文章目錄
- 一 、原理決議
- 1.1全景拼接
- 1.2 RANSAC演算法
- 1.3 影像配準
- 1.4圖割方法
- 1.5 影像融合
- 1.6 APAP演算法
- 1.7multi-band bleing演算法
- 二、代碼
- 三、結果展示與分析
- 3.1第一組(光線好-不同角度相同景深,效果偏優)
- 3.2第二組(光線好-不同角度不同景深,效果中)
- 3.3第三組(光線差-相同角度相同景深,效果最佳)
- 3.4 第四組(光線好-多角度不同景深,效果糟糕)
- 四 、遇到的問題和解決方法
- 五、一些概念補充
一 、原理決議
全景影像:
同一位置(即影像的照相機位置相同)拍攝的兩幅或者多幅影像是單應性相關的,
我們經常使用該約束將很多影像縫補起來,拼成一個大的影像
1.1全景拼接
將SIFT應用到影像拼接上,根據特征點匹配的方式,則利用這些匹配的點來估算單應矩陣使用RANSAC演算法,也就是把其中一張通過個關聯性和另一張匹配的方法,通過單應矩陣H,可以將原影像中任意像素點坐標轉換為新坐標點,轉換后的影像即為適合拼接的結果影像,
可以簡單分為以下幾步:
1.根據給定影像/集,實作特征匹配,
2.通過匹配特征計算影像之間的變換結構,
3.利用影像變換結構,實作影像映射,
4.針對疊加后的影像,采用APAP之類的演算法,對齊特征點,(影像配準)
5.通過圖割方法,自動選取拼接縫,
6.根據multi-band blending策略實作融合,
1.2 RANSAC演算法
RANSAC[1] (隨機抽樣一致)是一種迭代演算法,該演算法從一組包含“外點(outlier)”的觀測資料中估計數學模型的引數,“外點”指觀測資料中的無效資料,通常為噪聲或錯誤資料,比如影像匹配中的誤匹配點和曲線擬合中的離群點,與“外點”相對應的是“內點(inlier)”,即用來估計模型引數的有效資料,因此,RANSAC也是一種“外點”檢測演算法,此外,RANSAC演算法是一種非確定演算法,它只能在一定概率下產生可信的結果,當迭代次數增加時,準確的概率也會增加,
RANSAC演算法是用來找到正確模型來擬合帶有噪聲資料的迭代方法,
基本思想:資料中包含正確的點和噪聲點,合理的模型應該能夠在描述正確資料點的同時擯棄噪聲點,
RANSAC的基本思想和演算法流程如下:
隨機采樣K個點,K是求解模型引數的最少點個數;
使用K個點估計模型引數;
計算剩余點到估計模型的距離,距離小于閾值則為內點,統計內點的數目;
重復步驟1~3,重復次數M且保留數目最多的內點;
使用所有的內點重新估計模型,
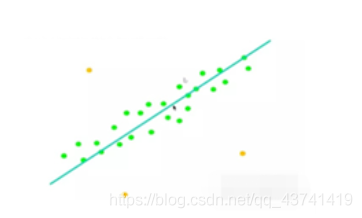
舉例:RANSAC擬合直線
1.隨機選取K=2個點

2.擬合直線

3.統計內點個數

4.重復步驟1-3,重復次數M且保留數目最多的內點
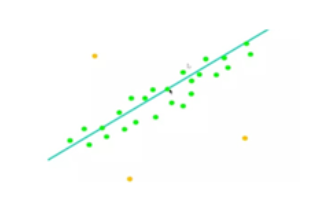
5.使用所有的內點重新擬合直線
1.3 影像配準
影像配準是對影像進行變換,使變換后的影像能夠在常見的坐標系中對齊,為了能夠進行影像對比和更精細的影像分析,影像配準是一步非常重要的操作,影像配準的方法有很多,這里以APAP演算法為例:
1.提取兩張圖片的sift特征點
2.對兩張圖片的特征點進行匹配
3.匹配后,仍有很多錯誤點,此時用RANSAC進行特征點對的篩選,篩選后的特征點基本能夠一一對應,
4.使用DLT演算法,將剩下的特征點對進行透視變換矩陣的估計,
5.因為得到的透視變換矩陣是基于全域特征點對進行的,即一個剛性的單應性矩陣完成配準,為提高配準的精度,Apap將影像切割成無數多個小方塊,對每個小方塊的變換矩陣逐一估計,
1.4圖割方法
最大流最小割演算法原理,
1.最小割問題
一個有向圖,并有一個源頂點(source vertex)和目標頂點(target vertex).邊的權值為正,又稱之為容量(capacity),如下圖
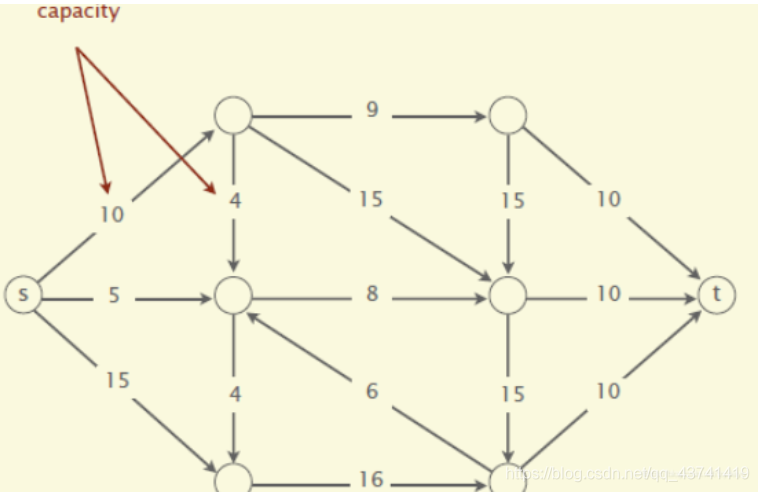
一個st-cut(簡稱割cut)會把有向圖的頂點分成兩個不相交的集合,其中s在一個集合中,t在另外一個集合中,
這個割的容量(capacity of the cut)就是A到B所有邊的容量和,注意這里不包含B到A的,最小割問題就是要找到割容量最小的情況,
2.最大流問題
跟mincut問題類似,maxflow要處理的情況也是一個有向圖,并有一個原頂點(source vertex)和目標(target vertex),邊的權值為正,又稱之為容量(capacity),
(1)初始化,所有邊的flow都初始化為0,
(2)沿著增廣路徑增加flow,增廣路徑是一條從s到t的無向路徑,但也有些條件,可以經過沒有滿容量的前向路徑(s到t)或者是不為空的反向路徑(t->s),
1.5 影像融合
影像拼接之后可以發現,在拼接的交界處有明顯的銜接痕跡,存在邊緣效應,因為光照色澤的原因使得圖片交界處的過渡很糟糕,所以需要特定的處理解決這種不自然,那么這時候可以采用blending方法,multi-band blending是目前影像融和方面比較好的方法,
原理:
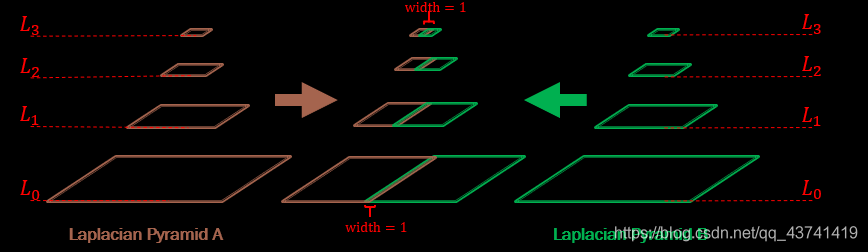
1.建立兩幅影像的拉普拉斯金字塔
2.求高斯金字塔(掩模金字塔-為了拼接左右兩幅影像)因為其具有尺度不變性
3. 進行拼接blendLapPyrs() ; 在每一層上將左右laplacian影像直接拼起來得結果金字塔resultLapPyr
4.重建影像: 從最高層結果圖
將左右laplacian影像拼成的resultLapPyr金字塔中每一層,從上到下插值放大并和下一層相加,即得blend影像結果(reconstructImgFromLapPyramid)
且我們可以將拉普拉斯金字塔理解為高斯金字塔的逆形式,
1.6 APAP演算法
在影像拼接融合的程序中,受客觀因素的影響,拼接融合后的影像可能會存在“鬼影現象”以及影像間過度不連續等問題,下圖就是影像拼接的一種“鬼影現象”,
解決鬼影現象可以采用APAP演算法,

演算法流程:
1.SIFT得到兩幅影像的匹配點對
2.通過RANSAC剔除外點,得到N對內點
3.利用DLT和SVD計算全域單應性
4.將源圖劃分網格,取網格中心點,計算每個中心點和源圖上內點之間的歐式距離和權重
5.將權重放到DLT演算法的A矩陣中,構建成新的W*A矩陣,重新SVD分解,自然就得到了當前網格的區域單應性矩陣
6.遍歷每個網格,利用區域單應性矩陣映射到全景畫布上,就得到了APAP變換后的源圖
7.最后就是進行拼接線的加權融合


Apap雖然能夠較好地完成配準,但非常依賴于特征點對,若影像高頻資訊較少,特征點對過少,配準將完全失效,并且對大尺度的影像進行配準,其效果也不是很好,一切都決定于特征點對的數量,
1.7multi-band bleing演算法
在找完拼接縫后,由于影像噪聲、光照、曝光度、模型匹配誤差等因素,直接進行影像合成會在影像重疊區域的拼接處出現比較明顯的邊痕跡,

這些邊痕跡需要使用影像融合演算法來消除,這里介紹一種方法—multi-band bleing
思想:
采用的方法是直接對帶拼接的兩個圖片進行拉普拉斯金字塔分解,后一半對前一半進行融合
步驟:
首先計算當前待拼接影像和已合成影像的重疊部分,并對影像A、B 重疊部分進行高斯金字塔和拉普拉斯金字塔分解
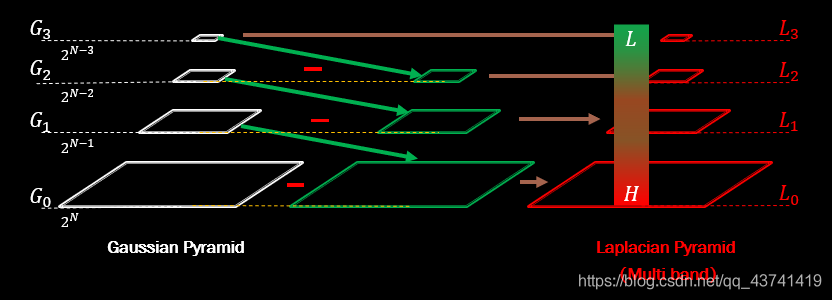
G0為原始影像,G1表示對G0做reduce操作,Reduce操作定義如下:
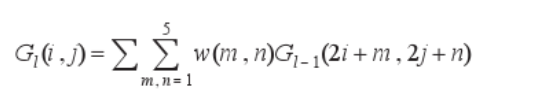
對G1進行擴展后與G0相減,可以得到拉普拉斯金字塔的第一層L0,同理,拉普拉斯金字塔的L2、L3等層也可以按照這種方法來計算,
兩幅影像的融合程序:分別構建影像A、B的高斯金字塔和拉普拉斯金字塔,然后進行加權融合,
對加權后的拉普拉斯金字塔進行重構
二、代碼
# -*- codeing =utf-8 -*-
# @Time : 2021/4/20 11:00
# @Author : ArLin
# @File : demo1.py
# @Software: PyCharm
from pylab import *
from numpy import *
from PIL import Image
# If you have PCV installed, these imports should work
from PCV.geometry import homography, warp
from PCV.localdescriptors import sift
np.seterr(invalid='ignore')
"""
This is the panorama example from section 3.3.
"""
# 設定資料檔案夾的路徑
featname = ['D:\python\pytharm\demo\pythonProject\JsVision\拼接圖象實驗\image\\' + str(i + 1) + '.sift' for i in range(5)]
imname = ['D:\python\pytharm\demo\pythonProject\JsVision\拼接圖象實驗\image\\' + str(i + 1) + '.jpg' for i in range(5)]
# 提取特征并匹配使用sift演算法
l = {}
d = {}
for i in range(5):
sift.process_image(imname[i], featname[i])
l[i], d[i] = sift.read_features_from_file(featname[i])
matches = {}
for i in range(4):
matches[i] = sift.match(d[i + 1], d[i])
# 可視化匹配
for i in range(4):
im1 = array(Image.open(imname[i]))
im2 = array(Image.open(imname[i + 1]))
figure()
sift.plot_matches(im2, im1, l[i + 1], l[i], matches[i], show_below=True)
# 將匹配轉換成齊次坐標點的函式
def convert_points(j):
ndx = matches[j].nonzero()[0]
fp = homography.make_homog(l[j + 1][ndx, :2].T)
ndx2 = [int(matches[j][i]) for i in ndx]
tp = homography.make_homog(l[j][ndx2, :2].T)
# switch x and y - TODO this should move elsewhere
fp = vstack([fp[1], fp[0], fp[2]])
tp = vstack([tp[1], tp[0], tp[2]])
return fp, tp
# 估計單應性矩陣
model = homography.RansacModel()
fp, tp = convert_points(1)
H_12 = homography.H_from_ransac(fp, tp, model)[0] # im 1 to 2
fp, tp = convert_points(0)
H_01 = homography.H_from_ransac(fp, tp, model)[0] # im 0 to 1
tp, fp = convert_points(2) # NB: reverse order
H_32 = homography.H_from_ransac(fp, tp, model)[0] # im 3 to 2
tp, fp = convert_points(3) # NB: reverse order
H_43 = homography.H_from_ransac(fp, tp, model)[0] # im 4 to 3
# 扭曲影像
delta = 2000 # for padding and translation用于填充和平移
im1 = array(Image.open(imname[1]), "uint8")
im2 = array(Image.open(imname[2]), "uint8")
im_12 = warp.panorama(H_12, im1, im2, delta, delta)
im1 = array(Image.open(imname[0]), "f")
im_02 = warp.panorama(dot(H_12, H_01), im1, im_12, delta, delta)
im1 = array(Image.open(imname[3]), "f")
im_32 = warp.panorama(H_32, im1, im_02, delta, delta)
im1 = array(Image.open(imname[4]), "f")
im_42 = warp.panorama(dot(H_32, H_43), im1, im_32, delta, 2 * delta)
figure()
imshow(array(im_42, "uint8"))
axis('off')
show()
三、結果展示與分析
3.1第一組(光線好-不同角度相同景深,效果偏優)
原始圖片集:

全景拼接結果:





結果分析:

結果分析:
該圖只有兩處拼接縫,明顯的拼接縫是藍框拼接縫,由于是人工手持手機拍攝,亮度有些許的不同,從天空的色彩我們可以看出明顯的不同,說明演算法對光線變化不做檢測處理,僅對圖中角點進行特征匹配,
其實總體來說這是一組非常不錯的全景拼接結果,
3.2第二組(光線好-不同角度不同景深,效果中)
原始照片集:

全景拼接結果:





結果分析:

第二組圖片相對于第一組來說,
角度足夠大,視覺上也更呈現出了全景拼接的效果,
- 但是就如藍框,我們還是可以看到明顯的拼接縫,這是由于拍攝圖片的曝光程度有所不同而造成的
- 綠框是這一部分的影像被扭曲了,演算法以影像中的尚大樓為中心,在拼接程序中左邊的影像,即綠框里影像進行了仿射變換,導致了雕塑物的影像扭曲現象,
- 橙框可能是拍攝角度造成的不對齊,
總體來說效果也很不錯啦,不得不讓人稱贊一句集大美麗的風景啊
3.3第三組(光線差-相同角度相同景深,效果最佳)
原照片集:

全景拼接結果:





結果分析:

結果分析:
這組圖其實是我從我之前拍的一張夜景圖從不同角度截取的五張圖,
這組圖的景物景深足夠遠,加上是夜景拍攝,亮度不佳,噪聲點的原因,使得我們看到的拼接結果中拼接縫其實不明顯,
我也是瞪大眼睛找了好久才看到的,
因為這組圖的建筑物很對稱,
在之前的圖片放置順序錯誤導致了出現多重建筑重疊拼接,
經過修正后,
沒想到特征點的匹配十分準確,
導致出現的結果也是十分完美
3.4 第四組(光線好-多角度不同景深,效果糟糕)
原始照片集:

全景拼接結果:





結果分析:

這組圖片的全景拼接結果可能會讓人懷疑,啊這,還是那個出現完美結果的演算法嗎,我斬釘截鐵的說,是的,
這可能就是老師要我們找的killresult,前面機組照片結果都還不錯的原因是它們都屬于一組比較二維的圖片,就是基本就是近大遠小的呈現,
- 這組照片紅框部分出現了非常明顯的景物錯位的情況
- 籃框部分是由于不同角度圖片疊加拼接導致出現的

就是這個部分的拼接,我們可以看到這是一個建筑物的立體面,由于左右眼的視差,在人的大腦里資訊的處理,可以達到一種3D的效果,
在這個演算法,很顯然,特征點的匹配覆寫的非常滿,但是無法達到我們想要的一種3D環繞的全景效果
四 、遇到的問題和解決方法
問題1程式中報錯:
ValueError: all the input arrays must have same number of dimensions, but the array at index 0 has 3 dimension(s) and the array at index 1 has 2 dimension(s)
所有輸入陣列的維數必須相同,但索引0處的陣列有3個維數,索引1處的陣列有2個維數
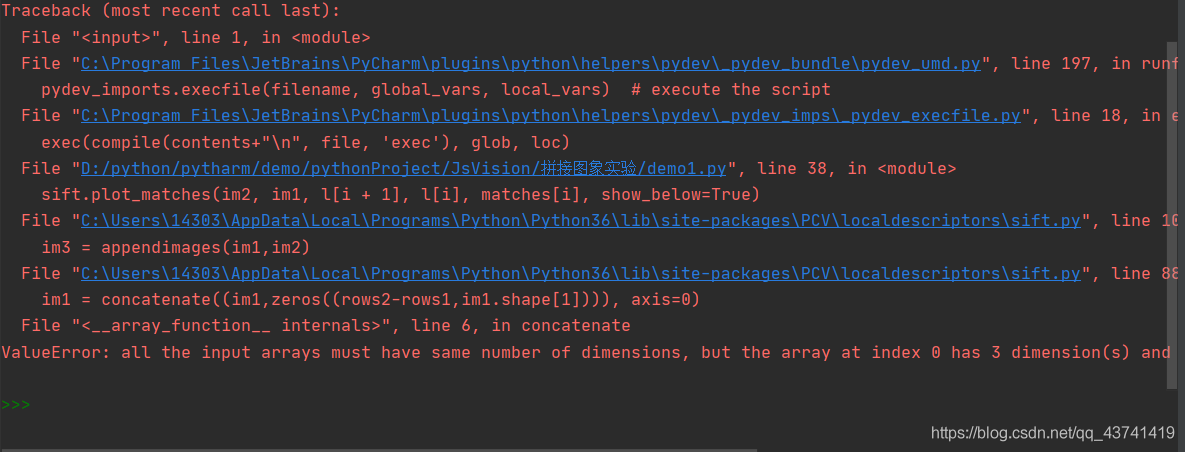
主要是由于放入的照片集的大小不一致導致的輸入陣列的維數不同,
解決方法:
編輯好自己的照片的大小,需要相同的大小(長寬比),可以手動編輯也可以使用美圖秀秀批量處理工具,推薦使用寬2000左右的大小,因為3000的跑的速度太慢(可能也是我電腦太菜),1000的圖片看不大清楚,
問題2:
ValueError: did not meet fit acceptance criteria
不符合擬合驗收標準,導致拼接失敗
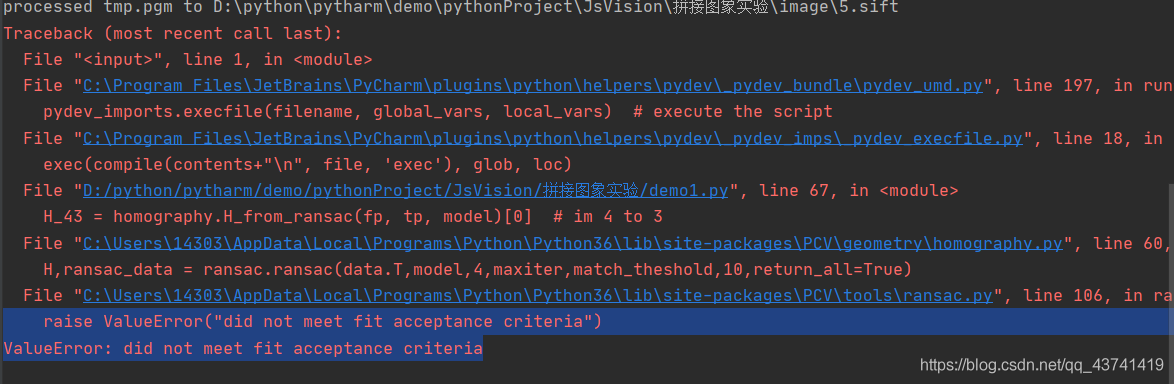

這是同學拍的一組照片遇到的問題然后跟我一起討論的,
從匹配結果來看,演算法檢測到的匹配點并不多,
我跑了他的照片集后發現首先他的照片集是前面有是樹木擋住的,這就導致后面的建筑物因為拍攝角度的不同招致被不同程度的擋住了,我人眼也都很難去判斷整體全景的位置方向(不是很難,是根本判斷不出來)
這說明了演算法雖然能夠較好地完成配準,但非常依賴于特征點對,若影像高頻資訊較少,特征點對過少,配準將完全失效
解決方法:
照片集的挑選對于本次實驗來說十分重要,建議是自己模擬一下手機全景拍攝的步驟,基本就要求你拍攝的圖片在同一個水平線上,而且最好你的特征性建筑突出,這樣你可以得到較好的實驗結果,
問題3:
一開始我的拼接效果非常差,跑了好多組資料,類似于下面這樣的結果



解決方法:
這是由于照片的排列順序是要求從右往左的,但是我一開始是從左往右排序,就會導致這樣的結果,我們的照片集應該按照從右到左編號,因為匹配是從最右邊的照片開始計算,
問題四:
runtimewarning:invalid value encountered in divide
runtimewarning:在divide中遇到無效值
解決方法:
通過網上查閱資料,了解到只要加一句代碼:
np.seterr(invalid=‘ignore’)
就可以忽略報錯,繼續運行得出結果
五、一些概念補充
單應性:
python計算機視覺-影像處理基礎章節第三章之根據仿射或單應性變換實作影像的扭曲,映射,融合
鏈接: python計算機視覺-影像處理基礎章節第三章之根據仿射或單應性變換實作影像的扭曲,映射,融合
sift演算法介紹:
python計算機視覺-影像處理基礎章節之第二章 影像區域描述符
鏈接: python計算機視覺-影像處理基礎章節之第二章 影像區域描述符.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280355.html
標籤:其他
上一篇:introducing to computer systems病史研究:5.1部分
下一篇:計算機原理 二