Hive入門(一)
- Hive與HDFS的資料映射
- 集群啟動
- Hive物件
- 資料庫
- 表
- 表的資料
- 元資料映射
- Hive轉換MapReduce
- 功能映射
- 執行決議
- metastore
- 功能
- 三種方式
- 嵌入式資料庫
- 本地資料庫
- 遠程Metastore服務
- 兩個位置
- 默認位置
- 自定義位置
- 共享
- metastore服務
- metastore配置
- metastore啟動
Hive部署
Hive與HDFS的資料映射
集群啟動
先啟動HDFS:
start-dfs.sh
然后啟動YARN:
start-yarn.sh
之前已經配置好了Hive,在node3直接啟動即可:
cd /export/server/hive-2.1.0-bin/
bin/hive
Hive物件
上一篇中已經在node1:50070查看過Hive會在HDFS檔案系統中存盤各種資料,
資料庫
事實上,Hive創建的每個資料庫都對應HDFS中的某個目錄,目錄的名字是:資料庫名.db,
在啟動Hive的命令列:
hive> show databases;
OK
default
Time taken: 1.027 seconds, Fetched: 1 row(s)
hive> create database aaa;
OK
Time taken: 0.242 seconds
可以用瀏覽器在node1:50070看到:
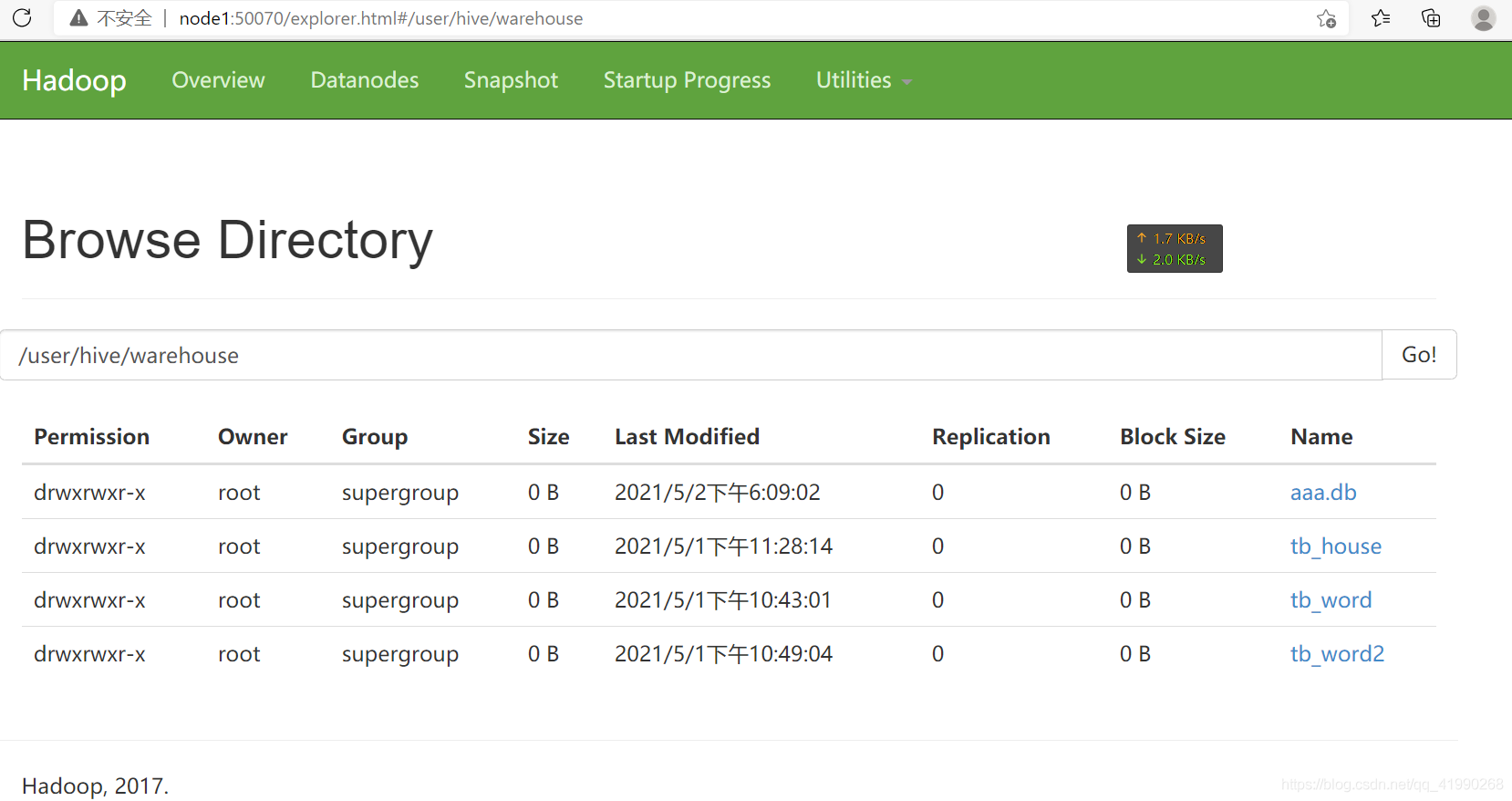
新建的資料庫會存放在之前配置好的倉庫路徑內,/user/hive/warehouse是之前配置的倉庫路徑,
表
每張表會在資料庫對應的目錄下建立一個與表同名的目錄,
在啟動Hive的命令列:
hive> select current_database();
OK
default
Time taken: 1.834 seconds, Fetched: 1 row(s)
可以看到當前使用的資料庫是default【這是廢話,,,之前也只有這個資料庫】,
在啟動Hive的命令列:
hive> show tables;
OK
tb_house
tb_word
tb_word2
Time taken: 0.041 seconds, Fetched: 3 row(s)
可以看到:
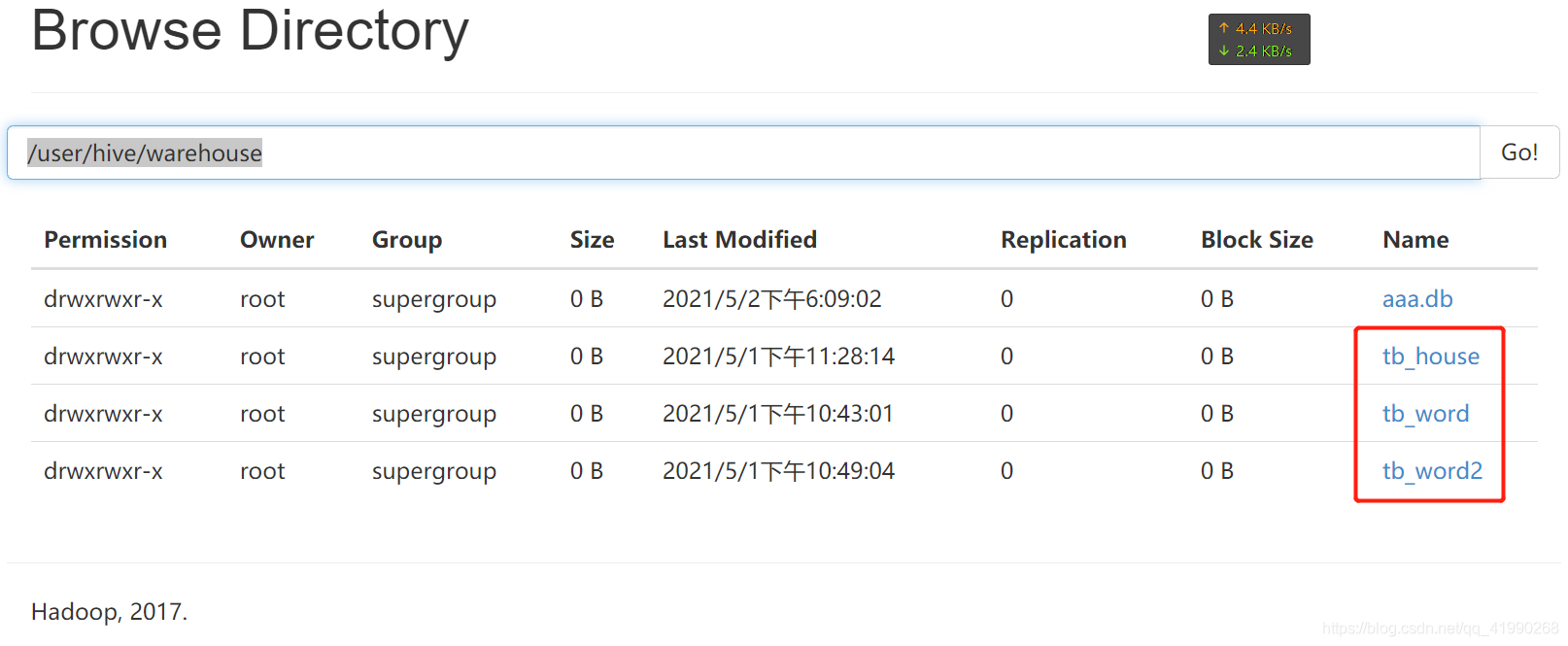
表的資料
表的資料映射的是HDFS上的檔案,
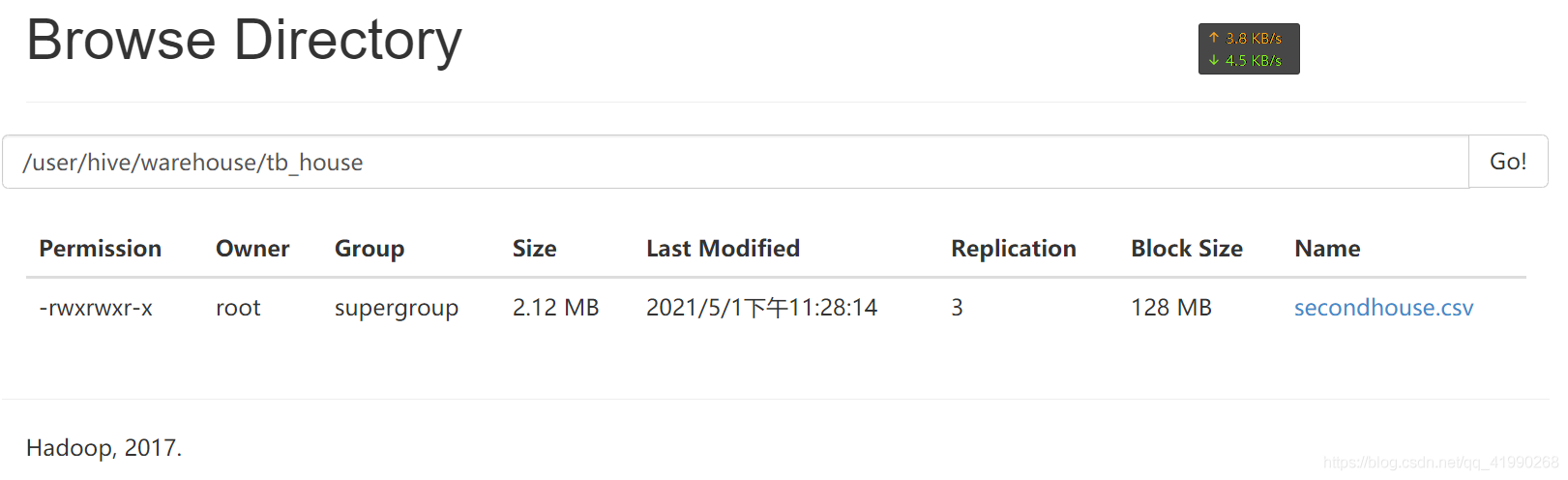
進入到目錄后可以看到檔案(建表時被Hive搬到倉庫路徑的檔案),
元資料映射
在啟動Hive的命令列:
select * from tb_word2
后Hive可以找到這個表對應的資料并展示在命令列,使用ctrl+c,多按幾次結束,exit;退出hive,
看看MySQL中存盤了寫啥玩意兒:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| hivemetadata |
| itcast_shop |
| mysql |
| performance_schema |
+--------------------+
5 rows in set (0.00 sec)
mysql> use hivemetadata
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+---------------------------+
| Tables_in_hivemetadata |
+---------------------------+
| AUX_TABLE |
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_QUEUE |
| COMPLETED_COMPACTIONS |
| COMPLETED_TXN_COMPONENTS |
| DATABASE_PARAMS |
| DBS |
| DB_PRIVS |
| DELEGATION_TOKENS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| HIVE_LOCKS |
| IDXS |
| INDEX_PARAMS |
| KEY_CONSTRAINTS |
| MASTER_KEYS |
| NEXT_COMPACTION_QUEUE_ID |
| NEXT_LOCK_ID |
| NEXT_TXN_ID |
| NOTIFICATION_LOG |
| NOTIFICATION_SEQUENCE |
| NUCLEUS_TABLES |
| PARTITIONS |
| PARTITION_EVENTS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_PRIVS |
| PART_COL_STATS |
| PART_PRIVS |
| ROLES |
| ROLE_MAP |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| TBL_COL_PRIVS |
| TBL_PRIVS |
| TXNS |
| TXN_COMPONENTS |
| TYPES |
| TYPE_FIELDS |
| VERSION |
| WRITE_SET |
+---------------------------+
57 rows in set (0.00 sec)
好吧,,,還不少,,,
先看下DBS表的內容(Hive支持大小寫關鍵字):
mysql> SELECT * FROM DBS;
+-------+-----------------------+----------------------------------------------+---------+------------+------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE |
+-------+-----------------------+----------------------------------------------+---------+------------+------------+
| 1 | Default Hive database | hdfs://node1:8020/user/hive/warehouse | default | public | ROLE |
| 6 | NULL | hdfs://node1:8020/user/hive/warehouse/aaa.db | aaa | root | USER |
+-------+-----------------------+----------------------------------------------+---------+------------+------------+
2 rows in set (0.00 sec)
原來這貨存盤了Hive中所有資料庫的資訊,
再看下TBLS表的內容:
mysql> SELECT * FROM TBLS;
+--------+-------------+-------+------------------+-------+-----------+-------+----------+---------------+--------------------+--------------------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT |
+--------+-------------+-------+------------------+-------+-----------+-------+----------+---------------+--------------------+--------------------+
| 1 | 1619879908 | 1 | 0 | root | 0 | 1 | tb_word | MANAGED_TABLE | NULL | NULL |
| 2 | 1619880547 | 1 | 0 | root | 0 | 2 | tb_word2 | MANAGED_TABLE | NULL | NULL |
| 3 | 1619882149 | 1 | 0 | root | 0 | 3 | tb_house | MANAGED_TABLE | NULL | NULL |
+--------+-------------+-------+------------------+-------+-----------+-------+----------+---------------+--------------------+--------------------+
3 rows in set (0.00 sec)
原來這貨存盤了Hive中所有表的資訊,SD_ID是個神馬玩意兒?不妨看看SDS表:
mysql> SELECT * FROM SDS;
+-------+-------+------------------------------------------+---------------+---------------------------+------------------------------------------------+-------------+------------------------------------------------------------+----------+
| SD_ID | CD_ID | INPUT_FORMAT | IS_COMPRESSED | IS_STOREDASSUBDIRECTORIES | LOCATION | NUM_BUCKETS | OUTPUT_FORMAT | SERDE_ID |
+-------+-------+------------------------------------------+---------------+---------------------------+------------------------------------------------+-------------+------------------------------------------------------------+----------+
| 1 | 1 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://node1:8020/user/hive/warehouse/tb_word | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 1 |
| 2 | 2 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://node1:8020/user/hive/warehouse/tb_word2 | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 2 |
| 3 | 3 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://node1:8020/user/hive/warehouse/tb_house | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 3 |
+-------+-------+------------------------------------------+---------------+---------------------------+------------------------------------------------+-------------+------------------------------------------------------------+----------+
3 rows in set (0.00 sec)
原來SD_ID是個外鍵,,,
那么真相其實很簡單:
所有Hive中資料庫、表與HDFS的映射關系都存盤在元資料中,Hive服務端會讀取元資料找到這張表對應的HDFS資料的路徑從而找到該檔案,
資料庫就是HDFS目錄,表也是HDFS目錄(資料庫目錄深一層),表的資料是指向的HDFS檔案(再深入一層),
還可以安裝hive-standalone-metastore-3.0.0,這貨是Hive的精簡版,只保留了Hive中將檔案映射為Hive表的功能(閹割了轉換為MapReduce的功能),
Hive轉換MapReduce
功能映射
select 1 from 2 where 3 group by 4 having 5 order by 6 limit 7
Hive與MySQL的執行順序基本一致,,,
1出的內容決定了Hive的SQL執行后再結果中顯示的列的欄位及對應的內容,
這種完整的SQL陳述句當然是按五大階段的MapReduce來跑的,,,
| MapReduce階段 | SQL引數 |
|---|---|
| Input | 2 |
| Map | 1,3 |
| Shuffle | 4,6 |
| Reduce | 5,7 |
| Output | 保存SQL |
由于不一定會保存,Output階段可能并不會保存到檔案,
執行決議
使用exit退出MySQL,重新進入Hive,
hive> explain select region,count(*) as numb from tb_house where region != '浦東' group by region order by numb;
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-2 depends on stages: Stage-1
Stage-0 depends on stages: Stage-2
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: tb_house
Statistics: Num rows: 22259 Data size: 2225948 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (region <> '浦東') (type: boolean)
Statistics: Num rows: 22259 Data size: 2225948 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: count()
keys: region (type: string)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 22259 Data size: 2225948 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string)
sort order: +
Map-reduce partition columns: _col0 (type: string)
Statistics: Num rows: 22259 Data size: 2225948 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: bigint)
Reduce Operator Tree:
Group By Operator
aggregations: count(VALUE._col0)
keys: KEY._col0 (type: string)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 11129 Data size: 1112923 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazybinary.LazyBinarySerDe
Stage: Stage-2
Map Reduce
Map Operator Tree:
TableScan
Reduce Output Operator
key expressions: _col1 (type: bigint)
sort order: +
Statistics: Num rows: 11129 Data size: 1112923 Basic stats: COMPLETE Column stats: NONE
value expressions: _col0 (type: string)
Reduce Operator Tree:
Select Operator
expressions: VALUE._col0 (type: string), KEY.reducesinkkey0 (type: bigint)
outputColumnNames: _col0, _col1
Statistics: Num rows: 11129 Data size: 1112923 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 11129 Data size: 1112923 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 2.284 seconds, Fetched: 69 row(s)
其中,explain是用于查看執行計劃的,換句話說,explain開頭的供Hive執行的SQL陳述句并不會真正運行并計算,只是展示下預期的運行程序,<>代表不等于,
此例中顯示總共會劃分為3步,運行次序有嚴格的依賴性,必須先運行Stage-1(使用了region作K2),然后是Stage-2,最后是Stage-0,_col0, _col1則是個數,
metastore
功能
metastore字面意思就是元資料存盤,
Hive中的元資料記錄了Hive中所有物件資訊:資料庫資訊、表資訊、欄位資訊,
Hive中的元資料重點記錄了Hive表與HDFS檔案的映射關系,每次創建表關聯檔案,Hive都會自動創建表的元資料,每次查詢表的資料,Hive都會從元資料中獲取表對應的HDFS資訊,
三種方式
嵌入式資料庫
Local/Embedded Metastore Database (Derby),存盤在derby中,Apache Derby是個完全用java撰寫的資料庫,類似sqlite,免配置C/S即可使用,
本地資料庫
存盤在本地MySQL中,直接訪問,
遠程Metastore服務
存盤在MySQL中,但是是通過一個行程來進行訪問,
兩個位置
默認位置
Hive自帶的Derby資料庫,不能共享,不能啟動多個實體,一般不用,
自定義位置
自定義將元資料存盤在其他資料庫中,MySQL、Oracle之類的普通資料庫都可以,∵MySQL免費,∴一般存盤在MySQL中,
共享
Hive默認是轉換為MapReduce程式,但是眼下MapReduce性能堪憂將近淘汰,顯然大概率不會使用Hive來實作資料倉庫中的分布式計算,SparkSQL、Impala、Presto等工具更快,性能更好,語法都兼容Hive的語法,應該讓這些更先進的框架能夠訪問Hive的資料,
只需要讀取Hive元資料就能知道Hive有哪些表,中間可能需要決議元資料,但是很多框架都需要訪問Hive的元資料,都自行封裝代碼決議元資料就會導致程式冗余,
metastore服務
Java有JDBC訪問資料庫,C#可以使用ADO.NET和ASP.NET訪問SQL server,Hive則是提供了metastore服務來實作元資料共享服務,metastore服務專門負責管理Hive的元資料,并且接受所有需要訪問元資料的請求,
metastore配置
為了避免出錯,先quit;退出Hive,然后關掉多余的行程,jps查看3個節點確保行程殺干凈,
stop-dfs.sh
stop-yarn.sh
沒有殺掉的行程可以考慮kill -9 ,
cd /export/server/hive-2.1.0-bin/conf
vim hive-site.xml
找個空位按o向下插入:
<property>
<name>hive.metastore.uris</name>
<value>thrift://node3:9083</value>
</property>
記得:wq保存,這一步設定了metastore是通過node3的9083埠訪問,
metastore啟動
由于配置了Metastore,Hive已經不再能夠直接訪問MySQL中的元資料,以后必須先啟動metastore,再啟動Hive的服務端,
不服可以試試直接啟動Hive,會報錯:
Caused by: java.net.ConnectException: 拒絕連接 (Connection refused)
metastore服務已經不再允許Hive自行連接MySQL訪問元資料,它要全權管理,
老老實實正常啟動:
cd /export/server/hive-2.1.0-bin/
hive --service metastore
有時候一次啟動不成功,只好多來幾次,,,

由于這貨是個前臺程式,會一直霸占命令列,,,沒辦法操作了,,,先去虛擬機:
手敲一遍,,,先把Hive啟動,或者新建個命令列視窗啟動,當然還是啟動不了的!!!
使用:
netstat -atunlp |grep 9083
發現metastore服務啟動成功:
[root@node3 hive-2.1.0-bin]# netstat -atunlp |grep 9083
tcp 0 0 0.0.0.0:9083 0.0.0.0:* LISTEN 3820/java
仔細檢查,是報錯:
The reported blocks 50 has reached the threshold 0.9990 of total blocks 50. The number of live datanodes 3 has reached the minimum number 0. In safe mode extension. Safe mode will be turned off automatically in 2 seconds.
不開啟HDFS和YARN就會因為分布式存盤空間達到0.9990以上的占有率【這句話當然是廢話,,,】,從而不能寫入HDFS檔案,只好進入了安全模式,,,
啟動HDFS:
start-dfs.sh
啟動YARN:
start-yarn.sh
要多等一會兒,,,然后使用Hive命令即可成功啟動Hive,
虛擬機使用jps查看行程:
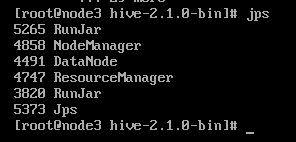
發現有2個RunJar,一個5265,一個3820,顯然3820的這個RunJar先啟動,它是metastore服務,5265的RunJar后啟動,它是Hive的行程,
一波三折!!!
還有很長的路要走:Hive入門(二)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282598.html
標籤:其他
上一篇:ambari集群安裝hdp
下一篇:2021年大資料Flink(三十九):???????Table與SQL ??????總結 Flink-SQL常用算子