0 前言
本人數學(本科)+統計(碩士)專業出身,求職方向為資料分析師,具有近3年跨境電商財務運營分析經驗,以下將結合個人專業理解、以往作業經驗和近期求職情況,就“資料分析師求職“課題作相關經驗/考察點的分享/總結,見識有限僅供參考,
1 簡歷構成
- 個人資訊:姓名+ 電話+ 郵箱+ 求職意向+ 個人網站/github/領英鏈接(加分項,如作業學習筆記、專案建模等);
- 教育背景:就讀時間+ 學校+ 學歷+ 專業+ 主修課程(課程重在體現專業能力);
- 知識技能:統計分析方法和模型+ 機器學習演算法和模型+ excel+ BI+ sql+ python(技能展示熟練程度,如sql應用,python常用包);
- 其他技能:業務指標+ 資料思維+ 分析方法(結合崗位業務理解);
- 作業經驗:復盤與意向崗位相關作業經驗(重點語言表述,以序列形式列出);
- 專案經歷:技術工具+ 分析方法+ 效果/價值產出(根據STAR法則描述:動作+細節+結果,重點能力體現:溝通、協調、學習、分析思維能力以及工具使用情況),
2 指標體系搭建
2.1 指標體系簡介
指標體系將零散單點的具有相互聯系的指標(將業務單元細分后量化的度量值),系統化的組織起來,通過單點看全域,通過全域解決單點的問題,它主要由指標和體系兩部分組成,指標體系的作用:
- 衡量業務發展質量;
- 建立指標因果關系;
- 指導用戶分析作業;
- 指導基礎資料建設;
- 指導內容產品建設;
- 統一指標消費口徑,
2.2 指標體系構建
【1-大致思路】
- 分析業務需求,確定核心指標 ;
- 根據業務分類、AARRR、產品功能,確定二級指標;
- 拆解指標,
【2-思路詳解】
- 【計劃-分析】思考產品型別和業務目標,梳理業務流程,形成一個指標體系框架;
- 【設計】根據指標框架進行指標體系拆分,并與各部門溝通指標其合理性,確定統計維度及粒度(度量單位,如記錄度量,時間頻次),指標包括:a. 基礎指標-多為有具體的業務場景或者可直接獲取的資料,通常為描述性的指標,如人數、單量、UV、PV等,b. 衍生指標-多是從基礎指標轉換而來,可以一定程度上反應出業務的好壞優劣,如完成率、單均價格等;
- 【開發-測驗】整理底層資料存盤邏輯(資料源取數、指標、維度、計算邏輯),驗證指標可行性輸出,準確性校驗,整理問題給出解決方案,遇到問題如:指標沒有埋點無法獲取、有埋點但是資料未傳、資料缺失、錯誤嚴重等;
- 【可視化】指標資料可視化展示,便于業務概覽及例外資料監控,分析報告輸出;
- 【維護】根據業務調整,指標體系持續更新優化,
互聯網產品的資料導向業務作業流 :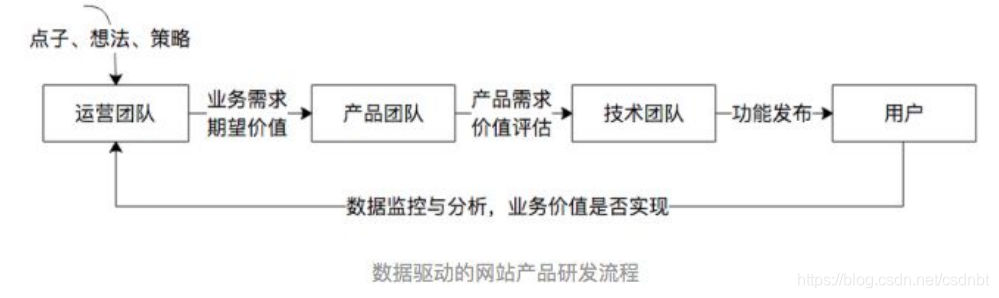
【3-分析方法】
運營是針對不同的用戶群體,通過內容和渠道來做營銷,通過資料指標來優化運營的手段、產品的功能與用戶體驗的一種思維,OSM模型(Obejective業務目標–Strategy業務策略–Measurement業務度量)是指標體系建設中輔助確定核心的重要方法,

如何把業務問題轉化為資料問題 ?
- 指標:確定業務問題的關鍵指標,并進行適度拆分;
- 維度:確定業務問題的維度,圍繞維度構建問題,
2.3 電商指標體系
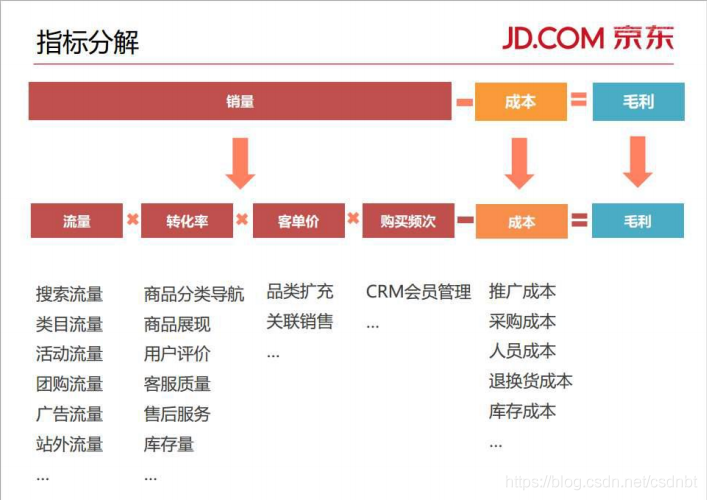
總結各類指標主要可分為以下三大類:
- 金額/價值指標:如銷售額、廣告投入額、獲客成本等;
- 數量指標:如訂單數、用戶數量、加購頻次等;
- 質量指標:如投入產出比率、轉化率、波動率等,
3 原型設計開發
3.1 原型設計簡介
原型設計是確認需求、設計產品最重要的溝通工具,是產品經理具備的基礎技能,原型圖種類(可應用于手機端、桌面端、平板):
- 線框圖(快速、低成本描述方案);
- 高保真原型圖(耗時、高還原度,要素:形狀、尺寸、色彩、貼圖-推薦搜索引擎如iconfont\baidu、互動動作-頁面切換\回應范圍\點擊動效、演示效果-手機演示\原型托管\螢屏適配);
- 需求檔案(PRD/MRD,邏輯與業務說明指導研發),
3.2 原型設計分析
原型設計程序包括分析、整體設計、單界面設計、驗證四個部分,
(功能實作:確認界面布局和內容-》確認互動-》實作)
- 分析:分析用戶需求,確認原型設計的目標是什么,
- 整體設計:有效需求分析-業務場景分析,以“場景-問題/挑戰-方案”的邏輯來分析每個業務場景,從而匯出所需的功能,對原型進行整體設計,主要從兩個維度考慮:資訊結構(功能模塊、模塊之間的關系、哪些模塊是公共的、哪些模塊要定制化顯示不同內容等)、使用流程(結合場景和用戶體驗設計界面之間的跳轉邏輯),
- 單界面設計:對每個界面制作原型,并做好界面之間的鏈接,優先考慮滿足產品需求,然后是讓界面好看好用,
- 驗證:正式的專案中,針對原型設計需要有相應的評審會議,和專案成員、客戶進行確認,收集意見反饋并調整,
3.3 原型設計工具
Axure RP、墨刀、Adobe XD、PtotoPie等,
4 業務分析框架
4.1 分析方法
-
描述性分析(找出問題):描述性統計是借助圖表或者總結性的數值來描述資料的統計手段,常見指標如下:
a. 集中趨勢:眾數、分位數、中位數、平均數
b. 離散趨勢:異眾比率、四分位差、極差、方差、標準差、變異系數/離散系數(CV=標準差/總體均值,是概率分布離散程度的歸一化量度)
c. 偏差程度:z分數(反映一個值距離該組資料平均數的相對標準距離)、切比雪夫定理(任意一個資料集中,位于其平均數m個標準差范圍內的比例(或部分)總是至少為1?1/m2)
d. 相關程度:協方差、相關系數
e. 分布形狀:偏度、峰度, -
診斷性分析(分析問題);
-
預測性分析(趨勢分析);
-
規范性分析(解決問題),
(詳細參考本人博客《資料分析-導論》)
4.2 分析思路
以電商訂單資料為例,資料分析基本思路是:使用可視化報表檢測訂單關鍵指標的變化,并在資料維度上進行維度下鉆,
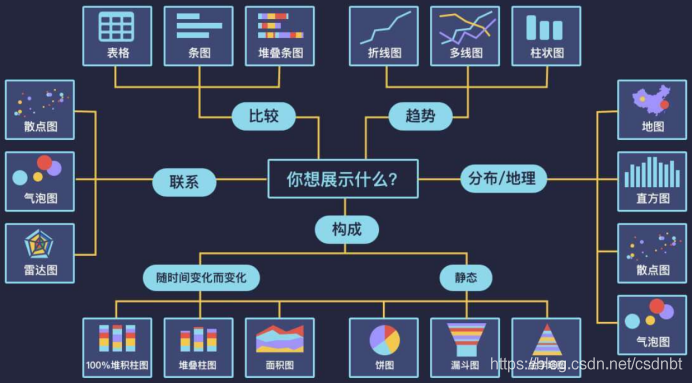
1. 可視化報表:散點圖-相關性、氣泡圖-三維比較、直方圖、條形圖、折線圖、累計分布折線圖(二八定律)等,
2. 關鍵指標變動分析:同比和環比,價值-數量-質量-轉化指標分析,如電商財務運營分析關注點:
① 營收規模,如:GMV、銷售額、訂單量、客單價、訂單有效率;平臺用戶數-拉新留存、用戶轉化率,等;
② 盈利能力,如:退貨退款倉儲等變動或固定成本占比、毛利率、邊利率、凈利率,等;
③ 資產占用(存貨+應收+應付),如:存貨可支撐天數和庫存減值、應識訓賬余額和周轉天數、其他貨幣資金凍結金額和回款預測,等,
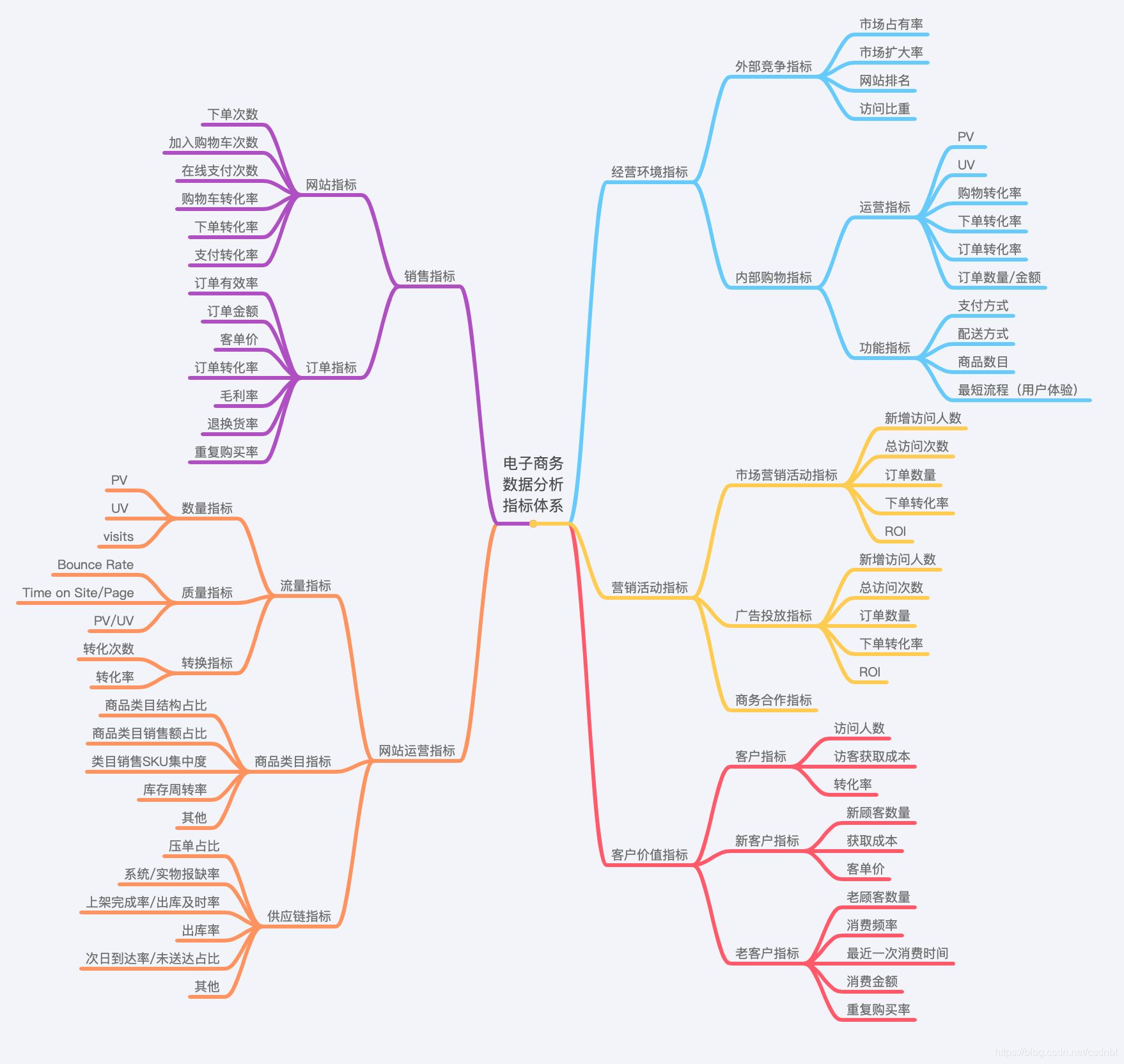
3. 維度下鉆:資料維度需結合資料驅動業務的影響因素出發,主要分為幾方面:用戶、產品、市場(人貨場指標體系見下圖),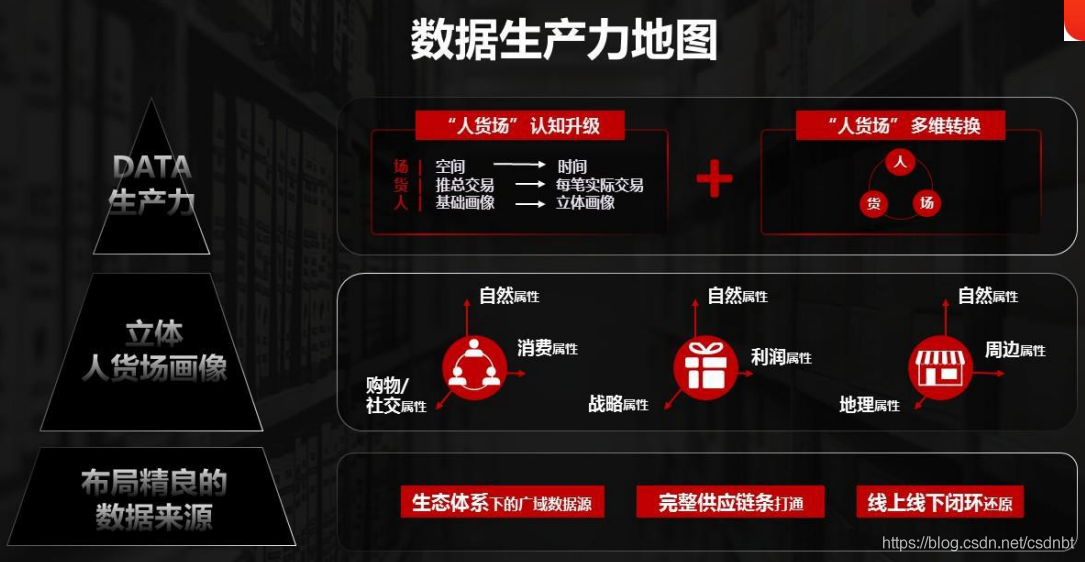
4.3 業務模型
4.3.1 用戶畫像
(1)用戶畫像簡介
1. 簡介:
用戶畫像是在電商行業運用廣泛的一種技術,是根據一系列用戶的真實資料而挖掘出的目標用戶模型,其主旨為將用戶的每個具體資訊抽象成標簽,利用這些標簽將用戶形象具體化,從而為用戶提供有針對性的服務,根據行業和產品的不同,用戶畫像所關注的特征也有不同,但主要還是體現在以下方面:
① 基本特征,如:年齡、性別、職業、家庭型別、地域等特征;
② 行為特征,如:搜索、瀏覽、收藏、加購物車、付款等一系列行為事件的特征;
③ 使用場景,如:用戶購物頻次、購買時間偏好、購買物品等屬性等,用戶的使用場景對運營策略的設計指導意義最大,
2. 實作步驟:
資料抓取-》特征工程-》資料標簽化-》搭建用戶畫像-》分析需求-》精細運營,
3. 電商應用:
① 分析用戶行為資料來獲取用戶的商品偏好、價格偏好等資訊,從而幫助平臺/入駐商更好地去推薦商品/生產商品;
② 分析用戶屬性資料來對用戶進行合理地分類,從而幫助平臺/入駐商更好地了解用戶需求,搭建用戶畫像,
4. 用戶畫像分類:
① 商戶畫像(AARRR模型):著重點是通過用戶的屬性和行為習慣來進行最優化的選品、制定最優化的價格策略和對庫存進行預測 ;
② 平臺畫像(RFM模型):著重點是通過提升用戶體驗、各式精準的營銷活動來吸引消費者到平臺進行瀏覽和轉化;
③ 商品畫像(購物籃分析):是產品的根基,對商品進行精準的定位,可以輔助建立用戶標簽進而優化用戶的體驗,同時可以驅動后端供應鏈的各種行為,如預測、補貨、促銷、庫存、采購、生產、物流等等,
(2)用戶生命周期
- 用戶生命周期:是全部用戶從第一次訪問產品到流失的整個程序中的階段劃分,階段劃分的標準可以參考用戶留存曲線和用戶購買頻次及其他指標進行劃分,一般劃分為:新手期、成長期、成熟期、沉默期、流失期五個階段,在用戶生命周期的基礎上,進一步細分用戶特征,幫助針對性的運營,延長用戶生命周期,促進用戶購買,最終提升GMV,
- 用戶生命周期價值(Customer Lifetime Value,CLV):是用戶整個生命周期內對GMV的貢獻,計算公式為: CLV(單個用戶)=用戶生命周期各階段的變現能力之和 -》 各階段用戶的生命周期價值=生命周期各階段用戶的平均變現能力*用戶數
-》用戶生命周期價值=sum(各階段用戶的生命周期價值),
(3)個性化推薦模型
常見個性化推薦模型:
- 基于關聯規則的推薦(user-item):采用概率統計的方式來判斷某兩種或者多種商品之間的相關性做出推薦,關聯規則演算法不僅可以用于推薦系統,也可以用于對用戶行為的分析;
- 協同過濾推薦:利用最近鄰演算法得到用戶和用戶,物品和物品的相似程度產生推薦結果;
- 邏輯回歸模型(Logistic Regression):用于解決二分類(0 或1)問題的統計學模型,用于估計某種事物的可能性,比如得到用戶行為可能性,再按照這個可能性排序來取top-k進行推薦,步驟:特征變換-訓練模型-模型推斷概率-概率排序獲得推薦串列,
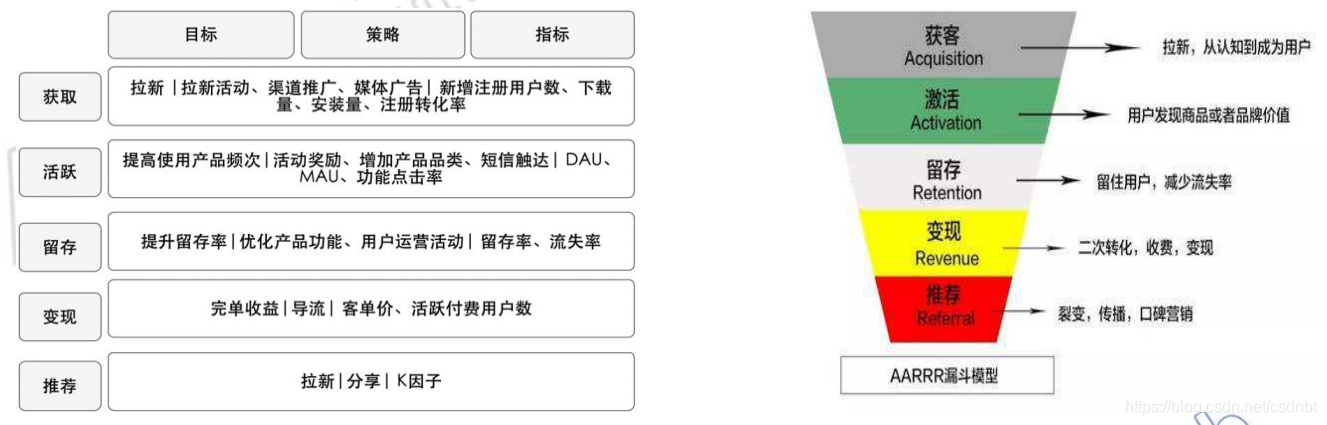
4.3.2 漏斗模型
-
什么是漏斗模型?
漏斗模型是一套流程式資料分析模型,用來反映用戶在流程里的關鍵行為以及從起點到終點各階段轉化和流失情況,若無法判斷轉化率低的確定因素,可結合AB測驗驅動產品迭代, -
為什么要用漏斗模型?
? 可以幫助分析師迅速定位流程中的短板;
? 利于多維度切分,捕捉用戶行為變化,及時發現例外;
? 有助于觀察和比較不同用戶群體之間的差異,持續提升用戶體驗,
【總結】對產品流程的精細化運營+精細化設計, -
常見的漏斗模型-AARRR模型
獲客(Acquisition)、激活(Activation)、留存(Retention)、收益(Revenue)、自傳播(Referral),AARRR & OSM模型:
-
如何搭建和分析漏斗模型?
① 梳理主要路徑和流失節點;
② 選定核心路徑:選擇開口大的路徑、漏斗環節不能太多、漏斗環節量差不能太大;
③ 觀察和比較資料:縱向對比、橫向對比、關注不同層級的資料指標,
【總結】漏斗模型將任意產品流程抽象成一個個的關鍵步驟,然后用轉化率來衡量每一個步驟的表現,最后通過例外的資料指標找出有問題的環節,從而解決問題,優化該步驟,最終達到提升轉化率的目的,
5 資料建模理論
5.1 資料運營框架
【計劃-分析】分析業務需求,建立和維護指標體系(確定核心指標、拆解指標)-》討論制定資料分析框架(分析目標資料化,確定分析思路、方法、資料抽取規則,專案的落地價值和迭代方向);
【設計-開發】資料采集-》資料預處理、可視化分析 -》特征工程(如篩選變數、新增變數、分箱)-》資料建模(資料挖掘建模 - 機器學習預測分群、資料挖掘歸因洞察;資料倉庫建模 - BI資料建設、ETL資料加工);
【測驗】模型評估(如:分類-準確率、精確率、召回率;回歸-RMSE平均均方根誤差、MAE平均絕對誤差)-》資料應用(產品、報表);
【維護】 指導(運營),
5.2 理論模型簡介
- 統計模型: 列聯表與方差分析、相關與回歸分析、聚類與判別分析、降維分析、預測分析;
(統計模型相關討論詳細參考本人博客《統計模型-基于sas》) - 機器學習模型:監督學習-分類、回歸;無監督學習-聚類、關聯分析、降維,
(機器學習模型相關討論詳細參考本人博客《機器學習模型-基于python》)
6 工具技能
6.1 excel
- 基礎— 快捷鍵、函式、透視表
- 進階(加分項)— vba、power bi
6.2 sql
- 基礎— ddl、dml陳述句
- 進階(面試考察)— 子查詢、join、having、over()、存盤程序
(sql相關討論詳細參考本人博客《sql入門-基礎-拓展》)
6.3 tableau
Tableau是一種商業智能軟體,允許任何人連接到相應的資料,然后可視化并創建互動式的可共享儀表板:
圖表(欄位操作、表計算、LOD、過濾器等)、儀表盤、故事
6.4 python
6.4.1 基礎
【內置包】os、re、csv等
【資料分析包】numpy、pandas、matplotlib
(1)numpy
numpy(import numpy as np)
1. 創建陣列(nd-array):
① np.array([])一維陣列(np.array([[]])多維陣列)
② np.arange(start, stop, step,dtype=)回傳ndarray均勻間隔值的陣列
2. 陣列的索引和切片:
① 一維陣列的索引和切片:arr[start:stop:step]
② 多維陣列的索引和切片:arr[r:][c:]或arr[r:,c:]
3. 陣列重組:
① 陣列變形:arr.reshape((r,c),order=’C’)
② 陣列展平:arr.ravel()、arr.flatten(“C”)
③ 陣列拼接:np.hstack((arr1, arr2))、np.concatenate((arr1, arr2), axis=)
④ 陣列分割:np.split(arr,n,axis=)
⑤ 陣列排序:sorted(arr)回傳臨時排序的串列、arr.argsort()排序后的初始下標、arr.sort()不回傳值,只進行排序操作
4. numpy幾個重要的函式:
① np.unique(arr)唯一值;
② np.tile(arr,n)重復n次、np.repeat(arr, [n1, n2,…],axis=)指定元素分別重復ni次;
③ 統計計算:arr.mean()、arr.std()、arr.var()、arr.sum(axis=)、arr.argmax(axis=)、arr.cumsum();
④ 生成亂數(對比import random):np.random.random(a)、np.random.randn(a, b)、np.random.randint(a, b, size=(c, d))、np.random.choice([“a”, “b”, “c”], n, replace=False);
⑤ 檔案讀取 :np.genfromtxt(‘檔案名’, delimiter=’’,dtype=, encoding=) 回傳多維陣列,支持讀取本地檔案和網路檔案,
(2)pandas
pandas ( import pandas as pd )
1. 第一種資料型別(Series):
sr = pd.Series([], index=[])
2. 第二種資料型別(DataFrame):
df1 = pd.DataFrame({: , :},index=[])
df2 = pd.DataFrame(df,index=[], columns=[])
3. 檔案處理:
① 讀取檔案: pd.read_csv()、pd.read_excel()、pd.read_sql()、pd.read_clipboard() ;
② 寫入檔案:to_csv()、to_excel()、to_sql()、 to_json()
③ 合并檔案:pd.concat([df1, df2], axis=, sort=, ignore_index=)拼接、pd.merge(df1, df2,on=,how=) 橫向關聯
4. 資料處理:
① 排序和行標簽:df.sort_values()、pd.cut(col,bins=[], labels=[]) ;
② 去重處理:df.drop_duplicates(subset=[] , keep=’last’/‘first’,
inplace=True);
③ 例外值處理:df.drop(labels =, inplace=True);
④ 空值處理(檢查缺失值:df.isnull()、df.notnull()、df.isnull().sum()):df[].fillna()、df.dropna(axis=, how=‘all’ / ‘any’, inplace=True);
⑤ 資料標準化:
a. 離差標準化:(df[“c”] - df[“c”].min()) / (df[“c”].max() - df[“c”].min()
b. 標準差標準化:(df[“c”] - df[“c”].mean()) / df[“c”].std()
⑥ 啞變數處理:pd.get_dummies(df[]);
⑦ 批量操作(呼叫函式):
a. 每個元素進行相同操作:df[].apply(func) #func可用lambda
b. 整列合并計算:df.agg({“c1”: func1, “c2”: func2})
c. 分組統計:df.groupby(by=[col], axis=).sum()
(3)matplotlib
matplotlib(import matplotlib.pyplot as plt)
1. 創建畫布與子圖:
① 創建畫布:plt.figure() ;
② 創建子圖:plt.subplot()、fig.add_subplot()
2. 添加畫布內容:
① 繪制函式: plt.text(x, y, s) 、 plt.annotate(s, xy) 、plt.grid(True) 、 plt.title(‘’)、plt.xlabel(‘’)、plt.xlim()、plt.xticks()、plt.legend()、plt.axis([])
② 設定動態rc引數(圖形屬性):lines.linewidth、lines.linestyle、lines.marker、lines.markersize
3. 繪圖:
① 分析特征間的關系: plt.scatter()散點圖 、 plt.plot()折線圖
② 分析特征內部資料分布與分散狀況: plt.hist()直方圖、 plt.bar()條形統計圖、 plt.pie()餅圖、 plt.boxplot()箱線圖
4. 存盤與展示影像:
① 統一調整子圖間距:fig.subplots_adjust(wspace= ,hspace= )
② 保存圖形:fig.savefig(" ")
③ 顯示圖形:plt.show()
④ 讀取圖形檔案:readshapefile()
6.4.2 進階
【爬蟲包】requests(靜態爬蟲,BeautifulSoup決議網頁)、webdriver(動態瀏覽器爬蟲)、futures(并發多執行緒爬蟲)、scrapy(爬蟲工程化/框架)
【機器學習包】sklearn
(python相關討論詳細參考本人博客《python入門-基礎-應用》)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280335.html
標籤:其他
上一篇:Redis事務控制
下一篇:Hadoop HA高可用架構