目錄
什么是 Serverless?
Serverless 的價值
1. 降低運維需求
2. 降低運營成本
3. 縮短迭代周期、上線時間
4. 快速試錯
什么是云計算?
云計算的價值
什么是大資料?
大資料的價值
什么是人工智能?
人工智能的價值
云計算、大資料、人工智能三劍合一
相遇(時代的需要,讓你們互相認識)
每文一語
什么是 Serverless?
Serverless ,按中文翻譯,稱為「無服務器」,這究竟是一種什么樣的形態或產品呢?無服務器,就是真的沒有服務器嗎?
其實,在行業內,目前對于 Serverless 有幾種解讀方法:
在某些場景可以解讀為一種軟體系統架構方法,通常稱為 Serverless 架構
而在另一些情況下,又可以代表一種產品形態,稱為 Serverless 產品
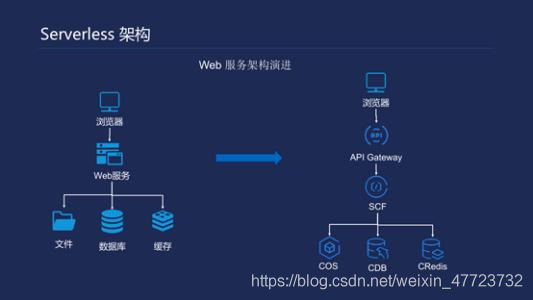
在說起 Serverless 架構時,Serverless 代表的是利用 Serverless 形態的產品實作的應用架構,這種架構完全依托于云廠商或云平臺提供產品完成系統的組織及構建,在這種架構中,用戶無需關注支撐應用服務運行的主機,而將關注點投入在系統架構,業務開發,業務支撐運維上,
而說起 Serverless 產品時,代表的是無需理解、管理服務器,按需使用,按使用付費的產品,Serverless 產品中,其實也可以包含存盤、計算等多種型別的產品,而典型的計算產品,就是云函式這種形態,
云函式,或者稱為函式即服務 (Function as a Service),它和后端即服務 (Backend as a Service) 一起,都可以稱為 Serverless 產品,通過組合使用這些產品,開發者可以構建自身的業務 Serverless 架構,
Serverless并不神秘,對于Serverless來說,用戶只是不用更多的去考慮服務器的相關內容了,無需再去考慮服務器的規格大小、存盤型別、網路帶寬、自動擴縮容問題了;同時,也無需再對服務器進行運維了,無需不斷的打系統補丁、應用補丁、無需進行資料備份、軟體配置等作業了,
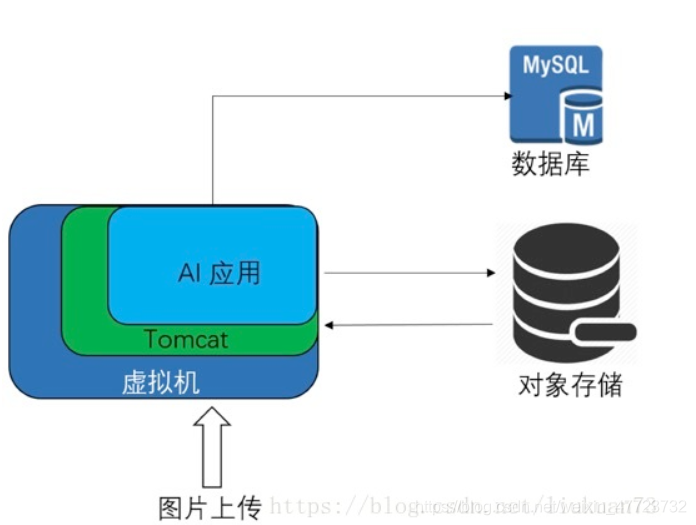
用一個簡單的例子就可講明,我們設計了一個AI應用,可以識別出圖片中人物的人種,我們把它作為一種SaaS服務架設在公共云上提供給客戶使用,其典型的后端架構設計如下:
Serverless 的價值
Serverless 技術為什么會獲得越來越多的關注?我們可以從幾個角度來看,
首先,從開發者使用的來說,不用更多地去考慮服務器的相關內容,無需再去考慮服務器的規格大小、存盤型別、網路帶寬、自動擴縮容問題,同時,也無需再對服務器進行運維,無需不斷打系統補丁、應用補丁,無需進行資料備份、軟體配置等作業,
其次,Serverless 產品是完全自動化的彈性擴縮容的,在業務高峰時,產品的計算能力、容量自動擴容,承載更多的用戶請求,而在業務下降時,所使用的資源也會同時收縮,避免資源浪費,
再次,跟隨著完全自動化的彈性所帶來的,是全新的計量計費模式,開發者僅需根據使用量來付費,而在深夜無業務量的情況下,不會有空閑資源占用,因此也不會有費用產生,
隨著如上提到的特性,Serverless 給開發者或用戶帶來了具體的商業價值:
1. 降低運維需求
- Serverless 使得應用與服務器解耦,業務上線前無需預估資源,無需進行服務器購買、配置
- Serverless 也使得底層運維作業量進一步降低,業務上線后,也無需擔憂服務器運維,而是全部交給了云平臺或云廠商
2. 降低運營成本
- Serverless 的應用是按需執行的,應用只在有請求需要處理或者事件觸發時才會被加載運行,在空閑狀態下 Serverless 架構的應用本身并不占用計算資源
- 在使用 Serverless 產品時,用戶只需要為處理請求的計算資源付費,而無須為應用空閑時段的資源占用付費
3. 縮短迭代周期、上線時間
- Serverless 架構帶來的是進一步的業務解耦,應用功能被解構成若干個細顆粒度的無狀態函式,開發可以聚焦在單功能的快速開發和上線
- 同時拆解后的云函式,也都可以進行獨立的迭代升級,更快速的實作業務迭代,縮減功能的上市時間
4. 快速試錯
- 利用 Serverless 架構的簡單運維、低成本及快速上線能力,可以來快速嘗試業務的新形態、新功能
- 利用 Serverless 產品的強彈性擴容能力,在業務獲得成功時,也無需為資源擴容而擔心
什么是云計算?
云計算是分布式計算的一種,指的是通過網路“云”將巨大的資料計算處理程式分解成無數個小程式,然后,通過多部服務器組成的系統進行處理和分析這些小程式得到結果并回傳給用戶,云計算早期,簡單地說,就是簡單的分布式計算,解決任務分發,并進行計算結果的合并,因而,云計算又稱為網格計算,通過這項技術,可以在很短的時間內(幾秒鐘)完成對數以萬計的資料的處理,從而達到強大的網路服務,
官方的回答讓我們對云計算的理解可能不是特別的明顯,總而言之,在資料種類比較多的環境下,資料量非常大的情況下,云計算就是把單純的資料環境,轉移到云上進行相關操作
近幾年的:華為云,騰訊云,阿里云.......發展的如火如荼,順應時代的需要,必定會有一種全新的發展和質的突破!
現階段所說的云服務已經不單單是一種分布式計算,而是分布式計算、效用計算、負載均衡、并行計算、網路存盤、熱備份冗雜和虛擬化等計算機技識訓合演進并躍升的結果,

云計算的價值
通過“云計算”可將IT資源進行集中化和標準化,這樣就為政府、企事業單位的IT運行環境帶來了無法估量的價值,具體表現在:
1) 通過整合服務器、動態調整資源及虛擬化存盤技術,就可使政府、企事業單位的IT部門用小規模的硬體部署來完成同級別或更高級別的服務,從而大大提升企業的生產力和政府及事業單位的業務價值,同時提升服務器效力,
2) 用“云計算”來構建IT運行環境后,政府、企事業單位的IT運行環境會更加集中簡潔,再加上存盤、網路及服務器的自動化操作,將大幅度減少IT運行時的人為差錯,
3) 通過購買更少的硬體設備及軟體許可,大大降低采購成本,通過自動化管理迅速降低系統管理員的作業負荷,這就意味著降低了政府、企事業單位在IT環境構建時的投入及運維成本,
總之,“云計算”通過技術手段把計算和存盤作為服務加以提供,提供了高附加值的服務;“云計算”打破現有機房的空間局限,在更小的空間內提供了更多的服務能力;“云計算”通過規模效應降低了單位資源的投資及維護成本;同時,“云計算”帶給用戶更好的互動體驗,降低了用戶使用成本,提升了用戶滿意度及忠誠度,

什么是大資料?
大資料,IT行業術語,是指無法在一定時間范圍內用常規軟體工具進行捕捉、管理和處理的資料集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的資訊資產,
在維克托·邁爾-舍恩伯格及肯尼斯·庫克耶撰寫的《大資料時代》 [1] 中大資料指不用隨機分析法(抽樣調查)這樣捷徑,而采用所有資料進行分析處理,大資料的5V特點(IBM提出):Volume(大量)、Velocity(高速)、Variety(多樣)、Value(低價值密度)、Veracity(真實性),
對于“大資料”(Big data)研究機構Gartner給出了這樣的定義,“大資料”是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力來適應海量、高增長率和多樣化的資訊資產,
從技術上看,大資料與云計算的關系就像一枚硬幣的正反面一樣密不可分,大資料必然無法用單臺的計算機進行處理,必須采用分布式架構,它的特色在于對海量資料進行分布式資料挖掘,但它必須依托云計算的分布式處理、分布式資料庫和云存盤、虛擬化技術,
隨著云時代的來臨,大資料(Big data)也吸引了越來越多的關注,分析師團隊認為,大資料(Big data)通常用來形容一個公司創造的大量非結構化資料和半結構化資料,這些資料在下載到關系型資料庫用于分析時會花費過多時間和金錢,大資料分析常和云計算聯系到一起,因為實時的大型資料集分析需要像MapReduce一樣的框架來向數十、數百或甚至數千的電腦分配作業,
對于大資料我們如何理解資料的big:最小的基本單位是bit,按順序給出所有單位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB
它們按照進率1024(2的十次方)來計算:
1 Byte =8 bit
1 KB = 1,024 Bytes = 8192 bit
1 MB = 1,024 KB = 1,048,576 Bytes
1 GB = 1,024 MB = 1,048,576 KB
1 TB = 1,024 GB = 1,048,576 MB
1 PB = 1,024 TB = 1,048,576 GB
1 EB = 1,024 PB = 1,048,576 TB
1 ZB = 1,024 EB = 1,048,576 PB
1 YB = 1,024 ZB = 1,048,576 EB
1 BB = 1,024 YB = 1,048,576 ZB
1 NB = 1,024 BB = 1,048,576 YB
1 DB = 1,024 NB = 1,048,576 BB

大資料的價值
1、對大量消費者提供產品或服務的企業可以利用大資料進行精準營銷,今日頭條正在如此,這是一個精致過后的推廣,精準有效地將供需雙方牽線做聯系,
2、 做小而美模式的中長尾企業可以利用大資料做服務轉型,更好的利用的資料提高服務質量和效率,例如你在瀏覽某個物品時候購物網站已經把你想要的推送至眼前,
3、面臨互聯網壓力之下必須轉型的傳統企業需要與時俱進充分利用大資料的價值,例如很企業已經選擇開設網店和網路服務平臺,
如果說大資料和云計算的聯系,那么我們可以明顯的感受到,在云上的環境足矣讓大資料游刃有余
大資料離不開云處理,云處理為大資料提供了彈性可拓展的基礎設備,是產生大資料的平臺之一,自2013年開始,大資料技術已開始和云計算技術緊密結合,預計未來兩者關系將更為密切,除此之外,物聯網、移動互聯網等新興計算形態,也將一齊助力大資料革命,讓大資料營銷發揮出更大的影響力,
什么是人工智能?
人工智能,英文縮寫為AI,它是研究、開發用于模擬、延伸和擴展人的智能的理論、方法、技術及應用系統的一門新的技術科學,
人工智能是計算機科學的一個分支,它企圖了解智能的實質,并生產出一種新的能以人類智能相似的方式做出反應的智能機器,該領域的研究包括機器人、語言識別、影像識別、自然語言處理和專家系統等,人工智能從誕生以來,理論和技術日益成熟,應用領域也不斷擴大,可以設想,未來人工智能帶來的科技產品,將會是人類智慧的“容器”,人工智能可以對人的意識、思維的資訊程序的模擬,人工智能不是人的智能,但能像人那樣思考、也可能超過人的智能,
人工智能是一門極富挑戰性的科學,從事這項作業的人必須懂得計算機知識,心理學和哲學,人工智能是包括十分廣泛的科學,它由不同的領域組成,如機器學習,計算機視覺等等,總的說來,人工智能研究的一個主要目標是使機器能夠勝任一些通常需要人類智能才能完成的復雜作業,但不同的時代、不同的人對這種“復雜作業”的理解是不同的, 2017年12月,人工智能入選“2017年度中國媒體十大流行語”,
例如繁重的科學和工程計算本來是要人腦來承擔的,如今計算機不但能完成這種計算,而且能夠比人腦做得更快、更準確,因此當代人已不再把這種計算看作是“需要人類智能才能完成的復雜任務”,可見復雜作業的定義是隨著時代的發展和技術的進步而變化的,人工智能這門科學的具體目標也自然隨著時代的變化而發展,它一方面不斷獲得新的進展,另一方面又轉向更有意義、更加困難的目標,
人工智能就是人工+智能結合在一起的組合,但是作為21世紀的發展潮流,人工智能的發展完全可以引領新的時代潮流,

人工智能的價值
人工智能可以運用到很多的領域里面,它的范圍很廣,給我們帶來的福利也是非常之大的,其次人工智能給我們的真正的意義在于它可以給我們創造什么價值,而這種價值我們應該有足夠的的能力和技術可以支配和控制,
好萊塢的電影和科幻小說將AI描繪成占領世界的類人機器人,而AI技術的當前發展并沒有那么可怕,甚至還沒有那么聰明,取而代之的是,人工智能已經發展為在每個行業提供許多特定的利益,繼續閱讀有關醫療保健,零售等方面人工智能的現代示例,

1)AI通過資料實作重復學習和發現的自動化,但是,人工智能不同于硬體驅動的機器人自動化,AI不是自動執行手動任務,而是可靠,無疲勞地執行頻繁,大量的計算機化任務,對于這種型別的自動化,人工詢問對于設定系統并提出正確的問題仍然至關重要,

2)人工智能為現有產品增加了智能,在大多數情況下,不會將AI單獨出售,而是,您已經使用的產品將通過AI功能得到改善,就像將Siri作為新一代Apple產品的功能添加一樣,自動化,對話平臺,機器人和智能機可以與大量資料結合使用,以改善從安全智能到投資分析的各種家庭和作業場所技術,
3)AI通過漸進式學習演算法進行調整,以使資料進行編程,人工智能發現資料的結構和規律性,從而使該演算法獲得技能:該演算法成為分類器或預測器,因此,就像該演算法可以教自己如何下棋一樣,它可以教自己下一個在線推薦什么產品,當給定新資料時,模型會適應,反向傳播是一種AI技術,允許在第一個答案不太正確時通過訓練和添加資料來調整模型,

4)AI使用具有許多隱藏層的神經網路分析更多和更深的資料,幾年前幾乎不可能構建具有五個隱藏層的欺詐檢測系統,不可思議的計算機功能和大資料改變了這一切,您需要大量資料來訓練深度學習模型,因為它們直接從資料中學習,您可以提供的資料越多,它們變得越準確,
5)人工智能通過深度神經網路實作了令人難以置信的準確性,這在以前是不可能的,例如,Alexa,百度搜索和百度相冊的互動都是基于深度學習的,并且隨著我們使用它們的不斷增加,它們將變得越來越準確,在醫學領域,來自深度學習,影像分類和物件識別的AI技術現在可以用于以與訓練有素的放射科醫生相同的準確性在MRI上發現癌癥,

6)AI充分利用資料,當演算法是自學時,資料本身可以成為知識產權,答案在資料中,您只需要應用AI即可將其淘汰,由于資料的作用現在比以往任何時候都重要,因此可以創造競爭優勢,如果您在競爭激烈的行業中擁有最好的資料,即使每個人都在應用類似的技術,那么最好的資料也會取勝,
云計算、大資料、人工智能三劍合一
相遇(時代的需要,讓你們互相認識)
21世紀,每一天都在變化,每一秒都在產生奇跡,時代需要發展,那么技術必定需要革新,
隨著互聯網的興起和發展,資料的產生讓我們對價值的認識,有了更加深刻的領會,我們每一天都在產生海量的資料,而作為這些資料存盤地址,我們需要環境來收納,一般的傳統資料庫已經無法滿足大資料時代的需求了,在此環境下,云的概念產生了,云計算的概念也產生了,大資料讓云計算有了更好的發展,而云計算給了大資料更好的環境,之后我們需要對資料進行價值提取,如果只是單純的資料挖掘和分析,就失去大資料的特性了,在這個時候機器學習和智能模型演算法應運而生,人工智能的概念也隨之提出,大資料的資料之源為人工智能的學習提供最初的保障,而云計算加速了人工智能的發展,

大資料是人工智能的基石,目前的深度學習主要是建立在大資料的基礎上,即對大資料進行訓練,并從中歸納出可以被計算機運用在類似資料上的知識或規律,
雖然很多人將其定義為“大資料就是大規模的資料”,但是,這個說法并不準確!“大規模”只是指資料的量而言!資料量大,并不代表著資料一定有可以被深度學習演算法利用的價值!
所以針對資料量,我們如果只是單純的探索資料的大小,大資料的價值就失去原本的價值了,這背后還需要一個有力的紐扣來支撐,那就是人工智能,大資料為人工智能提供了資料的支持和背景的訓練,利用各種的演算法和機器學習,來訓練模型,按照資料的大規律來采集我們人類的資訊最終達到學習的效果,這個就是人工智能最核心的一部分,
云計算是大資料的寶塔之地,人工智能背后強大的助推器:云計算,人工智能也好、大資料也好、云計算也好,彼此依附相互助力,藕不斷絲且相連!
Serverless助推了云計算的發展,開啟了新時代的資料之門與演算法之門的奧秘,為我們的時代創新,帶來了無限的可能性!后三者合力搭檔在一起,組合拳出擊才更有力量,才能給未來多一些可能,給未知多一些可能性,給不可能多一些可能!
每文一語
永遠不要被現實所打敗,你想要的一定要靠自己,加油!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282251.html
標籤:AI