背景介紹
上一章和帶大家了解了一下Iceberg的元資料檔案特殊之處,也簡單的給大家描述了一下Iceberg是如何從快速定位到資料檔案的,上一章將的比較干,因為都是一些理論知識,這一章我們從iceberg-flink模塊的原始碼出發,帶大家更加深入的了解Iceberg
注意:本次原始碼分析基于Iceberg 0.11x分支,主要是講解iceberg-flink模塊,其余模塊因為暫未深入了解所以會跳過,敬請見諒;并且如果有任何地方講述不當,請直接指出
另外,需要對Iceberg和Flink都一定的基礎,否則會出現一知半解的情況
原始碼分析
開始之前
先回顧一下,我們如何通過Flink去讀取一張Iceberg表
首先我們需要建一個型別是iceberg的Flink Catalog
CREATE CATALOG iceberg_catalog
WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://localhost:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://hacluster/user/hive/warehouse'
);
假設,我們已經有一張Iceberg的表,通過Hive陳述句desc formatted iceberg_db.iceberg_kafka_test得到的資訊是這樣的
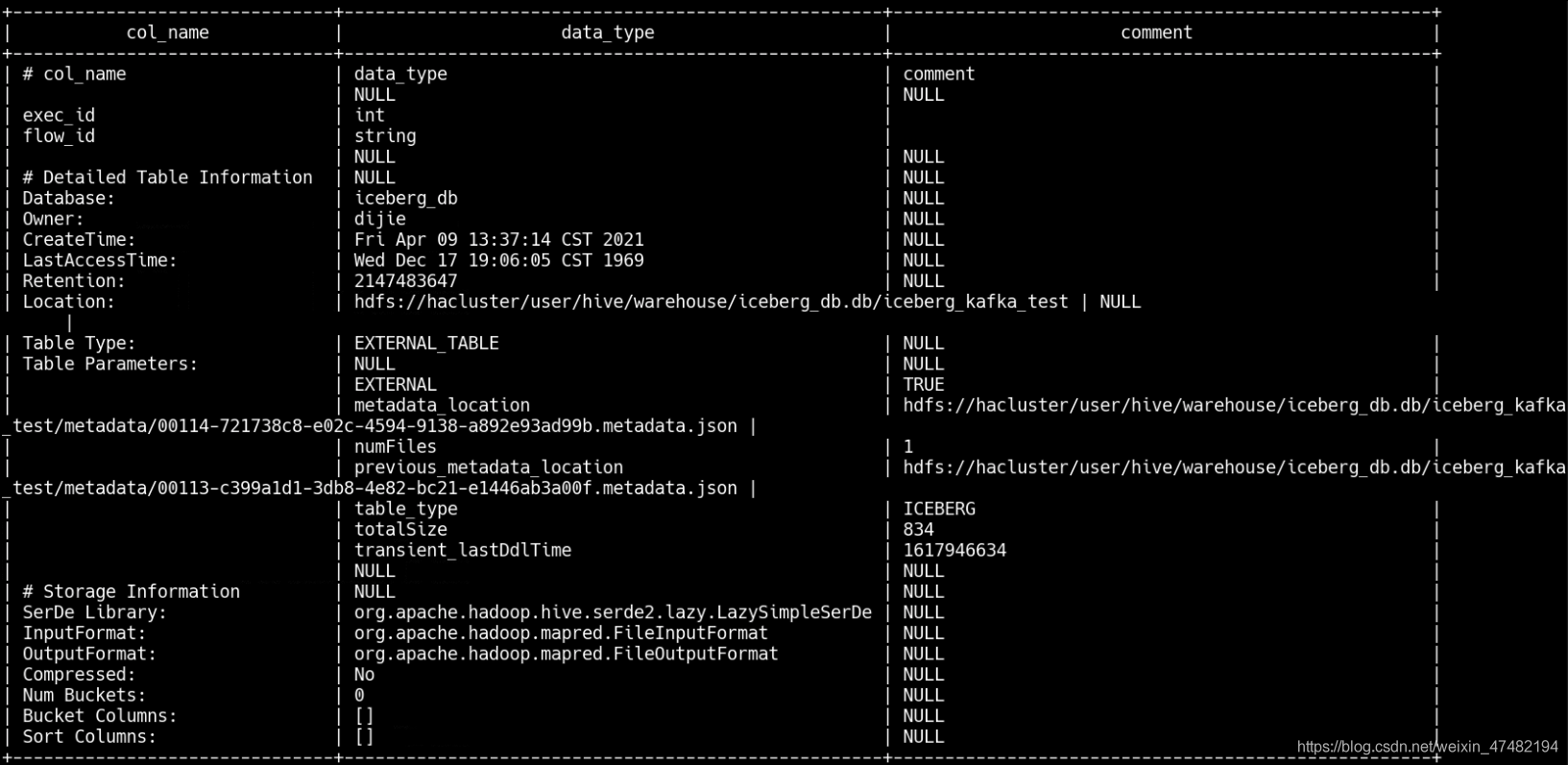
接下來,我們通過執行一條Flink Sql來進行資料的讀取
select * from iceberg_catalog.iceberg_db.iceberg_kafka_test
/*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')
然后耐心等待,我們很快就可以看到源源不斷的資料在控制臺進行展示,
簡單兩步,我們就可以通過Flink Sql對一張Iceberg進行資料讀取,那么在這背后,都發生了什么事情呢?
CREATE ICEBERG CATALOG
之前在講Flink 自定義Redis Lookop Table Source的時候說過,Flink會通過JAVA的SPI機制,將所有org.apache.flink.table.factories.TableFactory的實作類加載,然后通過type來區分到底是哪個實作類
同樣,CREATE ICEBERG CATALOG也不例外,根據以上步驟,定位到類org.apache.iceberg.flink.FlinkCatalogFactory
然后根據方法createCatalog()創建我們的Catalog Class org.apache.iceberg.flink.FlinkCatalog,并且因為我們創建的是Iceberg中的Hive Catalog,所以將Hive CatalogLoader傳入FlinkCatalog物件中,
protected Catalog createCatalog(String name, Map<String, String> properties, Configuration hadoopConf) {
CatalogLoader catalogLoader = createCatalogLoader(name, properties, hadoopConf);
String defaultDatabase = properties.getOrDefault(DEFAULT_DATABASE, "default");
String[] baseNamespace = properties.containsKey(BASE_NAMESPACE) ?
Splitter.on('.').splitToList(properties.get(BASE_NAMESPACE)).toArray(new String[0]) :
new String[0];
boolean cacheEnabled = Boolean.parseBoolean(properties.getOrDefault(CACHE_ENABLED, "true"));
return new FlinkCatalog(name, defaultDatabase, baseNamespace, catalogLoader, cacheEnabled);
}
接下來,我們繼續來看FlinkCatalog這個類,
在實體化它的時候,會呼叫傳入的Hive CatalogLoader物件,并執行它loadCatalog()的方法,得到真正的HiveCatalog,它的作用是負責與Hive Metastore通信,去執行我們的建表、刪表、查表陳述句,這里就不細講了,具體可以看看iceberg-hive-metastore模塊
回到FlinkCatalog,它還提供了listDatabases、listTables等方法,對應著我們的Sql陳述句show databases;、show tables,無一例外都是通過上面說的真正的HiveCatalog去執行對應的操作,有興趣的同學可以去看看,就不在這里展開說了
FlinkCatalog 中有個特殊的方法getTableFactory(),它的作用是將FlinkTableFactory的實體物件回傳出去,那么,這個Factory是啥呢?點進去看看,發現了兩個眼熟的方法createTableSource()、createTableSink(),
那既然本篇的主題是讀程序分析,那么我們就對createTableSource()中的內容進行深入分析
CREATE TABLE SOURCE
createTableSource()方法很簡單,一共4行代碼
@Override
public TableSource<RowData> createTableSource(TableSourceFactory.Context context) {
ObjectPath objectPath = context.getObjectIdentifier().toObjectPath();
TableLoader tableLoader = createTableLoader(objectPath);
TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getTable().getSchema());
return new IcebergTableSource(tableLoader, tableSchema, context.getTable().getOptions(),
context.getConfiguration());
}
其中,前三行的作用分別是拿到表路徑(一般來說就是庫名.表名),表加載物件(負責加載Iceberg的表)、表結構,然后通過它們去實體化IcebergTableSource,所以接下來我們再來看看IcebergTableSource這個類
點進去之后,我們能看到它實作了StreamTableSource這個介面,也就是說,IcebergTableSource提供對其資料的讀取訪問的能力,也就是通過getDataStream()去回傳一個dataStream,供下游的operator消費
@Override
public DataStream<RowData> getDataStream(StreamExecutionEnvironment execEnv) {
return FlinkSource.forRowData()
.env(execEnv)
.tableLoader(loader)
.properties(properties)
.project(getProjectedSchema())
.limit(limit)
.filters(filters)
.flinkConf(readableConfig)
.build();
}
這些鏈式方法的作用基本上都是把值塞進去,我們重點看一下properties()和build()
properties()里面的內容很簡單
public Builder properties(Map<String, String> properties) {
contextBuilder.fromProperties(properties);
return this;
}
我們來看看fromProperties()中做了什么
Builder fromProperties(Map<String, String> properties) {
Configuration config = new Configuration();
properties.forEach(config::setString);
return this.useSnapshotId(config.get(SNAPSHOT_ID))
.caseSensitive(config.get(CASE_SENSITIVE))
.asOfTimestamp(config.get(AS_OF_TIMESTAMP))
.startSnapshotId(config.get(START_SNAPSHOT_ID))
.endSnapshotId(config.get(END_SNAPSHOT_ID))
.splitSize(config.get(SPLIT_SIZE))
.splitLookback(config.get(SPLIT_LOOKBACK))
.splitOpenFileCost(config.get(SPLIT_FILE_OPEN_COST))
.streaming(config.get(STREAMING))
.monitorInterval(config.get(MONITOR_INTERVAL))
.nameMapping(properties.get(DEFAULT_NAME_MAPPING));
}
很明顯能看出來,我們通過傳入的properties的值,來指定我們的引數,例如startSnapshotId、asOfTimestamp等等;那properties的值都是什么呢?
一部分值來自于我們建表的時候,WITH中指定的引數;一部分是我們通過Table Hints動態修改的引數,比如start-snapshot-id、monitor_interval
說完properties(),我們來看build(),這里面的內容很多,大家認真看
public DataStream<RowData> build() {
Preconditions.checkNotNull(env, "StreamExecutionEnvironment should not be null");
FlinkInputFormat format = buildFormat();
ScanContext context = contextBuilder.build();
TypeInformation<RowData> typeInfo = RowDataTypeInfo.of(FlinkSchemaUtil.convert(context.project()));
if (!context.isStreaming()) {
int parallelism = inferParallelism(format, context);
return env.createInput(format, typeInfo).setParallelism(parallelism);
} else {
StreamingMonitorFunction function = new StreamingMonitorFunction(tableLoader, context);
String monitorFunctionName = String.format("Iceberg table (%s) monitor", table);
String readerOperatorName = String.format("Iceberg table (%s) reader", table);
return env.addSource(function, monitorFunctionName)
.transform(readerOperatorName, typeInfo, StreamingReaderOperator.factory(format));
}
}
該方法主要做了兩件事情
-
利用
tableLoader加載對應的table,然后通過這個table獲取到對應的FileIO、Schema、EncryptionManager;再加上之前的fromProperties()方法構建出的ScanContext物件,一起組裝成了負責輔助DataSource讀取資料、分發資料的InputFormat -
將DataSource
StreamingMonitorFunction注冊到env上,并且接上了一個自定義算子StreamingReaderOperator
至此,CREATE TABLE SOURCE的邏輯已經說完,接下來我們再看看Flink如何去mointor&read Iceberg表的
Mointor & Read
先看StreamingMonitorFunction
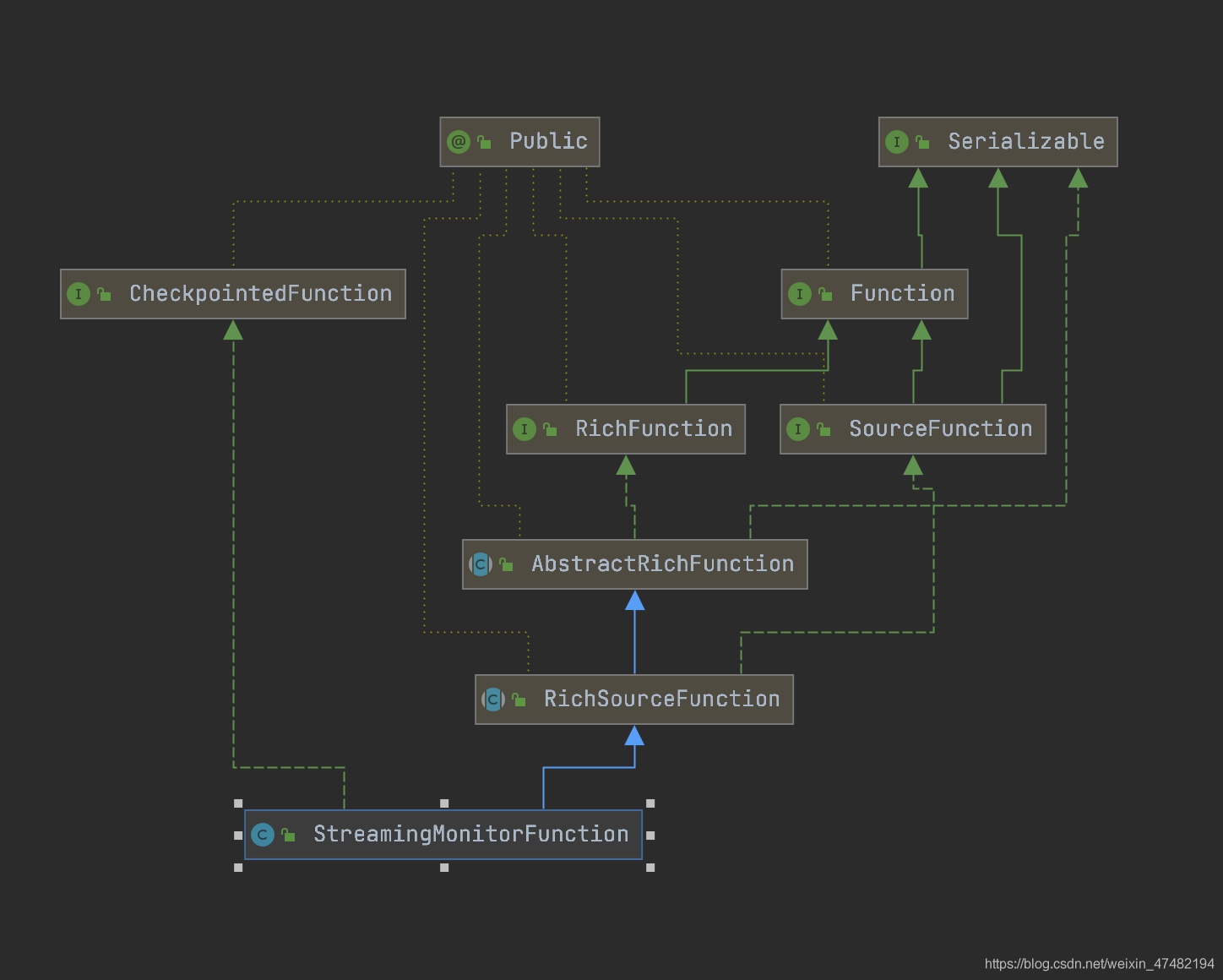
可以看到它實作了CheckpointedFunction介面,所以能夠保證在source端的一致性;
另外,因為它并沒有實作ParallelSourceFunction介面,所以它注定只能有一個并行度,這里的目的是確保在只有一個執行緒去監控Iceberg表和分發任務,多執行緒只會發生資料錯亂
每處理完當前到表最新的快照id中的資料之后,將表最新快照id標記為最后一次處理的快照id,并在checkpoint的時候,存在到state中;如果程式從故障中恢復,則取state中的快照id作為起始的快照id
這里有一個讓我產生疑惑的地方
if (context.isRestored()) {
LOG.info("Restoring state for the {}.", getClass().getSimpleName());
lastSnapshotId = lastSnapshotIdState.get().iterator().next();
}
如果lastSnapshotIdState中沒有任何值,lastSnapshotIdState.get().iterator().next()是否會拋出例外?
接下來看一下monitorAndForwardSplits()方法,它是負責去監控和分發任務
FlinkInputSplit[] splits = FlinkSplitGenerator.createInputSplits(table, newScanContext);
for (FlinkInputSplit split : splits) {
sourceContext.collect(split);
}
核心代碼就這2句話,首先通過FlinkSplitGenerator的createInputSplits方法,利用傳入的表,和新構建的ScanContext去構建任務分片,再將每個任務分發到下游算子StreamingReaderOperator中
FlinkSplitGenerator中的createInputSplits就不細看了,絕大部分內容(99.99%)屬于Iceberg的核心邏輯,大體流程也和我們上次分析Iceberg檔案中所涉及的讀邏輯差不多太多,這邊我還沒有細看,之后講到Iceberg核心技術的時候再來分析,
接下來再看看StreamingReaderOperator是如何消費的
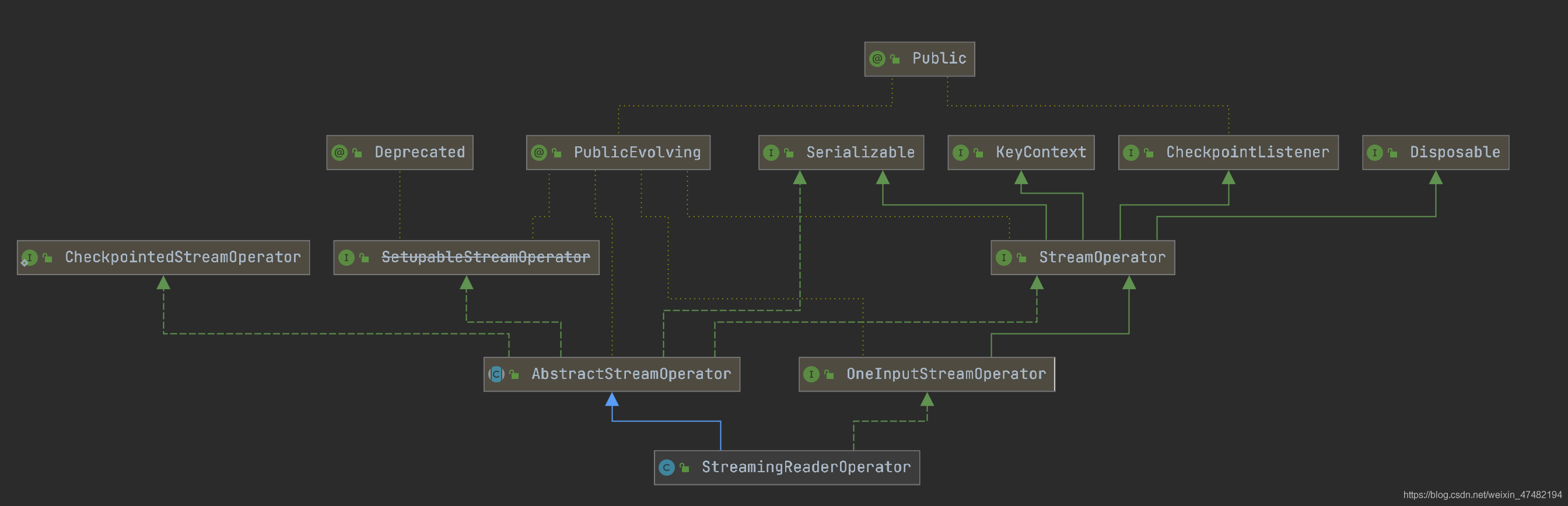
和StreamingMonitorFunction一樣,StreamingReaderOperator也實作了checkpoint相關的介面,因此也有一致性的保障;不一樣的地方是這個算子可以指定任意并行度
在記憶體中存放的任務分片splits是個佇列,每次在接收新的task就會丟到里面,每次會從splits中取出一個任務進行處理,再處理完一個任務后,進行類似遞回的操作,將splits中的任務不斷取出,在讀完splits中的任務會將算子標記為IDLE狀態,
在處理每個task的時候,之前的format會用task去構建一個RowDataIterator物件,并且根據task的檔案格式去創建不同格式的Iterable物件,并且會根據是否有位置洗掉和等值洗掉進行資料過濾,保證資料的一致性
然后將Iterable物件中的每個元素不斷取出,發向下游
這塊兒的邏輯不算太復雜,就是比較碎,有興趣的可以自己去翻看,大概邏輯就是我講的那樣
好了,講到這里,Iceberg中的Flink讀程序基本上都看完了,有些沒有講到的地方大家也可以自己去看,另外涉及Iceberg核心邏輯的地方之后的分享也會將
寫在最后
- 本章的內容還是比較多的,大家要慢慢看,最好是結合原始碼進行debug才能更好的了解Iceberg中的Flink讀程序
- 最近比較忙,所以這周就分享這么一篇了,另外我自己實作了如何給Flink Sql中的每個算子指定并行度、chain策略以及UID,有機會會分享出來,特別是指定UID,對我們的意義很大,這樣我們在Flink Sql進行邏輯變更的時候,也能從checkpoint/savepoint中恢復資料,以前因為UID是隨機生成的無法自己指定,只要邏輯變更,哪怕是同一個算子,產生的UID也會不一樣,所以導致無法恢復,
- 下一章我會暫停對Iceberg的分享,轉而去分享一下Hudi的相關內容,有喜歡Hudi的同學不要錯過
- 最后,看在我寫這么多的分子上,點個贊唄?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/279960.html
標籤:其他
下一篇:淺析正則運算式模式修正符