什么是 Bucketing
Bucketing 就是利用 buckets(按列進行分桶)來決定資料磁區(partition)的一種優化技術,它可以幫助在計算中避免資料交換(avoid data shuffle),并行計算的時候shuffle常常會耗費非常多的時間和資源.
Bucketing 的基本原理比較好理解,它會根據你指定的列(可以是一個也可以是多個)計算哈希值,然后具有相同哈希值的資料將會被分到相同的磁區,
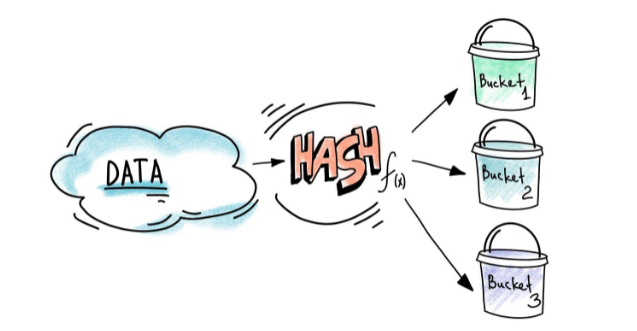
Bucket和Partition的區別
Bucket的最終目的也是實作磁區,但是和Partition的原理不同,當我們根據指定列進行Partition的時候,Spark會根據列的名字對資料進行磁區(如果沒有指定列名則會根據一個隨機資訊對資料進行磁區),Bucketing的最大不同在于它使用了指定列的哈希值,這樣可以保證具有相同列值的資料被分到相同的磁區,
怎么用 Bucket
按Bucket保存
目前在使用 bucketBy 的時候,必須和 sortBy,saveAsTable 一起使用,如下,這個操作其實是將資料保存到了檔案中(如果不指定path,也會保存到一個臨時目錄中),
df.write
.bucketBy(10, "name")
.sortBy("name")
.mode(SaveMode.Overwrite)
.option("path","/path/to")
.saveAsTable("bucketed")
資料分桶保存之后,我們才能使用它,
直接從table讀取
在一個SparkSession內,保存之后你可以通過如下命令通過表名獲取其對應的DataFrame.
val df = spark.table("bucketed")
其中spark是一個SparkSession物件,獲取之后就可以使用DataFrame或者在SQL中使用表,
從已經保存的Parquet檔案讀取
如果你要使用歷史保存的資料,那么就不能用上述方法了,也不能像讀取常規檔案一樣使用 spark.read.parquet() ,這種方式讀進來的資料是不帶bucket資訊的,正確的方法是利用CREATE TABLE 陳述句,詳情可用參考 https://docs.databricks.com/spark/latest/spark-sql/language-manual/create-table.html
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name1 col_type1 [COMMENT col_comment1], ...)]
USING data_source
[OPTIONS (key1=val1, key2=val2, ...)]
[PARTITIONED BY (col_name1, col_name2, ...)]
[CLUSTERED BY (col_name3, col_name4, ...) INTO num_buckets BUCKETS]
[LOCATION path]
[COMMENT table_comment]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
[AS select_statement]
示例如下:
spark.sql(
"""
|CREATE TABLE bucketed
| (name string)
| USING PARQUET
| CLUSTERED BY (name) INTO 10 BUCKETS
| LOCATION '/path/to'
|""".stripMargin)
用Buckets的好處
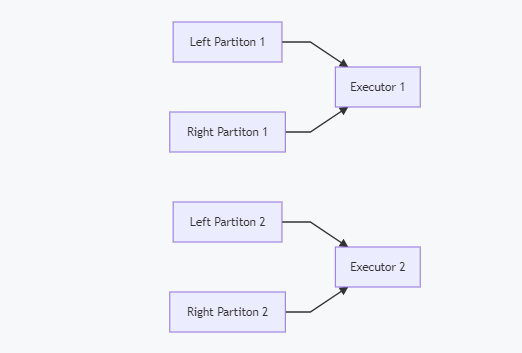
在我們join兩個表的時候,如果兩個表最好按照相同的列劃分成相同的buckets,就可以完全避免shuffle,根據前面所述的hash值計算方法,兩個表具有相同列值的資料會存放在相同的機器上,這樣在進行join操作時就不需要再去和其他機器通訊,直接在本地完成計算即可,假設你有左右兩個表,各有兩個磁區,那么join的時候實際計算就是下圖的樣子,兩個機器進行計算,并且計算后磁區還是2.
而當需要shuffle的時候,會是這樣的,
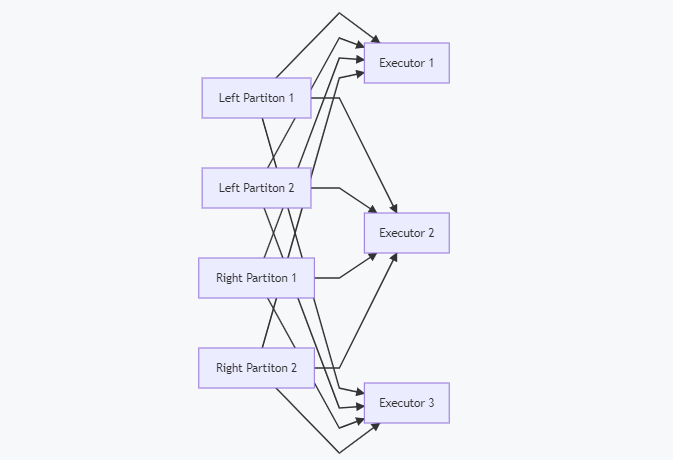
細心的你可能發現了,上面兩個磁區對應兩個Executor,下面shuffle之后對應的怎么成了三個Executor了?沒錯,當資料進行shuffle之后,磁區數就不再保持和輸入的資料相同了,實際上也沒有必要保持相同,
本地測驗
我們考慮的是大資料表的連接,本地測驗的時候一般使用小的表,所以逆序需要將小表自動廣播的配置關掉,如果開啟小表廣播,那么兩個小表的join之后磁區數是不會變的,例如:
| 左表磁區數 | 右表磁區數數 | Join之后的磁區數 |
|---|---|---|
| 3 | 3 | 3 |
關閉配置的命令如下:
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
正常情況下join之后磁區數會發生變化:
| 左表磁區數 | 右表磁區數數 | Join之后的磁區數 |
|---|---|---|
| 3 | 3 | 200 |
這個200其實就是 "spark.sql.shuffle.partitions" 配置的值,默認就是200. 所以如果在Join程序中出現了shuffle,join之后的磁區一定會變,并且變成spark.sql.shuffle.partitions的值,通常你需要根據自己的集群資源修改這個值,從而優化并行度,但是shuffle是不可避免的,
左右兩個表Bucket數目不一致時
實際測驗結果如下:
| 左表Bucket數 | 右表Bucekt數 | Join之后的磁區數 |
|---|---|---|
| 8 | 4 | 8 |
| 4 | 4 | 4 |
Spark依然會利用一些Bucekt的資訊,但具體怎么執行目前還不太清楚,還是保持一致的好,
另外,如果你spark job的可用計算核心數小于Bucket值,那么從檔案中讀取之后Bucekt值會變,就是說bucket的數目不會超過你能使用的最大計算核數,
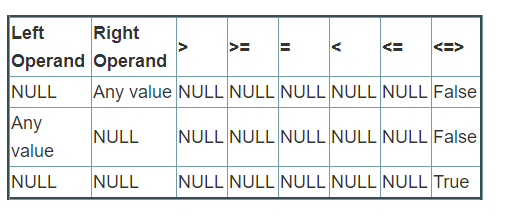
不要使用的 <=> 符號!!!
在處理null值的時候,我們可能會用到一些特殊的函式或者符號,如下表所示,但是在使用bucket的時候這里有個坑,一定要躲過,join的時候千萬不要使用 <=> 符號,使用之后spark就會忽略bucket資訊,繼續shuffle資料,原因可能和hash計算有關,
原文連接
如果你喜歡我的文章,可以在任一平臺搜索【黑客悟理】關注我,非常感謝!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/27929.html
標籤:其他