A 題 馬賽克瓷磚選色問題
選近似顏色的瓷磚,可以直接用距離公式搞定,matlab中用距離pdist2函式解決,edit pdist2后可以看到有很多種距離公式演算法
 ?
?
很多小朋友到這里就完事了,其實不然,舉個例子,三個顏色矩陣[0.6,0.6,0.6]、[0.5,0.5,0.5]、[0.5,0.6732,0.5],其中1和3和2歐式距離都相差0.1732距離,依次可視化顏色矩陣后

可以看出我們還應考慮的是 RGB 差值的方差,例如[0.6,0.6,0.6]與[0.5,0.5,0.5]做差后差 值一樣,其方差為 0;[0.5,0.5,0.5]與[0.5,0.6732,0.5]做差后得到[0,1.732,0],其方差為 1;兩 個公式后者作為優先排序條件,前者距離公式作為次要排序條件為宜,(方差為0說明為同種顏色,再次前提下歐式距離越大明暗差別越大),本段描述下面繪制程式,
figure % 0-1對應的為0-255
p=plot(1,1,'o','LineWidth',100);%方差為0
set(p,'color',[0.6 0.6 0.6]);
hold on
p=plot(2,1,'o','LineWidth',100);%標準點用于對比
set(p,'color',[0.5 0.5 0.5]);
p=plot(3,1,'o','LineWidth',100);
set(p,'color',[0.5 0.6732 0.5]);%方差不為0,歐氏距離與第一個點一致
axis([0,4,0,2])
然而在第一問中,附件2和附件3中如果按上述排序方式選擇近似顏色,就會發現,歐式距離過大,但是方差很小,顏色深淺差距很大,因此我們可以設定權重以平衡這兩個公式,同樣的我們可視化看下,

figure% 0-1 對應的為0-255
p=plot(1,1,'o','LineWidth',100);%方差為0
set(p,'color',[0.6 0.6 0.6]);
hold on
p=plot(2,1,'o','LineWidth',100);%標準點用于對比
set(p,'color',[0.5 0.5 0.5]);
p=plot(3,1,'o','LineWidth',100);
set(p,'color',[0.5 0.54 0.5]);%方差不為0,歐氏距離與第一個點一致
axis([0,4,0,2])
從效果來看還可以接受,兩個結果的歐式距離分別是0.1732和0.05,因此我們可以將差的方差和歐式距離公式權重比例設為0.776:0.224,我們新構建的距離公式應當為
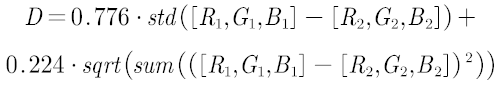
權重可以根據各自認為的顏色近似自行設定,這里只是給了一個案例
對于第二問,這個表現力就是說能夠近似體現多種顏色,優先增加與多個顏色差別較小,不管增加幾種顏色,但本質上還是選近似顏色,只不過同時多增加幾種顏色就要考慮新聚類中心的分布問題,FCM思想比較適合解決該問題,目標函式可以就以FCM的來
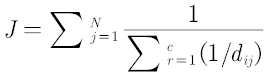
其中i表示聚類中心,j表示其他點,c為聚類中心總數,N為其他點總數,(別去管什么隸屬度矩陣,你們直接用上面函式就行,除了FCM也可以借助其他聚類演算法的思想來做)
該演算法思想就是其他點到聚類中心的距離的倒數之和最小,但是別直接套用該演算法程式,其中的距離公式需要更改,第二問說是從技術革新的角度,那么本問被聚類的點應當為256*256*256個點了,并不是附件2和附件3的點來做聚類分析,當然在選出新聚類中心顏色后,可以再去算一附件2和附件3的J函式值,對于題目提到的表現力,顏色越近似就說明表現力越好,表現力函式公式可以直接是J函式的倒數,
本文的程式設計思路可以做個參考:
1.兩個自變數,除了固定的22個顏色外額外增加的顏色數、聚類范圍(切記不是半徑為R的圓形)
2.(優化演算法)隨機產生n個個體,每個個體擁有m個新聚類中心(m個RGB值,看做是三維坐標)和1個聚類范圍,被聚類的點就是256*256*256個點,按第一問距離公式計算各聚類中心距離,
3.設立目標函式J,如果想將表現力設為目標函式,這里目標函式就設為1/J,(第一問兩個公式加權聚合為一個公式,權重自行設立,效果不好就除錯下),求J函式最小化或者1/J函式最大化,
4.迭代多次后,輸出新增最佳m個顏色RGB,
第三問,在上一問基礎上考慮成本,成本函式就按新增了多少個顏色來算,相當于說本問尋優的自變數個數m是變化的,可以在上述步驟增加一個目標函式M,即新增m個顏色,本問即是多目標尋優問題,可以去看下之前我發的推文(推文路徑:演算法-優化演算法-智能優化演算法函式尋優補充篇),專門舉了自變數個數變化的尋優案例程式,以及多目標常用排序方法(推文路徑:演算法-優化演算法-非支配排序-Ⅱ),就自己去微信公眾號找推文了,
B 題 技術問答社區重復問題識別
之前發的詞云圖推文可以參考下字串處理(推文路徑:演算法-Matlab版-詞云圖),本題的基本步驟為:字串處理(建議以翻譯列的問題來做,這些問題資料是爬蟲下來的,會有很多干擾字串,將換行符、網址、表情、圖片字符刪掉,在是對一些標點符號、數字進行清理,這里暫時不用清理英文字母),詞匯分割(常用中文詞匯庫,例如jieba,英文詞庫可以自己組建一個以軟體名稱為主的詞庫,中文詞庫和英文詞庫分別進行分詞)將每個問題提取成若干個詞匯、判斷是否為同類問題(這里需要根據附件2訓練下模型引數,在訓練前需要挖掘一些指標,label列為1的樣本例如共同詞匯在第1個問題中的占比、共同詞匯在第二個問題中的占比,label列為0的,這里要注意看下是否在找出與其共同詞匯占比最大的一個問題同樣的提取出共同詞匯占比資料[這里是為了盡可能將同類和不同類區分開來],構建好訓練集,將訓練資料帶入到邏輯回歸、神經網路、svm等模型中訓練引數),



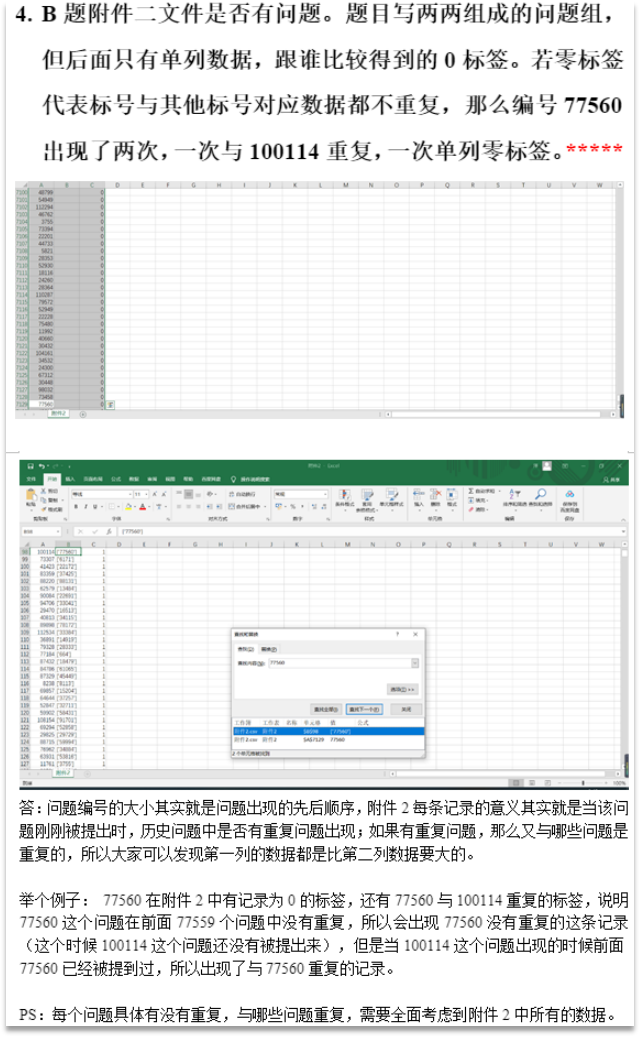
上述為舉辦方答疑
第一問的樣本問題組是指附件1中的所有資料,即需要計算出每個問題與其他問題的重復概率,第二問的目標問題是指在第一問的基礎上,找到每個問題重復概率排名前十的問題,找出來后通過評估公式進行評估,
本題做的效果取決于詞庫和分詞方法,附件中主要是一些軟體操作的問題,可以從搜狗萬能詞庫里下載一些軟體類的專業詞匯包括英文詞匯,本題的結果主要依賴詞庫,如果結果不是很好,就重新組合下詞庫,也可以從附件問題中挖掘出一些專業詞匯添加到詞庫中,
這個問題思路很簡單,但是做起來繁瑣,一般的都是針對專門的領域構建專門的詞庫,會花費很大的時間和精力,因此本題結果能看過得去就行,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282247.html
標籤:AI
上一篇:基于無監督深度學習的單目視覺的深度和自身運動軌跡估計的深度神經模型
下一篇:AlexNet 實作貓狗分類