第一章
1.Spark是什么
概念
Spark是一個大規模資料處理的統一分析引擎,
特點
迅速、通用、易用、支持多種資源管理器
迅速
Spark用十分之一的計算資源,獲得了比Hadoop快3倍的速度,
通用
可以用Spark進行sql查詢、流式計算、機器學習、圖計算,
易用
支持多種編程語言API,包括Java、Scala、Python、R
支持多種支援管理器
Spark可以使用單機集群模式來運行,也可以在Hadoop YARN、Apache Mesos、Kubernates上運行,或者在“云”里運行,
Spark可以訪問HDFS、Alluxio、Apache Cassandra、Apache HBase、Apache Hive等上百種資料源,
Spark與Hadoop
區別與聯系
解決問題的方式不一樣
Hadoop是分布式資料設施,
Spark只是一個專門的工具,不會進行分布式資料的存盤,
兩者可合可分
Hadoop可用自身的MapReduce來代替Spark
Spark可不依賴Hadoop,而選擇其他基于云的資料系統平臺,
Spark相對于MapReduce的優勢
中間結果輸出
Hadoop:兩步計算、磁盤存盤
Spark:多步計算、記憶體存盤
資料格式和記憶體布局
Hadoop:使用HDFS
Spark:使用RDD
誤區!!!
1.Spark是基于記憶體的技術
大多數的人會認為Spark都是基于記憶體的計算的,但是基于如下兩個情況,Spark會落地于磁盤
-
Spark避免不了shuffle
-
如果資料過大(比服務器的記憶體還大)也會落地于磁盤
參考鏈接
2.Spark要比Hadoop快 10x-100x
在比較短的作業確實能快上100倍,但是在真實的生產環境下,一般只會快 2.5x ~ 3x!
3.Spark的存在將代替Hadoop
目前備受追捧的Spark還有很多缺陷,比如:
-
穩定性方面,由于代碼質量問題,Spark長時間運行會經常出錯,在架構方面,由于大量資料被快取在RAM中,Java回收垃圾緩慢的情況嚴重,導致Spark性能不穩定,在復雜場景中SQL的性能甚至不如現有的Map/Reduce,
-
不能處理大資料,單獨機器處理資料過大,或者由于資料出現問題導致中間結果超過RAM的大小時,常常出現RAM空間不足或無法得出結果,然而,Map/Reduce運算框架可以處理大資料,在這方面,Spark不如Map/Reduce運算框架有效,
-
不能支持復雜的SQL統計;目前Spark支持的SQL語法完整程度還不能應用在復雜資料分析中,在可管理性方面,SparkYARN的結合不完善,這就為使用程序中埋下隱憂,容易出現各種難題,
參考鏈接
用途
推薦系統
實時日志系統
快速查詢系統
定制廣告系統
用戶圖計算系統
2.Spark的生態系統
生態系統
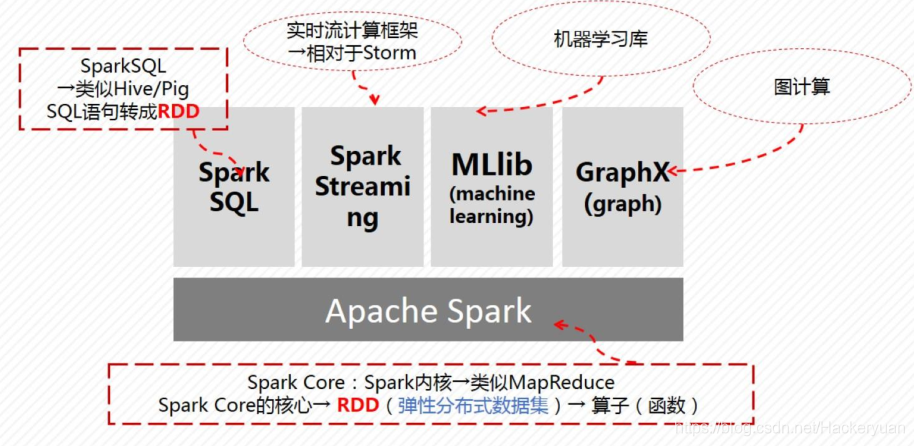
Spark Core
Spark Core提供Spark SQL、Spark Streaming、MLlib、GraphX四大模塊,進行離線計算,產生RDD彈性分布式資料集,
Spark SQL && DataFrame
Spark SQL是一種結構化的資料處理模塊,
DataFrame是Spark SQL提供的一個編程抽象,相當于一個列資料的分布式的采集組織,在關系資料庫或R/Python中的概念相當于一個表,
Spark Streaming
Spark Streaming處理實時資料流并容錯,
MLIib
MLlib是Spark提供的可擴展的機器學習庫
MLlib提供的API主要分為以下兩類:
- spark.mllib包提供主要API
- spark.ml包提供構建機器學習作業流的高層次API
GraphX
GraphX是Spark面向圖計算提供的框架與演算法庫
3.Spark的架構與原理
常見術語


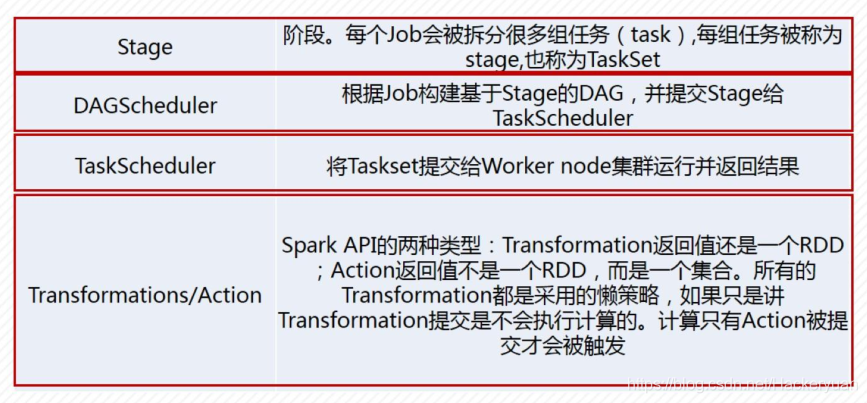
架構設計
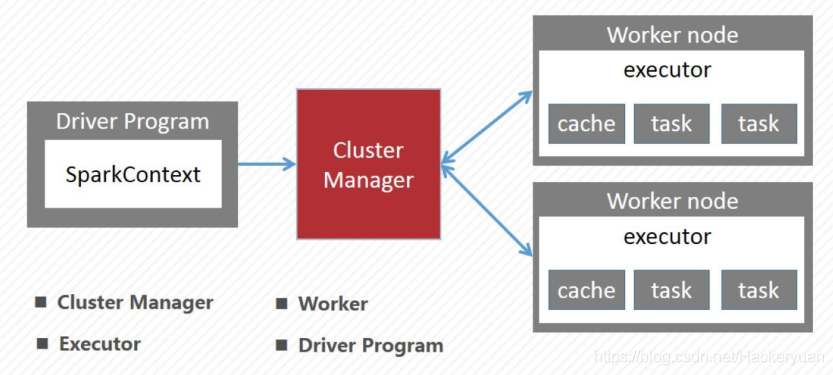
作業運行流程
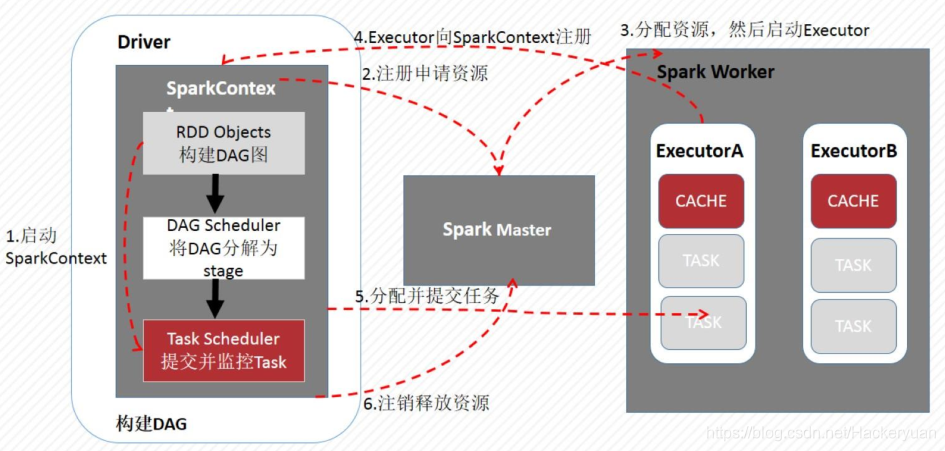
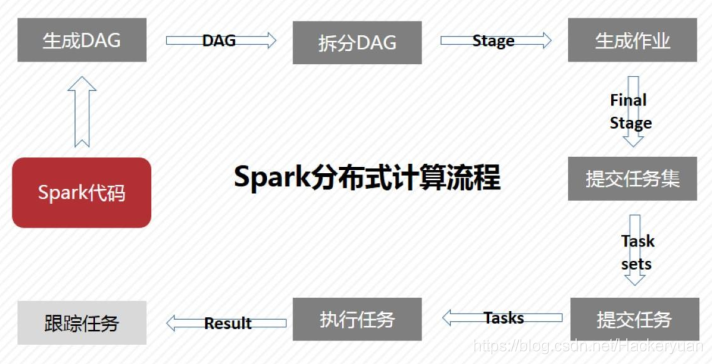
核心原理
4.Spark 2.X新特性
2.x對比1.x
2.x基本上是基于1.x進行了更多的功能和模塊的擴展以及性能的提升:
- 引入很多優秀特性,性能上有較大提升,API更易用
- 實作了離線計算和流計算API的統一
- 實作了Spark SQL和 Hive SQL操作API的統一
新特性
1.精簡的API
- 統一DataFrame和Dataset介面為datasets
- 新增SparkSession入口,統一舊的SQLContext與HiveContext
- 支持SQL 2003標準,支持子查詢,Spark SQL性能有2-10倍的提升
2.搭載了第二代引擎
主要思想:在運行時使用優化后的位元組碼,將整體查詢合成為單個函式,不再使用虛擬函式呼叫,而是利用CPU來注冊中間資料,
3.智能化程度
- Structured Streaming引入了低延遲的連續處理
- 通過改善Pandas UDFs的性能來提升PySpark
- 支持第四種調度引擎 Kubernetes Clusters
- 支持 Stream-to-stream Joins
第二章
1.Spark環境搭建
2.Spark集群啟動與關閉
Spark運行模式
- 在mesos或者yarn集群管理器上部署運行
- 在standalone和local的模式下部署運行
啟動
start-all.sh(已設定好環境變數)
關閉
stop-all.sh(已設定好環境變數)
3.Spark應用提交到集群
spark-submit //提交任務命令
--master spark://master:7077 //提交集群的地址
--deploy-mode client //部署模式為client模式
--executor-memory 512M //設定每個執行單元使用512Mb的記憶體空間
--total-executor-cores 4 //每個執行單元為4個核
demo.py //實際提交的應用程式,具體以實際為準
第三章
1.Python編程語言
不用多說,,,
2.Pyspark啟動與日志設定
PySpark啟動
local、standalone、yarn、mesos
以local模式啟動
pyspark --master local[4]
以Yarn模式啟動
pyspark --master yarn-client
以Standalone模式啟動
pyspark --master spark://Spark:7077
以Mesos模式啟動
pyspark --master mesos://Mesos:7077
日志設定
日志級別包括:ALL,DEBUG,ERROR,FATAL,INFO,OFF,TRACE,WARN
控制日志輸出內容的方式有兩種:
-
修改
log4j.properties,默認控制臺輸出INFO及以上級別資訊log4j.rooCategory=INFO,console -
代碼中使用
setLogLevel(logLevel)控制日志輸出
from pyspark import SparkContext
sc = SparkContext("local", "First App")
sc.setLogLevel("WARN")
3.PySpark開發
就是安裝環境,編譯器可以用Anaconda,Jupyter notebook,pycharm,pyspark是一個python的第三方庫,可以通過pip安裝,但是如果安裝了Spark包,bin目錄里會包含pyspark
第四章
1.RDD簡介
幾個問題
RDD是什么?
- 彈性分布式資料集
- 只讀的、磁區記錄的集合
- 只能基于在穩定物理存盤中的資料集和其他已有的RDD上執行確定性操作來創建
什么是彈性?
- RDD可以在記憶體和磁盤之間手動或自動切換
- RDD可以通過轉換成為其他的RDD
- RDD可以存盤任意型別的資料
存盤的內容?
初代RDD:真實資料的磁區資訊,單個磁區的讀取方法
子代RDD:初代RDD產生子代RDD的原因(動作),初代RDD的參考
資料讀取發生在什么時候?
task在executor上運行的時候
五個主要屬性
| 磁區資訊(Partition) | 資料集的基本組成單位 |
|---|---|
| Compute函式 | 對于給定的資料集,需要做哪些計算 |
| Partitioner函式 | 對于計算出來的資料結果如何分發 |
| 優先位置串列 | 對于data partition的位置偏好 |
| 依賴關系 | 描述了RDD之間的Lineage |
創建RDD
下面代碼都是Python API,使用pyspark
基于外部資料源創建
distFile = sc.textFile("file:///FILE_TO_PATH")
#textFile支持從多種源創建RDD,如hdfs://,s3n://
distFile.count()
#計算文本的行數
基于資料集合創建
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data) #通過并行化創建RDD
#parallelize可以傳入分片個數引數,否則采用defaultParallelism
distData.count() #回傳RDD中元素的個數
RDD操作
兩種算子(Operation)
| 轉換(transformation) | 在一個已存在的RDD上創建一個新的RDD,但實際的計算并沒有執行,僅僅記錄操作程序 |
|---|---|
| 行動(action) | 執行RDD記錄的所有運行transformations操作,并計算結果,結果可回傳到driver程式 |
如何區分?
- transformation算子一定會回傳一個rdd
- Action有的沒有回傳值,也可能有回傳值,但是一定不是rdd
2.RDD算子
Transformation算子-Value型
map(f, preservesPartitioning=False)
通過對這個RDD的每個元素應用一個函式來回傳一個新的RDD,
>>> rdd = sc.parallelize(['b', 'a', 'c'])
>>> sorted(rdd.map(lambda x: (x, 1)).collect())
[('a',1), ('b',1), ('c',1)]
flatMap(f, preservesPartition=False)
將函式應用于該RDD的所有元素,然后將結果平坦化(壓扁),從而回傳新的RDD,
>>> rdd = sc.parallelize([2, 3, 4])
>>> rdd2 = rdd.map(lambda x: range(1, x))
>>> rdd2.collect()
[[1], [1, 2], [1, 2, 3]]
>>> rdd1 = rdd.flatMap(lambda x: range(1, x))
>>> rdd1.collect()
[1, 1, 2, 1, 2, 3]
flatMap與map的區別:
| map | 映射 |
|---|---|
| flatMap | 先映射,后扁平化 |
| – | – |
| map對每一次(func)都產生一個物件,分別產生一個串列 | flatMap多一步,最后會將所有物件合并為一個串列回傳 |
mapPartitions(f, preservesPartitioning=False)
它的輸入函式應用于每個磁區,也就是把每個磁區中的內容作為整體來處理的
>>> rdd = sc.parallelize([1, 2, 3, 4], 2)
# 上面第二個引數是磁區數,所以分成了[1, 2]和[3, 4],
# 不管磁區數為多少,都是取下界,比如上面假如磁區數為3,則界限分別在4/3和8/3,取下界則分成[1], [2], [3, 4],
>>> def f(iterator): yield sum(iterator)
>>> rdd.mapPartitions(f).collect()
[3, 7]
mapPartitionsWithIndex(f, preservesPartitioning=False)
與mapPartitions的區別在于mapPartitionsWithIndex中傳入的函式要求接收兩個引數
第一個引數為磁區編號
第二個為對應磁區的元素組成的迭代器
>>> rdd = sc.parallelize([1, 2, 3, 4], 4) # [1] [2] [3] [4]
>>> def f(splitIndex, iterator): yield splitIndex
>>> rdd.mapPartitionsWithIndex(f).sum()
6 # 0+1+2+3
filter(f)
對每個元素應用f函式,回傳值為true的元素在RDD中保留,回傳值為false的元素將被過濾掉,
>>> rdd = sc.parallelize([1, 2, 3, 4, 5])
>>> rdd.filter(lambda x: x % 2 == 0).collect()
[2, 4]
distinct(numPartitions=None)
將RDD中的元素進行去重操作
>>> rdd = sc.parallelize([1, 1, 2, 3])
>>> rdd.distinct().collect()
[1, 2, 3]
union(other)
合并兩個RDD,結果中包含兩個RDD中的所有元素
>>> rdd1 = sc.parallelize([1, 2, 3, 4])
>>> rdd2 = sc.parallelize([5, 6, 7, 8])
>>> rdd1.union(rdd2).collect()
[1, 2, 3, 4, 5, 6, 7, 8]
intersection(other)
回傳這個RDD和另一個RDD的交集,輸出將不包含任何重復的元素
>>> rdd1 = sc.parallelize([1, 10, 2, 3, 4, 5])
>>> rdd2 = sc.parallelize([1, 6, 2, 3, 7, 8])
>>> rdd1.intersectioni(rdd2).collect()
[1, 2, 3]
substract(other)
回傳RDD1中出現,但是不在RDD2中出現的元素,不去重
>>> rdd1 = sc.parallelize([('a', 1), ('b', 4), ('b', 5), ('a', 3)])
>>> rdd2 = sc.parallelize([('a', 3), ('c', None)])
>>> rdd1.subtract(rdd2).collect()
[('a', 1), ('b', 4), ('b', 5)]
sortBy(K, ascending=True, numPartitions=None)
根據指定的Key進行排序
>>> tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
>>> sc.parallelize(tmp).sortBy(lambda x: x[0]).collect()
[('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
>>> sc.parallelize(tmp).sortBy(lambda x: x[1]).collect()
[('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
Transformation算子-Key-Value型
mapValues(f)
針對(Key, Value)型資料中的Value進行Map操作,而不對Key進行處理,
>>> rdd = sc.parallelize([('a', 1), ('b', 2), ('c', 3)])
>>> rdd.mapValues(lambda value: value + 2).glom().collect() # glom()將同一磁區的元素合并到一個串列里
[[('a', 3), ('b', 4), ('c', 5)]]
flatMapValues(f)
完成mapValues處理后,再對結果進行扁平化處理,
>>> rdd = sc.parallelize([('a', ['x', 'y']), ('b', ['p', 'r'])])
>>> rdd.flatMapValues(lambda x: x).collect()
[('a', 'x'), ('a', 'y'), ('b', 'p'), ('b', 'r')]
reduceByKey(func, numPartitions=None, partitionFunc=portable_hash)
相同Key值的value值進行對應函式運算,類似于hdp得combiner操作,
>>> from operator import add
>>> rdd = sc.parallelize([('a', 1), ('b', 2), ('a', 3)])
>>> rdd.reduceByKey(add).collect()
[('a', 4), ('b', 2)]
groupByKey(numPartitions=None, partitionFunc=portable_hash)
將Pair RDD中相同Key的值放在一個序列中
>>> rdd = sc.parallelize([('a', 1), ('b', 1), ('a', 1)])
>>> rdd.groupByKey().mapValues(len).collect()
[('a', 2), ('b', 1)]
>>> rdd.groupByKey().mapValues(list).collect()
[('a', [1 1]), ('b', [1])]
sortByKey(ascending=True, numPartitions=None, keyfunc=lambda x:x)
根據key值進行排序,默認升序
>>> tmp = [('a', 1), ('B', 2), ('1', 3), ('d', 4)]
>>> sc.parallelize(tmp).sortByKey()
[('1', 3), ('B', 2), ('a', 1), ('d', 4)]
>>> sc.parallelize(tmp).sortByKey(True, None, keyfunc=lambda k: k.lower()).collect()
[('1', 3), ('a', 1), ('B', 2), ('d', 4)]
keys()
回傳一個僅包含鍵的RDD
>>> m = sc.parallelize([(1, 2), (3, 4)]).keys()
>>> m.collect()
[1, 3]
values()
回傳一個僅包含值的RDD
>>> m = sc.parallelize([(1, 2), (3, 4)]).values()
>>> m.collect()
[2, 4]
joins(rdd)
可以將兩個RDD按照相同的Key值join起來
>>> x = sc.parallelize([('a', 1), ('b', 4)])
>>> y = sc.parallelize([('a', 2), ('a', 3)])
>>> x.join(y).collect()
[('a', (1, 2)), ('a', (1, 3))]
leftOuterJoin(rdd)
左外連接,與SQL中的左外連接一致
>>> x = sc.parallelize([('a', 1), ('b', 4)])
>>> y = sc.parallelize([('a', 2)])
>>> x.leftOuterJoin(y).collect()
[('a', (1, 2)), ('b', (4, None))]
rightOuterJoin(rdd)
右外連接,與SQL中的右外連接一致
>>> x = sc.parallelize([('a', 1), ('b', 4)])
>>> y = sc.parallelize([('a', 2)])
>>> x.rightOuterJoin(y).collect()
[('a', (1, 2))]
Action算子
collect()
回傳RDD中的所有元素,
>>> sc.parallelize([1, 2]).collect()
[1, 2]
count()
回傳RDD中的所有元素的個數,
>>> sc.parallelize([1, 2]).count()
2
reduce(f)
通過指定的聚合方法來對RDD中元素進行聚合,
>>> from operator import add
>>> sc.parallelize([1, 2, 3 ,4 ,5]).reduce(add)
15
>>> sc.parallelize([]).reduce(add)
Traceback (most recent call last):
ValueError: Can not reduce() empty RDD
take(num)
從RDD中回傳前num個元素的串列
>>> sc.parallelize([4, 6, 8, 2, 9]).take(2)
[4, 6]
>>> sc.parallelize([4, 6, 8, 2, 9]).take(10)
[4, 6, 8, 2, 9]
takeOrdered(num)
從RDD中回傳前num個最小的元素的串列,結果默認升序排列
>>> sc.parallelize([4,6,8,2,9]).takeOrdered(2)
[2, 4]
>>> sc.parallelize([4,6,8,2,9]).takeOrdered(10)
[2, 4, 6, 8, 9]
first()
從RDD中回傳第一個元素
>>> sc.parallelize([2,3,4,5,6]).first()
2
top(num, key=None)
從RDD中回傳最大的前num個元素串列,結果默認降序排列
如果Key引數有值,則先對各元素進行對應處理
注:會把所有資料都加載到記憶體,所以該方法只有在資料很小時使用
>>> sc.parallelize([10,4,2,12,3]).top(1)
[12]
>>> sc.parallelize([2,3,4,5,6],2).top(2)
[6, 5)
>>> sc.parallelize([10, 4, 2, 12, 3]).top(4, key=str)
[4, 3, 2, 12]
foreach(f)
遍歷RDD的每個元素,并執行f函式操作,無回傳值
>>> def f(x): print(x)
>>> sc.parallelize([1, 2, 3, 4, 5]).foreach(f)
1
2
3
4
5
foreachPartition(f)
對每個磁區執行f函式操作,無回傳值
>>> def f(iterator):
... s = sum(iterator)
... print(s)
>>> sc.parallelize([1,2,3,4,5],3).foreachPartition(f) # 1 2+3+4 5
1
9
5
saveAsTextFile(path, compressionCodecClass=None)
將RDD中的元素以字串的格式存盤在檔案系統中,
>>> rdd = sc.parallelize(['foo', 'bar'], 2)
>>> rdd.saveAsTextFile('/home/...')
>>> rdd.saveAsTextFile('hdfs://host:8020/...')
collectAsMap()
以字典形式,回傳PairRDD中的鍵值對,如果key重復,則后面的value覆寫前面的,
>>> rdd = sc.parallelize([(1, 2), (3, 4)])
>>> rdd.collectAsMap()
{1: 2, 3: 4}
>>> rdd = sc.parallelize([(1, 2), (3, 4), (1, 4)])
{1: 4, 3: 4}
countByKey()
以字典形式,回傳PairRDD中key值出現的次數
>>> rdd = sc.parallelize([('a', 1), ('b', 1), ('a', 1)])
>>> rdd.countByKey()
[('a', 2), ('b', 1)]
3.共享變數
累加器
accumulator:一個全域共享變數, 可以完成對資訊進行聚合操作,
counter = sc.accumulator(0)
rdd = sc.parallelize(range(10))
def increment(x):
global counter
counter += x
rdd.foreach(increment)
print("Counter value: ", counter.value)
# Counter value: 45
注意事項!!!
- 累加器在Driver端定義賦初始值,累加器只能在Driver端讀取最后的值,在Excutor端更新,
- 累加器不是一個調優的操作,因為如果不這樣做,結果是錯的,
廣播變數
Spark1.x:HttpBroadcast、TorrentBroadcast
Spark2.x:TorrentBroadcast、TorrentBroadcast:點到點的傳輸,有效避免單點故障,提高網路利用率,減少節點壓力,
Broadcast:
- 一個全域共享變數,可以廣播只讀變數,
- 一般用于處理共享組態檔,通用的資料子,常用的資料結構等等;不適合存放太大的資料
- 不會記憶體溢位,因為其資料的保存的 Storage Level 是 MEMORY_AND_DISK 的方式
>>> b = sc.broadcast([1,2,3,4,5])
>>> b.value
[1, 2, 3, 4, 5]
>>> sc.parallelize([0, 0]).flatMap(lambda x: b.value).collect()
[1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
>>> b.unpersist()
# 空
注意事項!!!
- 能不能將一個RDD使用廣播變數廣播出去?
不能,因為RDD是不存盤資料的,可以將RDD的結果廣播出去, - 廣播變數只能在Driver端定義,不能再Executor端定義,
- 在Driver端可以修改廣播變數的值,在Executor端無法修改廣播變數的值,
- 如果Executor端用到了Driver的變數,如果不使用廣播變數在Executor有多少task就有多少Driver端的變數副本,
- 如果Executor端用到了Driver的變數,如果使用廣播變數在每個Executor中只有一份Driver端的變數副本,
4.RDD依賴關系
- RDD只能基于在穩定物理存盤中的資料集和其他已有的RDD上執行確定性操作來創建,
- 能從其他RDD通過確定操作創建新的RDD的原因是RDD含有從其他RDD衍生(計算)出本RDD的相關資訊(即血統,Lineage)
- Dependency代表了RDD之間的依賴關系,分為窄依賴和寬依賴
窄依賴
------------------------------------------------------未完待續-----------------------------------------------------------
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280330.html
標籤:其他