hadoop 分布式檔案系統的部署
- 1. hadoop 檔案系統的簡介
- 2. 虛擬集群的搭建
- 2.1 單機模式
- 2.2 偽分布式
- 2.3 完全分布式檔案系統
1. hadoop 檔案系統的簡介
Hadoop是一個由Apache基金會所開發的分布式系統基礎架構,用戶可以在不了解分布式底層細節的情況下,開發分布式程式,充分利用集群的威力進行高速運算和存盤,Hadoop實作了一個分布式檔案系統( Distributed File System),其中一個組件是HDFS,HDFS有高容錯性的特點,并且設計用來部署在低廉的(low-cost)硬體上;而且它提供高吞吐量(high throughput)來訪問應用程式的資料,適合那些有著超大資料集(large data set)的應用程式,HDFS放寬了(relax)POSIX的要求,可以以流的形式訪問(streaming access)檔案系統中的資料,Hadoop的框架最核心的設計就是:HDFS和MapReduce,HDFS為海量的資料提供了存盤,而MapReduce則為海量的資料提供了計算,
-
Hadoop的框架最核心的設計就是:HDFS和MapReduce
HDFS為海量的資料提供了存盤,
MapReduce為海量的資料提供了計算, -
Hadoop框架包括以下四個模塊:
Hadoop Common: 這些是其他Hadoop模塊所需的Java庫和實用程式,這些庫提供檔案系統和作業系統級抽象,并包含啟動Hadoop所需的Java檔案和腳本,
Hadoop YARN: 這是一個用于作業調度和集群資源管理的框架,
Hadoop Distributed File System (HDFS): 分布式檔案系統,提供對應用程式資料的高吞吐量訪問,
Hadoop MapReduce:這是基于YARN的用于并行處理大資料集的系統,
優點
Hadoop是一個能夠對大量資料進行分布式處理的軟體框架, Hadoop 以一種可靠、高效、可伸縮的方式進行資料處理 ,
Hadoop 是可靠的,因為它假設計算元素和存盤會失敗,因此它維護多個作業資料副本,確保能夠針對失敗的節點重新分布處理 ,
Hadoop 是高效的,因為它以并行的方式作業,通過并行處理加快處理速度 ,
Hadoop 還是可伸縮的,能夠處理 PB 級資料 ,
此外,Hadoop 依賴于社區服務,因此它的成本比較低,任何人都可以使用 ,
Hadoop是一個能夠讓用戶輕松架構和使用的分布式計算平臺,用戶可以輕松地在Hadoop上開發和運行處理海量資料的應用程式,它主要有以下幾個優點
- 高可靠性,Hadoop按位存盤和處理資料的能力值得人們信賴,
- 高擴展性,Hadoop是在可用的計算機集簇間分配資料并完成計算任務的,這些集簇可以方便地擴展到數以千計的節點中 ,
- 高效性,Hadoop能夠在節點之間動態地移動資料,并保證各個節點的動態平衡,因此處理速度非常快 ,
- 高容錯性,Hadoop能夠自動保存資料的多個副本,并且能夠自動將失敗的任務重新分配 ,
- 低成本,與一體機、商用資料倉庫以及QlikView、Yonghong Z-Suite等資料集市相比,hadoop是開源的,專案的軟體成本因此會大大降低 ,
Hadoop帶有用Java語言撰寫的框架,因此運行在 Linux 生產平臺上是非常理想的,Hadoop 上的應用程式也可以使用其他語言撰寫,比如 C++ ,
Hadoop 由許多元素構成,其最底部是 Hadoop Distributed File System(HDFS),它存盤 Hadoop 集群中所有存盤節點上的檔案,HDFS的上一層是MapReduce 引擎,該引擎由 JobTrackers 和 TaskTrackers 組成,通過對Hadoop分布式計算平臺最核心的分布式檔案系統HDFS、MapReduce處理程序,以及資料倉庫工具Hive和分布式資料庫Hbase的介紹,基本涵蓋了Hadoop分布式平臺的所有技術核心,
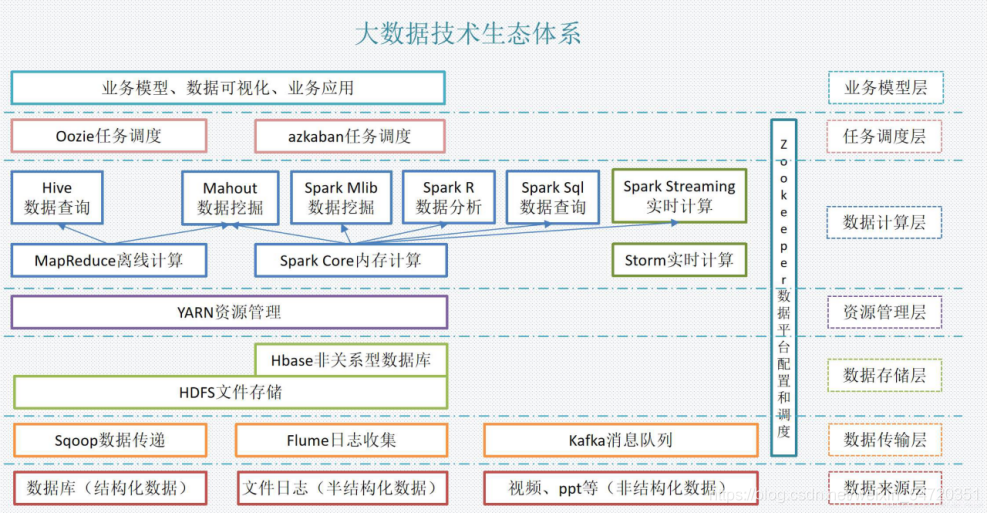
HDFS屬于Master與Slave結構,一個集群中只有一個NameNode,可以有多個DataNode,
HDFS存盤機制保存了多個副本,當寫入1T檔案時,我們需要3T的存盤,3T的網路流量帶寬;系統提供容錯機制,副本丟失或宕機可自動恢復,保證系統高可用性,
HDFS默認會將檔案分割成block,然后將block按鍵值對存盤在HDFS上,并將鍵值對的映射存到記憶體中,如果小檔案太多,會導致記憶體的負擔很重,
HDFS采用的是一次寫入多次讀取的檔案訪問模型,一個檔案經過創建、寫入和關閉之后就不需要改變,這一假設簡化了資料一致性問題,并且使高吞吐量的資料訪問成為可能,
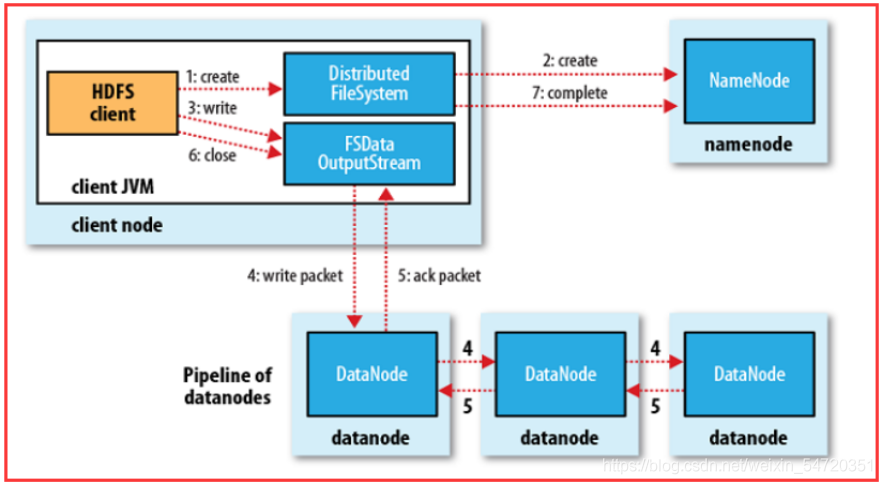
HDFS存盤理念是以最少的錢買最爛的機器并實作最安全、難度高的分布式檔案系統(高容錯性低成本),HDFS認為機器故障是種常態,所以在設計時充分考慮到單個機器故障,單個磁盤故障,單個檔案丟失等情況,
HDFS容錯機制:
節點失敗監測機制:DN每隔3秒向NN發送心跳信號,10分鐘收不到,認為DN宕機,
通信故障監測機制:只要發送了資料,接收方就會回傳確認碼,
資料錯誤監測機制:在傳輸資料時,同時會發送總和校驗碼,
2. 虛擬集群的搭建
官網 https://hadoop.apache.org/ 此處下載的是 3.2.1 的版本;
(1)創建用戶 hadoop ,給創建的用戶設定密碼;
[root@server5 ~]# useradd hadoop
##新建用戶,以普通用戶的身份去搭建 hadoop 平臺
[root@server5 ~]# echo westos | passwd --stdin hadoop
Changing password for user hadoop.
passwd: all authentication tokens updated successfully.
(2)搭建平臺
解壓 jdk 的包,并做一個軟鏈接,方便后面做升級;
[root@server5 ~]# su - hadoop
[hadoop@server5 ~]$ ls
hadoop-3.2.1.tar.gz jdk-8u181-linux-x64.tar.gz
[hadoop@server5 ~]$ tar zxf jdk-8u181-linux-x64.tar.gz
[hadoop@server5 ~]$ ls
hadoop-3.2.1.tar.gz jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
[hadoop@server5 ~]$ ln -s jdk1.8.0_181 java ##軟連接,以后升級做更改軟連接即可
[hadoop@server5 ~]$ ls
hadoop-3.2.1.tar.gz java jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
[hadoop@server5 ~]$ ll
total 532076
-rw-r--r-- 1 root root 359196911 Apr 24 10:02 hadoop-3.2.1.tar.gz
lrwxrwxrwx 1 hadoop hadoop 12 Apr 24 10:02 java -> jdk1.8.0_181
drwxr-xr-x 7 hadoop hadoop 245 Jul 7 2018 jdk1.8.0_181
-rw-r--r-- 1 root root 185646832 Apr 24 10:02 jdk-8u181-linux-x64.tar.gz
解壓 hadoop 的包,并做一個軟鏈接,方便后面做升級;
[hadoop@server5 ~]$ tar zxf hadoop-3.2.1.tar.gz
[hadoop@server5 ~]$ ls
hadoop-3.2.1 hadoop-3.2.1.tar.gz java jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
[hadoop@server5 ~]$ ln -s hadoop-3.2.1 hadoop
[hadoop@server5 ~]$ ls
hadoop hadoop-3.2.1 hadoop-3.2.1.tar.gz java jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
修改組態檔
[hadoop@server5 ~]$ cd hadoop
[hadoop@server5 hadoop]$ ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[hadoop@server5 hadoop]$ cd etc/hadoop/
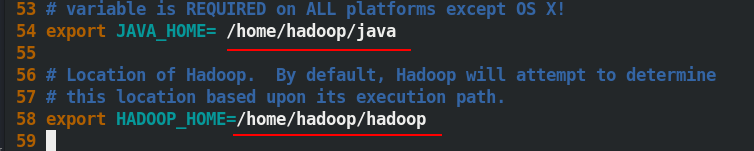
[hadoop@server5 hadoop]$ vim hadoop-env.sh ##編輯環境腳本
配置 hadoop-env.sh 檔案內容如圖所示:
2.1 單機模式
安裝單機模式的Hadoop無需配置,在這種方式下,Hadoop被認為是一個單獨的Java行程,這種方式經常被用來除錯
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hadoop
##檢驗環境,寫入檔案中的路徑是否正確
[hadoop@server5 hadoop]$ mkdir input ##新建目錄
[hadoop@server5 hadoop]$ cp etc/hadoop/*.xml input/ ##匯入測驗檔案
[hadoop@server5 hadoop]$ ls input/
capacity-scheduler.xml hadoop-policy.xml httpfs-site.xml kms-site.xml yarn-site.xml
core-site.xml hdfs-site.xml kms-acls.xml mapred-site.xml
[hadoop@server5 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar ##查看可以做那些計算
[hadoop@server5 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
##運算,此時 output 目錄不能存在,如果存在就會報錯
此時很快,因為資料比較小,小資料量不建議用 hadoop ,小資料會浪費時間在網路等因素上,
[hadoop@server5 hadoop]$ cd output/
##完成之后會生成該目錄
[hadoop@server5 output]$ ls
part-r-00000 _SUCCESS
[hadoop@server5 output]$ cat * ##查看檔案內容
1 dfsadmin
運行 Hadoop 自帶演算法 grep ,運行結束后匹配統計結果已經被寫入了HDFS 的 output 目錄下,output目錄會被自動建立,
2.2 偽分布式
偽分布式 Hadoop 配置可以把偽分布式的 Hadoop 視為只有一個節點的集群;在這個集群中,這個節點既是 Master,又是 Slave;既是NameNode,又是DataNode;既是JobTracker,又是TaskTracker,
- 修改組態檔
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server5 hadoop]$ vim core-site.xml
[hadoop@server5 hadoop]$ vim hdfs-site.xml
修改組態檔 core-site.xml 內容如下圖所示:
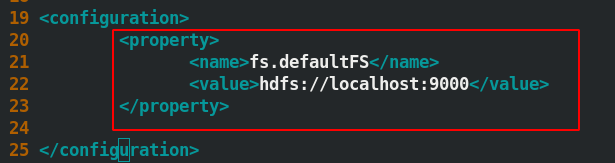
修改組態檔 hdfs-site.xml內容如下圖所示:
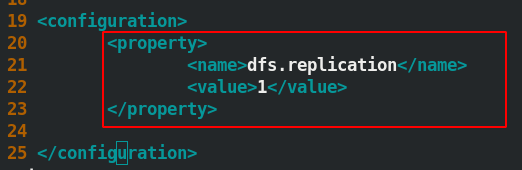
- 做免密認證:
[hadoop@server5 ~]$ ssh-keygen
[hadoop@server5 ~]$ ssh-copy-id localhost
[hadoop@server5 ~]$ cd hadoop/etc/hadoop/
[hadoop@server5 hadoop]$ ll workers ##這個里面默認定義的是存盤結點(node)
-rw-r--r-- 1 hadoop hadoop 10 Sep 10 2019 workers
[hadoop@server5 hadoop]$ cat workers
localhost
[hadoop@server5 hadoop]$ ssh localhost ##測驗面密是否成功
Last login: Sat Apr 24 10:40:22 2021
[hadoop@server5 ~]$ exit
logout
Connection to localhost closed.
- 格式化,然后啟動
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hdfs namenode -format ##格式化,默認的資料目錄在/tmp
[hadoop@server5 hadoop]$ id
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
[hadoop@server5 hadoop]$ ls /tmp/
hadoop hadoop-hadoop hadoop-hadoop-namenode.pid hsperfdata_hadoop
[hadoop@server5 hadoop]$ sbin/start-dfs.sh ##啟動
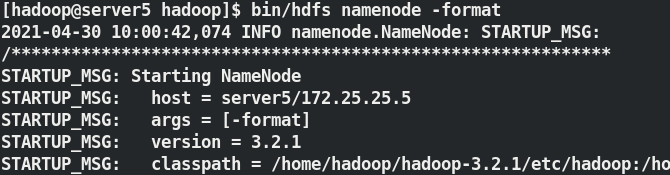
格式化完成之后的效果如圖所示,此時在 /tmp/ 中會生成 Hadoop 的資料 ;

啟動之后便可以看到其埠等資訊;

- 寫入環境變數
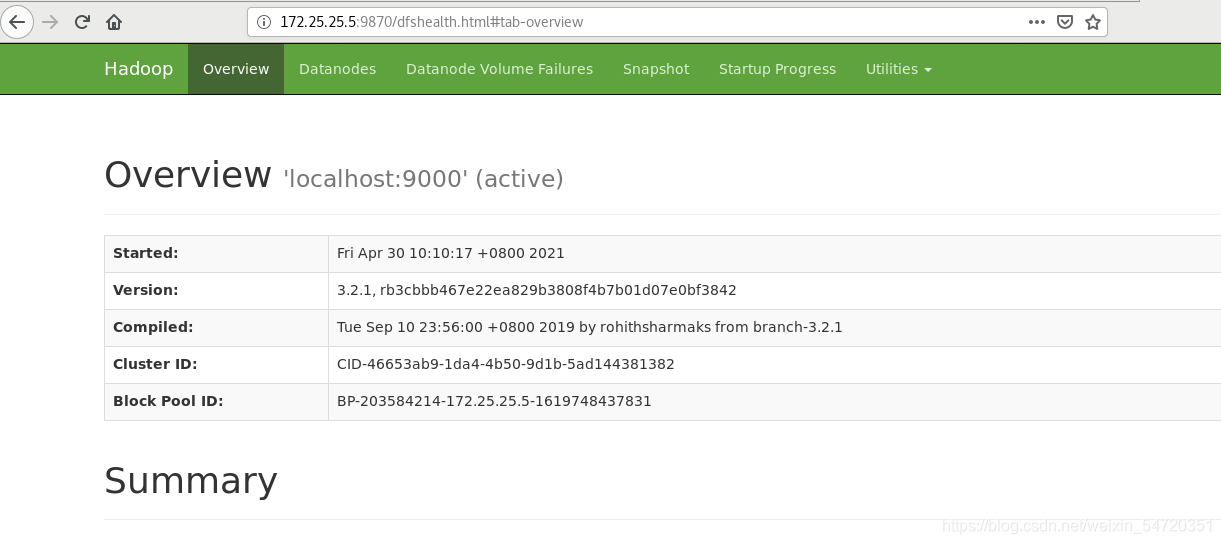
用命令 jps 可以查看到 Hadoop 是否啟動成功;啟動成功之后當前主機既是 NameNode,又是 DataNode;9000 埠也成功打開;
[hadoop@server5 hadoop]$ cd
[hadoop@server5 ~]$ vim .bash_profile
[hadoop@server5 ~]$ source .bash_profile
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$HOME/java/bin ##寫入決議的目的是為了查看行程方便
[hadoop@server5 ~]$ jps
5234 Jps
4870 DataNode
4763 NameNode
5054 SecondaryNameNode
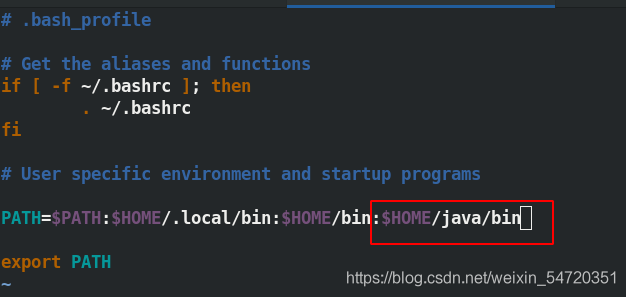
此時查過埠號之后,便可以在網頁加埠號訪問172.25.25.5:9870;
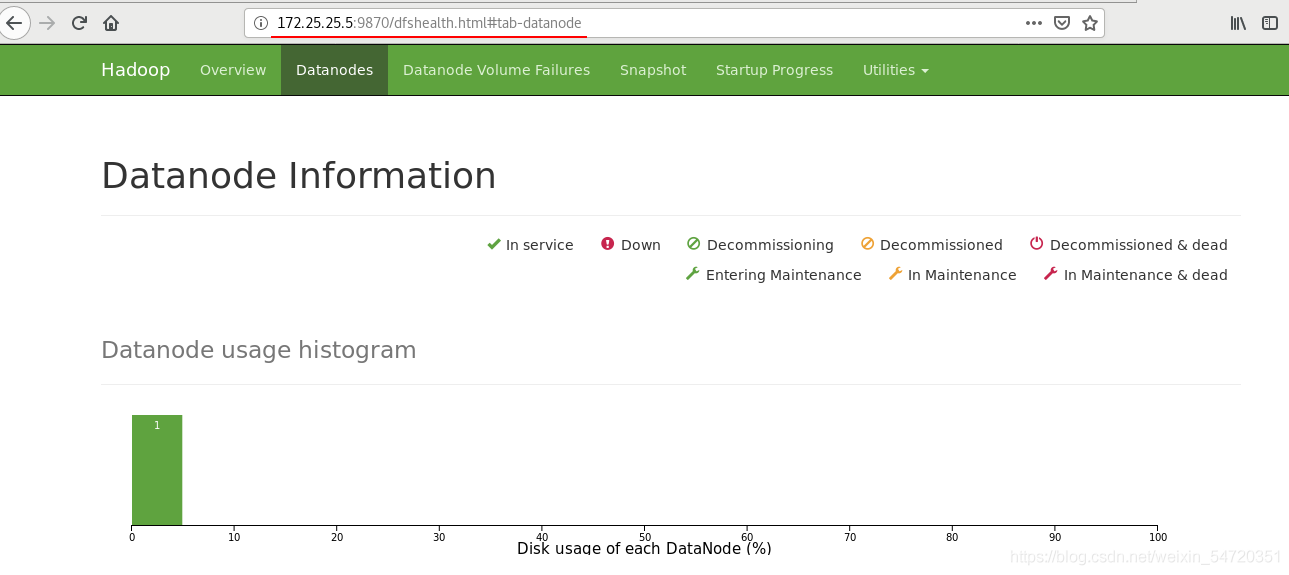
- Hadoop 基本命令及測驗
hadoop 中默認的塊是 128M
(1)上傳
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls ##列出用戶的根目錄
ls: `.': No such file or directory
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir /user
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop ##創建以自己用戶名稱的目錄
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls ##此時沒有報錯
[hadoop@server5 hadoop]$ rm -fr output/
[hadoop@server5 hadoop]$ ls
bin etc include input lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share
[hadoop@server5 hadoop]$ bin/hdfs dfs -put input ##上傳
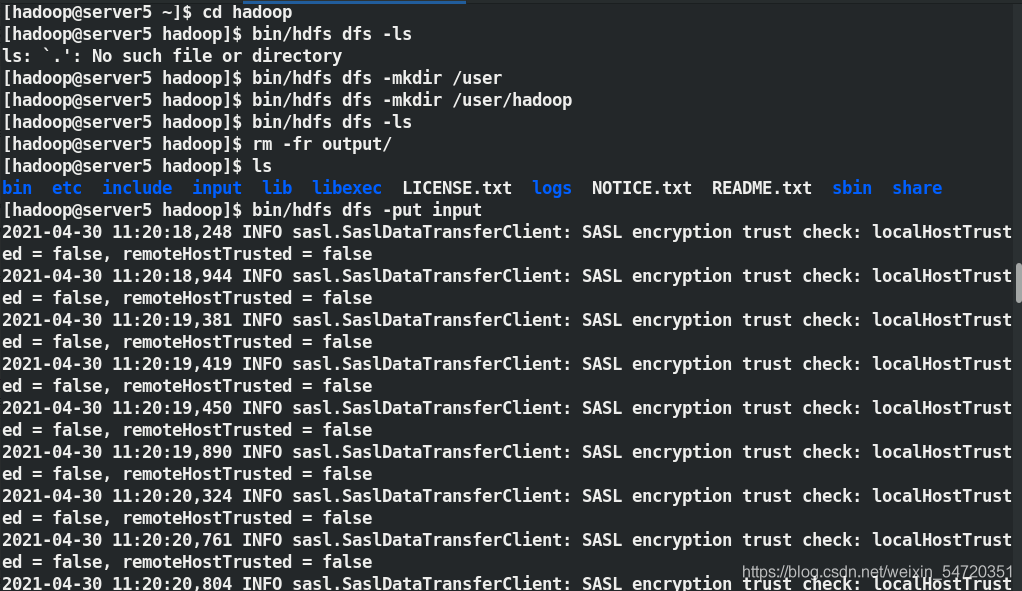
此時再次訪問網頁時便可看到上傳到分布式檔案系統的資訊:
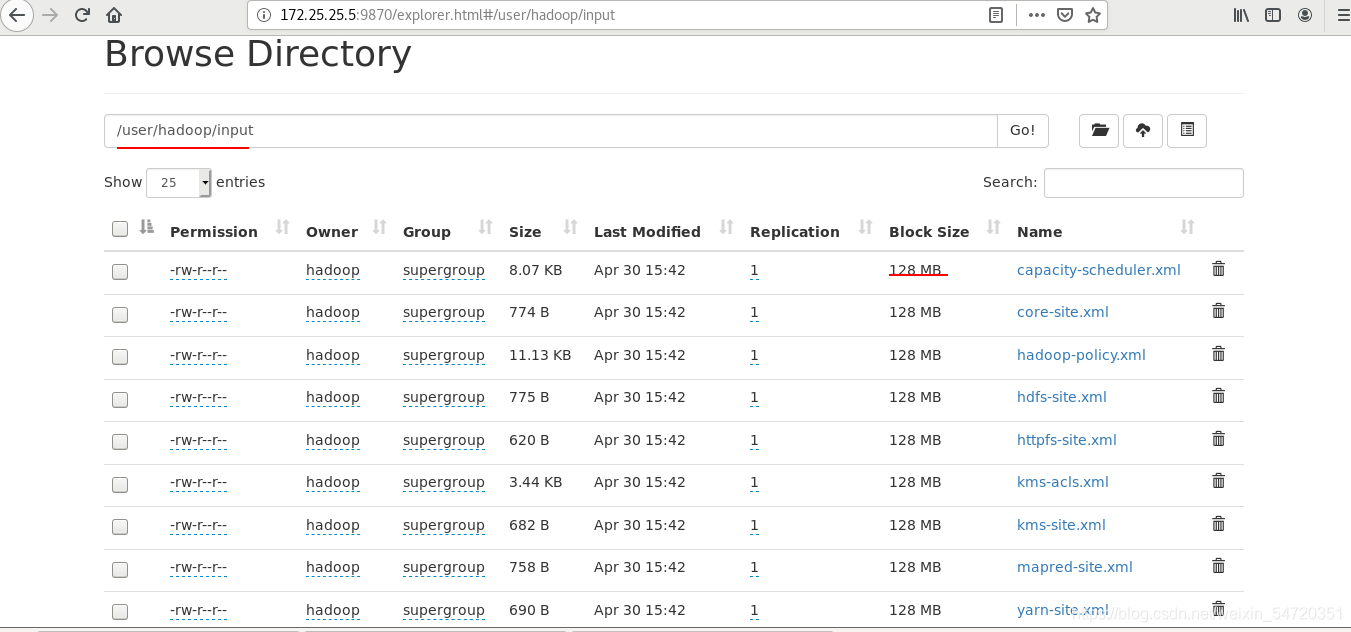
(2)下載
當分布式檔案系統存在時,此時下載時時從分布式檔案系統中獲得的;此處洗掉本地的 input 目錄來觀察實驗效果;
當洗掉本地的 input 目錄之后,此時通過網頁查看 Hadoop 內的資源,發現input目錄依舊存在,
這里再次運行 Hadoop 自帶演算法 wordcount 來過濾單詞;
運行結束后詞頻統計結果已經被寫入了HDFS 的 output 目錄下;
[hadoop@server5 hadoop]$ rm -fr input/
[hadoop@server5 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output
##用計算來統計數量,此時input目錄不在會在分布式檔案系統中去找,output 目錄不能存在,output 也會在分布式檔案系統中出現
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2021-04-30 11:20 input
drwxr-xr-x - hadoop supergroup 0 2021-04-30 11:22 output
注: hadoop 要求系統的結點時間要一致.
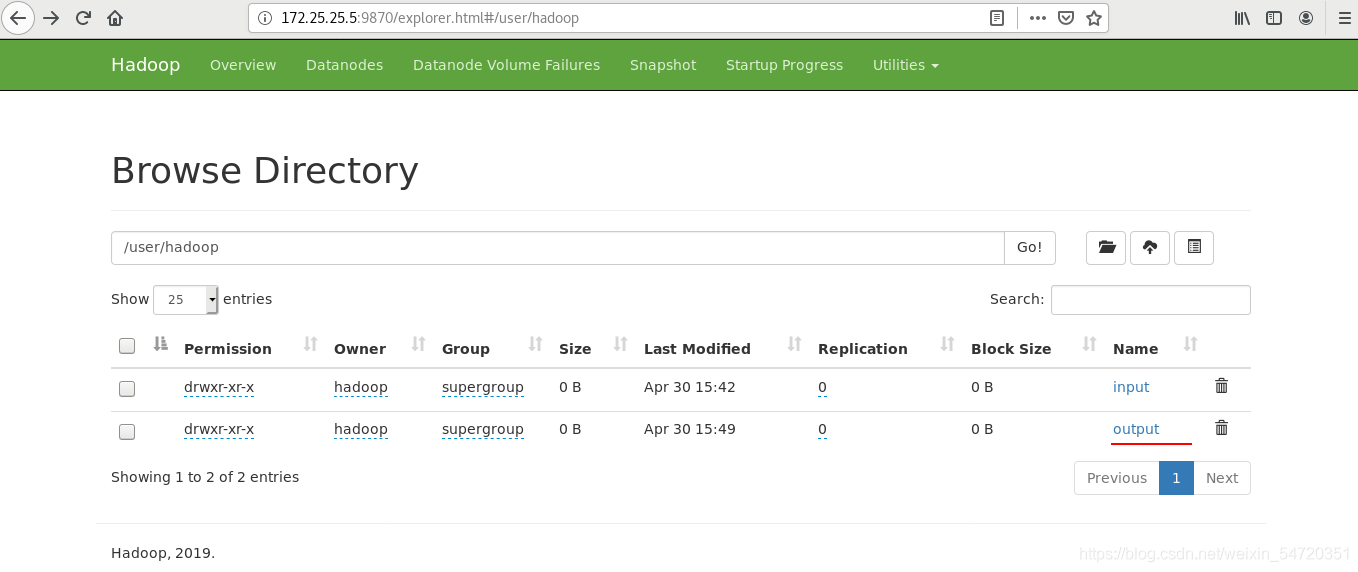
執行命令 bin/hdfs dfs -cat output/*查看詞頻統計結果;
執行命令 bin/hdfs dfs -get output下載資料;
[hadoop@server1 hadoop]$ bin/hdfs dfs -cat output/*
[hadoop@server1 hadoop]$ bin/hdfs dfs -get output ##下載
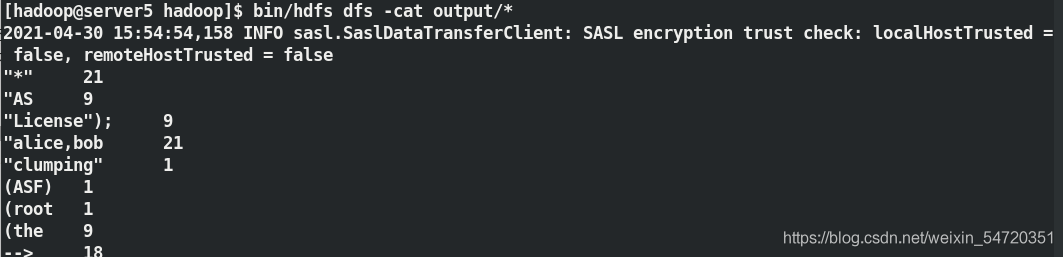

以上的集中方式,不管是網頁查看,還是命令列的查看還是下載到本地檔案系統,都是巍峨了查看檔案內容;
分布式檔案系統分塊的意義是為了快速定位,
(3)洗掉
[hadoop@server1 hadoop]$ cd output/
[hadoop@server1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@server1 hadoop]$ rm -fr output/*
[hadoop@server1 hadoop]$ bin/hdfs dfs -rm -r output
Deleted output
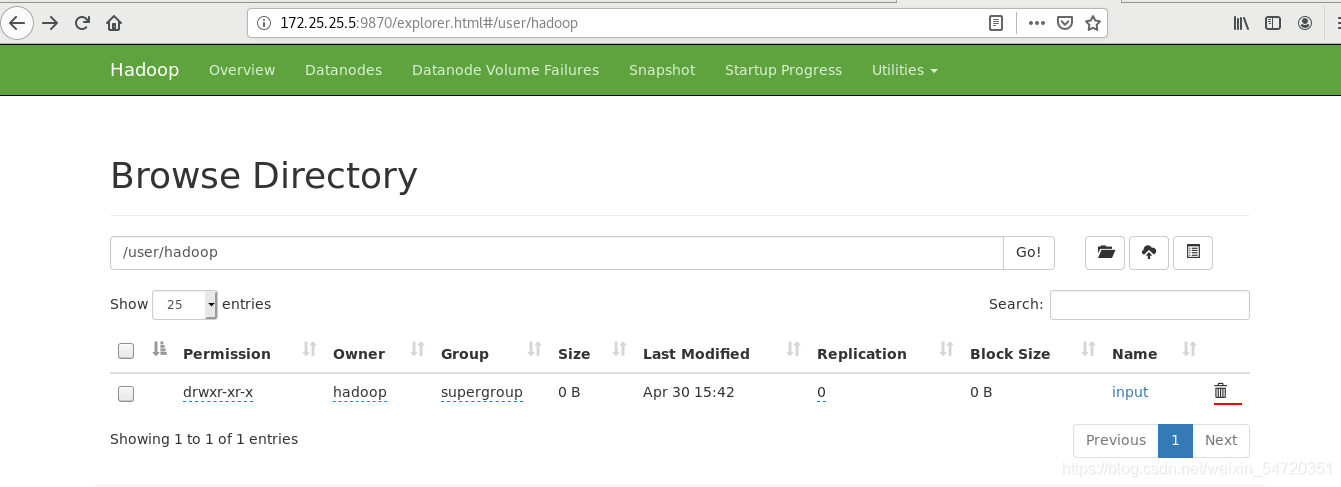
從網頁也可以洗掉,但是默認是沒有權限的,
2.3 完全分布式檔案系統
Hadoop 的組態檔分為2類:
-
只讀型別的默認檔案:
src/core/core-default.xml、src/hdfs/hdfs-default.xml、src/mapred/mapred-default.xml -
定位設定:
etc/hadoop/core-default.xml、etc/hadoop/hdfs-default.xml、etc/hadoop/mapred-default.xml -
除此之外,也可以通過設定
conf/Hadoop-env.sh來為Hadoop的守護行程設定環境變數(在bin目錄中)在Hadoop的設定中,Hadoop的配置是通過資源定位的,每個資源由一系列name/value對以XML檔案的形式構成,它以一個字串命名或者是以Hadoop定義的Path類命名
集群中至少有三臺主機來觀察實驗效果;
前面的操作方法和第一臺雷同,新建用戶,設定密碼,寫入決議,
此時,將 server5 作為NameNode,server6和server7作為DataNode.
(1)新建用戶
[root@server6 ~]# useradd hadoop
[root@server6 ~]# echo westos | passwd --stdin hadoop
Changing password for user hadoop.
passwd: all authentication tokens updated successfully.
[root@server7 ~]# useradd hadoop
[root@server7 ~]# echo westos | passwd --stdin hadoop
Changing password for user hadoop.
passwd: all authentication tokens updated successfully.
(2)關閉之前偽分布檔案系統開啟的行程
[hadoop@server5 hadoop]$ ls
bin etc include input lib libexec LICENSE.txt logs NOTICE.txt output README.txt sbin share
[hadoop@server5 hadoop]$ sbin/stop-dfs.sh

(3)為了保證全平臺資料一致性,此處在每臺主機上安裝 nfs ;
[root@server5 ~]# yum install -y nfs-utils.x86_64
[root@server6 ~]# yum install -y nfs-utils.x86_64
[root@server7 ~]# yum install -y nfs-utils.x86_64
在第一個用戶上進行掛載需要寫組態檔,將 /home/hadoop 目錄共享出去;
[root@server5 ~]# vim /etc/exports
[root@server5 ~]# cat /etc/exports
/home/hadoop *(rw,anonuid=1000,anongid=1000)
[root@server5 ~]# systemctl start nfs
[root@server5 ~]# showmount -e
Export list for server5:
/home/hadoop *

在其他結點上也將其掛載:
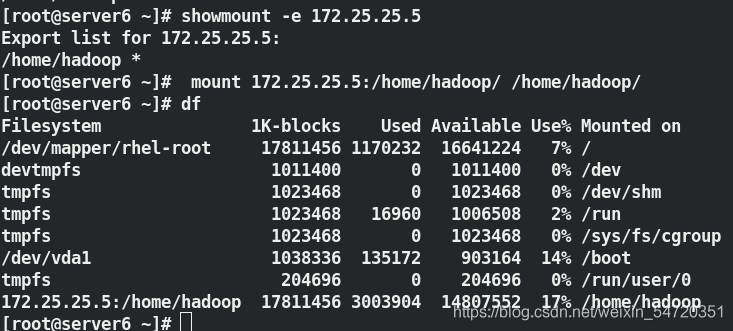
[root@server6 ~]# showmount -e 172.25.25.5
Export list for 172.25.25.5:
/home/hadoop *
[root@server6 ~]# mount 172.25.25.5:/home/hadoop/ /home/hadoop/
[root@server6 ~]# su - hadoop
[hadoop@server6 ~]$ ls
hadoop hadoop-3.2.1 hadoop-3.2.1.tar.gz java jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
[root@server7 ~]# showmount -e 172.25.25.5
Export list for 172.25.25.5:
/home/hadoop *
[root@server7 ~]# mount 172.25.25.5:/home/hadoop/ /home/hadoop/
[root@server7 ~]# su - hadoop
[hadoop@server7 ~]$ ls
hadoop hadoop-3.2.1 hadoop-3.2.1.tar.gz java jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
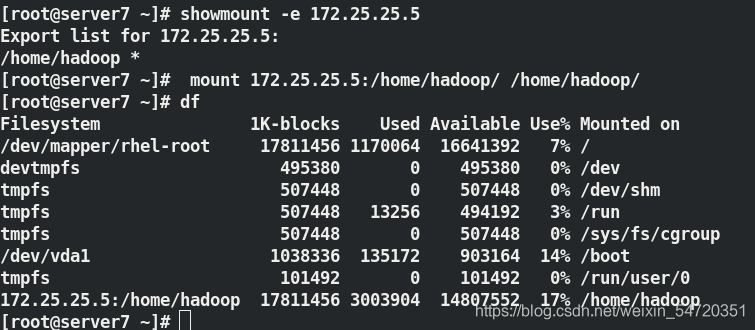
此時免密也已經自動好了; DataNode 掛載了server5 的/home/hadoop;在掛載的目錄中就包含有 SSH 的公鑰;只需要進行免密的驗證即可
(4) Hadoop 集群的配置
- 配置Hadoop核心的組態檔
[hadoop@server5 hadoop]$ vim workers ##告訴 server6 和 server7 是 datanode
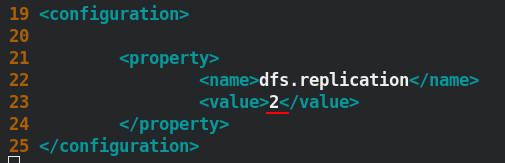
[hadoop@server5 hadoop]$ vim hdfs-site.xml ##此時有兩個結點
[hadoop@server1 hadoop]$ vim core-site.xml ##決議檔案中的域名
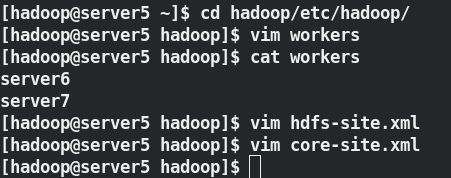
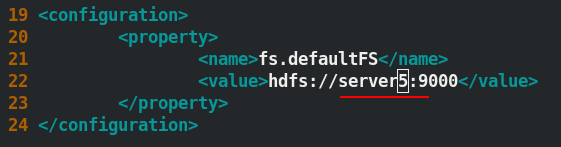
- 格式化
洗掉之前偽分布式操作留下的臨時資料,然后格式化再啟動;
[hadoop@server5 hadoop]$ rm -fr /tmp/*
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hdfs namenode -format
[hadoop@server5 hadoop]$ sbin/start-dfs.sh
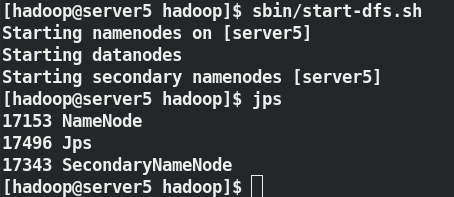
啟動之后在另外兩個結點即可看到對應的資訊;
[hadoop@server6 ~]$ jps
4032 Jps
3965 DataNode
[hadoop@server7 ~]$ jps
3905 DataNode
3966 Jps
此時檔案系統就已經搭建完畢,
接下來做測驗:
- 生成一個檔案
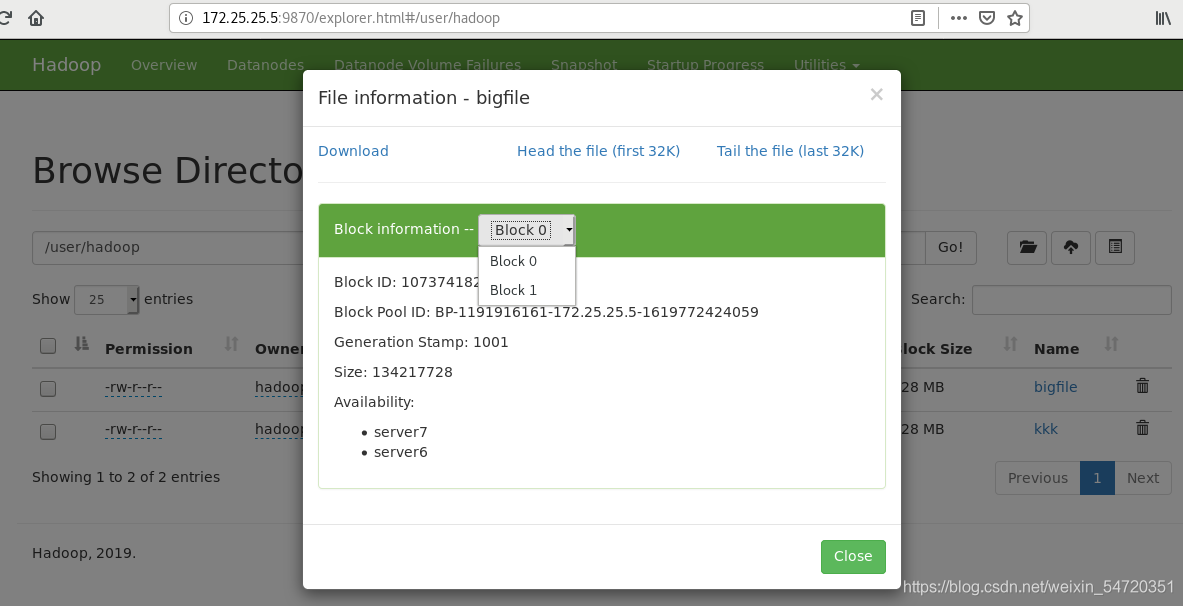
生成一個200M的檔案;該檔案大于128M時會被分割成兩個block;
[hadoop@server5 hadoop]$ dd if=/dev/zero of=bigfile bs=1M count=200
200+0 records in
200+0 records out
209715200 bytes (210 MB) copied, 0.139584 s, 1.5 GB/s
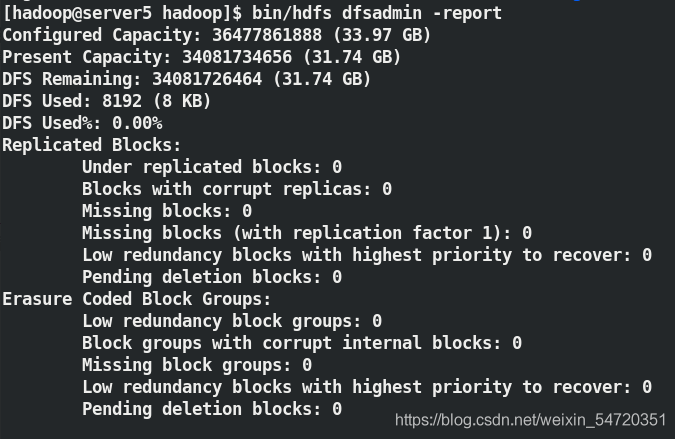
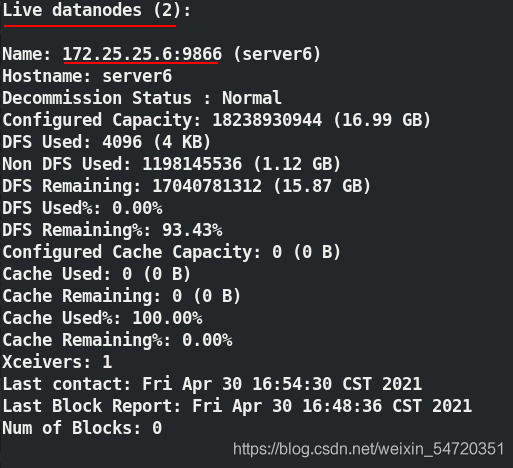
[hadoop@server5 hadoop]$ bin/hdfs dfsadmin -report ##查看報告
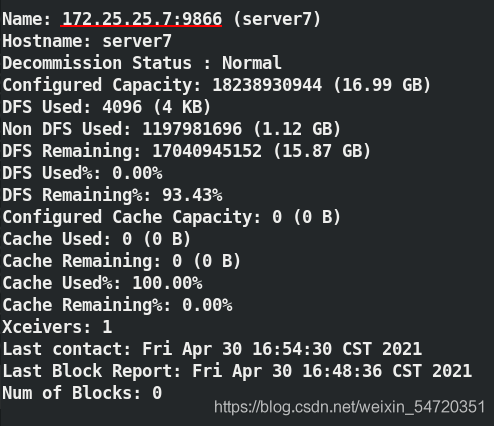
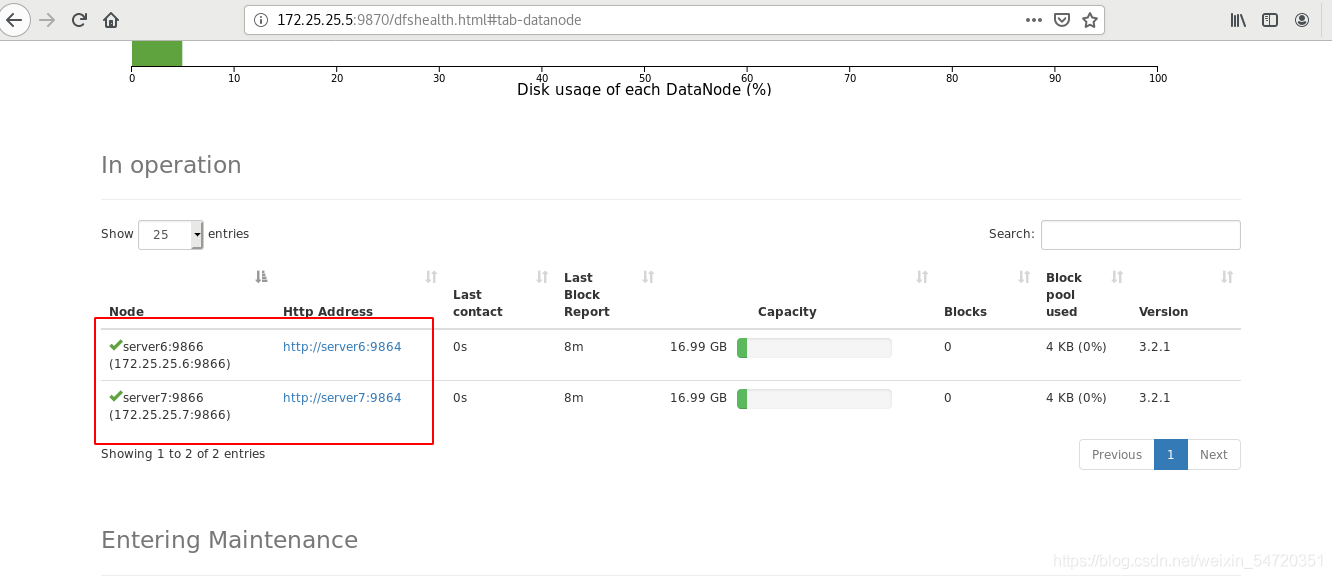
也可以在網頁中通過圖形的方式來查看:
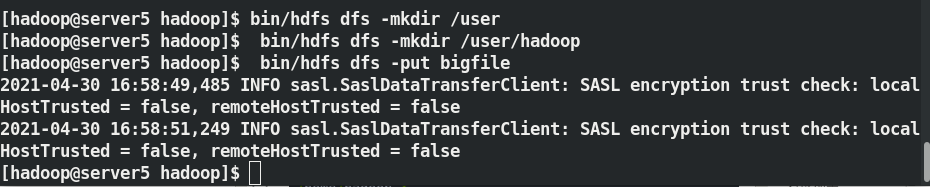
- 上傳
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir /user
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server5 hadoop]$ bin/hdfs dfs -put bigfile
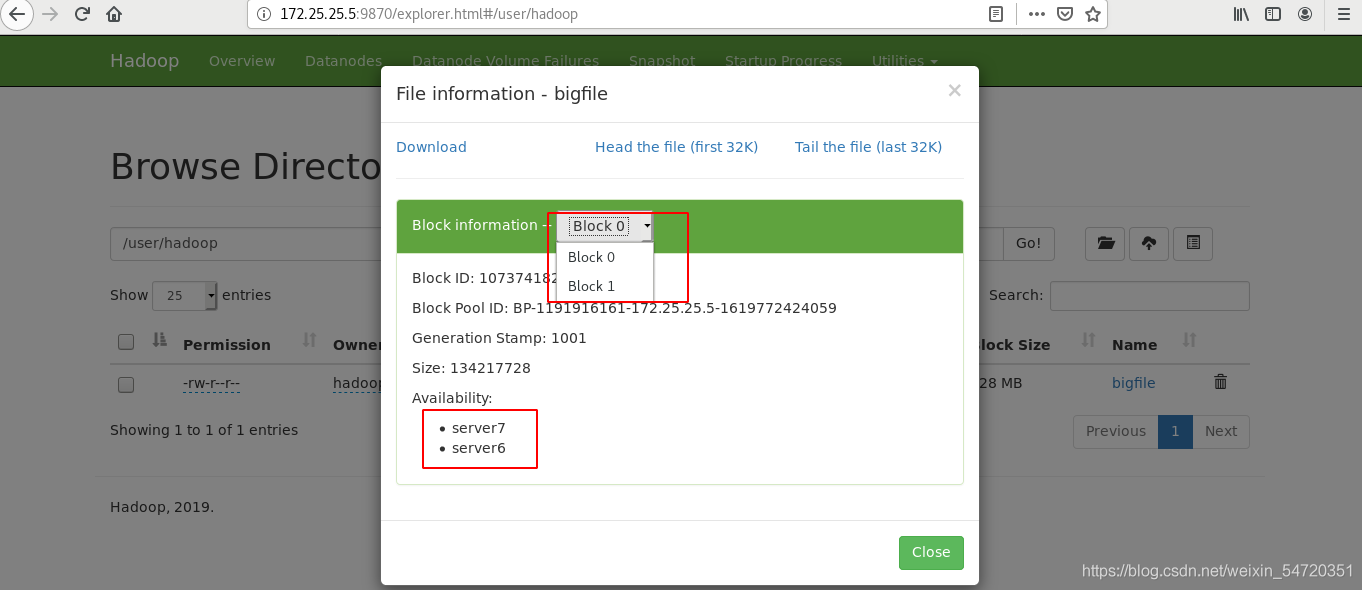
此時訪問網頁,發現存了2份,在兩個節點上;
(5)熱添加
再新建一個 server8 用來實作熱更改.
和之前一樣要下載 nfs ,寫入決議,創建用戶和密碼;
[root@server8 ~]# yum install nfs-utils.x86_64 -y
[root@server8 ~]# vim /etc/hosts
[root@server8 ~]# useradd hadoop
[root@server8 ~]# echo westos | passwd --stdin hadoop
[root@server8 ~]# showmount -e 172.25.25.5
[root@server8 ~]# mount 172.25.25.5:/home/hadoop/ /home/hadoop/
[root@server8 ~]# su - hadoop
[hadoop@server8 ~]$ ls
hadoop hadoop-3.2.1 hadoop-3.2.1.tar.gz java jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
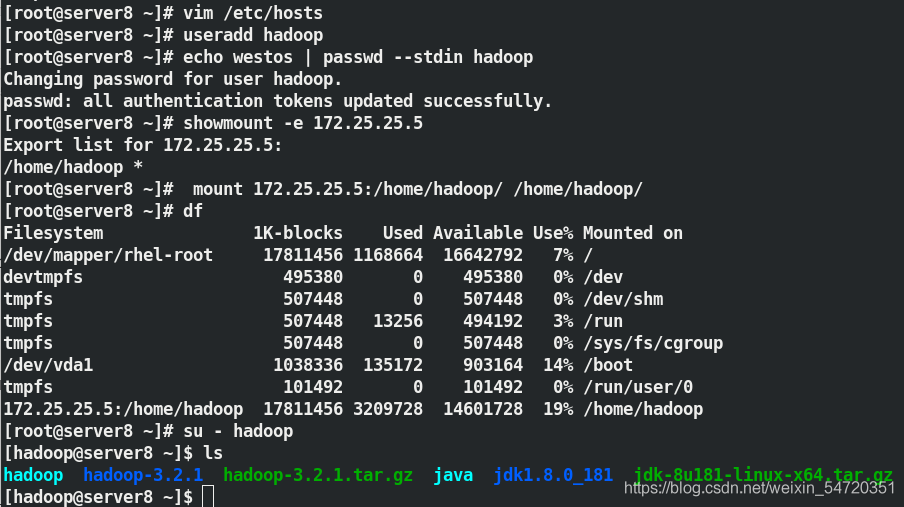
完成之后,此時需要編輯組態檔來實作熱添加;新添加的 server8 作為 DataNode 要寫入 workers 檔案中;
[hadoop@server8 ~]$ cd hadoop
[hadoop@server8 hadoop]$ jps ##此時沒改檔案,可以看到沒有添加上去
13648 Jps
[hadoop@server8 hadoop]$ vim workers
[hadoop@server8 hadoop]$ cat workers
server6
server7
server8
[hadoop@server8 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server8 hadoop]$ bin/hdfs --daemon start datanode ##啟動集群
[hadoop@server8 hadoop]$ jps
14107 Jps
14077 DataNode
以上啟動程序在那個結點都可以,熱添加;
此時在網頁訪問使便可以看到三個 datanode;
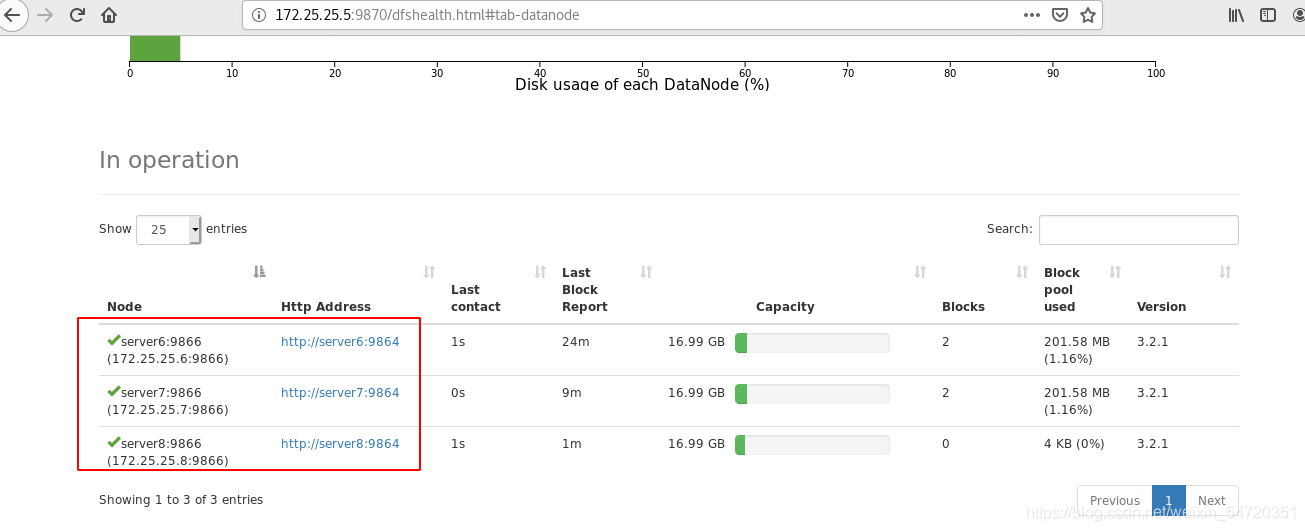
測驗
模擬用戶上傳資料
不管是在slave 還是master 端操作都一樣;此次在 server8 上上傳資料來觀察效果;
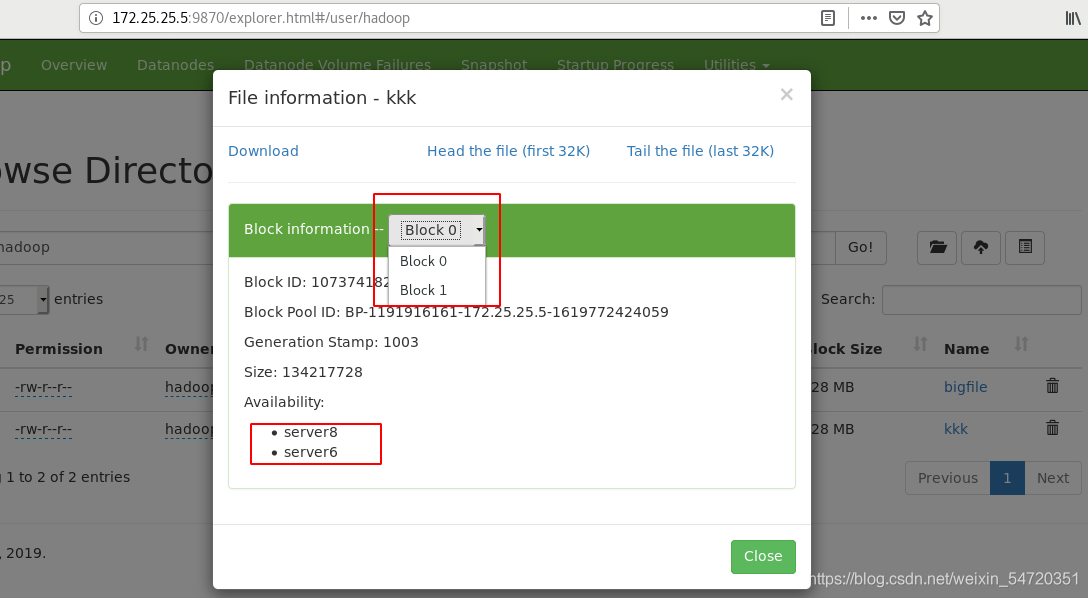
客戶端將檔案 kkk 分割成 2個block,分別交給指定的DataNode,DataNode復制保存block;
[hadoop@server8 hadoop]$ ls
bigfile etc lib LICENSE.txt NOTICE.txt README.txt share
bin include libexec logs output sbin
[hadoop@server8 hadoop]$ mv bigfile kkk
[hadoop@server8 hadoop]$ bin/hdfs dfs -put kkk
此時 server8 即是一個資料結點又是一個客戶端;
此時在網頁中可以看到新上傳的檔案,三個節點之間是均勻分布的,
第一個副本一定會存放在當前,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282284.html
標籤:其他
上一篇:2021年大資料Flink(三十一):???????Table與SQL案例準備 依賴和???????程式結構
下一篇:Docker學習