導讀:目前 Kafka 已經定位為一個分布式流式處理平臺,它以高吞吐、可持久化、可水平擴展、支持流資料處理等多種特性而被廣泛使用,目前越來越多的開源分布式處理系統如 Cloudera、Storm、Spark、Flink 等都支持與 Kafka 集成,
2021年4月19日,Kafka官方發布了2.8.0版本,包含了很多新特性!其中,我覺得最感興趣的是提到的第一條特性-Kafka用自管理的Quorum代替ZooKeeper管理元資料,

之前Kafka使用ZooKeeper來存盤有關磁區和代理的元資料,并選擇一個代理作為Kafka控制器,目前洗掉對ZooKeeper的依賴,這將使Kafka夠以更具擴展性和更強大的方式管理元資料,從而支持更多磁區,它還將簡化Kafka的部署和配置,
Kafka 2.8.0 用自管理的Quorum代替ZooKeeper管理元資料,官方稱這個為 "Kafka Raft metadata mode",即KRaft mode
KRaft最大的好處在于移除了ZooKeeper,這樣我們無需維護zk集群,只要維護Kafka集群就可以了
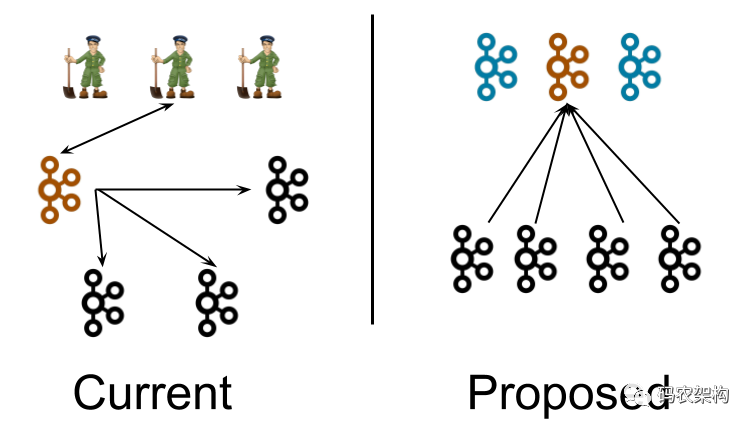
請注意,此圖有些誤導,除控制器外的其他代理可以并且確實與ZooKeeper進行通信,因此,實際上,應該從每個經紀人到ZK劃清界限,但是,繪制很多線會使該圖難以閱讀,
可能有一些剛接觸Kafka的小伙伴還不明白這到底代表著什么,
在kafka 2.8.0之前體系架構包括若干 Producer、若干 Broker、若干 Consumer,以及一個 ZooKeeper 集群,如下圖所示,其中 ZooKeeper 是 Kafka 用來負責集群元資料的管理、控制器的選舉等操作的,Producer 將訊息發送到 Broker,Broker 負責將收到的訊息存盤到磁盤中,而 Consumer 負責從 Broker 訂閱并消費訊息,
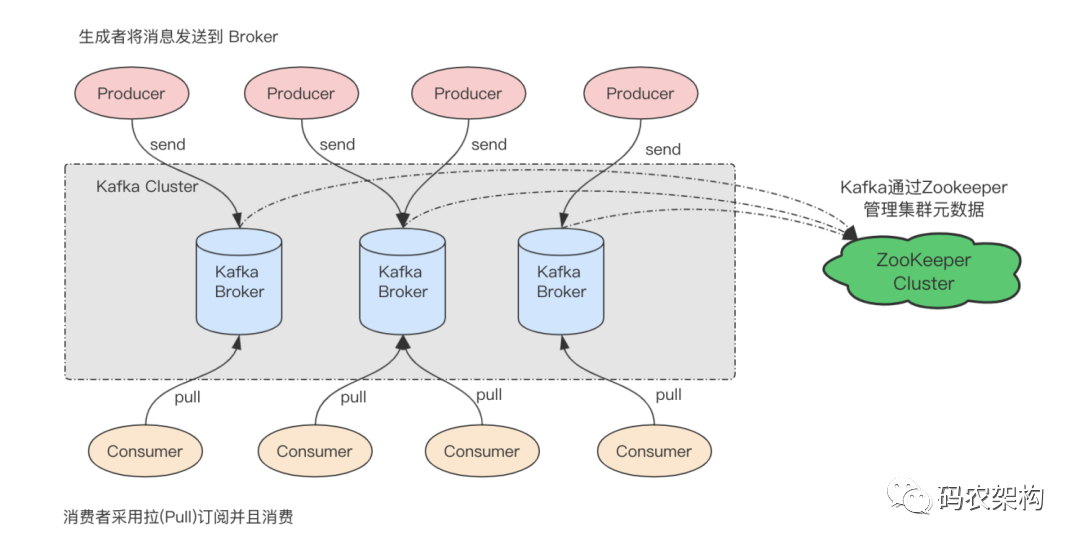
不太理解的小伙伴可以查看下Kafka 2.8.0之前的部署和一些教程發現和新版本的差異還是很大的,你會發現增加了很多的成本,但短期可能會帶來很多不便,基于長遠的角度思考,這次改動對于Kafka的長遠發展利大于弊,
Kafka 的代碼庫中還有很大一部分是負責在多個集群中安排日志、分配領導權、處理故障等,這使的 Kafka 成為一個可靠和可信的分布式系統,而ZooKeeper就是分布式代碼作業的關鍵,在以往的版本中,ZooKeeper 提供了權威的元資料存盤,這些元資料存盤了系統中最重要的東西,例如磁區可以存在哪里,哪個組件是主導等等等等
但不管怎么樣,ZooKeeper 是一個基于一致日志的特殊檔案系統/觸發器API,而Kafka 是一個建立在一致日志之上的發布/訂閱系統,
Kafka 2.8.0包括許多重要的新功能,以下是重要變化
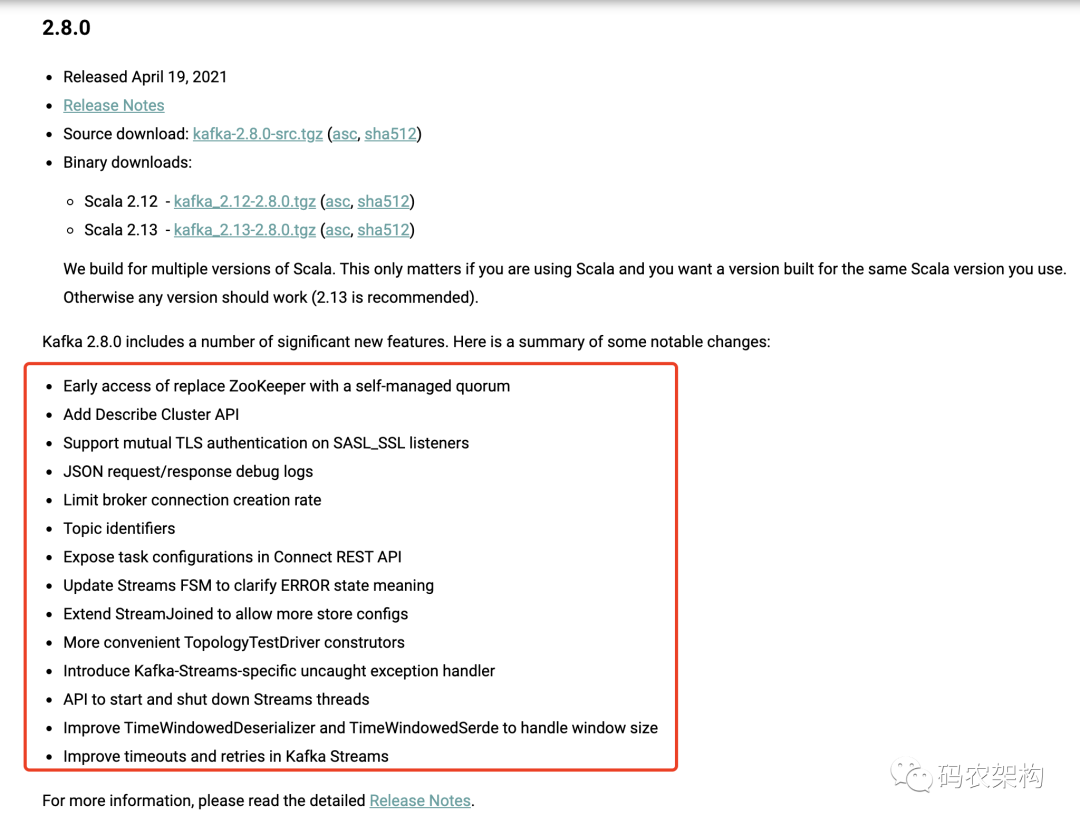
簡單點可以理解為:
-
搶先體驗,kafka通過自我管理的仲裁來替代ZooKeeper(很快,Apache Kafka將不再需要ZooKeeper,)
-
增加集群描述API
-
在SASL_SSL監聽器上支持彼此TLS認證
-
JSON請求/回應的debug日志
-
限制broker連接創建率
-
Topic識別
-
在Connect REST API中公開任務配置
-
更新 Streams FSM 以澄清ERROR狀態的含義
-
擴展 StreamJoined 以允許更多的存盤配置
-
更方便的TopologyTestDriver構造
-
引入 Kafka-Streams 專用的未捕獲例外處理程式
-
啟動和關閉Streams執行緒的API
-
改進 TimeWindowedDeserializer 和 TimeWindowedSerde 處理視窗大小
-
改善Kafka流中的超時和重試情況
智哥現在用的版本還停留在Kafka 2.2.1,當然這個版本一用就是幾年🤣當然如果2.8.0版本穩定后建議后面的系統架構設計可以考慮下!
如果對具體的更新內容感興趣,可以直接登陸官網進行查看:
-
https://kafka.apache.org/downloads
-
https://downloads.apache.org/kafka/2.8.0/RELEASE_NOTES.html
-
https://blogs.apache.org/kafka/entry/what-s-new-in-apache5
當然,2.8.0版本還有很多未完善的地方,可能還不適合應用在生產環境,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282595.html
標籤:其他
上一篇:2021年大資料Flink(三十八):???????Table與SQL ??????案例五 FlinkSQL整合Hive