歷史文章推薦:
- HashMap面試,看這一篇就夠了
- 七種方式教你在SpringBoot初始化時搞點事情
- Java序列化的這三個坑千萬要小心
- Java中七個潛在的記憶體泄露風險,你知道幾個?
- JDK 16新特性一覽
- 啥?用了并行流還更慢了
- InnoDB自增原理都搞不清楚,還怎么CRUD?
一些題外話
前一篇文章我們對HashMap的實作做了詳細的決議和總結,這篇文章繼續剖析一下ConcurrentHashMap的實作,由于ConcurrentHashMap的內容比較多,而且Java 7和Java 8兩個版本的實作相差比較大,如果采用我們上篇中對比的那種行文思路,在有限的篇幅中難免會遺漏一些細節,因此我決定采用兩篇文章去詳細闡述兩個版本中ConcurrentHashMap技術細節,不過為了幫助讀者體系化的理解,三篇文章(包含HashMap的那一篇)整體文章的結構將保持一致,
把書讀薄
《阿里巴巴Java開發手冊》的作者孤盡對ConcurrentHashMap的設計十分推崇,他說:“ConcurrentHashMap原始碼是學習Java代碼開發規范的一個非常好的學習材料,我建議同學們可以時常去看一看,總會有新的識訓的”,相信大家平常也能聽到很多對于ConcurrentHashMap設計的溢美之詞,在展開隱藏在ConcurrentHashMap所有小秘密之前,大家在大腦中首先要有這樣的一幅圖:
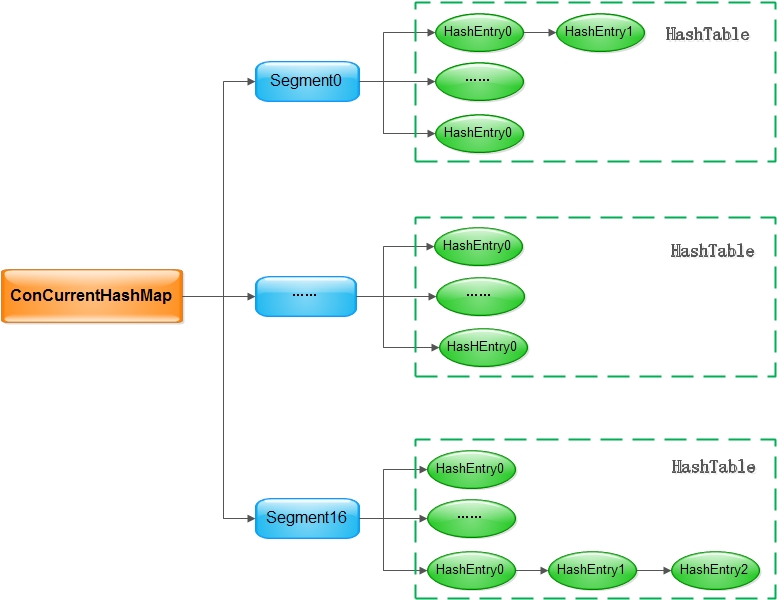
對于Java 7來說,這張圖已經能完全把ConcurrentHashMap的架構說清楚了:
ConcurrentHashMap是一個執行緒安全的Map實作,其讀取不需要加鎖,通過引入Segment,可以做到寫入的時候加鎖力度足夠小- 由于引入了
Segment,ConcurrentHashMap在讀取和寫入的時候需要需要做兩次哈希,但這兩次哈希換來的是更小的臨界區,也就意味著可以支持更高的并發 - 每個桶陣列中的
key-value對仍然以鏈表的形式存放在桶中,這一點和HashMap是一致的,
把書讀厚
關于Java 7的ConcurrentHashMap的整體架構,用上面三兩句話就可以概括,這張圖應該很快就可以在大家的大腦中留下印象,接下來我們通過幾個問題來嘗試吸引大家繼續看下去,把書讀厚:
ConcurrentHashMap的哪些操作需要加鎖?ConcurrentHashMap的無鎖讀是如何實作的?- 在多執行緒的場景下呼叫
size()方法獲取ConcurrentHashMap的大小有什么挑戰?ConcurrentHashMap是怎么解決的? - 在有
Segment存在的前提下,是如何擴容的?
在上一篇文章中我們總結了HashMap中最重要的點有四個:初始化,資料尋址-hash方法,資料存盤-put方法,擴容-resize方法,對于ConcurrentHashMap來說,這四個操作依然是最重要的,但由于其引入了更復雜的資料結構,因此在呼叫size()查看整個ConcurrentHashMap的數量大小的時候也有不小的挑戰,我們也會重點看下Doug Lea在size()方法中的設計
初始化
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
// 保證ssize是大于concurrencyLevel的最小的2的整數次冪
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 尋址需要兩次哈希,哈希的高位用于確定segment,低位用戶確定桶陣列中的元素
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor), (HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
初始化方法中做了三件重要的事:
- 確定了
segments的陣列的大小ssize,ssize根據入參concurrencyLevel確定,取大于concurrencyLevel的最小的2的整數次冪 - 確定哈希尋址時的偏移量,這個偏移量在確定元素在
segment陣列中的位置時會用到 - 初始化
segment陣列中的第一個元素,元素型別為HashEntry的陣列,這個陣列的長度為initialCapacity / ssize,即初始化大小除以segment陣列的大小,segment陣列中的其他元素在后續put操作時參考第一個已初始化的實體初始化
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
final void setNext(HashEntry<K,V> n) {
UNSAFE.putOrderedObject(this, nextOffset, n);
}
}
這里的HashEntry和HashMap中的HashEntry作用是一樣的,它是ConcurrentHashMap的資料項,這里要注意兩個細節:
細節一:
HashEntry的成員變數value和next是被關鍵字volatile修飾的,也就是說所有執行緒都可以及時檢查到其他執行緒對這兩個變數的改變,因而可以在不加鎖的情況下讀取到這兩個參考的最新值
細節二:
HashEntry的setNext方法中呼叫了UNSAFE.putOrderedObject,這個介面是屬于sun安全庫中的api,并不是J2SE的一部分,它的作用和volatile恰恰相反,呼叫這個api設值是使得volatile修飾的變數延遲寫入主存,那到底是什么時候寫入主存呢?
JMM對此規定:
對一個變數執行unlock操作之前,必須先把此變數同步到主記憶體中(執行store和write操作)
后文在講put方法的時候我們再詳細看setNext的用法
哈希
由于引入了segment,因此不管是呼叫get方法讀還是呼叫put方法寫,都需要做兩次哈希,還記得在上文我們講初始化的時候系統做了一件重要的事:
- 確定哈希尋址時的偏移量,這個偏移量在確定元素在
segment陣列中的位置時會用到
沒錯就是這段代碼:
this.segmentShift = 32 - sshift;
這里用32去減是因為int型的長度是32,有了segmentShift,ConcurrentHashMap是如何做第一次哈希的呢?
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// 變數j代表著資料項處于segment陣列中的第j項
int j = (hash >>> segmentShift) & segmentMask;
// 如果segment[j]為null,則下面的這個方法負責初始化之
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
我們以put方法為例,變數j代表著資料項處于segment陣列中的第j項,如下圖所示假如segment陣列的大小為2的n次方,則hash >>> segmentShift正好取了key的哈希值的高n位,再與掩碼segmentMask相與相當與仍然用key的哈希的高位來確定資料項在segment陣列中的位置,

hash方法與非執行緒安全的HashMap相似,這里不再細說,
細節三:
在延遲初始化Segment陣列時,作者采用了CAS避免了加鎖,而且CAS可以保證最終的初始化只能被一個執行緒完成,在最終決定呼叫CAS進行初始化前又做了兩次檢查,第一次檢查可以避免重復初始化tab陣列,而第二次檢查則可以避免重復初始化Segment物件,每一行代碼作者都有詳細的考慮,
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset 實際的位元組偏移量
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck 再檢查一次是否已經被初始化
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s)) // 使用 CAS 確保只被初始化一次
break;
}
}
}
return seg;
}
put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k; // 如果找到key相同的資料項,則直接替換
if ((k = e.key) == key || (e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
// node不為空說明已經在自旋等待時初始化了,注意呼叫的是setNext,不是直接操作next
node.setNext(first);
else
// 否則,在這里新建一個HashEntry
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1; // 先加1
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// 將新節點寫入,注意這里呼叫的方法有門道
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
這段代碼在整個ConcurrentHashMap的設計中非常出彩,在這短短的40行代碼中,Doug Lea就像一位神奇的魔術師,轉眼間已經變換了好幾種魔法,讓人目瞪口呆,感嘆其對并發的理解之深,讓我們慢慢的決議Doug Lea在這段代碼中使用的魔法:
細節四:
CPU的調度是公平的,好不容易輪到的時間片如果因為獲取不到鎖就將本執行緒掛起無疑會降低本執行緒的效率,更何況掛起之后還要重新調度,切換背景關系,又是一筆不小的開銷,如果可以遇見其他執行緒占有鎖的時間不會很長,采用自旋將會是一個比較好的選擇,在這里面也有一個權衡,如果別的執行緒占有鎖的時間過長,反而是掛起阻塞等待性能好一點,我們來看下ConcurrentHashMap的做法:
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
while (!tryLock()) { // 自旋等待
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) { // 這個桶中還沒有寫入k-v項
if (node == null) // speculatively create node 直接創建一個新的節點
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
// key值相等,直接跳出去嘗試獲取鎖
else if (key.equals(e.key))
retries = 0;
else // 遍歷鏈表
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
// 自旋等待超過一定次數之后只能掛起執行緒,阻塞等待了
lock();
break;
}
else if ((retries & 1) == 0 && (f = entryForHash(this, hash)) != first) {
// 如果頭節點改變了,則重置次數,繼續自旋等待
e = first = f;
retries = -1;
}
}
return node;
}
ConcurrentHashMap的策略是自旋MAX_SCAN_RETRIES次,如果還沒有獲取到鎖則呼叫lock掛起阻塞等待,當然如果其他執行緒采用頭插法改變了鏈表的頭結點,則重置自旋等待次數,
細節五:
要知道,如果要從編碼的角度提升系統的并發度,一個黃金法則就是減少并發臨界區的大小,在scanAndLockForPut這個方法的設計上,有個小細節讓我眼前一亮,就是在自旋的程序中初始化了一個HashEntry,這樣做的好處就是執行緒在拿到鎖之后不用初始化HashEntry了,占有鎖的時間相應減小,進而提升并發,可見Doug Lea對并發的理解程度之深,盡可能的優化每一處細節,
細節六:
在put方法的開頭,有這么一行不起眼的代碼:
HashEntry<K,V>[] tab = table;
看起來好像就是簡單的臨時變數賦值,其實大有來頭,我們看一下table的聲明:
transient volatile HashEntry<K,V>[] table;
table變數被關鍵字volatile修飾,CPU在處理volatile修飾的變數的時候采取下面的行為:
嗅探
每個處理器通過嗅探在總線上傳播的資料來檢查自己快取的值是不是過期了,當處理器發現自己快取行對應的記憶體地址被修改,就會將當前處理器的快取行設定成無效狀態,當處理器對這個資料進行修改操作的時候,會重新從系統記憶體中把資料讀到處理器快取里
因此直接讀取這類變數的讀取和寫入比普通變數的性能消耗更大,因此在put方法的開頭將table變數賦值給一個普通的本地變數目的是為了消除volatile帶來的性能損耗,這里就有另外一個問題:那這樣做會不會導致table的語意改變,讓別的執行緒讀取不到最新的值呢?別著急,我們接著看,
細節七:
注意put方法中的這個方法:entryAt():
static final <K,V> HashEntry<K,V> entryAt(HashEntry<K,V>[] tab, int i) {
return (tab == null) ? null : (HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)i << TSHIFT) + TBASE);
}
這個方法的底層會呼叫UNSAFE.getObjectVolatile,這個方法的目的就是對于普通變數讀取也能像volatile修飾的變數那樣讀取到最新的值,在前文中我們分析過,由于變數tab現在是一個普通的臨時變數,如果直接呼叫tab[i]則大概率是拿不到最新的首節點的,細心的讀者讀到這里可能會想:Doug Lea是不是糊涂了,兜兜轉換不是回到了原點么,為啥不剛開始就操作volatile變數呢,費了這老大勁,我們繼續往下看,
細節八:
在put方法的實作中,如果鏈表中沒有key值相等的資料項,則會把新的資料項插入到鏈表頭寫入到陣列中,其中呼叫的方法是:
static final <K,V> void setEntryAt(HashEntry<K,V>[] tab, int i, HashEntry<K,V> e) {
UNSAFE.putOrderedObject(tab, ((long)i << TSHIFT) + TBASE, e);
}
putOrderedObject這個介面寫入的資料不會馬上被其他執行緒獲取到,而是在put方法最后呼叫unclock后才會對其他執行緒可見,參見前文中對JMM的描述:
對一個變數執行unlock操作之前,必須先把此變數同步到主記憶體中(執行store和write操作)
這樣的好處有兩個,第一是性能,因為在持有鎖的臨界區不需要有同步主存的操作,因此持有鎖的時間更短,第二是保證了資料的一致性,在put操作的finally陳述句執行完之前,put新增的資料是不對其他執行緒展示的,這是ConcurrentHashMap實作無鎖讀的關鍵原因,
我們在這里稍微總結一下put方法里面最重要的三個細節,首先將volatile變數轉為普通變數提升性能,因為在put中需要讀取到最新的資料,因此接下來呼叫UNSAFE.getObjectVolatile獲取到最新的頭結點,但是通過呼叫UNSAFE.putOrderedObject讓變數寫入主存的時間延遲到put方法的結尾,一來縮小臨界區提升性能,而來也能保證其他執行緒讀取到的是完整資料,
細節九:
如果put真的需要往鏈表頭插入資料項,那也得注意了,ConcurrentHashMap相應的陳述句是:
node.setNext(first);
我們看下setNext的具體實作:
final void setNext(HashEntry<K,V> n) {
UNSAFE.putOrderedObject(this, nextOffset, n);
}
因為next變數是用volatile關鍵字修飾的,這里呼叫UNSAFE.putOrderedObject相當于是改變了volatile的語意,這里面的考量有兩個,第一個仍然是性能,這樣的實作性能明顯更高,這一點前文已經詳細的分析過,第二點是考慮了語意的一致性,對于put方法來說因為其呼叫的是UNSAFE.getObjectVolatile,仍然能獲取到最新的資料,對于get方法,在put方法未結束之前,是不希望不完整的資料被其他執行緒通過get方法讀取的,這也是合理的,
resize擴容
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list 只有一個節點,簡單處理
newTable[idx] = e;
else {
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 保證下文中newTable[k]不會為null
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone remaining nodes 對標記之前的不能重用的節點進行復制,再重新添加到新陣列對應的hash桶中去
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node 部分的put功能,把新節點添加到鏈表的最前面
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
如果大家看過我們上一篇分析HashMap的rehash的程序看這段代碼就會比較輕松,在上一篇我們分析過,在整個桶陣列長度為2的正整數冪的情況下,擴容前同一個桶中的元素在擴容后只會分布在兩個桶中,其中一個桶的下標保持不變,我們稱之為舊桶,另一個桶的下標為舊桶下標加上舊的容量,我們稱之為新桶,其實第一個for回圈的目的就是在一個鏈表中找到最后一個應該移到新桶的資料項,直接移到新桶中,這樣做是為了保證后面呼叫HashEntry<K,V> n = newTable[k];的時候不會讀取到null,第二個for就比較簡單了,將所有的資料項移到新的桶陣列中,當所有的操作完成之后才將newTable賦值給table,
rehash方法中是沒有加鎖的,并不是說呼叫這個方法不需要加鎖,作者是在外層加了鎖,這一點需要注意,
size方法
之前在分析HashMap方法的時候我們并沒有去講size方法,因為在單執行緒環境下這個方法可以使用一個全域的變數解決,同樣的方案當然也可以在多執行緒場景下使用,不過要在多執行緒環境下讀取全域變數又會陷入到無盡的“鎖”中,這是我們不愿意看到的,那ConcurrentHashMap是如何解決這個問題的呢:
public int size() {
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
在前面介紹put方法時我們選擇忽略了一個小小的成員變數modCount,這個變數在這里大顯身手,它的主要作用就是記錄整個Segment中寫入操作的次數,因為寫入操作是會影響整個ConcurrentHashMap的大小的,
因為在讀取ConcurrentHashMap大小的時候需要保證讀到的是最新的值,因此其呼叫了UNSAFE.getObjectVolatile這個方法,雖然這個方法的性能比普通變數要差,但是比起全域加鎖,可好多了,
static final <K,V> Segment<K,V> segmentAt(Segment<K,V>[] ss, int j) {
long u = (j << SSHIFT) + SBASE; // 計算實際的位元組偏移量
return ss == null ? null : (Segment<K,V>) UNSAFE.getObjectVolatile(ss, u);
}
細節十:
在size方法的設計上,ConcurrentHashMap先嘗試無鎖的方法,如果兩次遍歷所有segment陣列的時候整個ConcurrentHashMap沒有發生寫入操作,則直接回傳每個segment陣列的size()之和,否則重新遍歷,如果寫入操作頻繁,則不得已加鎖處理,這里的加鎖相當于是一個全域的鎖,因為對segment陣列的每一個元素都加了鎖,那如何判斷整個ConcurrentHashMap的寫入是否頻繁呢?就看無鎖重試的次數,當無鎖重試的次數超過閾值的話就全域加鎖處理,
總結
在看完ConcurrentHashMap中的這些細節之后我們嘗試回答一下文章開頭提出來的問題:
-
ConcurrentHashMap的哪些操作需要加鎖?答:只有寫入操作才需要加鎖,讀取操作不需要加鎖
-
ConcurrentHashMap的無鎖讀是如何實作的?答:首先
HashEntry中的value和next都是有volatile修飾的,其次在寫入操作的時候通過呼叫UNSAFE庫延遲同步了主存,保證了資料的一致性 -
在多執行緒的場景下呼叫
size()方法獲取ConcurrentHashMap的大小有什么挑戰?ConcurrentHashMap是怎么解決的?答:
size()具有全域的語意,如何能保證在不加全域鎖的情況下讀取到全域狀態的值是一個很大的挑戰,ConcurrentHashMap通過查看兩次無鎖讀中間是否發生了寫入操作來決定讀取到的size()是否可信,如果寫入操作頻繁,則再退化為全域加鎖讀取, -
在有
Segment存在的前提下,是如何擴容的?答:
segment陣列的大小在一開始初始化的時候就已經決定了,擴容主要擴的是HashEntry陣列,基本的思路與HashTable一致,但這是一個執行緒不安全方法,呼叫之前需要加鎖,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/281614.html
標籤:其他