集成演算法
- 1 集成學習演算法的定義
- 2 bagging
- (1)bootstrap抽樣與方差降低
- (2)隨機森林與決策樹獨立同分布
- (3)極限隨機樹(極限森林)與API
- 3 boosting
- (1)梯度提升樹
- a 原理
- b 縮減 shrinkage
- c 梯度提升樹的API
- (2)Adaboost演算法
- a 原理
- b API
1 集成學習演算法的定義
所謂集成學習,就是訓練出完成統一任務的多個不同的子模型,并綜合這些子模型的預測結果做出最終的預測,集成學習中的每一個子模型都都稱為一個弱模型,對多個弱模型的綜合就稱為強模型,弱模型的選擇是靈活多樣的,可以源自不同的機器學習演算法,也可以是同一演算法,當源自同一演算法時,需要采用不同的訓練資料或者不同的特征選擇,綜合弱模型的預測結果的方式也可以靈活多樣,比如可以對預測結果取平均值,也可以取眾數,還可以將一個弱模型的輸出作為另一個弱模型的輸入,
集成學習演算法大致可以分為兩類:袋裝法(bagging)和提升法(boosting),
2 bagging
(1)bootstrap抽樣與方差降低
袋裝法又稱自助法(bootstrap法),其使用 bootstrap 抽樣,即有放回抽樣,每次訓練子模型使用的訓練樣本均為從原訓練樣本中有放回抽樣得來,在這些子訓練集中各自獨立地建立弱模型,并用這些弱模型預測,如果弱模型為決策樹,那么該集成演算法就是隨機森林,
因為是有放回的抽樣,能有效降低方差
對于n個獨立同分布的隨機變數Xi,假設他們的方差為σ^2,則n個隨機變數均值的方差為
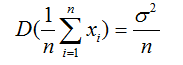
如果將每個弱模型的預測結果作為隨機變數,那么多個弱模型的預測結果平均值,其方差只有單個弱模型的 1/n ,
為何方差越小越好?
方差越大,波動性越大,預測結果波動性大,試想一下,一個模型今天預測是A,明天預測是B,后天就變C了,你覺得這個模型靠譜嗎?
而小的方差,代表預測結果更加穩定,雖然穩定值不一定正確,但只要每一個弱模型預測正確的概率比較大,那么結果的可信度就能大大提高,試想一下,某個集成模型,今天預測是A,明天也是A,后天也A,一個星期里6天預測是A,只有一天預測是B,由于波動性小,總體來看,這個集成模型還是比較靠譜的,因為預測結果穩定于結果A,雖然真實結果未必就是A,但總比上一個模型更靠譜,這里的集成模型,是由100個弱模型構成,最后的結果是100個弱模型投票,可以認為是100個人投了一個星期的票,每個人在一周內的波動性都大,但每天投票的綜合結果卻是穩定的,
當然,上面的解釋不嚴謹,只是方便理解,因為每個弱模型未必相互獨立,預測結果也未必同分布,比如在隨機森林中,由于生成每一棵樹的資料子集取自同一訓練集,因此這些訓練集存在一定的關聯性,訓練出來的每棵決策樹也是比較相似,這樣各棵決策樹無法做到獨立同分布,
(2)隨機森林與決策樹獨立同分布
隨機森林的思想依據是:雖然森林中的每棵樹都有一定的預測錯誤概率,但它們同時出錯的概率是很低的,
通過重復采樣,隨機森林預測的均方誤差,以及發生過擬合的概率都小于單棵決策樹,
為了增加隨機森林中各棵樹獨立的可能性,隨機森林在訓練每棵決策樹的時候需要一個額外的步驟:在每次劃分資料時,隨機的選取一部分特征進行遍歷,而不是遍歷所有的特征,因為考慮的特征不一樣,這樣各個決策樹就有不一樣結構,這樣就能使得每棵樹的預測結果更加接近于獨立同分布(獨立好理解了,但同分布如何理解?因為每棵樹都在擬合相同的目標值,相當于在擬合同一個分布,因此可以認為預測結果是同分布),當然,上述措施只能在某種程度上是預測結果接近獨立同分布,只要每個訓練子集取自同一個樣本集,就很難真正做到獨立同分布,
(3)極限隨機樹(極限森林)與API
極限隨機樹,又稱極限森林、極端隨機樹,
隨機森林中,每棵樹都是隨機選擇一部分樣本(有放回),生成決策樹時,每次劃分都是隨機選擇一部分特征(無放回),然后遍歷這些特征的所有取值,以確定劃分所使用的特征和閾值,
極限森林與隨機森林主要有兩個區別,一是使用所有的樣本,二是極限森林在每次劃分時,隨機選擇閾值,何謂“隨機選擇閾值”,我們這里來解釋一下:
假如原始的資料有10個特征,在每次劃分樣本時,隨機抽5個特征作為特征子集,為特征子集中的每一個特征隨機選擇一個值作為候選閾值,那么會有5個候選閾值,分別計算這5個候選閾值對應的基尼系數或者交叉熵(如果是回歸問題則計算均方差),能得到最小基尼系數或交叉熵的候選閾值,即為最終的閾值,其對應的特征,就是本次劃分時使用的特征,
隨機森林是在特征子集里面遍歷選擇特征,極限森林為特征子集中的每個特征隨機生成一個閾值,并從這些隨機生成的閾值中選取最佳閾值作為分割規則,
API
極限分類森林
sklearn.ensemble.ExtraTreesClassifier(n_estimators=100, criterion='gini',
max_depth=None, max_features='auto', rand_state=None)
n_estimators 極限森林中決策樹的數量,默認100
criterion 劃分樣本時采用的標準,可以選擇 ‘gini’,也可以 ‘entropy’,默認 ‘gini’
max_depth 每棵樹的最大深度
max_features 特征子集中的特征數目,默認是auto,即對樣本總特征數取平方根(max_features=sqrt(n_features))
random_state 隨機種子
其他引數基本和隨機森林一致,
除了極限分類森林外,還有極限回歸森林,其原理和API與分類森林類似,
3 boosting
提升法是在同一個訓練集上依次訓練出一系列弱模型,每一個弱模型在訓練的時候,都在擬合上一個弱模型的誤差,因此,這些弱模型具有很強的依賴關系,集成模型的每次迭代,都是向其加入一個弱模型,提升演算法的核心思想是讓每一個弱模型都能彌補前一個弱型的不足,從而使得集成模型(強模型)得到的最終結果更加準確,
(1)梯度提升樹
a 原理
梯度提升樹(Gradient Boosting Decision Tree,簡稱gbdt)是由很多回歸樹組成,其基本思想是不斷生成新的決策樹來擬合前一棵決策樹的誤差,以期所有決策樹預測的綜合達到良好的效果,
具體來說,給定一個回歸問題的訓練資料 S={(x(1), y(1)),(x(1), y(1)),……,(x(m), y(m))},按照慣例,用
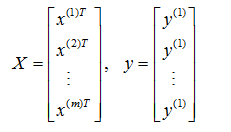
分別表示特征矩陣和標簽向量,
演算法第一棵決策樹 T0 來表示最小化均方誤差
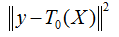
用 r0=y-T0(X) 表示決策樹 T0 的預測誤差,可以認為,r0 是 T0 的不足之處,為了彌補不足,再訓練一棵決策樹 T1 來擬合誤差 r0,因此,T1的任務是最小化均方誤差
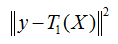
此時,用 r1 = r0 - T1(X) 表示 T1 的預測誤差,由此,梯度提升回歸樹又可以再訓練一棵決策樹 T2 來擬合誤差 r1 ,這一程序可以不斷地進行下去,直到決策樹的誤差接近0,
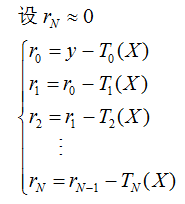
將上面格式相加并左右消元之后,可以得到:
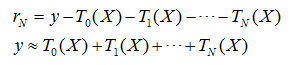
因此,可以用一系列回歸決策樹輸出結果的和來擬合標簽,這就是梯度提升樹的回歸演算法原理,
梯度提升樹中,弱模型是決策樹,如果不對決策樹的深度進行限制,那么每棵決策樹都會對訓練集進行準確無誤地擬合,弱模型不需要那么高的精度,因此可以使用深度來約束弱模型的精度,
由于該演算法類似于函式空間中的梯度下降演算法,每一次對前一棵樹的誤差擬合,都相當于在函式空間中沿梯度反方向搜索,并以此來提升模型的效果,因此成為梯度提升樹,
b 縮減 shrinkage
Shrinkage 的思想認為,每走一小步要比每次邁一大步更容易接近極值點,像函式空間中的梯度下降演算法一樣,這里可以加入學習率的概率,
假設 F(x)為強模型,如果沒有學習率,則
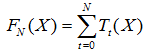
每增加一棵樹,都是對強模型的一次迭代
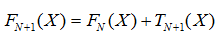
Shrinkage 不直接用殘差修復誤差,而是只修復一點點,把大步切成小步,本質上是給每棵樹加上一個權值,即它并不是完全信任每一棵殘差樹,
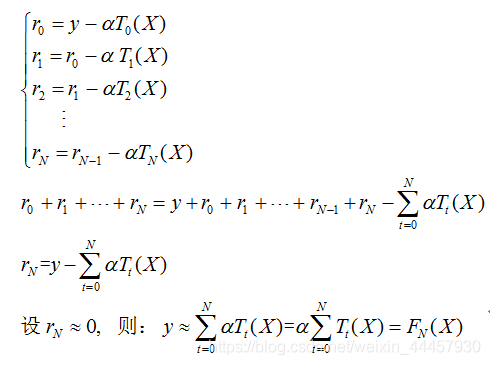
圖片中 α 是學習率,
從最后的結果可以看到,當加上學習率之后,最后的強模型,是若干個弱模型預測值之和乘以學習率,
因此,迭代強模型時
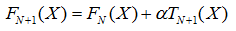
c 梯度提升樹的API
sklearn.ensemble.GradientBoostingRegressor(learning_rate=0.1,
n_estimators=100, max_depth=3, random_state=None)
learning_rate 學習率,默認0.1
n_estimators 樹的棵數
max_depth 每棵樹的最大深度
random_state 亂數種子
(2)Adaboost演算法
Adaboost是一種應用于二分類問題的演算法,它用弱分類器的線性組合來構造強分類器,弱分類器的性能不太好用,僅比隨機瞎猜強,依靠它們可以構造一個非常準確的強分類器,
a 原理
在每次訓練弱模型時,都重點關注上一個弱模型中預測錯誤的樣本,其大致程序是:對于第k個弱模型預測錯誤的樣本,為其增大權重,預測正確的樣本縮小權重,同時根據第k個弱模型的預測錯誤率,為弱模型分配權重,訓練集的每一個樣本,在每次訓練弱模型時,都會改變權重,弱模型一般是用決策樹,
具體公式理論的推導與證明,詳見《機器學習與應用》雷明 清華大學出版社,P284-295,
b API
sklearn.ensemble.AdaBoostClassifier(n_estimators=100)
n_estimators 弱模型的數量,這里的弱模型指的是深度為1的決策樹,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282286.html
標籤:其他
上一篇:Docker學習