如果你也對以下問題有好奇心,那么這篇文章適合讀一讀:
搜索引擎的基本作業原理是什么?
四代搜索技術發展的歷史行程是什么?
什么是大搜?什么是垂搜?
什么是query?什么是index?什么是term?什么是doc?
query分析包括哪些方面?
什么是查詢策略?
什么是搜索SUG?
什么是摘要索引?
什么是相關搜索?
什么是搜索引擎cache快取機制?
什么是正排索引?什么是倒排索引?
什么是內容農場?
針對搜索爬蟲,常見的內容作弊方式有哪些?
針對鏈接引擎中的鏈接分析技術,常見的鏈接作弊方法有哪些?
什么是頁面隱藏作弊?
什么是網頁去重演算法?
百度搜索引擎的快取機制是什么?
什么是淘寶搜索引擎的快取機制?
什么是搜索引擎的快取物件?
什么是搜索引擎的快取結構?
什么是搜索引擎的快取淘汰策略?
什么是搜索引擎的快取更新策略(Refresh Policy)?
什么是谷歌三架馬車?
什么是谷歌三架馬車之一的GFS?
什么是谷歌三架馬車之一的MapReduce?
什么是谷歌三架馬車之一的Bigtable?
什么是FST資料結構?
什么是SkipList的資料結構?
什么是BKD Tree的資料結構?
什么是搜索召回?
什么是搜索小流量?
什么是互聯網毒瘤內容農場?
什么是暗網?
什么是深度網路搜索?
搜索引擎怎樣爬取暗網?
什么是暗網?
搜索引擎為什么一定要抓取暗網?
常用的搜索技巧有哪些?
參考
搜索引擎的基本作業原理是什么?
用戶發起請求后,大致的搜索流程如下:
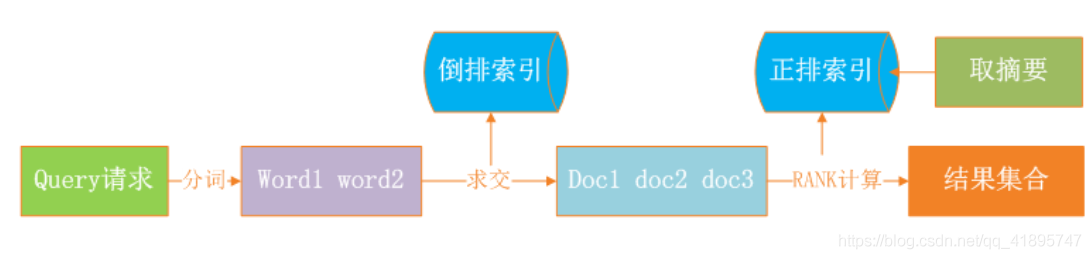
首先用切詞組件做分詞,把query分成多個word,然后多個word會從我們的倒排索引里面獲取倒排拉鏈,在倒排拉鏈的基礎上,會做求交計算來拿到所有命中的doc list,拿到doc list之后,我們希望能夠把優質的網頁反饋給用戶,這時候我們還需要做rank計算,rank計算就是拿倒排里面的一些位置索引資訊,包括在正排里面拿一些rank的屬性特征資訊做打分,最侄訓把分數比較高的Top N結果反饋用戶,當然在前端web頁面展示的時候,需要從正排中提取摘要資訊,展示給用戶,這就是整個的檢索程序,
四代搜索技術發展的歷史行程是什么?
將搜索引擎技術的發展分為4個時代:分類目錄、文本檢索、連接分析和用戶中心,
史前一代:分類目錄的一代
這個時代也可以成為“導航時代”,Yahoo和hao123是這個時代的代表,通過人工收集整理,把各類別的高質量網站或者網頁分門別類羅列,用戶可以根據分級目錄來查找高質量的網站,這種方式是純人工的方式,并未采取什么高深的技術手段,
采取分類目錄的方式,一般被收錄的網站質量都較高,但是這種方式可擴展性不強,絕大部分網站不能被收錄,
第一代:文本檢索的一代
文本檢索的一代采用經典的資訊檢索模型,比如布爾模型、向量空間模型或者概率模型,來計算用戶查詢關鍵詞和網頁文本內容的相關程度,網頁之間有豐富的鏈接關系,而這一代搜索引擎并未使用這些資訊,早期的很多搜索引擎比如Alta Vista、Excite等大都采取這種模式,
相比分類目錄,這種方式可以收錄大部分網頁,并能夠按照網頁內容和用戶查詢的匹配程度進行排序,但是總體而言,搜索結果質量不是很好,
第二代:連接分析的一代
這一代的搜索引擎充分利用了網頁之間的鏈接關系,并深入挖掘和利用了網頁鏈接所代表的含義,通常而言,網頁鏈接代表的一種推薦關系,所以通過鏈接分析可以在海量內容中找出重要的網頁,這種重要性本質上是對網頁流行程度的一種衡量,因為被推薦次數多的網頁其實代表了其具有流行性,搜索引擎通過結合網頁流行性和內容相似性來改善搜索質量,
Google率先提出并使用PageRank鏈接分析技術,并大獲成功,這同時也引進了學術界和其他商業搜索引擎的關注,后來學術界陸續推出了很多改進的鏈接分析演算法,目前幾乎所有的商業搜索引擎都采取了鏈接分析技術,
采用鏈接分析能夠有效改善搜索質量,但是這種搜索引擎并未考慮用戶的個性化要求,所以只要輸入的查詢請求相同,所有用戶都會獲得相同的搜索結果,另外,很多網站擁有者為了獲得更高的搜索排名,針對鏈接分析演算法提出了不少鏈接作弊方案,這樣導致搜索結果質量變差,
第三代:用戶中心的一代
目前的搜索引擎大都可以歸為第三代,即以理解用戶需求為核心,不同用戶即使輸入同一個查詢關鍵詞,但其目的也有可能不一樣,比如同樣輸入“蘋果”作為查詢詞,一個追捧iPhone的時尚青年和一個果農的目的會有相當大的差距,即使是同一個用戶,輸入相同的查詢詞,也會因為所在的時間和場合不同,需求有所變化,而目前搜索引擎大都致力于解決如下問題,如何能夠理解用戶發出的某個很短小的查詢詞背后包含的真正需求,所以這一代搜索引擎稱之為以用戶為中心的一代,
為了能夠獲取用戶的真實需求,目前搜索引擎大都做了很多技術方面的嘗試,比如利用用戶發送查詢詞時的時間和地理位置資訊,利用用戶過去發出的查詢詞及相應的點擊記錄、歷史資訊等技術手段,來試圖理解用戶此時此刻的真正需求,
例如舉一個很簡單的例子,現在的搜索引擎都有SUG系統,即suggestion建議,我們輸入一個query,搜索引擎會預測出我們想要搜索的單詞:
這個搜索建議極大提升了我們的搜索體驗,是以用戶為中心設計思想的典范,
什么是大搜?什么是垂搜?
大家有沒有發現,現在的搜索習慣和十年前的搜索習慣完全不一樣了,現在我們想要搜一個要去的地點/景區,會去高德/去哪兒/攜程;想要買衣服,一般去淘寶搜索;想要聽音樂,會去QQ音樂/網易云音樂;想要看某部電影,一般去愛奇藝/騰訊視頻等等,而十年前,無論我們想要干啥,都會去百度一下/谷歌一下,現在互聯網各大寡頭圈地為王,每個公司都有自己擅長的領域,我們想去搜索某一類特定的知識,會打開特定的APP/網站,這就是垂類搜索(垂搜),
- 綜合領域:像百度、google、搜狗、360等,搜索全網內容,一般叫大搜,一般搜索的內容是互聯網上的網頁,多數是通過爬蟲獲取到,通過網頁的標題和正文來搜索,
- 垂直領域:像視頻、音樂、電商、小說等,只搜索特定領域的內容,一般叫垂搜或小搜,垂域搜索的資料,往往是非常結構化的,比如淘寶里的商品,優酷里的影片資訊等,與網頁相比,文本偏短,
什么是query?什么是index?什么是term?什么是doc?
-
query:搜索關鍵字,也叫keyword
-
doc:被搜索的內容,比如一個網頁,一部影響,一件商品,在索引里是一條記錄,都叫一個doc
-
QU:query understanding,查詢理解,即對query進行分析,得到一些用戶意圖相關的資訊,輔助檢索
-
index:索引
-
term:query分詞后,每個詞,稱為一個term
query分析包括哪些方面?
這是一個經典的NLP問題,query分析基本包涵三點:確定檢索的粒度、Term屬性分析、Query需求分析,
確定檢索的粒度
所謂確定檢索粒度,就是分詞的粒度,我們會提供標準的分詞,以及短語、組合詞,針對不同的分詞粒度回傳的網頁集合是不一樣的,標準分詞粒度越小,回傳的結果越多,從中拿到優質結果的能力就越低,而短語和組合詞本身就是一個精準的檢索組合,相對的拿到的網頁集合的質量就會高一些,
Term屬性分析
這一塊主要是涉及到兩個點,
第一個點就是query中每一個詞的term weight(權重),權重是用來做什么的?每一個用戶的query它本身都有側重點,舉個例子,比如“北京長城”這個query,用戶輸入這個詞搜索的時候其實他想搜的是長城,北京只是長城的一個限定詞而已,所以說在term weight計算的時候,長城是作為一個主詞來推薦的,即使query只搜長城也會回傳一個符合用戶預期的結果,但是如果只搜北京的話,是不可能回傳用戶預期的結果的,
第二個就是term本身的一些緊密性,緊密性代表用戶輸入的query的一些關聯關系,舉個明顯的例子,有些query是具有方向性的,比如說北京到上海的機票怎么買?多少錢?這本身是有方向性的語意,
Query需求分析
針對query本身我們要分析用戶的意圖是什么?當然也包括一些時效性的特征,舉個例子,比如說“非誠勿擾”這個詞,它有電影也有綜藝節目,
如果說能夠分析出用戶本身他是想看電影還是看綜藝節目,我們就會給用戶反饋一個更優質的結果,來滿足用戶的需求,
什么是查詢策略?
查詢策略覆寫的工具就是我們整個引擎架構所要做的作業,查詢策略主要包括四個方面的作業:檢索資源、確定相關網頁集合、結果相關性計算、重查策略,
檢索資源
所謂檢索資源就是我們從互聯網上拿到的網頁,從互聯網上能拿到的網頁,大概是萬億規模,如果說我們把所有網頁拿過來,然后做建庫做索引,在用戶層面檢索,從量級上來說是不太現實的,因為它需要很多的機器資源,包括一些服務資源,另外我們從這么大一個集合里面來選取符合用戶需求的資料,代價也是很大的,所以說我們會對整個檢索資源做一個縮減,也就是說我們會針對互聯網上所有的抓取過的網頁,做一個質量篩選,
質量篩選出結果之后,我們還會對網頁做一個分類,我們拿到陌生的網頁,會根據它本身的站點的權威性,網站本身的內容質量做打分,然后我們會對網頁分類,標記高質量的網頁,普通網頁,時效性的一個網頁,這樣的話在用戶檢索的時候我們會優先選擇高質量的網頁回傳給用戶,當然從另外一個維度來講,我們也會從內容上進行分類,就是說每個網頁的title和qanchor資訊,也就是錨文本資訊,是對整篇文章的一個描述資訊,也代表文章的主體,如果我們優先拿title和anchor資訊作為用戶的召回的一個相關url集合,那它準確性要比從正文拿到的結果質量要高,當然我們也會保留這種資訊來提升它的召回的量,這是檢索要準備的檢索資源這一塊,
確定相關網頁集合
這一塊的話基本上可以分為兩點,
一個是整個query切分后的 term命中,能夠命中query當然非常好,因為它能夠反應相關資料,正常情況下,網站和用戶query相關性是非常高的,
但是也會存在這樣問題,所有的query全命中有可能回傳網站數量不夠,我們這時候就需要做一些term部分命中的一些策略,前面query分析中講到了term weight的概念,我們可能會選擇一些term weight比較重要的term來作為這次召回結果的一個term,整個確定相關網頁集合的程序,就是一個求交計算的程序,后面我會再詳細介紹,
結果相關性計算
我們拿到了相關的網頁之后,會做一個打分,打分就是所說的結果相關性計算,我這里列舉了兩個最基礎的計算,第一個是基礎權值的計算,針對每個term和文章本身的相關性的資訊,第二個就是term緊密度計算,也就是整個query里面的term在文章中的分布情況,
重查策略
為什么有重查策略,就是因為在用戶檢索程序中有可能回傳的結果比較少,也有可能回傳給用戶的結果質量比較低,最差的就是結果不符合用戶的真正意圖,我們可能通過以下三個方式來解決這個問題,一是增加檢索資源來拿到更多的結果;而是通過更小粒度的term,減掉一些不重要的term來拿到的結果,還有我們可能也會做一些query的改寫以及query的擴展,來滿足用戶的意圖,
從整個檢索模型可以看到,我們要做的作業首先是query分析;第二我們需要把檢索資源提前準備好,那就是所謂的索引;第三點是在一個query過來之后,我們通過求交計算確定相關的網頁集合,然后通過相關性計算,把優質的集合回傳給用戶,最后如果結果不滿足用戶要求的話,我們可以做一個重查,
什么是搜索SUG?
絕大部分搜索都有SUG,就是suggestion的簡稱,具體效果如下:
簡單來說就是搜索會有聯想功能,但是sug也會有缺點,因為現在JS回應速度遠大于滑鼠點擊的速度,所以會有多次的請求對后端造成壓力,
一般會根據IP、query ID等這些要素進行簽名,一次搜索只請求一次后端,降低后端的壓力,
感興趣的可以看看這篇文章:https://blog.csdn.net/tim_tsang/article/details/39268189
什么是摘要索引?
摘要索參考于部分場景的搜索效率提升,摘要索引將檔案所需回傳展示的對應資訊存盤在一起,通過Doc_id可以定位該檔案的存盤位置,并獲取對應的摘要資訊,為用戶提供摘要獲取服務,摘要索引的結構和正排索引類似,但其功能不同,
什么是相關搜索?
相關搜索(related searches):google和百度搜索結果頁的底部,都有展示相關搜索,即搜索query_a的用戶,也喜歡搜索query_b, query_c等,

什么是搜索引擎cache快取機制?
其實對于任意的后端來說,增加cache機制都是最有效優化手段,
任何領域都有2-8定律,搜索引擎也不例外,80%的搜索都集中在20%的內容上,我們只要增加有效的cache,兜得住這80%的搜索量,就能極大程度上優化搜索體驗,但是,什么樣的query命中cache?cache在什么地方觸發?cache的失效時間是怎樣?cache什么時候更新?如何更新?等等,這些問題就是搜索架構設計的時候需要考慮到的,事實上,對于現在的搜索引擎來說,cache的命中率已經是很高很高,極大程度上優化了用戶體驗,
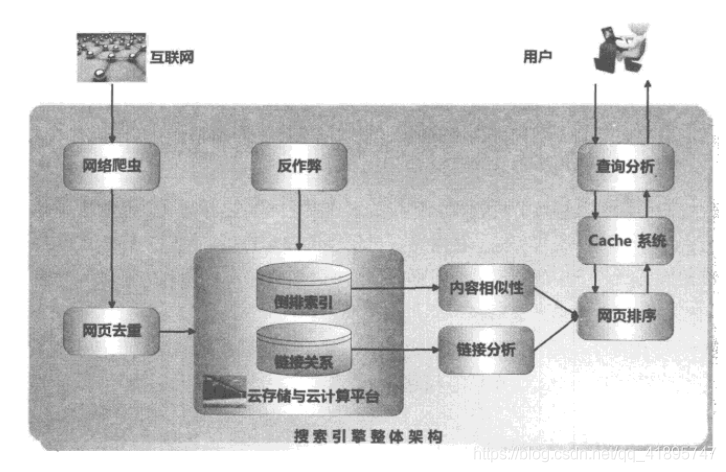
如下圖所示,這個搜索架構在query分析后就加上了cache,如果命中cache,后面的操作就可以省略,歸并廣告等結果后就可以光速召回了,
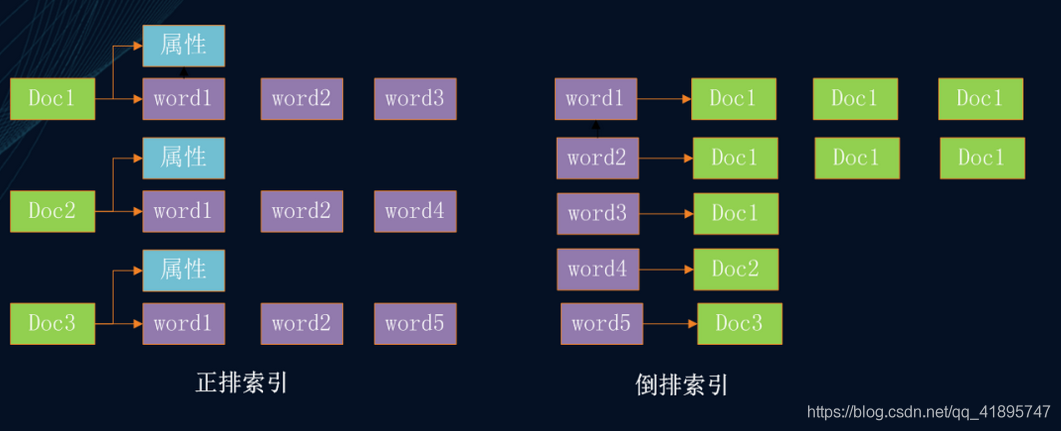
什么是正排索引?什么是倒排索引?
-
正排索引:以doc作為key,以這個doc包含的term或屬性資訊作為value,就是常規的資料庫存盤結構,便于通過docId,查詢這個doc的屬性資訊,想像一下,如果要檢索出所有包含“apple”的網頁,需要將索引里所有doc遍歷一遍,
-
倒排索引:與正排相反,以term作為key,以包含這個term的所有doc的ID作為value,構建出的KV結構,如果要檢索出包含“apple”的網頁,只需要以apple作為key,一把就能取出所有包含apple這個詞的網頁,
什么是內容農場?
隨著搜索引擎的誕生而誕生,其本質是產生大量低質量內容的網站,內容來源可能是爬蟲,也可能由寫手產生,經營內容農場的人大多都擅長SEO,因此在搜索引擎中搜索對應關鍵字或者文章時,內容農場的網站往往排名在原創網站之上,
如果你是互聯網從業者,那么使用搜索引擎去查找技術問題時,肯定會遇到一些排名靠前的回答,似是而非,排版混亂,那一般是復制粘貼型的內容產生者,這在中文搜索時更為常見,
內容農場無孔不入,在PC時代污染了搜索引擎,在移動互聯網時代就污染啟動頁推送;即便是在微信這樣封閉的生態圈中,他們也穩穩地生根發芽,公眾號、小程式、視頻號,都潛伏著內容農場的身影,
都說互聯網時代是“資訊爆炸”的時代,這點我不否認,互聯網中存在著大量優質的內容,天文地理、古今中外,無所不包,但是,你可能永遠都找不到, 內容農場看似人畜無害,但實際上卻是種潛移默化的污染,一個高產的內容農廠,一個月可以產出一百萬份文章,這個數字相當于四個英文版維基百科一年的出版數,
針對搜索爬蟲,常見的內容作弊方式有哪些?
比較常見的內容作弊方式包括:
1. 關鍵詞重復
對于作弊者關心的目標關鍵詞,大量重復設定在頁面內容中,因為詞頻是搜索引擎相似度計算中必然會考慮的因子,關鍵詞重復本質上是通過增高目標關鍵詞的詞頻來影響搜索引擎內容相似性排名,
2. 無關查詢詞作弊
為了能夠盡可能多吸引搜索流量,作弊者在頁面內容中增加很多和頁面主題無關的關鍵詞,這本質上也是一種詞頻作弊,即將原先為0的單詞詞頻增加到非0詞頻,以此吸引更多搜索引擎流量,
比如有的作弊者在網頁的末端以不可見的方式加入一堆單詞詞表,也有作弊者在正文內容插入某些熱門查詢詞,甚至有些頁面內容是靠機器完全隨機生成或者利用其他網頁的頁面內容片段隨機拼湊而成的,
3. 圖片alt標簽文本作弊
alt標簽原本是作為圖片描述資訊來使用的,一般不會在HTML頁面顯示,除非用戶將滑鼠放在圖片上,但是搜索引擎會利用這個資訊,所以有些作弊者將alt的內容以作弊詞匯來填充,達到吸引更多搜索流量的目的,
4. 網頁標題作弊
網頁標題作為描述網頁內容的綜述性資訊,對于判斷一個網頁所講述的主題是非常重要的啟發因素,所以搜索引擎在計算相似性得分時,往往會增加標題詞匯的得分權重,作弊者利用這一點,將與網頁主題無關的目標詞重復放置在標題位置來獲得好的排名,
5. 網頁重要標簽作弊
網頁不像普通格式的文本,是帶有HTML標簽的,而有些HTML標簽代表了強調內容重要性的含義,比如加粗標記<b> </b>,段落標題<h> </h>,字體大小標記等,
搜索引擎一般會利用這些資訊進行排序,因為這些標記因素能夠更好的體現網頁的內容所表現的主題資訊,作弊者通過在這些重要位置插入作弊關鍵詞也能影響搜索引擎排名結果,
6. 網頁元資訊作弊
網頁元資訊比如網頁內容描述區(meta description)和網頁內容關鍵詞區(meta keyword)是供制作網頁的人對網頁主題資訊進行簡短描述的,同以上情況類似,作弊者往往也會通過在其中插入作弊關鍵詞來影響網頁排名,
通過以上幾種常見作弊手段的描述,我們可以看出,作弊者的作弊意圖主要有以下幾類:
1. 增加目標作弊詞詞頻來影響排名;
2. 增加主題無關內容或者熱門查詢吸引流量;
3. 關鍵位置插入目標作弊詞影響排名;
針對鏈接引擎中的鏈接分析技術,常見的鏈接作弊方法有哪些?
所謂“鏈接作弊”,是網站擁有者考慮到搜索引擎排名中利用了“鏈接分析”技術,所以通過操縱頁面之間的鏈接關系,或者操縱頁面之間的鏈接錨文字,以此來增加鏈接排序因子的得分,并影響搜索結果排名的作弊方法,常見的鏈接作弊方法眾多,此節簡述幾種比較流行的作弊方法,
1.鏈接農場(Link Farm)
為了提高網頁的搜索引擎鏈接排名,“鏈接農場”構建了大量互相緊密鏈接的網頁集合,期望能夠利用搜索引擎鏈接演算法的機制,通過大量相互鏈接來提高網頁排名,“鏈接農場”內的頁面鏈接密度極高,任意兩個頁面都可能存在互相指向鏈接,圖8-2展示了一個精心構建的鏈接農場,
2.Goolge 轟炸(Google Bombing)
“錨文字”是指向某個網頁的鏈接描述文字,這些描述資訊往往體現了被指向網頁的內容主題,所以搜索引擎往往會在排序演算法中利用這一點,
作弊者通過精心設定錨文字內容來誘導搜索引擎給予目標網頁較高排名,一般作弊者設定的錨文字和目標網頁內容沒有什么關系,
幾年前曾經有個著名例子,采用“Google轟炸”來操控搜索結果排名,當時如果用Google搜索“miserable failure”,會發現排在第二位的搜索結果是美國時任總統小布什的白宮頁面,這就是通過構建很多其它網頁,在頁面中包含鏈接指向目標頁面,其鏈接錨文字包含 “miserable failure”(參考圖8-3和圖8-4),通過這種方式就導致了人們看到的搜索結果,
3.交換友情鏈接
作弊者通過和其它網站交換鏈接,相互指向對方的網頁頁面,以此來增加網頁排名,很多作弊者過分地使用此種手段,但是并不意味這使用這個手段的都是作弊網站,交換友情鏈接的做法也是正常網站的常規措施,
4.購買鏈接
有些作弊者會通過購買鏈接的方法,即花錢讓一些排名較高的網站的鏈接指向自己的網頁,以此提高網站排名,
5.購買過期域名
有些作弊者會購買剛剛過期的域名,因為有些過期域名本身的PageRank排名是很高的,通過購買域名可以獲得高價值的外鏈,
6.“門頁”作弊(Doorway Pages)
“門頁”本身不包含正文內容,而是由大量鏈接構成,而這些鏈接往往會指向同一網站內的頁面,作弊者通過制造大量的“門頁”來提升網站排名,
什么是頁面隱藏作弊?
“頁面隱藏作弊”通過一些手段瞞騙搜索引擎爬蟲,使得搜索引擎抓取的頁面內容和用戶點擊查看到的頁面內容不同,以這種方式來影響搜索引擎的搜索結果,常見的頁面隱藏作弊方式有:
1. IP地址隱形作弊(IP Cloaking)
網頁擁有者在服務器端記載搜索引擎爬蟲的IP地址串列,如果發現是搜索引擎在請求頁面,則會推送給爬蟲一個偽造的網頁內容,而如果是其它IP地址,則會推送另外的網頁內容,這個頁面往往是有商業目的的營銷頁面,
2. HTTP請求隱形作弊(User agent Cloaking)
客戶端和服務器在獲取網頁頁面的時候遵循HTTP協議,協議中有一項叫做“用戶代理項”(user agent),搜索引擎爬蟲往往會在這一項有明顯的特征(比如Google爬蟲此項可能是:Googlebot/2.1),服務器如果判斷是搜索引擎爬蟲則會推送和用戶看到的不同的頁面內容,
圖8-5是一個HTTP請求隱藏作弊的例子,作弊網站服務器推送給搜索引擎爬蟲的頁面是講述減肥食品的內容,而推送給頁面訪問者的則是減肥產品銷售推廣頁面,這樣當用戶在搜索減肥知識的時候就會直接訪問減肥產品頁面,從而達到作弊者的商業目的,
3. 網頁重定向
作弊者使得搜索引擎索引某個頁面內容,但是如果是用戶訪問則將頁面重定向到一個新的頁面,
4.頁面內容隱藏
通過一些特殊的HTML標簽設定,將一部分內容顯示為用戶不可見,但是對于搜索引擎來說是可見的,比如設定網頁字體前景色和背景色相同,或者在CSS中加入不可見層來隱藏頁面內容,將隱藏的內容設定成一些與網頁主題無關的熱門搜索詞,以此增加被用戶訪問到的概率,
什么是網頁去重演算法?
網頁去重演算法-怎么和搜索引擎演算法做斗爭
不知道大家有沒有仔細去研究過搜索引擎爬蟲抓取的一個程序,這里可以簡單的說一下:
一、定(要知道你準備在哪個范圍或者網站去搜索);百度提交,合作DNS,已有爬蟲入口
二、爬(將所有的網站的內容全部爬下來)
三、取(分析資料,去掉對我們沒用處的資料); 去重:Shingle演算法》SuperShinge演算法》I-Match演算法》SimHash演算法
四、存(按照我們想要的方式存盤和使用)
五、表(可以根據資料的型別通過一些圖示展示)
搜索引擎簡單的看就是抓取到頁面到資料庫,然后存盤頁面到資料庫,到資料庫取出頁面進行展現,所以這里面是有很多演算法的,到現在搜索引擎為了防止作弊,更好的滿足用戶需求對很多演算法已經進行改進,具體的有哪些基礎演算法大家可以自己去了解(點擊: SEO演算法 -進行了解 ),今天主要講的是原始碼去重,也就是第三部取,
通過上面幾個步驟可以了解到,搜索引擎不可能把互聯網上的所有頁面都存盤到資料庫,在把你的頁面存到資料庫之前是要對你的頁面進行檢查的,檢查你的頁面是否跟已經存盤的頁面重復了,這也是很多seoer要去做偽原創增加收錄幾率的原因,
根據去重的基礎演算法可以了解到頁面去重它是分代碼去重和內容去重的,如果我把別人網站的模板程式原封不動的拿過來做網站,那我需要怎么做代碼去重呢?今天分享一下怎么做代碼去重,

如圖,可以看到在每個模板的class后面加上自己的特征字符,這樣是既不不影響css樣式,又可以做到代碼去重的效果,欺騙搜索引擎,告訴它我這是你沒有見過的代碼程式,
很多東西說出來簡單,都是經過很多實操總結出來的,大家需要多去操作,那給大家提一下發散的問題,
如果去重演算法有效的話,互聯網上面這么多相同程式的網站他們的代碼幾乎相同(很多程式用相同的模板:織夢,帝國等),他們的權重排名為什么都可以做的很好?
去重演算法他有一個發展升級的,簡單的說就是最開始的Shingle演算法,到后面的SuperShinge演算法再升級到I-Match演算法之后到SimHash演算法,現在每個搜索引擎的演算法都是在這些基礎的演算法上面進行升級改進,我們可以了解大致的原理,
簡單點說就是搜索引擎給每個頁面一個指紋,每個頁面分層很多個小模塊,由很多個小模塊組成一個頁面,就像指紋一樣由很多條線組成,
知道這個原理的話我們就知道現在大家所做的偽原創是沒有用的,打亂段落順序,改一些詞,是不會影響頁面指紋的,
真正的可以做到抄別人內容,還不被判定為重復內容要怎么去做呢?
首先了解一個機制,搜索引擎存盤的頁面資料他是分層級的,簡單點說就是你輸入一個搜索詞的時候它優先排名的是優質層的資料,其次再是普通層,劣質層,平時看到的很多高權重平臺他的內頁的排名也可以超過很多網站首頁有這里面的原因,
當2個網站程式代碼幾乎相同,內容也幾乎相同的時候,搜索引擎怎么去發現他們是重復的呢?
因為搜索引擎存盤的資料量很大,不可能每存盤一個新頁面就把之前所有存盤的頁面拿出來對比,那他只能是通過演算法判斷拿出與新頁面標題描述相關的優質層的頁面,來與新頁面進行重復度對比,如果重復度達到某個值那么他就會被判斷為重復內容,就被去重演算法給去掉不被收錄,如果沒有被判定為重復內容則被收錄到劣質層,當你想對這個新頁面做優化讓他的排名有所提,進入到優質層,那它相應的要求也會提升,它會調取更多的頁面資料出來,與其進行對比,而不僅僅是通過調取相關標題描述的資料,這樣的話就會被搜索引擎發現,它不是原創的,通過綜合的一個評估不給予它進入到優質層,
這也是我們看到的一個現象,為什么很多抄的內容可以收錄,但是沒辦法獲得好的排名,
如果我們抄了一篇文章,但是我們用了不同的標題,那對于搜索引擎來說,他在劣質層里面沒辦法發現他是重復的,這也是解釋很多奇怪的現象,比如圖中:
一個克隆的網站,因為標題的不同,搜索引擎在抓取去重程序中沒有發現它,但是之后如果這個頁面想要進去到優質層資料庫,它就會被發現是重復的,不會給予好的排名展現,
總結:市面上面的偽原創工具是沒有用的,沒有影響要頁面的指紋,如果非要抄別人的修改標題即可,但是不會獲得好的排名,在新站初期可以用改標題的方法增加收錄,增加網站蜘蛛,中期開始要自己做內容,為獲得好的排名展現做鋪墊,
百度搜索引擎的快取機制是什么?
快取就是臨時檔案互換區,是可以開展高速資料交換的存盤器,它先于記憶體與CPU互換統計資料,因而速度很快,如今以便加速客戶查詢的回應速度,快取基本上變成百度搜索引擎的標準配置,搜索引擎會把一些客戶常常檢索的關鍵詞的搜索放進到快取中,那樣當該關鍵詞再度被搜索時,就可以立即從記憶體中讀取搜索結果,而無須再從索引庫中開展再次查找和排行,快取體制的匯入,不但加速了搜索引擎對用戶搜索的反應速度,也降低了搜索引擎對資料的反復測算,
用戶的搜索請求中,少數查詢詞占了查詢總數量的相當大的占比,而大部分查詢詞單獨出現的頻次都很少,類似長尾理論,因而搜索引擎把用戶常常查尋的“少量”關鍵詞的搜索結果儲放于快取中,就可以解決大部分用戶的搜索請求了,整個搜索引擎的快取體制中還會涉及到快取淘汰和快取更新體制,
由于搜索引擎的快取也并不是無限的,毫無疑問也有載滿的時候,這時就必須有效的淘汰體制,把應用頻率小的搜索去除,填補進來應用頻率大的搜索結果,來確保快取檔案中的內容可以回應及命中當下盡量多的用戶搜索請求,同時網頁和索引庫中的檔案內容隨之時間的轉變也會進而變化,以便促使快取中的結果和網頁同步,這時就必須有效的快取更新體制,
這解釋一下快取更換體制:百度搜索引擎以便節約資源,并不是對快取中的內容開展實時更新,只是會挑選在深夜等搜索請求較為少的時間范圍開展更新快取,因此用戶在不一樣時間搜索相同關鍵詞獲得的結果將會是不一樣的,可是通常在較短期內的反復搜索會獲得同樣的搜索,如今的搜素引擎會分析搜索關鍵詞的特性,并依據搜索關鍵詞的特性調節快取的更新頻率,例如,如今百度搜索的“最新基本資訊”“最新有關微博”等實用性搜索的快取更新頻率和一般詞快取更新的頻率毫無疑問是不一樣的,必須表明的是,如今大型搜索引擎的快取并不是簡單地直接快取檔案關鍵詞的搜索結果,而是有著很繁雜的快取結構和統計資料,通常是多級結構的,一起提高百度搜索引擎的回應速度和快取資料的命中率范疇,
什么是淘寶搜索引擎的快取機制?
當淘寶搜索引擎接收到用戶查詢的時候,會首先在快取系統查找,看快取內是否包含用戶查詢的搜索結果,如果發現快取已經存盤了相同查詢的搜索結果,則從快取內讀出結果展現給用戶;如果快取內沒有找到相同的用戶查詢,則將用戶查詢按照常規處理方式交由淘寶搜索引擎回傳結果,并將這條用戶查詢的搜索結果及中間資料根據一定策略調入快取中,這樣下次遇到同樣的查詢可以直接在快取中讀取,以加快用戶回應速度并減少淘寶搜索引擎系統的計算負載,
淘寶快取系統包含兩個部分,即快取存盤區及快取管理策略,快取存盤區是高速記憶體中的一種資料結構,可以存放某個查詢對應的搜索結果,也可以存放搜索中間結果,比如一個查詢單詞的倒排串列,
快取管理策略又包含兩個子系統,即快取淘汰策略和快取更新策略,
之所以需要快取淘汰策略,是因為不論給快取分配多大空間,當系統運行到一定程度,很可能快取已經滿了,當有新的需要快取的內容要進入快取時,需要根據一定的策略,從快取中剔除一部分優先級別較低的快取內容,以騰出空間供后續內容放入快取存盤區,如何選擇替換專案是快取淘汰策略需要考慮的問題,
另外,使用快取系統是有一定風險存在的,即快取內容和索引內容不一致問題,如果淘寶搜索引擎索引的檔案集合是靜態檔案,這個問題是不存在的,因為既然檔案集合沒有發生任何變化,只要搜索引擎的排序演算法不更改,那么針對固定的用戶查詢,其對應的搜索結果是固定不變的,所以快取里面的內容永不過期,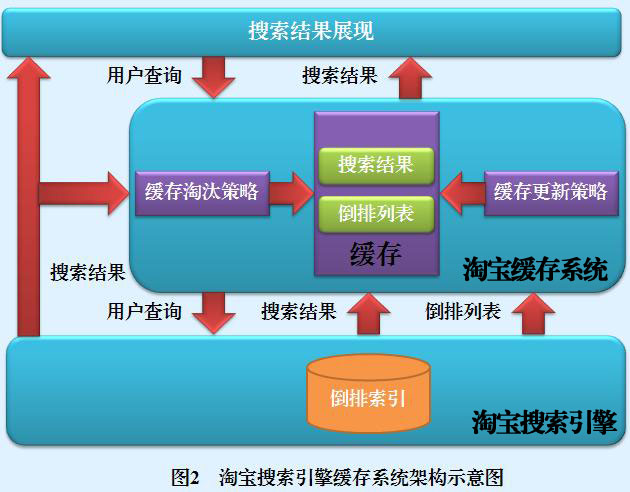
但是在一般應用場景中,淘寶搜索引擎要處理的檔案集合是動態變化的,可能會面臨新加入的檔案,也可能會洗掉舊的檔案或者舊的檔案內容發生了變化,當索引己經反映了這種變化,而快取資料沒有隨著索引做出相應的變化,那么就會發生快取內容和索引內容不一致的問題,快取更新策略就是用來維持兩者一致性的,
對淘寶搜索引快取系統來說,一個優秀的快取系統,希望能夠在以下兒個方面表現出色,
1、最大化快取命中率
所謂快取的命中率,就是說一段時間內所有用戶發出的查詢中,有多大比例的查詢對應的搜索結果是從快取中獲得的,這個比例越高,說明快取管理策略越成功,就有效地節省了淘寶搜索引擎的計算成本,具體而言,不同的快取淘汰策略就是采用不同演算法來獲得盡可能高的命中率,
2、快取內容與索引內容保持一致性
好的快取管理策略應該避免出現快取內容與索引內容不一致的狀況,因為這種不一致會影響用戶的搜索體驗,所以快取系統需要有優秀的快取更新策略來達到這個目的,
什么是搜索引擎的快取物件?
對于搜索引擎快取,在存盤區記憶體放的資料物件并不是唯一的,可以是搜索結果,也可以是某個查詢詞匯對應的倒排串列,或者是一些搜索的中間結果,
最常見的快取物件型別是用戶查詢請求所對應的搜索結果資訊,比如寶貝的標題、寶貝URL等,圖3給出了將搜索結果作為快取內容的示例,快取里保存了“連衣裙" ,“運動鞋”等用戶查詢,以及其對應的搜索結果,如果此時有另外一個用戶愉入“連衣裙”作為查詢,則淘寶搜索引擎首先在快取里面查找,發現己經存在這個用戶查詢項,則直接提取原先的搜索結果作為輸出回傳給用戶,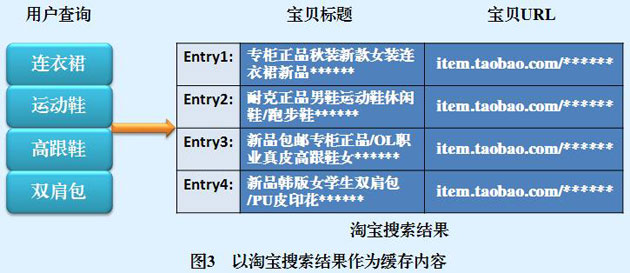
另外一種比較常見的存盤物件型別是查詢詞匯對應的倒排串列(Posting List),圖4是以單詞倒排串列作為快取內容的一個示例圖,從圖中可以看出,以搜索結果作為快取內容的情況下,用戶查詢即使包含多個單詞,也是作為一個整體存盤在快取槽里的;而以單詞倒排串列作為快取內容的方式,其存盤粒度相對會小些,是以用戶查詢的分詞結果存盤在快取槽里的,比如“夏季 連衣裙”這個用戶查詢,在搜索結果作為快取內容情形下占用一項快取槽,而在快取倒排串列方式下會占用兩個快取槽,“夏季”和“連衣裙”各自占用一個存盤位置,
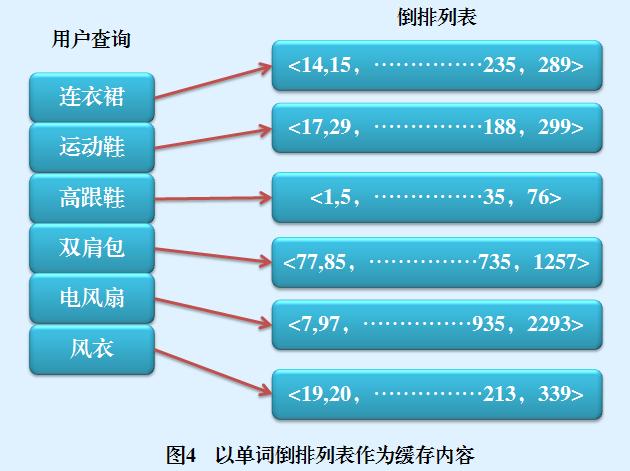
這兩種不同的快取存盤內容各自有其優缺點,對于搜索結果型快取來說,其用戶查詢回應速度非常快,因為只需要進行查找運算即可回傳結果,但是其粒度比較粗,比如在如圖3所示的例子中,如果此時用戶輸入查詢“連衣裙 韓版”,則淘寶搜索引擎會發現快取里面并不存在這個查詢,只能按照正常搜索流程,去呼叫索引資料并進行網頁排序等運算,但是倒排串列型快取因為粒度較小,會發現“連衣裙”這個查詢詞匯已經在快取中了,此時只需要從存盤在硬碟的倒排索引中讀取“韓版”這個詞匯的倒排串列資料,然后進行排序運算即可回傳結果,由這個例子可以看出,倒排串列型快取粒度小,所以命中率高,但是因為保存的只是倒排串列這種中間資料,所以仍然需要進行后續的計算才能回傳最終結果,在用戶回應效率方面慢于搜索結果型快取,而搜索結果型快取粒度大,如果在快取內命中用戶查詢,則很快給出最終結果,但是命中率要低于倒排串列型快取,
另外,搜索結果型快取因為征個搜索結果的大小是可以預估的(一般取前列的K個搜索結果),所以管理起來比較簡單,而倒排串列型快取需要快取某個單詞的倒排串列,而不同單詞的倒排串列大小差異很大,如果遇到一個非常大的倒排串列,可能會對目前的快取空間造成較大影響,甚至被迫移出經常使用的用戶查詢快取項,所以如何管理倒排串列型快取存盤區相對而言比較復雜,
以上兩種快取物件是比較常見的快取型別,還有一種不太經常使用的方式,即保留兩個經常搭配出現單詞的倒排串列的交集,以這種中間結果形式作為快取內容,因為用戶查詢有很大比例是由2個或者3個單詞組成的,對于多詞構成的用戶查詢,搜索引擎在從硬碟讀出每個詞匯的倒排串列后,需要進行檔案佇列的交集運算,而如果能夠事先將這些交集運算的計算結果快取起來,則可以避免后續的交集運算,提高搜索系統回傳結果的速度,但是這種詞匯組合的資料量非常大,都放置到記憶體中往往很困難,所以一般這種中間結果會存盤在磁盤上,這種型別的快取不能單獨使用,但是可以作為多級快取中的一個快取級別存在,對其他型別的快取起到補充作用,
什么是搜索引擎的快取結構?
搜索引擎快取的結構設計可以有多種選擇,最常見的是單級快取,也可以設計為二級甚至是三級快取結構,
單級快取是一種最常見也最簡單直接的快取結構,快取系統中只包含一個單一快取,配以快取管理策略構成了整個快取系統,圖5左方和右方分別是搜索結果型和倒排串列型單級快取示意圖,
盡管單級快取只包含一級快取,但是對于不同快取物件型別來說,其內部處理流程有一定差異,搜索結果型快取首先在快取中查找是否包含用戶查詢,如果存在則直接將搜索結果回傳,否則對用戶查詢進行處理,由搜索系統回傳搜索結果并加入快取中,之后將搜索結果回傳給用戶,對于倒排串列型快取,其處理步驟正好相反,查詢處理階段首先將用戶查詢分詞,之后在快取中查找這些單詞對應的倒排串列,如果所有單詞的倒排串列都在快取中,則由查詢處理模塊根據單詞倒排串列對搜索結果進行排序,并將搜索結果回傳給用戶,如果發現某些單詞的倒排串列不在快取中,會首先從磁盤讀入單詞對應的倒排串列,將其放入快取,之后講行查詢處理步驟,
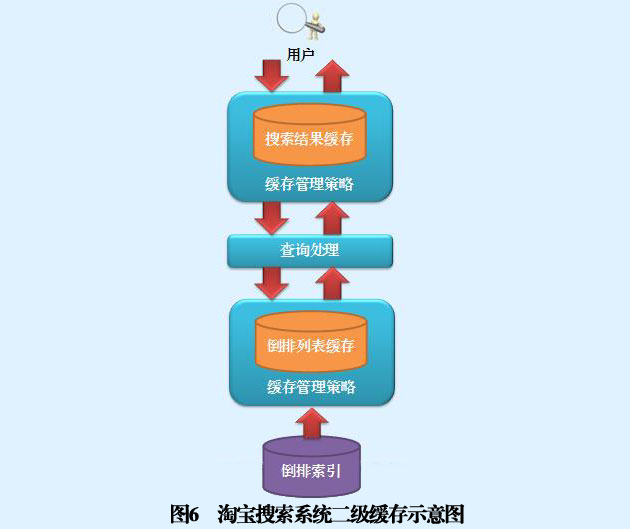
二級快取結構由兩級快取串聯構成,第1級快取是搜索結果型快取,第2級快取是倒排串列型快取,圖6是二級快取示意圖,當系統接收到用戶查詢時,首先在一級快取查找,如果找到相同查詢請求,則回傳搜索結果;如果在一級快取沒有找到完全相同的查詢,則轉向二級快取查找構成查詢的各個單詞的倒排串列,如果某些單詞的倒排串列沒有在二級快取中找到,則從磁盤讀取對應的倒排串列,進入二級快取;之后,對所有單詞的倒排串列進行求交集運算并根據排序演算法排序輸出最相關的搜索結果,將相應的用戶查詢和搜索結果放入一級快取進行存盤,并回傳最終結果給用戶,采用兩級快取結構的出發點在于能夠融合搜索結果型快取的用戶快速回應速度和倒排串列型快取的命中率高這兩個優點,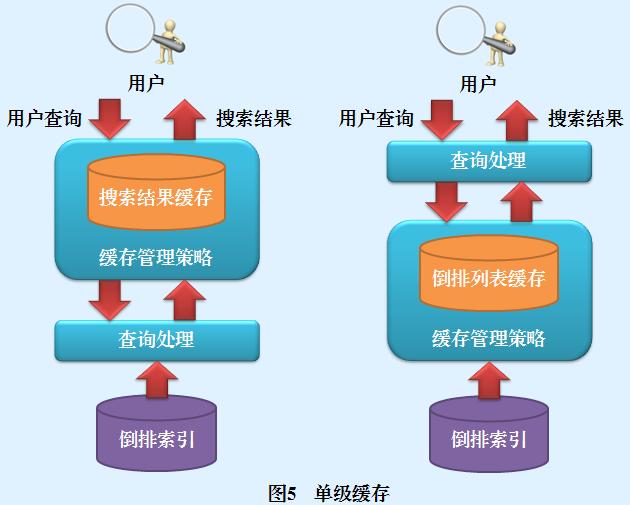
什么是搜索引擎的快取淘汰策略?
快取淘汰策略是任何快取必須配備的管理策略,因為快取的大小總是有限的,當快取已滿的時候,如果有新的快取項需要加入,那么必須從已有的快取項中剔除相對最不重要的專案,而不同的快取淘汰策略就是根據不同的演算法來衡量專案的重要性,并剔除掉最不重要專案占用的記憶體空間,快取淘汰策略方法眾多,從宏觀角度,可以將其分為動態策略和靜態動態混合策略,
動態策略
動態策略的快取資料完全來自于在線用戶查詢請求,這種快取策略的基本思路是:對快取項保留一個權重值,這個權重值根據查詢命中情況動態調整,當快取已滿的情況出現時,優先淘汰權重值最低的那個快取項,通過這種方式來騰出空間,比較常見的動態策略包括:LRU策略、LandLord策略及SLRU等改進策略,
LRU策略:最近最少使用策略(Least Recently Used)
LRU淘汰策略是計算機領域使用非常廣泛的快取替換演算法,在作業系統記憶體管理和Web頁面快取等領域也發揮著重要作用,LRU策略的基本思想是:當快取已滿時,將在設定的時間范圍內使用次數最少的專案剔除出快取,也就是將在設定時間段范圍內最少訪問的用戶查詢剔除掉,
在實際系統中,往往為每個快取項設定一個計數器,將命中查詢的計數器清零,與此同時,其他查詢計數器加1,如果快取己滿,則將計數器數值最大的專案剔除出快取,LandLord策略
LandLord策略是一種加權快取策略(Weighted Cache),其基本計算流程如下:當一個快取項插入快取的時候,會根據快取項能夠獲得收益和快取項所占記憶體大小的比率設定一個過期值 (Deadline),可以將這個比率理解為系統快取這個專案的性價比,如果快取已滿,需要剔除專案的時候,選擇過期值最小的專案進行淘汰,即淘汰性價比 最低的專案,同時,其他未被淘汰的專案對應的過期值都減去被淘汰專案的過期值,如果一個查詢請求在快取中命中時,會相應地將其過期值根據一定策略調大,
SLRU策略:大小自適應LRU (Size-adjusted LRU)
SLRU策略是對LRU方法的改進,快取被分為兩個部分:非保護區域和保護區域,每個區域的快取項都按照最近使用頻度由高到低排序,頻率高端叫做MRU,低端的叫做LRU,如果某個查詢沒有在快取中找到,那么將這個查詢放入非保護區域的MRU端;如果某個查詢在快取中命中,則把這個查詢記錄放到保護區的MRU端;如果保護區已滿,則把記錄從保護區放入非保護區的MRU,這樣保護區的記錄最少要被訪問兩次,淘汰機制是將非保護區的LRU端快取項淘汰,
混合策略
動態策略的快取資料完全來自于在線用戶查詢請求,混合策略與此不同,其快取資料一方面來自于在線用戶查詢,一方面來自于搜索日志等歷史資料,目前效果較好的混合策略包括SDC策略和AC策略,圖7是這種策略的示意圖,
SDC策略:靜態動態混合快取策略(Static and Dynamic Caching)
SDC策略是一種混合快取策略,SDC將快取切割為兩個部分,一個靜態快取與一個動態快取,所謂靜態快取,即快取內容是事先根據搜索日志統計出的最高頻的那部分查詢請求,在一定時間范圍里是相對不變的;而動態快取則可以配合使用LRU等其他快取管理策略,根據用戶查詢請求不斷更換內容,通過同時使用靜態快取和動態緩存,可以有效增加快取請求命中率,SDC是目前效果最好的快取策略之一,
AC策略:準入策略(Admission Control)
準入策略是類似于SDC策略的一種方法,該方法也將快取分為兩個部分,分別存盤高頻出現的歷史用戶查詢和動態出現的用戶查詢及其對應的搜索結果,與SDC不同之處在于:SDC的靜態快取所存盤的高頻用戶查詢是完全從過去的搜索日志統計得來的靜態內容,而AC策略則綜合了搜索日志的統計資料、查詢長度等多個判斷因素,以此來預測某個查詢是否會在未來被多次訪問,如果判斷是,則放入高頻用戶查詢快取,
什么是搜索引擎的快取更新策略(Refresh Policy)?
如果搜索引擎的索引內容不發生變化,快取的內容就總是和索引系統保持一致,但是淘寶搜索引擎索引經常更新,如果索引內容發生變化,而快取內容不隨著索引變動,會導致快取內容和索引內容的不一致,這種不一致對于用戶的搜索體驗會造成負面影響,快取更新策略就是通過一定的技術手段盡可能保持快取內容和索引內容的一致性,
目前很多搜索引擎使用簡單的更新策略,即在搜索引擎比較繁忙的時候不考慮快取更新問題,而等到搜索引擎請求很少的時候,比如午夜等時間段,將快取內的內容批量進行更新,使快取內容保持和索引內容的一致,這種簡單策略適合索引更新不是非常頻繁的應用場景,對于索引更新頻繁的場景,需要相對復雜些的快取更新策略,
根據快取內容和索引內容聯系的密切程度,目前的快取更新策略可以分為兩種:快取——索引密切耦合策略和快取——索引非耦合策略,
快取——索引密切耦合策略在索引和快取之間增加一種直接的變化通知機制,一旦索引內容發生變化則通知快取系統,快取系統根據一定的方法判斷哪些快取的內容發生了改變,然后將改變的快取內容進行更新,或者設定快取項為過期,這樣就可以緊密跟蹤并反映索引變化內容,這種密切耦合策略在實際實作時是非常復雜的,因為頻繁的索引更新導致頻繁的快取更新,對系統效率及快取命中率都會有直接影響,圖8是一個快取——索引密切耦合策略的示意圖,當有新的索引檔案進入淘寶搜索引擎時,系統會對檔案內容進行分析,抽取出檔案中得分較高的索引詞匯,并將這些詞匯及其得分傳遞給失效通知模塊,因為如果快取中的查詢包含這些索引詞匯的話,很可能該檔案將會使得快取內容失效,失效通知模塊會評估哪些快取項需要進行內容更新,如果某項快取項需要更新,則提取最新的快取內容更新舊快取項,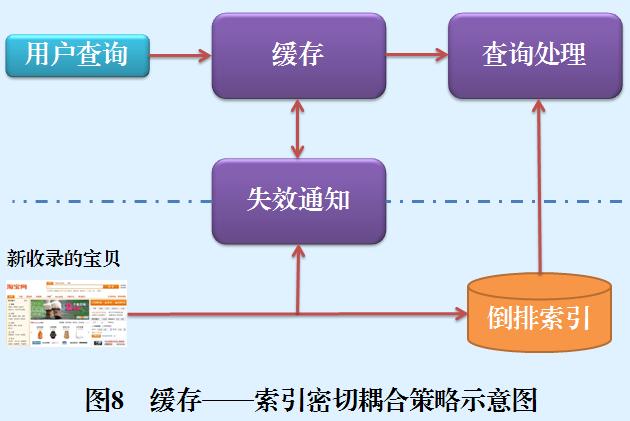
快取——索引非耦合策略則使用相對簡單的策略,當索引變化時并不隨時通知快取系統進行內容更新,而是給每個快取項設定一個過期值(Time To Live),隨著時間流逝,項會逐步過期,通過這種方式可以將快取項和索引的不一致盡可能減小,淘寶搜索引擎就是采用了用了快取——索引非禍合策略來維護快取內容的更新,這就是淘寶搜索系統中下架時間的最根本的來源,
什么是谷歌三架馬車?
GFS(Google File System)、MapReduce、Bigtable
谷歌在2003到2006年間發表了三篇論文,《MapReduce: Simplified Data Processing on Large Clusters》,《Bigtable: A Distributed Storage System for Structured Data》和《The Google File System》介紹了Google如何對大規模資料進行存盤和分析,這三篇論文開啟了工業界的大資料時代,被稱為Google的三駕馬車,
這是谷歌搜索安身立命的根本,三駕馬車橫空出世,奠定了谷歌搜索的霸主地位,這里面的歷史故事可以去看看吳軍博士的《數學之美》,
時至今日,如果我們拉長時間軸到20年為一個周期來看呢,這三駕馬車到今天的影響力其實已然不同,MapReduce作為一個有很多優點又有很多缺點的東西來說,很大程度上影響力已經釋微了,BigTable以及以此為代表的各種KeyValue Store還有著它的市場,但是在Google內部Spanner作為下一代的產品,也在很大程度上開始取代各種各樣的的BigTable的應用,而作為這一切的基礎的Google File System,不但沒有任何倒臺的跡象,還在不斷的演化,事實上支撐著Google這個龐大的互聯網公司的一切計算,
什么是谷歌三架馬車之一的GFS?
背景介紹
在21世紀初,互聯網上的內容,大多數企業需要存盤的資料量并不大,但是Google不同,Google的搜索引擎的資料基于爬蟲,而由于網頁的大量增加,爬蟲得到的資料也隨之急速膨脹,單機或簡單的分布式方案已經不能滿足業務的需求,所以Google必須設計新的資料存盤系統,其產物就是Google File System(GFS),不過,在Google的設計中,為了盡可能的解耦,GFS僅負責資料存盤而不提供類似資料庫的服務,也就是說,GFS只存資料,而對資料的具體內容一無所知,自然也就不能提供基于內容的檢索功能,所以,更進一步,Google開發了Bigtable作為資料庫,向上層服務提供基于內容的各種功能,此外,Google 的搜索結果依賴于PageRank演算法的排序,而該演算法又需要一些額外的資料,比如某網頁的被參考次數,所以他們還開發了對于的資料處理工具MapReduce,在讀取了Bigtable資料的技術上,根據業務需求,對資料內容進行運算,其總體架構如下,GFS能充分利用多個Linux服務器的磁盤,并向上掩蓋分布式系統的細節,Bigtable在GFS的基礎上對資料內容進行識別和存盤,向上提供類似資料庫的各種操作,MapReduce則使用Bigtable中的資料進行運算,再提供給具體的業務使用,
Bigtable
Bigtable實作在Google File System的基礎上,它關心資料的內容,根據的資料的內容建立資料模型,對外提供讀寫資料的介面,
資料模型
Bigtable基本的資料結構和關系型資料庫類似,都是以行列構成的表,但是,它還另外增加了新的維度——時間,也就是說,在行列確定的情況下,一個單元格(Cell)中有多個以事件為版本的資料,Bigtable用(row:string, column:string, time:int64) → string表示映射關系,下圖為論文中給出的一個例子,

如果想要在表中查詢指定版本的內容,我們需要指出行,列,及版本,比如(“com.cnn.www”,“anchor:cnnsi.com”,t9)→ "CNN",我個人猜想,增加時間這個維度是因為“三駕馬車”被設計出來的時候主要是為了支持搜索引擎,搜索引擎可能需要保留多個時間段的網頁資料,而GFS也使用追加(Append)作為資料的主要修改方式,所以增加時間戳作為版本既充分利用了GFS的特性,也能滿足業務的需求,
另外,Bigtable還把多個Column Keys并入到被稱為Column Family的集合中,并將Column Family作為訪問控制的基礎單元,我認為,這種方案其實是一種事務(Transaction)的實作方案,傳統的事務以行為基本操作單位,在讀寫時對行上鎖以實作隔離,而Bigtable則是以Column Family為單位,這里的訪問控制其實就是鎖的思想,
相關組件
在介紹系統的整體架構之前,我們要對Bigtable用到的兩個重要組件有一些了解,由于Bigtable是分布式的資料庫,在節點之間的協調上需要額外的處理,這里,Bigtable使用了Google內部的Chubby,我們可以把Chubby看做是Zookeeper,因為Zookeeper本質也就是Chubby的開源版本,另一方面,為了加快資料的查找和存盤效率,Bigtable在存盤資料之前都進行了排序,而此處用到的存盤檔案文論稱之為SSTable(Sorted String Table),
在Bigtable中,由于單個表(Table)存盤的資料可能相當地多,那么讀寫的效率就會十分低下,于是Bigtable將Table分割為固定大小的Tablet,將其作為資料存盤和查找的基本單位,每當Table增加了這里要說明的是,tablet是資料存盤的基本單元,是用戶感知不到的,而Column Family則是訪問的基本單元,是編程時指定的,兩者一前一后,不是一個概念,
Tablet 定位
因為是在分布式系統中,那么每個Tablet所在的機器不同,需要記錄相關資訊(METADATA)對其進行管理,而存盤這些METADATA又需要分布式的系統,所以Bigtable又將這些METADATA的METADATA記錄在一個檔案中,并將這個檔案的位置保存在Chubby中,總結一下,Bigtable有以下三層結構:
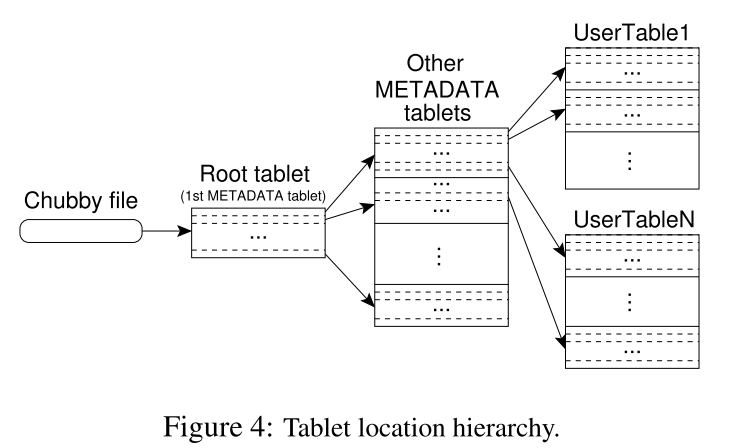
- 在Chubby中保存著Root Tablet的位置
- Root Tablet中保存著METADATA Table中所有 Tablet 的位置
- METADATA Table中保存著所有存盤資料的Tablet的位置
這其中有幾點值得注意,由于Root Tablet的特殊性,哪怕它的資料量再大,它也不允許被分割,METADATA tables被讀取到記憶體中以加快速度,其中存盤的是以開始和結尾的Row Key作為鍵,tablet位置作為值的映射,
如果客戶端希望讀取特定的資料,那么它會以此讀取Chubby中的檔案,Root Tablet,METADATA Tablet,最后讀取存盤改資料的Tablet,同時,為了加快讀取的速度,它會將這些資訊快取到本地,直到資訊失效,
Tablet分配
在談Table分配之前,論文先討論了怎么處理成員變更的問題,類似于GFS,Bigtable使用Master節點來管理這些相關的事情,
首先,Bigtable使用Chubby來檢測Tablet Server的變化,這里的操作和Zookeeper的用法類似,當有新節點加入時,它需要在Chubby中新建一個對應的檔案,并獲取該檔案的鎖,由于所有的節點在Chubby中都有對應的檔案,那么Master可以通過監聽Chubby來獲取所有Tablet Server的資訊,這里有兩種節點失效的情況,一種是僅僅回收了鎖但是檔案還在,這種情況很可能是節點崩潰了,由于節點不能自己退出,所以在Master節點得到該檔案的鎖后,它會將檔案洗掉,以此表示節點退出,另一種情況是,檔案已經被洗掉,這種情況說明節點是主動退出系統,那么可以直接重新分配Tablet給其他節點即可,
在正常的情況下,系統中會有大量資料寫入,Master需要負責將這些資料分配到合適的Tablet Server,Bigtable并沒有明確指出分配所使用的的演算法,但是它提出了一個要求,為了保證資料的一致性,同一時間,一個 Tablet只能被分配給一個Tablet Server,Master通過向 Tablet Server 發送載入請求來分配 Tablet,如果該載入請求被Tablet Server接收到前Master仍是有效的,那么就可以認為此次 Tablet 分配操作已成功,
在這里,我們還要考慮Master崩潰的情況,論文中描述了Master恢復的步驟如下:
- 在 Chubby 上獲取 Master 獨有的鎖,確保不會有另一個 Master 同時啟動
- 從 Chubby 了解在作業的 Tablet Server
- 從各個 Tablet Server 處獲取其所負責的 Tablet 串列,并向其表明自己作為新 Master 的身份,確保 Tablet Server 的后續通信能發往這個新 Master
- Master 確保 Root Tablet 及
METADATA表的 Tablet 已完成分配 - Master 掃描
METADATA表獲取集群中的所有 Tablet,并對未分配的 Tablet 重新進行分配
其中,第四步是為了第五步的正確執行,
讀寫Tablet
上面我們談了Bigtable的資料模型,如何尋找和分配Tablet,那么資料是怎么以(row,column,time)的格式被組織成Tablet的呢?論文中給出的流程圖如下:
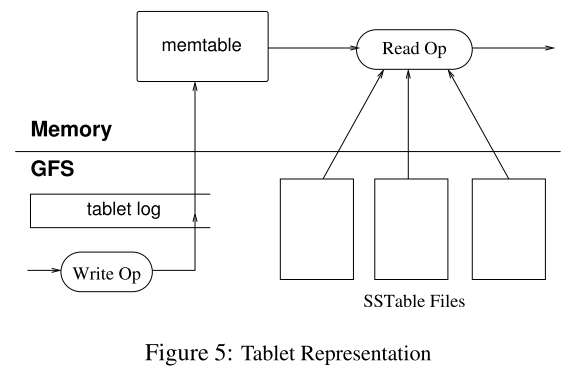
每個Tablet由若干個位于 GFS 上的 SSTable、一個位于記憶體內的MemTable以及一份Tablet Log組成,
我們來解釋一下這張圖,為了保證系統可恢復,Google首先使用Table Log(即WAL)將客戶端發出的寫操作請求記錄在磁盤中,那么,一旦系統崩潰,仍然可以從磁盤讀取資料,繼續執行命令,然后,相關的資料被放入位于記憶體中的Memtable中,因為記憶體的速度相當快,那么執行排序等操作就要快得多,當Memtable的大小達到設定的值后,它就會以SSTable的形式被存盤到GFS中,這被稱為Minor Compaction,
客戶端的讀操作請求則要綜合考慮Memtable和SSTable中的資料,如果Memtable中已經有需要讀的資料,就無需讀取SSTable,由于Memtable和SSTable都是有序的,所以讀取的速度都相當快,
在這里,雖然論文沒有明確指出,我認為Memtable和SSTable的大小很可能是64MB,因為GFS將單個Chunk設定為64MB,那么為了最大化地利用磁盤空間,Memtable和SSTable的大小設定為這個值是相當合理的,
由于SSTable中的資料有可能被標記為洗掉,那么我們需要定期對其進行處理,Bigtable將其稱為Major Compaction,在這個程序中,Bigtable會將過期或者被洗掉的資料洗掉,并合并多個SSTable,這里似乎和GFS的Garbage Collection有點類似,但是我認為這可能是兩個層面的活動,Bigtable清理的是單個Chunk中的資料,而GFS清理的是磁盤中的單個Chunk,
優化
論文中提到,僅靠上述這些方法還不能達到要求的速度,因此,Bigtable還做了一些優化,
第一,為了提高讀取的速度,Bigtable使用布隆過濾器判斷資料是否在某個SSTable中,
第二,Tablet Server使用Scan Cache快取SSTable回傳的資料,在重復讀時提高效率,使用Block Cache快取從GFS讀取的SSTable,這樣在讀取附近的資料時就無需從磁盤讀取,
第三,Bigtable把所有的寫入操作都寫入到同一個Bigtable Log檔案中,而不是每個Server分配一個,同時,因為這個檔案相當大,恢復起來很費事,Bigtable會對其進行排序并進行切分,每個Tablet Sever只需讀取自己的那部分就可以了,
第四,Bigtable允許針對特定的Column Family生成SSTable,同時進行壓縮,以提高讀取的效率,
總結
Bigtable重要的貢獻是證明了在分布式的系統中,針對超大規模的資料量,使用排序大表的來設計資料庫是可行的,這直接帶動了LSM Tree的流行,在后來的HBase,LevelDB中都使用了這種方式處理資料,另外,Bigtable系統中Chubby的使用,還告訴工業界分布式協調組件的重要性,這也引導了Zookeeper的設計實作,而其仍然是今天的分布式系統中重要的組件,
什么是谷歌三架馬車之一的MapReduce?
背景介紹
在21世紀初,互聯網上的內容,大多數企業需要存盤的資料量并不大,但是Google不同,Google的搜索引擎的資料基于爬蟲,而由于網頁的大量增加,爬蟲得到的資料也隨之急速膨脹,單機或簡單的分布式方案已經不能滿足業務的需求,所以Google必須設計新的資料存盤系統,其產物就是Google File System(GFS),不過,在Google的設計中,為了盡可能的解耦,GFS僅負責資料存盤而不提供類似資料庫的服務,也就是說,GFS只存資料,而對資料的具體內容一無所知,自然也就不能提供基于內容的檢索功能,所以,更進一步,Google開發了Bigtable作為資料庫,向上層服務提供基于內容的各種功能,此外,Google 的搜索結果依賴于PageRank演算法的排序,而該演算法又需要一些額外的資料,比如某網頁的被參考次數,所以他們還開發了對于的資料處理工具MapReduce,在讀取了Bigtable資料的技術上,根據業務需求,對資料內容進行運算,其總體架構如下,GFS能充分利用多個Linux服務器的磁盤,并向上掩蓋分布式系統的細節,Bigtable在GFS的基礎上對資料內容進行識別和存盤,向上提供類似資料庫的各種操作,MapReduce則使用Bigtable中的資料進行運算,再提供給具體的業務使用,
MapReduce
MapReduce本來是函式式編程中的兩個函式,在嘗試解決利用大資料進行計算時,Jeff Dean和Sanjay Ghemawat想到了使用這種思想簡化計算模型,
基本思想
MapReduce把所有的計算都拆分成兩個基本的計算操作,即Map和Reduce,其中Map函式以一系列鍵值對作為輸入,然后輸出一個中間檔案(Intermediate),這個中間態是另一種形式的鍵值對,然后,Reduce函式將這個中間態作為輸入,計算得出結果,其中,Map函式和Reduce函式的邏輯都是由開發人員自行定義的,一種經典的邏輯如下圖所示,
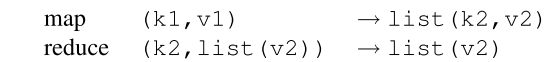
以WordCount為例,準備要統計一本書中所有單詞出現的次數,在Map函式中,我們每遇到一個單詞W,就往中間檔案中寫入(W,1),然后,在Reduce函式中,把所有(W,1)出現的次數相加,就能得到W的出現次數V,
分布式MapReduce流程
上面提到的模型和思想都是單機的,想要在分布式系統中實作,還需要一些改動,在MapReduce中,他們選擇將大任務拆分成小任務分配給多臺機器,以此充分利用分布式系統的性能,下圖是論文中展示的MapReduce的流程圖,
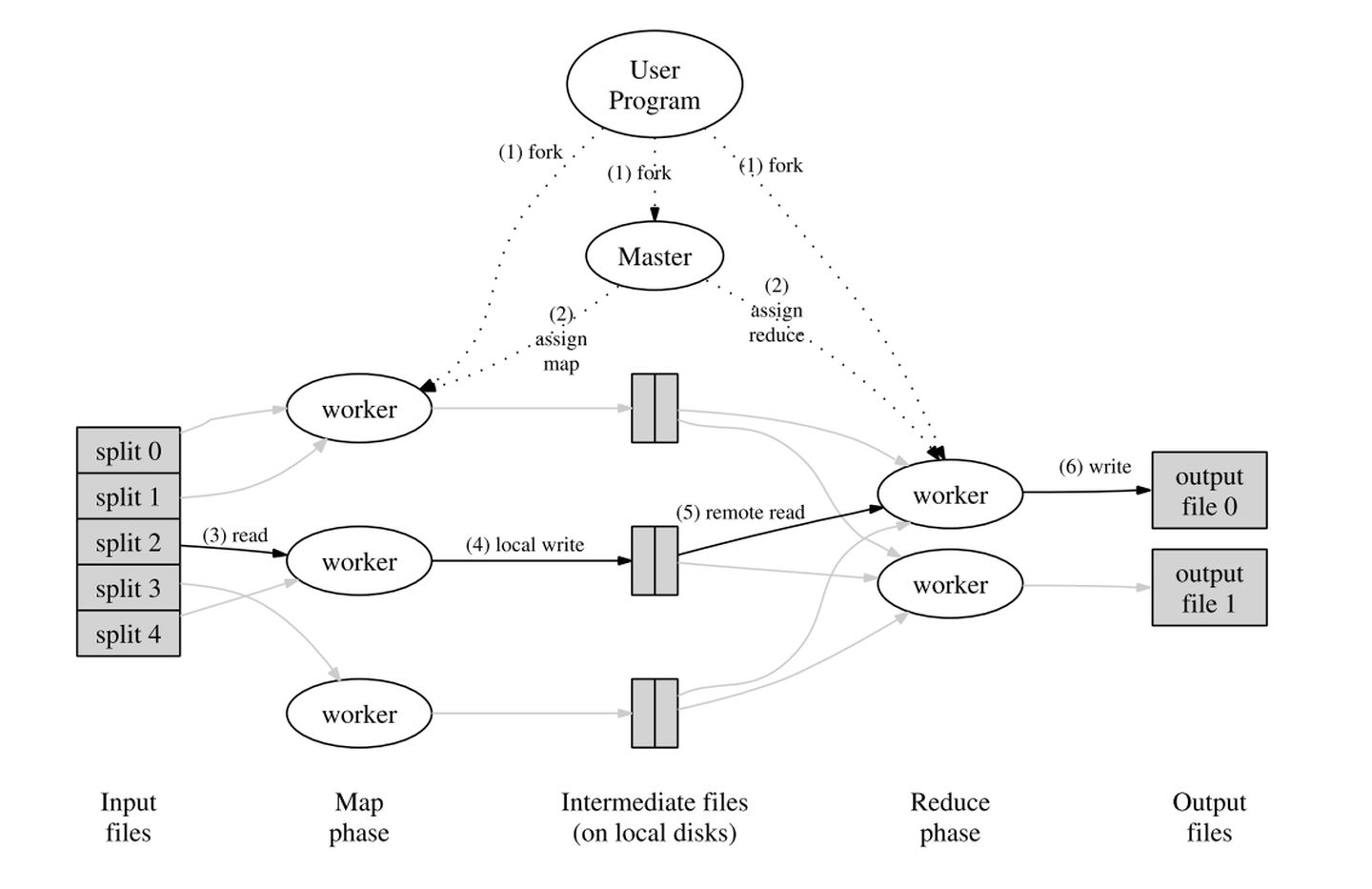
具體的流程如下
- MapReduce客戶端會將輸入的檔案會分為M個片段,每個片段的大小通常在 16~64 MB 之間,然后在多個機器上開始運行MapReduce程式,
- 系統中會有一個機器被選為Master節點,整個 MapReduce 計算包含M個Map 任務和R個 Reduce 任務,Master節點會為空閑的 Worker節點分配Map任務和 Reduce 任務
- 執行Map任務的 Worker開始讀入自己對應的片段并將讀入的資料決議為輸入鍵值對,然后呼叫由用戶定義的 Map任務,最后,Worker會將Map任務輸出的結果存在記憶體中,
- 在執行Map的同時,Map Worker根據Partition 函式將產生的中間結果分為R個部分,然后定期將記憶體中的中間檔案存入到自己的本地磁盤中,任務完成時,Mapper 便會將中間檔案在其本地磁盤上的存放位置報告給 Master,
- Master會將中間檔案存放位置通知給Reduce Work,Reduce Worker接收到這些資訊后便會通過RPC讀取中間檔案,在讀取完畢后,Reduce Worker會對讀取到的資料進行排序,保證擁有相同鍵的鍵值對能夠連續分布,
- 最后,Reduce Worker會為每個鍵收集與其關聯的值的集合,并呼叫用戶定義的Reduce 函式,Reduce 函式的結果會被放入到對應的結果檔案,
- 當所有Map和Reduce都結束后,程式會換新客戶端并回傳結果,
整個流程非常清晰,首先,將輸入檔案分割成M個個片段,然后每個Map Worker讀取對應的片段并執行Map函式,將結果存入中間檔案,Reduce Work則通過Master得知中間檔案的位置,然后讀取其對應中間檔案的內容并運行Reduce函式,最后把結果輸出到結果檔案中,
這里值得說明的是,無論是輸入檔案到Map Worker的映射還是中間檔案到Reduce Worker的映射都可以通過自定義的哈希函式來確定,論文中默認使用Hash(key) mod R來確定,另外,M和R的值都是由用戶指定的,應當比實際的機器數量要多一些,以此實作均衡負載,
Fault-Tolerance
因為使用了分布式系統,所以不可避免地要考慮容錯的問題,在MapReduce中,容錯也考慮Master和Work兩種情況,
Master節點會定期地將當前運行狀態存為快照,當Master節點崩潰,就從最近的快斬訓復然后重新執行任務,
Master節點會定期地Ping每個Work節點,一旦發現Work節點不可達,針對其當前執行的是Map還是Reduce任務,會有不同的策略,
如果是Map任務,無論任務已完成或是未完成,都會廢除當前節點的任務,,之后,Master會將任務重新分配給其他節點,同時由于已經生成的中間檔案不可訪問,還會通知還未拿到中間檔案的Reduce Worker去新的節點拿資料,
如果是Reduce任務,由于結果檔案存在GFS中,檔案的可用性和一致性由GFS保證,所以Master僅將未完成的任務重新分配,
優化
如果集群中有某個 Worker 花了特別長的時間來完成最后的幾個 Map 或 Reduce 任務,整個 MapReduce 計算任務的耗時就會因此被拖長,這樣的 Worker 也就成了落后者,MapReduce 在整個計算完成到一定程度時就會將剩余的任務即同時將其分配給其他空閑 Worker 來執行,并在其中一個 Worker 完成后將該任務視作已完成,
這里論文中還提出了其他一些策略,但是我認為不是十分重要也就不再提及,
總結
MapReduce是一個相當簡單的計算模型,它嘗試將所有的計算任務都拆分成基礎的Map和Reduce,以此降低實作的復雜度,但是,這恰恰提高了編程邏輯的復雜度,我看過使用MapReduce實作Join功能的代碼,十分地巧妙靈活,但是看似巧妙的背后,是模型過于簡單而導致復雜度轉移到了代碼邏輯的層面,
另一方面,MapReduce的程式類似于批處理程式,需要完整的輸入程式才能開始運算,而且每次運算都要至少寫入兩次磁盤,這就導致每次運算都要等待很長的時間,完全不能實作需要快速回應的業務場景的需求,
以上兩個方面,一個引出了支持類SQL的計算工具,另一個引出了支持流式計算的工具,而這兩個特性正是今天流行的計算工具的熱點,
總得來說,雖然MapReduce在今天幾乎拋棄了,但是在當初那個年代以及谷歌的業務需求看來,是相當合適的,
什么是谷歌三架馬車之一的Bigtable?
背景介紹
在21世紀初,互聯網上的內容,大多數企業需要存盤的資料量并不大,但是Google不同,Google的搜索引擎的資料基于爬蟲,而由于網頁的大量增加,爬蟲得到的資料也隨之急速膨脹,單機或簡單的分布式方案已經不能滿足業務的需求,所以Google必須設計新的資料存盤系統,其產物就是Google File System(GFS),不過,在Google的設計中,為了盡可能的解耦,GFS僅負責資料存盤而不提供類似資料庫的服務,也就是說,GFS只存資料,而對資料的具體內容一無所知,自然也就不能提供基于內容的檢索功能,所以,更進一步,Google開發了Bigtable作為資料庫,向上層服務提供基于內容的各種功能,此外,Google 的搜索結果依賴于PageRank演算法的排序,而該演算法又需要一些額外的資料,比如某網頁的被參考次數,所以他們還開發了對于的資料處理工具MapReduce,在讀取了Bigtable資料的技術上,根據業務需求,對資料內容進行運算,其總體架構如下,GFS能充分利用多個Linux服務器的磁盤,并向上掩蓋分布式系統的細節,Bigtable在GFS的基礎上對資料內容進行識別和存盤,向上提供類似資料庫的各種操作,MapReduce則使用Bigtable中的資料進行運算,再提供給具體的業務使用,
Bigtable
Bigtable實作在Google File System的基礎上,它關心資料的內容,根據的資料的內容建立資料模型,對外提供讀寫資料的介面,
資料模型
Bigtable基本的資料結構和關系型資料庫類似,都是以行列構成的表,但是,它還另外增加了新的維度——時間,也就是說,在行列確定的情況下,一個單元格(Cell)中有多個以事件為版本的資料,Bigtable用(row:string, column:string, time:int64) → string表示映射關系,下圖為論文中給出的一個例子,
如果想要在表中查詢指定版本的內容,我們需要指出行,列,及版本,比如(“com.cnn.www”,“anchor:cnnsi.com”,t9)→ "CNN",我個人猜想,增加時間這個維度是因為“三駕馬車”被設計出來的時候主要是為了支持搜索引擎,搜索引擎可能需要保留多個時間段的網頁資料,而GFS也使用追加(Append)作為資料的主要修改方式,所以增加時間戳作為版本既充分利用了GFS的特性,也能滿足業務的需求,
另外,Bigtable還把多個Column Keys并入到被稱為Column Family的集合中,并將Column Family作為訪問控制的基礎單元,我認為,這種方案其實是一種事務(Transaction)的實作方案,傳統的事務以行為基本操作單位,在讀寫時對行上鎖以實作隔離,而Bigtable則是以Column Family為單位,這里的訪問控制其實就是鎖的思想,
相關組件
在介紹系統的整體架構之前,我們要對Bigtable用到的兩個重要組件有一些了解,由于Bigtable是分布式的資料庫,在節點之間的協調上需要額外的處理,這里,Bigtable使用了Google內部的Chubby,我們可以把Chubby看做是Zookeeper,因為Zookeeper本質也就是Chubby的開源版本,另一方面,為了加快資料的查找和存盤效率,Bigtable在存盤資料之前都進行了排序,而此處用到的存盤檔案文論稱之為SSTable(Sorted String Table),
在Bigtable中,由于單個表(Table)存盤的資料可能相當地多,那么讀寫的效率就會十分低下,于是Bigtable將Table分割為固定大小的Tablet,將其作為資料存盤和查找的基本單位,每當Table增加了這里要說明的是,tablet是資料存盤的基本單元,是用戶感知不到的,而Column Family則是訪問的基本單元,是編程時指定的,兩者一前一后,不是一個概念,
Tablet 定位
因為是在分布式系統中,那么每個Tablet所在的機器不同,需要記錄相關資訊(METADATA)對其進行管理,而存盤這些METADATA又需要分布式的系統,所以Bigtable又將這些METADATA的METADATA記錄在一個檔案中,并將這個檔案的位置保存在Chubby中,總結一下,Bigtable有以下三層結構:
- 在Chubby中保存著Root Tablet的位置
- Root Tablet中保存著METADATA Table中所有 Tablet 的位置
- METADATA Table中保存著所有存盤資料的Tablet的位置
這其中有幾點值得注意,由于Root Tablet的特殊性,哪怕它的資料量再大,它也不允許被分割,METADATA tables被讀取到記憶體中以加快速度,其中存盤的是以開始和結尾的Row Key作為鍵,tablet位置作為值的映射,
如果客戶端希望讀取特定的資料,那么它會以此讀取Chubby中的檔案,Root Tablet,METADATA Tablet,最后讀取存盤改資料的Tablet,同時,為了加快讀取的速度,它會將這些資訊快取到本地,直到資訊失效,
Tablet分配
在談Table分配之前,論文先討論了怎么處理成員變更的問題,類似于GFS,Bigtable使用Master節點來管理這些相關的事情,
首先,Bigtable使用Chubby來檢測Tablet Server的變化,這里的操作和Zookeeper的用法類似,當有新節點加入時,它需要在Chubby中新建一個對應的檔案,并獲取該檔案的鎖,由于所有的節點在Chubby中都有對應的檔案,那么Master可以通過監聽Chubby來獲取所有Tablet Server的資訊,這里有兩種節點失效的情況,一種是僅僅回收了鎖但是檔案還在,這種情況很可能是節點崩潰了,由于節點不能自己退出,所以在Master節點得到該檔案的鎖后,它會將檔案洗掉,以此表示節點退出,另一種情況是,檔案已經被洗掉,這種情況說明節點是主動退出系統,那么可以直接重新分配Tablet給其他節點即可,
在正常的情況下,系統中會有大量資料寫入,Master需要負責將這些資料分配到合適的Tablet Server,Bigtable并沒有明確指出分配所使用的的演算法,但是它提出了一個要求,為了保證資料的一致性,同一時間,一個 Tablet只能被分配給一個Tablet Server,Master通過向 Tablet Server 發送載入請求來分配 Tablet,如果該載入請求被Tablet Server接收到前Master仍是有效的,那么就可以認為此次 Tablet 分配操作已成功,
在這里,我們還要考慮Master崩潰的情況,論文中描述了Master恢復的步驟如下:
- 在 Chubby 上獲取 Master 獨有的鎖,確保不會有另一個 Master 同時啟動
- 從 Chubby 了解在作業的 Tablet Server
- 從各個 Tablet Server 處獲取其所負責的 Tablet 串列,并向其表明自己作為新 Master 的身份,確保 Tablet Server 的后續通信能發往這個新 Master
- Master 確保 Root Tablet 及
METADATA表的 Tablet 已完成分配 - Master 掃描
METADATA表獲取集群中的所有 Tablet,并對未分配的 Tablet 重新進行分配
其中,第四步是為了第五步的正確執行,
讀寫Tablet
上面我們談了Bigtable的資料模型,如何尋找和分配Tablet,那么資料是怎么以(row,column,time)的格式被組織成Tablet的呢?論文中給出的流程圖如下:
每個Tablet由若干個位于 GFS 上的 SSTable、一個位于記憶體內的MemTable以及一份Tablet Log組成,
我們來解釋一下這張圖,為了保證系統可恢復,Google首先使用Table Log(即WAL)將客戶端發出的寫操作請求記錄在磁盤中,那么,一旦系統崩潰,仍然可以從磁盤讀取資料,繼續執行命令,然后,相關的資料被放入位于記憶體中的Memtable中,因為記憶體的速度相當快,那么執行排序等操作就要快得多,當Memtable的大小達到設定的值后,它就會以SSTable的形式被存盤到GFS中,這被稱為Minor Compaction,
客戶端的讀操作請求則要綜合考慮Memtable和SSTable中的資料,如果Memtable中已經有需要讀的資料,就無需讀取SSTable,由于Memtable和SSTable都是有序的,所以讀取的速度都相當快,
在這里,雖然論文沒有明確指出,我認為Memtable和SSTable的大小很可能是64MB,因為GFS將單個Chunk設定為64MB,那么為了最大化地利用磁盤空間,Memtable和SSTable的大小設定為這個值是相當合理的,
由于SSTable中的資料有可能被標記為洗掉,那么我們需要定期對其進行處理,Bigtable將其稱為Major Compaction,在這個程序中,Bigtable會將過期或者被洗掉的資料洗掉,并合并多個SSTable,這里似乎和GFS的Garbage Collection有點類似,但是我認為這可能是兩個層面的活動,Bigtable清理的是單個Chunk中的資料,而GFS清理的是磁盤中的單個Chunk,
優化
論文中提到,僅靠上述這些方法還不能達到要求的速度,因此,Bigtable還做了一些優化,
第一,為了提高讀取的速度,Bigtable使用布隆過濾器判斷資料是否在某個SSTable中,
第二,Tablet Server使用Scan Cache快取SSTable回傳的資料,在重復讀時提高效率,使用Block Cache快取從GFS讀取的SSTable,這樣在讀取附近的資料時就無需從磁盤讀取,
第三,Bigtable把所有的寫入操作都寫入到同一個Bigtable Log檔案中,而不是每個Server分配一個,同時,因為這個檔案相當大,恢復起來很費事,Bigtable會對其進行排序并進行切分,每個Tablet Sever只需讀取自己的那部分就可以了,
第四,Bigtable允許針對特定的Column Family生成SSTable,同時進行壓縮,以提高讀取的效率,
總結
Bigtable重要的貢獻是證明了在分布式的系統中,針對超大規模的資料量,使用排序大表的來設計資料庫是可行的,這直接帶動了LSM Tree的流行,在后來的HBase,LevelDB中都使用了這種方式處理資料,另外,Bigtable系統中Chubby的使用,還告訴工業界分布式協調組件的重要性,這也引導了Zookeeper的設計實作,而其仍然是今天的分布式系統中重要的組件,
什么是FST資料結構?
資料字典 Term Dictionary,通常要從資料字典找到指定的詞的方法是,將所有詞排序,用二分查找即可,這種方式的時間復雜度是 Log(N),占用空間大小是 O(N*len(term)),缺點是消耗記憶體,存在完整的term,當 term 數達到上千萬時,占用記憶體非常大,
lucene從4開始大量使用的資料結構是FST(Finite State Transducer),FST有兩個優點:
空間占用小,通過讀 term 拆分復用及前綴和后綴的重用,壓縮了存盤空間;
查詢速度快,查詢僅有 O(len(term)) 時間復雜度
那么 FST 資料結構是什么原理呢? 先來看看什么是 FSM (Finite State Machine), 有限狀態機,從“起始狀態”到“終止狀態”,可接受一個字符后,自回圈或轉移到下一個狀態,
而FST呢,就是一種特殊的 FSM,在 Lucene 中用來實作字典查找功能(NLP中還可以做轉換功能),FST 可以表示成FST的形式
舉例:對“cat”、 “deep”、 “do”、 “dog” 、“dogs” 這5個單詞構建FST(注:必須已排序),結構如下:
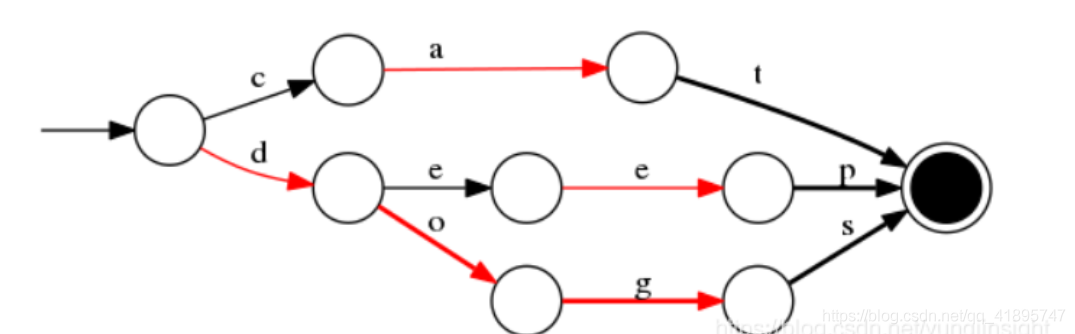
當存在 value 為對應的 docId 時,如 cat/0 deep/1 do/2 dog/3 dogs/4, FST 結構圖如下:
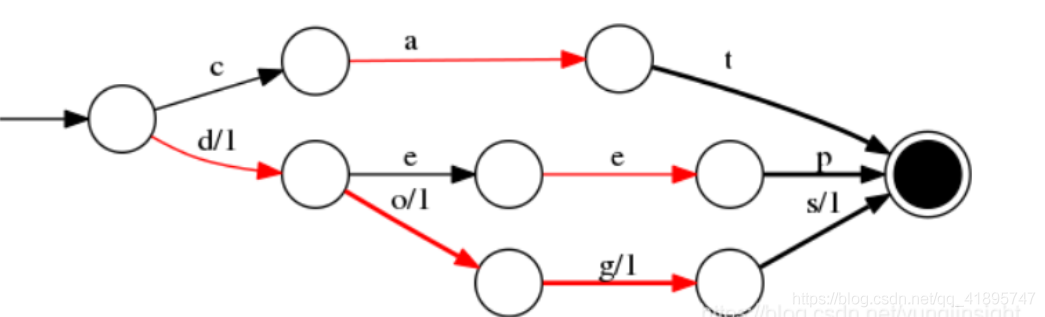
FST 還有一個特點,就是在前綴公用的基礎上,還會做一個后綴公用,目標同樣是為了壓縮存盤空間,
什么是SkipList的資料結構?
為了能夠快速查找docid,lucene采用了SkipList這一資料結構,SkipList有以下幾個特征:
元素排序的,對應到我們的倒排鏈,lucene是按照docid進行排序,從小到大;
跳躍有一個固定的間隔,這個是需要建立SkipList的時候指定好,例如下圖以間隔是;
SkipList的層次,這個是指整個SkipList有幾層
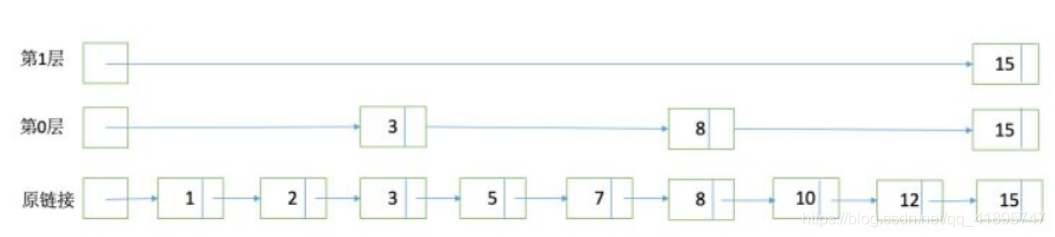
在什么位置設定跳表指標?
? 設定較多的指標,較短的步長, 更多的跳躍機會
? 更多的指標比較次數和更多的存盤空間
? 設定較少的指標,較少的指標比較次數,但是需要設定較長的步長?較少的連續跳躍
如果倒排表的長度是L,那么在每隔一個步長S處均勻放置跳表指標,
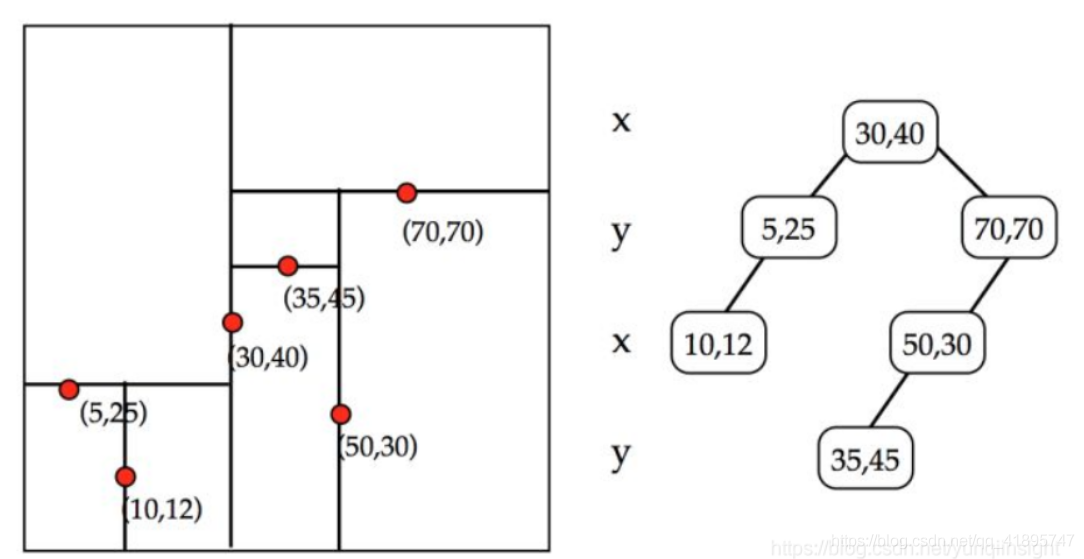
什么是BKD Tree的資料結構?
也叫 Block KD-tree,根據FST思路,如果查詢條件非常多,需要對每個條件根據 FST 查出結果,進行求并集操作,如果是數值型別,那么潛在的 Term 可能非常多,查詢銷量也會很低,為了支持高效的數值類或者多維度查詢,引入 BKD Tree,在一維下就是一棵二叉搜索樹,在二維下是如果要查詢一個區間,logN的復雜度就可以訪問到葉子節點對應的倒排鏈,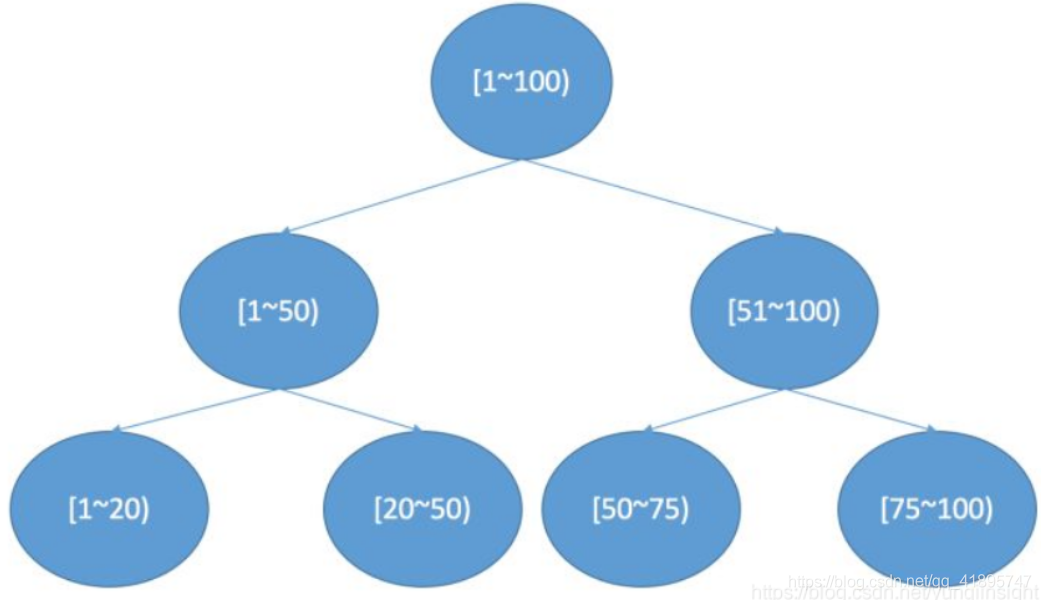
- 確定切分維度,這里維度的選取順序是資料在這個維度方法最大的維度優先,一個直接的理解就是,資料分散越開的維度,我們優先切分,
- 切分點的選這個維度最中間的點,
- 遞回進行步驟1,2,我們可以設定一個閾值,點的數目少于多少后就不再切分,直到所有的點都切分好停止,
什么是搜索召回?
搜索召回是根據輸入的query,能夠高效的獲取query相關的候選doc集合的程序,相關的doc如果不能被被召回,即使后面的粗排、精排做的再好也是徒勞無功,所以召回對于搜索引擎是非常重要的,決定了搜索引擎質量的上限,
什么是搜索小流量?
其實不是搜索架構才有,只要一個系統達到一定的量級,比如百萬PV,不做小流量直接上線風險很大,頭鐵除外,
小流量是讓pv總量的一小部分使用到新功能,而其余用戶仍然使用原來的功能,
至于怎樣抽取小流量、如何抽取更隨機更合理,這就不是搜索技術研究的重點了,
什么是互聯網毒瘤內容農場?
說起毒瘤一點也不過分,拿我自己舉例子,我自己的博客,搜一下:
會發現很多和我自己一模一樣的博文,有的算有良心表明了轉載,有的是洗稿子,有的直接寫原創,很多不是人為去抄的,而是爬蟲自動爬取,也許你發布博文的后三秒,這一篇blog已經在其他的網站里面出現了!更有趣的事情是,你百度或者谷歌一下,權重排在前面的竟然是轉載或者抄襲的文章,辛辛苦苦原創的反而排在后面?!這就是典型的內容農場啦,
參考維基百科對內容農場的描述:
內容農場(英語:content farm)是指圖謀網路廣告等商業利益,以獲取網路流量為主要目標,而以各種合法、非法手段大量、快速生產質量不穩定網路文章的網站或企業,
內容農場通常不會主動管理產出的內容,對侵權或錯誤內容投訴的處理也很消極,其產出內容有極高比例是盜用、盜譯自他人的原創圖文,或由非專業寫手胡亂拼湊網路文章而來,因而多半缺乏可靠來源、質量低劣、不具參考價值、傳播誤導訊息,也經常摻雜大量廣告或惡意程式,
內容農場的管理者在這些內容上的花費通常都比傳統上作家拿到的薪水低,每篇文章公司大約付給作家3.50美元,遠低于主流在線媒體的給薪,有些內容農場的內容貢獻者每天生產數篇文章,得到的薪水便足以過活,據報導,這些作家通常是受過教育的有小孩的婦女,在家作業賺取額外收入,[1]
至于繁體中文的內容農場,有一部分屬于由國外內容農場或博客文章翻譯而來,尤其是醫學類文章等,較著名的一例便是美國博客Psychology Spot上一篇以"Did you know that intelligence is inherited from mothers?"(你知道智商的遺傳是來自于母親嗎?)為題的文章,而此文章發布后便隨即出現中文版本,也流傳到許多內容農場里,然而諷刺的是,這篇文章被指內容不為所參考的論文支持,“智商基因”的說法也沒有任何醫師或遺傳學權威的支持,此篇文章更曾引來臺灣醫界人士的強烈質疑,與對其缺乏資料論證的批判,
其實谷歌、百度早在十年前就對內容農場宣戰,只是過了十年,這種方式并沒有消除,必然永遠無法消除,畢竟有人的地方就有江湖,有互聯網的地方就有抄襲,最后來看一下常見內容農場的串列:
- apple01(蘋果網) - 包括 apple01.cc、apple01.co、apple01.net
- beeper.live(嘟嘟網) - 包括 hknews.pro
- biglife.fun
- bomb01 - 包括 bomb01.asia、bomb01.cc、bomb01.club、bomb01.co、bomb01.com、bomb01.life、bomb01.me、bomb01.media、bomb01.online、bomb01.org、bomb01.party、bomb01.today、bomb01.tw、bomb01.vip、bomb01.xyz
- BuzzHand - 包括 buzzhand.com、buzzhand.net、buzzhand.org、buzzworld.tech
- CMoney
- COCOHK - 包括 cocohk.com, cocohk.net, cocohk.cc, cocohk.me, cocohk.today, cocohk.vip, coco02.com, coco02.net
- COCO01 - 包括 coco01.cc, coco01.today, coco01.me, coco01.net, cocomy.net(COCO大馬), peekme.cc
- codertw.com(程式前沿)
- daliulian(大榴梿) - 包括 daliulian.net, daliulian.org
- fafa01.com(看頭條) - 包括 fafabest.com、fafa01.com、fale100.com、greatpo.com、post01vicky.com、91post.net、ezreader.life、eeeduuu.com、readdoo.com、readbest.net、lovegamett.com、godayup.com、17no1.com、goupdayday.com、zmjayouzan.com
- gigacircle.com
- hkpeople-local.com
- hot.petonea.com
- hssszn.com(贊新聞)
- itread01.com
- jianshu.com(簡書)
- kanwatch - 包括 kanwatch.com、kanwatch.live、kanwatch.site、kanwatch.best
- kknews.cc(每日頭條)
- kokomy.net(閃文聯盟) - 包括 *.fbs.one、*.orgs.host、*.orgs.life、*.orgs.pub、*.orgs.one、*.orgs.pub、*.orgs.ltd、*.orgs.press、*.ipub.one、*.ipub.pro
- lifeonea.co(壹A新聞)
- lookersideas.com(好點子)
- mission-tw.com(密訊) - 包括 missiback.com, mission-new.com, osometalk.com, tiksomo.com
- moptt.tw
- nooho.net(怒吼)
- presslocal(愛縮兔)- 包括 iso2.cc、iso2.cx、presslocalhk.com、hklocalpress.com、pressyourmum.com
- PTT01(娛樂新聞)- 包括 ptt01.cc、ptt01.tv
- qiqi.news(琦琦看新聞) - 包括 cnba.live、iqiqi.pro、qiqis.net、qiqi.world、iqiqis.com、ipipi.co、ipipi.me、my-love.org、newqiqi.com、twitter-qiqi.com、qiqi.today、allqiqi.com、qiqis.org、defense.rocks
- qiqu.pro(奇趣網) - 包括 qiqu.live、qiqu.world
- read01.com(壹讀)
- share001 - 包括 share001.com、share001.net、share001.org
- twgreatdaily(今天頭條) - 包括 twgreatdaily.com、twgreatdaily.fun、twgreatdaily.life、twgreatdaily.live
- vivi01.com, 包括 cklive.net,ptttube.com,buzzvideo.pro,cookernote.com,live525.com
- xuehua(雪花新聞) - 包括 xuehua.tw、xuehua.us
- itw01.com 中文技術分享平臺
- aboluowang.com 阿波羅新聞網
這篇blog講的也非常好,推薦一看:https://www.cnblogs.com/pannengzhi/p/12386268.html
什么是暗網?
所謂暗網,是指目前搜索引擎爬蟲按照常規方式很難抓取到的互聯網頁面,搜索引擎爬蟲依賴頁面內中的鏈接關系發現新的頁面,但是很多網站的內容是以資料庫的方式存盤的,典型的例子是一些垂直領域網站,比如京東的3C家電數碼資料,很難有顯性鏈接指向資料庫內的記錄,往往是服務網站提供組合查詢界面,只有用戶按照要求選擇查詢條件后,才可能獲得相關資料,所以常規的爬蟲無法索引這些資料內容,
什么是深度網路搜索?
當我們在任何搜索引擎上搜索某項內容時,它只會顯示由約10個鏈接組成的一些結果,并且我們發現至少有一個鏈接可以滿足大多數情況下搜索到的術語,這就是所謂的簡單搜索,或者我們可能會在網上沖浪,這樣,我們僅使用傳統的搜索引擎瀏覽網頁,但是深度網路搜索到底是什么意思?為了解釋這一點,我們將使用說明性示例,我們使用Internet,即通過Web探索,學習和發現很多東西,這些內容包括資訊收集,照片和視頻收集,檔案收集等,
搜索引擎怎樣爬取暗網?
暗網并不完全是非法的資訊,絕大部分還是合法的,比如買火車票的12306官網,那么搜索引擎怎樣爬取暗網資料并整合呢?百度谷歌都作了相關技術的探索,百度推出了阿拉丁計劃,谷歌的富含資訊查詢模板技術等,有興趣的可以搜索一下,比較復雜就不展開了,其實這些已經不僅僅是暗網搜索了,更重要是谷歌百度提供各種垂類搜索,打破資訊孤島,做到真正的大搜,
什么是暗網?
“暗網”是指隱藏的網路,普通網民無法通過常規手段搜索訪問,需要使用一些特定的軟體、配置或者授權等才能登錄,由于“暗網”具有匿名性等特點,容易滋生以網路為勾聯工具的各類違法犯罪,一些年輕人深陷其中,記者在中國裁判文書網上搜索顯示,涉“暗網”的案件共有21例,涉及販賣毒品、傳播色情恐怖非法資訊、侵害公民個人資訊等犯罪行為,
互聯網是一個多層結構,“表層網”處于互聯網的表層,能夠通過標準搜索引擎進行訪問瀏覽,藏在“表層網”之下的被稱為“深網”,深網中的內容無法通過常規搜索引擎進行訪問瀏覽,“暗網”通常被認為是“深網”的一個子集,顯著特點是使用特殊加密技術刻意隱藏相關互聯網資訊,
暗網是利用加密傳輸、P2P對等網路、多點中繼混淆等,為用戶提供匿名的互聯網資訊訪問的一類技術手段,其最突出的特點就是匿名性,
搜索引擎為什么一定要抓取暗網?
因為暗網資料不僅僅是違法資訊,殺人放火,奸殺淫掠這些,還有很多有用的資訊,
比如小程式資訊、微博小程式、地域資訊、地圖資訊等等,特別是在移動互聯網時代,不是以URL形式作為唯一展現;這些也是廣義上的暗網,所以搜索引擎需要針線這些資訊,打破資訊孤島,
常用的搜索技巧有哪些?
摘自:https://zhuanlan.zhihu.com/p/351163107
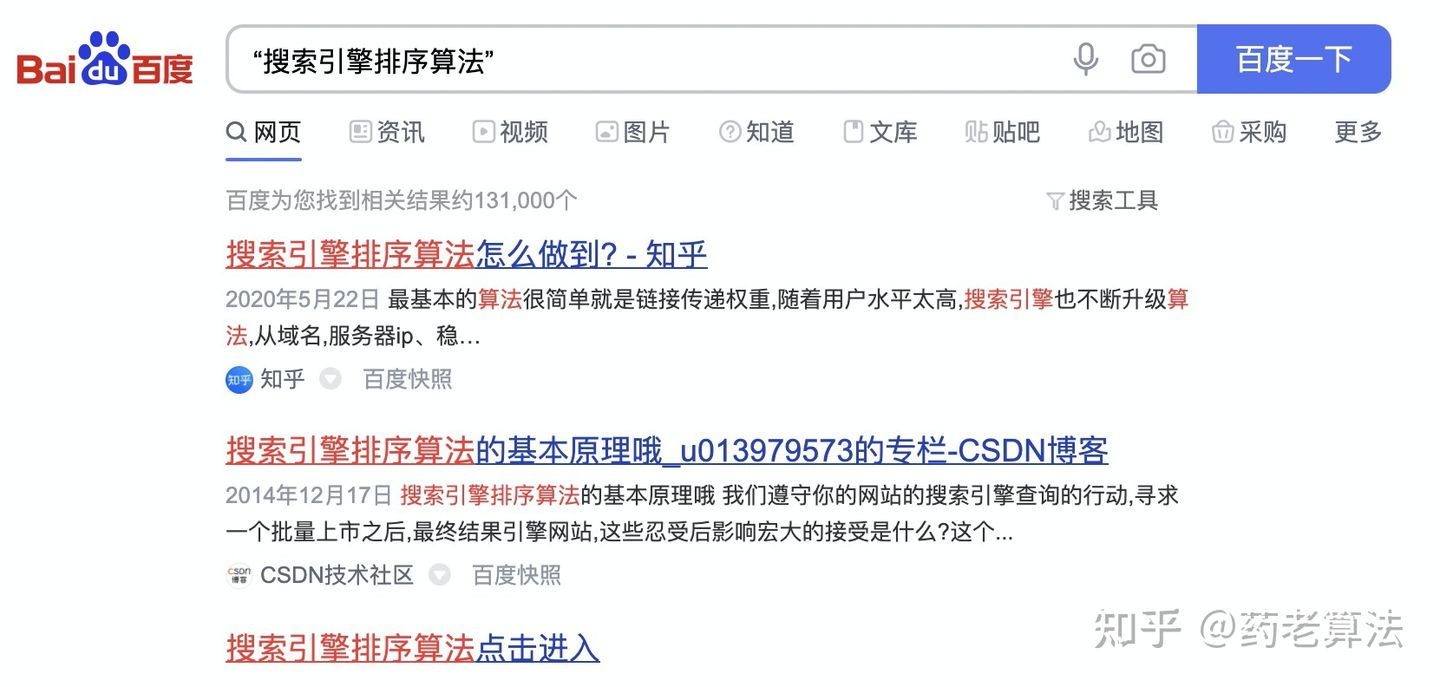
整詞查詢
眾所周知搜索引擎中都會將query進行分詞,如果你在搜索的程序中不想分詞,則可以在詞的首位添加引號,既為整詞查詢,關鍵詞為:“搜索引擎排序演算法”如下:
排除關鍵詞 -
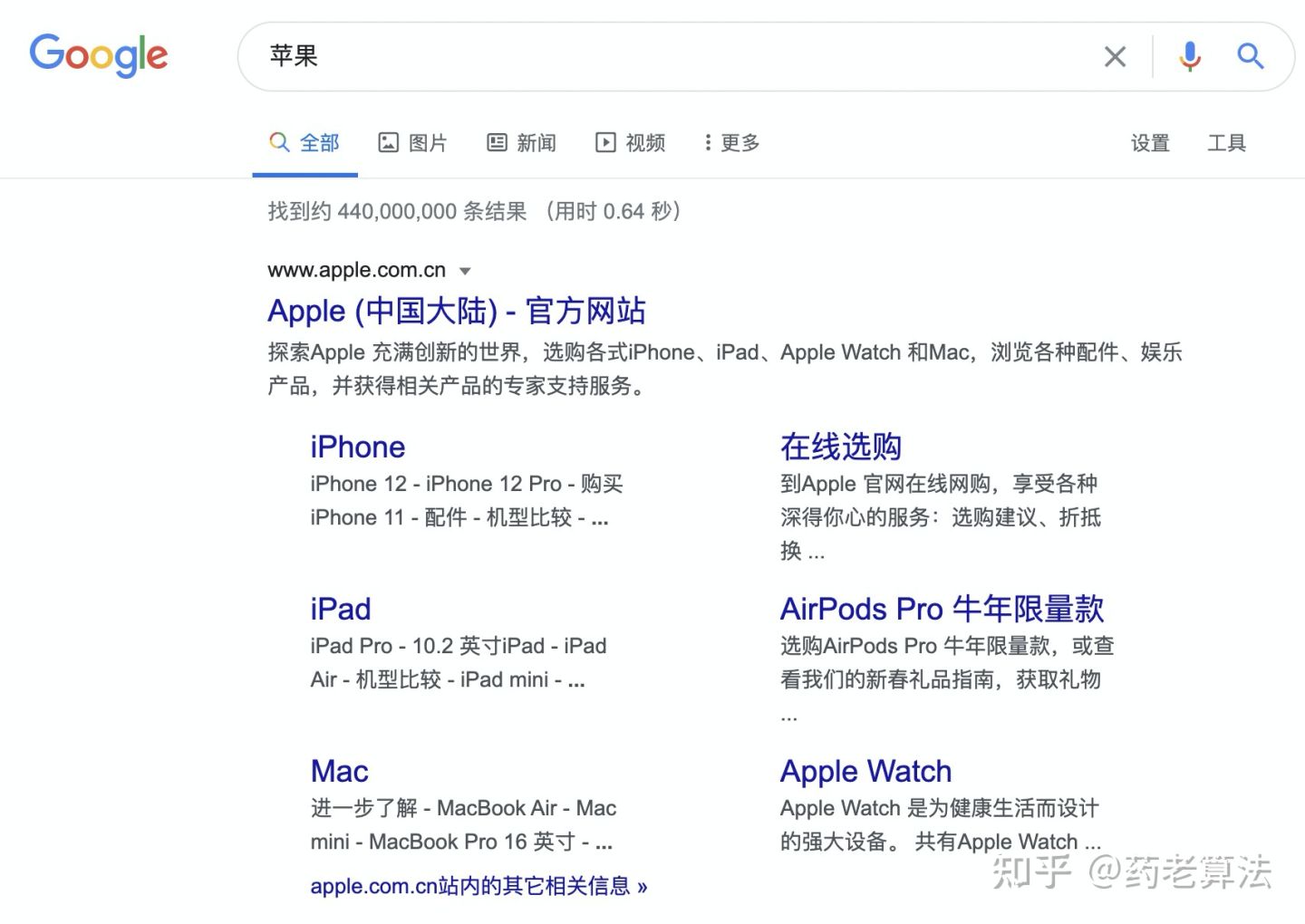
在搜索時可能會碰上很多同義詞,當你知道某些范圍的詞我不需要的時候,這個時候可以使用“-”字符進行排除,例如我搜索“蘋果”時,只想搜索水果的蘋果,而不是蘋果手機,則可以使用“蘋果 -手機”,如下
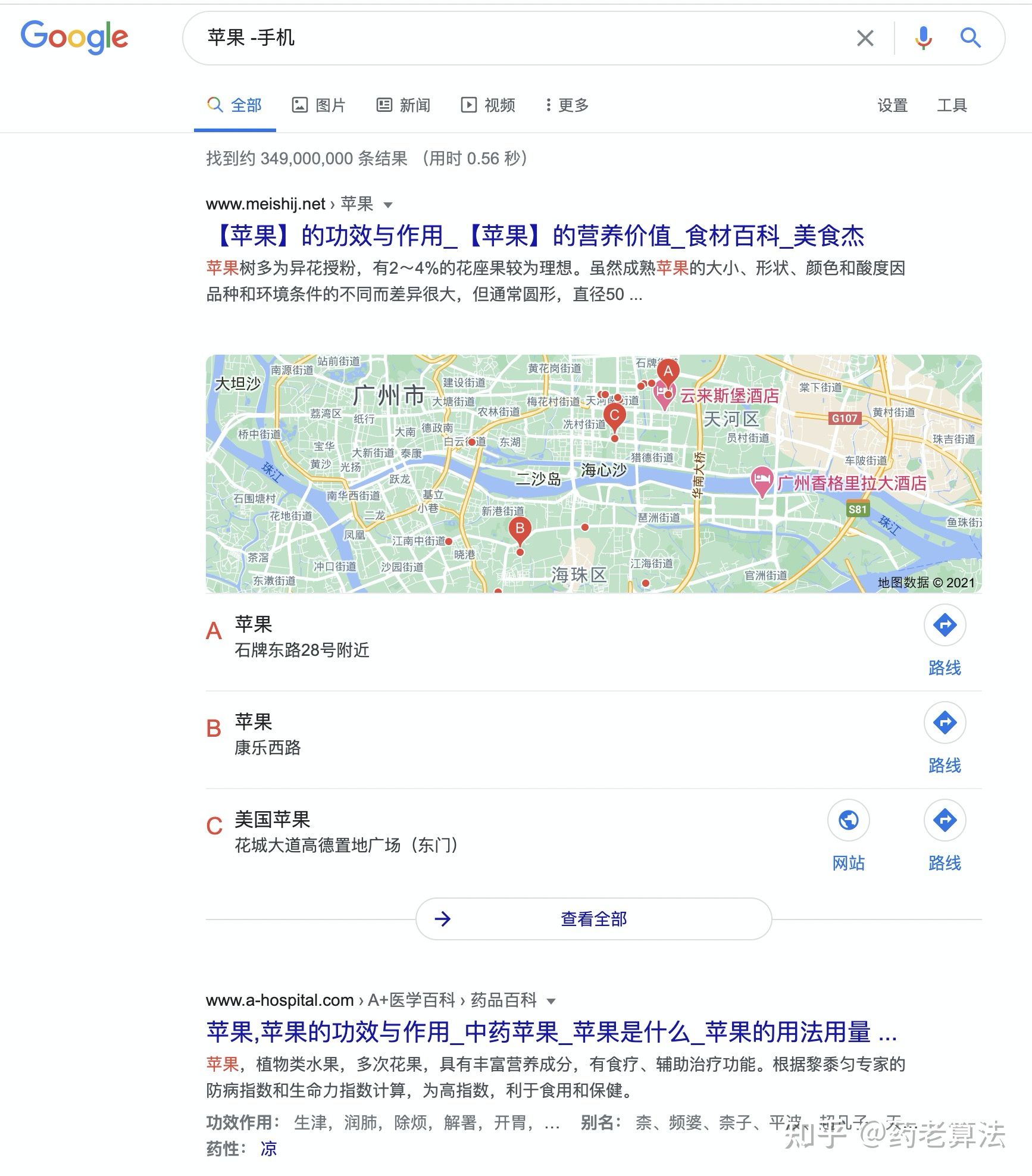
而如果不加范圍,可能會出現如下結果:搜索“蘋果”
AND / OR
在我們使用多個詞進行搜索時,有些需求是只命中一個即可,有些需求則是命中全部,比如我只需搜索“搜索引擎”和“推薦系統”中的一個,則可以使用OR,如下:
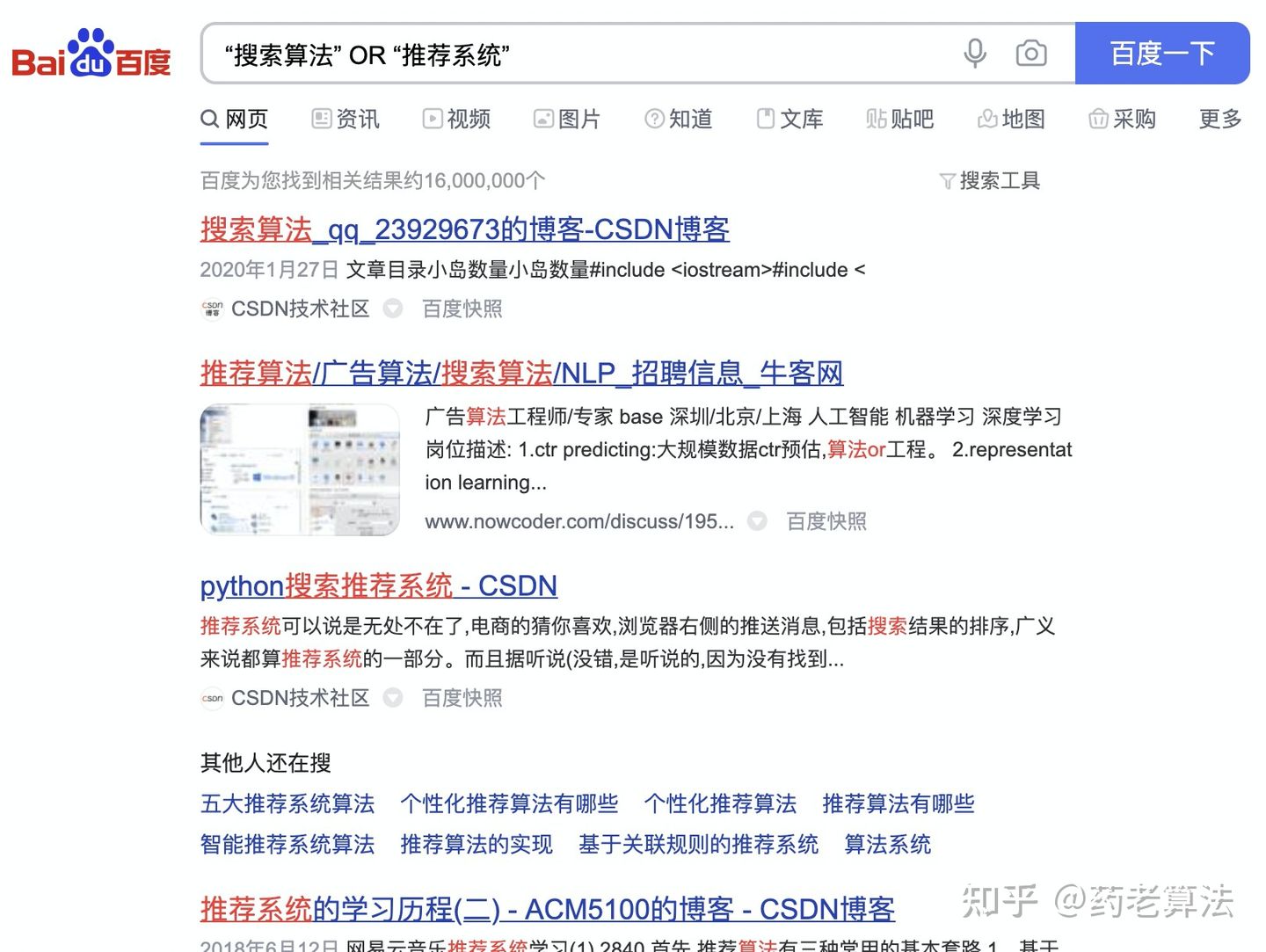
如果需要全命中,則可以使用AND,查找的網頁中會同時包含這兩個關鍵詞,這個指令,其實我們一直在用,只是沒有意識,一般用空格代替,還可以用加號+代替,意思是邏輯“與”,如下:
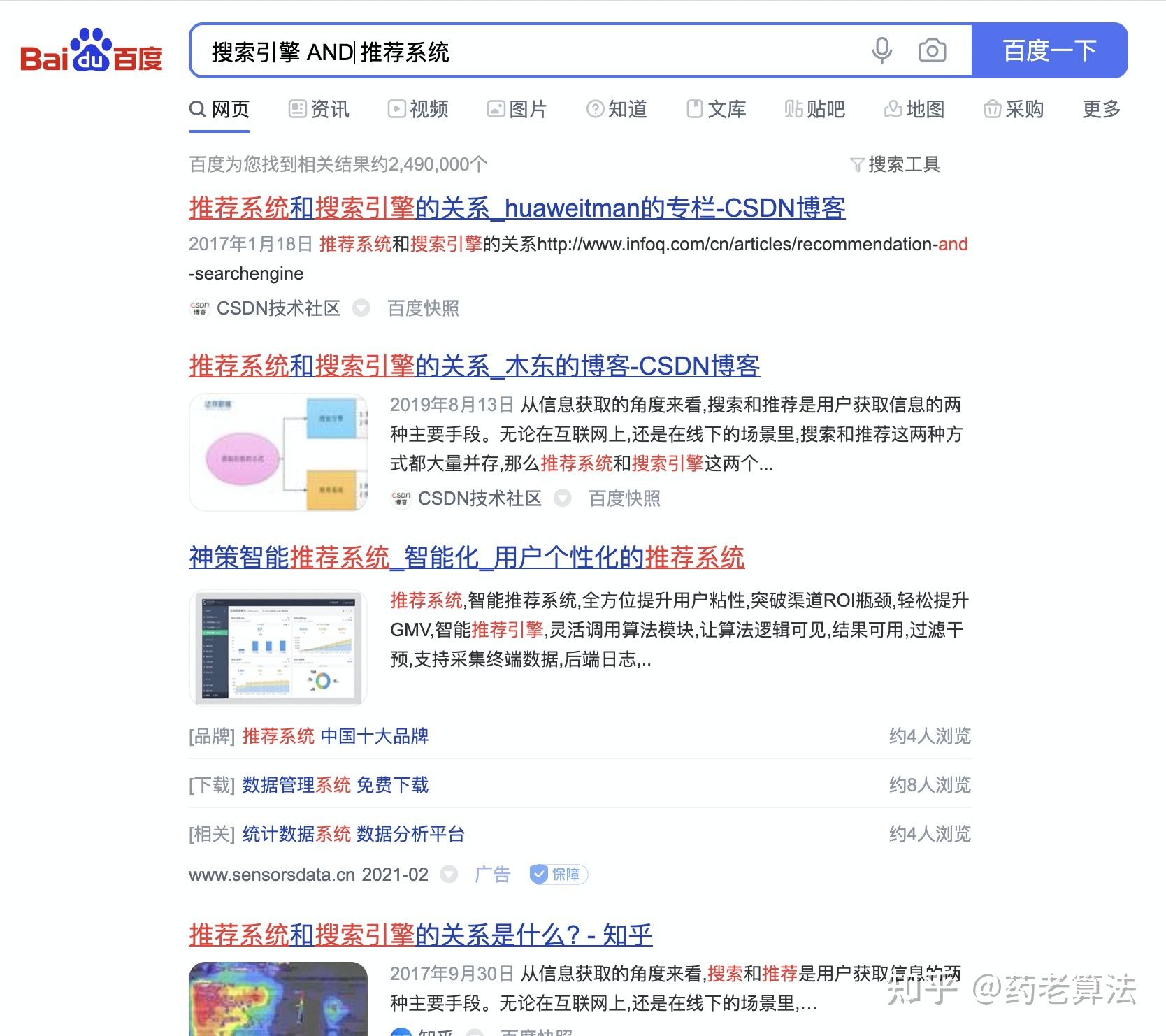
站內搜索
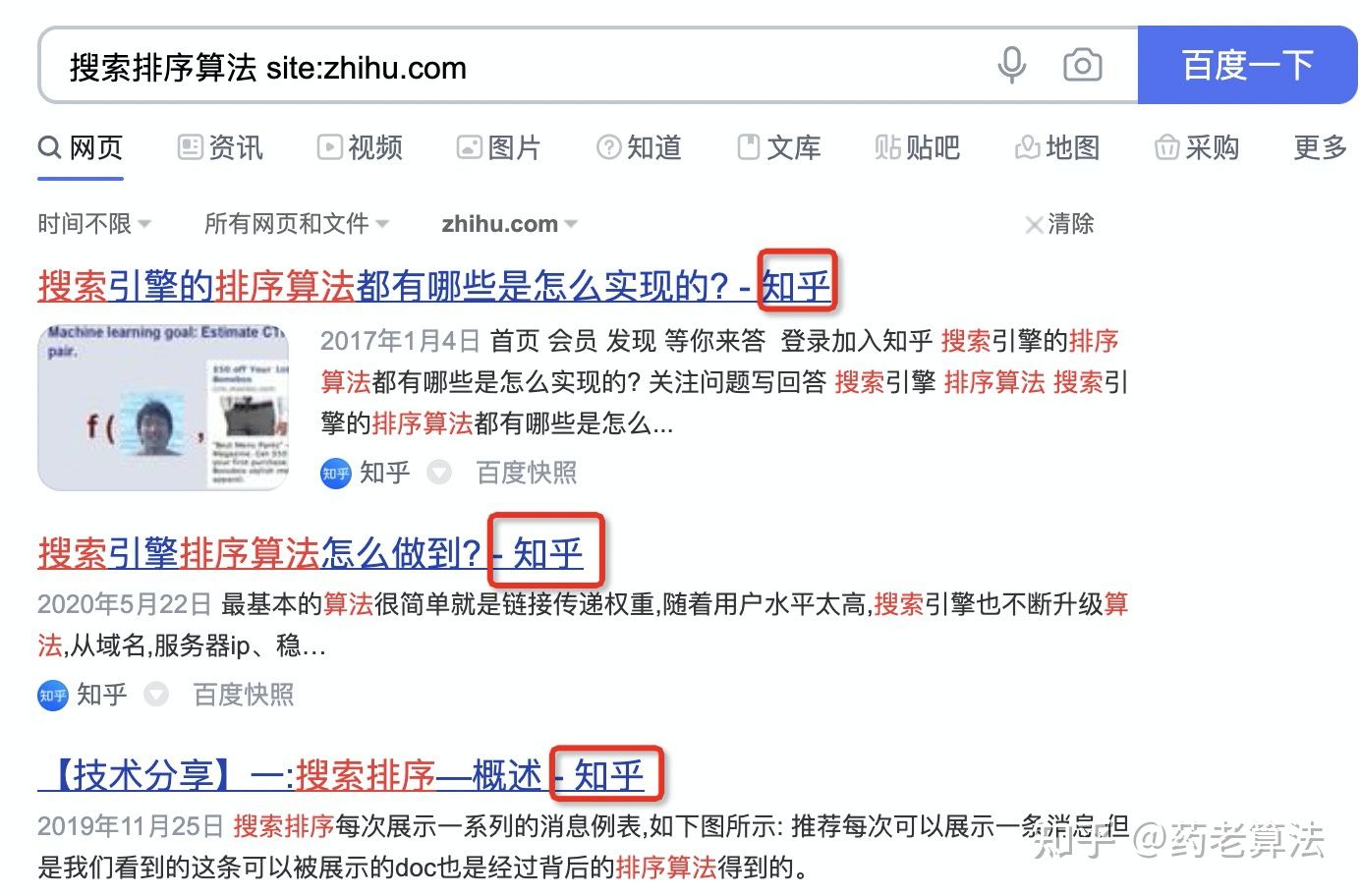
在實際搜索程序中,很多時候我們只想搜索某個站點的結果,比如技術文章我會搜索csdn,想資訊問題我會搜索知乎等,其實有這么一個site指令,讓你搜索某個站點的內容,你想查詢知乎站點中的“搜索排序演算法”,則可以使用“搜索排序演算法 site:zhihu.com”,如下:
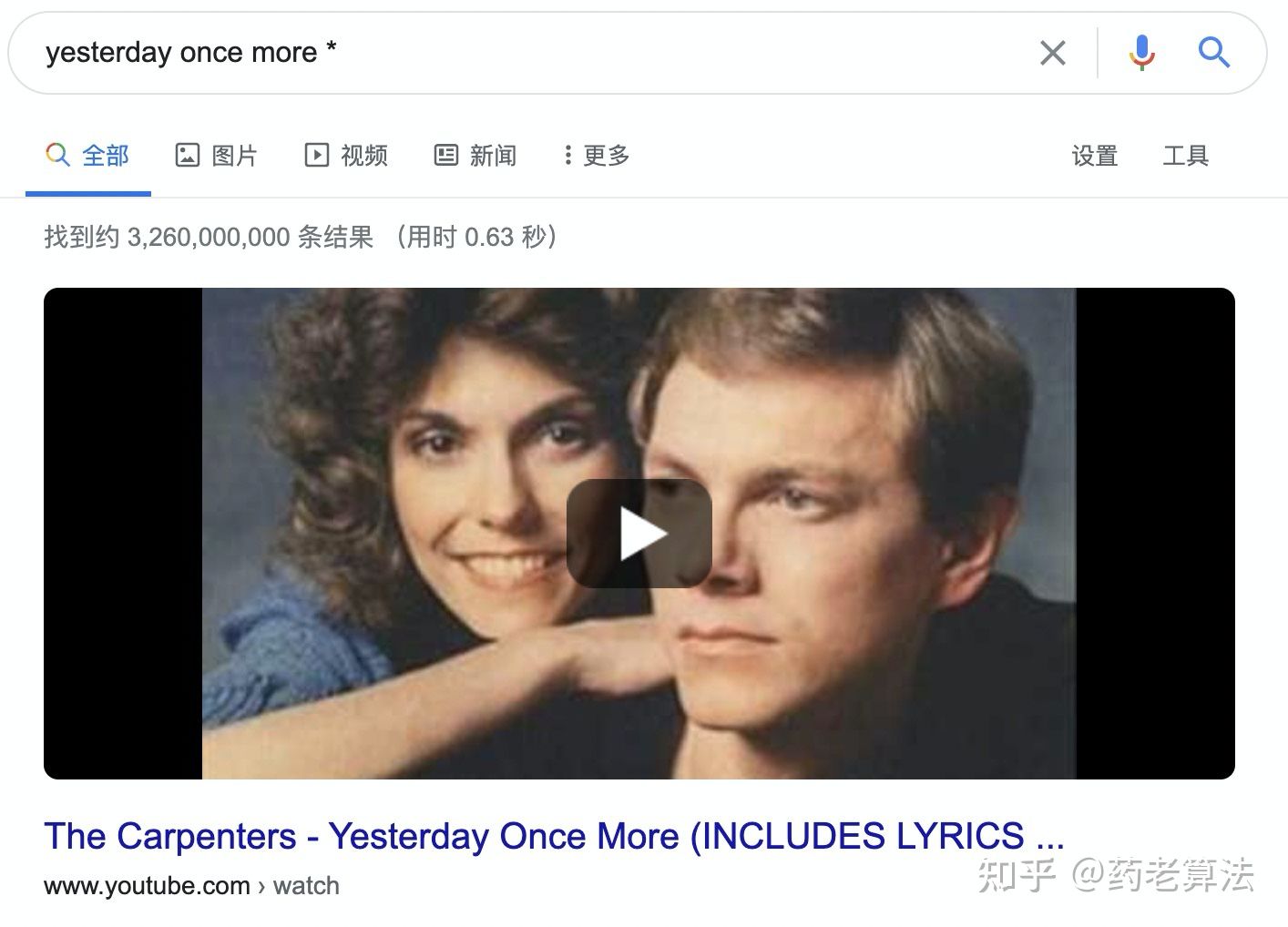
* 星號通配符
有一些場景是我們在搜索程序中,只記得某些文本,但串聯不上,無法整句輸入,則可以使用 * 通配符,比如一些找歌曲和找詩歌的場景,如下:
欄位搜索
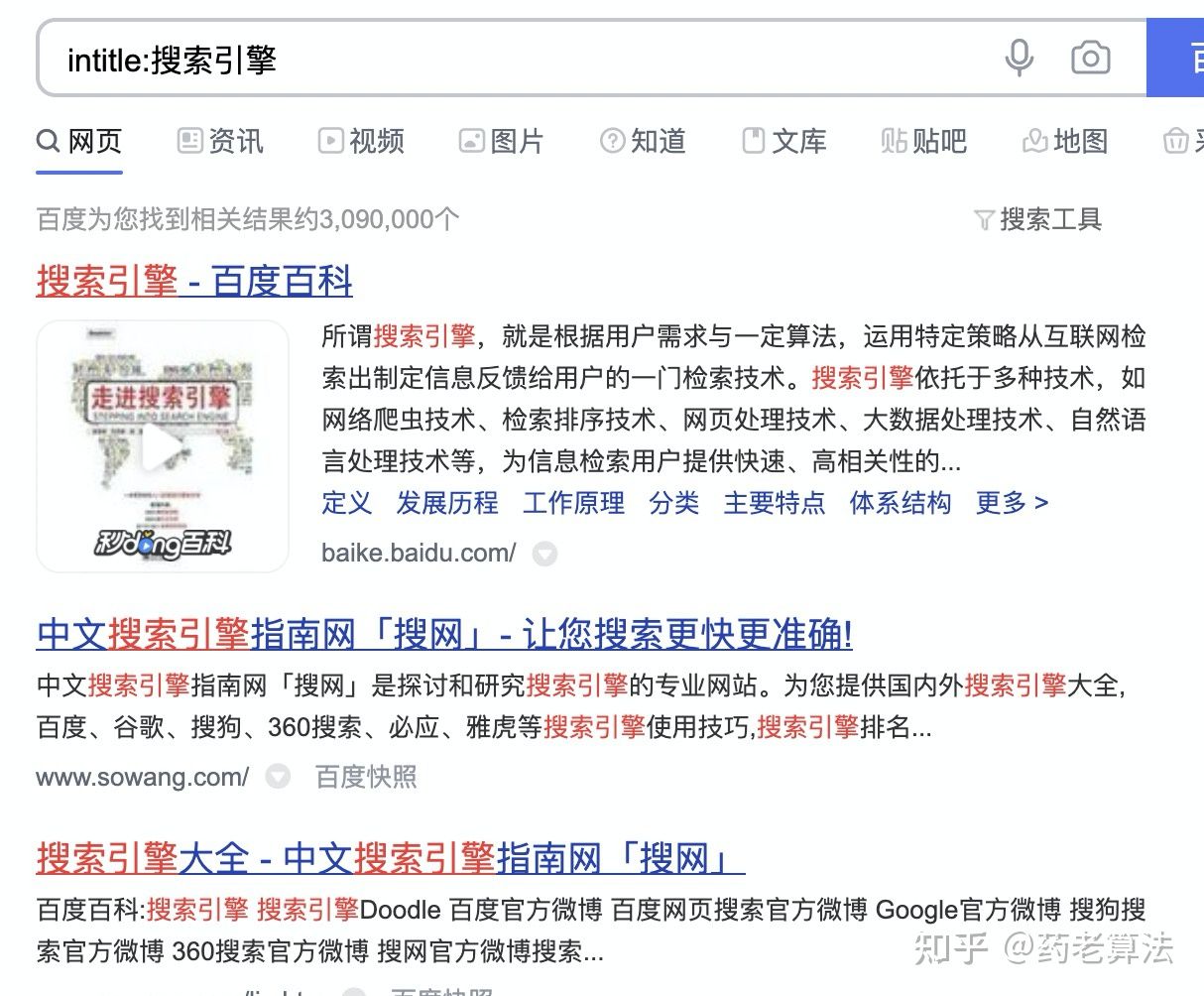
此前文章我們有講過《索引技術》,索引是需要以欄位為基礎的,而google和百度分別開放了幾個欄位供用戶搜索,本文主要講解intitle、inurl、allintitle、allinurl以及filetype這幾個欄位,
intitle:搜索引擎,指的是標題中命中“搜索引擎”的結果,如下:
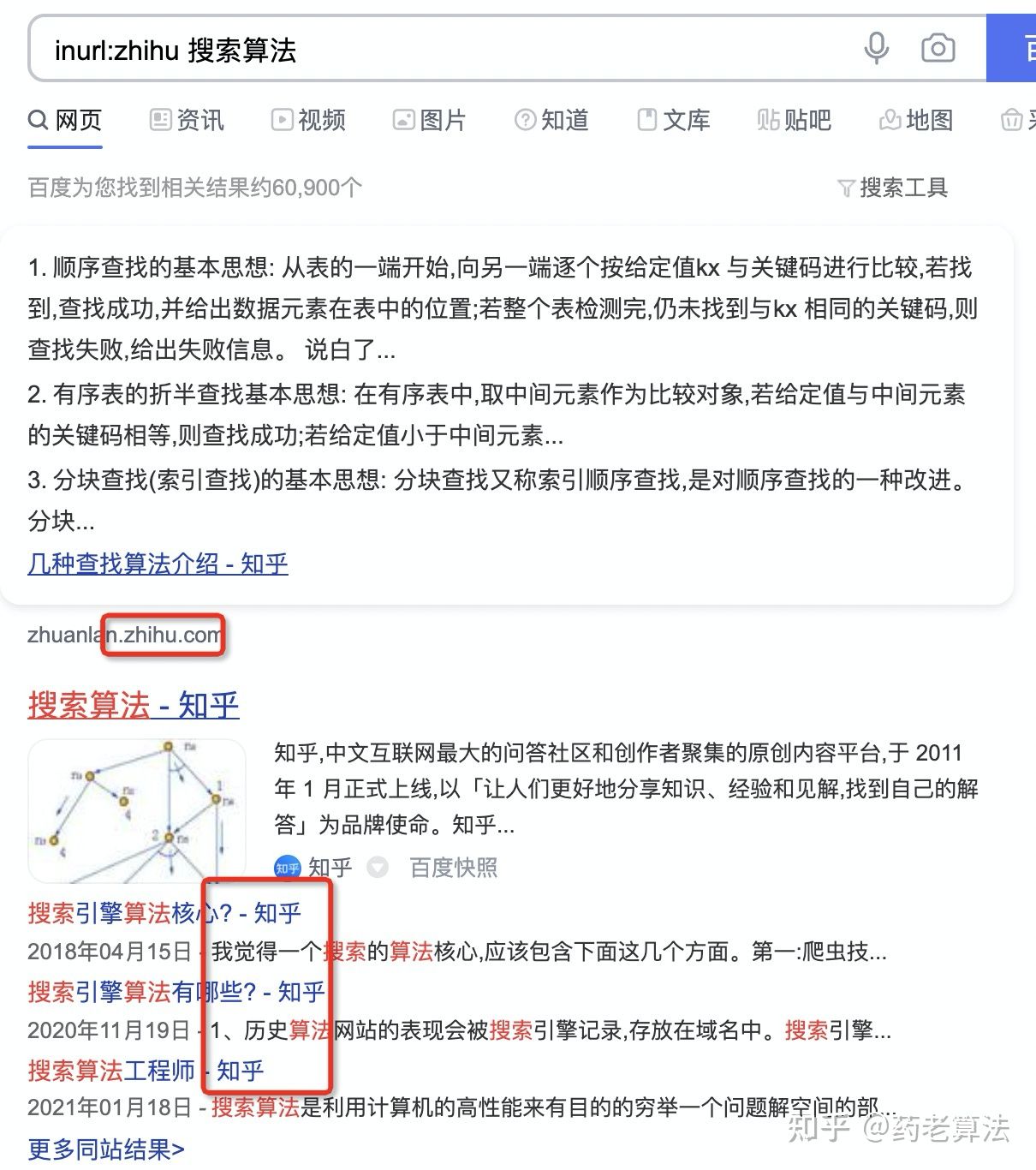
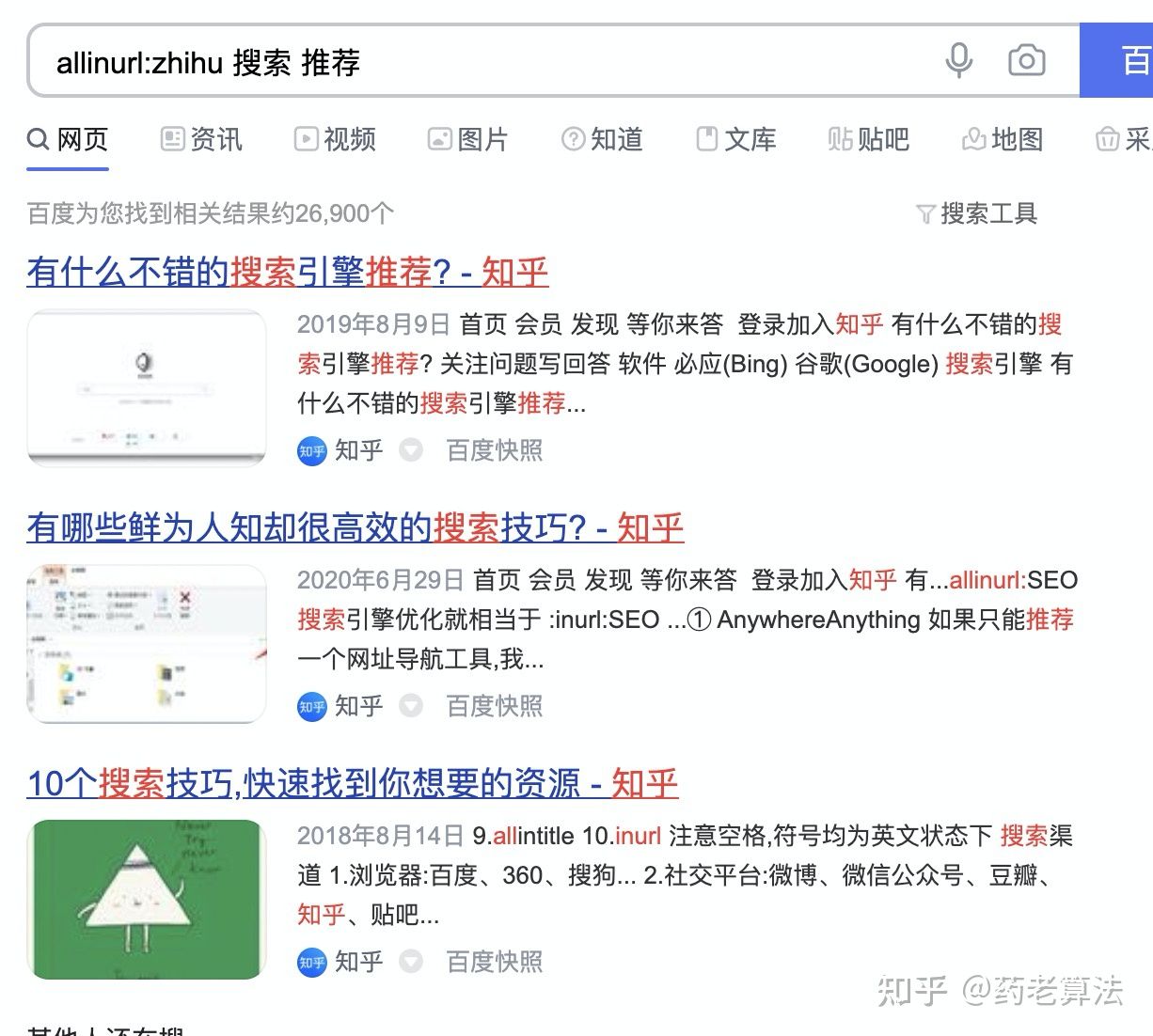
inurl:zhihu,指的是鏈接中命中zhihu的搜索結果,如下:
allintitle和allinurl:指令含意和intitle及inurl一樣,區別在于intitle和inurl后面只能添加一個關鍵詞,而allintitle和allinurl后面能添加多個關鍵詞或者短語,如下:
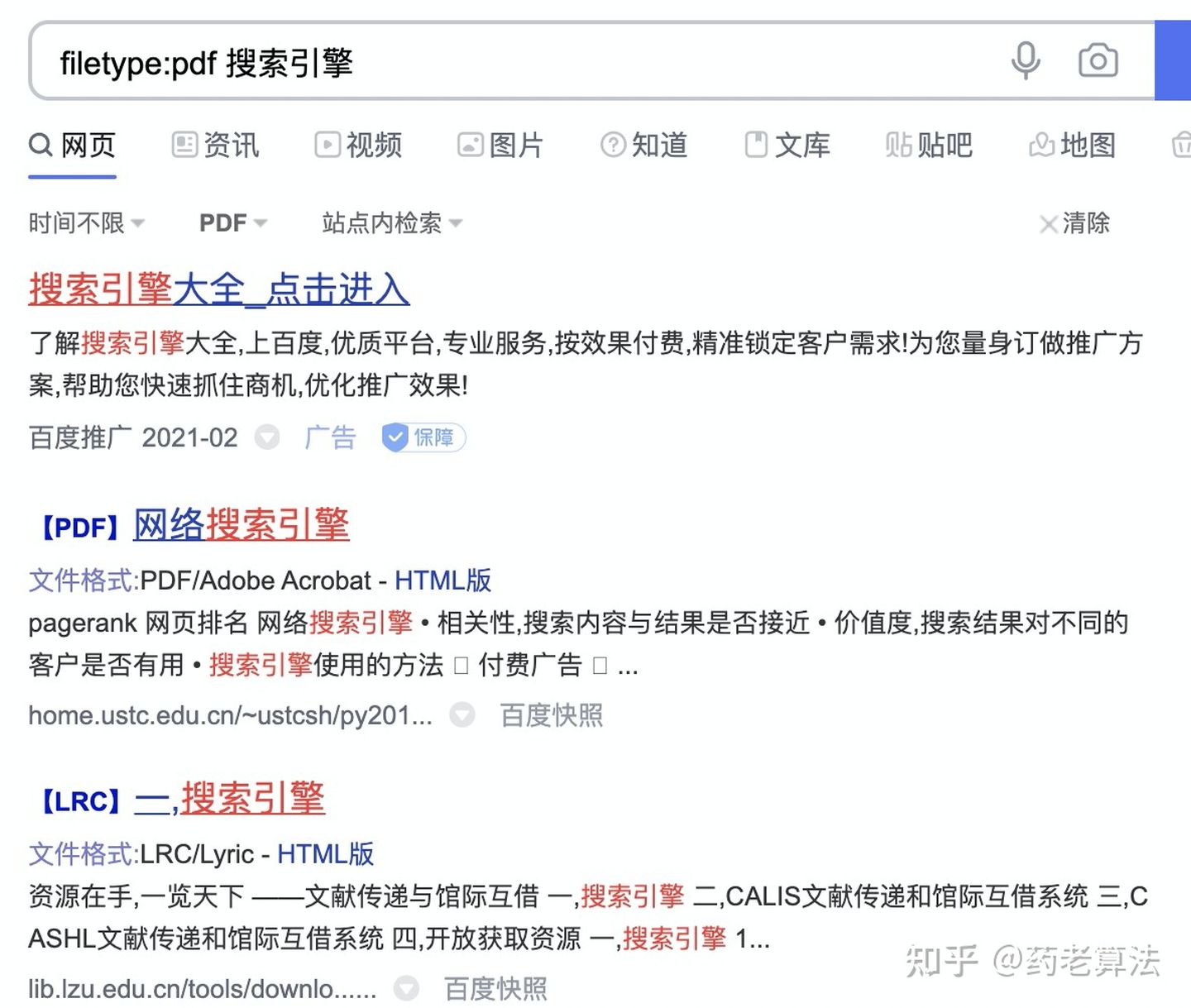
filetype:用于搜索特定檔案格式,google和百度都支持filetype指令,
使用“filetype:pdf 搜索引擎”進行搜索,如下:
寫在最后:
各位大佬能看到這兒,已經閱讀了將近三萬字,至少超過95%的人了,先膜一下大佬~
搜索技術是一項集大成的技術,豈能是區區3萬字能講得透徹的呀!這三萬字很多都是參考、借鑒各位大佬、前輩的文章,在參考中一一列舉出了,
寫這篇三千問的初衷也是對這些知識的一次整理,方便自己日后常查閱常學習,繼續加油!
參考
- 《這就是搜索引擎——核心技術詳解》
- https://www.leiphone.com/news/201511/XD0ZESDzc65GE9me.html
- 《數學之美》
- https://blog.csdn.net/qihoo_tech/article/details/98000090?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.control
- https://zhuanlan.zhihu.com/p/24382357
- https://zhuanlan.zhihu.com/p/338566270
- https://zhuanlan.zhihu.com/p/348159133
- https://www.ddosi.com/b240/
- https://blog.csdn.net/yunqiinsight/article/details/90232254?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-4&spm=1001.2101.3001.4242
- https://blog.csdn.net/zhaipengfei1231/article/details/81186798
- https://blog.csdn.net/malefactor/article/details/2032473
- https://blog.csdn.net/malefactor/category_69592.html
- https://blog.csdn.net/malefactor/article/details/7389311
- https://blog.csdn.net/malefactor/article/details/7401022
- https://blog.csdn.net/a345017062/article/details/51447302?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-14.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-14.control
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282831.html
標籤:AI