目錄
總結 Flink-SQL常用算子
SELECT
WHERE
???????DISTINCT
???????GROUP BY
???????UNION 和 UNION ALL
???????JOIN
??????????????Group Window
???????Tumble Window
???????Hop Window
???????Session Window
總結 Flink-SQL常用算子
SELECT
SELECT 用于從 DataSet/DataStream 中選擇資料,用于篩選出某些列,
示例:
SELECT * FROM Table;// 取出表中的所有列
SELECT name,age FROM Table;// 取出表中 name 和 age 兩列
與此同時 SELECT 陳述句中可以使用函式和別名,例如我們上面提到的 WordCount 中:
SELECT word, COUNT(word) FROM table GROUP BY word;
???????WHERE
WHERE 用于從資料集/流中過濾資料,與 SELECT 一起使用,用于根據某些條件對關系做水平分割,即選擇符合條件的記錄,
示例:
SELECT name,age FROM Table where name LIKE ‘% 小明 %’;
SELECT * FROM Table WHERE age = 20;
WHERE 是從原資料中進行過濾,那么在 WHERE 條件中,Flink SQL 同樣支持 =、<、>、<>、>=、<=,以及 AND、OR 等運算式的組合,最終滿足過濾條件的資料會被選擇出來,并且 WHERE 可以結合 IN、NOT IN 聯合使用,舉個例子:
SELECT name, age
FROM Table
WHERE name IN (SELECT name FROM Table2)
???????DISTINCT
DISTINCT 用于從資料集/流中去重根據 SELECT 的結果進行去重,
示例:
SELECT DISTINCT name FROM Table;
對于流式查詢,計算查詢結果所需的 State 可能會無限增長,用戶需要自己控制查詢的狀態范圍,以防止狀態過大,
???????GROUP BY
GROUP BY 是對資料進行分組操作,例如我們需要計算成績明細表中,每個學生的總分,
示例:
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name;
???????UNION 和 UNION ALL
UNION 用于將兩個結果集合并起來,要求兩個結果集欄位完全一致,包括欄位型別、欄位順序,
不同于 UNION ALL 的是,UNION 會對結果資料去重,
示例:
SELECT * FROM T1 UNION (ALL) SELECT * FROM T2;
???????JOIN
JOIN 用于把來自兩個表的資料聯合起來形成結果表,Flink 支持的 JOIN 型別包括:
JOIN - INNER JOIN
LEFT JOIN - LEFT OUTER JOIN
RIGHT JOIN - RIGHT OUTER JOIN
FULL JOIN - FULL OUTER JOIN
這里的 JOIN 的語意和我們在關系型資料庫中使用的 JOIN 語意一致,
示例:
JOIN(將訂單表資料和商品表進行關聯)
SELECT * FROM Orders INNER JOIN Product ON Orders.productId = Product.id
LEFT JOIN 與 JOIN 的區別是當右表沒有與左邊相 JOIN 的資料時候,右邊對應的欄位補 NULL 輸出,RIGHT JOIN 相當于 LEFT JOIN 左右兩個表互動一下位置,FULL JOIN 相當于 RIGHT JOIN 和 LEFT JOIN 之后進行 UNION ALL 操作,
示例:
SELECT * FROM Orders LEFT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders RIGHT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders FULL OUTER JOIN Product ON Orders.productId = Product.id
??????????????Group Window
根據視窗資料劃分的不同,目前 Apache Flink 有如下 3 種 Bounded Window:
Tumble,滾動視窗,視窗資料有固定的大小,視窗資料無疊加;
Hop,滑動視窗,視窗資料有固定大小,并且有固定的視窗重建頻率,視窗資料有疊加;
Session,會話視窗,視窗資料沒有固定的大小,根據視窗資料活躍程度劃分視窗,視窗資料無疊加,
???????Tumble Window
Tumble 滾動視窗有固定大小,視窗資料不重疊,具體語意如下:
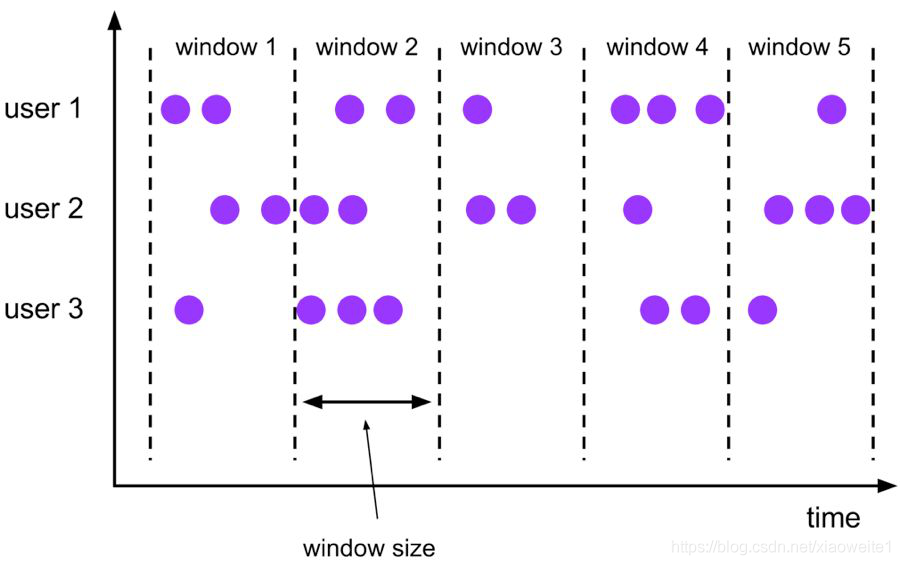
Tumble 滾動視窗對應的語法如下:
SELECT
[gk],
[TUMBLE_START(timeCol, size)],
[TUMBLE_END(timeCol, size)],
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], TUMBLE(timeCol, size)
其中:
[gk] 決定了是否需要按照欄位進行聚合;
TUMBLE_START 代表視窗開始時間;
TUMBLE_END 代表視窗結束時間;
timeCol 是流表中表示時間欄位;
size 表示視窗的大小,如 秒、分鐘、小時、天,
舉個例子,假如我們要計算每個人每天的訂單量,按照 user 進行聚合分組:
SELECT user, TUMBLE_START(rowtime, INTERVAL ‘1’ DAY) as wStart, SUM(amount)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL ‘1’ DAY), user;
???????Hop Window
Hop 滑動視窗和滾動視窗類似,視窗有固定的 size,與滾動視窗不同的是滑動視窗可以通過 slide 引數控制滑動視窗的新建頻率,因此當 slide 值小于視窗 size 的值的時候多個滑動視窗會重疊,具體語意如下:
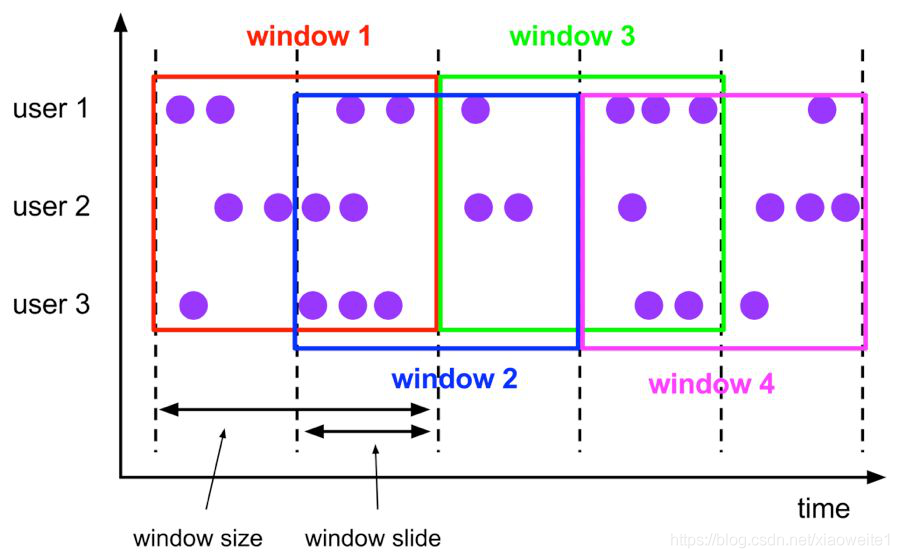
Hop 滑動視窗對應語法如下:
SELECT
[gk],
[HOP_START(timeCol, slide, size)] ,
[HOP_END(timeCol, slide, size)],
agg1(col1),
...
aggN(colN)
FROM Tab1
GROUP BY [gk], HOP(timeCol, slide, size)
每次欄位的意思和 Tumble 視窗類似:
[gk] 決定了是否需要按照欄位進行聚合;
HOP_START 表示視窗開始時間;
HOP_END 表示視窗結束時間;
timeCol 表示流表中表示時間欄位;
slide 表示每次視窗滑動的大小;
size 表示整個視窗的大小,如 秒、分鐘、小時、天,
舉例說明,我們要每過一小時計算一次過去 24 小時內每個商品的銷量:
SELECT product, SUM(amount)
FROM Orders
GROUP BY product,HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '1' DAY)
???????Session Window
會話時間視窗沒有固定的持續時間,但它們的界限由 interval 不活動時間定義,即如果在定義的間隙期間沒有出現事件,則會話視窗關閉,
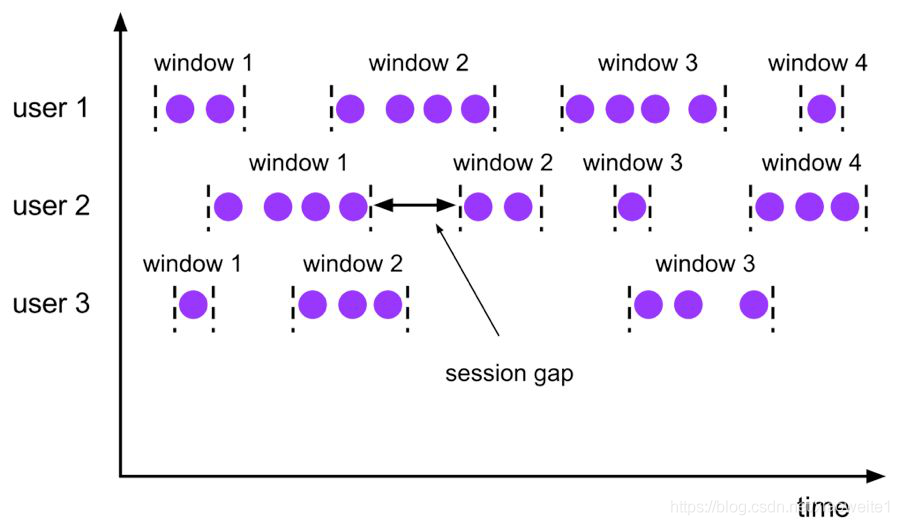
Seeeion 會話視窗對應語法如下:
SELECT
[gk],
SESSION_START(timeCol, gap) AS winStart,
SESSION_END(timeCol, gap) AS winEnd,
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], SESSION(timeCol, gap)
[gk] 決定了是否需要按照欄位進行聚合;
SESSION_START 表示視窗開始時間;
SESSION_END 表示視窗結束時間;
timeCol 表示流表中表示時間欄位;
gap 表示視窗資料非活躍周期的時長,
例如,我們需要計算每個用戶訪問時間 12 小時內的訂單量:
SELECT user, SESSION_START(rowtime, INTERVAL ‘12’ HOUR) AS sStart, SESSION_ROWTIME(rowtime, INTERVAL ‘12’ HOUR) AS sEnd, SUM(amount)
FROM Orders
GROUP BY SESSION(rowtime, INTERVAL ‘12’ HOUR), user
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282599.html
標籤:其他
上一篇:Hive入門(一)