7-7 社交集群 (30 分)
當你在社交網路平臺注冊時,一般總是被要求填寫你的個人興趣愛好,以便找到具有相同興趣愛好的潛在的朋友,一個“社交集群”是指部分興趣愛好相同的人的集合,你需要找出所有的社交集群,
輸入格式:

輸出格式:
首先在一行中輸出不同的社交集群的個數,隨后第二行按非增序輸出每個集群中的人數,數字間以一個空格分隔,行末不得有多余空格,
輸入樣例:
8
3: 2 7 10
1: 4
2: 5 3
1: 4
1: 3
1: 4
4: 6 8 1 5
1: 4
輸出樣例:
3
4 3 1
這道題的愛好是一個可變的集合,我們通過列舉人的愛好更新這個集合并記錄這個集合中的人數,通過并查集更新連通塊的時候用一個a陣列記錄每個人的第一個愛好作為標記,相當于這個人最后拿著這個標記作為信號跟有緣人走到一起,形成一個社交集群,
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
int n,x,y,k=0;
int p[1010];
int a[1010];
int cnt[1010];
int vis[1010];
int ans=0,mx=-1;//連通塊個數,列舉的最多數量(當然也可以列舉到1010)
int find(int x)
{
if(p[x]!=x) return p[x]=find(p[x]);
else return x;
}
bool cmp(int a,int b)
{
return a>b;
}
int main()
{
cin>>n;
for(int i=1;i<=1010;i++) p[i]=i;//開始沒有記錄最大值,只能初始化到邊界
for(int i=1;i<=n;i++)//8個人
{
string op;
cin>>op>>y;
a[i]=y;//記錄每個人第一個愛好,以統計連通塊人數
if(mx<y) mx=y;
x=op[0]-'0';
x-=1;
while(x--)
{ int pp;
cin>>pp;
if(pp>mx) mx=pp;
int a=find(y);
int b=find(pp);
if(a!=b)
{
p[a]=b;
}
}
}
for(int i=1;i<=n;i++)//8個人
{
int t=find(a[i]);//指向每個連通塊的終點
cnt[t]++;//根節點的人數 += 當前列舉的這個人數
}
sort(cnt+1,cnt+mx+1,cmp);
for(int i=1;i<=n;i++)//8個人
{
if(cnt[i]!=0) ans++;//在這些愛好中,非根節點和未出現的愛好cnt=0.
//這兩種不管哪種情況都不計數,只計數根節點,
}
printf("%d\n",ans);//連通塊個數
for(int i=1;i<=ans;i++)
{
printf("%d",cnt[i]);
if(i==ans) puts("");
else printf(" ");
}
}
7-5 檔案傳輸 (25 分)
這題得了24分,注釋的地方寫錯了,確實寫的短就要多注意細節,
#include<iostream>
#include<cstring>
using namespace std;
int n,m;
const int N=1e4+10;;
int p[N];
int cnt[N];
int find(int x)
{
if(x!=p[x]) return p[x]=find(p[x]);
else return x;
}
int main()
{
cin>>n;
for(int i=1;i<=n;i++) p[i]=i;
while(1)
{
string op;
int x,y;
cin>>op;
if(op[0]=='S') break;
cin>>x>>y;
if(op[0]=='C')
{
if(find(x)!=find(y))
puts("no");
else puts("yes");
}
else if(op[0]=='I')
{
if(find(x)!=find(y))
{
p[find(x)]=find(y);//注意不是p[x]=y;
}
}
}
int cnt=0;
for(int i=1;i<=n;i++)
{
if(p[i]==i) cnt++;
}
if(cnt==1) cout<<"The network is connected.\n";
else cout<<"There are "<<cnt<<" components.\n";
}
7-3 朋友圈 (25 分)
某學校有N個學生,形成M個俱樂部,每個俱樂部里的學生有著一定相似的興趣愛好,形成一個朋友圈,一個學生可以同時屬于若干個不同的俱樂部,根據“我的朋友的朋友也是我的朋友”這個推論可以得出,如果A和B是朋友,且B和C是朋友,則A和C也是朋友,請撰寫程式計算最大朋友圈中有多少人,
輸入格式:
輸入的第一行包含兩個正整數N(≤30000)和M(≤1000),分別代表學校的學生總數和俱樂部的個數,后面的M行每行按以下格式給出1個俱樂部的資訊,其中學生從1~N編號:
第i個俱樂部的人數Mi(空格)學生1(空格)學生2 … 學生Mi
輸出格式:
輸出給出一個整數,表示在最大朋友圈中有多少人,
輸入樣例:
7 4
3 1 2 3
2 1 4
3 5 6 7
1 6
輸出樣例:
4
這道題也是并查集,要注意這道題和第一題的cnt初始化是有區別的:
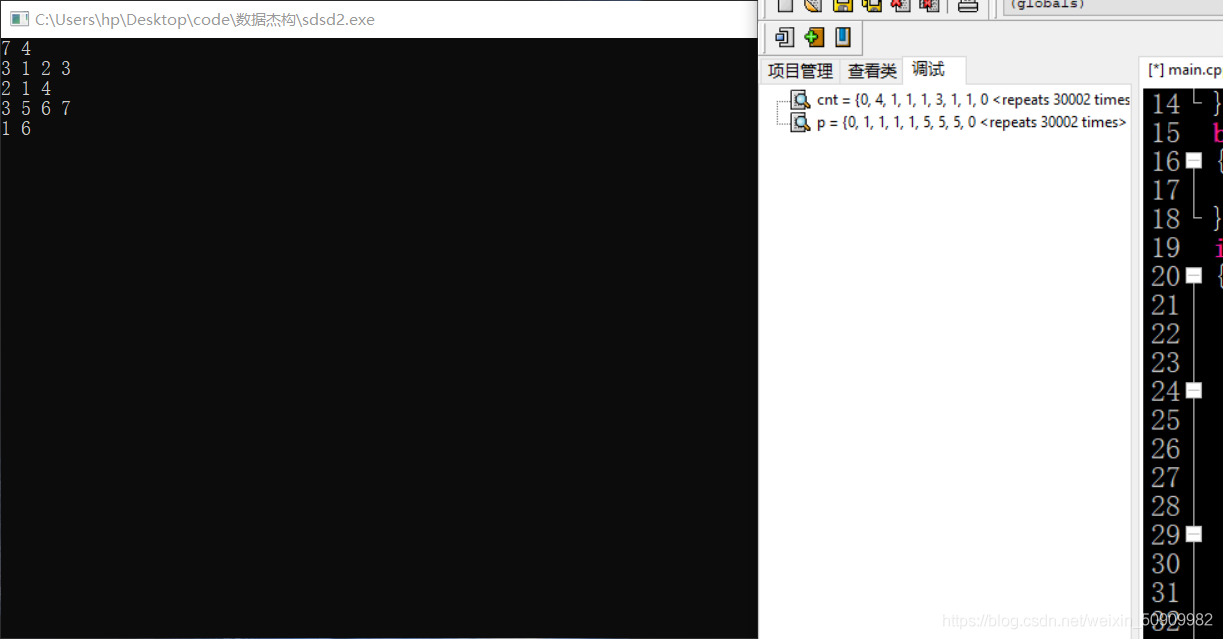
如果對于一個人 4 他沒有興趣愛好:
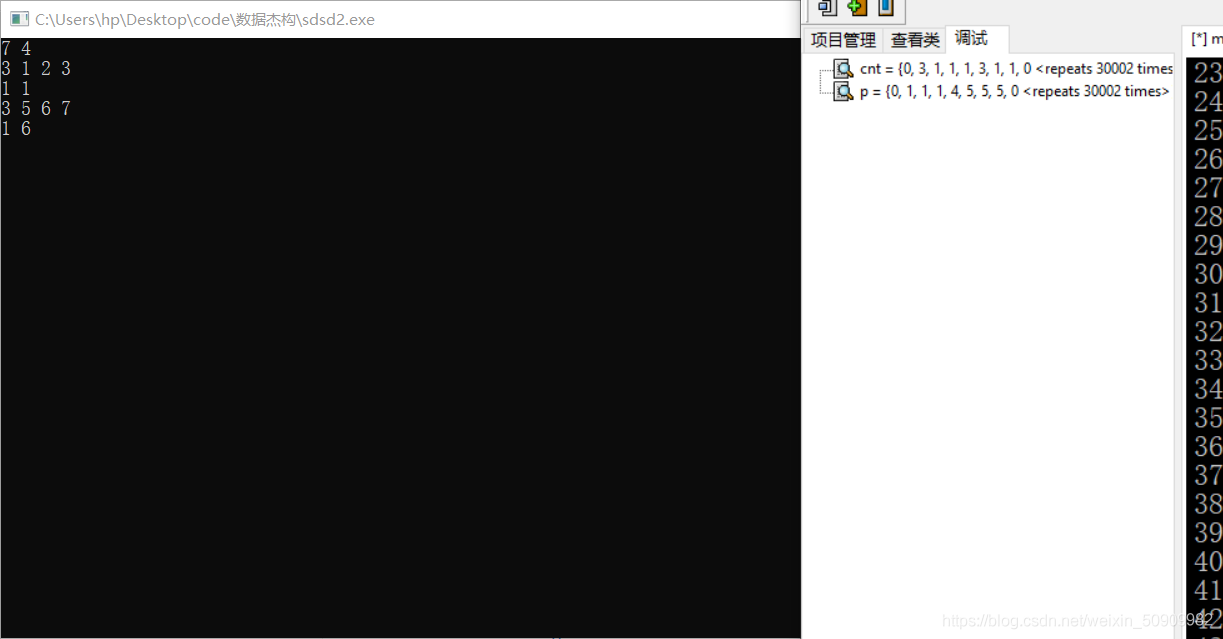
那么他的p[i]=i且,cnt[i]=1的資料我們無法判斷他是有一個僅有4的連通塊,還是沒有這個連通塊,
所以如果這道題像第一個題一樣要求把每個連通塊內部元素個數排序的話,需要再開一個vis陣列記錄出現過的人,只有一個人出現過,且p[i] = i,且 cnt[i] =1 我們才能認為他是一個孤立點組成的連通塊,
#include <iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=30010;
int n,m;
int p[N];
int cnt[N];
int vis[N];
int find(int x)
{
if(x!=p[x]) return p[x]=find(p[x]);
else return x;
}
bool cmp(int a,int b)
{
return a>b;
}
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++) p[i]=i,cnt[i]=1;
for(int i=1;i<=m;i++)
{
int x,par,pp,y;
cin>>x>>pp;
par=find(pp);
for(int j=1;j<=x-1;j++)
{
cin>>y;
int py=find(y);
if(par!=py)
{
p[py]=par;//形成朋友圈
cnt[par]+=cnt[py];//統計每一個連通塊個數
}
}
}
int t=-1;
for(int i=1;i<=n;i++)
{
t=max(t,cnt[i]);
}
printf("%d\n",t);
}
7-4 部落 (25 分)
在一個社區里,每個人都有自己的小圈子,還可能同時屬于很多不同的朋友圈,我們認為朋友的朋友都算在一個部落里,于是要請你統計一下,在一個給定社區中,到底有多少個互不相交的部落?并且檢查任意兩個人是否屬于同一個部落,
輸入格式:
輸入在第一行給出一個正整數N(≤10^4?? ),是已知小圈子的個數,隨后N行,每行按下列格式給出一個小圈子里的人:
K P[1] P[2] ? P[K]
其中K是小圈子里的人數,P[i](i=1,?,K)是小圈子里每個人的編號,這里所有人的編號從1開始連續編號,最大編號不會超過10^4,
之后一行給出一個非負整數Q(≤10^4 ),是查詢次數,隨后Q行,每行給出一對被查詢的人的編號,
輸出格式:
首先在一行中輸出這個社區的總人數、以及互不相交的部落的個數,隨后對每一次查詢,如果他們屬于同一個部落,則在一行中輸出Y,否則輸出N,
輸入樣例:
4
3 10 1 2
2 3 4
4 1 5 7 8
3 9 6 4
2
10 5
3 7
輸出樣例:
10 2
Y
N
簡單并查集的應用
這道題我改了一個世紀都不知道自己哪錯了,最后發現一個事情:
如果最開始初始化p的范圍等于const int N 的這個數,這個題就給我1分,只要讓這倆數不相等馬上就AC了,不知道這道題是不是編譯器的問題,真是吐了,
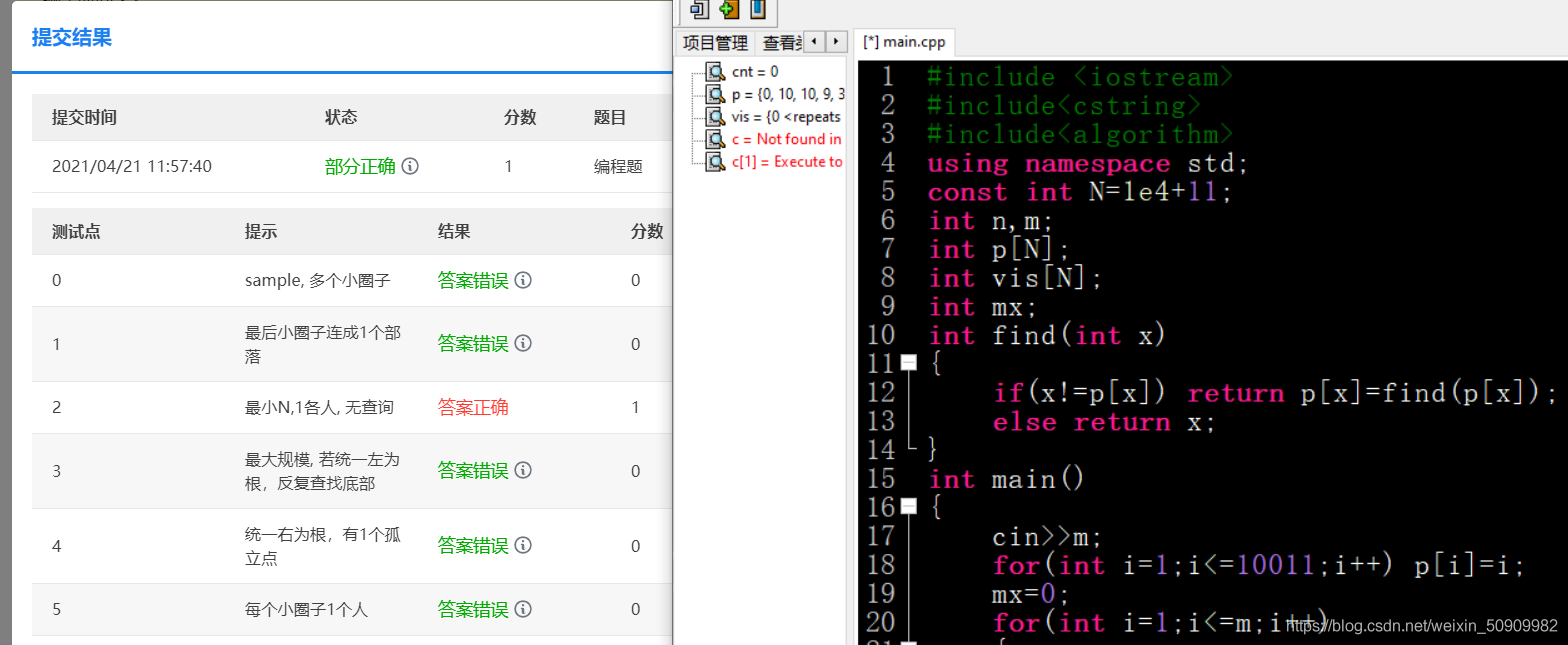
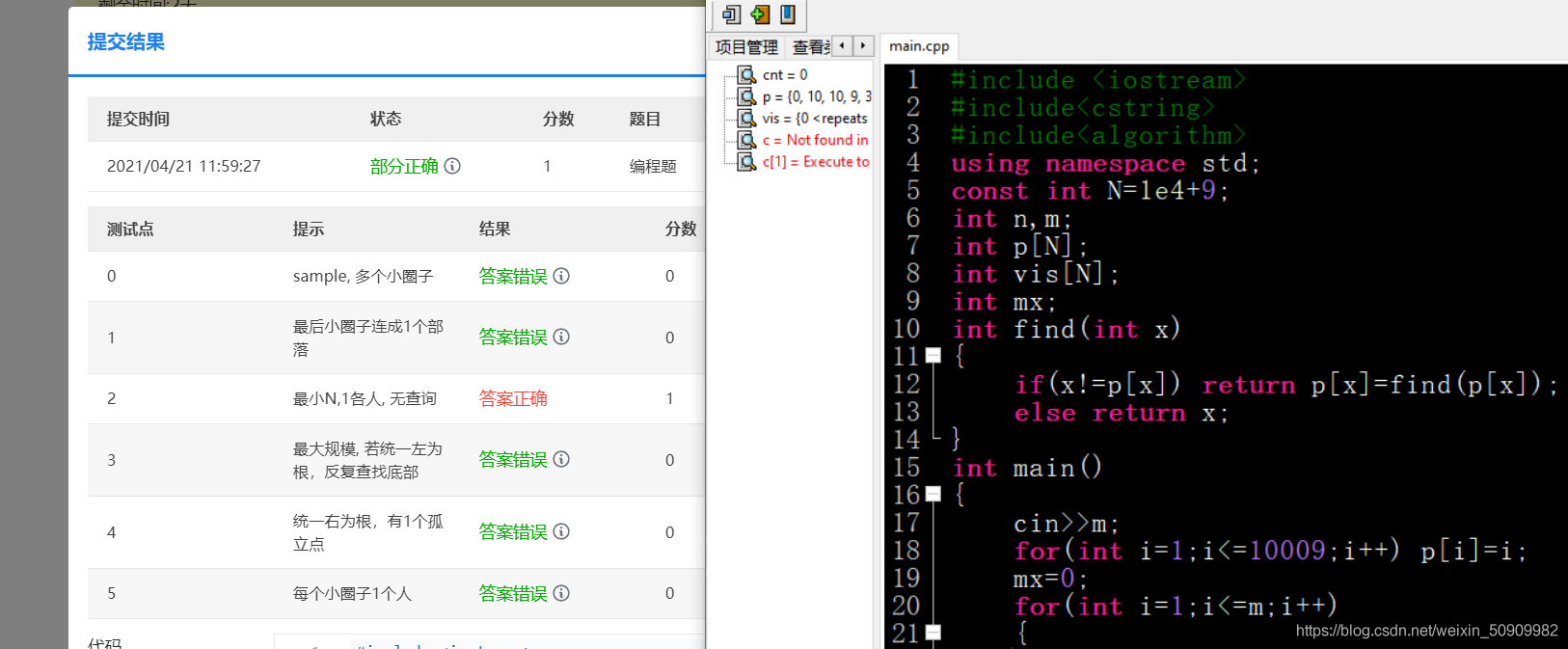
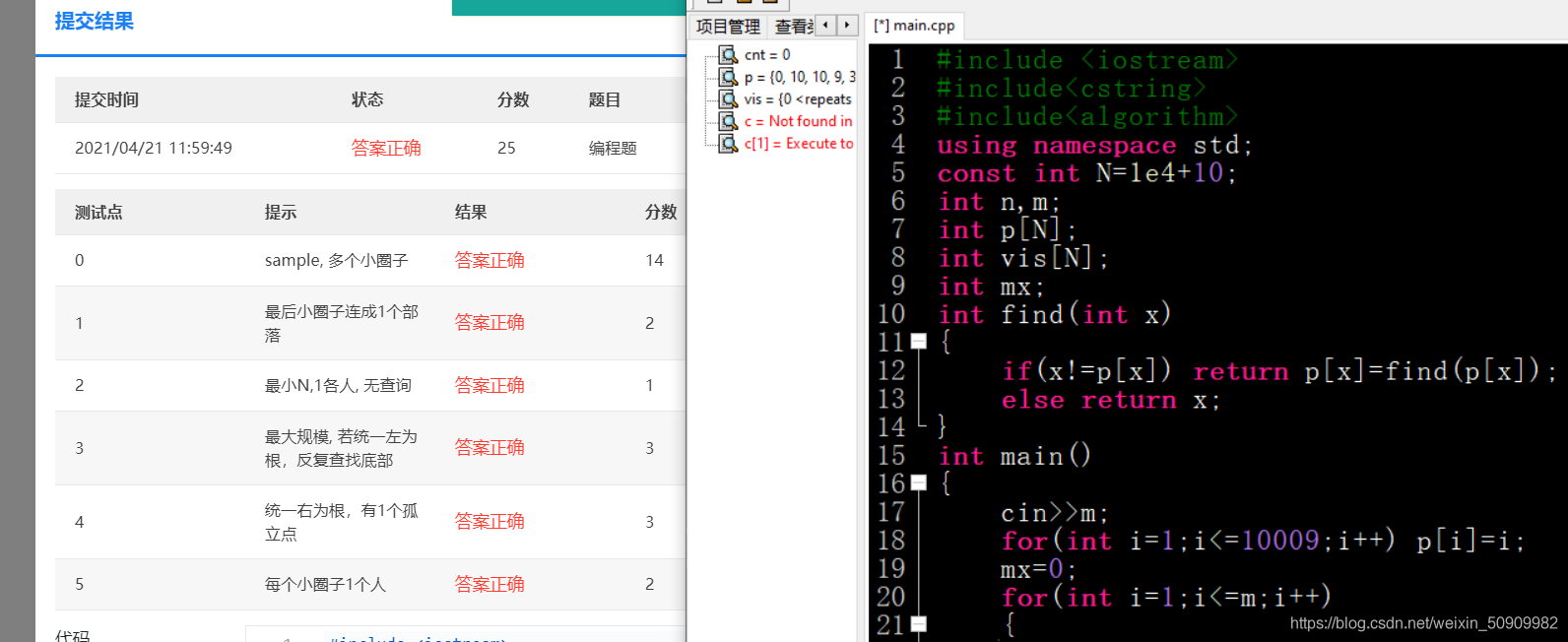
真的無語!
#include <iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=1e4+10;
int n,m;
int p[N];
int vis[N];
int mx;
int find(int x)
{
if(x!=p[x]) return p[x]=find(p[x]);
else return x;
}
int main()
{
cin>>m;
for(int i=1;i<=10009;i++) p[i]=i;
mx=0;
for(int i=1;i<=m;i++)
{
int x,par,pp,y;
cin>>x>>pp;
par=find(pp);
if(pp>mx) mx=pp;
for(int j=1;j<=x-1;j++)
{
cin>>y;
int py=find(y);
if(par!=py)
{
p[py]=par;//形成朋友圈
if(y>mx) mx=y;
}
}
}
int ans=0;
for(int i=1;i<=mx;i++)
{
if(p[i]==i) ans++;
}
printf("%d %d\n",mx,ans);
int q;
cin>>q;
while(q--)
{
int a,b;
cin>>a>>b;
if(find(a)!=find(b)) puts("N");
else puts("Y");
}
return 0;
}
7-8 是否同一棵二叉搜索樹 (25 分)
給定一個插入序列就可以唯一確定一棵二叉搜索樹,然而,一棵給定的二叉搜索樹卻可以由多種不同的插入序列得到,例如分別按照序列{2, 1, 3}和{2, 3, 1}插入初始為空的二叉搜索樹,都得到一樣的結果,于是對于輸入的各種插入序列,你需要判斷它們是否能生成一樣的二叉搜索樹,
輸入格式:
輸入包含若干組測驗資料,每組資料的第1行給出兩個正整數N (≤10)和L,分別是每個序列插入元素的個數和需要檢查的序列個數,第2行給出N個以空格分隔的正整數,作為初始插入序列,最后L行,每行給出N個插入的元素,屬于L個需要檢查的序列,
簡單起見,我們保證每個插入序列都是1到N的一個排列,當讀到N為0時,標志輸入結束,這組資料不要處理,
輸出格式:
對每一組需要檢查的序列,如果其生成的二叉搜索樹跟對應的初始序列生成的一樣,輸出“Yes”,否則輸出“No”,
輸入樣例:
4 2
3 1 4 2
3 4 1 2
3 2 4 1
2 1
2 1
1 2
0
輸出樣例:
Yes
No
No
思路:分別建二叉排序樹,然后進行遞回比較,
#include<bits/stdc++.h>
using namespace std;
int n,m;
struct node
{
int data;
struct node *lc,*rc;
};
void build(node *root,int x)
{
if(x<root->data)
{
if(root->lc)
{
build(root->lc,x);
}
else
{
node *p=new node;
p->data=x;
p->lc=NULL;
p->rc=NULL;
root->lc=p;
return ;
}
}
else
{
if(root->rc)
{
build(root->rc,x);
}
else
{
node *p=new node;
p->data=x;
p->lc=NULL;
p->rc=NULL;
root->rc=p;
return ;
}
}
}
bool judge(struct node *root,struct node *rot)
{
if(root==NULL&&rot==NULL) return true;
if(root==NULL||rot==NULL) return false;
if(root->data!=rot->data) return false;
return judge(root->lc,rot->lc)&&judge(root->rc,rot->rc);
}
int main()
{
while(cin>>n)
{ if(n==0) return 0;
cin>>m;
node *root=new node;
for(int i=1;i<=n;i++)
{
int x;
scanf("%d",&x);
if(i==1)
{
root->data=x;
root->lc=NULL;
root->rc=NULL;
}
else
{
build(root,x);
}
}
while(m--)
{
node *rot=new node;
for(int i=1;i<=n;i++)
{
int y;
scanf("%d",&y);
if(i==1)
{
rot->data=y;
rot->lc=NULL;
rot->rc=NULL;
}
else
{
build(rot,y);
}
}
if(judge(root,rot)) cout<<"Yes"<<endl;
else cout<<"No"<<endl;
free(rot);
}
}
}
排序二叉樹的板子也可以短一些:
node *build (node *root,int x)
{
if(root==NULL)
{
root=new node;
root->data=x;
root->lc=root->rc=NULL;
return root;
}
else
{
if(x<root->data)
root->lc=build(root->lc,x);
else
root->rc=build(root->rc,x);
}
return root;
}
7-10 搜索樹判斷 (25 分)
對于二叉搜索樹,我們規定任一結點的左子樹僅包含嚴格小于該結點的鍵值,而其右子樹包含大于或等于該結點的鍵值,如果我們交換每個節點的左子樹和右子樹,得到的樹叫做鏡像二叉搜索樹,
現在我們給出一個整數鍵值序列,請撰寫程式判斷該序列是否為某棵二叉搜索樹或某鏡像二叉搜索樹的前序遍歷序列,如果是,則輸出對應二叉樹的后序遍歷序列,
輸入格式:
輸入的第一行包含一個正整數N(≤1000),第二行包含N個整數,為給出的整數鍵值序列,數字間以空格分隔,
輸出格式:
輸出的第一行首先給出判斷結果,如果輸入的序列是某棵二叉搜索樹或某鏡像二叉搜索樹的前序遍歷序列,則輸出YES,否側輸出NO,如果判斷結果是YES,下一行輸出對應二叉樹的后序遍歷序列,數字間以空格分隔,但行尾不能有多余的空格,
輸入樣例1:
7
8 6 5 7 10 8 11
輸出樣例1:
YES
5 7 6 8 11 10 8
輸入樣例2:
7
8 6 8 5 10 9 11
輸出樣例2:
NO
原文鏈接
作者代碼寫的挺清晰的,先求出二叉排序樹,然后求出二叉搜索樹的前序遍歷,并將其存入陣列,對于鏡像二叉搜索樹的前序,只需要把二叉搜索樹的根左右變為根右左來遍歷,那么就相當于遍歷了鏡像二叉搜索樹,最后把這兩個陣列與題目資料對比,處理一下后序輸出即可,
#include<bits/stdc++.h>
using namespace std;
struct node
{
node *l,*r;
int data;
};
int a[10001],b[10001],c[10001];
int top,tot,flag1=1,flag2=1,flag3,flag4;
node *create(node *root,int x)
{
if(root==NULL)
{
root=new node;
root->data=x;
root->l=root->r=NULL;
return root;
}
else
{
if(x<root->data)
root->l=create(root->l,x);
else
root->r=create(root->r,x);
}
return root;
}
void show1(node *root)
{
if(root)
{
b[++top]=root->data;
show1(root->l);
show1(root->r);
}
}
void show2(node *root)
{
if(root)
{
c[++tot]=root->data;
show2(root->r);
show2(root->l);
}
}
void finallshow1(node *root)
{
if(root)
{
finallshow1(root->l);
finallshow1(root->r);
if(flag3==0)
{
cout<<root->data;
flag3=1;
}
else
cout<<" "<<root->data;
}
}
void finallshow2(node *root)
{
if(root)
{
finallshow2(root->r);
finallshow2(root->l);
if(flag4==0)
{
cout<<root->data;
flag4=1;
}
else
cout<<" "<<root->data;
}
}
int main()
{
int n;
cin>>n;
node *root=NULL;
for(int i=1;i<=n;i++)
{
cin>>a[i];
root=create(root,a[i]);//先建立二叉搜索樹
}
show1(root);//分別將先序遍歷和鏡像先序遍歷放入b和c陣列里
show2(root);
for(int i=1;i<=n;i++)//只要有1個不同,就說明不是該樹的遍歷
{
if(a[i]!=b[i])
{
flag1=0;
break;
}
}
for(int i=1;i<=n;i++)
{
if(a[i]!=c[i])
{
flag2=0;
break;
}
}
if(flag1)
{
cout<<"YES"<<endl;
finallshow1(root);//樹的遍歷
}
else if(flag2)
{
cout<<"YES"<<endl;
finallshow2(root);//樹的鏡像遍歷
}
else
cout<<"NO"<<endl;
return 0;
}
7-9 樹種統計 (25 分)
隨著衛星成像技術的應用,自然資源研究機構可以識別每一棵樹的種類,請撰寫程式幫助研究人員統計每種樹的數量,計算每種樹占總數的百分比,
輸入格式:
輸入首先給出正整數N(≤10^?5),隨后N行,每行給出衛星觀測到的一棵樹的種類名稱,種類名稱由不超過30個英文字母和空格組成(大小寫不區分),
輸出格式:
按字典序遞增輸出各種樹的種類名稱及其所占總數的百分比,其間以空格分隔,保留小數點后4位,
輸入樣例:
29
Red Alder
Ash
Aspen
Basswood
Ash
Beech
Yellow Birch
Ash
Cherry
Cottonwood
Ash
Cypress
Red Elm
Gum
Hackberry
White Oak
Hickory
Pecan
Hard Maple
White Oak
Soft Maple
Red Oak
Red Oak
White Oak
Poplan
Sassafras
Sycamore
Black Walnut
Willow
輸出樣例:
Ash 13.7931%
Aspen 3.4483%
Basswood 3.4483%
Beech 3.4483%
Black Walnut 3.4483%
Cherry 3.4483%
Cottonwood 3.4483%
Cypress 3.4483%
Gum 3.4483%
Hackberry 3.4483%
Hard Maple 3.4483%
Hickory 3.4483%
Pecan 3.4483%
Poplan 3.4483%
Red Alder 3.4483%
Red Elm 3.4483%
Red Oak 6.8966%
Sassafras 3.4483%
Soft Maple 3.4483%
Sycamore 3.4483%
White Oak 10.3448%
Willow 3.4483%
Yellow Birch 3.4483%
思路:對map容器的使用:
#include<bits/stdc++.h>
using namespace std;
#define maxn 1000010
map<string,int>mp;
int main(){
int n;
cin>>n;
getchar();
for( int i=0; i<n; i++ )
{
string str;
getline(cin,str);
mp[str]++;
}
for( map<string,int >::iterator it = mp.begin(); it!=mp.end(); it++ )
{
cout<<it->first<<' ';
double num=0;
num=it->second*100.0/n;//int乘100.0/int 為double
printf("%.4f%\n",num);
}
return 0;
}
輸出的時候注意int * 1.0 / int 型別 可以轉化為double
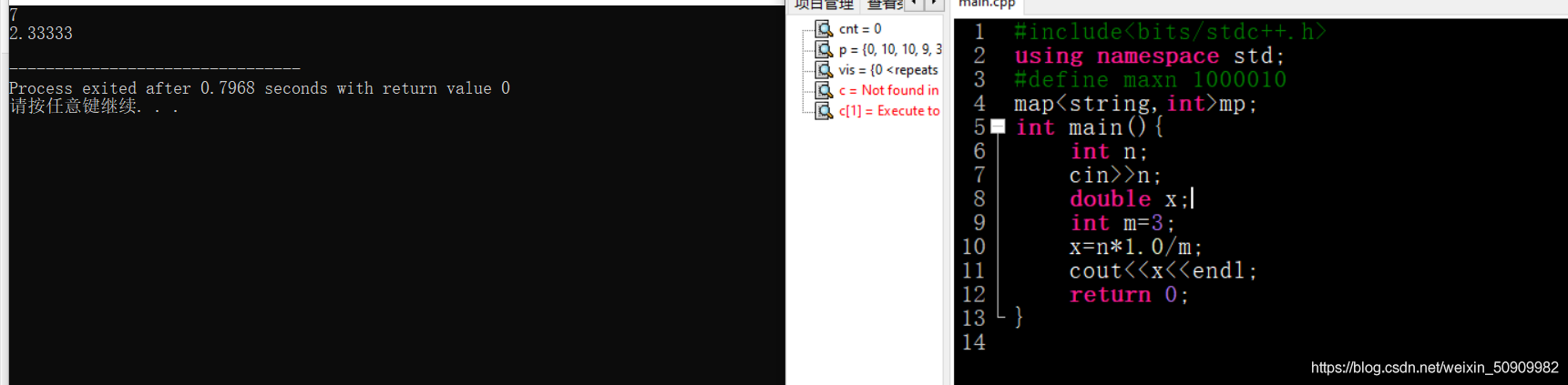
這里區別一下set容器的遍歷,輸出的是* it:
for(set<string>::iterator it=s.begin();it!=s.end();it++)
cout<<*it<<endl;
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278950.html
標籤:其他
下一篇:C1認證:任務一