文章目錄
- 一、什么是Hadoop
- 二、Hadoop各個組件的作用
- 三、Hadoop核心組件的架構
- 3.1、HDFS
- 3.2、MapReduce
- 3.3、YARN
- 四、實時計算和離線計算的程序
后端系統通常會有一些需要超大資料集分析的業務場景,比如A/B Test、埋點資料分析、大資料關聯圖譜等,此時需要存盤/分析的資料量以GB甚至是TB作為單位,由于資料量太大,MySQL進行分庫分表后雖然可以解決資料存盤問題,但是無法做到復雜資料分析及查詢,大資料技術就應用在這種業務場景當中,作為一名后端開發者,需要對不同的業務場景選擇合適的技術,學習入門大資料技術是有必要的,
一、什么是Hadoop
Hadoop是一套大資料解決方案,包攬了一筐子技術,使得大資料處理人員能夠簡單高效地對大型資料集進行分布式處理,Hadoop主要解決的大規模資料下的離線資料分析問題,可以用于一次寫入,多次讀取分析,具備較高的處理時延(T+1),其架構核心為MapReduce、HDFS、Yarn,分別為Hadoop提供了分布式計算、分布式存盤以及分布式資源調度的能力,而基于Hadoop的大資料技術則有Hive(離線資料分析)、Spark(實時資料分析)、HBase(分布式NoSQL)等,
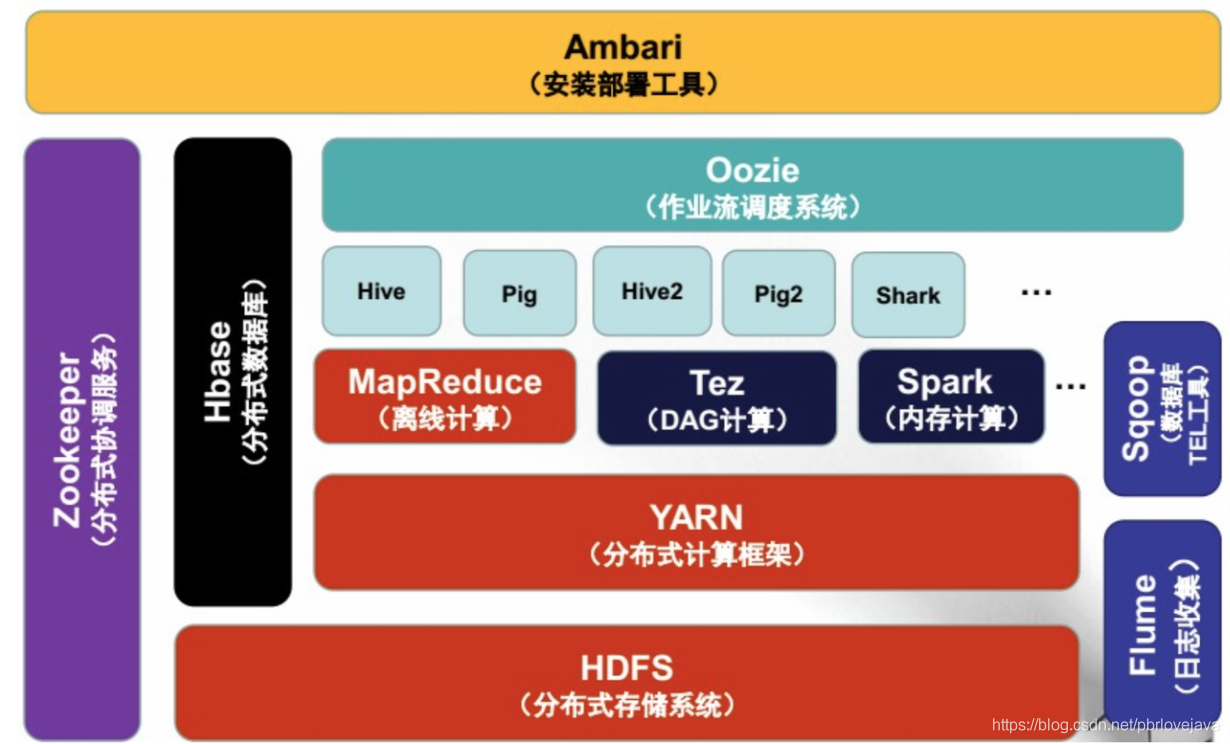
二、Hadoop各個組件的作用
- (Hadoop)HDFS:Hadoop Distributed File System,即Hadoop生態中的分布式檔案系統,它的作用是提供了Hadoop基礎的資料檔案的存盤以及管理,通過HDFS可以使得大資料分布在服務集群之中,解決了資料的單點問題,并且提供了統一的管理方式,HDFS是整個Hadoop生態中的存盤基礎,
- (Hadoop)MapReduce:MapReduce的核心設計思想為Map和Reduce,也就是將大資料拆分成一個個的資料塊,并對這些資料塊進行分布式的處理,最后再進行統一的匯總從而形成最終的計算結果,
- (Hadoop)Yarn:Yarn是Hadoop2.0引入的一種資源管理系統,通過Yarn來計算各個框架之間的資源占用及調度,使得多個運算框架可以運行在同一個集群之中,
- Hive:Hive是基于MapReduce的一個計算框架,Hive通過類似SQL般的HSQL來提交MapReduce計算任務,從而以結構化的方式來對大資料進行分析,
- HBase:HBase是一種構建于HDFS之上的分布式K-V資料庫,用于大量資料寫入及讀取,適用于實時計算,
- Zookeeper:Zookeeper是一個被分布式系統廣泛使用的配置中心服務,能夠對服務集群提供統一命名、狀態同步、集群管理和Leader選舉等服務,
三、Hadoop核心組件的架構
3.1、HDFS
Hadoop Distributed File System,分布式檔案系統,其架構如下:

3.2、MapReduce
用以實作分布式并行計算,計算分為Map和Reduce兩個程序,Map將計算拆分到各個節點中進行,Reduce匯總各節點的計算結果,其架構如下:

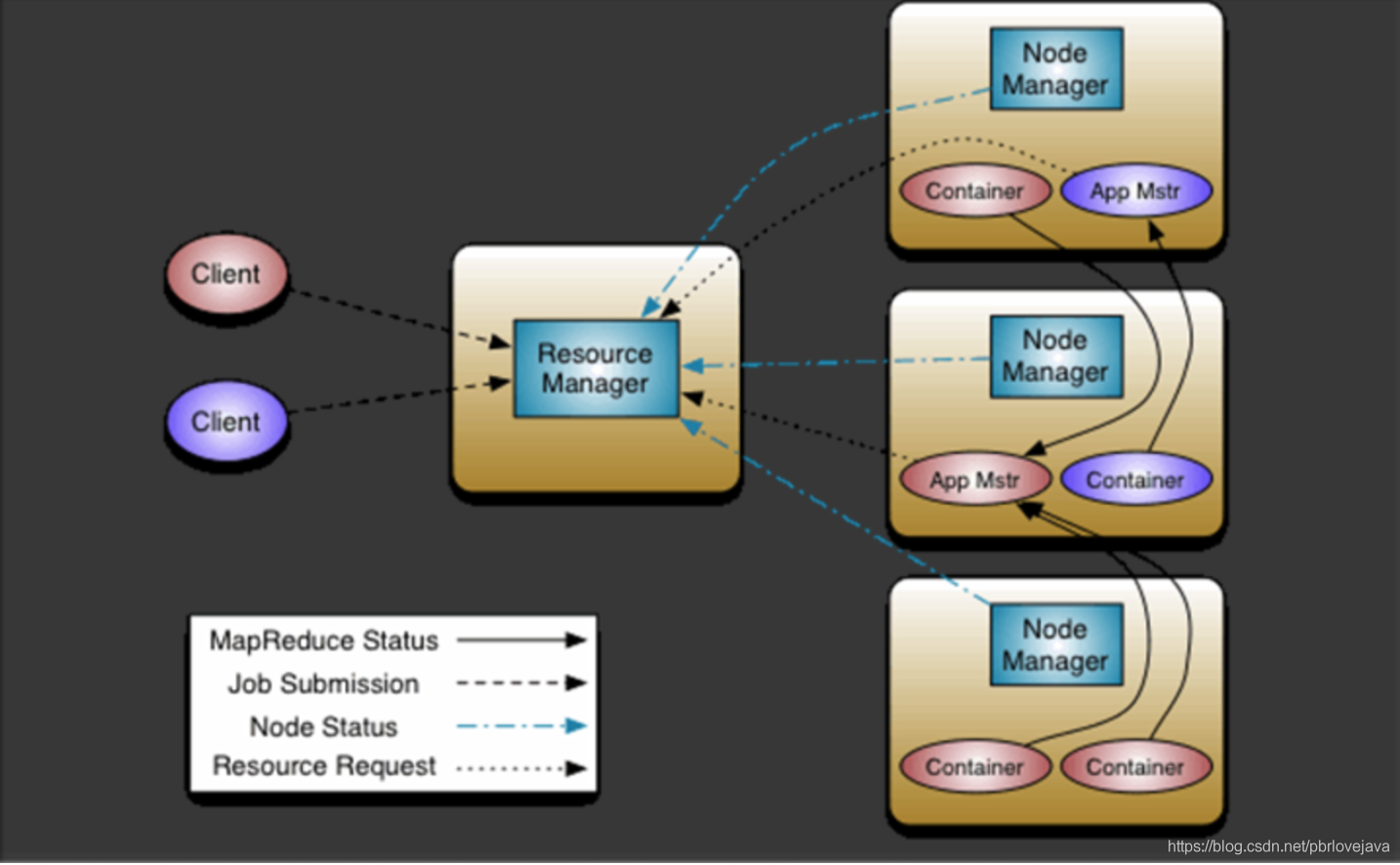
3.3、YARN
YARN是Hadoop 2.0中的分布式資源管理系統,它將Hadoop 1.0版本的MapReduce中的JobTracker拆分成了兩個獨立的服務:一個全域的資源管理器ResourceManager和每個應用程式特有的ApplicationMaster,其中ResourceManager負責整個系統的資源管理和分配,而ApplicationMaster負責單個應用程式的管理,其架構如下:
四、實時計算和離線計算的程序
關于實時計算及離線計算的概念參考該篇文章:
實時計算And 離線計算
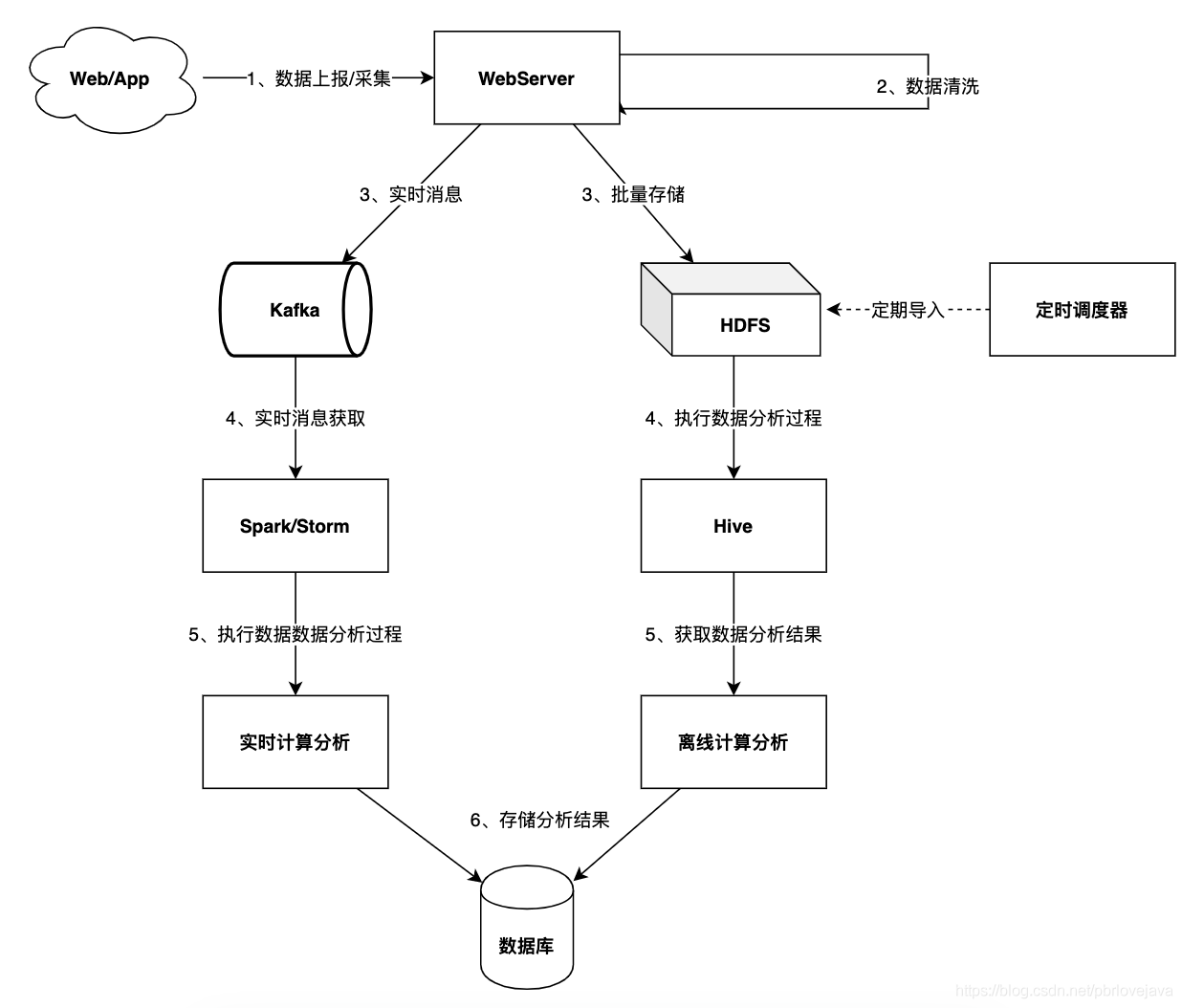
對于大資料的處理,一般分為幾個步驟:
- 資料采集階段:資料收集階段是指通過各類日志、埋點、爬蟲或手工整理的方式來對需要分析的資料進行收集
- 資料清洗階段:資料收集階段收集到的資料為原始資料,需要對其不合規的資料(空值或例外資料)進行剔除或處理
- 資料存盤階段:將清洗好的資料存盤到HDFS系統中(可以通過Hive或Spark這類進行存盤,其底層都為HDFS),以便進行分布式計算分析
- 資料分析階段:通過MapReduce、Hive或Spark進行大資料的分布式計算分析,得出分析結果
- 資料結果持久化:由于每次資料分析需要花費的時間較長,所以需要將分析結果持久化至資料庫中
- 資料可視化:將分析結果進行可視化展示
以下是基于Hadoop的經典的實時計算和離線計算分析的大致流程圖和組件圖:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/279962.html
標籤:其他
上一篇:淺析正則運算式模式修正符