Hadoop HA高可用架構
- 架構的問題及解決方案
- Hadoop1與Hadoop2
- 模塊
- 架構
- Hadoop HA高可用機制
- Hadoop Federation聯盟機制
- HA實作可能遇到的問題
- 兩個NameNode的Active與Standby
- DataNode會向哪個NameNode發送心跳和匯報塊
- 客戶端如何知道哪個NameNode是Active
- 如何保證兩個NameNode記憶體元資料的一致性
- HA環境搭建
- 準備作業
- 節點規劃
- 修改組態檔
- 修改core-site.xml
- 修改hdfs-site.xml
- 修改yarn-site.xml
- 分發修改
- 安裝psmisc
- 啟動
- 啟動ZooKeeper
- 啟動journalnode
- 格式化
- 同步元資料
- 關聯ZooKeeper
- 關閉journalnode
- node1啟動HDFS
- node3啟動YARN
- node2啟動ResourceManager
- HA環境測驗
- 查看Web監控
- 測驗HDFS的HA
- 測驗YARN的HA
- 手動切換Active與Standby狀態
先看這幾篇:
Hadoop概述
Hadoop集群
ZooKeeper簡單使用
HDFS概述
HDFS資料安全
架構的問題及解決方案
Hadoop1與Hadoop2
模塊
Hadoop1:HDFS、MapReduce(具有資源統籌功能),
Hadoop2:HDFS、MapReduce、YARN(新增了YARN,替代MapReduce做資源統籌),
架構
Hadoop1:支持單個主節點,存在主節點單點故障問題,
Hadoop2:支持兩種架構,
Hadoop HA高可用機制
啟動兩個主節點,一個為Active狀態,另外一個為Standby(一個作業,一個不作業),如果Active出現故障,Standby會切換為Active狀態,
有時候稱為高可用容錯機制,
Hadoop Federation聯盟機制
啟動兩個NameNode,兩個NameNode都作業,用以提高性能,但是元資料比起硬碟資料小的可憐,如果是元資料過大導致需要使用這種模式,可想而知硬碟所存盤的資料量極度龐大,由于這種方式單純提高了性能,但是容錯率并沒有任何提升,為了確保資料安全,使用聯盟機制就必須搭配HA機制,
有時候稱為負載均衡機制:load_balance,
HA實作可能遇到的問題
兩個NameNode的Active與Standby
由ZooKeeper來實作解決,兩個NameNode都向ZooKeeper注冊一個臨時節點,誰創建成功,誰就是Active,另外一個監聽這個臨時節點,如果這個臨時節點消失,表示Active的NameNode故障,Standby要切換為Active,
有個特殊的行程:ZKFC【Zookeeper Failover Controller】,這貨
監聽NameNode狀態,實作狀態指令的發布,輔助NameNode向ZK中進行注冊,創建臨時節點或者監聽臨時節點,每一個NameNode會有一個ZKFC行程,
DataNode會向哪個NameNode發送心跳和匯報塊
每個DataNode會向所有的NameNode注冊,發送心跳和匯報塊,
客戶端如何知道哪個NameNode是Active
挨個請求,只有Active能接受對應的請求,
如何保證兩個NameNode記憶體元資料的一致性
JournalNode集群:設計類似于ZK,公平節點,屬于Hadoop內部的一個組件,可以存盤大資料檔案,Active的NameNode將edits寫入JournalNode,Standby的NameNode從JournalNode中讀取Edits,這樣就能共享edits檔案,Active的NameNode宕機或者故障,Standby的NameNode就能完整地接替原來Active的NameNode,
HA環境搭建
準備作業
虛擬機node3突然掛了:CentOS的ens33網卡丟失,好在reboot后解決了,,,reboot永遠的神!!!
此時可以虛擬機拍快照(掛起狀態更占硬碟,故速度慢),關機狀態拍快照稍微省點硬碟空間,先切換node1路徑看看:
cd /export/server/hadoop-2.7.5/sbin/
使用ll -ah查看,發現了許多命令:
這一大坨中,cmd是Windows的命令(win+r,然后cmd寫的命令,可以保存為bat腳本),Linux用的是sh結尾的命令,
正確的關機順序應該是:
先關閉dfs服務:
stop-dfs.sh
然后關閉yarn服務:
stop-yarn.sh
筆者的node3宕機重啟,貌似出了故障,,,先重新打開服務試試能不能用,不能用的話只好先恢復為上古時代的快照,,,
按照之前的節點規劃,node1是Namenode,node3是ResourceManager,先在node1啟動NameNode:
hadoop-daemon.sh start namenode
在node3啟動ResourceManager:
yarn-daemon.sh start resourcemanager
然后3臺機都要執行:
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
然后3臺機都是用jps命令查看狀態,node1:
[root@node1 sbin]# jps
9362 DataNode
9237 NameNode
9467 NodeManager
9595 Jps
2748 QuorumPeerMain
再看看node2:
[root@node2 ~]# jps
8705 NodeManager
8833 Jps
2550 QuorumPeerMain
8603 DataNode
最后看下node3:
[root@node3 ~]# jps
2258 DataNode
2360 NodeManager
2488 Jps
1996 ResourceManager
瀏覽器輸入網址:
node1:50070
可以看到:
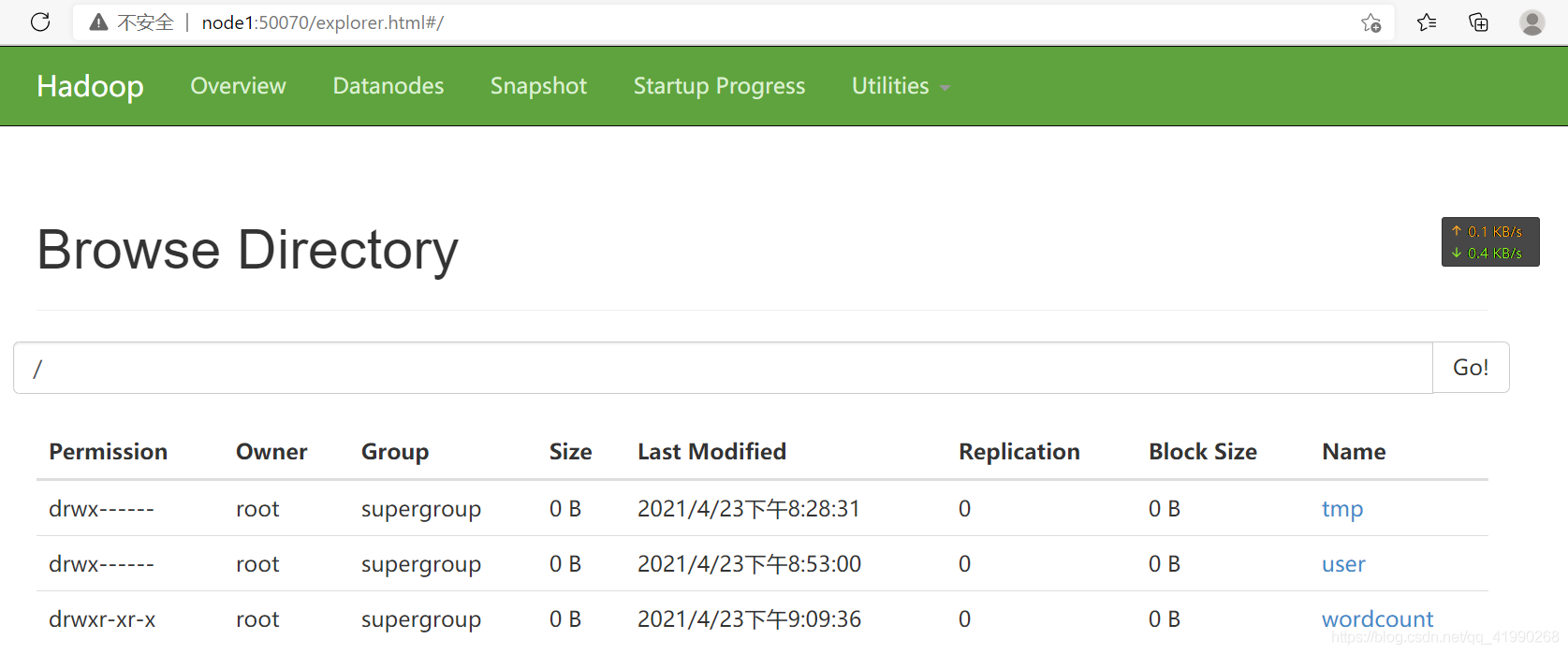
貌似沒啥大問題了,,,每次宕機或重啟的善后都要做很多作業,,,筆者還是喜歡掛起,,,
按照上述正確的關機順序:
cd /export/server/hadoop-2.7.5/sbin/
stop-dfs.sh
stop-yarn.sh
把3臺機都關閉服務,使用jps查看不到相關的行程后,就可以shutdown慢慢關機,或者poweroff斷點,先歇口氣壓壓驚,,,
然后拍快照,關機狀態/未登錄狀態拍的快照省硬碟,
然后正常啟動,登錄,,,
節點規劃
| 行程/機器 | node1 | node2 | node3 |
|---|---|---|---|
| NameNode | Active | Standby | |
| ZKFC | √ | √ | |
| JN | √ | √ | √ |
| DataNode | √ | √ | √ |
| ResourcecManager | Standby | Active | |
| NodeManager | √ | √ | √ |
這種方式,3臺節點宕機都不會使集群失去對外的功能,健碩性很強,資源足夠的情況下,可以使用4臺節點,
修改組態檔
洗掉3個node的臨時目錄并且重新創建(使用secure CRT,3臺同時執行):
cd /export/server/hadoop-2.7.5/
rm -rf hadoopDatas/
mkdir datas
mkdir journalnode
由于HA環境需要ZooKeeper協作,先使用之前寫的腳本看看狀態:
status-zk-all.sh
果然:
[root@node1 hadoop-2.7.5]# status-zk-all.sh
node1
JMX enabled by default
Using config: /export/server/zookeeper-3.4.6/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
node2
JMX enabled by default
Using config: /export/server/zookeeper-3.4.6/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
node3
JMX enabled by default
Using config: /export/server/zookeeper-3.4.6/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
還省的用自定義腳本stop-zk-all.sh關閉ZooKeeper了,,,
老套路,使用Notepad++修改,不清楚的可以參照前幾篇,
修改core-site.xml
先修改node1的組態檔:
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/server/hadoop-2.7.5/datas</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
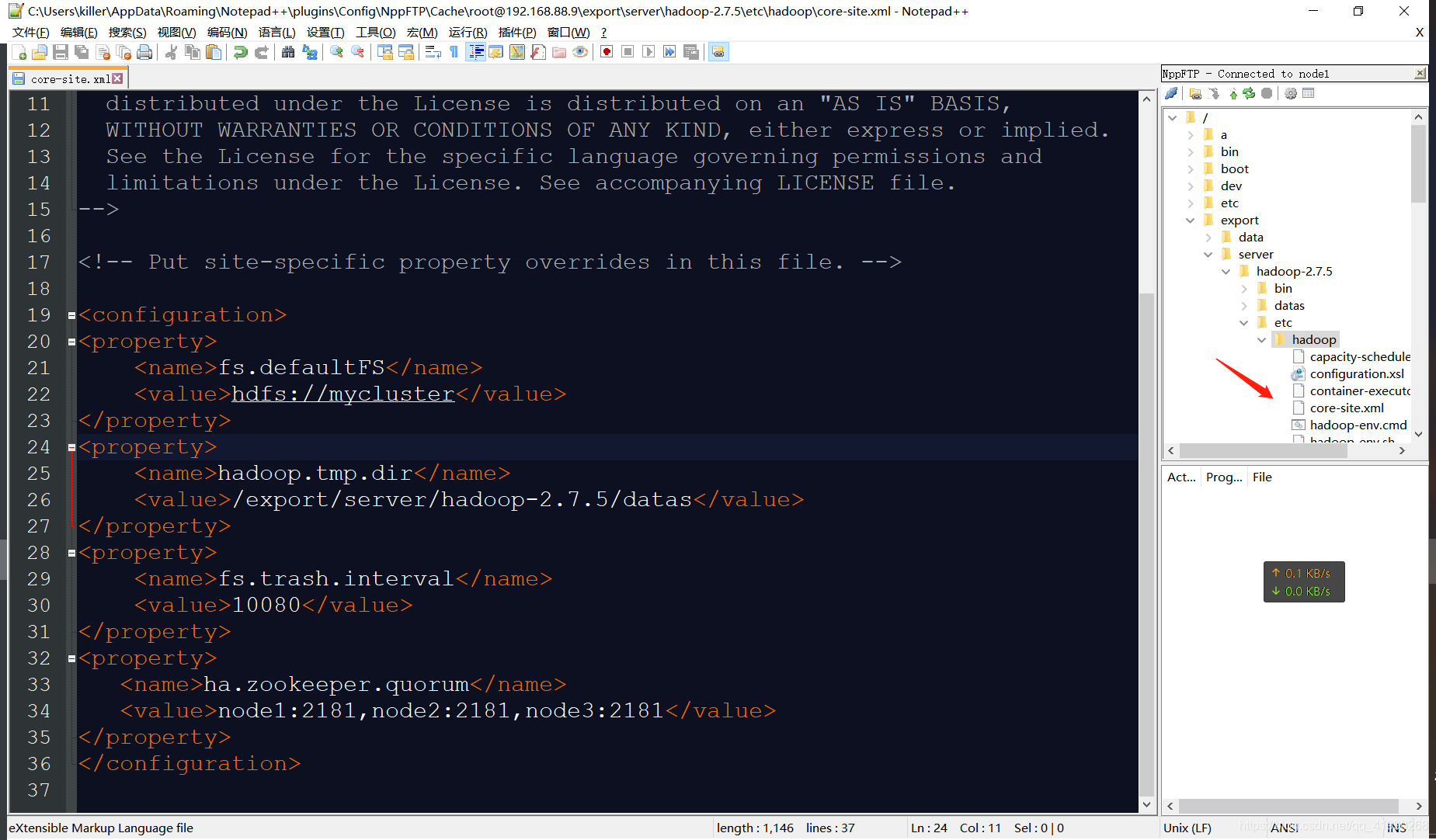
fs.defaultFS:指定HDFS地址,
ha.zookeeper.quorum:指定zk的地址,
修改hdfs-site.xml
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export/server/hadoop-2.7.5/journalnode</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
dfs.nameservices:將兩個NN從邏輯上合并為一個整體的名稱,一定要對應core-site中fs.defaultFS的配置,
dfs.ha.namenodes.mycluster:指定邏輯名稱中有幾個NN,每個NN的名稱是什么,
dfs.namenode.rpc-address.mycluster.nn1/nn2:配置兩個NameNode具體的RPC和HTTP協議地址,
dfs.namenode.shared.edits.dir:JournalNode的地址,
dfs.journalnode.edits.dir:edits檔案的存盤位置,
dfs.client.failover.proxy.provider.mycluster:客戶端請求服務端的方式,
dfs.ha.fencing.methods:隔離機制,解決腦裂問題的,
dfs.ha.automatic-failover.enabled:自動切換,
修改yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node3:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
分發修改
使用node1分發給node2和node3:
cd /export/server/hadoop-2.7.5/etc/hadoop/
scp core-site.xml hdfs-site.xml yarn-site.xml node2:$PWD
scp core-site.xml hdfs-site.xml yarn-site.xml node3:$PWD
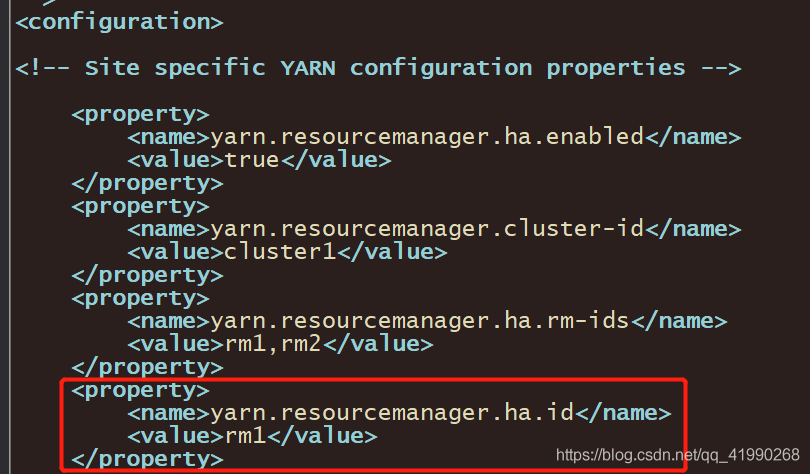
由于node1不是ResourcecManager,這段內容就是多余的:
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
在vim中干掉:
cd /export/server/hadoop-2.7.5/etc/hadoop/
vim yarn-site.xml
而node2需要作為備份的ResourcecManager,需要修改為rm2:
cd /export/server/hadoop-2.7.5/etc/hadoop/
vim yarn-site.xml
安裝psmisc
3臺機同時:
yum install psmisc -y
這是個行程管理工具,
啟動
啟動ZooKeeper
使用自定義腳本:
start-zk-all.sh
啟動journalnode
3臺機都需要:
cd /export/server/hadoop-2.7.5/
sbin/hadoop-daemon.sh start journalnode
使用jps查看,確認3臺機器都已經啟動:
格式化
首次啟動需要格式化,后續啟動不再需要,node1:
bin/hdfs namenode -format
老規矩:
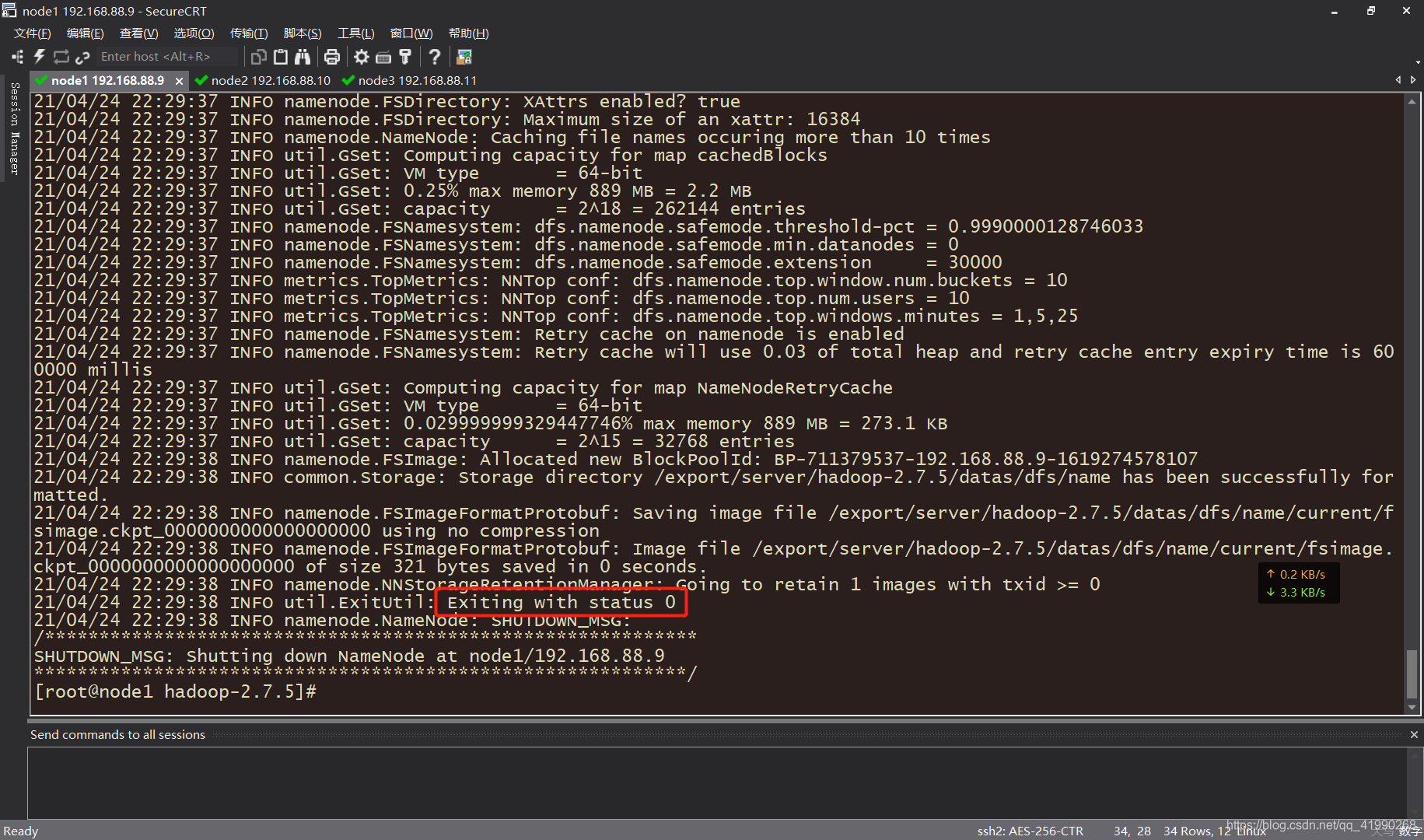
這樣代表成功,
同步元資料
node1同步資料到node2(NameNode):
scp -r datas node2:$PWD
關聯ZooKeeper
第一臺機器關聯zookeeper,進行初始化:
bin/hdfs zkfc -formatZK
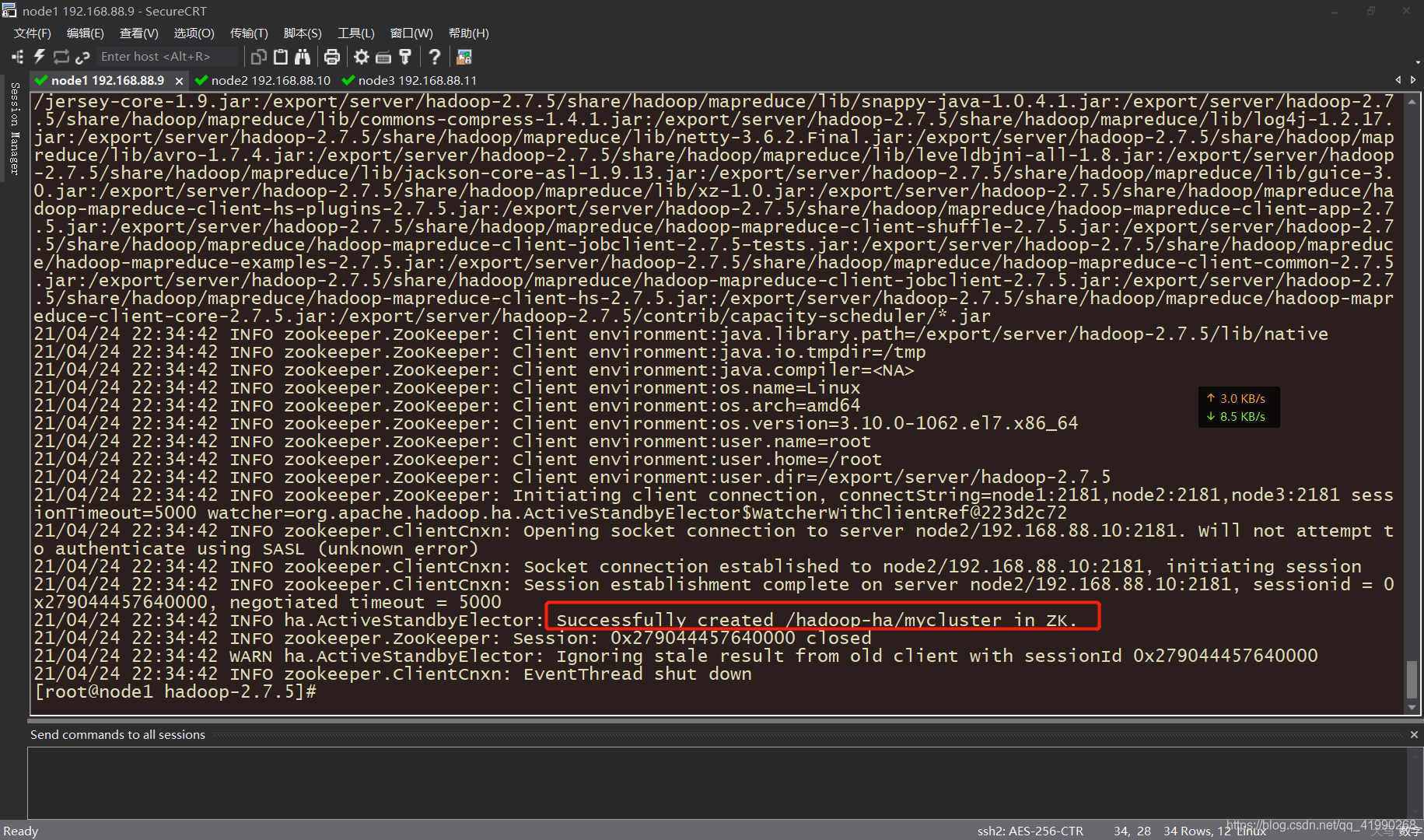
成功創建,
關閉journalnode
3臺機都需要:
sbin/hadoop-daemon.sh stop journalnode
node1啟動HDFS
start-dfs.sh
結束后:
[root@node1 hadoop-2.7.5]# start-dfs.sh
Starting namenodes on [node1 node2]
node2: starting namenode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-namenode-node2.out
node1: starting namenode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-namenode-node1.out
node1: starting datanode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-datanode-node1.out
node2: starting datanode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-datanode-node2.out
node3: starting datanode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-datanode-node3.out
Starting journal nodes [node1 node2 node3]
node3: starting journalnode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-journalnode-node3.out
node1: starting journalnode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-journalnode-node1.out
node2: starting journalnode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-journalnode-node2.out
Starting ZK Failover Controllers on NN hosts [node1 node2]
node2: starting zkfc, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-zkfc-node2.out
node1: starting zkfc, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-zkfc-node1.out
這條命令很強大,把所有HDFS行程都啟動了!!!namenode、datanode、journalnode、zkfc都能一鍵啟動,
node3啟動YARN
start-yarn.sh
結束后:
[root@node3 hadoop-2.7.5]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-resourcemanager-node3.out
node1: starting nodemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-nodemanager-node1.out
node2: starting nodemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-nodemanager-node2.out
node3: starting nodemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-nodemanager-node3.out
node2啟動ResourceManager
yarn-daemon.sh start resourcemanager
結束后:
[root@node2 hadoop-2.7.5]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-resourcemanager-node2.out
使用jps查看行程:
[root@node1 hadoop-2.7.5]# jps
2800 NodeManager
2321 DataNode
1890 QuorumPeerMain
2516 JournalNode
2215 NameNode
2696 DFSZKFailoverController
2910 Jps
[root@node2 hadoop-2.7.5]# jps
2228 JournalNode
2390 NodeManager
2311 DFSZKFailoverController
1897 QuorumPeerMain
2137 DataNode
2522 ResourceManager
2575 Jps
[root@node3 hadoop-2.7.5]# jps
2466 ResourceManager
2100 QuorumPeerMain
2362 JournalNode
2571 NodeManager
2878 Jps
2271 DataNode
配置終于結束,,,(node2的NameNode不知為何被干掉了,先留個坑)
HA環境測驗
查看Web監控
瀏覽器:
node1:50070
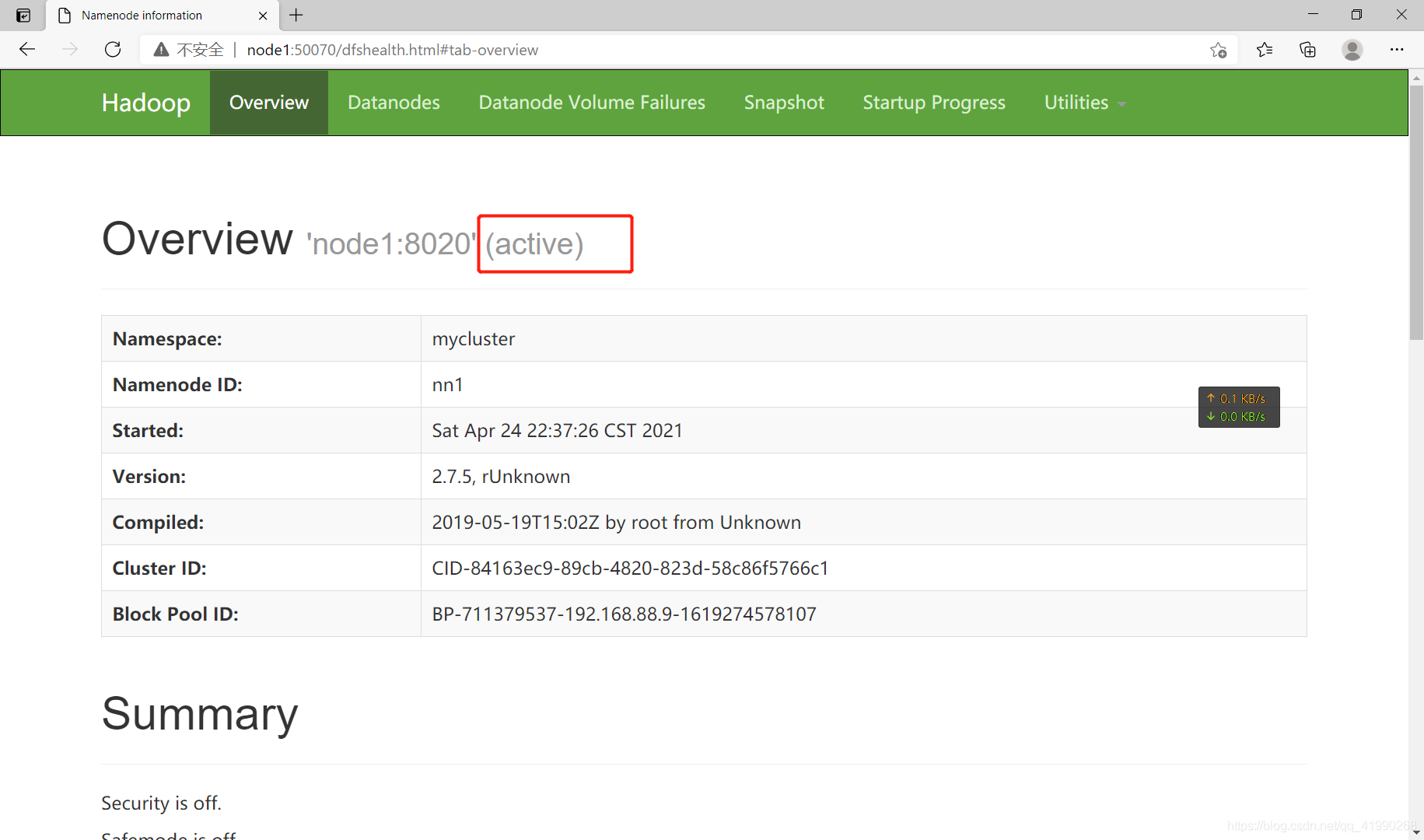
node1為active,
?What?NameNode2沒有啟動???
node2手動啟動下試試:
sbin/hadoop-daemon.sh start namenode
然后jps看下行程:
[root@node2 hadoop-2.7.5]# jps
2770 Jps
2228 JournalNode
2390 NodeManager
2311 DFSZKFailoverController
1897 QuorumPeerMain
2137 DataNode
2522 ResourceManager
2687 NameNode
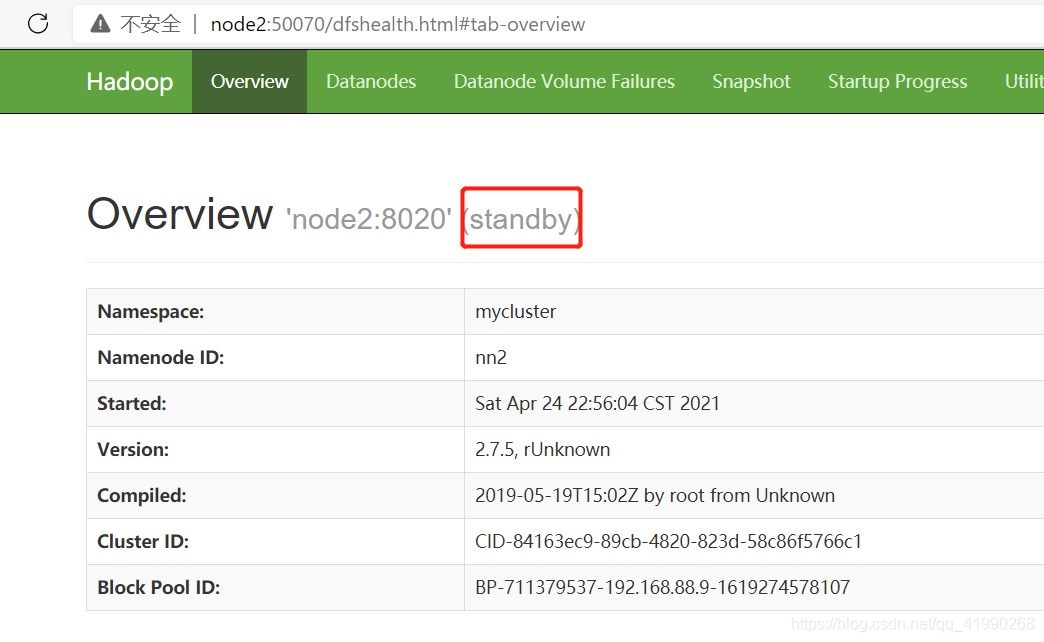
再次嘗試node2:50070,可以看出node2是standby狀態,
瀏覽器:
node3:8088
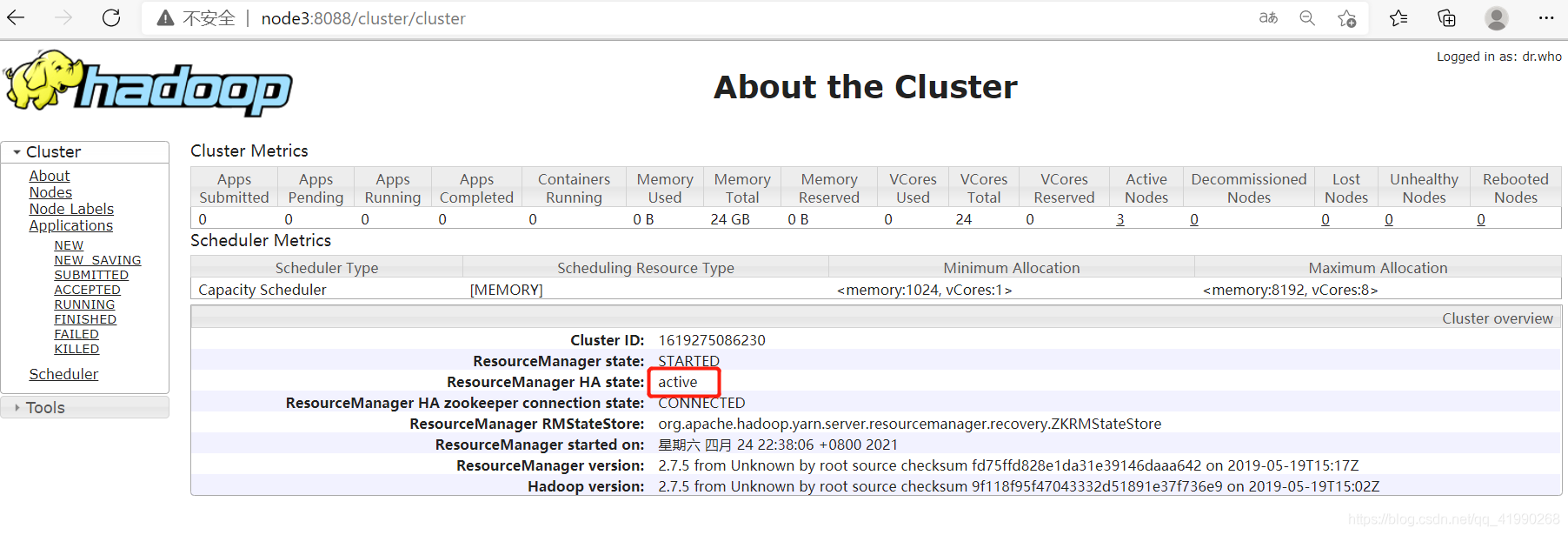
node3為active,
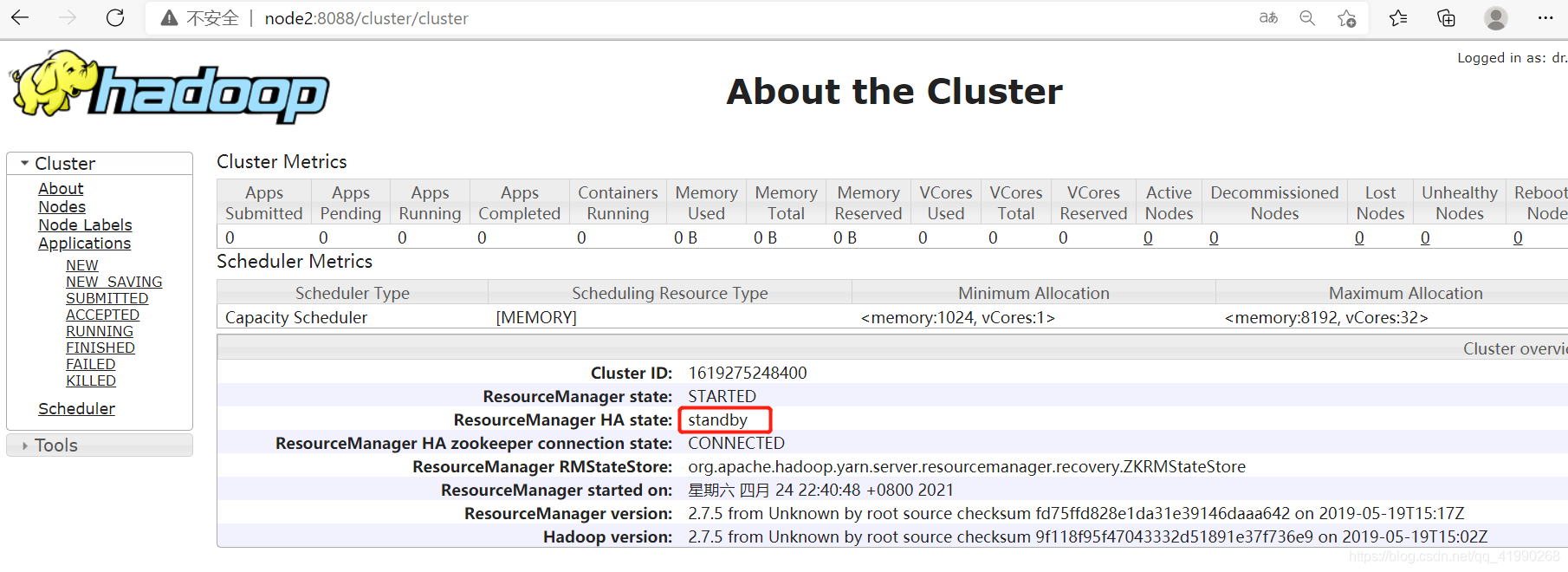
node2為standby,
測驗HDFS的HA
node1關閉NameNode:
sbin/hadoop-daemon.sh stop namenode
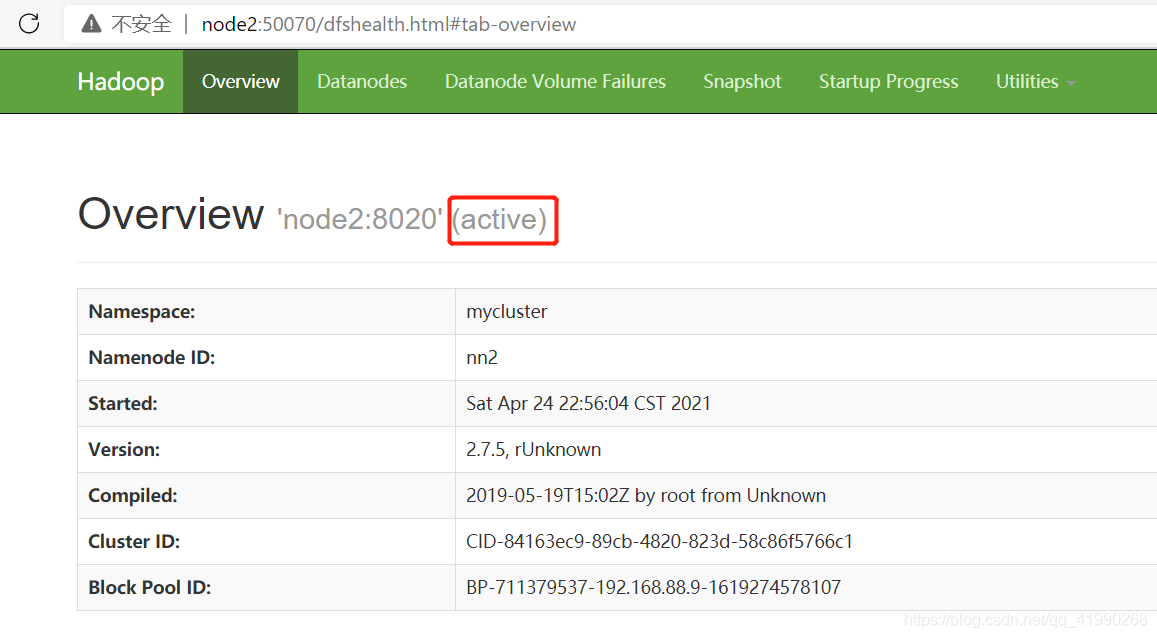
可以看出node2自動變成了active,
node1啟動NameNode:
sbin/hadoop-daemon.sh start namenode
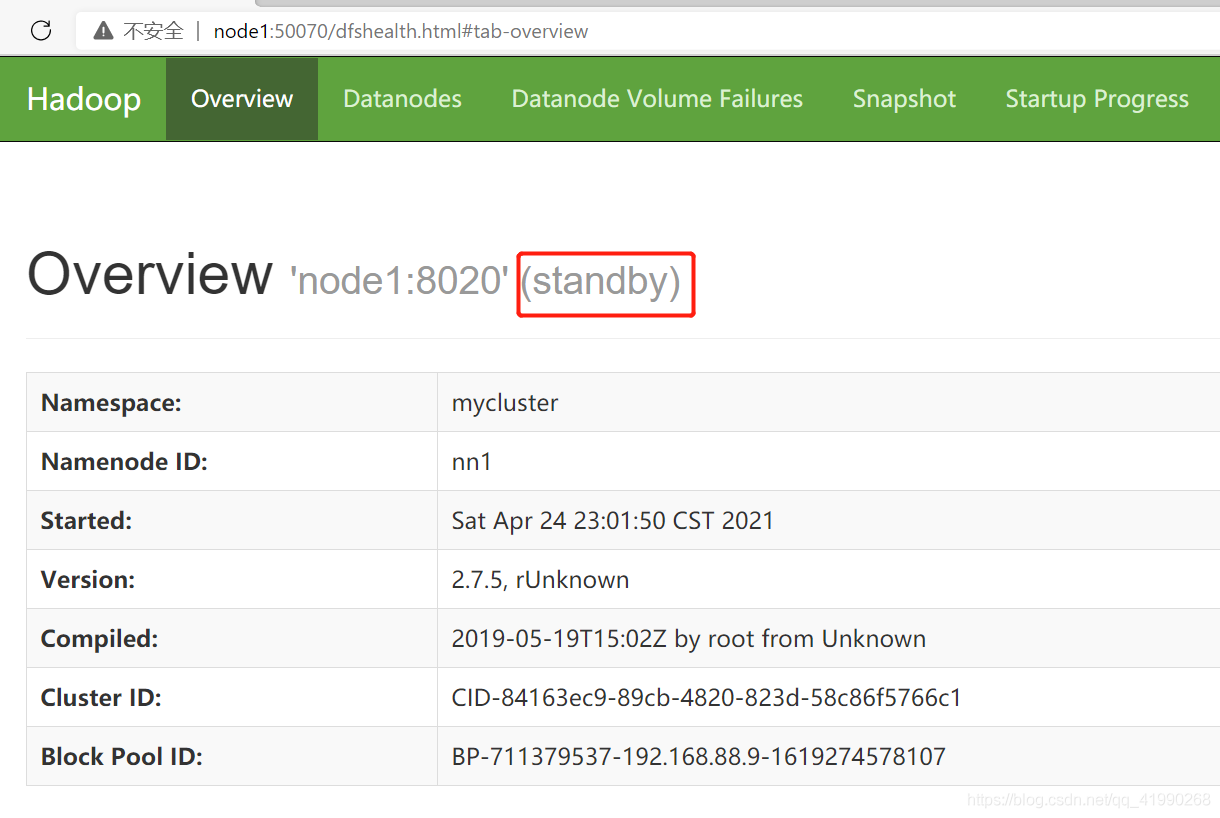
看到node1例外自覺地變成standby狀態,并沒有爭搶active,
測驗YARN的HA
關閉node3的ResourceManager:
yarn-daemon.sh stop resourcemanager
在node2:8088看到:
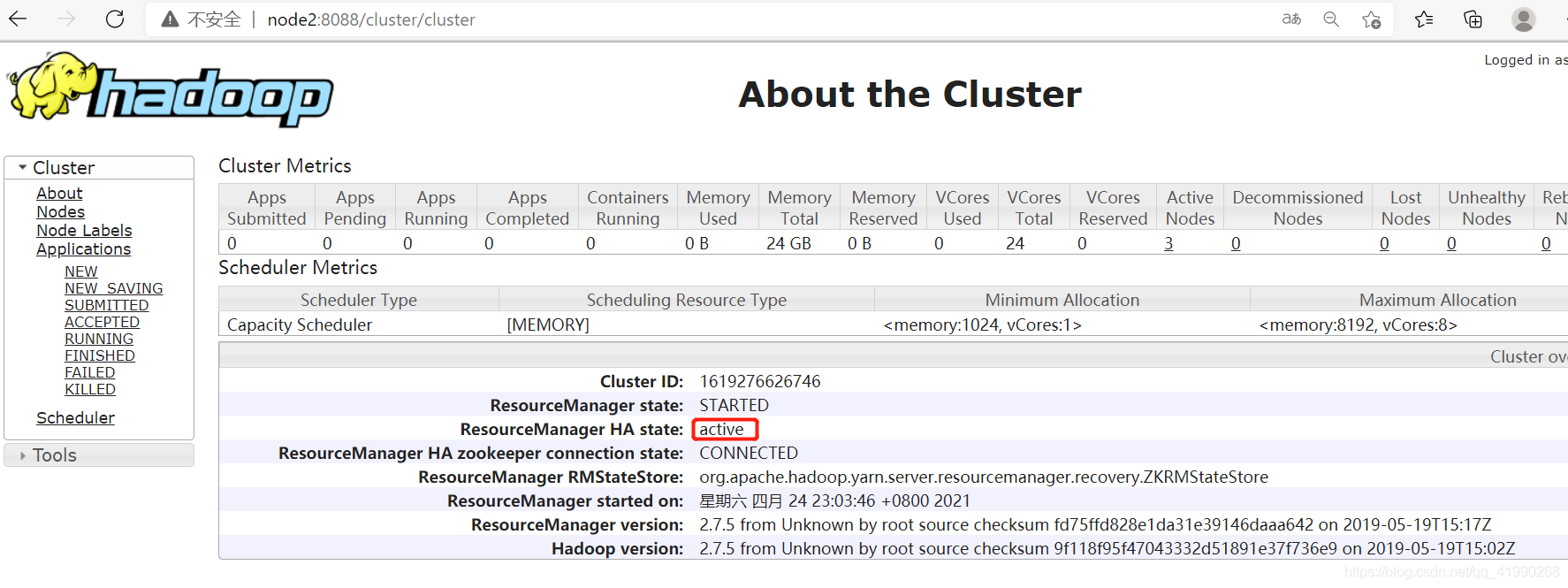
node2變成了active,
node3啟動服務:
yarn-daemon.sh start resourcemanager
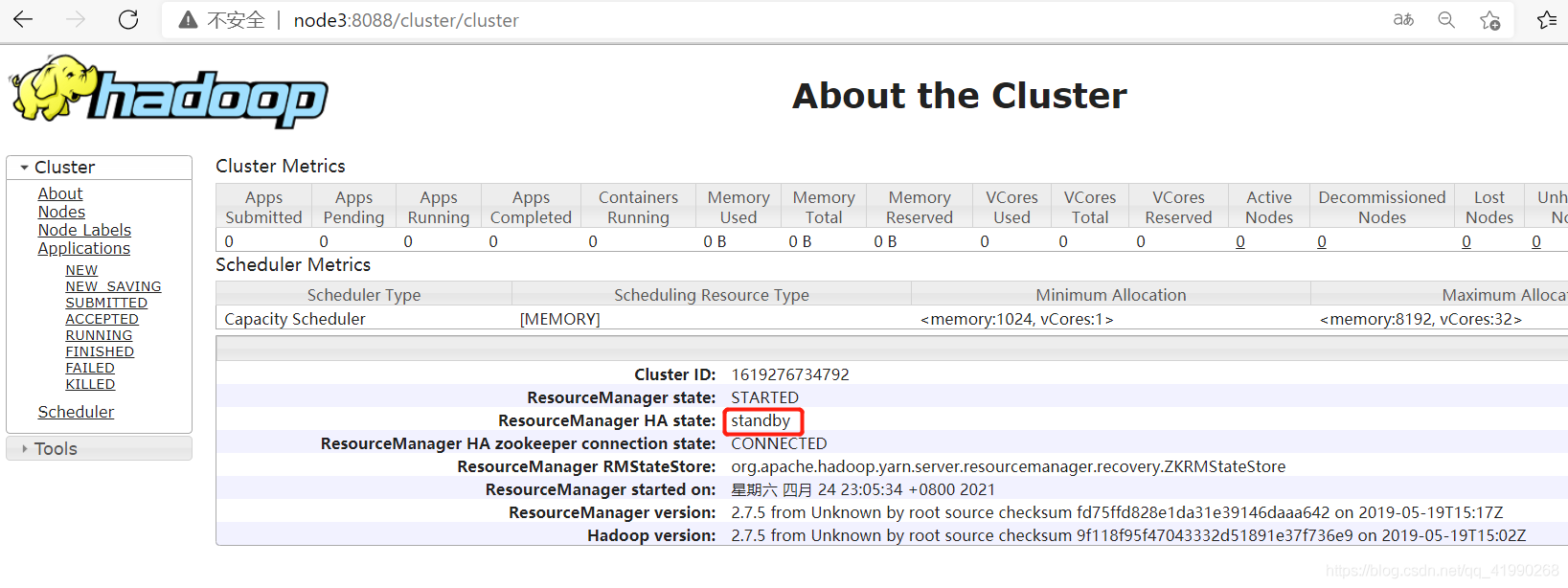
看到node3例外自覺地變成standby并且沒有爭搶active,
手動切換Active與Standby狀態
來一發素質三聯:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
hdfs haadmin -failover nn2 nn1
可以看到執行前的狀態,再來一發素質二聯:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
發現狀態成功切換:
[root@node1 hadoop-2.7.5]# hdfs haadmin -getServiceState nn1
standby
[root@node1 hadoop-2.7.5]# hdfs haadmin -getServiceState nn2
active
[root@node1 hadoop-2.7.5]# hdfs haadmin -failover nn2 nn1
Failover to NameNode at node1/192.168.88.9:8020 successful
[root@node1 hadoop-2.7.5]# hdfs haadmin -getServiceState nn1
active
[root@node1 hadoop-2.7.5]# hdfs haadmin -getServiceState nn2
standby
這條命令就是用來手動切換節點的Active與Standby狀態的,
hdfs haadmin -failover 想要active的節點 想要standby的節點
保存快照以備不時之需!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280336.html
標籤:其他
上一篇:資料分析師-求職篇