文章目錄
- CPU使用率的定義
- 查看CPU使用率:top和pidstat
- 排查高CPU使用率:pref
- 參考文獻
寫在前面:
由于之前在開發分布式系統中由于云服務器性能原因,導致系統總是斷連等錯誤,但是之前一般只是簡單gdb除錯一下,定位錯誤例外艱難,所以決定開設此專欄,系統的記錄我學習Linux 性能優化的歷程,
作者郵箱:2107810343@qq.com
時間:2021/04/29 13:46
實作環境:Linux
系統:ubuntu 18.04
CPU使用率的定義
CPU使用率是一個衡量當前CPU瓶頸的重要指標,我們首先就需要知道CPU使用率是怎么計算出來的,
為了維護CPU時間,Linux會事先定義節拍率(內核表示HZ),觸發時間中斷,并維護全域變數Jiffies記錄了開機以來的節拍數,每發生一次時間中斷,Jiffies的值就加一,
注:
這也是CPU時間片輪轉法實施的基礎,
節拍數是內核的可配置選項,可以設定為100、250、1000等,不同的系統可能設定不同數值,可以通過查看/boot/config內核選項來查看它的配置值,
ubuntu@VM-0-2-ubuntu:~/ByteTalk/UserService$ grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=250
# 我這里設定就是250HZ,也就是4ms切換一次
Linux通過 /proc 虛擬檔案系統,向用戶空間提供系統內部狀態資訊,而/proc/stat提供的就是系統的CPU 和任務統級時間,
# 保留CPU的資料
ubuntu@VM-0-2-ubuntu:~/ByteTalk/UserService$ cat /proc/stat | grep ^cpu
cpu 15517599 934 269286 18794245 70312 0 3441 0 0 0
cpu0 11026589 293 105096 6155651 46206 0 1590 0 0 0
cpu1 4491010 640 164189 12638593 24106 0 1850 0 0 0
第一行時兩個CPU各個時間的總和,以下是各個列的解釋:
| 列名 | 含義 |
|---|---|
| cpu | 表示CPU編號,如cpu0,cpu1 |
| user | 代表用戶態的CPU時間,不包括nice和guest時間 |
| nice | 待避岙低優先級用戶態CPU時間,也就是行程的nice值被調整為1-19之間時的CPU時間 |
| system | 內核態CPU時間 |
| idle | 代表空閑時間,不包括等待I/O時間 |
| iowait | 等待I/O的CPU時間 |
| irq | 硬中斷的CPU時間 |
| softtrip | 軟中斷的CPU時間 |
| steal | 代表當前系統運行在虛擬機中的時候,被其他虛擬機占用的CPU時間 |
| guest | 通過虛擬化運行其他作業系統的時間,也就是運行虛擬機的CPU時間 |
| guest_nice | 以低優先級運行虛擬機的時間 |
而CPU使用率,就是除了空閑時間外其他時間占總CPU時間的百分比:

但是這個公式是有缺陷的,/proc/stat里面統計的是開機以來的資料,我們真正需要的是瞬時值,所以公式就應該做個修改,每隔幾秒取以下值,兩次間隔中取差值去計算CPU使用率:

查看CPU使用率:top和pidstat
現在,我們來使用top查看一下CPU的使用率:
ubuntu@VM-0-2-ubuntu:~/ByteTalk/UserService$ top
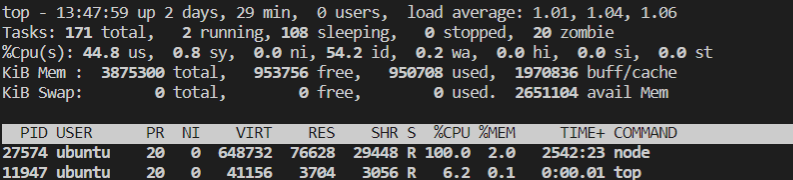
在這個結果中,第三行就是CPU使用率了,然后下面白色行之后就是每個行程的情況,都有一個%CPU列,表示行程的CPU使用率,它是用戶態和內核態CPU使用率的總和,包括行程用戶空間使用的CPU、通過系統呼叫執行的內核空間CPU以及在就緒佇列中等待運行的CPU,
但是top,沒有具體解決如何查看用戶態和內核態CPU使用率的問題,我們就需要使用pidstat來查看一下,
# 每秒輸出一次資料,總共輸出3組
ubuntu@VM-0-2-ubuntu:~/ByteTalk/UserService$ pidstat 1 3
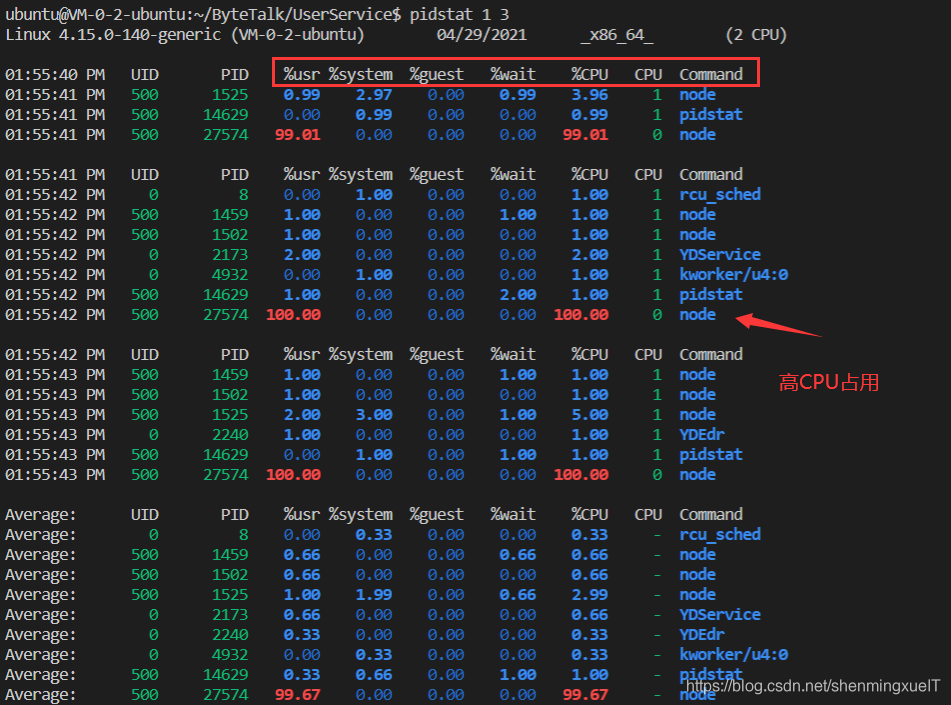
可以看到紅框圈出來一些資料,我們挨個來解讀一下:
| 列名 | 含義 |
|---|---|
| %user | 用戶態CPU使用率 |
| %system | 內核態CPU使用率 |
| %guest | 運行虛擬機CPU使用率 |
| %wait | 等待CPU使用率 |
| %cpu | 總CPU使用率 |
排查高CPU使用率:pref
我們剛剛在這幅圖也看到了,node行程占用了非常高的CPU使用率,由于不是作者自己寫的行程,我只能嘗試著排查,給大家演示一下:
除錯的話,熟悉Linux開發的小伙伴肯定第一時間想到的就是gdb除錯了,但是gdb除錯并不適合性能分析的早期應用,因為gdb除錯程式的程序會中斷程式運行,這在線上環境往往是不允許的,
我們現在來使用工具perf來分析CPU性能問題:
先安裝一下perf吧:
ubuntu@VM-0-2-ubuntu:~/ByteTalk/UserService$ sudo apt install linux-tools-common
ubuntu@VM-0-2-ubuntu:~/ByteTalk/UserService$ sudo apt install linux-tools-generic
ubuntu@VM-0-2-ubuntu:~/ByteTalk/UserService$ sudo apt install linux-tools-4.15.0-140-generic
然后執行以下命令:
# 這個可以像top那樣,實時顯示占用CPU時鐘最多的函式或者指令,因此可以查找熱點函式
ubuntu@VM-0-2-ubuntu:~/ByteTalk/UserService$ perf top
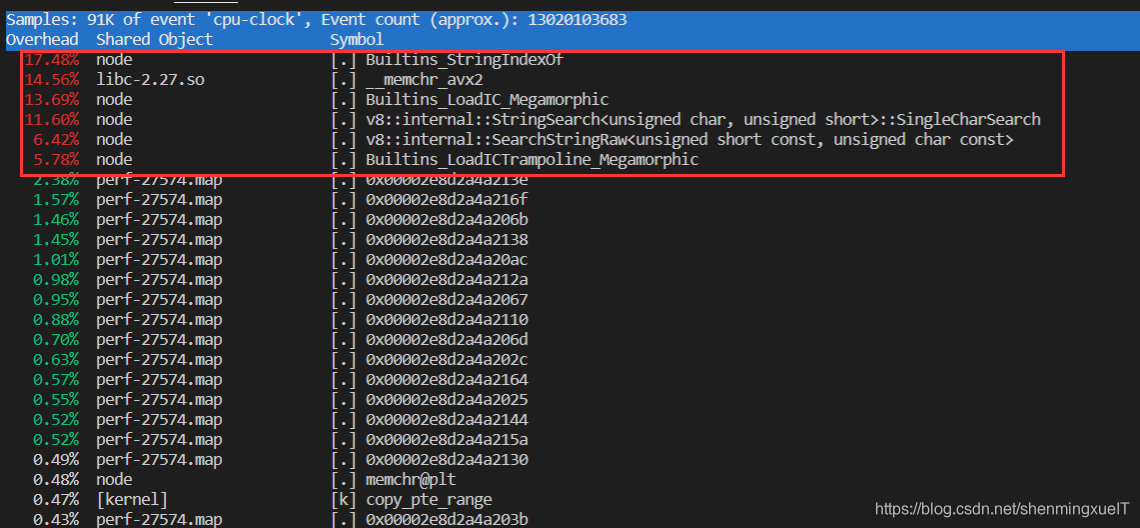
第一行有三個資料:采樣數(samples)、事件型別(event)和事件總數量(event count)
它的輸出結果分別包括四種資料:
| 列名 | 含義 |
|---|---|
| overhead | 該符號的性能事件在所有采樣中的比例 |
| shared | 該函式或指令所在動態庫共享物件 |
| object | 共享物件的型別,[.]表示用戶空間的可執行程式,或者動態連接庫,[k]表示內核空間 |
| symbol | 函式名,當函式名未知的時候,用16進制的地址來表示 |
這里我們可以看到是node行程里面的某個函式(具體看圖)造成的CPU高使用率,
注:
node是nodejs,是vscode中插件的依賴,可以直接kill
另外,由于perf top是實時查看CPU使用情況的,但是不會保存資料,也就無法用于離線或者后續的分析,我們就需要使用使用 perf record 和 perf report 了:
# 開啟后自動捕捉資料,按ctrl+c結束采樣
ubuntu@VM-0-2-ubuntu:~/ByteTalk/UserService$ sudo perf record
^C[ perf record: Woken up 5 times to write data ]
[ perf record: Captured and wrote 1.443 MB perf.data (24504 samples) ]
# 展示采樣的資料
ubuntu@VM-0-2-ubuntu:~/ByteTalk/UserService$ sudo perf report
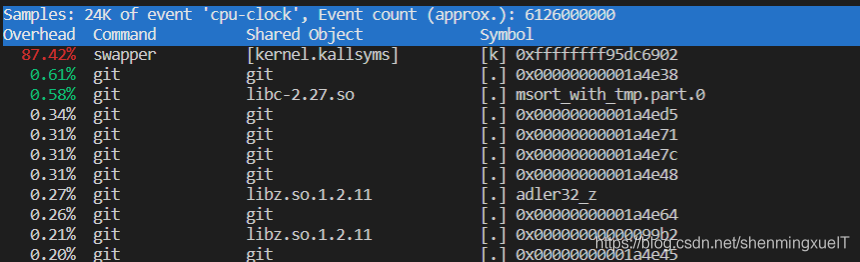
注:
這個采樣百分比和某行程是否占用過高的CPU資源是無關的!
參考文獻
[1] 倪朋飛.Linux性能優化實戰.極客時間
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/281743.html
標籤:其他
上一篇:集群(四)——haproxy日志