本文是對文章《Unsupervised Learning of Depth and Ego-Motion from Video》的解讀,

Figure 1. 深度圖和Ground-Truth [1]
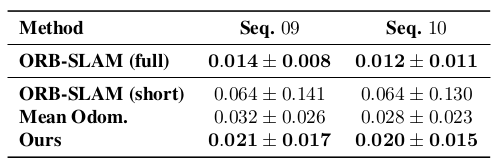
Figure 2. Absolute Trajectory Error(ATE) on KITTI dataset [1]
1. 概述
1.1為什么要講這篇文章?
在無人駕駛、3D重建和AR三個領域中,對于周圍環境物體的深度(Depth)和對自身位置的估計(State Estimation)一直是一個非常棘手而復雜的問題,
過去常用的方法,傳統的SLAM,通常用非常繁瑣的數學公式和基于特征點/直接法的方法來進行軌跡估算,而深度通常用單目視覺(多型幾何),雙目視覺,激光雷達來進行估計,
但傳統方法通常只能進行稀疏的特征點(Features),進行深度估計和自身姿態估計,而不能利用所有pixel,而這對于自動駕駛領域中重建高精地圖和AR領域中的室內環境感知來說就會導致資訊的缺失,
1.2 這篇文章提出了什么新方法?
這篇文章主要提出了一種基于無監督深度學習的單目視覺的深度和自身運動軌跡估計的深度神經模型,
它的新穎之處在于:
-
提出了一種堪稱經典的:depth network和ego-motion network共同訓練的架構模式,(因此這篇文章可以說是最2年基于深度學習的depth estimation的祖師爺,Google和Toyota的最新論文都借鑒了它的訓練模式)
-
無監督學習:只需任意單目相機的視頻就可以學習其深度和軌跡資訊,
-
同時追蹤所有像素點,不丟失任何場景資訊,
-
深度估計比肩傳統SLAM,自身軌跡估計優于傳統SLAM,
它在工程之中的應用價值:
-
高境地圖重建(自動駕駛車,移動機器人)
-
3D視覺效果重建
-
AR/VR定位
2. 文章核心
簡單來說,這篇文章的核心就是下圖中的兩個深度卷積網路CNN,Depth CNN和Pose CNN系結在一起通過View Synthesis進行訓練,
具體來說,通過把Target Image (It )中每一個pixel都按下圖的公式給warp到Source Image ( I t ? 1 或 I t + 1 )中,計算Pixel-Wise的intensity error:
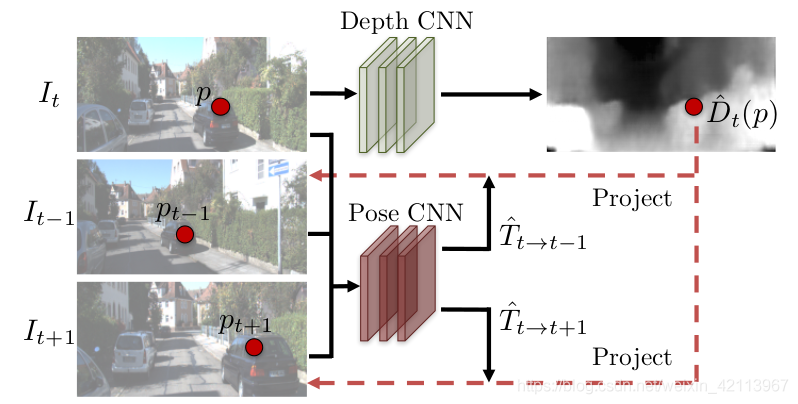
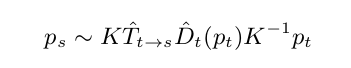
Figure 3. Depth/Pose nNtwork共同訓練的模式 [1]
-
大師兄:看到這里,俺老孫就想到了當年GAN生成對抗網路,也是兩個Network捆綁在一起進行訓練,
-
師傅:是的徒兒,這篇文章就是把Depth和Pose的Output合并在一起計算Loss,具體細節請聽為師娓娓道來~
2.1 View Synthesis與誤差函式的構建
眾所周知,深度學習模型的關鍵就是Loss function,它類似于傳統SLAM中的最小二乘法問題,都是要尋找到一個全域最小殘差,從而使得模型最能夠接近于最優解,
本文的Loss function用到了一個很強的假設:
-
假設:已有 t t t時刻影像target image和每個像素對應的深度, 以及target image相對上一 ( t ? 1 ) (t-1) (t?1)時刻影像source幀相機位置的T,(transfomration matrix)
-
結論:若D, T均是正確完美的數值,則必定可以準確地將targe image每一個像素點 p t對應warp到上一幀source image中的 p s 位置,
這么說可能有些抽象,打個比方: “ t t t時刻影像有一個艾菲爾鐵塔的尖尖,經過Depth和T的warp變換后,我們可以得到上一 ( t ? 1 ) (t-1) (t?1)時刻在另一個角度拍攝的艾菲爾鐵塔的尖尖的pixel位置,那么它們兩個點影像的亮度 (intensity) 應該是一樣的”,
有了這個假設以后,我們的Loss就可以設為pixel intensity ( I I I)的差值之和:
![]()
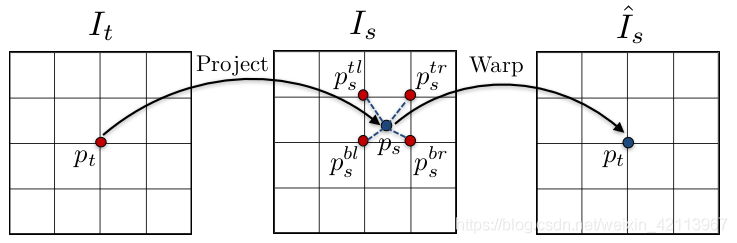
Figure 4. Warping [1]
2.2 Warping的數學模型
在上一節中使用的warping公式,具體含義如下:
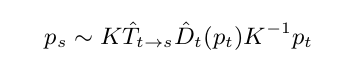
p s : pixel in source image
p t : pixel in target image
K : camera intrinsics matrix
D ^ t : Depth of a point, at time t t t
T ^ t ? > s : Transformation matrix from target image to source image
除此以外,為了讓該公式能夠被神經網路訓練,求出D和T,我們必須讓它可求導 (differentiable),
本文的做法是采用Spatial Transformer Networks [2]文章中的雙線性插值法 (biliner interpoltion),具體原理如下:

Figure 5. bilinear interpoltion [2]
2.3 Explainability Mask & Regularization
2.1節中的監督模型有一個很強的假設,但現實世界;總是不盡如人意的,有以下三種特殊情況會打破之前的假設:
-
場景中有移動物體
-
前后兩幀之家出現不連續性,如有物體被遮擋
-
Surface不符合Lambertian規律(不是理想散射)
因此,本文引入了一個Explainability Mask Network ( E ^ s (?))來“馬賽克”移動物體,遮擋物體和不符合理想散射的平面,
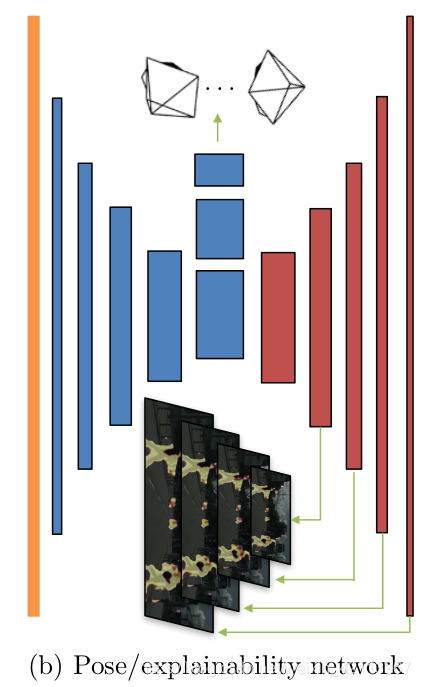
Figure 6. Explainability Mask Network [1]
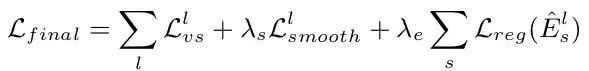
除此以外,由于low-texture region和far from current estimation的緣故,我們在訓練模型時容易進入gradient locality (梯度區域性),簡單來說就是“訓練不動了”,加入regularization因子可以有效地解決這點,最終我們可以得到一個loss function:
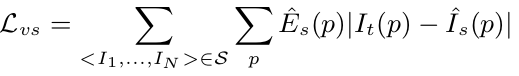
2.4 Network Architecture
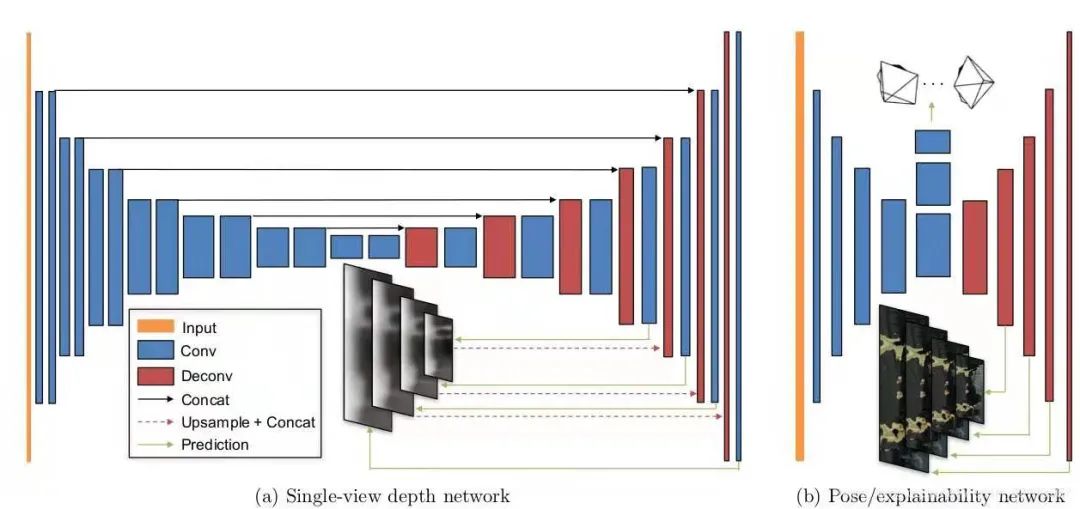
Figure 7. Network Architecture [1]
注:本文采用了multi-scale side predictions,在四個layer的位置,生成了四張不同清晰度的predictions,具體效果估計是讓Loss更robust,對不同大小和清晰度的影像都能兼容吧(個人觀點~)
3. Conclusion
總的來說,本文使用Unsupervised Learning獲得的Depth和Trajectory的效果均獲得了不遜色于傳統SLAM和基于Supervised-Learning的Depth Estimation的結果,并且,本文對于Trajectory估計的效果還要更勝一籌,
在實際工程中,基于深度學習得到的Depth和Ego-Motion可直接用于vSLAM或者3D reconstruction,并且可以實作全像素的追蹤,這一點和基于幾十幾百個稀疏的feature pixels的傳統SLAM是一個巨大的優勢,
因為它可以獲得更加穩定的Depth/Motion Estimation,并且可以拓展到魚眼攝像頭、全景攝像頭等不規則相機的SLAM,
(因為目前自動駕駛通常會使用魚眼相機來保證360度的周圍環境感知和深度測量,能夠通過文章[3] [4]來拓展本文的pin-hole方法,到Fisheye)
3.1 基于本文的拓展: Google AI 2019論文
在本文所介紹的[1]中,訓練集是一個非常頭疼的問題,海量的資料就是模型準確度提升的關鍵,但是網上存在的很多Wild Videos連相機模型都不一定有,更不用說內參了,
Google 2019年的這篇論文[4]名為"Depth from videos in the wild",顧名思義,它基于[1]所作出的改進就是在不需要已知Camera Instrinsics的情況下,可以同時估計Depth和Intrinsics,
3.2 基于本文的拓展: Toyota 2020論文
在本文所介紹的[1]中,只有針孔相機模型的intrinsics matrix是可以估計的,而其他Fisheye或者catadioptric相機由于intrinsics matrix的模型都不一樣,
(有各種radial distortion模型,所需的引數數量都不一樣),
Toyota 2020的這篇論文[2]就在上兩篇論文的基礎上,記入了對所有相機型別的支持,
它不使用任何analytical (決議)模型,而是用network直接自己學習2D pixel 到 3D point的projection公式,因而不需要一個預設的,要估計的內參模型,

Figure 8. Toyota的最新論文基于本文的方法拓展到了所有異型相機的Depth Estimation [3]
4. Appendix
4.1 Experiment on Cityscapes and KITTI

Figure 9. Depth Prediction Results [1]
4.2 Experiment on NYU depth and KITTI

Figure 10. Depth Prediction Results [1]
4.3 Experiment on KITTI for Trajectory
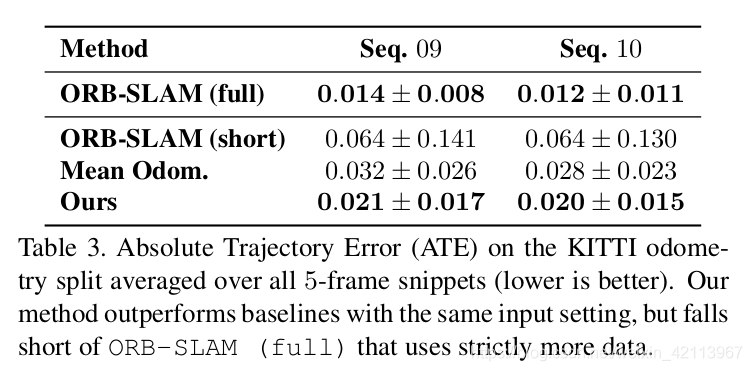
Figure 11. Ego-Motion Prediction Results [1]
Reference:
[1] T. Zhou, M. Brown, N. Snavely and D. G. Lowe, “Unsupervised Learning of Depth and Ego-Motion from Video,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017, pp. 6612-6619, doi: 10.1109/CVPR.2017.700.
[2] M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In Advances in Neural Information Processing Systems, pages 2017–2025, 2015.
[3] Vasiljevic, Igor & Guizilini, Vitor & Ambrus, Rares & Pillai, Sudeep & Burgard, Wolfram & Shakhnarovich, Greg & Gaidon, Adrien. (2020). Neural Ray Surfaces for Self-Supervised Learning of Depth and Ego-motion. 1-11. 10.1109/3DV50981.2020.00010.
[4] A. Gordon, H. Li, R. Jonschkowski and A. Angelova, “Depth From Videos in the Wild: Unsupervised Monocular Depth Learning From Unknown Cameras,” 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 8976-8985, doi: 10.1109/ICCV.2019.00907.
作者介紹:夏唯桁,柏林工業大學碩士研究生,主要研究方向為自動駕駛和移動機器人的SLAM及運動規劃,目前在法國雷諾集團擔任自動駕駛SLAM演算法實習生,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282246.html
標籤:AI