本文已收錄github:https://github.com/BigDataScholar/TheKingOfBigData,里面有大資料高頻考點,Java一線大廠面試題資源,上百本免費電子書籍,作者親繪大資料生態圈思維導圖…持續更新,歡迎star!
前言
大家好,我是夢想家!
眾所周知,Hadoop 中最核心的兩大組件就是 HDFS 和 MapReduce,其中 HDFS 提供了承載海量資料存盤的能力,而 MapReduce 則提供了海量資料高并行計算的能力,關于 HDFS 的介紹,之前已經寫了兩篇來分別介紹 HDFS 的架構 和 HDFS實作檔案管理和容錯的文章 ,而本期文章,我將為大家介紹關于 MapReduce 的核心知識點,

MapReduce的原理
Hadoop 中 MapReduce 最核心的思想就是分而治之,通過 MapReduce 這個名字就可以看出,MapReduce 包含有 Map 和 Reduce 兩個部分,它將一個大型的計算問題分解成一個個小的,簡單的計算任務,交給 MapReduce 中的 Map 部分執行,隨后 Reduce 部分會對 Map 部分輸出的中間結果進行聚合計算,輸出最終的統計結果,
為了方便大家理解,可以看下 MapReduce 的簡要模型圖:
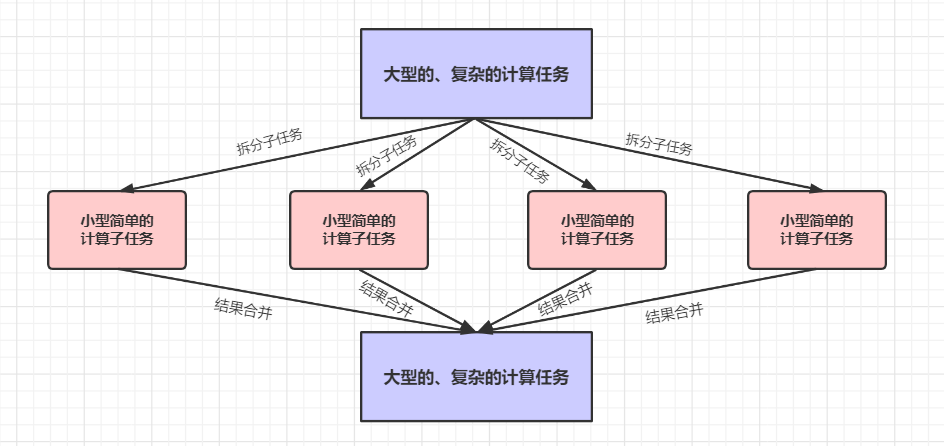
每個子任務在框架中都是高度并行計算的,然后 MapReduce 框架將各個計算子任務的計算結果進行合并,得出最終的計算結果,
每個子任務在 MapReduce 內部都是高度并行計算的,子任務的高度并行化極大地提高了 Hadoop 處理海量資料的性能,MapReduce 的并行計算模型如圖所示:
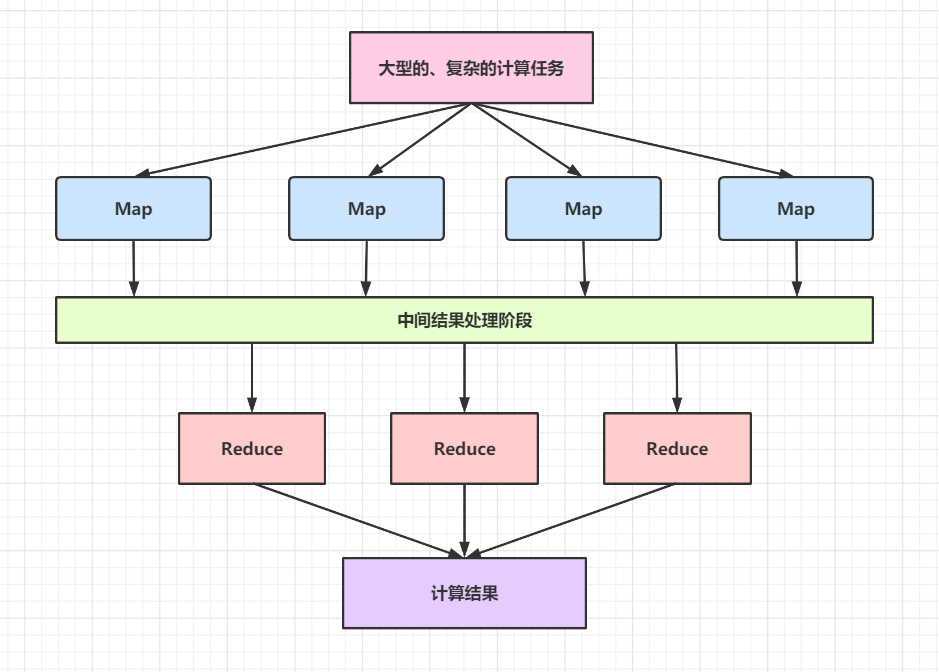
由圖可知,MapReduce 框架將一個大型的計算任務拆分為多個簡單的計算任務,交由多個 Map 并行計算,每個 Map 的計算結果經過中間結果處理階段的處理后輸入 Reduce 階段,Reduce 階段將輸入的資料進行合并處理,輸出最終的計算結果 ,
同時,用戶無須關心 MapReduce 底層各個節點之間的通信機制與通信程序,只需簡單地撰寫 map() 函式和 reduce() 函式即可開發 Hadoop MapReduce 程度,
MapReduce的部署結構
MapReduce 框架由一個主節點(ResourceManager)、多個子節點(NodeManager)和每個執行任務的 MR AppMaster 共同組成 ,通常會將 MapReduce 的計算節點和存盤節點部署在同一臺服務器上,如圖所示:
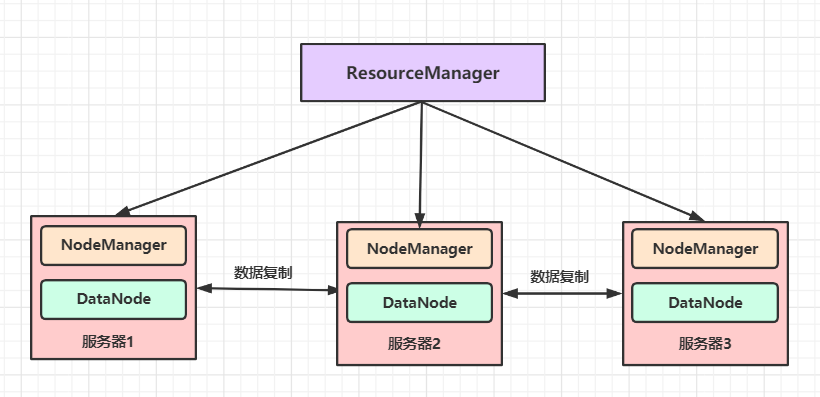
這種部署結構可以使 MapReduce 框架在已經存盤好資料的節點上快速、高效地調度任務,盡可能地不用通過 RPC 從其他服務器上獲取資料來執行任務,使整個集群的網路帶寬被高效利用,極大地提升了處理任務的效率,
MapReduce 的運行流程
MapReduce 編程模型簡化了分布式系統中并行計算的復雜度,開發人員能夠不必關心 MapReduce 程式的底層實作細節,只專注于解決業務需求,
在 MapReduce 框架內部,整個運行流程可以分為如下四個階段,其中每個階段中的資料傳輸格式也不一樣,
簡單運行流程如下所示:
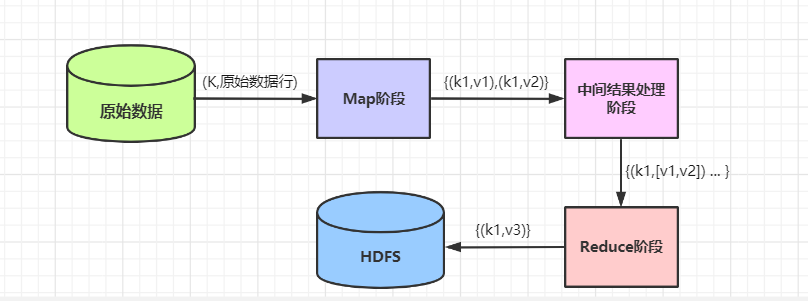
大致流程:
(1)原始資料經過 Hadoop 框架的處理,將 “(k,原始資料行)”格式的資料輸入 Map 階段,即 Map 階段接收到的資料都是 “(k,元素資料行)”的,
(2)資料經過 Map 階段處理之后,輸出 “{(k1,v1),(k2,v2)}”格式的中間結果
(3)Map階段輸出的中間結果經由 Hadoop 的中間結果處理階段(如聚合、排序等)之后,會形成 “ {(k1,[v1,v2]) …} ”格式的資料
(4)中間結果處理階段形成的 “{(k1,[v1,v2]) …}”格式的資料會輸入 Reduce 階段進行處理,此時,key相同的資料會被輸入進同一個 Reduce 函式進行處理(也可以由用戶自定義資料分發規則)
(5)資料經過 Reduce 階段處理之后,最侄訓形成“{(k1,v3)}” 格式的資料存入 HDFS 中
另外,如果覺得不夠清晰,也可以參考下下面這個版本的 MapReduce 運行流程,
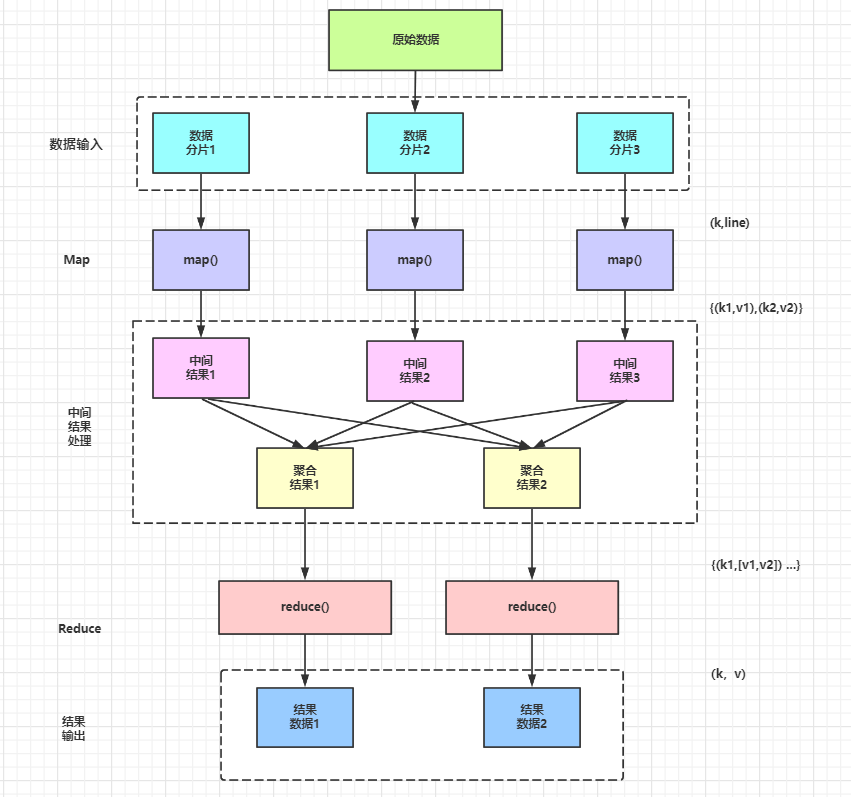
(1)原始資料被切分為多個小的資料分片輸入 map() 函式,這些小的資料分片往往是原始資料的資料行,它們以 “(k,line)” 的格式輸入 map() 函式,其中 k 表示資料的偏移量,line 表示整行資料,
(2)map() 函式并行處理輸入的資料分片,根據具體的業務規則對輸入的資料進行相應的處理,輸出中間處理結果,這些中間處理結果往往以“{(k1,v1),(k2,v2)}” 的格式存在,
(3)中間處理階段將 map() 函式輸出的中間結果根據 key 進行聚合處理,輸出聚合結果,這些聚合結果的格式為:“{(k1,[v1,v2])}”,
(4)中間處理階段將輸出的聚合結果輸入 reduce () 函式進行處理( key相同的資料會被輸入同一個 reduce()函式中,用戶也可以自定義資料分發規則 ),reduce()函式對這些資料進行進一步聚合和計算等,
(5)reduce 函式將最終的結果以 “ (k,v) ”的格式輸出到 HDFS 中,
MapReduce的容錯機制
MapReduce 容錯包括 Task(任務)容錯,AppMaster 容錯、NodeManager 容錯和 ResourceManager 容錯,
1、Task 容錯
AppMaster 一段時間沒有收到任務進度的更新,就會將任務標記為失敗,但是不會立刻殺死執行任務的行程,而是等待一定的超時時間,該超時時間可以在mapred-site.xml檔案中進行配置,具體的屬性為mapreduce.task.timeout:
<properties>
<name>mapreduce.task.timeout</name>
<value>600000</value>
</property>
超時時間默認值為 10 min,即任務被標記為失敗的 10 min 之后才會將任務失敗的行程殺死,
MapReduce 提供了重試機制,重試的次數主要由 map-site.xml檔案中的 mapreduce.map.maxattempts屬性和mapreduce.reduce.maxattempts屬性配置,代碼如下所示:
<properties>
<name>mapreduce.map.maxattempts</name>
<value>4</value>
</property>
<properties>
<name>mapreduce.reduce.maxattempts</name>
<value>4</value>
</property>
默認重試次數為4,即任務失敗后,MapReduce 框架會重試4次,如果任務依然失敗,MapReduce才會認為任務徹底失敗了,
也可以配置允許任務失敗的最大百分比,可以由屬性 mapreduce.map.failures.maxpercent 和 mapreduce.reduce.failures.maxprecent 進行配置,
2、AppMaster 容錯
AppMaster也提供了重試機制,YARN中的應用程式失敗之后,最多嘗試次數由mapred-site.xml檔案中的mapreduce.am.max-attempts屬性配置:
<properties>
<name>mapreduce.am.max-attempts</name>
<value>4</value>
</property>
嘗試次數默認值為2,即當 AppMaster 失敗2次之后,運行的任務將會失敗,
在 MapReduce 內部,YARN 框架對 AppMaster 的最大嘗試次數做了限制,其中,每個在 YARN 中運行的應用程式不能超過這個數量限制,具體限制由 yarn-site.xml 檔案中的 yarn.resourcemanager.am.max-attempts屬性控制,配置資訊如下所示:
<properties>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>2</value>
</property>
3、NodeManager 容錯
當 NodeManager 發生故障,停止向 ResourceManager 節點發送心跳資訊時,ResourceManager 節點并不會立即移除 NodeManager,而是要等待一段時間,該時間可以由 yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms 屬性設定,代碼如下:
<properties>
<name>yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms</name>
<value>600000</value>
</property>
等待時間默認值為 10 min,即 NodeManager 發生故障之后,ResourceManager 節點接收不到 NodeManager 發生過來的心跳資訊,過 10 min 之后才會將 NodeManager 移除 ,
當 NodeManager 上運行的失敗任務數量達到一定的值時,AppMaster 就會將該節點上的任務調度到其他節點上,任務失敗的閾值由 mapred-site.xml 檔案中的 mapreduce.job.maxtaskfailures.per.tracker 屬性設定,代碼如下所示:
<properties>
<name>mapreduce.job.maxtaskfailures.per.tracker</name>
<value>3</value>
</property>
此默認值為3,即當一個 NodeManager 上有超過3個任務失敗,AppMaster 就會將該節點上的任務調度到其他節點上 ,
ResourceManager 容錯
新版本的 Hadoop 中提供了 ResourceManager 節點的 HA 機制,如果主 ResourceManager 失敗,備 ResouceManager 會迅速接管作業,
Hadoop 中對 ResourceManager節點提供了檢查點機制,當所有的 ResourceManager 節點失敗后,重啟 ResouceManager 節點,可以從上一個失敗的 ResourceManager 節點保存的檢查點進行狀態恢復,
這些檢查點的存盤是由 yarn-site.xml檔案中的 yarn-resourcemanager.store.class屬性設定的,代碼如下所示:
<properties>
<name>yarn-resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore</value>
</property>
當然,默認是保存到檔案中,
MapReduce的優化
技術面試中,關于 MapReduce 優化的考察頻率可能不如 Spark,Flink,但是作為 Hadoop 知識的熱門考點,我們對于它的優化還是要有一個清晰的認識 , 這里,我們從以下幾個小點逐一展開,
MapReduce跑的慢的原因
MapReduce程式效率的瓶頸在于兩點:
- 計算機性能
CPU、記憶體、磁盤健康、網路
- I/O 操作優化
- 資料傾斜
- Map 和 Reduce 數設定不合理
- Map運行時間太長,導致 Reduce 等待過久
- 小檔案過多
- 大量的不可分塊的超大檔案
- Spill 次數過多
- Merge 次數過多等,
MapReduce優化
關于 MapReduce 優化方法主要從以下6個方面進行考慮,分別是:資料傾斜、Map階段、Reduce階段、IO傳輸、資料傾斜問題和常用的調優引數,
1、資料輸入
(1)合并小檔案:在執行 MR 任務之前將小檔案進行合并,大量的小檔案會產生大量的 MR 任務,增大 Map 任務裝載次數,而任務的裝載比較耗時,從而導致 MR 運行較慢,
(2)采用 CombineText InputFormat 來作為輸入,解決輸入端大量小檔案場景,
2、Map階段
(1)減少溢寫(spill)次數:通過調整 io.sort.mb 及 sort.spill.percent 引數值,增大觸發 Spill 的記憶體上限,減少 Spill 次數,從而減少磁盤 IO ,
(2)減少合并(Merge)次數:通過調整io.sort.factor引數,增大 Merge 的檔案數目,減少 Merge 的次數,從而縮短 MR 處理時間,
(3)在 Map 之后,不影響業務邏輯前提下,先進行 Combine 處理,減少 I/O ,
3、Reduce 階段
(1)合理設定 Map 和 Reduce 數:兩個都不能設定的太少,也不能設定的太多,太少,會導致 Task 等待,延長處理時間;太多,會導致 Map,Reduce 任務間競爭資源,造成處理超時等錯誤 ,
(2)設定 Map、Reduce 共存:調整 slowstart.completedmap引數,使 Map 運行到一定程度后,Reduce 也開始運行,減少 Reduce 的等待時間 ,
(3)規避使用 Reduce:因為 Reduce 在用于連接資料集的時候將會產生大量的網路消耗,
(4)合理設定 Reduce 端的 Buffer:默認情況下,資料達到一個閾值的時候,Buffer 中的資料就會寫入磁盤,然后 Reduce 會從磁盤中獲得所有的資料,也就是說,Buffer 和 Reduce 是沒有直接關聯的,中間多次寫磁盤 -> 讀磁盤的程序,既然有這個弊端,那么就可以通過引數來配置,使得 Buffer 中的一部分資料可以直接輸送到 Reduce,從而減少 IO 開銷 : mapreduce.reduce.input.buffer.percent,默認為 0.0 ,當值大于 0 的時候,會保留指定比例的記憶體讀 Buffer 中的資料直接拿給 Reduce 使用 , 這樣一來,設定 Buffer 需要記憶體,讀取資料需要記憶體,Reduce 計算也需要記憶體,所以要根據作業的用運行情況進行調整 ,
4、I/O 傳輸
(1)采用 資料 壓縮的方式,減少 網路 IO 的時間 , 安裝 Snappy 和 LZO 壓縮編碼器,
(2)使用 SequenceFile 二進制檔案,
5、資料傾斜問題
1. 資料傾斜現象:
- 資料頻率傾斜——某一個區域的資料量要遠遠大于其他的區域,
- 資料大小傾斜——部分記錄的大小遠遠大于平均值
2.減少資料傾斜的方法:
方法1 :抽樣和范圍磁區
可以通過對原始資料進行抽樣得到的結果集來預設磁區邊界值,
方法2:自定義磁區
基于輸出鍵的背景知識進行自定義磁區,例如,如果 Map 輸出鍵的單詞來源于一本書,且其中某幾個專業詞匯較多,那么就可以自定義磁區將這些專業詞匯發送給固定的一部分 Reduce 實體,而其他的都發送給剩余的 Reduce 實體,
方法3:Combine
使用 Combine 可以大量的減少資料傾斜,在可能的情況下,Combine 的目的就是聚合并精簡資料,
方法4:采用 Map Join,盡量避免 Reduce Join
這個我們上面說過了,Reduce 在用于連接資料集的時候將會產生大量的網路消耗,所以我們采用 MapJoin,盡量避免 Reduce Join ,
6、常用的調優引數
1、資源相關引數
(1)以下引數是在用戶自己的MR應用程式中配置就可以生效(mapred-default.xml)
| 配置引數 | 引數說明 |
|---|---|
| mapreduce.map.memory.mb | 一個MapTask可使用的資源上限(單位:MB),默認為1024,如果MapTask實際使用的資源量超過該值,則會被強制殺死, |
| mapreduce.reduce.memory.mb | 一個ReduceTask可使用的資源上限(單位:MB),默認為1024,如果ReduceTask實際使用的資源量超過該值,則會被強制殺死, |
| mapreduce.map.cpu.vcores | 每個MapTask可使用的最多cpu core數目,默認值: 1 |
| mapreduce.reduce.cpu.vcores | 每個ReduceTask可使用的最多cpu core數目,默認值: 1 |
| mapreduce.reduce.shuffle.parallelcopies | 每個Reduce去Map中取資料的并行數,默認值是5 |
| mapreduce.reduce.shuffle.merge.percent | Buffer中的資料達到多少比例開始寫入磁盤,默認值0.66 |
| mapreduce.reduce.shuffle.input.buffer.percent | Buffer大小占Reduce可用記憶體的比例,默認值0.7 |
| mapreduce.reduce.input.buffer.percent | 指定多少比例的記憶體用來存放Buffer中的資料,默認值是0.0 |
(2)應該在YARN啟動之前就配置在服務器的組態檔中才能生效(yarn-default.xml)
| 配置引數 | 引數說明 |
|---|---|
| yarn.scheduler.minimum-allocation-mb | 給應用程式Container分配的最小記憶體,默認值:1024 |
| yarn.scheduler.maximum-allocation-mb | 給應用程式Container分配的最大記憶體,默認值:8192 |
| yarn.scheduler.minimum-allocation-vcores | 每個Container申請的最小CPU核數,默認值:1 |
| yarn.scheduler.maximum-allocation-vcores | 每個Container申請的最大CPU核數,默認值:32 |
| yarn.nodemanager.resource.memory-mb | 給Containers分配的最大物理記憶體,默認值:8192 |
(3)Shuffle性能優化的關鍵引數,應在YARN啟動之前就配置好(mapred-default.xml)
| 配置引數 | 引數說明 |
|---|---|
| mapreduce.task.io.sort.mb | Shuffle的環形緩沖區大小,默認100m |
| mapreduce.map.sort.spill.percent | 環形緩沖區溢位的閾值,默認80% |
2、容錯相關引數(MapReduce性能優化)
| 配置引數 | 引數說明 |
|---|---|
| mapreduce.map.maxattempts | 每個Map Task最大重試次數,一旦重試引數超過該值,則認為Map Task運行失敗,默認值:4, |
| mapreduce.reduce.maxattempts | 每個Reduce Task最大重試次數,一旦重試引數超過該值,則認為Map Task運行失敗,默認值:4, |
| mapreduce.task.timeout | Task超時時間,經常需要設定的一個引數,該引數表達的意思為:如果一個Task在一定時間內沒有任何進入,即不會讀取新的資料,也沒有輸出資料,則認為該Task處于Block狀態,可能是卡住了,也許永遠會卡住,為了防止因為用戶程式永遠Block住不退出,則強制設定了一個該超時時間(單位毫秒),默認是600000,如果你的程式對每條輸入資料的處理時間過長(比如會訪問資料庫,通過網路拉取資料等),建議將該引數調大,該引數過小常出現的錯誤提示是“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.” |
巨人的肩膀
1、《海量資料處理與大資料技術實戰》
2、《Hadoop權威指南》
小結
實際上,關于 MapReduce的內容還有很多,本期文章只是將比較重要核心的部分介紹了一下,其中,MapReduce的原理,運行流程,優化是面試中比較經常考察的點,而部署結構,容錯機制我們僅做學習了解即可,我還想強調一點,一定要學會自發的去學習新的知識和總結學過的內容,否則就容易出現,新學的記不住,學過的忘記了的情況,
好了,本期文章就到這里,我是夢想家,我們下一期見!如果對您有所幫助,請記得一鍵三連~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282596.html
標籤:其他
上一篇:Kafka 2.8.0 正式發布,增加了哪些新特性?
下一篇:ambari集群安裝hdp