AlexNet 實作貓狗分類
前言
在訓練網路程序中遇到了很多問題,先在這里抱怨一下,沒有硬體條件去使用龐大的ImageNet2012 資料集 ,所以在選擇合適的資料集上走了些彎路,最后選擇有kaggle提供的貓狗資料集,因為二分類問題可能訓練起來比較容易一些,實驗結果和代碼我放在kaggle上了,有時會加載不出來,ipynb檔案百度云里面也有 下載完成后用jupyter打開,下面附上鏈接
| 內容 | 地址 |
|---|---|
| 資料集 | 鏈接 |
| kaggle實驗程序 | 鏈接 |
| 百度云ipynb檔案 | 鏈接 提取碼:di7c |
好,我們開始介紹吧!
AlexNet簡介
首先呢,AlexNet是2012年,由Alex Krizhevsky、 llya Sutskever 和 Geoffrey E. Hinton 提出來的一種卷積神經網路模型,并獲得了2012年ILSVRC影像分類大賽的冠軍,自此呢也掀起了深度學習的熱潮,神經網路通常都是直接上圖比較直觀,
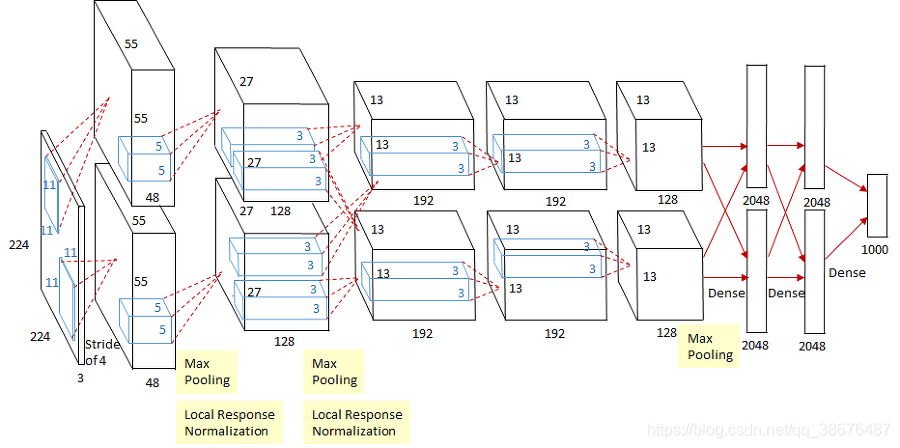
看上去好像 很復雜的樣子,其實由于當時硬體條件限制,所以將圖片分成了兩個部分,分別用兩塊GPU進行訓練,分別放置了一半的卷積核,相比上一篇提到的LeNet, 它有很多優點,如下表所示:
| 技巧 | AlexNet | LeNet |
|---|---|---|
| Relu,多GPU | 訓練速度塊 | 訓練速度慢 |
| 區域回應歸一化 | 提高了精度,緩解過擬合 | 無 |
| 資料擴充,丟失輸出 | 減少過擬合 | 無 |
這里有爭議的就是區域回應歸一化(Local Response Normalization,簡稱LRN),在它之后有論文證明區域回應歸一化并沒有太大作用,我第一次實驗也用的區域回應歸一化但效果并不好,后面采用的是批標準化(BatchNormalization, 簡稱BN),
網路結構
網路節后從圖中可以詳細看出,這里就不再進行贅述,我們可以看看keras搭建好的AlexNet網路結構:
Model: "AlexNet"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
zero_padding2d_2 (ZeroPaddin (None, 227, 227, 3) 0
_________________________________________________________________
conv_block_1 (Conv2D) (None, 55, 55, 96) 34944
_________________________________________________________________
max_pooling_1 (MaxPooling2D) (None, 27, 27, 96) 0
_________________________________________________________________
batch_normalization_12 (Batc (None, 27, 27, 96) 384
_________________________________________________________________
conv_block_2 (Conv2D) (None, 27, 27, 256) 614656
_________________________________________________________________
max_pooling_2 (MaxPooling2D) (None, 13, 13, 256) 0
_________________________________________________________________
batch_normalization_13 (Batc (None, 13, 13, 256) 1024
_________________________________________________________________
conv_block_3 (Conv2D) (None, 13, 13, 384) 885120
_________________________________________________________________
max_pooling_3 (MaxPooling2D) (None, 6, 6, 384) 0
_________________________________________________________________
batch_normalization_14 (Batc (None, 6, 6, 384) 1536
_________________________________________________________________
conv_block_4 (Conv2D) (None, 6, 6, 384) 1327488
_________________________________________________________________
conv_block_5 (Conv2D) (None, 6, 6, 256) 884992
_________________________________________________________________
max_pooling_5 (MaxPooling2D) (None, 2, 2, 256) 0
_________________________________________________________________
batch_normalization_15 (Batc (None, 2, 2, 256) 1024
_________________________________________________________________
flatten (Flatten) (None, 1024) 0
_________________________________________________________________
fc_1 (Dense) (None, 4096) 4198400
_________________________________________________________________
dropout_1 (Dropout) (None, 4096) 0
_________________________________________________________________
batch_normalization_16 (Batc (None, 4096) 16384
_________________________________________________________________
fc_2 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_2 (Dropout) (None, 4096) 0
_________________________________________________________________
batch_normalization_17 (Batc (None, 4096) 16384
_________________________________________________________________
dense_2 (Dense) (None, 1000) 4097000
=================================================================
Total params: 28,860,648
Trainable params: 28,842,280
Non-trainable params: 18,368
可以清楚的看到每一層網路的輸入輸出及節點數,我們不用ImageNet2012作為訓練資料,這里直接用一塊GPU訓練就好,
注意事項
由于輸入是224x224x3(HWC)大小的圖片,但實際運算時使用的是227x227x3(HWC)大小的圖片,所以又要進行填0操作:
x = ZeroPadding2D(((3, 0), (3, 0)))(img_input)
下面請看詳細代碼:
- 構建網路模型:
#定義網路結構
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, Flatten, Lambda, MaxPooling2D, Dropout, Input, Dense,ZeroPadding2D,BatchNormalization
from tensorflow.python.keras import backend
from tensorflow.python.keras.engine import training
from tensorflow.python.keras.utils import layer_utils
from tensorflow.keras import optimizers, losses, initializers
def alexnet(input_shape=(224, 224, 3), input_tensor=None,classes=1000):
if input_tensor is None:
img_input = Input(shape=input_shape)
else:
if not backend.is_keras_tensor(input_tensor):
img_input = Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
x = ZeroPadding2D(((3, 0), (3, 0)))(img_input)
# 第一個塊
x = Conv2D(filters=96, kernel_size=(11, 11), kernel_initializer=initializers.RandomNormal(stddev=0.01),strides=4, padding='valid', name='conv_block_1', activation='relu')(
x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, name='max_pooling_1')(x)
# x = Lambda(tf.nn.local_response_normalization, name='lrn_1')(x)
x=BatchNormalization()(x)
# 第二個塊
x = Conv2D(filters=256, kernel_size=(5, 5),kernel_initializer=initializers.RandomNormal(stddev=0.01),strides=1, padding='same', activation='relu', name='conv_block_2')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, name='max_pooling_2')(x)
# x = Lambda(tf.nn.local_response_normalization, name='lrn_2')(x)
x=BatchNormalization()(x)
# 第三個塊
x = Conv2D(filters=384, kernel_size=(3, 3),kernel_initializer=initializers.RandomNormal(stddev=0.01),strides=1, padding='same', activation='relu', name='conv_block_3')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, name='max_pooling_3')(x)
x=BatchNormalization()(x)
# 第四到第五塊
x = Conv2D(filters=384, kernel_size=(3, 3),kernel_initializer=initializers.RandomNormal(stddev=0.01),strides=1, padding='same', activation='relu', name='conv_block_4')(x)
x = Conv2D(filters=256, kernel_size=(3, 3),kernel_initializer=initializers.RandomNormal(stddev=0.01),strides=1, padding='same', activation='relu', name='conv_block_5')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, name='max_pooling_5')(x)
x=BatchNormalization()(x)
# 這個是將卷積介面一維化 用于鏈接全連接
x = Flatten(name='flatten')(x)
# 全連接層
x = Dense(4096, name='fc_1', activation='relu')(x)
x=Dropout(0.4,name='dropout_1')(x)
x=BatchNormalization()(x)
x = Dense(4096, name='fc_2', activation='relu')(x)
x = Dropout(0.4, name='dropout_2')(x)
x=BatchNormalization()(x)
x=Dense(classes,activation='softmax')(x)
if input_tensor is not None:
inputs = layer_utils.get_source_inputs(input_tensor)
else:
inputs = img_input
model = training.Model(inputs, x, name='AlexNet')
return model
model =alexnet(classes=2)
model.summary()
代碼里注解得有LRN的使用方法,感興趣的話可以自己去除錯,
- 資料集加載:
這里借助的是kaggle得在線平臺,直接在kaggle上使用在線資料集,自己使用時記得改路徑,
import os
train_data_dir =r'../input/cat-and-dog/training_set/training_set'
test_data_dir =r'../input/cat-and-dog/test_set/test_set'
IMG_WEIGHT=224
IMG_HEIGHT=224
IMG_CHANEL=3
floders = os.listdir(train_data_dir)
NUM_Categories=len(os.listdir(train_data_dir))
print(NUM_Categories) #這里總共會有2個分類
for floder in floders:
path = train_data_dir+'/'+floder
print(floder.split('-')[-1]) #查看標簽讀取是否正確
import cv2
from PIL import Image
import numpy as np
floders = os.listdir(train_data_dir)
image_data=[] #用于保存分類
image_labels=[] #用于保存標簽
type_dict={} #下表和所屬類別對應
index =-1 #用于字典下表和標簽
for floder in floders:
index+=1#從0開始編號
path = train_data_dir+'/'+floder
print('loading '+path)
type_dict[index]=floder.split('-')[-1]
images = os.listdir(path)
for img in images:
try: #加入例外判斷 防止讀取的時候 出錯
image = cv2.imread(path+'/'+img)
img_fromarray =Image.fromarray(image,'RGB')
img_resize = img_fromarray.resize((IMG_WEIGHT,IMG_HEIGHT))
image_data.append(np.array(img_resize))
image_labels.append(index)
except Exception as err: #防止出錯
print(err)
print('Error in '+img)
- 資料轉換及驗證集劃分:
image_data=np.array(image_data,np.float32)
image_labels=np.array(image_labels,np.int)
print(image_data.shape,image_labels.shape)
rom tensorflow import keras
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(image_data, image_labels, train_size=0.7,random_state=42,
shuffle=True)
del image_data #洗掉不適用得變數,防止記憶體溢位
del image_labels #洗掉不適用得變數,防止記憶體溢位
X_train = X_train / 255.0 #歸一化
X_val = X_val / 255.0 #歸一化
y_train = keras.utils.to_categorical(y_train,NUM_Categories)
y_val = keras.utils.to_categorical(y_val,NUM_Categories)
print("X_train.shape", X_train.shape)
print("X_valid.shape", X_val.shape)
print("y_train.shape", y_train.shape)
print("y_valid.shape", y_val.shape)
- 資料數量可視化: 這里主要是為了 看樣本之前得數量占比,防止某一樣本數量過少,導致模型收斂過慢,個別類別學習特征較少,導致模型泛化能力
較差,
import matplotlib.pyplot as plt
def visual_train_data(train_path,classes):
"""
?
:param train_path: 訓練資料路徑
:param classes: 標簽字典 如classes = { 0:'Speed limit (20km/h)',
1:'Speed limit (30km/h)',
2:'Speed limit (50km/h)',
3:'Speed limit (60km/h)',
4:'Speed limit (70km/h)'}
:return:
"""
folders = os.listdir(train_path)
train_num = []
class_num = []
index=0
for folder in folders:
train_files = os.listdir(train_path + '/' + folder)
train_num.append(len(train_files))
class_num.append(classes[index])
index+=1
zipped_lists = zip(train_num, class_num)
sorted_pair = sorted(zipped_lists)
tuples = zip(*sorted_pair) # 這里是解壓
# 這個人一定是腦子有問題才壓縮之后還要解壓,還要用 tuples來遍歷
train_num, class_num = [list(tuple) for tuple in tuples]
plt.figure(figsize=(21, 10))
plt.bar(class_num, train_num)
plt.xticks(class_num, rotation='vertical')
plt.show()
visual_train_data(train_data_dir,type_dict)
- 模型訓練配置:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import Adam,SGD
lr=0.0001
epochs=20
opt=Adam(lr=lr,decay=lr/(epochs/0.5))
model = alexnet(classes=2)
model.compile(loss='categorical_crossentropy',optimizer=opt,metrics=['acc'])
aug = ImageDataGenerator( #這里設定資料增強,提高模型得泛化能力
rotation_range=10,
zoom_range=0.15,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.15,
horizontal_flip=False,
vertical_flip=False,
fill_mode='nearest'
)
history = model.fit(X_train, y_train, batch_size=50,
epochs=epochs, validation_data=(X_val, y_val))
- 測驗集加載與測驗:
del X_train #同樣是為了防止記憶體溢位
del y_train
del X_val
del y_val
import cv2
from PIL import Image
import numpy as np
floders = os.listdir(test_data_dir)
test_data=[] #用于保存分類
test_labels=[] #用于保存標簽
test_dict={} #下表和所屬類別對應
index =-1 #用于字典下表和標簽
for floder in floders:
index+=1#從0開始編號
path = test_data_dir+'/'+floder
print('loading '+path)
test_dict[index]=floder.split('-')[-1]
images = os.listdir(path)
for img in images:
try: #加入例外判斷 防止讀取的時候 出錯
image = cv2.imread(path+'/'+img)
img_fromarray =Image.fromarray(image,'RGB')
img_resize = img_fromarray.resize((IMG_WEIGHT,IMG_HEIGHT))
test_data.append(np.array(img_resize))
test_labels.append(index)
except Exception as err:
print(err)
print('Error in '+img)
test_data=np.array(test_data,np.float32)
test_labels=np.array(test_labels,np.int)
print(test_labels.shape,test_labels.shape)
test_data = test_data / 255.0 #歸一化
test_labels = keras.utils.to_categorical(test_labels,NUM_Categories)
model.evaluate(test_data,test_labels
- 這里是最后的準確率:
64/64 [==============================] - 12s 171ms/step - loss: 0.6805 - acc: 0.8052
[0.680515706539154, 0.805239737033844]
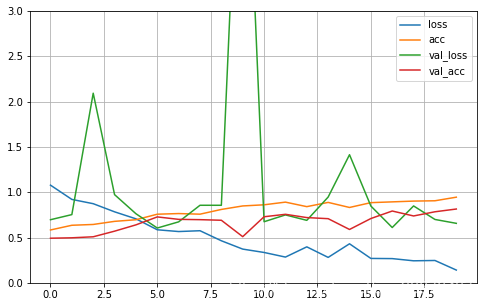
- 訓練程序可視化:
import pandas as pd
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 3)
plt.show()
model.save('my_model.h5')
9. 總結:
從頭開始訓練一個模型太難了,所以還是了解一下遷移學習吧,我個人感覺目前的資料集和硬體條件,是深度學習面臨的最大挑戰,從AlexNet中學到的東西就是怎樣減少過擬合,但我的理論推導有些欠缺,以后會嘗試添加一點理論推導,下一篇可能做ZFNet,但它僅僅在AlexNet上有一點點創新,如把11x11的卷積核改為7x7,只用一個GPU訓練等,
10. 參考:
書籍:
書名:深度學習:卷積神經網路從入門到精通
作者:李玉鑑 張婷 單傳輝 劉兆英
ISBN:9787111602798
版次:1-1
字數:258
出版社:機械工業出版社
鏈接:
[1]https://blog.csdn.net/qq_35912099/article/details/107237182
[2]https://zhuanlan.zhihu.com/p/141530560
[3]https://blog.csdn.net/DeepLearningJay/article/details/107971526
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282248.html
標籤:AI