正則運算式之模式修正符
眾所周知,我們可以利用正則運算式在文本中匹配自己想匹配的字符,而為了方便我們匹配字符,于是出現了一種幫助匹配的字符,叫做:
模式修正符
模式修正符可以幫我們提高自己作業的效率,接下來我們就來介紹一下模式修正符,
1.介紹
?對于模式修正符,其實就是在正則運算式后面加上一個“/”,再在后面加上一些特定的字母,便可以對匹配的字符做出限定,而這個限定是全域的,也就是說,它的優先級是最高的,
2.字符
?而在“/”后面可以加上的字符有這些:
| 字符 | 原詞 | 含義 |
|---|---|---|
| g | global | 匹配全部可匹配結果 |
| m | multi line | 多行模式(此模式下^和$可以分別匹配行首和行尾) |
| i | insensitive | 不區分大小寫 |
| x | extended | 忽略空白字符,可以多行書寫,并使用#進行注釋說明 |
| s | single line | 單行模式(此狀態下”.“可以匹配任意字符,包括換行符) |
| u | unicode | 模式字串被當作UTF-8 |
| U | Ungreedy | 使量詞默認為非貪婪模式 |
| A | Anchored | 從目標字串的開頭開始匹配 |
| Z | 從目標字串的末尾或出現在字串末尾的 \n 之前開始匹配 | |
| z | 從目標字串的末尾開始匹配 | |
| J | Jchanged | 允許子模式重復命名 |
| D | Dollar end only | 字 符 僅 匹 配 目 標 字 符 串 的 結 尾 ; 沒 有 此 選 項 時 , 如 果 最 后 一 個 字 符 是 換 行 符 的 話 字符僅匹配目標字串的結尾;沒有此選項時,如果最后一個字符是換行符的話 字符僅匹配目標字符串的結尾;沒有此選項時,如果最后一個字符是換行符的話字符也能匹配 |
3.實體
?話不多說,上圖
?例子:
首先我們選擇匹配abc
1)g:匹配全部可匹配結果
未加“g”之前
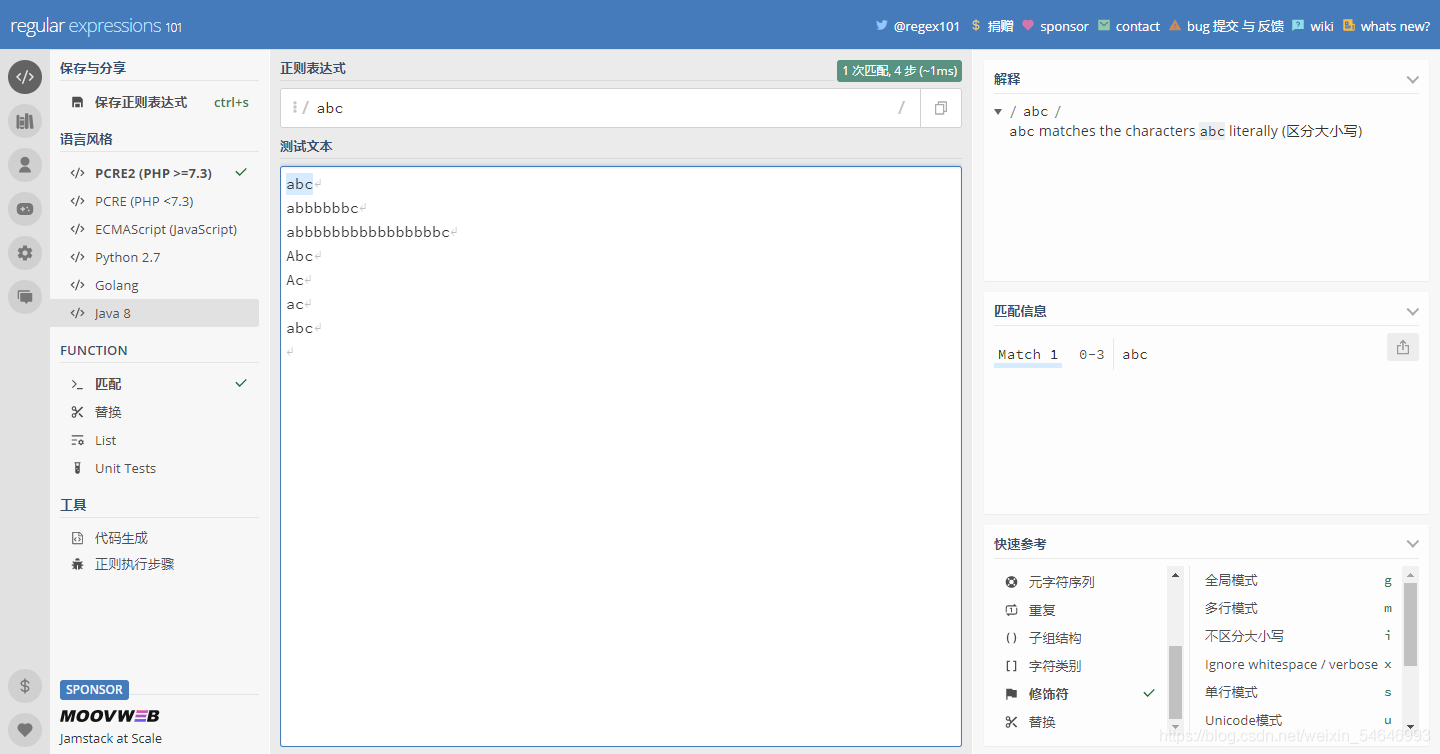
加了“g”后
(ps:我使用的網址是直接點擊“g”就可以調整模式修正詞了)
? 可以看出未加“g”之前只能匹配一個結果,加上“g”后就可以匹配多個結果,
2)m:多行模式(此模式下^和$可以同時匹配行首和行尾)
此模式下可以同時運用元字符“^”和“$”
未加“m”之前:
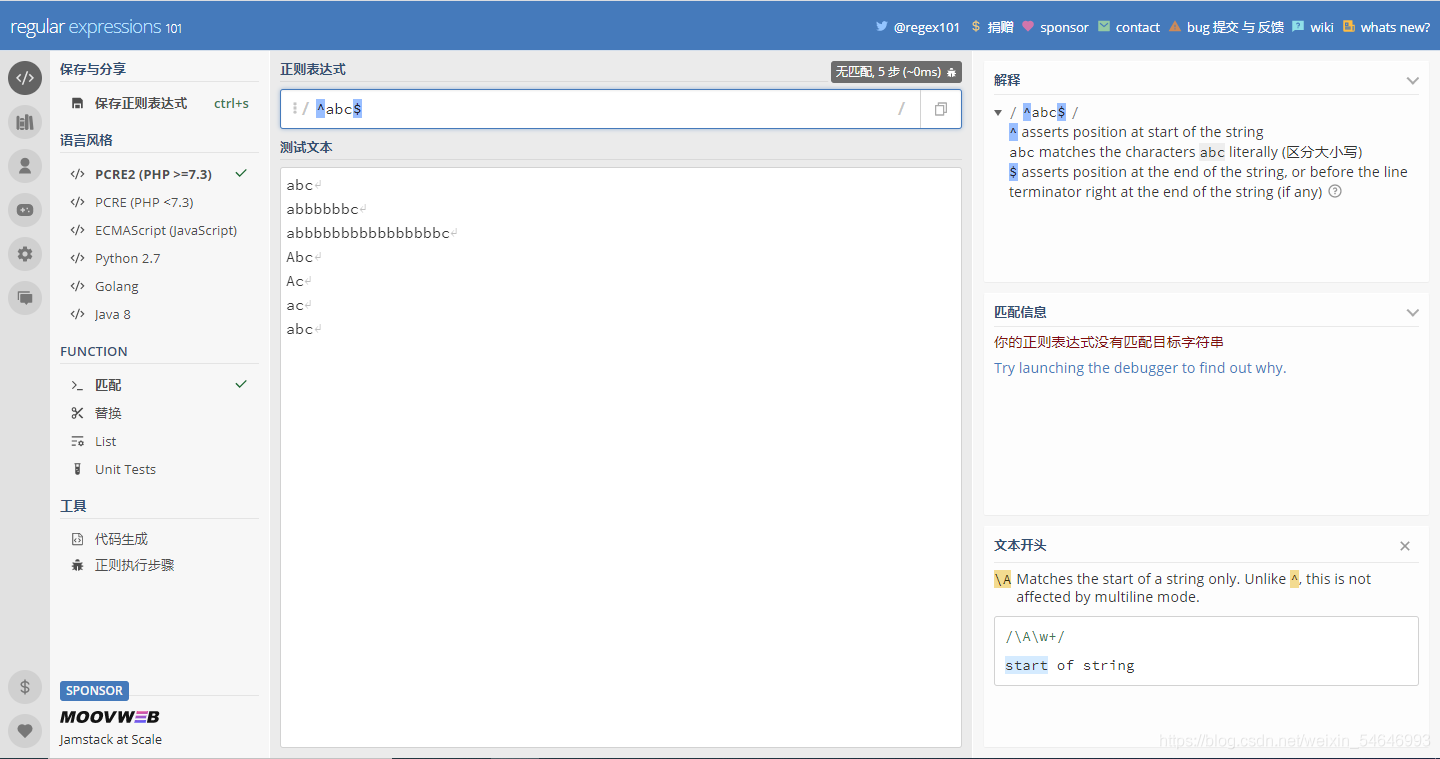
加上“m”以后:
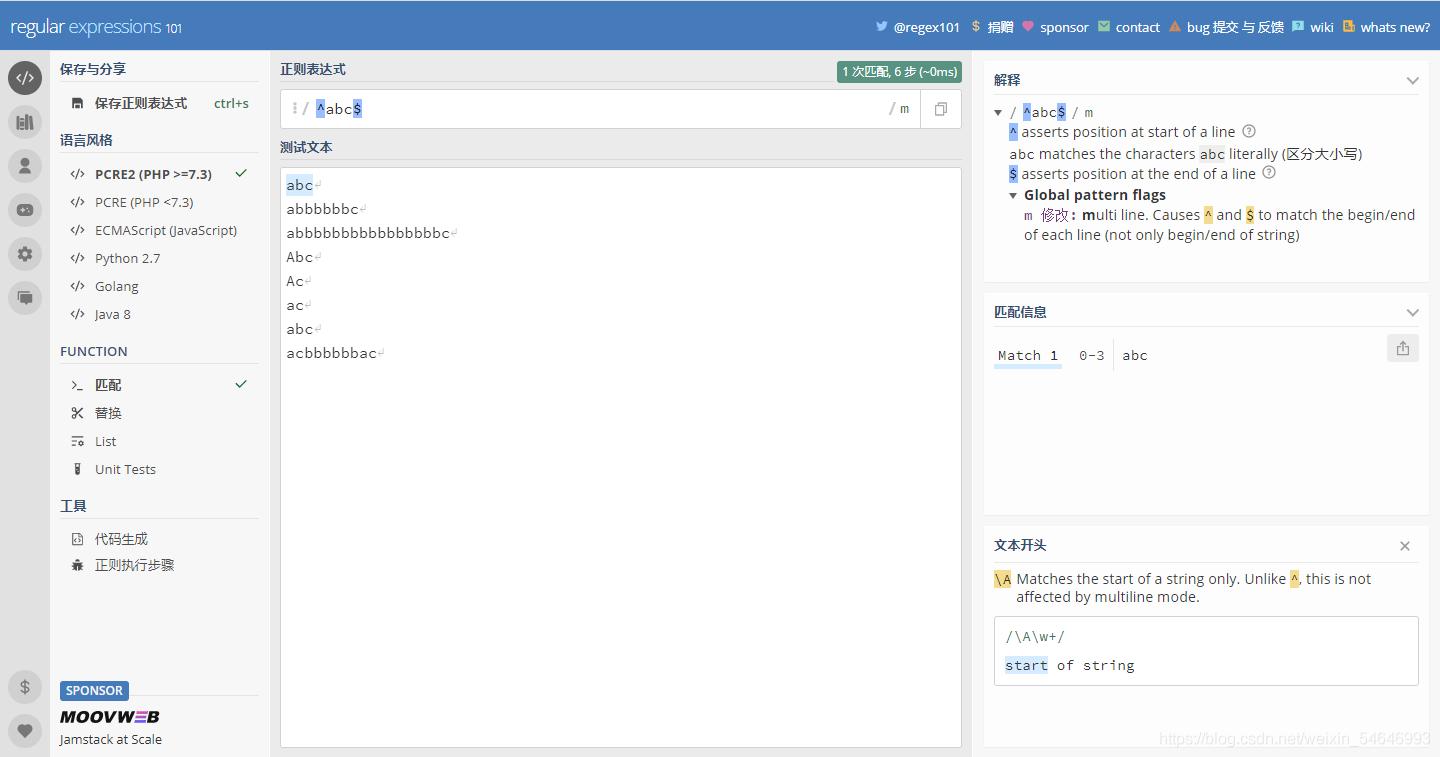
但有一點要注意,當它們同時出現在同一段字符的時候,它們只會匹配這一段字符占了一行的欄位(“g”和“m”同時加上)
比如我決定匹配“ac”,單獨加上“^”和“$”分別是這樣的:
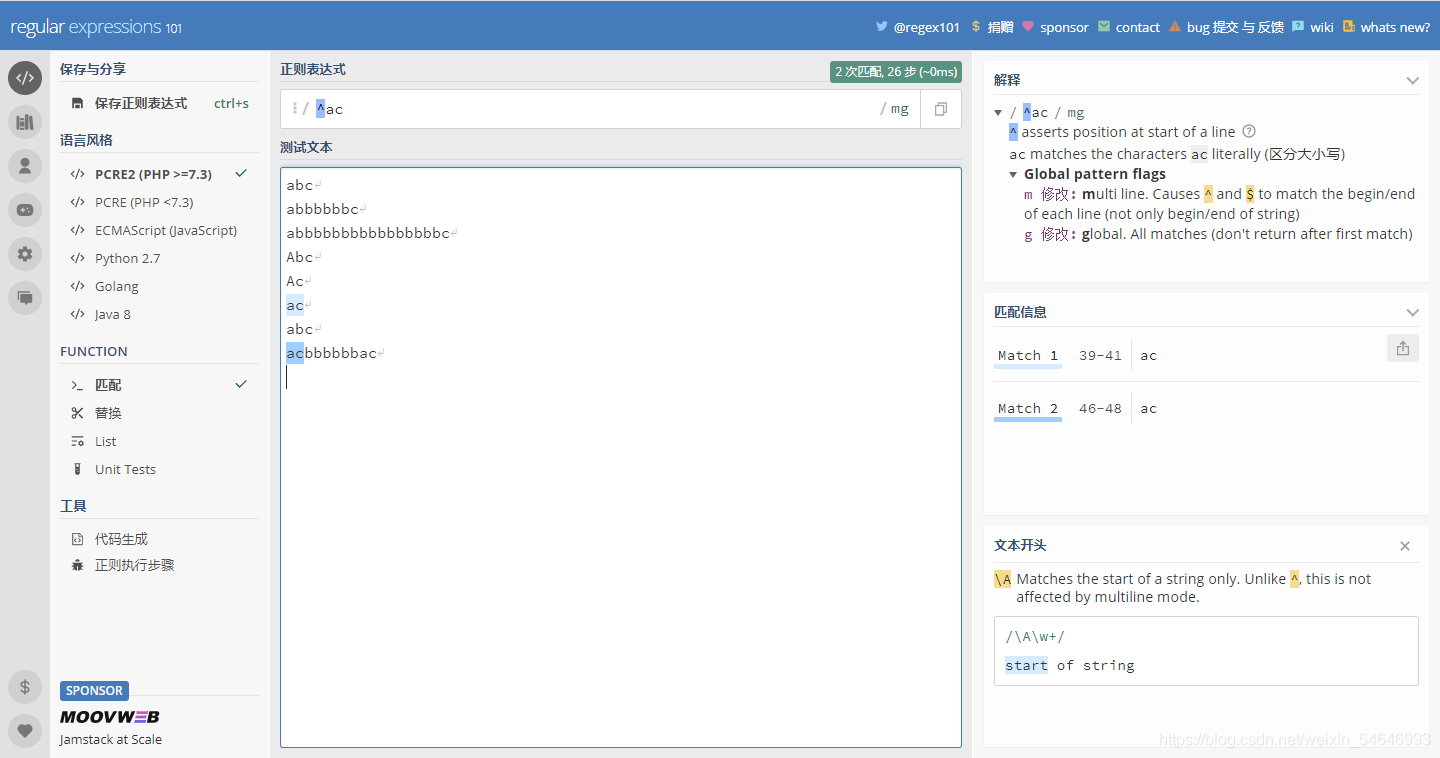
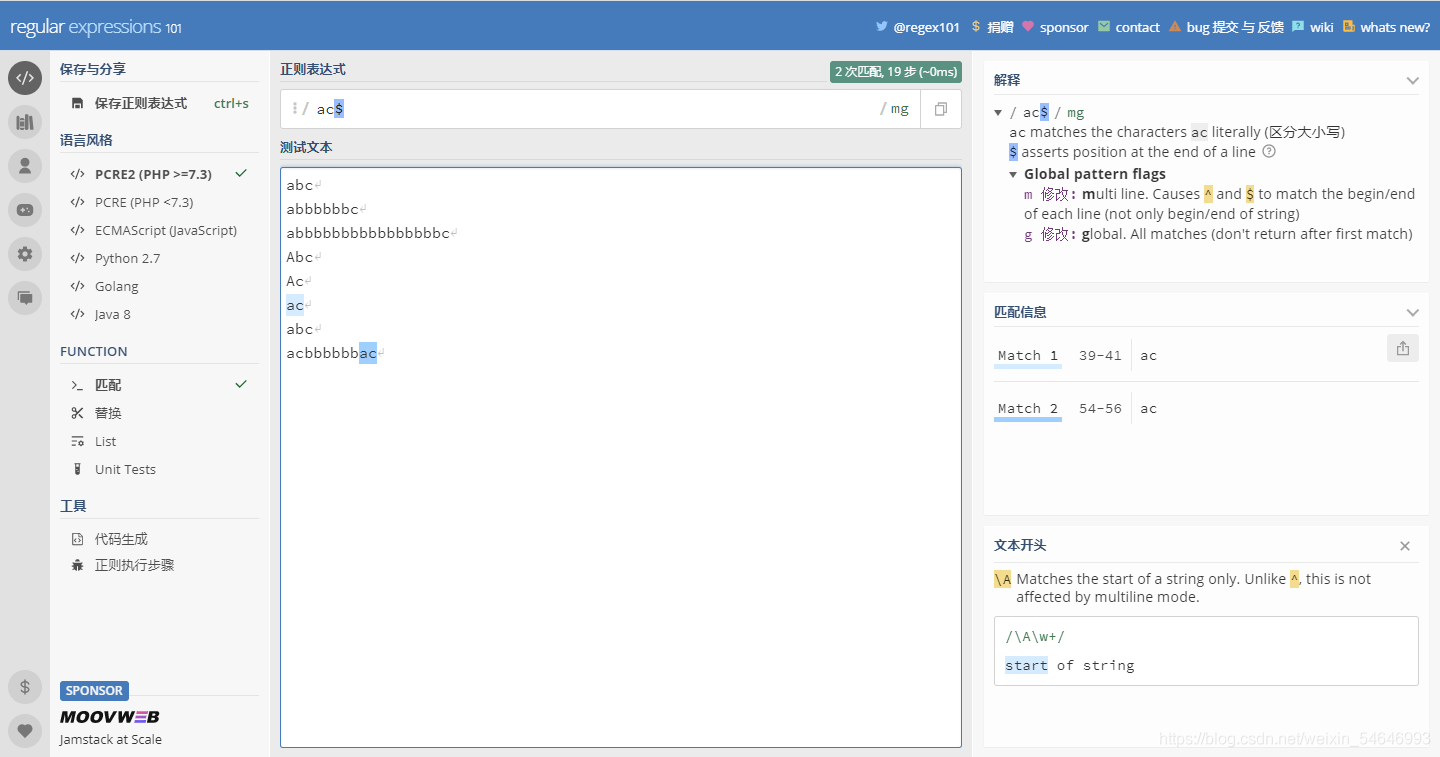
而兩個一起放上去是這樣的:
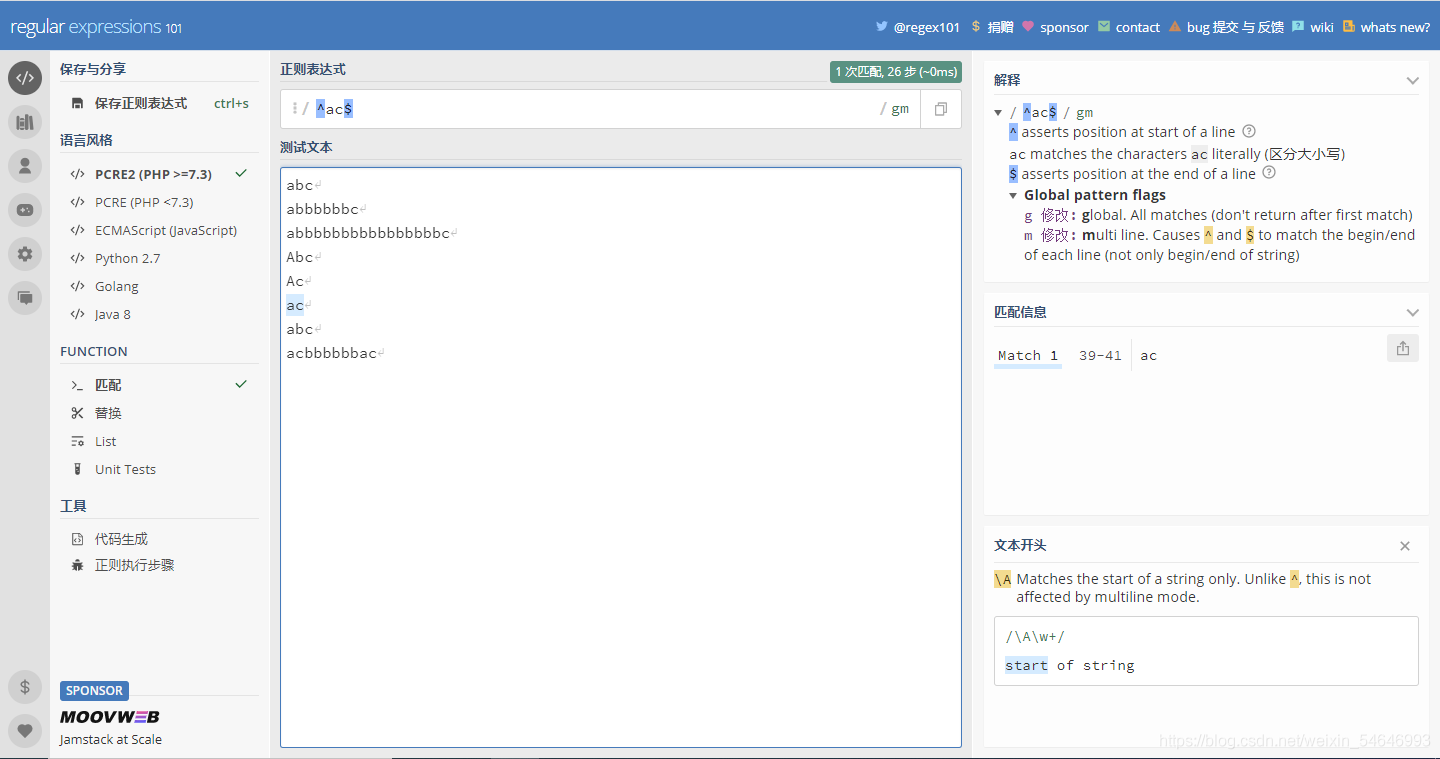
可以發現,單獨使用“^”和“$”匹配都會出現兩次結果,而兩個一起加上去只出現了一個結果,而且這個結果前兩次也出現過,這是什么情況?
似乎有點像找公倍數,
再換個字符試試看,
^bc$
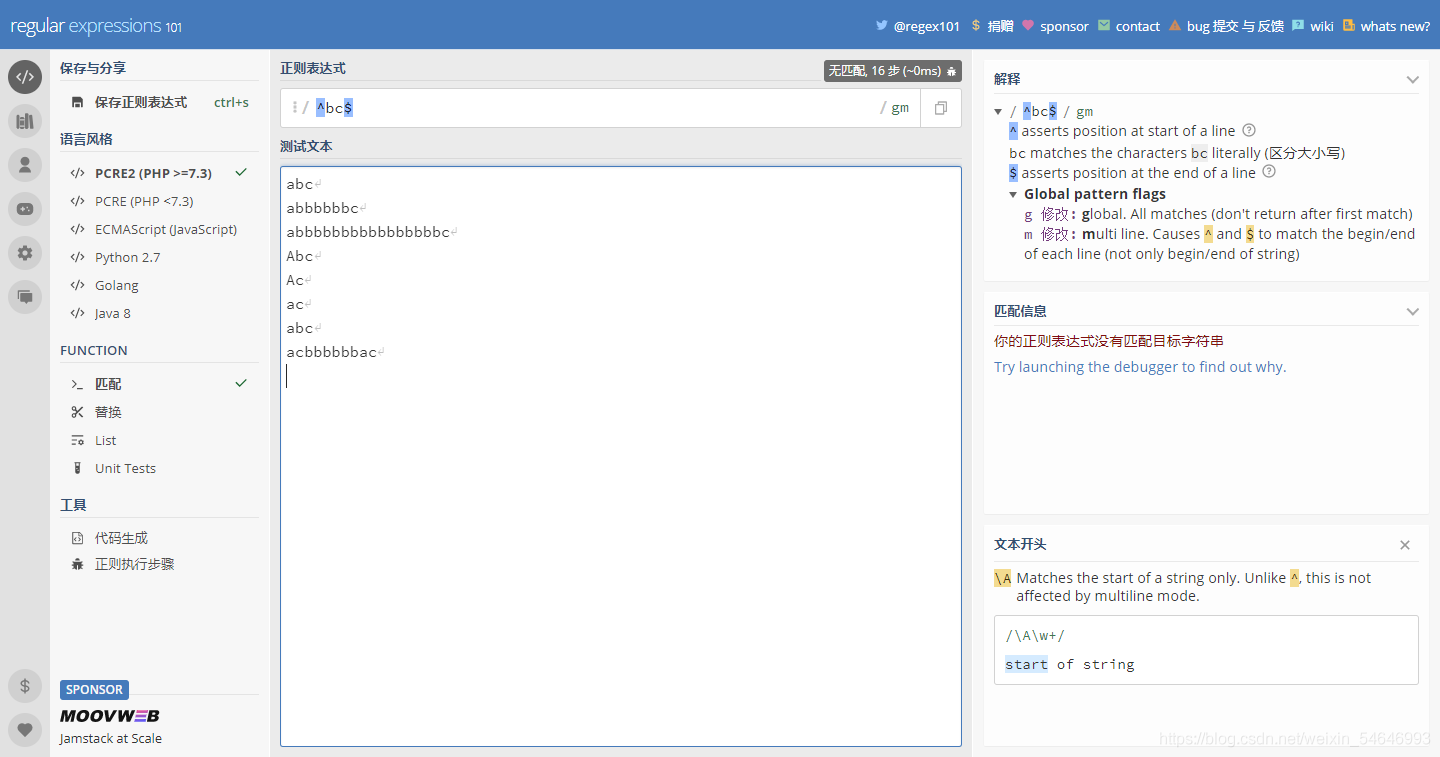
欸,這又是什么意思?怎么一個都沒匹配到?
把“^”去掉試試看
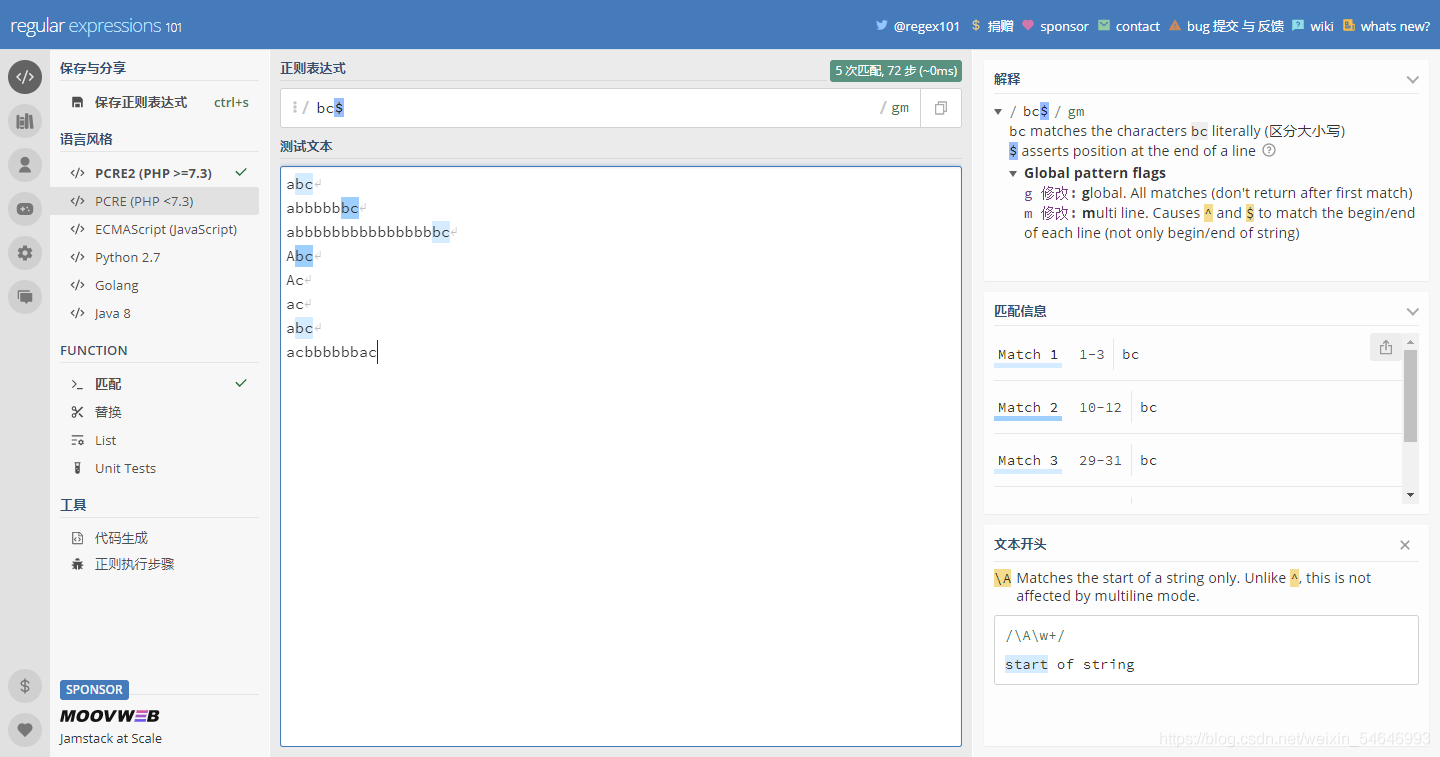
一下子多出了五個!
這下搞懂了,當我們同時對一段字符加上“^”“$”時,它只會匹配占了一行的這一段字符,
為了驗證猜想,試著在加上一行“bc”試一試,
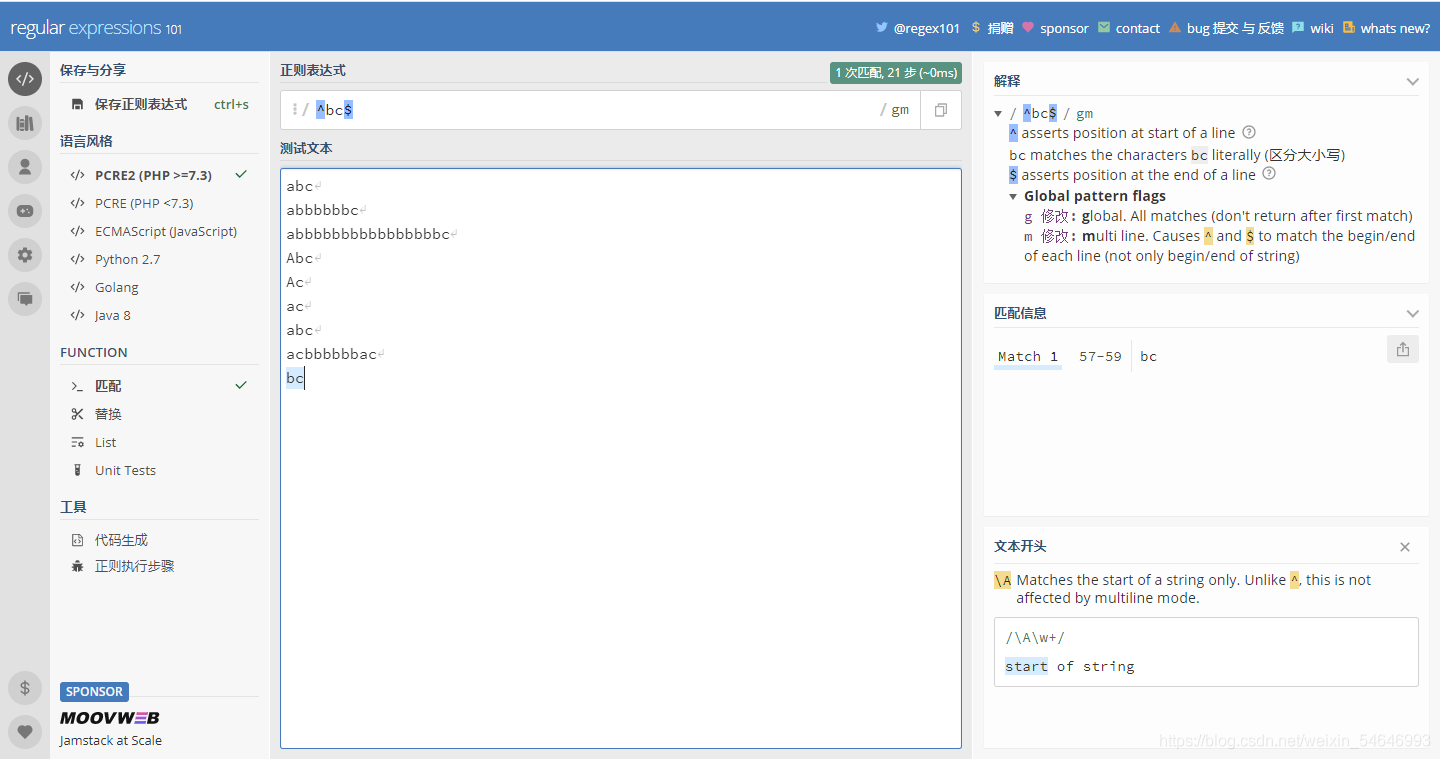
果然如此!
3)i:不區分大小寫
“i”可以幫我們不區分大小寫地去匹配字符,某些場景可以發揮很大的作用
為了方便大家觀察,我選擇加上“g”一起實驗
未加“i”之前:
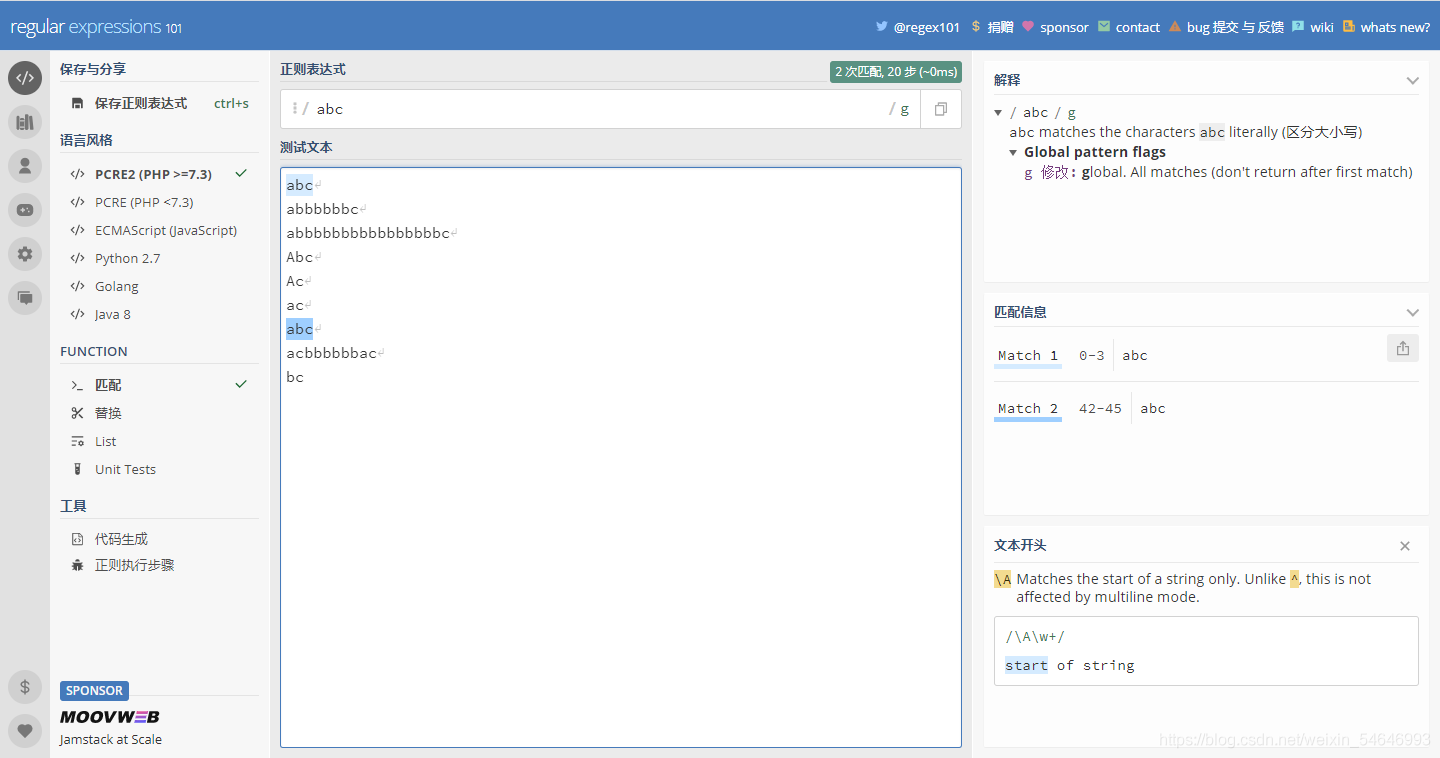
加上“i”之后:
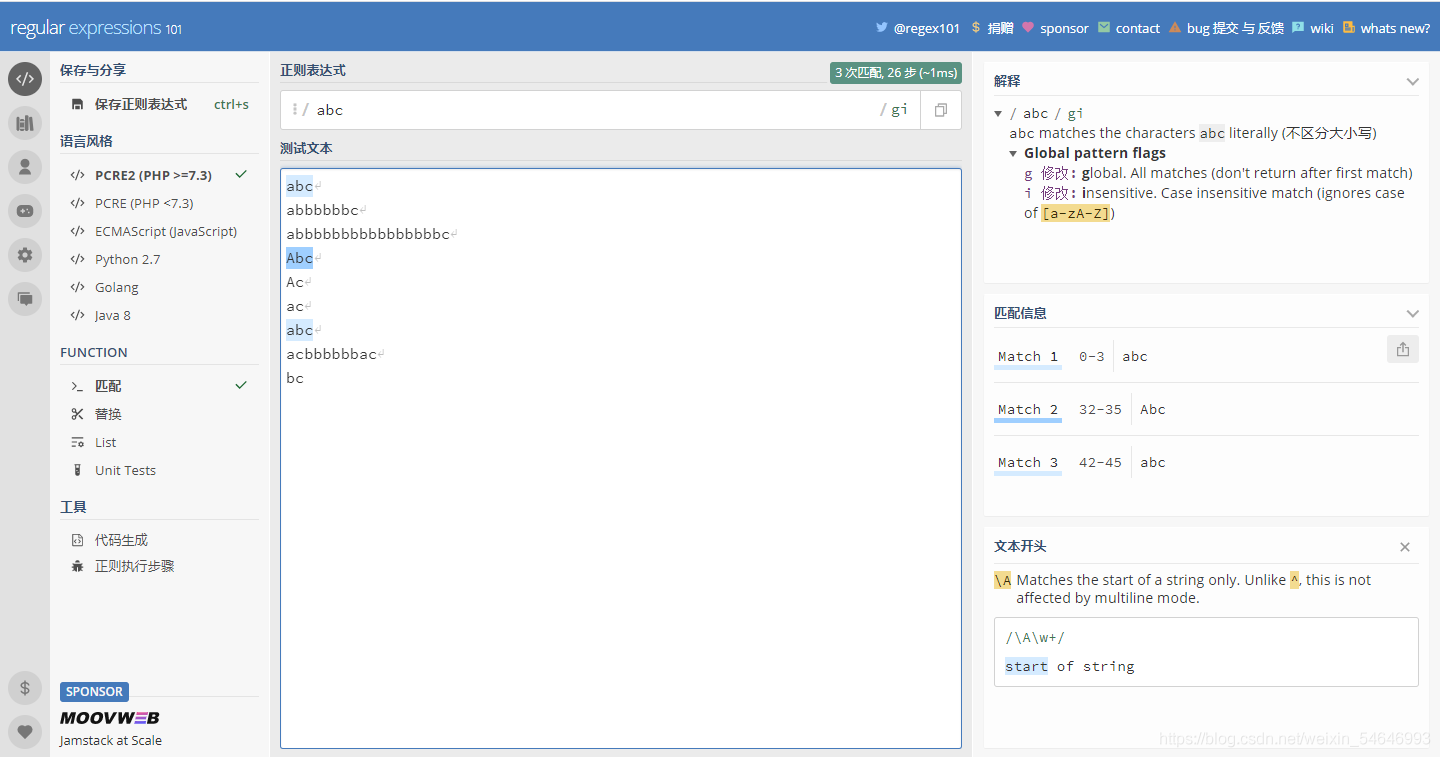
可以發現匹配的結果多出了一個“Abc”
4)x:忽略空白字符,可以多行書寫,并使用#進行注釋說明
“x”的作用是忽略空白字符,可以多行書寫,還可以使用#進行注釋說明
?這次需要分三次講解
首先看“x”的第一個作用:忽略空白字符
直接上圖吧
未加“x”之前:
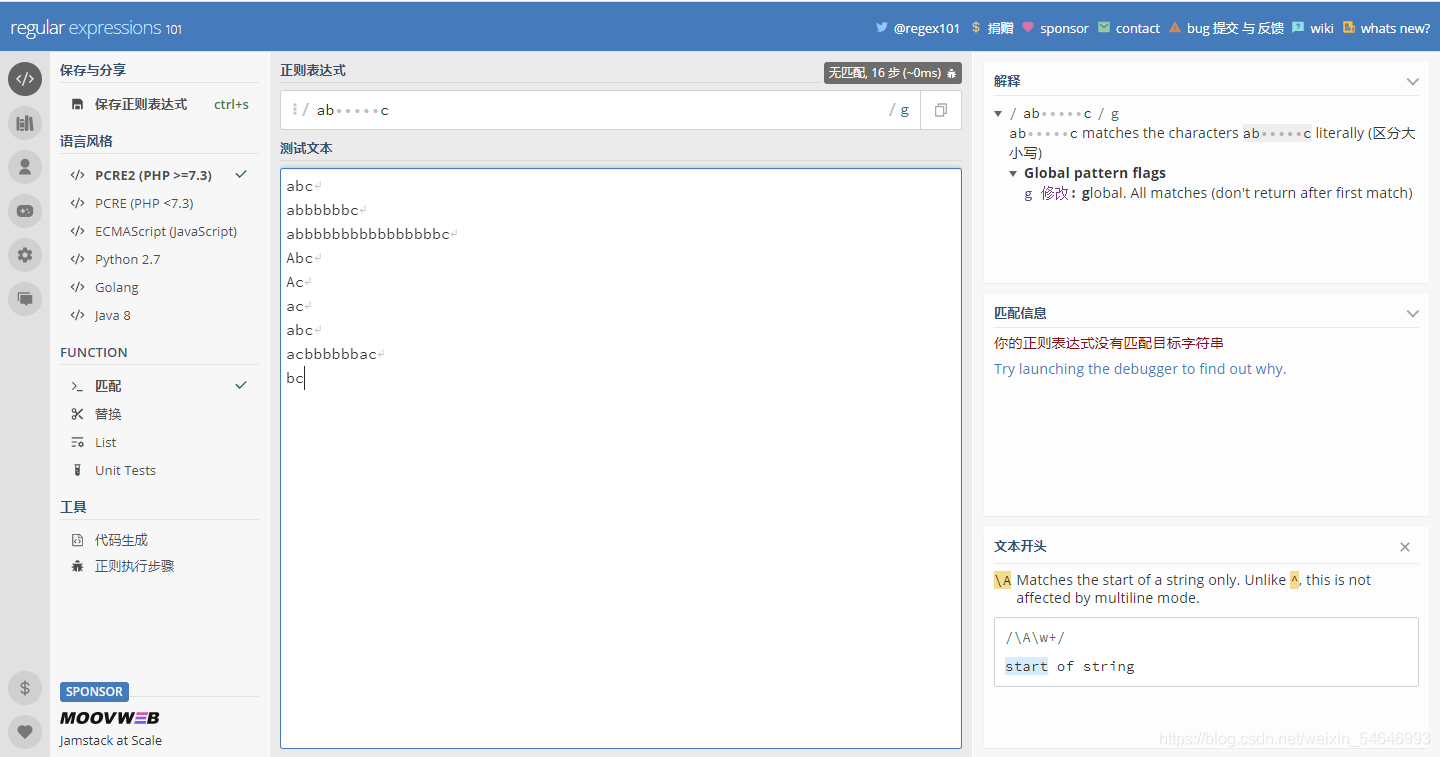
加上“x”之后:
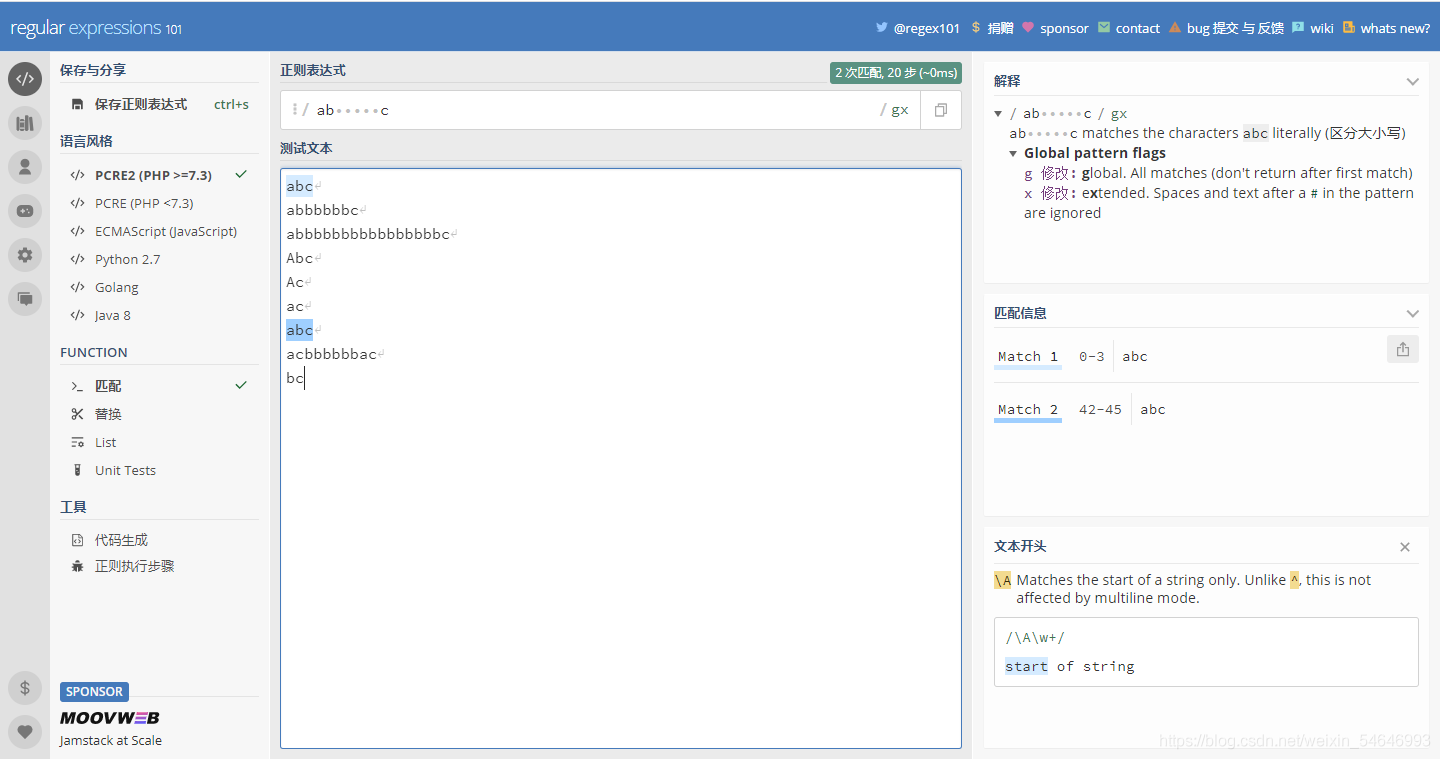
可以發現,加上“x”之后正則運算式直接忽略了空格直接開始匹配
這很好理解,第二個作用和第一個也是一樣的,只是把空格換成了回車
未加“x”之前:
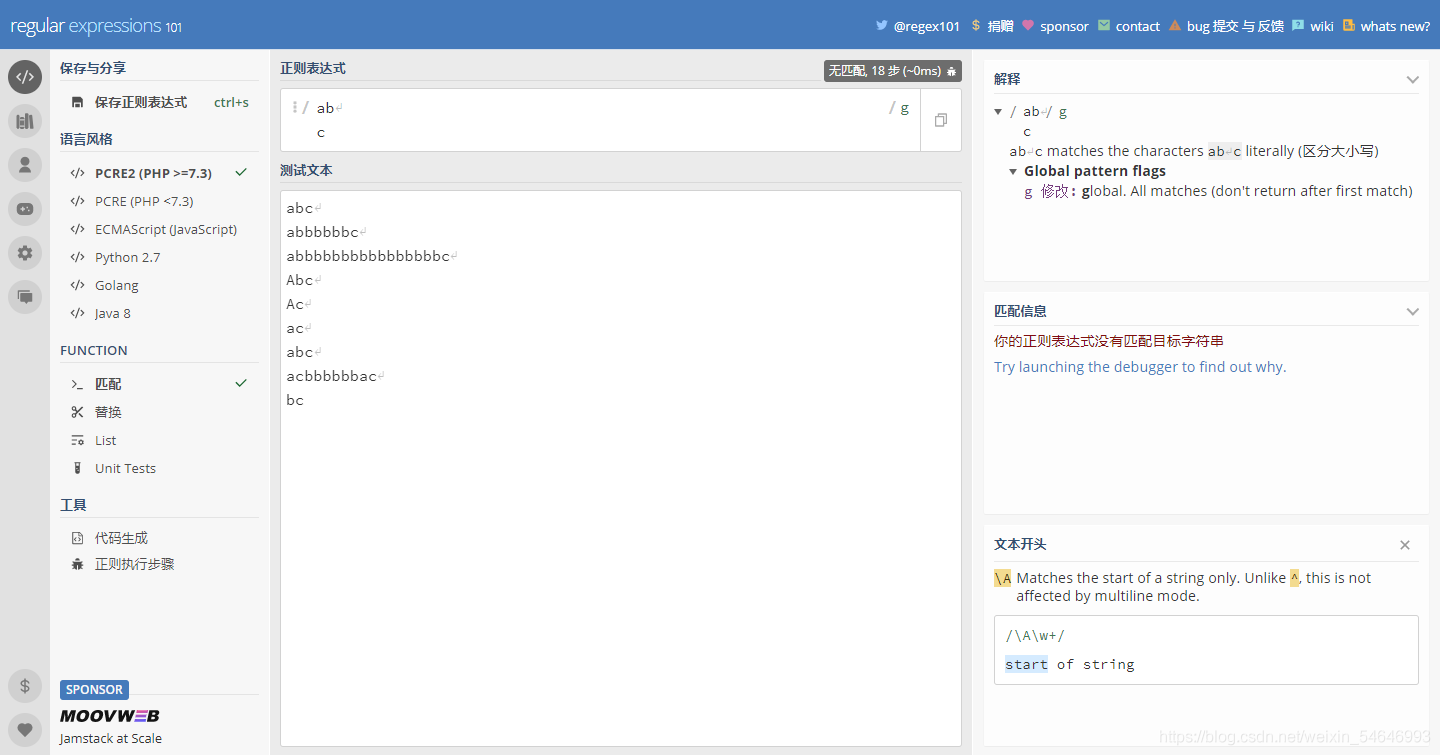
加上“x”之后:
可以看到正則運算式直接忽略了回車直接選擇匹配
? 前面兩種都比較簡單,第三種也一樣簡單
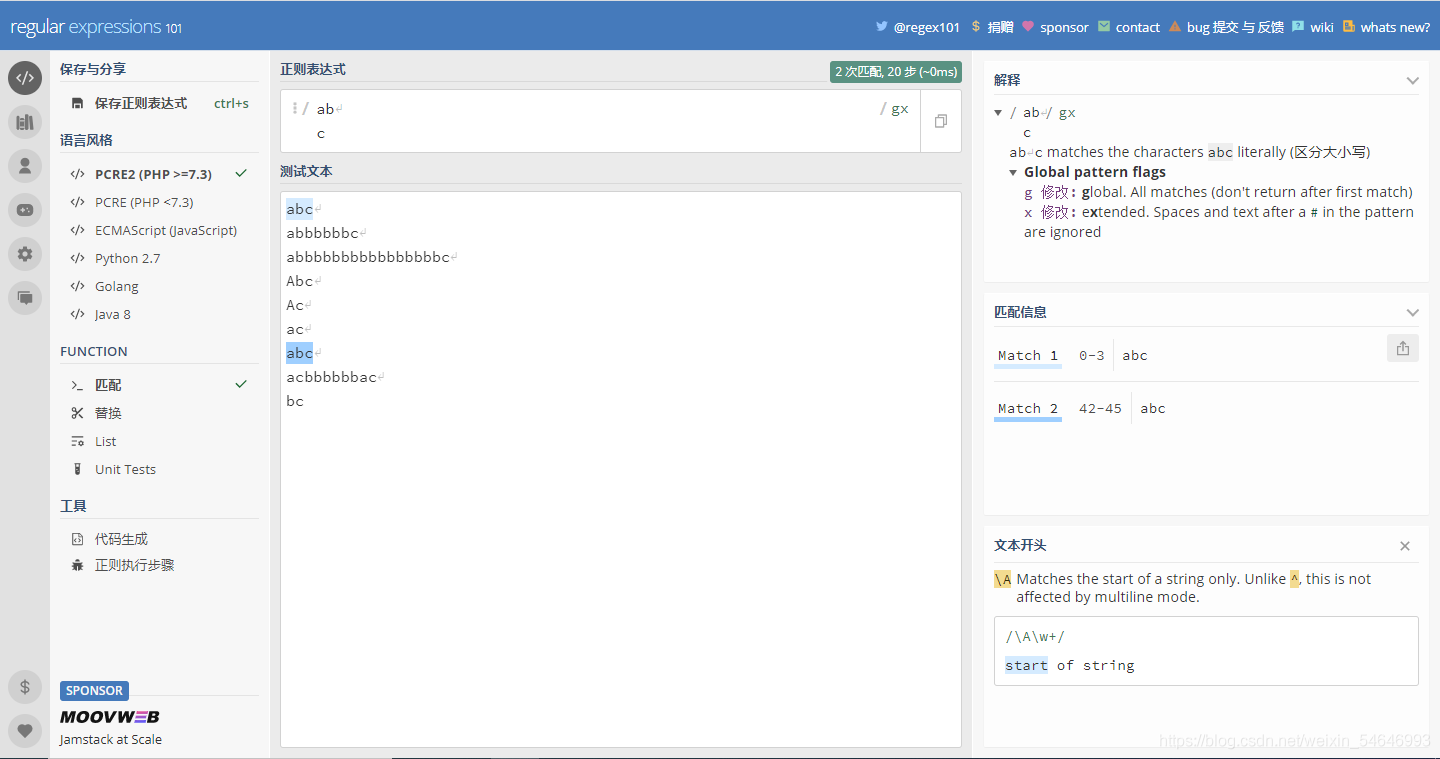
? 使用#進行注釋說明,大家都知道“#”是注釋的意思,加上了就可以把“#”后的字符忽略,正則運算式也是一樣的
? 未加“x”之前:
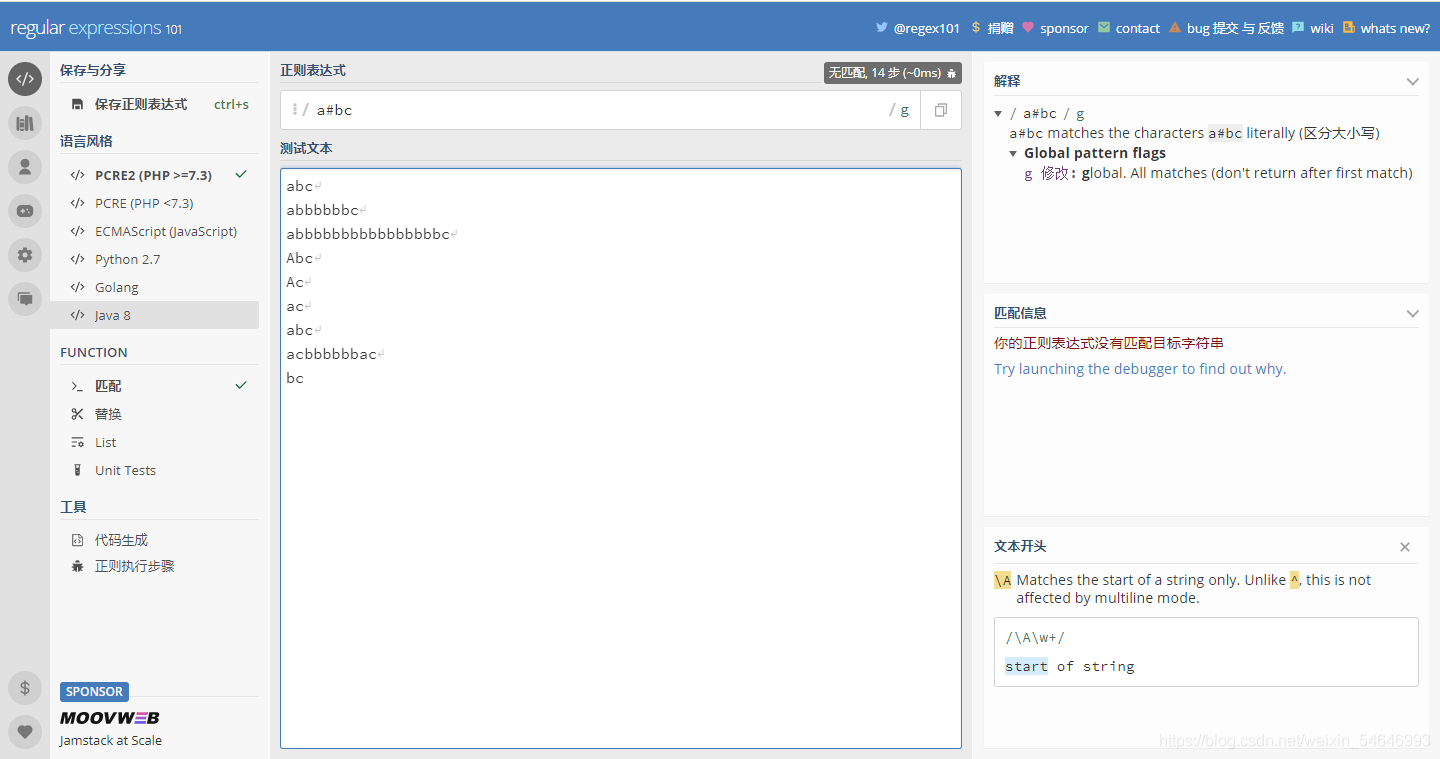
加上"x"之后:
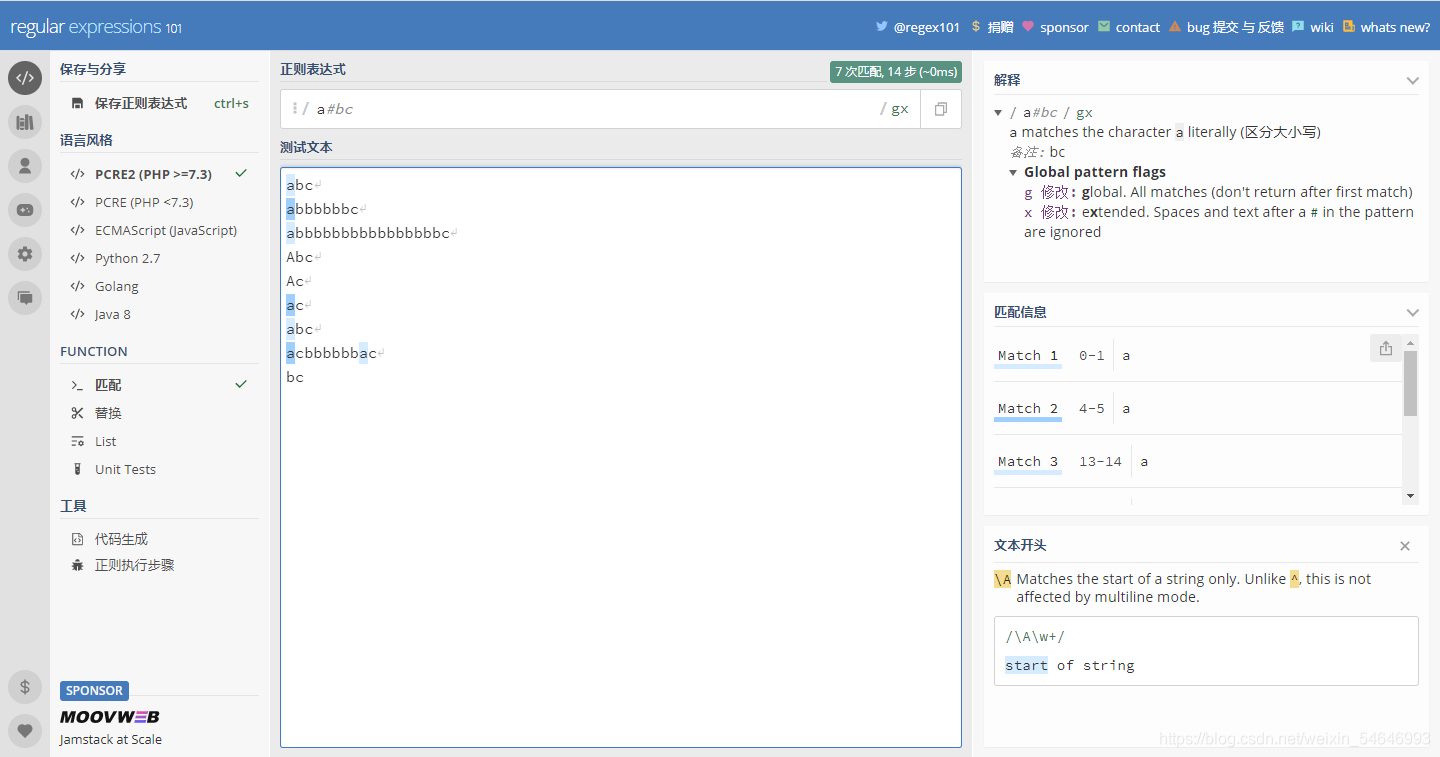
可見“bc”直接被注釋掉了,只剩下“a”
? 由此可見加上“x”之后就可以使用“#”了,
4)s:單行模式(此狀態下”.“可以匹配任意字符,包括換行符)
? 之前講過,”.“可以匹配任意字符,但獨獨不能匹配換行符,當我們選擇了“s”時,”.“就可以匹配換行符了,
? 例子:
a.c
? 未加”s“之前:

加上”s“之后:

可以看到使用”s“以后就可以匹配任何”aXc“格式的字符了,包括換行符,
5)u:模式字串被當作UTF-8
? 當我們選擇“u”時,模式字串就會被正則運算式當作UTF-8,這個不過多解釋,
6)U:使量詞默認為非貪婪模式
? 關于這個“U”稍稍有些難以理解,它可以使量詞默認為非貪婪模式,這是什么意思呢?
? 看下圖:


上面是未加上“U”之前的情況,第一張圖是貪婪模式,第二張是非貪婪模式,這很正常,但加上“U”之后就不對勁了(貪婪模式和非貪婪模式詳見上一篇文章,本文結尾有鏈接),
? 看下圖:


可以發現本該貪婪模式出現的情況卻在非貪婪模式出現了,而非貪婪模式也一樣,
于是可以得出結果:選擇用“U”時,正則運算式就會默認非貪婪模式,當我們嘗試用貪婪匹配的時候,它會給出非貪婪模式所匹配的結果,
7)A:從目標字串的開頭開始匹配
這個“A”和我們之前學的元字符“^”的作用是一樣的,也就是從開頭開始匹配,默認是匹配第一個想匹配的字符,
未加“A”之前:

加上“A”以后:
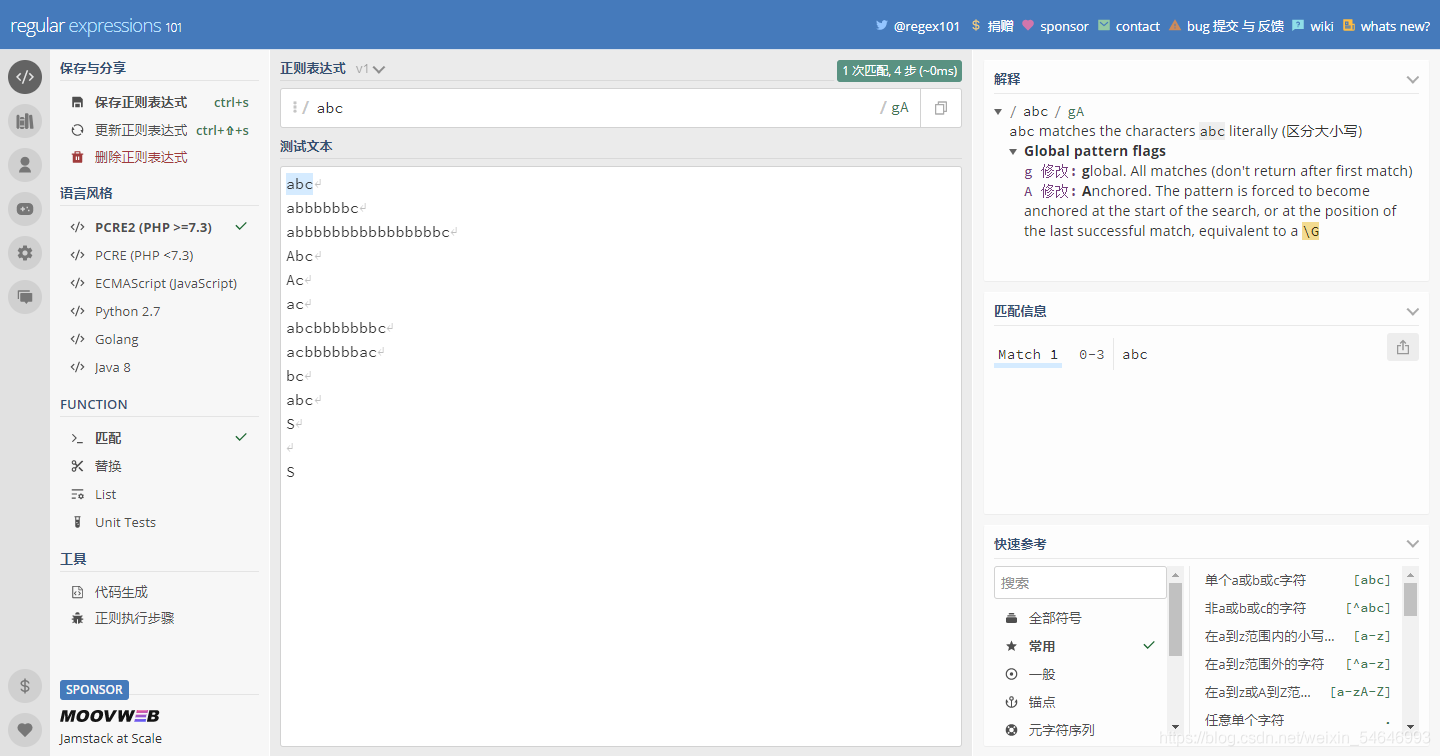
8)Z:從目標字串的末尾或出現在字串末尾的 \n 之前開始匹配
?這個“Z”的作用和元字符“$”一樣,這和”A“是相同的,不再過多贅述(我使用的正則運算式網頁并沒有這個修正詞,所以也不去截屏了)
9)z:從目標字串的末尾開始匹配
?同上,只是比”Z“少了一個功能
10)J:允許子模式重復命名
?這個”J“是用子模式的時候使用的,暫時不去多講,后面學到了再講,
11)D:$ 字符僅匹配目標字串的結尾;沒有此選項時,如果最后一個字符是換行符的話,$ 字符也能匹配
當我們選中”D“時,$ 字符僅匹配目標字串的結尾,這似乎和沒加是一樣的,但其實不然,沒有選擇”D“時,如果最后一個字符是換行符的話,$字符也是可以匹配的
?未加”D“之前:
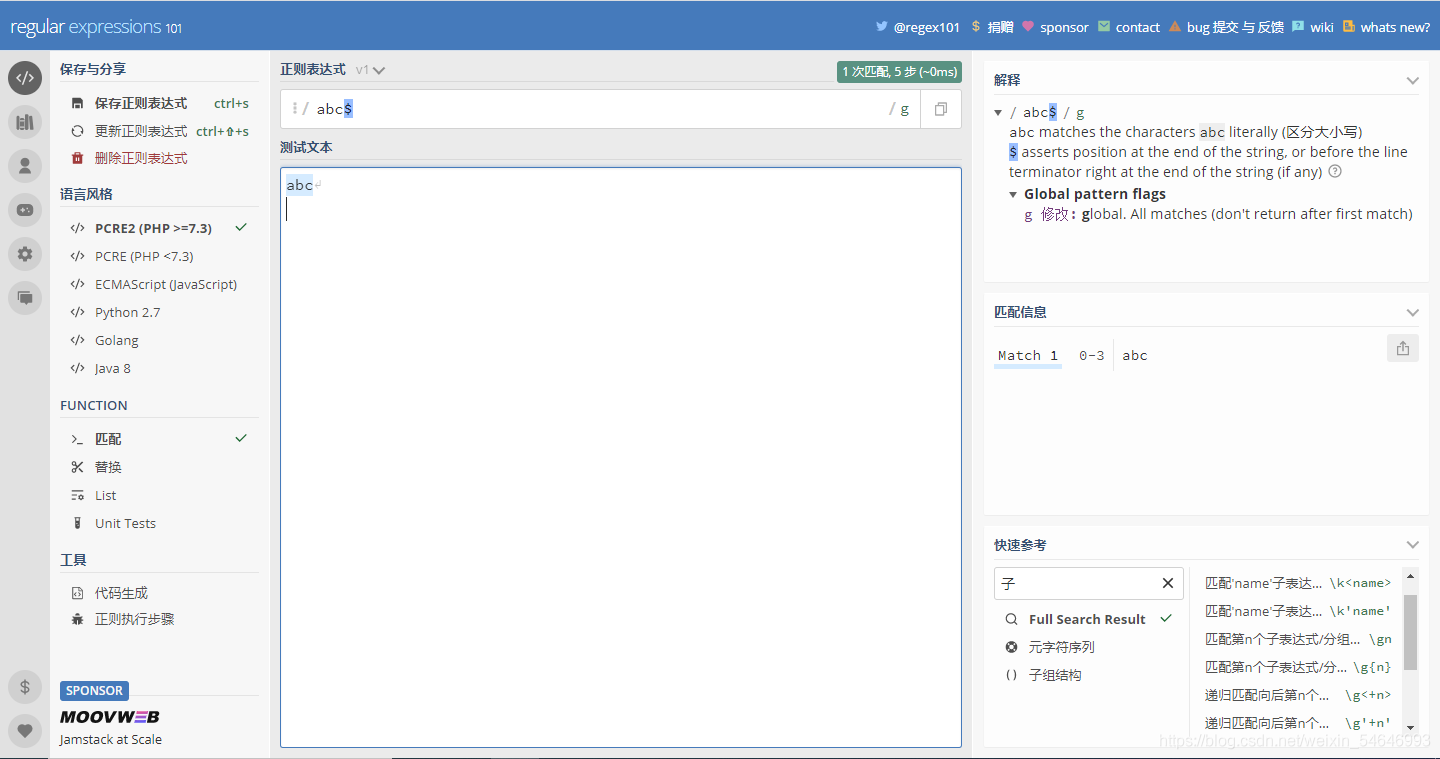
加上”D“之后:
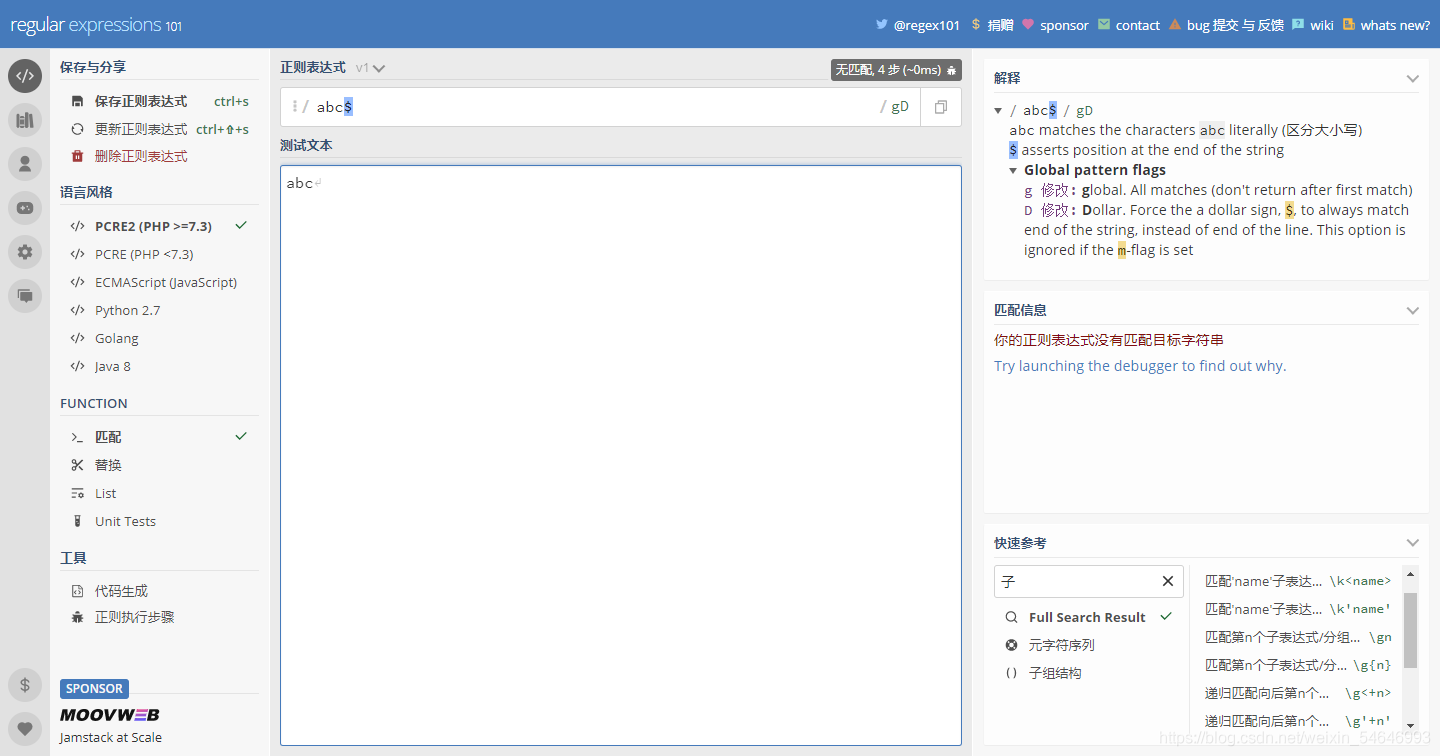
可以看到確實上面所講的一樣,
4.總結
至此,已經講完了絕大部分的內容,如果還有我沒有講到的,那是因為我目前的能力不夠導致的,我會繼續努力,謝謝!
本文運用的正則運算式網址為:https://regex101.com/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/279961.html
標籤:其他