倒排索引
elasticsearch使用的是一種稱為倒排索引 |的結構,采用Lucene倒排索作為底層,這種結構適用于快速的全文搜索,一個索引由文
檔中所有不重復的串列構成,對于每一個詞,都有一個包含它的檔案串列, 例如,現在有兩個檔案,每個檔案包含如下內容
Study every day, good good up to forever # 文 檔1包含的內容
To forever, study every day,good good up # 檔案2包含的內容
為創建倒排索引,我們首先要將每個檔案拆分成獨立的詞(或稱為詞潭訓者tokens) ,然后創建一一個包含所有不重 復的詞條的排序串列,然后列出每個詞條出現在哪個檔案:
| term | doc_1 | doc_2 |
|---|---|---|
| Study | √ | x |
| To | x | x |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | x | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | x |
| up | √ | √ |
現在,我們試圖搜索 to forever,只需要查看包含每個詞條的檔案
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | x |
| forever | √ | √ |
| total | 2 | 1 |
兩個檔案都匹配,但是第一個檔案比第二個匹配程度更高,如果沒有別的條件,現在,這兩個包含關鍵字的檔案都將回傳,
再來看一個示例,比如我們通過博客標簽來搜索博客文章,那么倒排索引串列就是這樣的一個結構:
| 博客文章(原始資料) | 博客文章(原始資料) | 索引串列(倒排索引) | 索引串列(倒排索引) |
| 博客文章ID | 標簽 | 標簽 | 博客文章ID |
| 1 | python | python | 1,2,3 |
| 2 | python | linux | 3,4 |
| 3 | linux,python | ||
| 4 | linux |
如果要搜索含有python標簽的文章,那相對于查找所有原始資料而言,查找倒排索引后的資料將會快的多,只需要查看標簽這一欄,然后獲取相關的文章ID即可,完全過濾掉無關的所有資料,提高效率!
elasticsearch的索引和Lucene的索引對比
在elasticsearch中,索引(庫)這個詞被頻繁使用,這就是術語的使用,在elasticsearch中 ,索引被分為多個分片,每份分片是一個Lucene的索引,所以一個elasticsearch索引是由多 個Lucene索引組成的,別問為什么,誰讓elasticsearch使用Lucene作為底層呢!如無特指,說起索引都是指elasticsearch的索引,
接下來的一切操作都在kibana中Dev Tools下的Console里完成,基礎操作!
5.總結
1.索引(資料庫)
2.欄位型別(可以理解為映射mapping)
3.檔案(資料)
4.采用分片的方式
六、IK分詞器插件
什么是IK分詞器?
分詞:即是把一段中文或者別的劃分成一個個的關鍵字,我們在搜索時候會把自己的資訊進行分詞,會把資料庫中或者索引庫中的資料進行分詞,然后進行一個匹配操作,默認的中文分詞是將每一個字看成一個詞,比如“我愛吃飯”---->會被分詞“我”,“愛”,“吃”,“飯”,這顯然是不符合要求的,所以我們需要安裝中文分詞器ik解決此問題
#ik提供了兩種分詞演算法
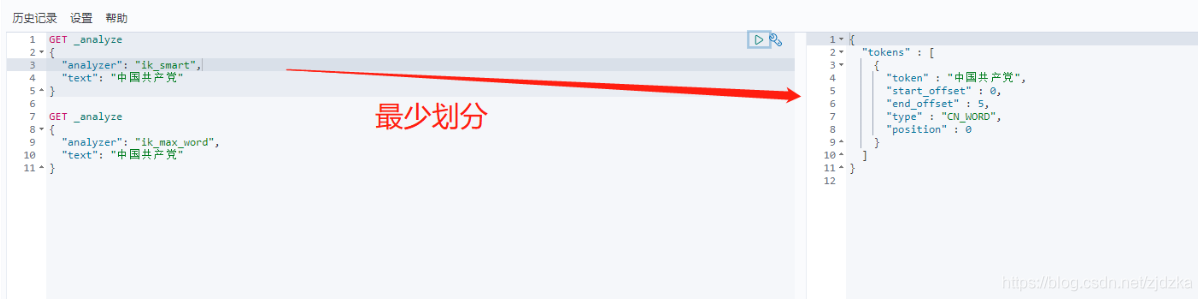
ik_smart #最少切分
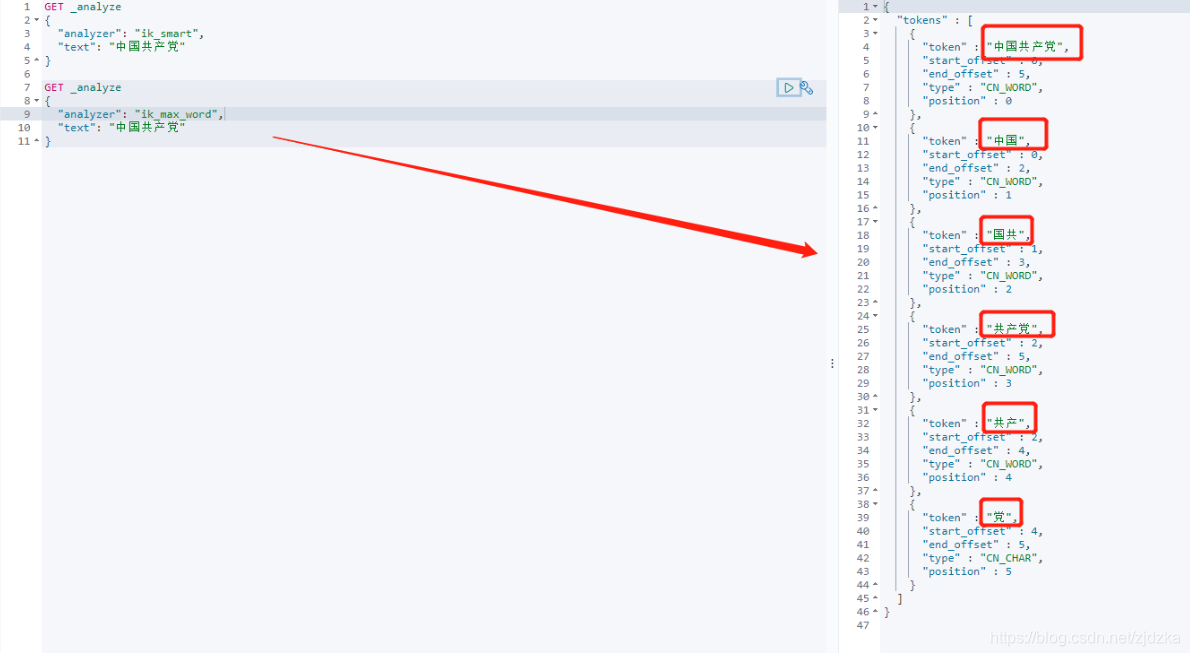
ik_max_word #最細粒度劃分
安裝
下載完畢之后,放入到es插件中即可
重啟觀察:

命令列測驗:

使用Kibana測驗:
ik_smart:
ik_max_word:
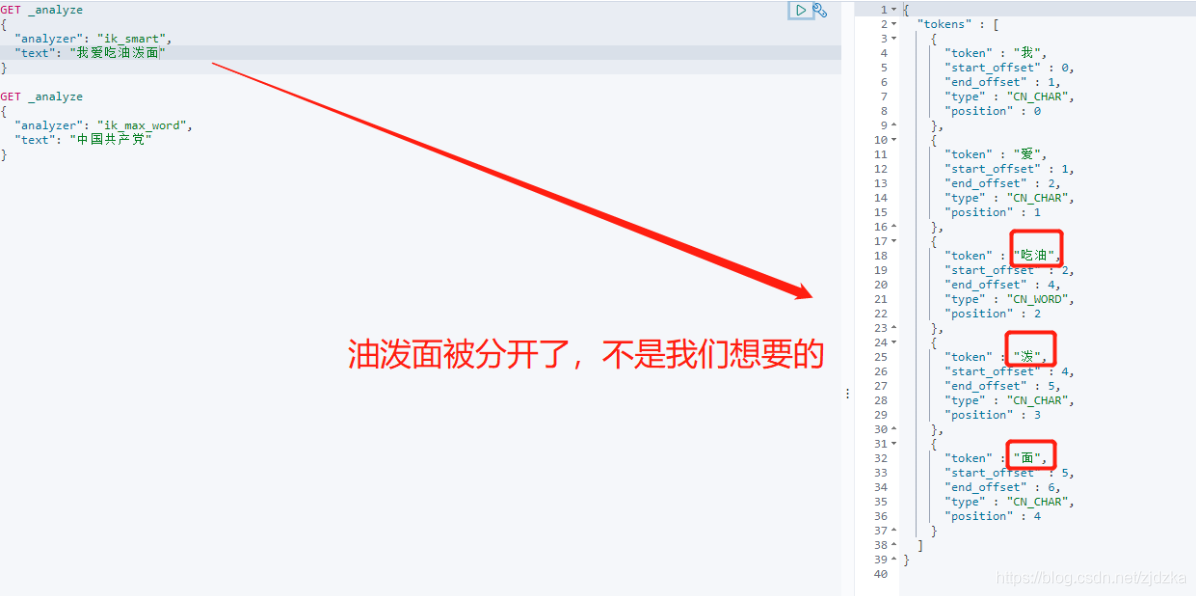
思考:當我們輸入一些其他詞匯時,可能會被拆開,不是我們想得到的,怎么辦呢?
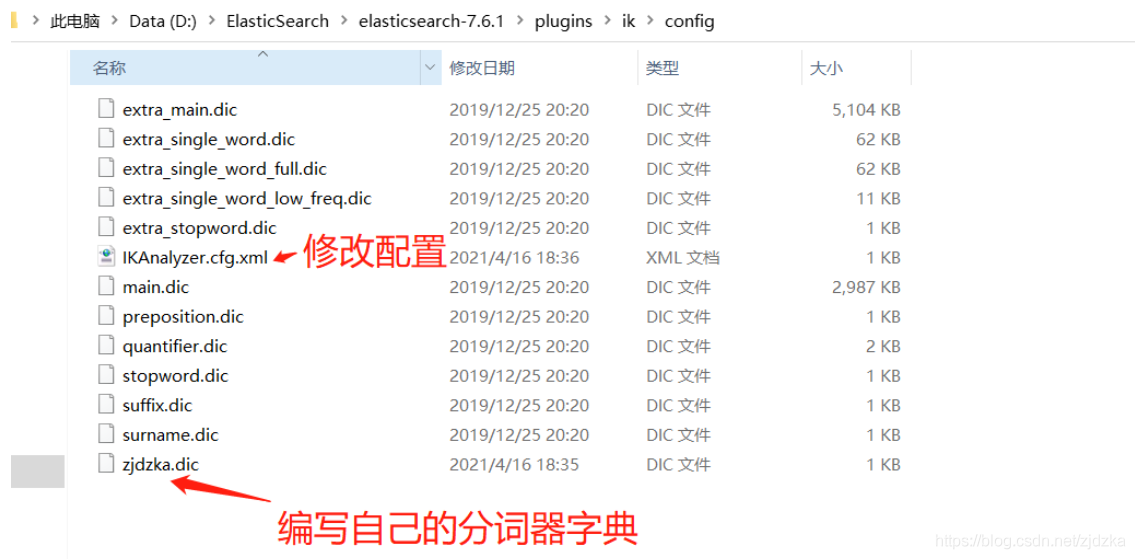
這種我們自己需要的詞,需要我們自己加到我們的分詞器的字典中
ik分詞器增加自己的配置
七、Rest風格-ES操作詳解
一種軟體架構風格,而不是標準,只是提供了一組設計原則和約束條件,它主要用于客戶端和服務器互動類的軟體,基于這個風格設計的軟體可以更簡潔,更有層次,更易于實作快取等機制
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名稱/型別名稱/檔案id | 創建檔案(指定檔案id) |
| POST | localhost:9200/索引名稱/型別名稱 | 創建檔案(隨機檔案id) |
| POST | localhost:9200/索引名稱/型別名稱/檔案id/_update | 修改檔案 |
| DELETE | localhost:9200/索引名稱/型別名稱/檔案id | 洗掉檔案 |
| GET | localhost:9200/索引名稱/型別名稱/檔案id | 通過檔案id查詢檔案 |
| POST | localhost:9200/索引名稱/型別名稱/_search | 查詢所有的資料 |
關于索引的操作
1.基本測驗
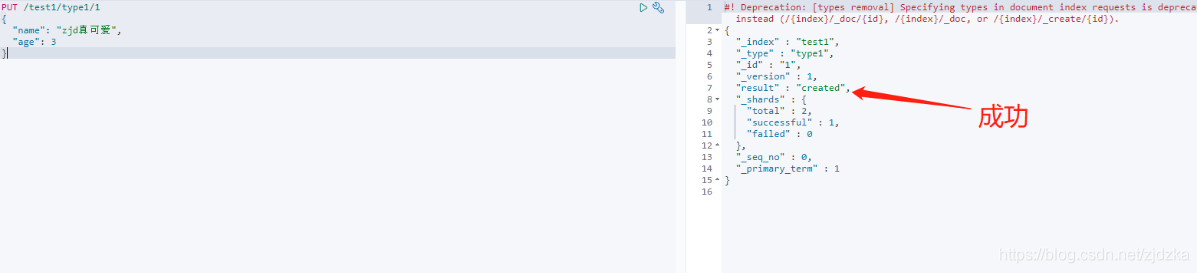
1.在kibana創建一個索引
PUT /索引名/型別名/檔案id
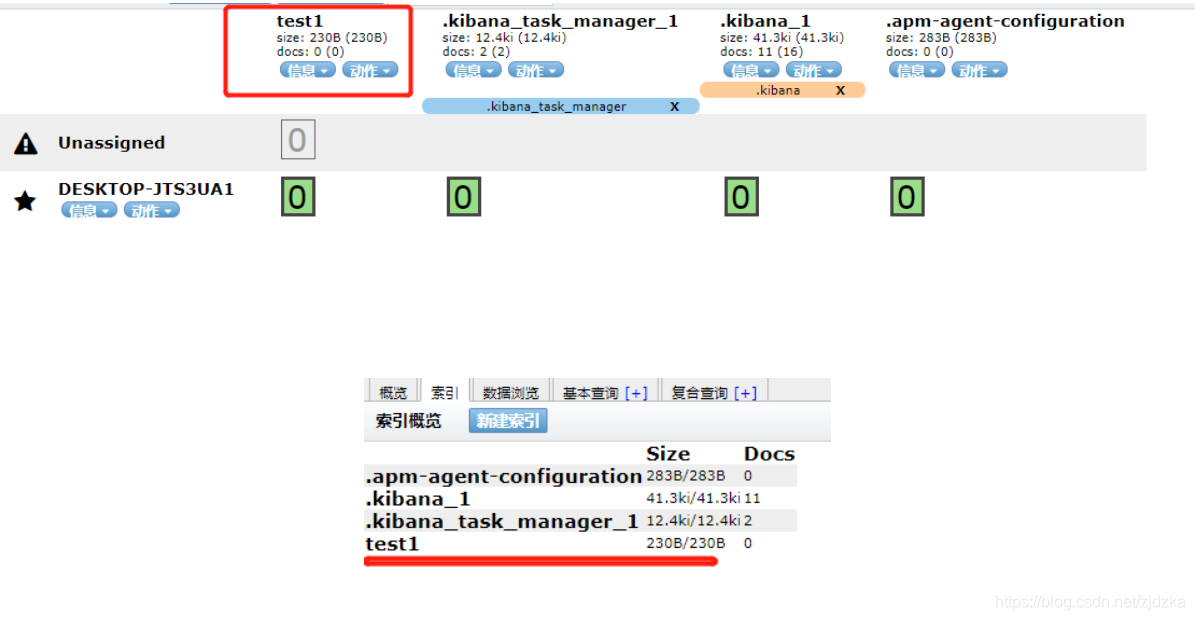
2.在head中查看
3.資料瀏覽:
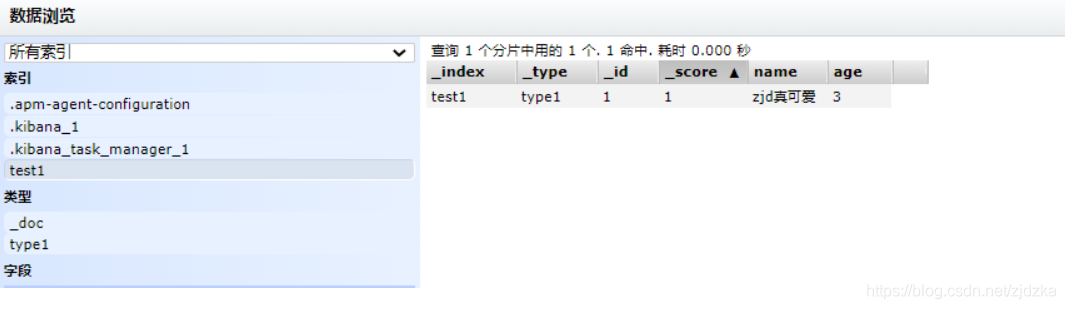
完成了自動添加索引!!!資料也成功的添加了!
擴展:欄位指定型別
- 字串型別
- text
- keyword
- 數值型別
- long、integer、short、byte、double、float、half float、scaled float
- 日期型別
- date
- 布林值型別
- boolean
- 二進制型別
- binary
- 等待……
具體使用可以查看官方檔案!
4.指定型別
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age" : {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
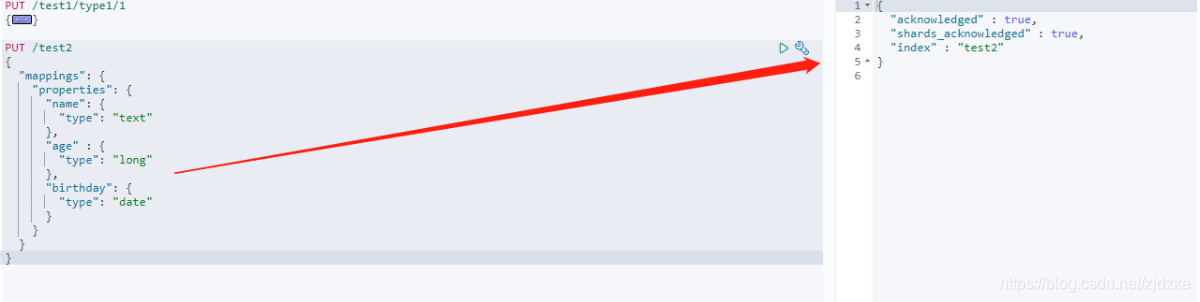
2.GET命令
獲得索引資訊:
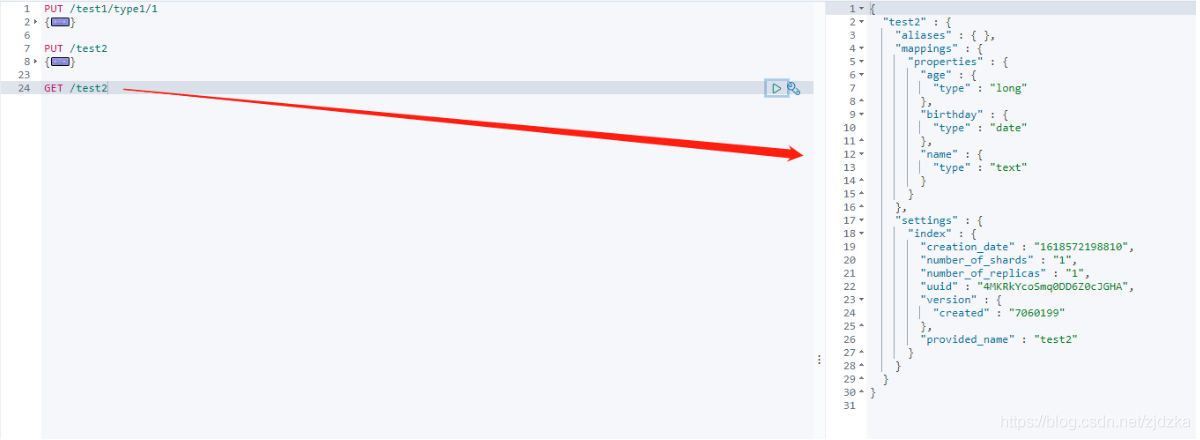
查看默認資訊:
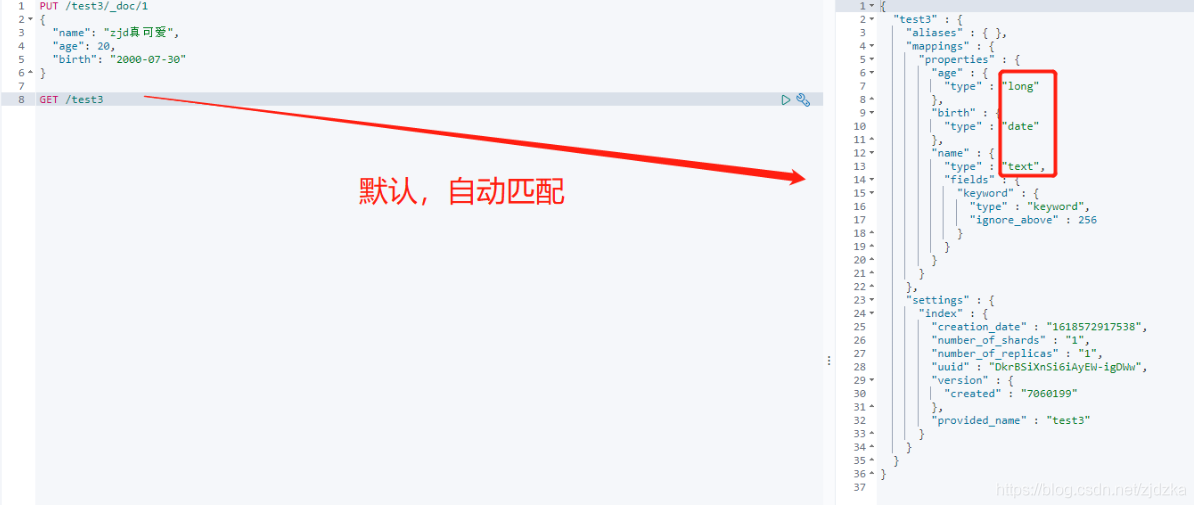
如果我們的檔案沒有指定欄位型別,那么我們的es就會自動匹配
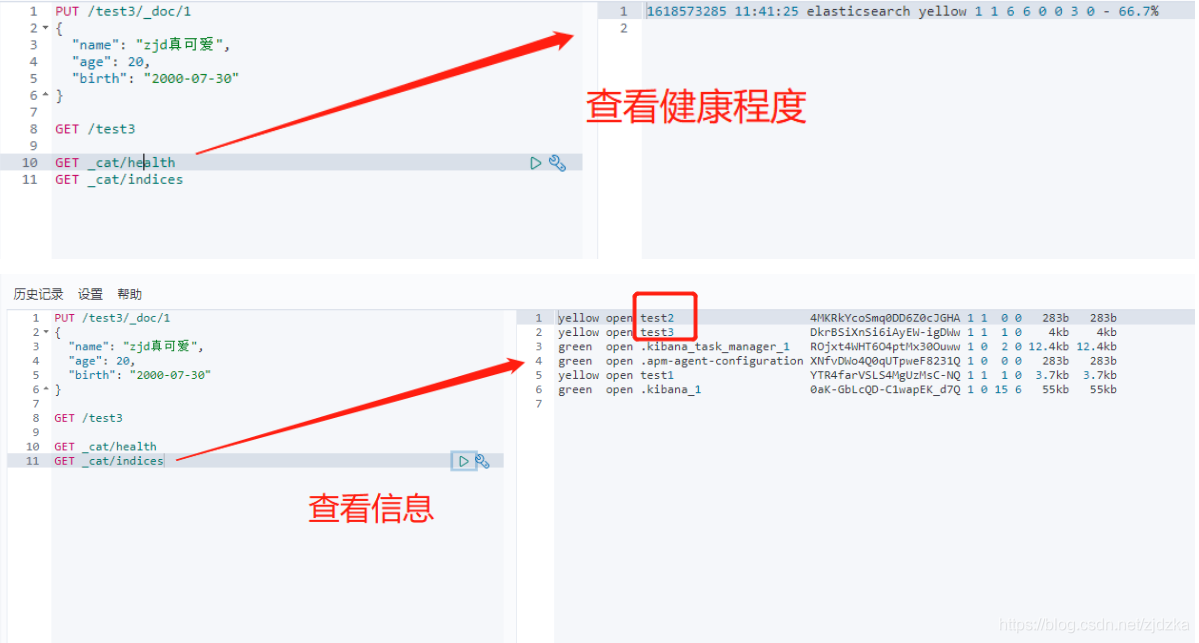
擴展:cat命令
GET _cat/
indices?v 查看es相關資訊
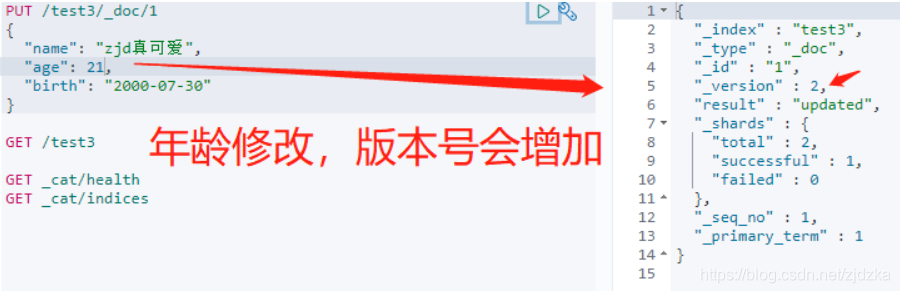
3.修改索引
方法1:PUT覆寫
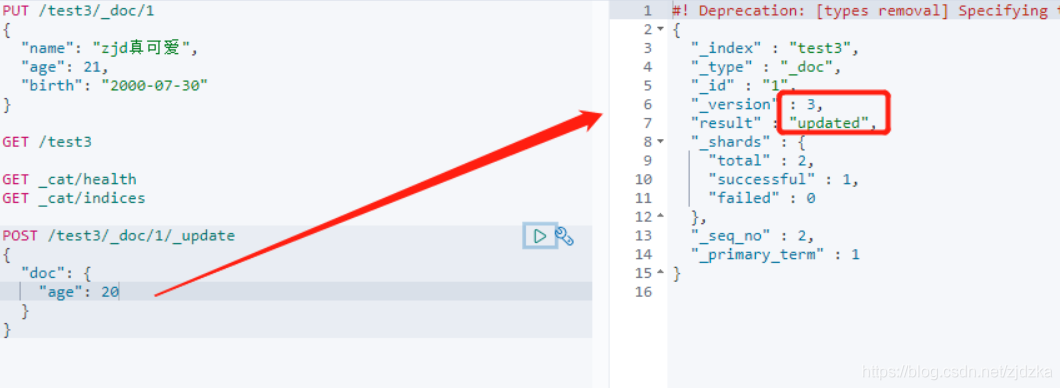
方法2 :update
4.洗掉檔案
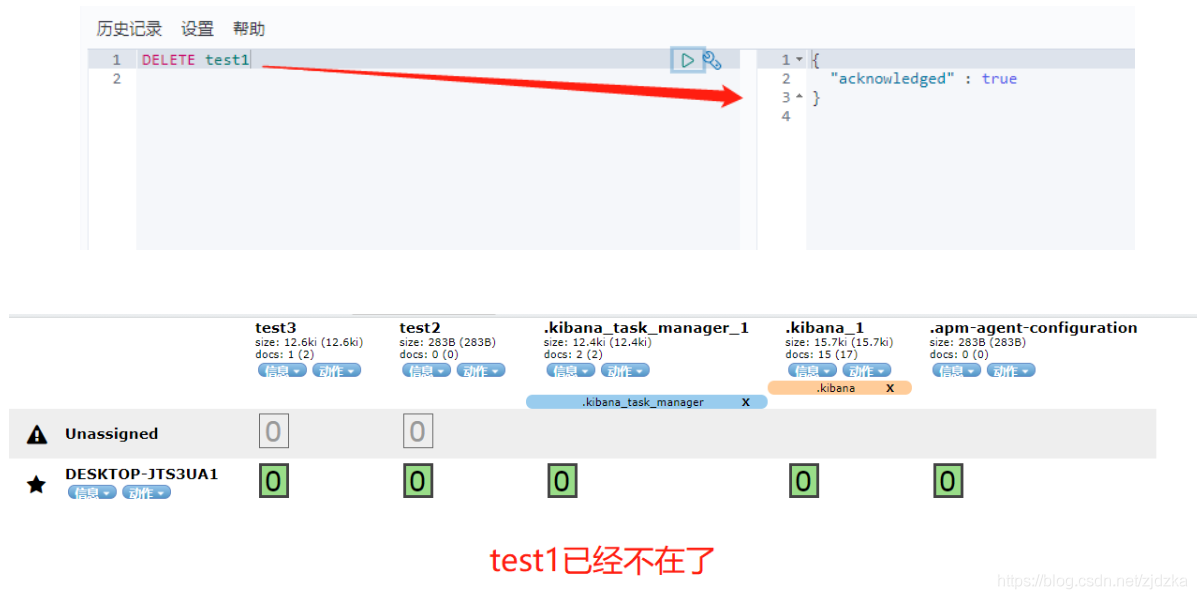
使用RestFul風格,是ES推薦使用的
關于檔案的操作
1.基本操作
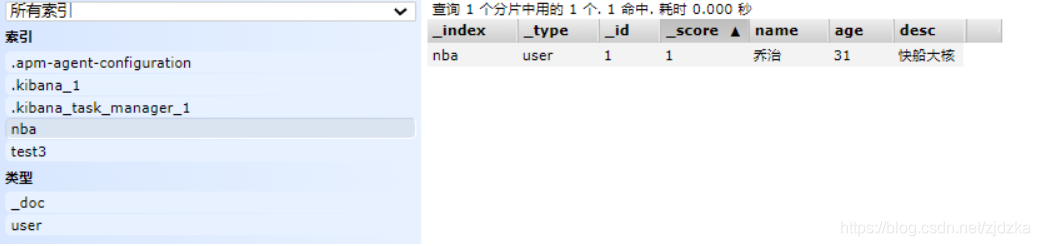
添加資料
PUT /nba/user/1
{
"name": "喬治",
"age": 31,
"desc": "快船大核",
"tags": ["三分","釣魚","扣籃"]
}
獲取資料
GET nba/user/1
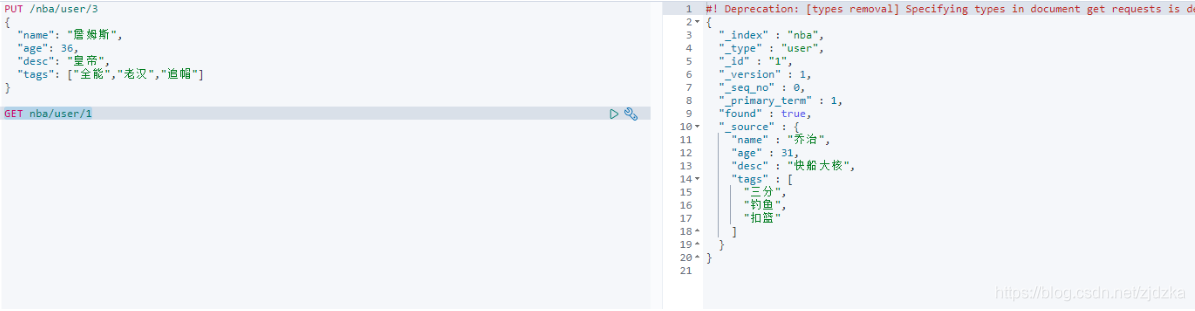
更新資料 PUT
推薦使用更新 POST _update
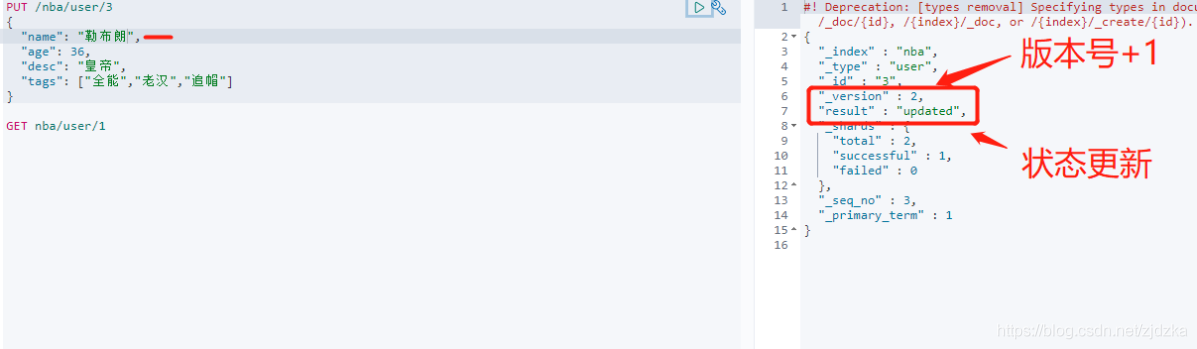
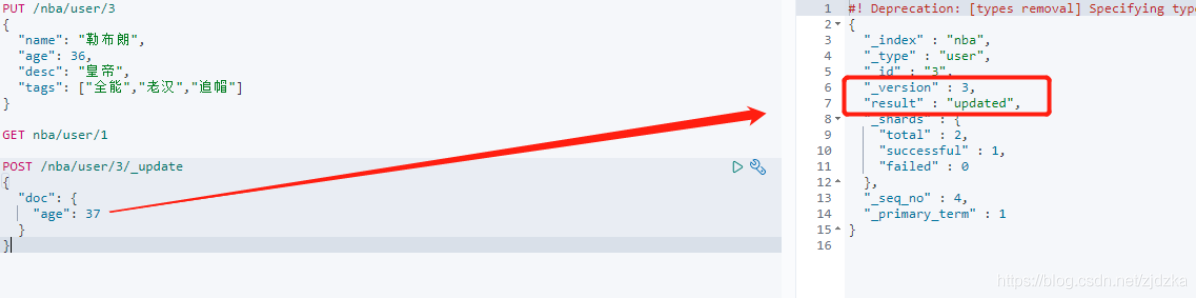
POST /nba/user/3/_update
{
"doc": {
"age": 37
}
}
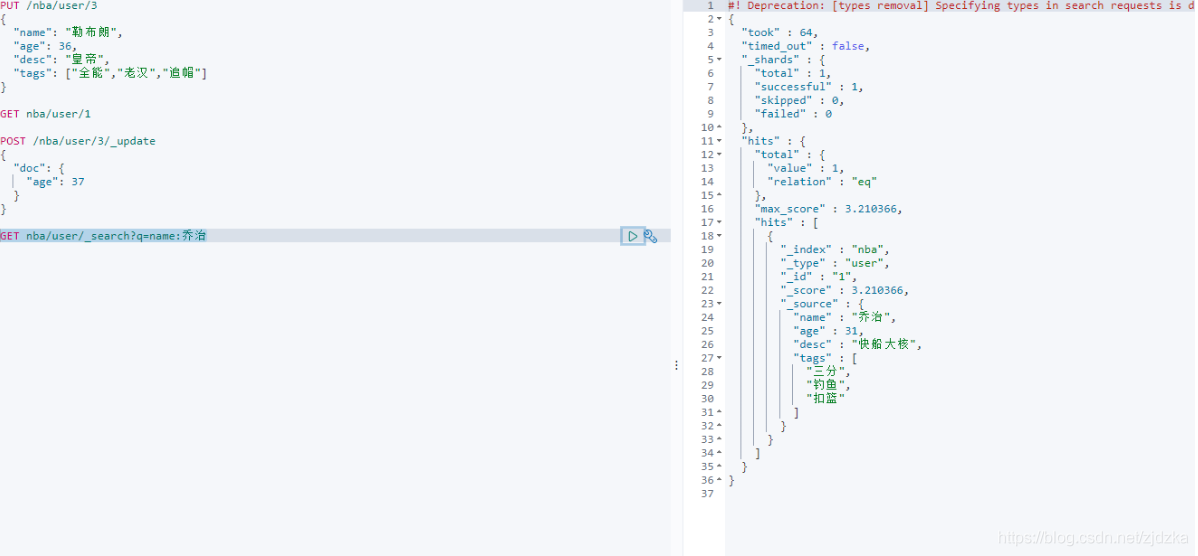
簡單條件搜索
GET nba/user/_search?q=name:喬治
2.復雜操作
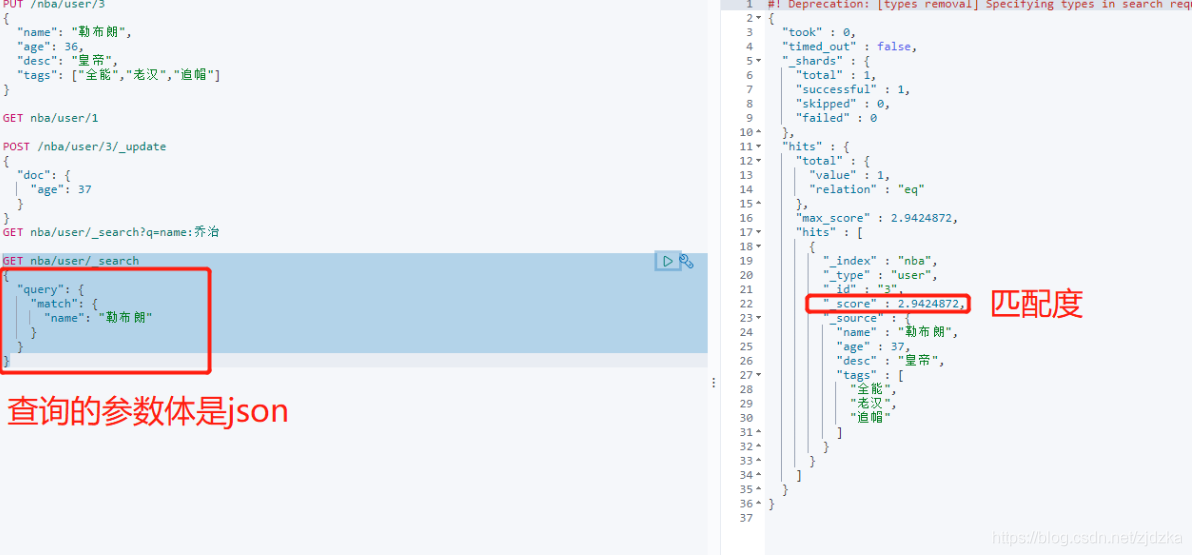
GET nba/user/_search
{
"query": {
"match": {
"name": "勒布朗"
}
}
}
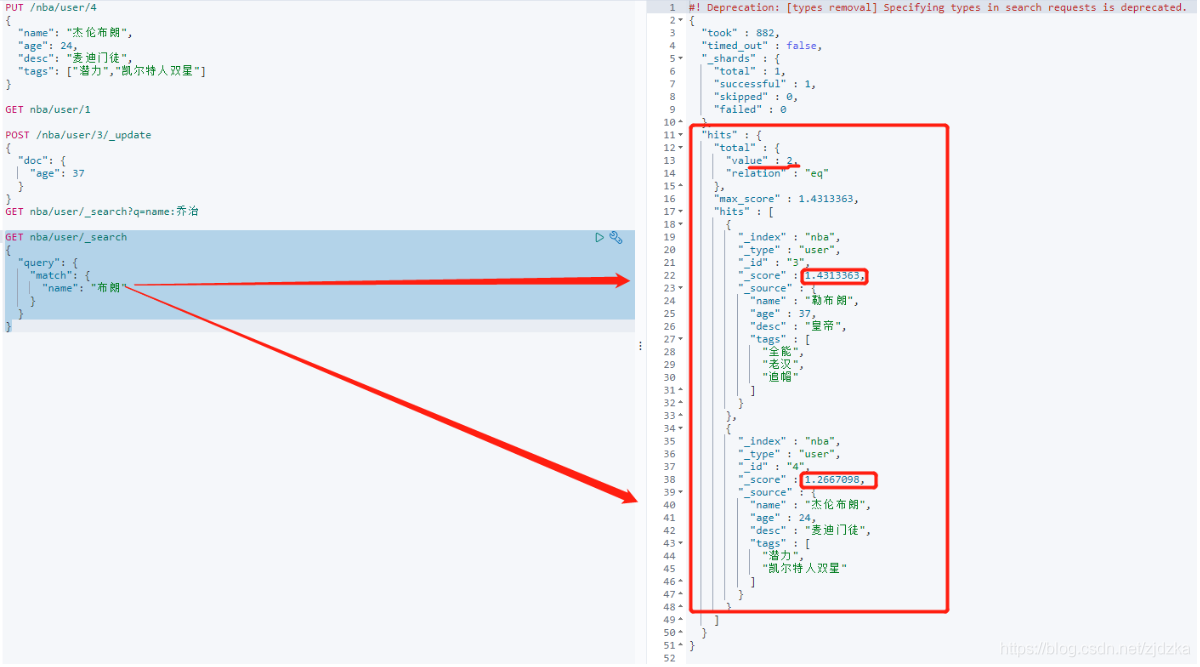
進階查詢
GET nba/user/_search
{
"query": {
"match": {
"name": "布朗"
}
}
}
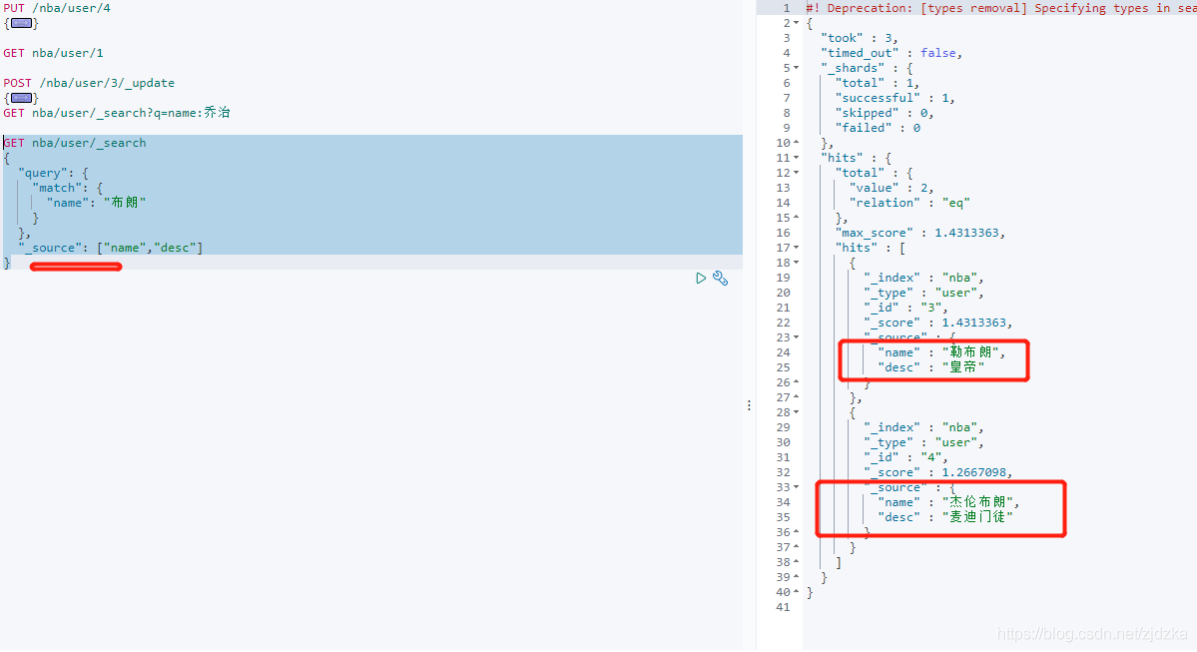
指定欄位查詢
GET nba/user/_search
{
"query": {
"match": {
"name": "布朗"
}
},
"_source": ["name","desc"]
}
我們之后使用java操作es,所有的方法和物件局輸這里面的key!
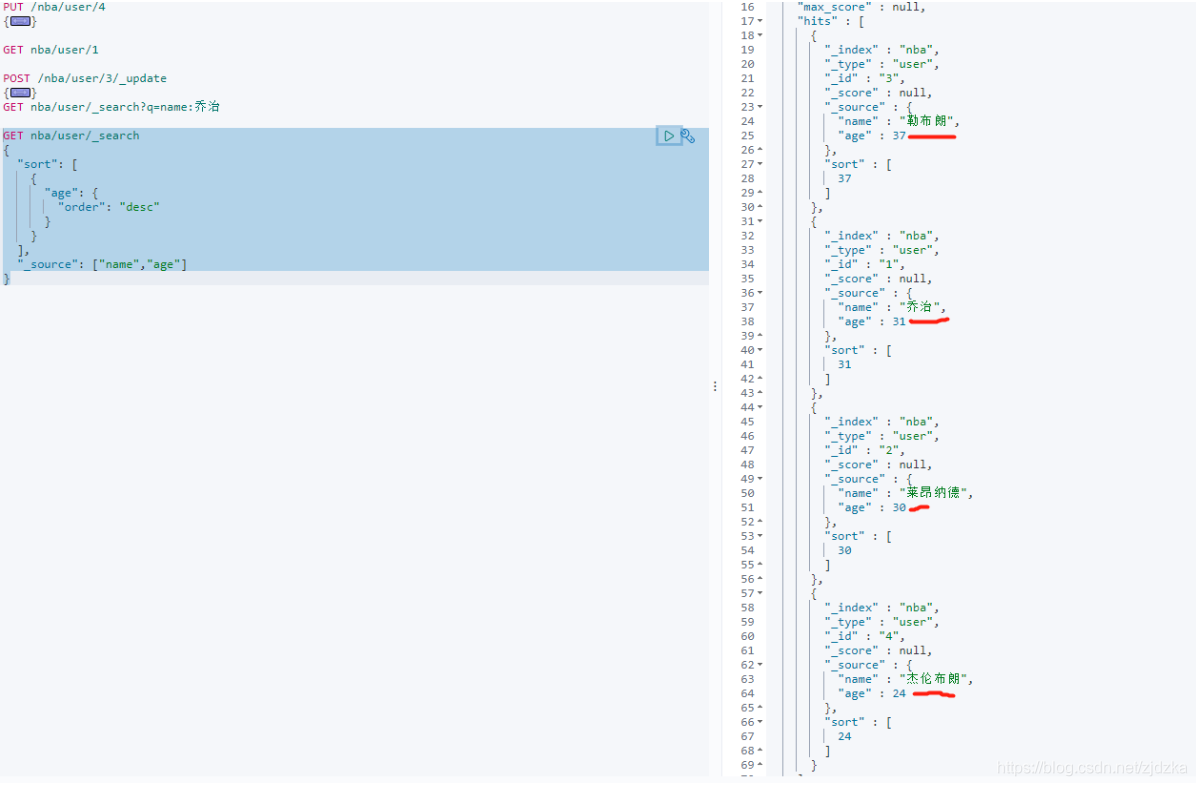
排序
GET nba/user/_search
{
"sort": [
{
"age": {
"order": "desc"
}
}
],
"_source": ["name","age"]
}
分頁查詢
GET nba/user/_search
{
"sort": [
{
"age": {
"order": "desc"
}
}
],
"_source": ["name","age"],
"from": 0,
"size": 2
}
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-nqfiaMpu-1618837828947)(C:\Users\24582\AppData\Roaming\Typora\typora-user-images\image-20210417134758860.png)]](https://img.uj5u.com/2021/04/20/2378042010511447.png)
布林值查詢
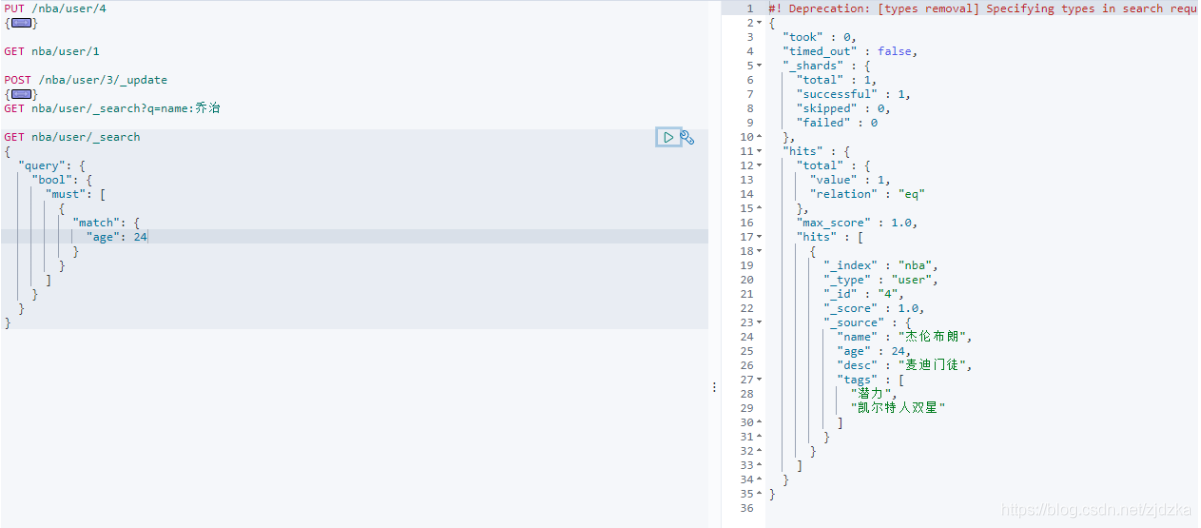
must (and),所有的條件都要符合
GET nba/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"age": 24
}
}
]
}
}
}
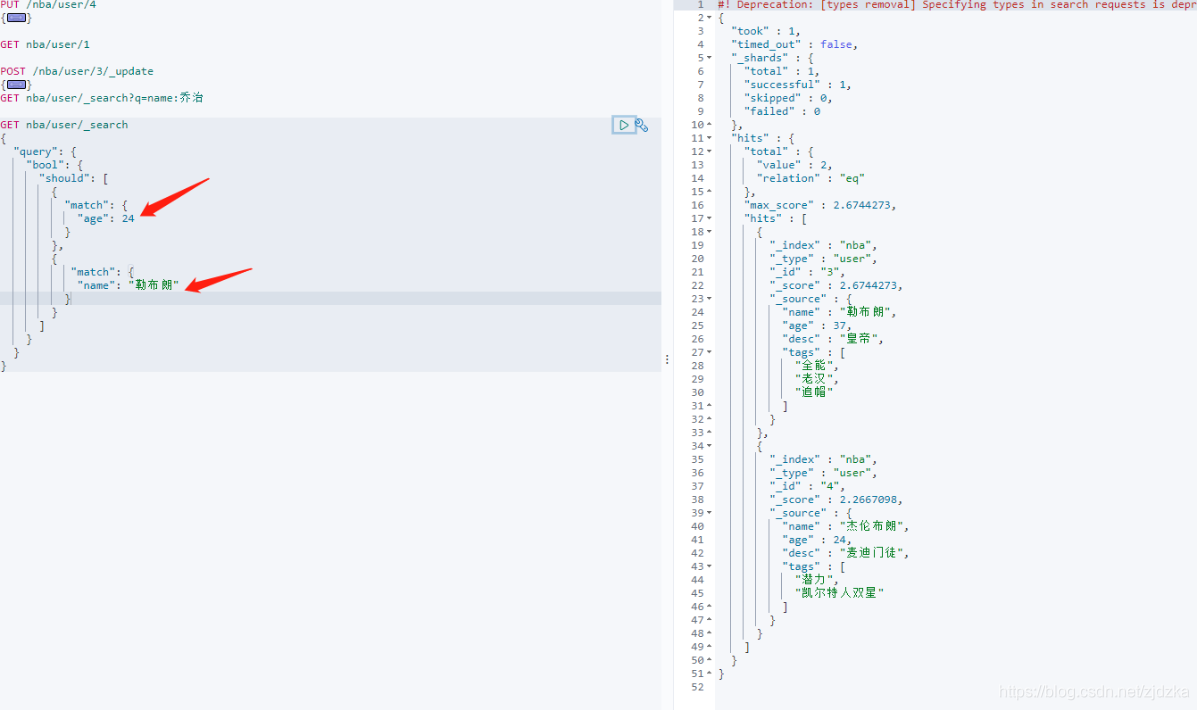
should(or),只要滿足一個就可
GET nba/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"age": 24
}
},
{
"match": {
"name": "勒布朗"
}
}
]
}
}
}
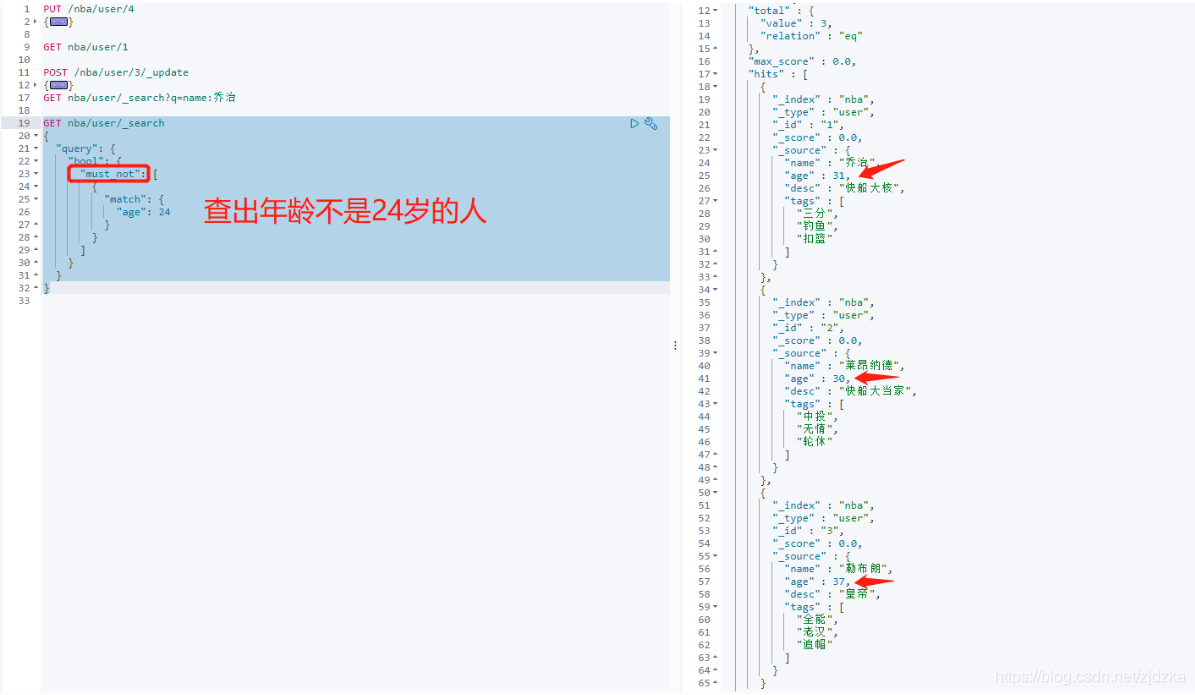
must_not(not)不等于
GET nba/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"age": 24
}
}
]
}
}
}
過濾器filter
GET nba/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "布朗"
}
}
],
"filter": {
"range": {
"age": {
"gt": 30,
"lt": 40
}
}
}
}
}
}
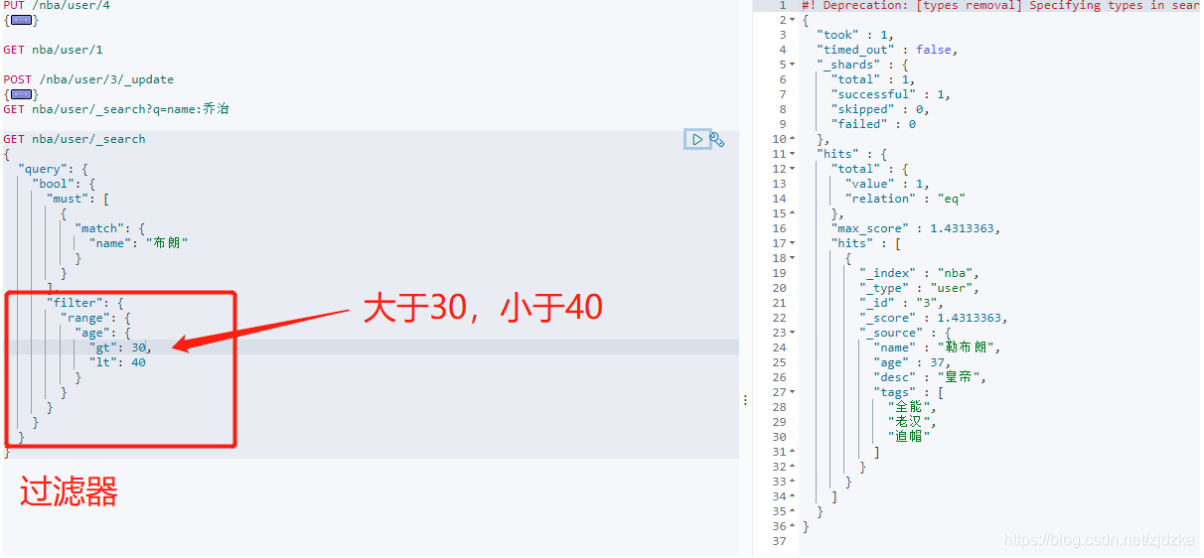
- gt 大于
- lt 小于
- gte大于等于
- lte小于等于
匹配多個搜索條件
GET nba/user/_search
{
"query": {
"match": {
"tags": "人 中"
}
}
}
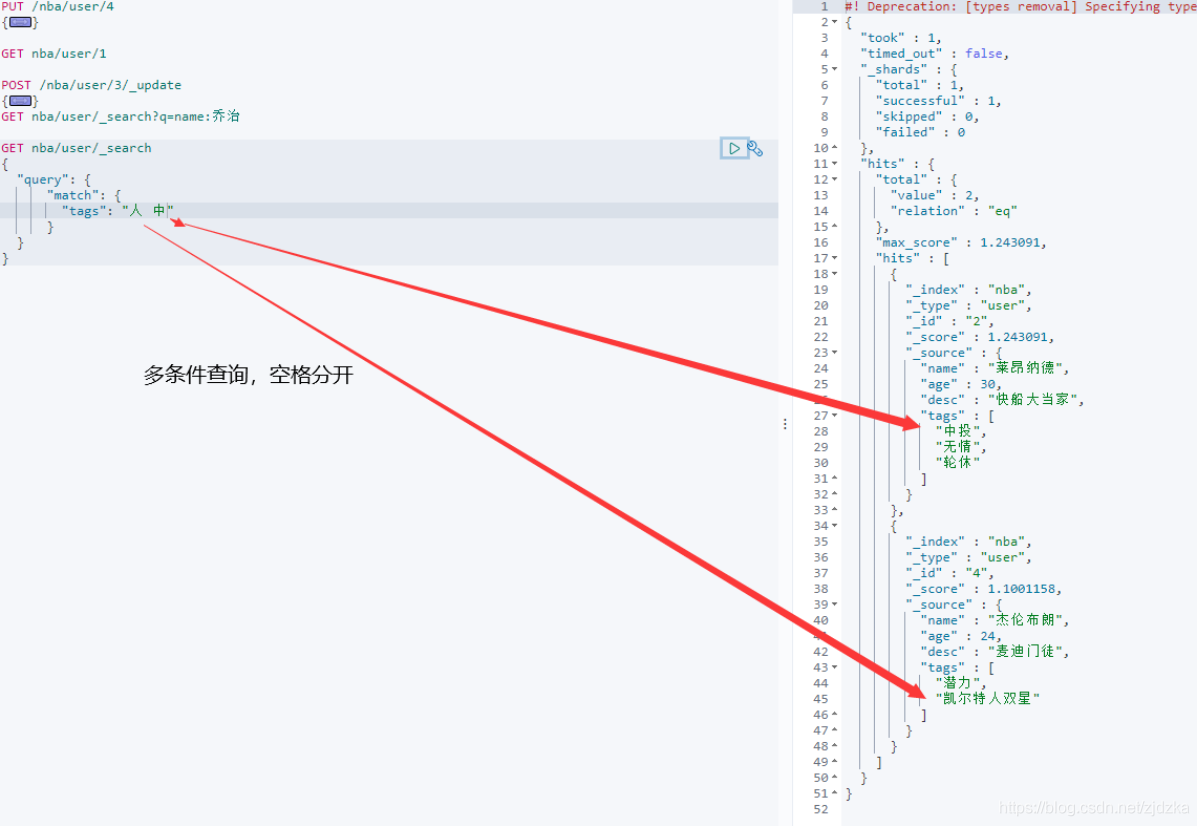
只要滿足其中一個結果即可回傳
精確查詢
term 查詢是直接通過倒排索引指定的詞條進行精確的查找
關于分詞:
-
term,直接查找精確的值
-
match,會使用分詞器決議(分析檔案在查詢)
兩個型別:
-
text:text型別可以被分詞器決議
-
key-word:不能被分詞器決議,整個詞
// 建一個索引,并指定型別
PUT testdb
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"desc":{
"type": "keyword"
}
}
}
}
//添加一條資料
PUT testdb/_doc/1
{
"name": "zjdzka 編程",
"desc": "zjdzka 學習"
}
PUT testdb/_doc/1
{
"name": "zjdzka 編程",
"desc": "zjdzka 學習2"
}
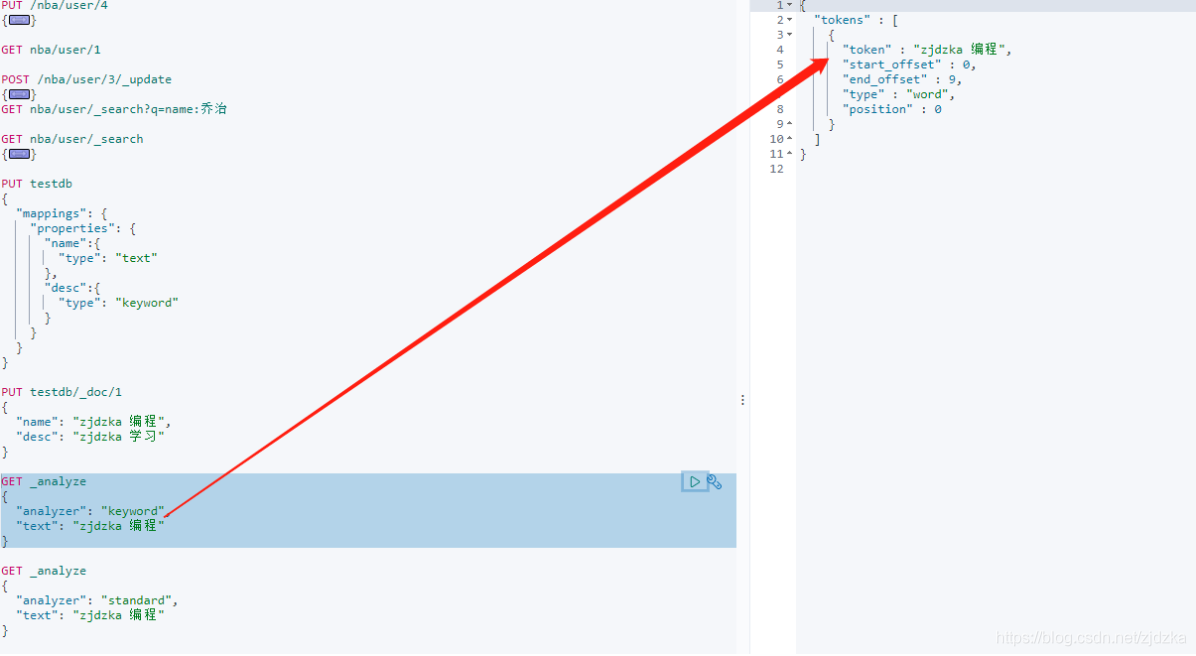
//查詢,采用keyword
GET _analyze
{
"analyzer": "keyword",
"text": "zjdzka 編程"
}
//查詢,采用分詞器
GET _analyze
{
"analyzer": "standard",
"text": "zjdzka 編程"
}
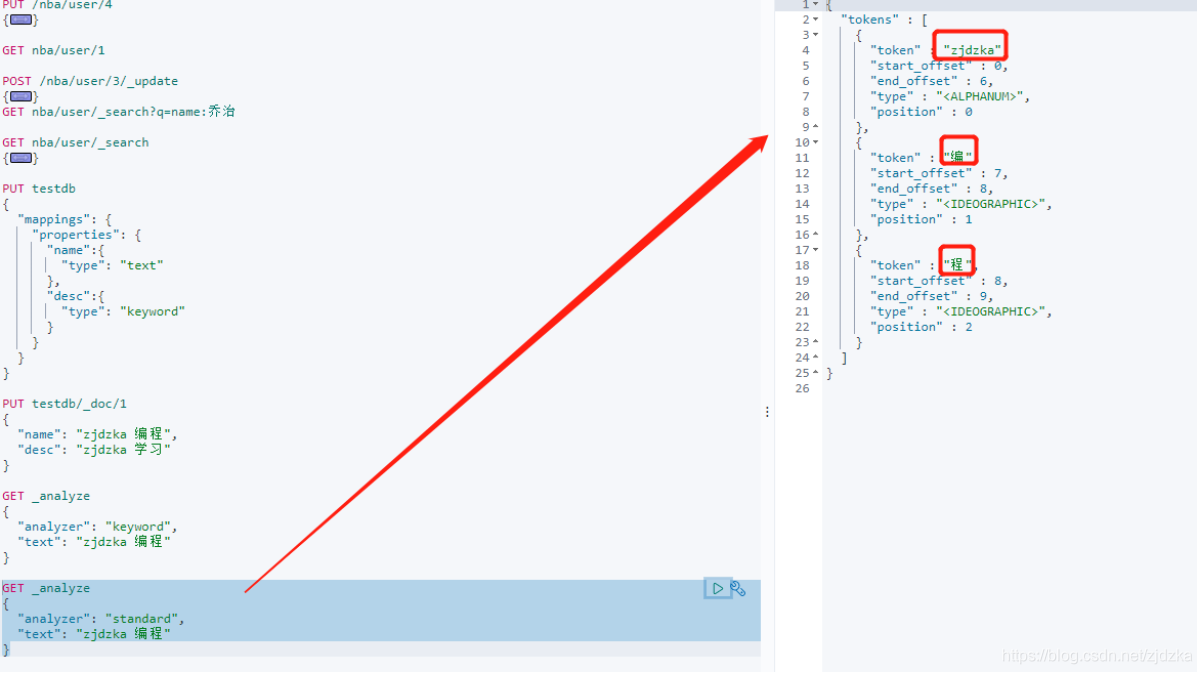
精確term案例
GET testdb/_search
{
"query": {
"term": {
"desc": "zjdzka 學習"
}
}
}
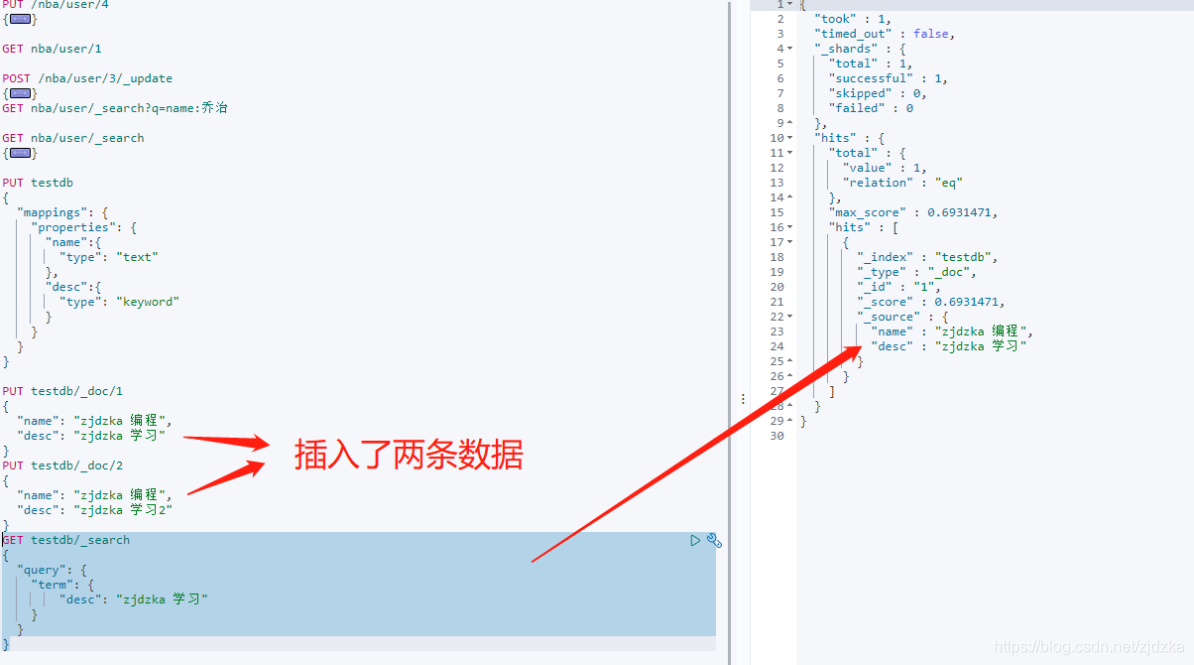
總結:因為desc欄位采用的是keyword型別,所以zjdzka 學習 和zjdzka 學習2被識別為兩個詞匯,因此查詢只能查出一個
多個值匹配的精確查詢
PUT testdb/_doc/5
{
"t1": "哈哈哈",
"t2": "22"
}
PUT testdb/_doc/6
{
"t1": "嘻嘻嘻",
"t2": "33"
}
//查詢
GET testdb/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t2": "22"
}
},
{
"term": {
"t2": "33"
}
}
]
}
}
}
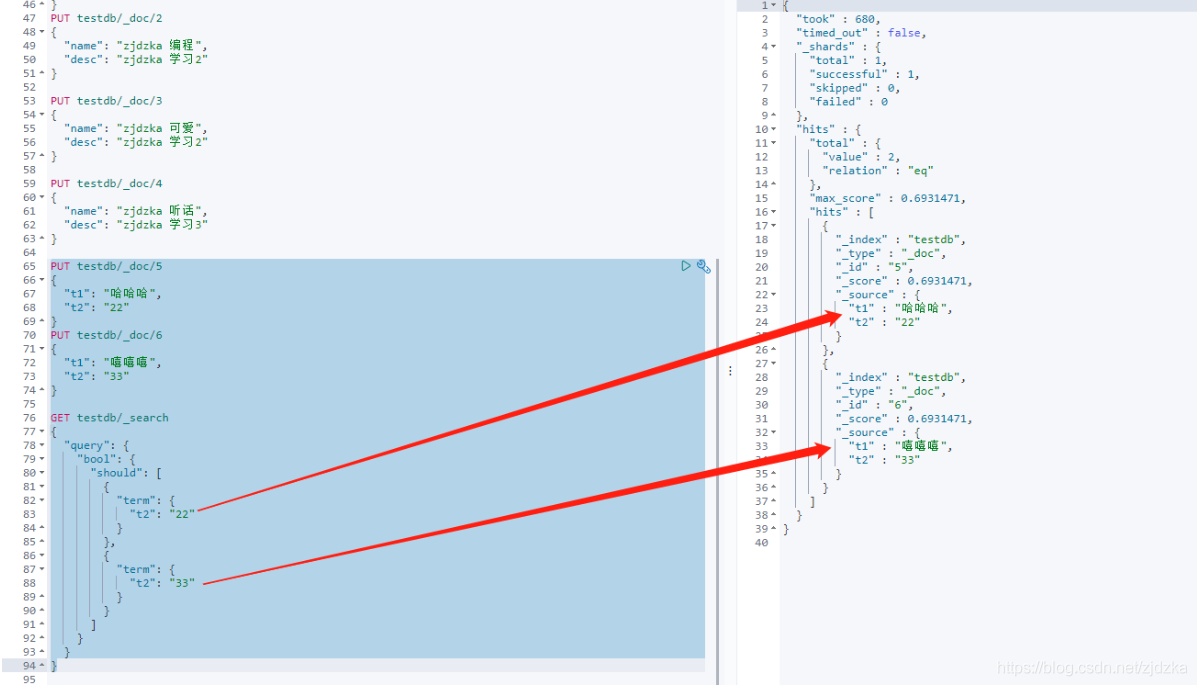
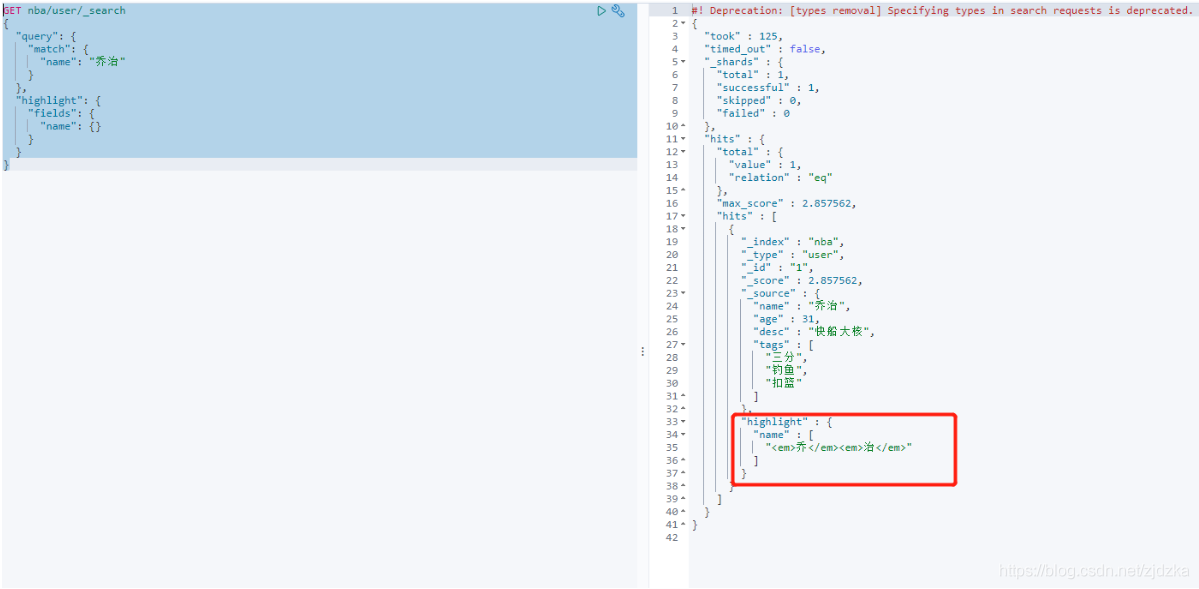
高亮查詢
GET nba/user/_search
{
"query": {
"match": {
"name": "喬治"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
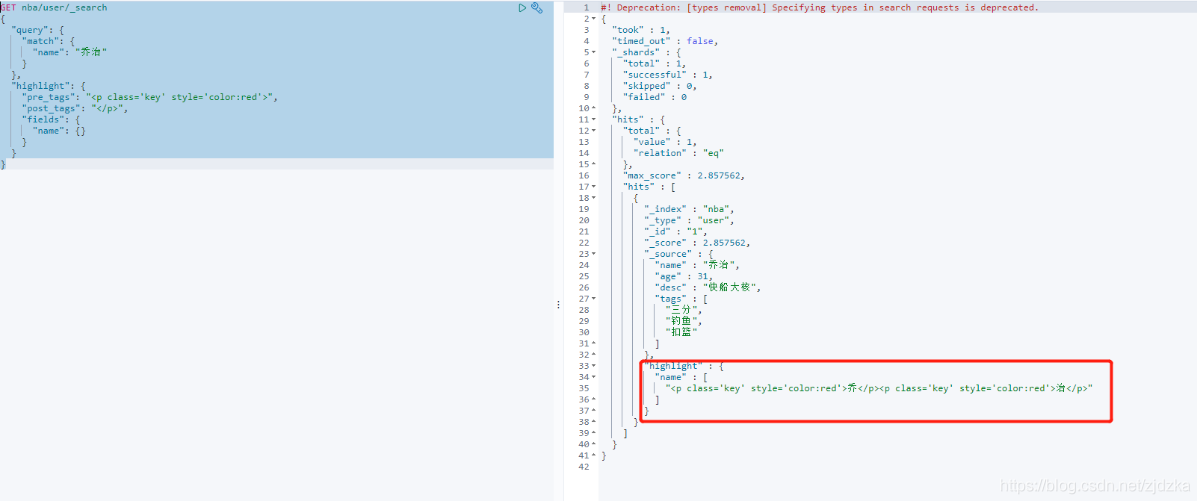
自定義高亮:
//自定義高亮
GET nba/user/_search
{
"query": {
"match": {
"name": "喬治"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
查詢總結
- 匹配
- 按照條件查詢
- 精確匹配
- 區間范圍匹配
- 匹配欄位過濾
- 多條件查詢
- 高亮查詢
其實Mysql也可以實作,只是ES效率更高效
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278050.html
標籤:其他