內容匯總:https://blog.csdn.net/weixin_43093481/article/details/114989382?spm=1001.2014.3001.5501
課程筆記:1.1 監督學習與情感分析(Supervised ML & Sentiment Analysis)
代碼:https://github.com/Ogmx/Natural-Language-Processing-Specialization
——————————————————————————————————————————
作業 1: 邏輯回歸(Logistic Regression)
學習目標:
? 學習邏輯回歸,你將會學習使用邏輯回歸對推特進行情感分析,給出一個推特,你要判斷其是正向情感還是負向情感,
具體而言,將會學習:
- 給出一段文本,學習如何提取特征用于邏輯回歸
- 從零開始實作邏輯回歸
- 應用邏輯回歸進行NLP任務
- 測驗邏輯回歸演算法
- 進行錯誤分析
我們將使用一系列推特資料,在最后你的模型應該能得到99%的準確率,
匯入函式和資料
# run this cell to import nltk
import nltk
from os import getcwd
下載資料
從該地址下載本實驗需要的資料documentation for the twitter_samples dataset.
- twitter_samples: 執行以下命令來下載資料
nltk.download('twitter_samples')
- stopwords: 執行以下命令來下載停用詞詞典:
nltk.download('stopwords')
從 utils.py 匯入幫助函式:
process_tweet(): 清理文本、拆分單詞、去停用詞、詞根化build_freqs(): 用于統計語料庫中各單詞被標記為"1"或"0"次數(即正向和負向情感),然后構建"freqs"詞典,其中鍵為(word,label) tuple,值為出現次數
# add folder, tmp2, from our local workspace containing pre-downloaded corpora files to nltk's data path
# this enables importing of these files without downloading it again when we refresh our workspace
filePath = f"{getcwd()}/../tmp2/"
nltk.data.path.append(filePath)
import numpy as np
import pandas as pd
from nltk.corpus import twitter_samples
from utils import process_tweet, build_freqs
準備資料
twitter_samples中包含5000條正向推特資料集,5000條負向推特資料集,整體10,000條推特資料集- 如果直接使用3個資料集,將會包含重復推特
- 因此只使用正向資料集和負向資料集
# select the set of positive and negative tweets
all_positive_tweets = twitter_samples.strings('positive_tweets.json')
all_negative_tweets = twitter_samples.strings('negative_tweets.json')
- 資料劃分: 20% 作為測驗集, 80% 作為訓練集
# split the data into two pieces, one for training and one for testing (validation set)
test_pos = all_positive_tweets[4000:]
train_pos = all_positive_tweets[:4000]
test_neg = all_negative_tweets[4000:]
train_neg = all_negative_tweets[:4000]
train_x = train_pos + train_neg
test_x = test_pos + test_neg
- 對正向標簽和負向標簽建立numpy陣列
# combine positive and negative labels
train_y = np.append(np.ones((len(train_pos), 1)), np.zeros((len(train_neg), 1)), axis=0)
test_y = np.append(np.ones((len(test_pos), 1)), np.zeros((len(test_neg), 1)), axis=0)
# Print the shape train and test sets
print("train_y.shape = " + str(train_y.shape))
print("test_y.shape = " + str(test_y.shape))
train_y.shape = (8000, 1)
test_y.shape = (2000, 1)
- 使用
build_freqs()函式構建頻率詞典.- 強烈建議在
utils.py中閱讀build_freqs()函式代碼來理解其原理
- 強烈建議在
for y,tweet in zip(ys, tweets):
for word in process_tweet(tweet):
pair = (word, y)
if pair in freqs:
freqs[pair] += 1
else:
freqs[pair] = 1
# create frequency dictionary
freqs = build_freqs(train_x, train_y)
# check the output
print("type(freqs) = " + str(type(freqs)))
print("len(freqs) = " + str(len(freqs.keys())))
type(freqs) = <class ‘dict’>
len(freqs) = 11346
處理推特
使用 process_tweet() 函式對推特中的每個單詞進行向量化,去停用詞和詞根化
# test the function below
print('This is an example of a positive tweet: \n', train_x[0])
print('\nThis is an example of the processed version of the tweet: \n', process_tweet(train_x[0]))
This is an example of a positive tweet:
#FollowFriday @France_Inte @PKuchly57 @Milipol_Paris for being top engaged members in my community this week 😃
This is an example of the processed version of the tweet:
[‘followfriday’, ‘top’, ‘engag’, ‘member’, ‘commun’, ‘week’, ‘😃’]
Part 1: 邏輯回歸
Part 1.1: Sigmoid
將會學習如何用邏輯回歸進行文本分類
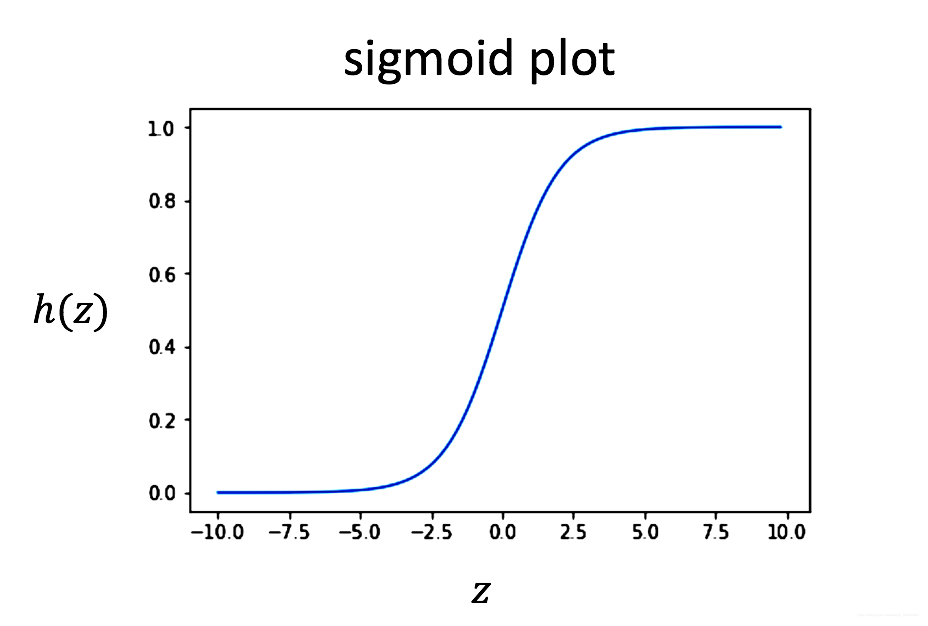
- sigmoid 函式定義:
h
(
z
)
=
1
1
+
exp
?
?
z
(1)
h(z) = \frac{1}{1+\exp^{-z}} \tag{1}
h(z)=1+exp?z1?(1)
將輸入’z’映射到0~1的區間中,也可以將其理解為概率
- numpy.exp
# UNQ_C1 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)
def sigmoid(z):
'''
Input:
z: is the input (can be a scalar or an array)
Output:
h: the sigmoid of z
'''
### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###
# calculate the sigmoid of z
h = 1/(1+np.exp(-z))
### END CODE HERE ###
return h
# Testing your function
if (sigmoid(0) == 0.5):
print('SUCCESS!')
else:
print('Oops!')
if (sigmoid(4.92) == 0.9927537604041685):
print('CORRECT!')
else:
print('Oops again!')
SUCCESS!
CORRECT!
邏輯回歸: 回歸與sigmoid
邏輯回歸采用一種標準線性回歸方法,并用sigmoid函式作為激活函式
回歸:
z
=
θ
0
x
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
θ
N
x
N
z = \theta_0 x_0 + \theta_1 x_1 + \theta_2 x_2 + ... \theta_N x_N
z=θ0?x0?+θ1?x1?+θ2?x2?+...θN?xN?
其中
θ
\theta
θ 表示權值. 在深度學習中常用 w 向量表示. 在本實驗中,用
θ
\theta
θ 來表示權值
邏輯回歸:
h
(
z
)
=
1
1
+
exp
?
?
z
h(z) = \frac{1}{1+\exp^{-z}}
h(z)=1+exp?z1?
z
=
θ
0
x
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
θ
N
x
N
z = \theta_0 x_0 + \theta_1 x_1 + \theta_2 x_2 + ... \theta_N x_N
z=θ0?x0?+θ1?x1?+θ2?x2?+...θN?xN?
其中 ‘z’ 為’logits’,即輸出.
Part 1.2 損失函式與梯度
使用全部樣本的平均對數損失作為邏輯回歸的損失函式:
J ( θ ) = ? 1 m ∑ i = 1 m y ( i ) log ? ( h ( z ( θ ) ( i ) ) ) + ( 1 ? y ( i ) ) log ? ( 1 ? h ( z ( θ ) ( i ) ) ) (5) J(\theta) = -\frac{1}{m} \sum_{i=1}^m y^{(i)}\log (h(z(\theta)^{(i)})) + (1-y^{(i)})\log (1-h(z(\theta)^{(i)}))\tag{5} J(θ)=?m1?i=1∑m?y(i)log(h(z(θ)(i)))+(1?y(i))log(1?h(z(θ)(i)))(5)
- m m m 是訓練樣本數
- y ( i ) y^{(i)} y(i) 是第i個樣本的真實標簽
- h ( z ( θ ) ( i ) ) h(z(\theta)^{(i)}) h(z(θ)(i)) 是模型預測的第i個樣本的標簽
對一個訓練樣本的損失函式:
L
o
s
s
=
?
1
×
(
y
(
i
)
log
?
(
h
(
z
(
θ
)
(
i
)
)
)
+
(
1
?
y
(
i
)
)
log
?
(
1
?
h
(
z
(
θ
)
(
i
)
)
)
)
Loss = -1 \times \left( y^{(i)}\log (h(z(\theta)^{(i)})) + (1-y^{(i)})\log (1-h(z(\theta)^{(i)})) \right)
Loss=?1×(y(i)log(h(z(θ)(i)))+(1?y(i))log(1?h(z(θ)(i))))
- 所有 h h h值為0~1,其對數為負,因此需要在最前面乘上-1
- 當模型預測結果為1 ( h ( z ( θ ) ) = 1 h(z(\theta)) = 1 h(z(θ))=1), y y y 的真實標簽也為1時,則該樣本損失值為0
- 同理,模型預測結果為0 ( h ( z ( θ ) ) = 0 h(z(\theta)) = 0 h(z(θ))=0), y y y 的真實標簽也為0時,則該樣本損失值為0
- 然而,當模型預測結果接近1 ( h ( z ( θ ) ) = 0.9999 h(z(\theta)) = 0.9999 h(z(θ))=0.9999),真實標簽為0時,第二項的對數損失將為一個很大的負數,當乘上-1后,變為很大的正數, ? 1 × ( 1 ? 0 ) × l o g ( 1 ? 0.9999 ) ≈ 9.2 -1 \times (1 - 0) \times log(1 - 0.9999) \approx 9.2 ?1×(1?0)×log(1?0.9999)≈9.2 即預測值與真實值相差越大,損失值越大
# verify that when the model predicts close to 1, but the actual label is 0, the loss is a large positive value
-1 * (1 - 0) * np.log(1 - 0.9999) # loss is about 9.2
9.210340371976294
- 同理,如果模型預測結果接近0 ( h ( z ) = 0.0001 h(z) = 0.0001 h(z)=0.0001),而真實標簽為1時,第一項的損失值很大: ? 1 × l o g ( 0.0001 ) ≈ 9.2 -1 \times log(0.0001) \approx 9.2 ?1×log(0.0001)≈9.2,
# verify that when the model predicts close to 0 but the actual label is 1, the loss is a large positive value
-1 * np.log(0.0001) # loss is about 9.2
9.210340371976182
更新權值
為了更新權值向量
θ
\theta
θ, 將使用梯度下降法來迭代提升模型表現
以
θ
j
\theta_j
θj?為權值計算出的的損失函式
J
J
J的梯度為:
?
θ
j
J
(
θ
)
=
1
m
∑
i
=
1
m
(
h
(
i
)
?
y
(
i
)
)
x
j
(5)
\nabla_{\theta_j}J(\theta) = \frac{1}{m} \sum_{i=1}^m(h^{(i)}-y^{(i)})x_j \tag{5}
?θj??J(θ)=m1?i=1∑m?(h(i)?y(i))xj?(5)
- ‘i’ 是全部’m’個訓練樣本的索引
- ‘j’ 是權值 θ j \theta_j θj? 的索引, 而 x j x_j xj? 是與 θ j \theta_j θj? 相匹配的特征
- 通過減去一部分梯度值來更新權值
θ
j
\theta_j
θj?,該部分由學習率
α
\alpha
α 決定
θ j = θ j ? α × ? θ j J ( θ ) \theta_j = \theta_j - \alpha \times \nabla_{\theta_j}J(\theta) θj?=θj??α×?θj??J(θ) - 學習率 α \alpha α 用來控制每步更新的大小/幅度
實作梯度下降
- 迭代次數
num_iters是使用整個訓練集的次數. - 在每次迭代中,都要用全部訓練樣本計算損失函式(共
m個訓練樣本) - 不是一次更新一個權值
θ
i
\theta_i
θi?,而是更新所有權值用向量表示為:
θ = ( θ 0 θ 1 θ 2 ? θ n ) \mathbf{\theta} = \begin{pmatrix} \theta_0 \\ \theta_1 \\ \theta_2 \\ \vdots \\ \theta_n \end{pmatrix} θ=????????θ0?θ1?θ2??θn?????????? - θ \mathbf{\theta} θ 的維度為 (n+1, 1), 其中 ‘n’ 是特征數, 用 θ 0 \theta_0 θ0? 表示偏差(bias) (與其相匹配的特征值 x 0 \mathbf{x_0} x0? 為 1).
- 輸出 ‘logits’, ‘z’, 通過特征矩陣’x’與權值向量’theta’相乘得到
z
=
x
θ
z = \mathbf{x}\mathbf{\theta}
z=xθ
- x \mathbf{x} x 的維度為 (m, n+1)
- θ \mathbf{\theta} θ: 的維度為 (n+1, 1)
- z \mathbf{z} z: 的維度為 (m, 1)
- 預測值 ‘h’, 通過對輸出’z’應該sigmoid函式得到: h ( z ) = s i g m o i d ( z ) h(z) = sigmoid(z) h(z)=sigmoid(z), 其維度為 (m,1).
- 損失函式
J
J
J 通過對向量 ‘y’ 和 ‘log(h)’ 計算點乘得到,因為’y’ 和 ‘h’ 都是維度為 (m,1) 的列向量, 轉置左側的向量, 使用矩陣乘法即可計算各行和各列的點乘
J = ? 1 m × ( y T ? l o g ( h ) + ( 1 ? y ) T ? l o g ( 1 ? h ) ) J = \frac{-1}{m} \times \left(\mathbf{y}^T \cdot log(\mathbf{h}) + \mathbf{(1-y)}^T \cdot log(\mathbf{1-h}) \right) J=m?1?×(yT?log(h)+(1?y)T?log(1?h)) - 對于theta的更新同樣是向量化的,因為
x
\mathbf{x}
x 的維度為 (m, n+1),
h
\mathbf{h}
h 和
y
\mathbf{y}
y 的維度都是 (m, 1), 需要對
x
\mathbf{x}
x 進行轉置然后將其放在左側以進行矩陣乘法,最終得到的結果維度為 (n+1, 1) :
θ = θ ? α m × ( x T ? ( h ? y ) ) \mathbf{\theta} = \mathbf{\theta} - \frac{\alpha}{m} \times \left( \mathbf{x}^T \cdot \left( \mathbf{h-y} \right) \right) θ=θ?mα?×(xT?(h?y))
- 使用 np.dot 實作矩陣乘法.
- 確保 -1/m 為浮點數, 對分子或分母 (或全部), 使用 `float(1)`, 或 `1.` 將其轉換為float型別.
# UNQ_C2 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)
def gradientDescent(x, y, theta, alpha, num_iters):
'''
Input:
x: matrix of features which is (m,n+1)
y: corresponding labels of the input matrix x, dimensions (m,1)
theta: weight vector of dimension (n+1,1)
alpha: learning rate
num_iters: number of iterations you want to train your model for
Output:
J: the final cost
theta: your final weight vector
Hint: you might want to print the cost to make sure that it is going down.
'''
### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###
# get 'm', the number of rows in matrix x
m = x.shape[0]
for i in range(0, num_iters):
# get z, the dot product of x and theta
z = np.dot(x,theta)
# get the sigmoid of z
h = sigmoid(z)
# calculate the cost function
J = -1/m * (np.dot(y.T,np.log(h)) + np.dot((1-y).T,np.log(1-h)))
# update the weights theta
theta = theta - alpha/m * (np.dot(x.T,(h-y)))
### END CODE HERE ###
J = float(J)
return J, theta
# Check the function
# Construct a synthetic test case using numpy PRNG functions
np.random.seed(1)
# X input is 10 x 3 with ones for the bias terms
tmp_X = np.append(np.ones((10, 1)), np.random.rand(10, 2) * 2000, axis=1)
# Y Labels are 10 x 1
tmp_Y = (np.random.rand(10, 1) > 0.35).astype(float)
# Apply gradient descent
tmp_J, tmp_theta = gradientDescent(tmp_X, tmp_Y, np.zeros((3, 1)), 1e-8, 700)
print(f"The cost after training is {tmp_J:.8f}.")
print(f"The resulting vector of weights is {[round(t, 8) for t in np.squeeze(tmp_theta)]}")
The cost after training is 0.67094970.
The resulting vector of weights is [4.1e-07, 0.00035658, 7.309e-05]
Part 2: 提取特征
- 給出一系列推特,提取其特征并存入矩陣中,將提取兩類特征
- 第一類特征是該推特中正向詞出現次數
- 第二類特征是該推特中負向詞出現次數
- 然后應用這些特征訓練邏輯回歸分類器.
- 在測驗集上測驗該模型
實作 extract_features 函式
- 該函式針對單個推特進行特征提取.
- 使用
process_tweet()函式處理推特并用串列存盤推特中單詞. - 使用回圈依次處理串列中的各單詞
- 對于每個單詞, 通過
freqs字典,統計其被標記為’1’的次數 (即查找鍵 (word, 1.0)) - 同上,統計其被標記為’0’的次數. (即查找鍵 (word, 0.0))
- 對于每個單詞, 通過
- 處理好當 (word, label) 鍵不在字典中的情況.
- 關于 `.get()` 的用法. 例子 example
# UNQ_C3 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)
def extract_features(tweet, freqs):
'''
Input:
tweet: a list of words for one tweet
freqs: a dictionary corresponding to the frequencies of each tuple (word, label)
Output:
x: a feature vector of dimension (1,3)
'''
# process_tweet tokenizes, stems, and removes stopwords
word_l = process_tweet(tweet)
# 3 elements in the form of a 1 x 3 vector
x = np.zeros((1, 3))
#bias term is set to 1
x[0,0] = 1
### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###
# loop through each word in the list of words
for word in word_l:
# increment the word count for the positive label 1
x[0,1] += freqs.get((word,1),0)
# increment the word count for the negative label 0
x[0,2] += freqs.get((word,0),0)
### END CODE HERE ###
assert(x.shape == (1, 3))
return x
# Check your function
# test 1
# test on training data
tmp1 = extract_features(train_x[0], freqs)
print(tmp1)
[[1.00e+00 3.02e+03 6.10e+01]]
# test 2:
# check for when the words are not in the freqs dictionary
tmp2 = extract_features('blorb bleeeeb bloooob', freqs)
print(tmp2)
[[1. 0. 0.]]
Part 3: 訓練模型
為了訓練模型:
- 將各訓練樣本的特征構成矩陣
X. - 使用之前實作的
gradientDescent函式進行梯度下降
# collect the features 'x' and stack them into a matrix 'X'
X = np.zeros((len(train_x), 3))
for i in range(len(train_x)):
X[i, :]= extract_features(train_x[i], freqs)
# training labels corresponding to X
Y = train_y
# Apply gradient descent
J, theta = gradientDescent(X, Y, np.zeros((3, 1)), 1e-9, 1500)
print(f"The cost after training is {J:.8f}.")
print(f"The resulting vector of weights is {[round(t, 8) for t in np.squeeze(theta)]}")
The cost after training is 0.24216529.
The resulting vector of weights is [7e-08, 0.0005239, -0.00055517]
Part 4: 測驗邏輯回歸模型
為了測驗邏輯回歸模型,應輸入一些非樣本資料,即模型從未見過的資料
實作函式: predict_tweet
預測一個推特是正向還是負向
- 給出一個推特,對其進行預處理和特征提取.
- 對提取出的特征應用訓練好的模型得到輸出’z’
- 對輸出’z’使用sigmoid函式,得到最終預測結果 (一個0~1之間的值).
y p r e d = s i g m o i d ( x ? θ ) y_{pred} = sigmoid(\mathbf{x} \cdot \theta) ypred?=sigmoid(x?θ)
# UNQ_C4 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)
def predict_tweet(tweet, freqs, theta):
'''
Input:
tweet: a string
freqs: a dictionary corresponding to the frequencies of each tuple (word, label)
theta: (3,1) vector of weights
Output:
y_pred: the probability of a tweet being positive or negative
'''
### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###
# extract the features of the tweet and store it into x
x = extract_features(tweet,freqs)
# make the prediction using x and theta
y_pred = sigmoid(np.dot(x,theta))
### END CODE HERE ###
return y_pred
# Run this cell to test your function
for tweet in ['I am happy', 'I am bad', 'this movie should have been great.', 'great', 'great great', 'great great great', 'great great great great']:
print( '%s -> %f' % (tweet, predict_tweet(tweet, freqs, theta)))
I am happy -> 0.518580
I am bad -> 0.494339
this movie should have been great. -> 0.515331
great -> 0.515464
great great -> 0.530898
great great great -> 0.546273
great great great great -> 0.561561
使用測驗集測驗模型效果
在使用訓練集對模型進行訓練后,使用測驗集驗證其在真實情況中的表現
實作函式 test_logistic_regression
- 給出測驗資料和訓練好的模型權值,計算模型預測準確率
- 使用
predict_tweet()函式對測驗集中每條推特進行預測 - 如果預測值>0.5,則將模型分類結果
y_hat設為1,反之將y_hat設為0 - 當
y_hat與test_y相等時,則認為預測準確,預測準確樣本數除樣本總數m,即為預測準確率
- 使用 np.asarray() 將 list 轉換為numpy array
- 使用 np.squeeze() 將維度為 (m,1) 的array轉化為維度為 (m,) 的array
# UNQ_C5 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)
def test_logistic_regression(test_x, test_y, freqs, theta):
"""
Input:
test_x: a list of tweets
test_y: (m, 1) vector with the corresponding labels for the list of tweets
freqs: a dictionary with the frequency of each pair (or tuple)
theta: weight vector of dimension (3, 1)
Output:
accuracy: (# of tweets classified correctly) / (total # of tweets)
"""
### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###
# the list for storing predictions
y_hat = []
for tweet in test_x:
# get the label prediction for the tweet
y_pred = predict_tweet(tweet, freqs, theta)
if y_pred > 0.5:
# append 1.0 to the list
y_hat.append(1)
else:
# append 0 to the list
y_hat.append(0)
# With the above implementation, y_hat is a list, but test_y is (m,1) array
# convert both to one-dimensional arrays in order to compare them using the '==' operator
cnt=0
test_y = test_y.squeeze()
for i in range(0,len(y_hat)):
if y_hat[i]==test_y[i]:
cnt+=1
accuracy = cnt / len(y_hat)
### END CODE HERE ###
return accuracy
tmp_accuracy = test_logistic_regression(test_x, test_y, freqs, theta)
print(f"Logistic regression model's accuracy = {tmp_accuracy:.4f}")
Logistic regression model’s accuracy = 0.9950
Part 5: 錯誤分析
在該部分將會找出那些模型預測錯誤的推特,并分析為什么會出錯?對于什么型別的推特會出錯?
# Some error analysis done for you
print('Label Predicted Tweet')
for x,y in zip(test_x,test_y):
y_hat = predict_tweet(x, freqs, theta)
if np.abs(y - (y_hat > 0.5)) > 0:
print('THE TWEET IS:', x)
print('THE PROCESSED TWEET IS:', process_tweet(x))
print('%d\t%0.8f\t%s' % (y, y_hat, ' '.join(process_tweet(x)).encode('ascii', 'ignore')))
Label Predicted Tweet
THE TWEET IS: @jaredNOTsubway @iluvmariah @Bravotv Then that truly is a LATERAL move! Now, we all know the Queen Bee is UPWARD BOUND : ) #MovingOnUp
THE PROCESSED TWEET IS: [‘truli’, ‘later’, ‘move’, ‘know’, ‘queen’, ‘bee’, ‘upward’, ‘bound’, ‘movingonup’]
1 0.49996890 b’truli later move know queen bee upward bound movingonup’
THE TWEET IS: @MarkBreech Not sure it would be good thing 4 my bottom daring 2 say 2 Miss B but Im gonna be so stubborn on mouth soaping ! #NotHavingit :p
THE PROCESSED TWEET IS: [‘sure’, ‘would’, ‘good’, ‘thing’, ‘4’, ‘bottom’, ‘dare’, ‘2’, ‘say’, ‘2’, ‘miss’, ‘b’, ‘im’, ‘gonna’, ‘stubborn’, ‘mouth’, ‘soap’, ‘nothavingit’, ‘:p’]
1 0.48622857 b’sure would good thing 4 bottom dare 2 say 2 miss b im gonna stubborn mouth soap nothavingit :p’
THE TWEET IS: I’m playing Brain Dots : ) #BrainDots
http://t.co/UGQzOx0huu
THE PROCESSED TWEET IS: [“i’m”, ‘play’, ‘brain’, ‘dot’, ‘braindot’]
1 0.48370665 b"i’m play brain dot braindot"
THE TWEET IS: I’m playing Brain Dots : ) #BrainDots http://t.co/aOKldo3GMj http://t.co/xWCM9qyRG5
THE PROCESSED TWEET IS: [“i’m”, ‘play’, ‘brain’, ‘dot’, ‘braindot’]
1 0.48370665 b"i’m play brain dot braindot"
THE TWEET IS: I’m playing Brain Dots : ) #BrainDots http://t.co/R2JBO8iNww http://t.co/ow5BBwdEMY
THE PROCESSED TWEET IS: [“i’m”, ‘play’, ‘brain’, ‘dot’, ‘braindot’]
1 0.48370665 b"i’m play brain dot braindot"
THE TWEET IS: off to the park to get some sunlight : )
THE PROCESSED TWEET IS: [‘park’, ‘get’, ‘sunlight’]
1 0.49578765 b’park get sunlight’
THE TWEET IS: @msarosh Uff Itna Miss karhy thy ap :p
THE PROCESSED TWEET IS: [‘uff’, ‘itna’, ‘miss’, ‘karhi’, ‘thi’, ‘ap’, ‘:p’]
1 0.48199810 b’uff itna miss karhi thi ap :p’
THE TWEET IS: @phenomyoutube u probs had more fun with david than me : (
THE PROCESSED TWEET IS: [‘u’, ‘prob’, ‘fun’, ‘david’]
0 0.50020353 b’u prob fun david’
THE TWEET IS: pats jay : (
THE PROCESSED TWEET IS: [‘pat’, ‘jay’]
0 0.50039294 b’pat jay’
THE TWEET IS: my beloved grandmother : ( https://t.co/wt4oXq5xCf
THE PROCESSED TWEET IS: [‘belov’, ‘grandmoth’]
0 0.50000002 b’belov grandmoth’
在后續課程中,將會學習如何用深度學習的方法來提升預測效果
Part 6: 預測你自己的推特
# Feel free to change the tweet below
my_tweet = 'This is a ridiculously bright movie. The plot was terrible and I was sad until the ending!'
print(process_tweet(my_tweet))
y_hat = predict_tweet(my_tweet, freqs, theta)
print(y_hat)
if y_hat > 0.5:
print('Positive sentiment')
else:
print('Negative sentiment')
[‘ridicul’, ‘bright’, ‘movi’, ‘plot’, ‘terribl’, ‘sad’, ‘end’]
[[0.48139087]]
Negative sentiment
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282830.html
標籤:AI
上一篇:網路邊緣和接入網