6.暫存器和記憶體
“隨機存取存盤器”,簡稱“RAM”,只能在有電的情況下存盤東西,比如游戲狀態
另一種存盤叫“持久存盤”,電源關閉時資料也不會丟失
存1位(AND-OR Latch - 鎖存器)
將輸出值回流到輸入值,其輸出結果仍然保持不變,這便使得可以持久存盤,結果就好像是被鎖住一樣,因此形象的稱為“鎖存”
放入資料的動作叫寫入,拿出資料的動作叫讀取
兩條線:一條是資料輸入,另一條是啟用寫入線
只有當寫入線啟用時,寫入的資料才會存盤到計算機里面,讀取資料時才會更新為剛剛寫入的值
存8位 (register - 暫存器)
位寬表示記憶體或顯存一次能傳輸的資料量
隨著存盤位數的增加,需要的線也越來越多,矩陣便是解決這個問題的方法
16x16 的矩陣便可以存 256 位
資料選擇器/多路復用器(Multiplexer)解碼8位地址,定位到單個鎖存器
4位代表行,4位代表列
如1100 1000 就代表12行8列的鎖存器
再比如0000 0001就代表0行1列的鎖存器
(行和列均由0開始)
組合256位記憶體 + 多路復用器
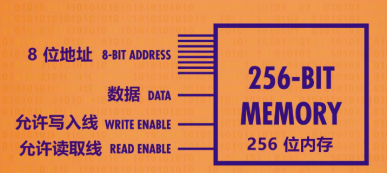
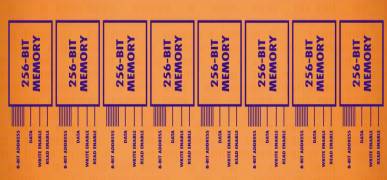
可尋址的256位元組 記憶體
一條1980年代的記憶體,1M大小
8個模塊,每個模塊有32個小方塊,
每個小方塊有4個小塊,每個小塊是128位x64位
7.中央處理器(CPU)
RAM(一大塊記憶體,能在不同地址存大量資料) + 暫存器(很小的一塊記憶體,能存一個值) + ALU(算術邏輯單元)做成了計算機的心臟“中央處理單元”簡稱CPU
CPU負責執行程式
解釋**“取指令–>解碼–>執行”**這個回圈
CPU完成“取指令–>解碼–>執行”每一步的速度叫**“時鐘速度”**
其中單位是赫茲–赫茲是用來表示頻率的單位,1赫茲代表1秒1個周期
舉個例子:6min執行了4條指令(讀取–>讀取–>相加–>存盤)
而每條指令經歷了“取指令–>解碼–>執行”三個時鐘速度
因此就是4(4條指令)*3(每條指令需要花費的時間速度)/3600s(四條指令總花費的時間),所以時鐘速度大概是0.03赫茲
超頻提升性能,降頻省電
8.指令和程式
每個地址可以存8位資料
前四位是“操作碼”,后四位是記憶體地址,或暫存器
指令 操作碼
LOAD_A(暫存器A) 0010
LOAD_B(暫存器B)
例如00101110,其中前四位代表指令LOAD_A,后四位指定記憶體地址的值,放入暫存器A
后四位是1110,十進制過后是14,因此00101110可以看成LOAD_A 14指令,從地址14拿
到數字然后放入暫存器A(LOAD_B同理)
ADD指令
例如“ADD B A”告訴ALU把暫存器B和暫存器A里的數字加起來
特別注意:B和A的順序很重要,因為結果會存在第二個暫存器,也就是這里會存在暫存器A里
STORE_A指令
例如:STORE_A 13就是把暫存器A的值存入記憶體地址13
SUB指令
實作減法操作,與ADD一致,也是兩個暫存器進行操作
JUMP指令
實作跳轉,讓程式跳轉到新的位置
例如JUMP 0可以跳回開頭
JUMP在底層的實作方式是把指令后四位代表的記憶體地址的值覆寫掉“指令地址暫存器”里的值
還有一個特別版的JUMP叫JUMP_NEGATIVE
它只在ALU的“負數標志”為真時,進行JUMP
HALT(停止)指令
能夠區分指令和資料 使計算機停下來
帶條件的跳轉,JUMP NEGATIVE是負數才跳轉,還有其他型別的JUMP
因為這里的CPU是為了便于理解做的假設
其中四位2進制最多只能表示16個指令或者地址,但真正現代CPU需要用更多指令集,
兩種策略
第一種策略是使位數更長,比如32位或者64位,這叫做指令長度
第二種策略是**“可變指令長度”**,長度可以是任意的,但讀取相對復雜
1971年的英特爾 4004處理器,有46個指令
這是第一次把CPU做成了一個芯片,給后來的英特爾處理器帶下了基礎
如今英特爾酷睿i7,有上千條指令還增加了不少指令變種
9.高級CPU設計
早期是加快晶體管切換速度,來提升CPU速度
給CPU專門的除法電路(早期的除法相當是在做一個又一個的減法操作,比如16/4 在早期是16 - 4 - 4 - 4 - 4,直到碰到0或者負數才停下) + 其他電路來做復雜操作,比如游戲,視頻解碼
如果想要的資料已經在快取,叫快取命中
如果想要的資料不在快取,叫快取未命中
臟位–Dirty bit
快取與RAM同步一般發生在 當快取滿了而CPU又要快取時
在清理快取騰出空間時,會先檢查“臟位”
如果是“臟”的,在加載新內容之前,會把資料寫回RAM
另一種提升性能的方法叫**“指令流水線”**
流水線設計,用1個洗衣機和1個干燥機舉例
例如:你要洗一整個酒店的床單,但只有1個洗衣機和1個干燥機
選擇1:按順序來,放洗衣機等30min洗完,然后拿出濕床單,放入干燥機等30min烘干
結果1:一批床單需要1個小時
并行處理–parallelize
同樣的例子
選擇2:洗衣機和干燥機同時進行
結果2:效率x2
同理,CPU也可以這樣處理,之前是“取址–>解碼–執行>”不斷重復
這種設計,三個時鐘周期執行1條指令
但因為每個階段用的是CPU的不同部分,意味著可以并行處理
例如當“執行”一個指令時,同時“解碼”下一個指令,“讀取”下下個指令
結果就是不同的任務重疊進行,同時用上CPU里所有的部分,這樣的流水線 每個時鐘周期就可以執行1個指令,吞吐量x3
但這樣做也會帶來幾個問題:
問題1:指令之間的依賴關系,比如“讀取”A地址的資料,而此時“執行”是修改A地址的資料,那么讀取到的資料就是執行修改后的資料,
因此流水線處理器就要先弄清資料依賴性,必要時停止流水線,避免出問題
而如今高端的CPU會進一步,動態排序 有依賴關系的指令最小化流水線的時間也就是亂序執行–out-of-order execution
問題2:“條件跳轉”,比如之前說的JUMP NEGATIVE
這些指令會改變程式的執行流
簡單的流水線處理器,看到JUMP指令會停一會兒 等待條件值確定下來,一旦JUMP的結果出了,處理器就會繼續流水線
而空等會造成延遲,所以高端處理器就會用一些技巧
例如:將JUMP想成是“岔路口”,高端CPU會猜哪條路的可能性大一些,然后提前把指令放進流水線,這叫**“推測執行”**,當JUMP的結果出了,如果CPU猜對了,流水線已經塞滿正確指令,可以馬上運行;如果CPU猜錯了,就要清空流水線
為了盡可能減少清空流水線的次數,CPU廠商開發了復雜的方法,來猜測哪條分支更有可能,叫**“分支預測”**,現代CPU的正確率超過90%
理想情況下,流水線一個時鐘周期完成1個指令,然后“超標量處理器”出現了,一個時鐘周期完成了多個指令
但即使有流水線設計,在指令執行階段,處理器有些區域還是可能會空閑
比如,執行一個“從記憶體取值”指令期間,ALU會閑置,所以一次性處理多條指令(取指令+解碼)會更好
超級計算機,中國的“神威 太湖之光”
有40960個CPU,每個CPU有256個核心
10.早期的編程方式
給機器編程的需求遠在計算機出現前就有了
例如如果你只想織一塊紅色大桌布,可以直接放紅線進織布機,但如果是圖案,工人則要每隔一會兒,調整一次織布機,因此非常消耗勞動力,導致圖案紡織品很貴
由此約瑟夫·瑪麗·雅卡爾 發明了可編程紡織機,于1801年首次亮相
每一行的圖案由可穿孔紙卡決定,特定位置有沒有穿孔,決定了線是高是低
打孔紙卡–Punched card,便宜、可靠、也易懂
并且在1890年用于美國人口普查
插線板–Plugboard
插線板不同意味著執行不同的程式,比如一個插線板算銷售稅,另一個算工資單
但插線板十分復雜,而人們急需更快、更靈活的新方式來編程
馮諾依曼架構
程式和資料都存在這里
馮諾依曼計算機的標志是:一個處理器(有算術邏輯單元)+資料暫存器+指令暫存器+指令地址暫存器+記憶體(負責存資料和指令)

面板編程
比起插線板用到大量的線,面板編程可以用一大堆開關和按鈕,做到相同的效果
第一款取得商業成功的家用計算機Altair 8800
編程依然很困難,人們需要更友好更簡單的方式編程–編程語言
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280356.html
標籤:其他
上一篇:python計算機視覺-影像處理基礎章節第三章之全景影像拼接
下一篇:7-1:C++的IO流